This weekend I announced and then hosted Homa Night II, an effort to use
technology to help bridge the chasms that’ve formed between my diaspora of friends as a result mostly of COVID. To a lesser extent
we’ve been made to feel distant from one another for a while as a result of our very diverse locations and lifestyles, but the resulting isolation was certainly compounded by lockdowns
and quarantines.
Long gone are the days when I could put up a blog post to say “Troma Night tonight?” and expect half a dozen friends to turn up at my house.
Back in the day we used to have a regular weekly film night called Troma Night, named after the studio
who dominated our early events and whose… genre… influenced many of our choices thereafter. We had over 300 such film
nights, by my count, before I eventually left our shared hometown of Aberystwyth ten years ago. I wasn’t the last one of the Troma Night
regulars to leave town, but more left before me than after.
Observant readers will spot a previous effort I made this year at hosting a party online.
Earlier this year I hosted Sour Grapes, a murder mystery party (an irregular highlight of our Aberystwyth social calendar,
with thanks to Ruth) run entirely online using a mixture of video chat and “second screen”
technologies. In some ways that could be seen as the predecessor to Homa Night, although I’d come up with most of the underlying technology to make Homa Night possible on a
whim much earlier in the year!
The idea spun out of a few conversations on WhatsApp but the final name – Homa Night – wasn’t agreed until early in November.
How best to make such a thing happen? When I first started thinking about it, during the first of the UK’s lockdowns, I considered a few options:
Streaming video over a telemeeting service (Zoom, Google Meet, etc.)
Very simple to set up, but the quality – as anybody who’s tried this before will attest – is appalling. Being optimised for speech rather than music and sound effects gives the audio
a flat, scratchy sound, video compression artefacts that are tolerable when you’re chatting to your boss are really annoying when they stop you reading a crucial subtitle, audio and
video often get desynchronised in a way that’s frankly infuriating, and everybody’s download speed is limited by the upload speed of the host, among other issues. The major benefit of
these platforms – full-duplex audio – is destroyed by feedback so everybody needs to stay muted while watching anyway. No thanks!
Teleparty or a similar tool Teleparty (formerly Netflix Party, but it now supports more services) is a pretty clever way to get almost exactly what I want:
synchronised video streaming plus chat alongside. But it only works on Chrome (and some related browsers) and doesn’t work on tablets, web-enabled TVs, etc., which would exclude some
of my friends. Everybody requires an account on the service you’re streaming from, potentially further limiting usability, and that also means you’re strictly limited to the media
available on those platforms (and further limited again if your party spans multiple geographic distribution regions for that service). There’s definitely things I can learn from
Teleparty, but it’s not the right tool for Homa Night.
“Press play… now!”
The relatively low-tech solution might have been to distribute video files in advance, have people download them, and get everybody to press “play” at the same time! That’s at least
slightly less-convenient because people can’t just “turn up”, they have to plan their attendance and set up in advance, but it would certainly have worked and I seriously
considered it. There are other downsides, though: if anybody has a technical issue and needs to e.g. restart their player then they’re basically doomed in any attempt to get back
in-sync again. We can do better…
A custom-made synchronised streaming service…?
A custom solution that leveraged existing infrastructure for the “hard bits” proved to be the right answer.
So obviously I ended up implementing my own streaming service. It wasn’t even that hard. In case you want to try your own, here’s how I did it:
Media preparation
First, I used Adobe Premiere to create a video file containing both of the night’s films, bookended and separated by “filler” content to provide an introduction/lobby, an intermission,
and a closing “you should have stopped watching by now” message. I made sure that the “intro” was a nice round duration (90s) and suitable for looping because I planned to hold people
there until we were all ready to start the film. Thanks to Boris & Oliver for the background
music!
Honestly, the intermission was just an excuse to keep my chroma key gear out following its most-recent use.
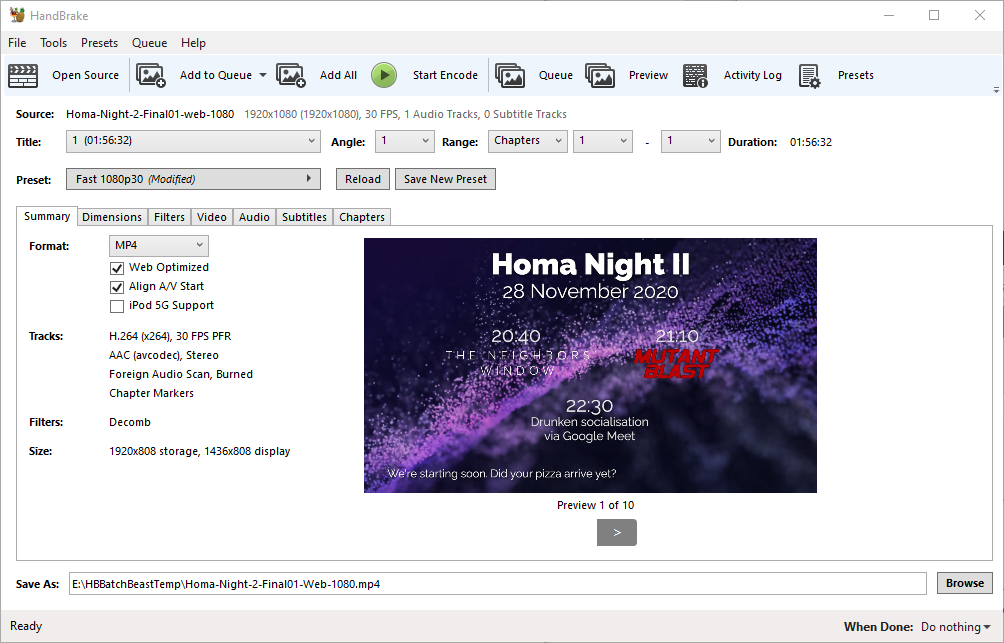
Next, I ran the output through Handbrake to produce “web optimized” versions in 1080p and 720p output sizes. “Web optimized” in this case means that
metadata gets added to the start of the file to allow it to start playing without downloading the entire file (streaming) and to allow the calculation of what-part-of-the-file
corresponds to what-part-of-the-timeline: the latter, when coupled with a suitable webserver, allows browsers to “skip” to any point in the video without having to watch the intervening
part. Naturally I’m encoding with H.264 for the widest possible compatibility.
Even using my multi-GPU computer for the transcoding I had time to get up and walk around a bit.
Real-Time Synchronisation
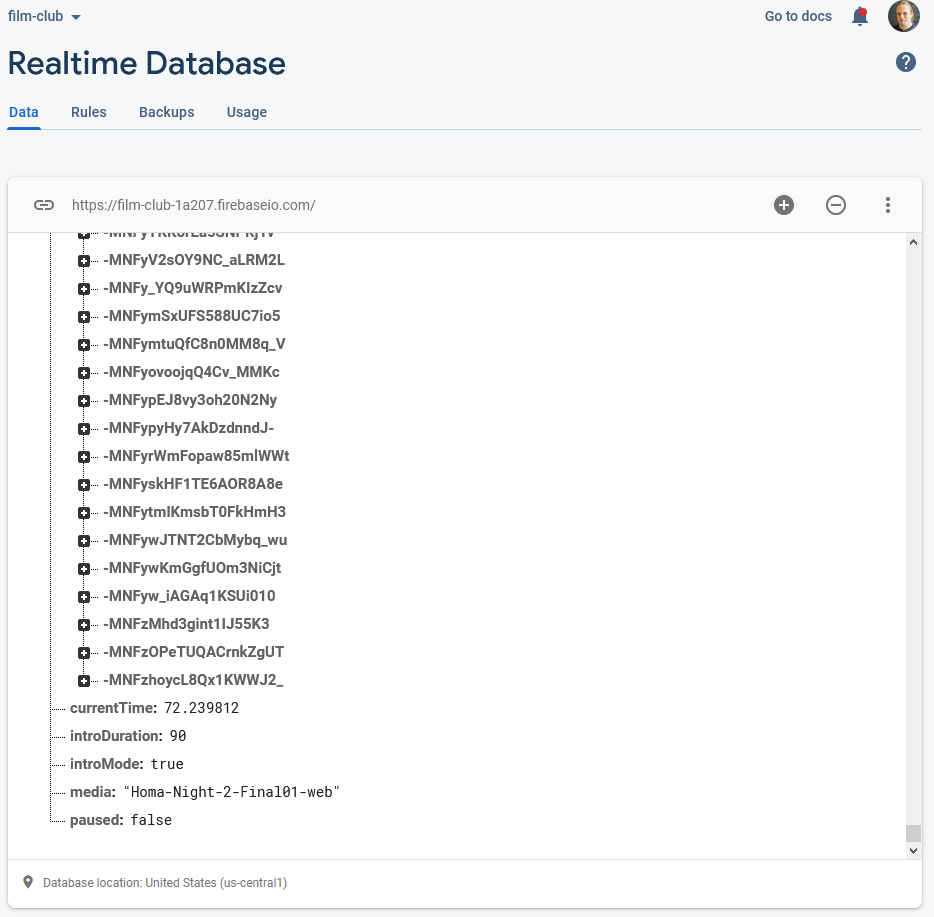
To keep everybody’s viewing experience in-sync, I set up a Firebase account for the application: Firebase provides an easy-to-use Websockets
platform with built-in data synchronisation. Ignoring the authentication and chat features, there wasn’t much
shared here: just the currentTime of the video in seconds, whether or not introMode was engaged (i.e. everybody should loop the first 90 seconds, for now), and
whether or not the video was paused:
Firebase makes schemaless real-time databases pretty easy.
To reduce development effort, I never got around to implementing an administrative front-end; I just manually went into the Firebase database and acknowledged “my” computer as being an
administrator, after I’d connected to it, and then ran a little Javascript in my browser’s debugger to tell it to start pushing my video’s currentTime to the server every
few seconds. Anything else I needed to edit I just edited directly from the Firebase interface.
Other web clients’ had Javascript to instruct them to monitor these variables from the Firebase database and, if they were desynchronised by more than 5 seconds, “jump” to the correct
point in the video file. The hard part of the code… wasn’t really that hard:
// Rewind if we're passed the end of the intro loopfunction introModeLoopCheck() {
if (!introMode) return;
if (video.currentTime > introDuration) video.currentTime =0;
}
function fixPlayStatus() {
// Handle "intro loop" modeif (remotelyControlled && introMode) {
if (video.paused) video.play(); // always play
introModeLoopCheck();
return; // don't look at the rest
}
// Fix current timeconst desync =Math.abs(lastCurrentTime - video.currentTime);
if (
(video.paused && desync > DESYNC_TOLERANCE_WHEN_PAUSED) ||
(!video.paused && desync > DESYNC_TOLERANCE_WHEN_PLAYING)
) {
video.currentTime = lastCurrentTime;
}
// Fix play statusif (remotelyControlled) {
if (lastPaused &&!video.paused) {
video.pause();
} elseif (!lastPaused && video.paused) {
video.play();
}
}
// Show/hide paused notification
updatePausedNotification();
}
Web front-end
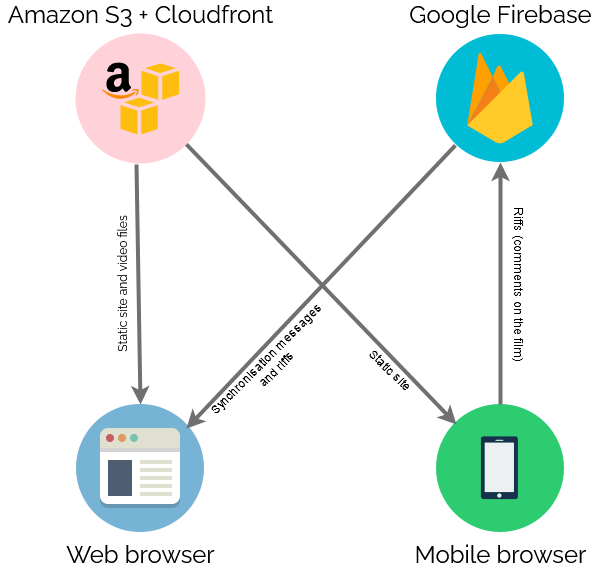
Finally, there needed to be a web page everybody could go to to get access to this. As I was hosting the video on S3+CloudFront anyway, I put the HTML/CSS/JS there too.
I decided to carry the background theme of the video through to the web interface too.
I tested in Firefox, Edge, Chrome, and Safari on desktop, and (slightly less) on Firefox, Chrome and Safari on mobile. There were a few quirks to work around, mostly to do with browsers
not letting videos make sound until the page has been interacted with after the video element has been rendered, which I carefully worked-around by putting a popup “over” the
video to “enable sync”, but mostly it “just worked”.
Delivery
On the night I shared the web address and we kicked off! There were a few hiccups as some people’s browsers got disconnected early on and tried to start playing the film before it was
time, and one of these even when fixed ran about a minute behind the others, leading to minor spoilers leaking via the rest of us riffing about them! But on the whole, it worked. I’ve
had lots of useful feedback to improve on it for the next version, and I might even try to tidy up my code a bit and open-source the results if this kind of thing might be useful to
anybody else.
I’ve been thinking a lot lately about the messages we send to our children about their role, and ours as adults, in keeping them safe from people who might victimise them. As a society,
our message has changed over the decades: others of my culture and generation will, like me, have seen the gradual evolution from “stranger danger” to “my body, my choice”. And it’s still evolving.
But as Kristin eloquently (and emotionally: I cried my eyes out!) explains, messages like these can subconsciously teach children that they alone are responsible for keeping
themselves from harm. And so when some of them inevitably fail, the shame of their victimisation – often already taboo – can be magnified by the guilt of their inability to prevent it.
And as anybody who’s been a parent or, indeed, a child knows that children aren’t inclined to talk about the things they feel guilty about.
And in the arms race of child exploitation, abusers will take advantage of that.
What I was hoping was to have a nice, concrete answer – or at least an opinion – to the question: how should we talk to children about their safety in a way that both tries to
keep them safe but ensures that they understand that they’re not to blame if they are victimised? This video doesn’t provide anything like that. Possibly there aren’t
easy answers. As humans, as parents, and as a society, we’re still learning.
Sometimes, I miss Troma Night. Hanging out with my friends and watching awful/awesome films over pizza and beer.
If only there were a way to do it during lockdown?
Oh wait, there is: danq.me/homa-night/homa-night-2
Having Boris-biked from Brixton to Brighton, it seemed only right to give Limebikes the same treatment. I started looking for places with Lime in the name and quickly found a route
from Dorset to Edinburgh, which would run from Lyme Regis to Limekilns by Limebike.
The catch was that it was 550 miles, it would take (at best) 6 days to get there and back, and Limebikes were charged at 15p per minute. A quick bit of maths showed that this would
likely cost £1296 – EACH -so it was crucial to get the company on board.
It’s also worth mentioning again that they are E-bikes, designed to give you a boost when pedalling away from traffic lights and, in the words of the companies CEO, ‘Be difficult to
throw up a tree’.
This meant two things:
There is a battery with a range of about 40 miles and that battery would definitely run out long before we reached Scotland.
The bikes are HEAVY, 35kg to be precise.
So it might seem easy to ride a power assisted bike the length of the country, but it was sounding harder by the minute.
…
I’ve been helping Ruth‘s brother Robin (of Challenge Robin 1 & 2 and Thames Path walk fame, among many, many, many, otherthings) to launch himself a new blog,
expanding on the ideas of 52 Reflect (his previous site, most-recently mentioned when I joined him in a midwinter mountaineering expedition
the winter before last) to create a site all about his many varied and amazing adventures. If you like to see one man do bloody stupid things in an effort to push himself to his
physical limits, explore the world, and see amazing places… go take a sneak peek at his new, under construction and changing every day, site: The Improbable Blog.
Oh, and there’s gonna be a podcast too, for those of you into such things.
Today we reinstated youtube-dl, a popular project on GitHub, after we received additional information about the project that enabled us to reverse a Digital
Millennium Copyright Act (DMCA) takedown.
…
This is a Big Deal. For two reasons:
Firstly, youtube-dl is a spectacularly useful project. I’ve used it for many years to help me archive my own content, to improve my access to content that’s freely
available on the platform, and to help centralise (freely available) metadata to keep my subscriptions on video-sharing sites. Others have even more-important uses for the tool. I love youtube-dl, and I’d never considered the possibility
that it could be used to circumvent digital restrictions (apparently it’s got some kind of geofence-evading features you can optionally enable, for people who don’t have a
multi-endpoint VPN I guess?… I note that it definitely doesn’t break DRM…) until its GitHub repo got taken down the other week.
Which was a bleeding stupid thing to use a DMCA request on, because, y’know: Barbara Streisand Effect. Lampshading that a free, open-source tool could be used for people’s convenience is likely to
increase awareness and adoption, not decrease it! Huge thanks to the EFF for
stepping up and telling GitHub that they’d got it wrong (this letter is
great reading, by the way).
But secondly, GitHub’s response is admirable and – assuming their honour their new stance –
effective. They acknowledge their mistake, then go on to set out a new process by which they’ll review takedown requests. That new process includes technical and legal review, erring on
the side of the developer rather than the claimant (i.e. “innocent until proven guilty”), multiparty negotiation, and limiting the scope of takedowns by allowing violators to export
their non-infringing content after the fact.
I was concerned that the youtube-dl takedown might create a FOSS “chilling effect” on GitHub. It still
might: in the light of it, I for one have started backing up my repositories and those of projects I care about to an different Git server! But with this response, I’d still be
confident hosting the main copy of an open-source project on GitHub, even if that project was one which was at risk of being mistaken for copyright violation.
Note that the original claim came not from Google/YouTube as you might have expected (if you’ve just tuned in) but from the RIAA, based on the fact that
youtube-dlcould be used to download copyrighted music videos for enjoyment offline. If you’re reminded of Sony v. Universal City Studios (1984) – the case behind the “Betamax standard” – you’re not
alone.
I’ve been working as part of the team working on the new application framework called the Endpoint Encabulator and wanted to share with you what I think makes our project so
exciting: I promise it’ll make for two minutes of your time you won’t seen forget!
Naturally, this project wouldn’t have been possible without the pioneering work that preceded it by John Hellins Quick, Bud Haggart, and others. Nothing’s invented in a vacuum. However,
my fellow developers and I think that our work is the first viable encabulator implementation to provide inverse reactive data binding suitable for deployment in front of a
blockchain-driven backend cache. I’m not saying that all digital content will one day be delivered through Endpoint Encabulator, but… well; maybe it will.
If the technical aspects go over your head, pass it on to a geeky friend who might be able to make use of my work. Sharing is caring!
I was chatting with a fellow web developer recently and made a joke about the HTML <blink> and
<marquee> tags, only to discover that he had no idea what I was talking about. They’re a part of web history that’s fallen off the radar and younger developers are
unlikely to have ever come across them. But for a little while, back in the 90s, they were a big deal.
Even Macromedia Dreamweaver, which embodied the essence of 1990s web design, seemed to treat wrapping
<blink> in <marquee> as an antipattern.
Invention of the <blink> element is often credited to Lou Montulli, who wrote pioneering web browser Lynx before being joining Netscape in 1994. He insists that he didn’t write any
of the code that eventually became the first implementation of <blink>. Instead, he claims: while out at a bar (on the evening he’d first meet his wife!), he
pointed out that many of the fancy new stylistic elements the other Netscape engineers were proposing wouldn’t work in Lynx, which is a text-only browser. The fanciest conceivable
effect that would work across both browsers would be making the text flash on and off, he joked. Then another engineer – who he doesn’t identify – pulled a late night hack session and
added it.
And so it was that when Netscape Navigator 2.0 was released in 1995 it added support for
the <blink> tag. Also animated GIFs and the first inklings of JavaScript, which collectively
would go on to define the “personal website” experience for years to come. Here’s how you’d use it:
<BLINK>This is my blinking text!</BLINK>
With no attributes, it was clear from the outset that this tag was supposed to be a joke. By the time HTML4 was
published as a a recommendation two years later, it was documented as being a joke. But the Web of the late 1990s
saw it used a lot. If you wanted somebody to notice the “latest updates” section on your personal home page, you’d wrap a <blink> tag around the title (or,
if you were a sadist, the entire block).
If you missed this particular chapter of the Web’s history, you can simulate it at Cameron’s World.
In the same year as Netscape Navigator 2.0 was released, Microsoft released Internet Explorer
2.0. At this point, Internet Explorer was still very-much playing catch-up with the features the Netscape team had implemented, but clearly some senior Microsoft engineer took a
look at the <blink> tag, refused to play along with the joke, but had an innovation of their own: the <marquee> tag! It had a whole suite of attributes to control the scroll direction, speed, and whether it looped or bounced backwards and forwards. While
<blink> encouraged disgusting and inaccessible design as a joke, <marquee> did it on purpose.
<MARQUEE>Oh my god this still works in most modern browsers!</MARQUEE>
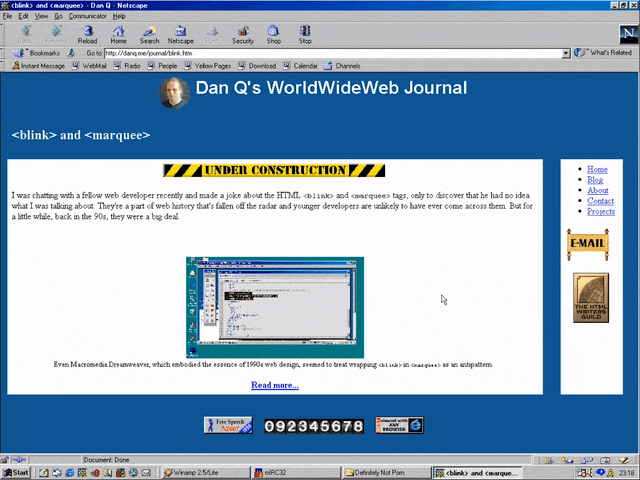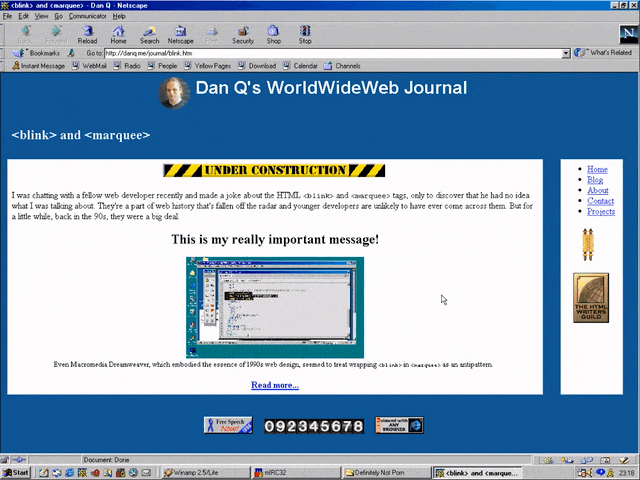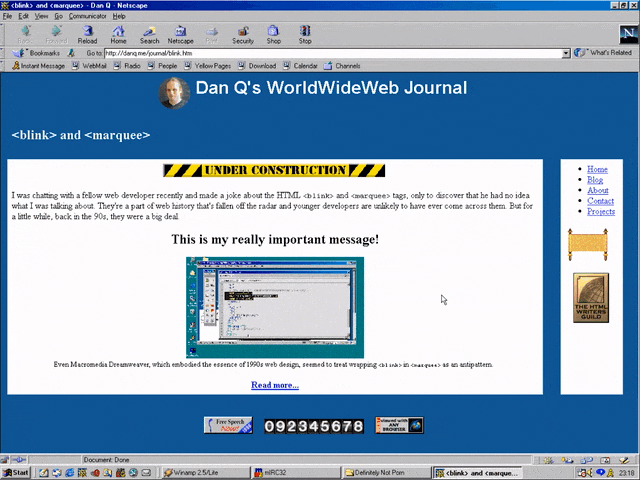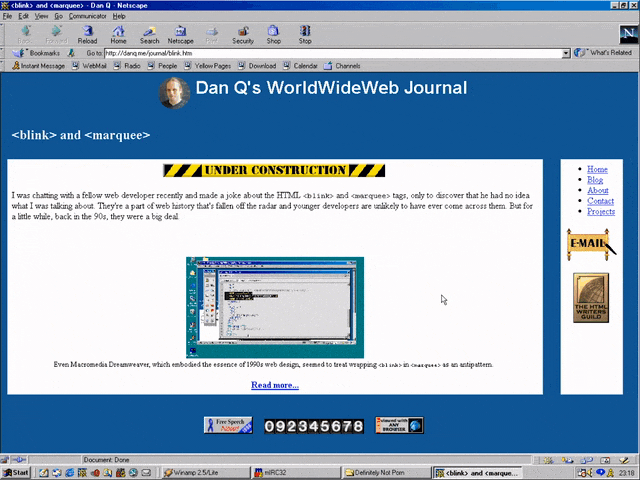
But here’s the interesting bit: for a while in the late 1990s, it became a somewhat common practice to wrap content that you wanted to emphasise with animation in both a
<blink> and a <marquee> tag. That way, the Netscape users would see it flash, the IE users
would see it scroll or bounce. Like this:
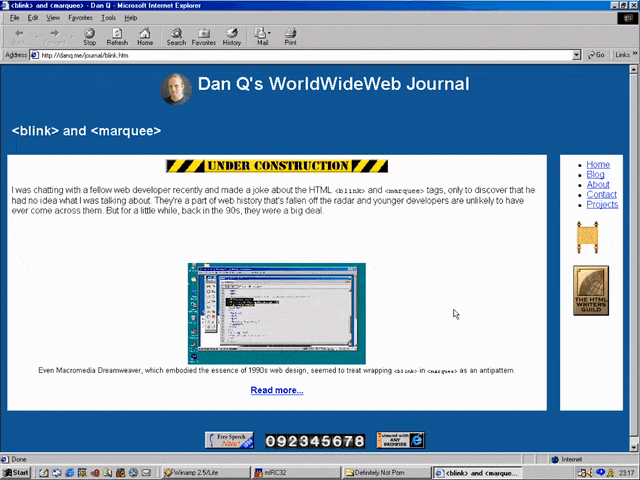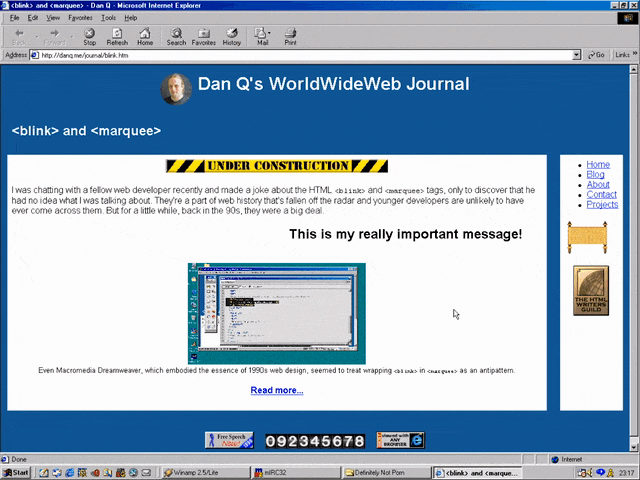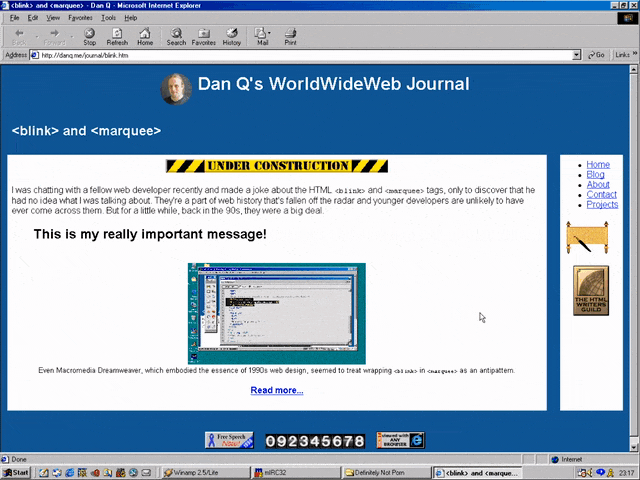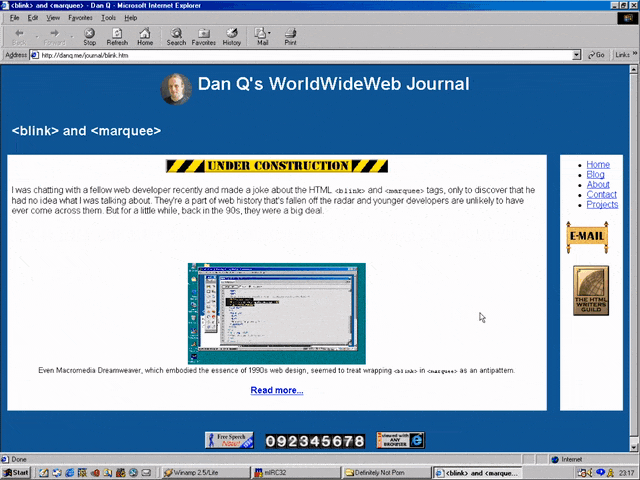
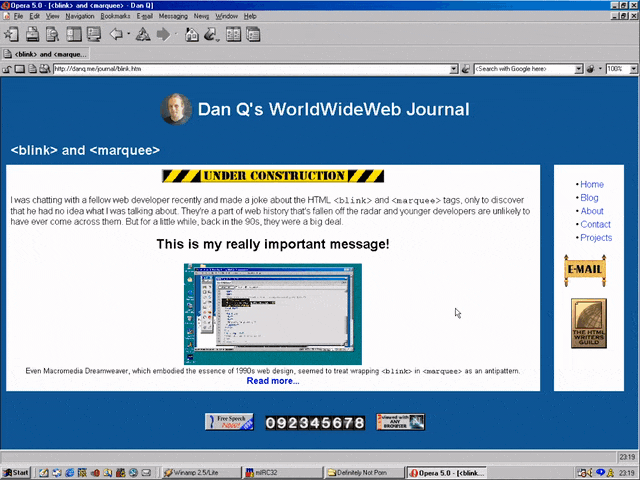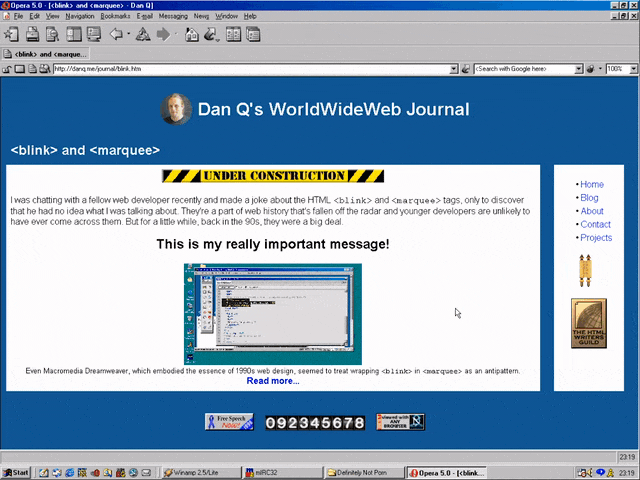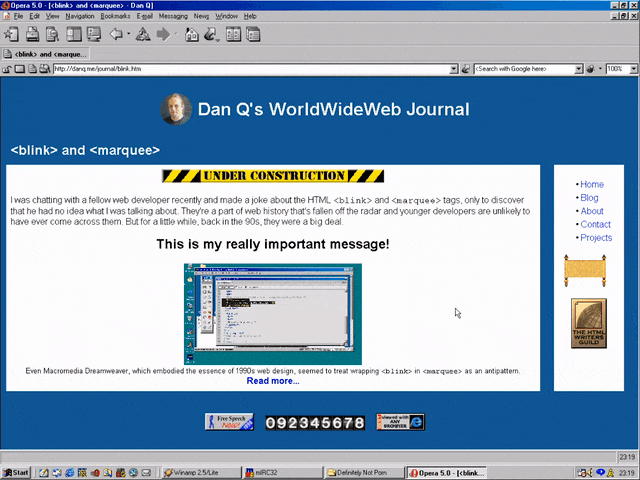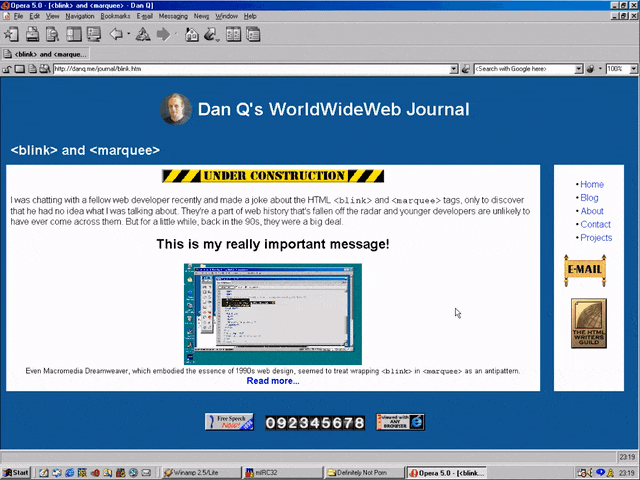
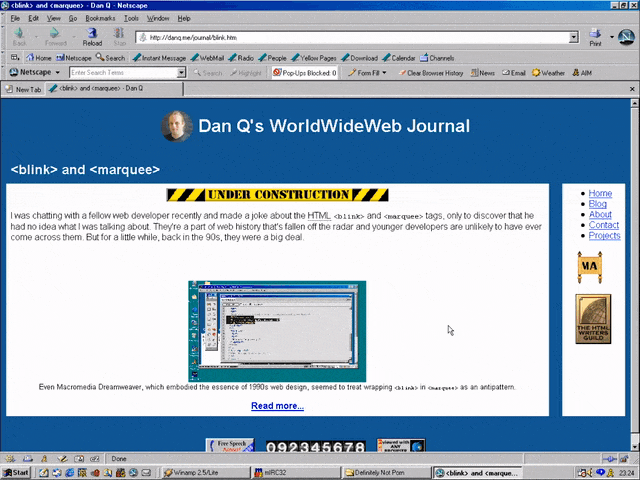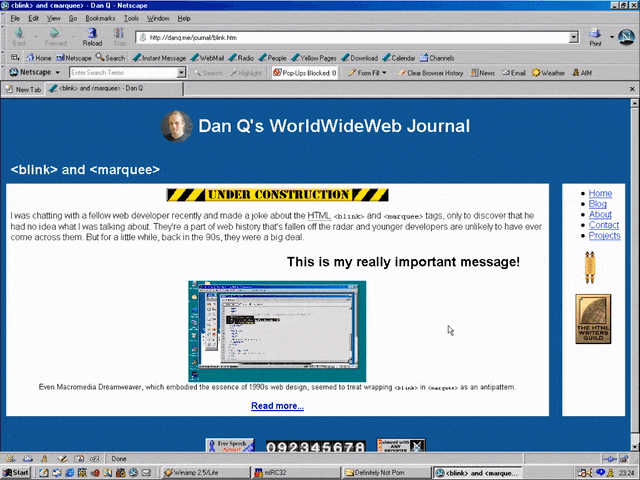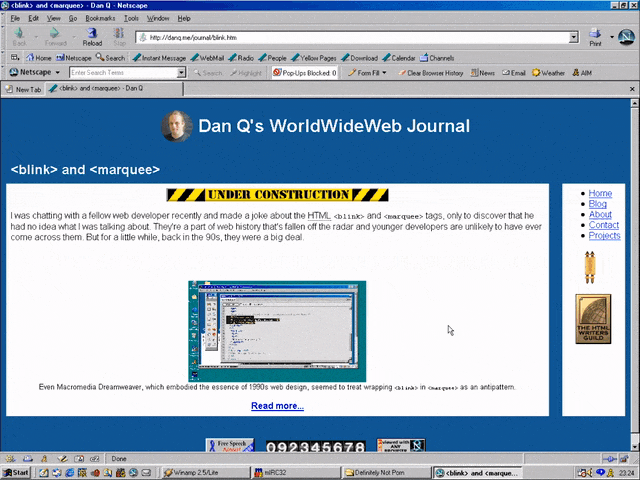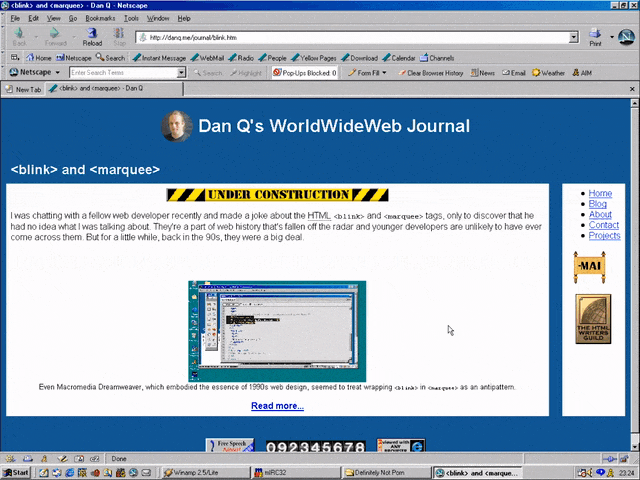
<MARQUEE><BLINK>This is my really important message!</BLINK></MARQUEE>
Wrap a <blink> inside a <marquee> and IE users will see the marquee. Delightful.
The web has always been built on Postel’s Law: a web browser should assume that it won’t understand everything it reads,
but it should provide a best-effort rendering for the benefit of its user anyway. Ever wondered why the modern <video> element is a block rather than a self-closing
tag? It’s so you can embed within it code that an earlier browser – one that doesn’t understand <video> – can read (a browser’s default state when seeing a
new element it doesn’t understand is to ignore it and carry on). So embedding a <blink> in a <marquee> gave you the best of both worlds, right?
(welll…)
Wrap a <blink> inside a <marquee> and Netscape users will see the blink. Joy.
Better yet, you were safe in the knowledge that anybody using a browser that didn’t understand either of these tags could still read your content. Used properly, the
web is about progressive enhancement. Implement for everybody, enhance for those who support the shiny features. JavaScript and CSS can be applied with the same rules, and doing so pays dividends in maintainability and accessibility (though, sadly, that doesn’t stop people writing
sites that needlessly require these technologies).
Personally, I was a (paying! – back when people used to pay for web browsers!) Opera user so I mostly saw neither <blink> nor <marquee> elements.
I don’t feel like I missed out.
I remember, though, the first time I tried Netscape 7, in 2002. Netscape 7 and its close descendent are, as far as I can tell, the only web browsers to support both<blink> and <marquee>. Even then, it was picky about the order in which they were presented and the elements wrapped-within them. But support was
good enough that some people’s personal web pages suddenly began to exhibit the most ugly effect imaginable: the combination of both scrolling and flashing text.
If Netscape 7’s UI didn’t already make your eyes bleed (I’ve toned it down here by installing the “classic skin”), its simultaneous
rendering of <blink> and <marquee> would.
The <blink> tag is very-definitely dead (hurrah!), but you can bring it back with pure CSS if you must.
<marquee>, amazingly, still survives, not only in polyfills but natively, as you might be able to see above. However, if you’re in any doubt as to whether or not
you should use it: you shouldn’t. If you’re looking for digital nostalgia, there’s a whole
rabbit hole to dive down, but you don’t need to inflict <marquee> on the rest of us.
Watched the pilot of Webbed Briefs by @heydonworks (of Every Layout fame). It’s a sarcastic independent vlog
about web technologies, so I immediately fell in love and subscribed to the feed…
VPNs have long been essential online tools that provide security, freedom, and most importantly, privacy. Each day, hundreds of millions of internet users connect to a VPN to
prevent their online activities from being tracked and monitored so that they can privately access web resources. In other words, the very purpose of a VPN is to prevent the
type of surveillance that Google engages in on a massive and unprecedented scale.
Google knows this, and in their whitepaper discussing VPN by Google One, Google acknowledges that VPN usage is becoming mainstream and that “up to 25% of all internet users accessed a VPN within the
last month of 2019.” Increasing VPN usage unfortunately poses a significant problem for Google, by making it more difficult to track users across the internet, mine their data, and
target them with advertisements. In short, VPNs undermine Google’s power.
…
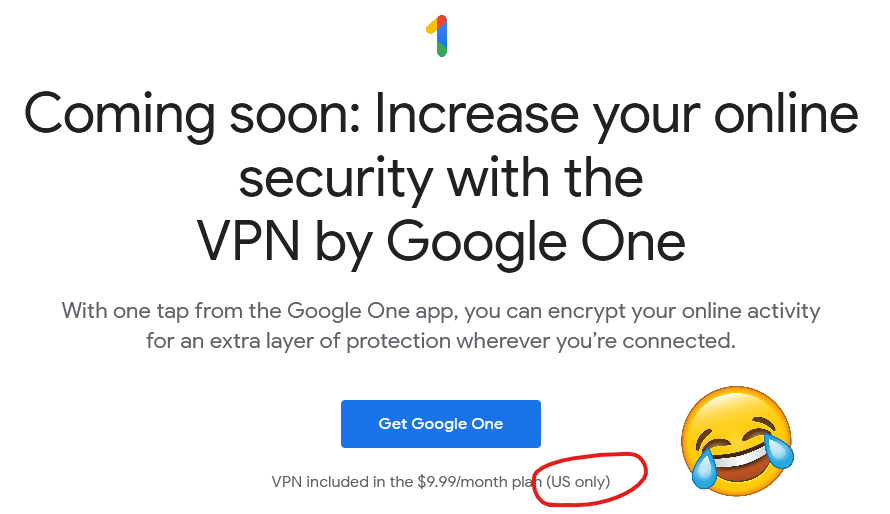
So yeah, it turns out that Google are launching a VPN service. I just checked,
and it’s not available to me anyway because it’s US-only (apparently nobody explained to Google the irony of having a VPN service that’s geofenced), but that’s pretty academic because I wasn’t going to touch it with a barge pole in the first place.
Is it 1 April already, Google?
Google already collect data on your browsing habits if you use their products. And I’m not just talking about Chrome, which of course continues to track you using your Google Account even after you log out and clear your cookies, and Google’s ubiquitous Web
tools, but also the tracking pixels hidden on every other website thanks to Google Analytics, AdWords, reCAPTCHA, Google Fonts, and the like. Sure, you can use e.g. uMatrix to stop all of these (although I’m in need of a
replacement), but that’s not a solution for, y’know, normal people. Container tabs help and you should
absolutely use them, but they don’t quite go far enough. It’s a challenge.
Switch to their VPN, though, and they’re suddenly able to track all of your browsing activity, in any browser on your
device. And probably many of the desktop applications you run, too, as most of them “phone home” for updates or functionality. And because it’s a paid-for VPN service, this data can be instantly linked to your real-world identity. By a company that’s demonstrated its willingness to misuse that data for their own benefit (or for the benefit of overreaching law enforcement agencies). Yeah: no deal,
Google.
Perhaps the only company I’d trust less to provide a VPN service would be Facebook, because you just know they’d be
doing so exclusively to undermine individual privacy. Oh wait;
that’s exactly what they did. Sigh.
On our first day‘s walking along the
Thames Path, Robin and I had trouble finding any evidence of water for some time. On our second day, we did not have this problem.
After weeks of sustained rain, the fields we walked over as we left Cricklade behind were extremely soggy. On our way out of town we passed Cricklade Millennium Wood, I took a
picture for the purpose of mocking it for being very small but later discovered it’s too small to appear on Google Maps and became oddly defensive of it – it’s trying, damn it, we
should at least acknowledge its existence.
…
Ruth and her brother Robin (of Challenge Robin/Challenge Robin II fame on this blog, among manyothercrazyadventures) have taken it upon themselves to walk the entirety of the Thames Path from the source of the river (or rather, one of
the many symbolic sources) to the sea, over the course of a series of separate one-day walks. I’ve mostly been acting as backup-driver so far, but I might join them for a leg or two
later on.
In any case, Ruth’s used it as a welcome excuse to dust off her blog and write about the experience, and it’s fun and delightful and you should follow along and give her a digital
cheer. The first part is here; the second part landed
yesterday.




 Levelled up my blood donation game!
Levelled up my blood donation game!