Sometimes, code is risky to change and expensive to refactor.
In such a situation, a seemingly good idea would be to rewrite it.
From scratch.
Here’s how it goes:
You discuss with management about the strategy of stopping new features for some time, while you rewrite the existing app.
You estimate the rewrite will take 6 months to cover what the existing app does.
A few months in, a nasty bug is discovered and ABSOLUTELY needs to be fixed in the old code. So you patch the old code and the new one too.
A few months later, a new feature has been sold to the client. It HAS TO BE implemented in the old code—the new version is not ready yet! You need to go back to the old code but
also add a TODO to implement this in the new version.
After 5 months, you realize the project will be late. The old app was doing way more things than expected. You start hustling more.
After 7 months, you start testing the new version. QA raises up a lot of things that should be fixed.
After 9 months, the business can’t stand “not developing features” anymore. Leadership is not happy with the situation, you are tired. You start making changes to the old,
painful code while trying to keep up with the rewrite.
Eventually, you end up with the 2 systems in production. The long-term goal is to get rid of the old one, but the new one is not ready yet. Every feature needs to be implemented
twice.
Sounds fictional? Or familiar?
Don’t be shamed, it’s a very common mistake.
…
I’ve rewritten legacy systems from scratch before. Sometimes it’s all worked out, and sometimes it hasn’t, but either way: it’s always been a lot more work than I could have
possibly estimated. I’ve learned now to try to avoid doing so: at least, to avoid replacing a single monolithic (living) system in a monolithic way. Nicholas gives an even-better
description of the true horror of legacy reimplementation, and promotes progressive strangulation as a candidate solution.
Found with fleeblewidget on a day trip to London from Oxford. Finding was pretty easy – GPSr dropped us right on it
and we spotted it immediately. Waiting for gaps in the human traffic, even on this rainy morning, during which to retrieve it was harder! TFTC.
An easy find with fleeblewidget during a day trip to London from Oxford. Posed for a photo in front of the bridge to give us an excuse to mill around for a few minutes. Perhaps thanks
to the rain there weren’t many tourists around, so we didn’t have to wait too long. TFTC!
A new email-based extortion scheme apparently is making the rounds, targeting Web site owners serving banner ads through Google’s AdSense program. In this scam, the
fraudsters demand bitcoin in exchange for a promise not to flood the publisher’s ads with so much bot and junk traffic that Google’s automated anti-fraud systems suspend the user’s
AdSense account for suspicious traffic.
…
The shape of our digital world grows increasingly strange. As anti-DoS techniques grow better and more and more uptime-critical
websites hide behind edge caches, zombie network operators remain one step ahead and find new and imaginative ways to extort money from their victims. In this new attack, the criminal
demands payment (in cryptocurrency) under threat that, if it’s not delivered, they’ll unleash an army of bots to act like the victim trying to scam their advertising network,
thereby getting the victim’s site demonetised.
Today my #distributed #remotework office is provided by @OCFI_OI, which provides me that most #Oxford of views: simultaneously containing architecture of the 1960s… and the 1160s.
Three athletes (and only three athletes) participate in a series of track and field events. Points are awarded for 1st, 2nd, and 3rd place in each event (the same points for each
event, i.e. 1st always gets “x” points, 2nd always gets “y” points, 3rd always gets “z” points), with x > y > z > 0, and all point values being integers.
The athletes are named: Adam, Bob, and Charlie.
Adam finished first overall with 22 points.
Bob won the Javelin event and finished with 9 points overall.
Charlie also finished with 9 points overall.
Question: Who finished second in the 100-meter dash (and why)?
…
I enjoyed this puzzle so much that I shared it with (and discussed it at length with) my smartypants puzzle-sharing group. Now it’s
your turn. The answer, plus a full explanation, can be found on the other side of the link, but I’d recommend that you try to solve it yourself first. If it seems impossible at first
glance, start by breaking it down into what you can know, and what you can almost know, and work from there. Good luck!
I first got into web design/development in the late 90s, and only as I type this sentence do I realize how long ago that was.
And boy, it was horrendous. I mean, being able to make stuff and put it online where other people could see it was pretty slick, but we did not have very much to work with.
I’ve been taking for granted that most folks doing web stuff still remember those days, or at least the decade that followed, but I think that assumption might be a wee bit
out of date. Some time ago I encountered a tweet marvelling at what we had to do without
border-radius. I still remember waiting with bated breath for it to be unprefixed!
But then, I suspect I also know a number of folks who only tried web design in the old days, and assume nothing about it has changed since.
I’m here to tell all of you to get off my lawn. Here’s a history of CSS and web design, as I remember it.
(Please bear in mind that this post is a fine blend of memory and research, so I can’t guarantee any of it is actually correct, especially the bits about causality. You may
want to try the W3C’s history of CSS, which is considerably shorter,
has a better chance of matching reality, and contains significantly less swearing.)
(Also, this would benefit greatly from more diagrams, but it took long enough just to write.)
…
I too remember the bad-old days of the pre-CSS and early-CSS Web. Back
then, when we were developing for it, we thought that it was magical. We tolerated issues like having to copy-paste our navigation around a stack of static pages, manually change our
design all over the place etc…. but man… I wouldn’t want to go back to working that way!
This is an excellent long-read for an up-close-and-personal look at how CSS has changed over the decades. Well worth a look if
you’ve any interest in the topic.
I know only a small percentage of you use VR and to everyone else I might as well by telling you how spiffy the handrails are up in this ivory tower, but for what it’s worth,
Boneworks is the first game in a while to make me think VR might be getting somewhere. It’s not there yet. The physics is full of little niggles as you might expect from a game
trying to juggle so much. The major issue with the climbing is only your hands and head can be moved and your in-game legs just flop around getting in the way of things like two
stubborn trails of cum dangling off your mum’s chin, but forget all that.
…
Speaking of VR, Yahtzee’s still playing with it and thinks it’s improving, which is high praise.
So there’s hope yet.
I really need to dig my heavyweight gear out of the attic, but I’m waiting until we (eventually) move house. And I absolutely agree with Yahtzee’s observation about the value of
VR games in which you can sit down, sometimes.
This weekend, my sister Sarah challenged me to define the difference between Virtual Reality and Augmented Reality. And the more I talked about the differences between them, the more I
realised that I don’t have a concrete definition, and I don’t think that anybody else does either.
AR: the man sees simulated reality and, probably, the whiteboard.
VR: the man sees simulated reality only, which may or may not include a whiteboard.
Either way: what the hell is he doing?
After all: from a technical perspective, any fully-immersive AR system – for example a hypothetical future version of the Microsoft Hololens that solves the current edition’s FOV problems – exists in a theoretical
superset of any current-generation VR system. That AR augments
the reality you can genuinely see, rather than replacing it entirely, becomes irrelevant if that AR system could superimpose
a virtual environment covering your entire view. So the argument that compared to VR, AR only covers part of your vision is not a reliable definition of the difference.
The difference by how much of your view is occluded by machine-generated images fails to define where the boundary between AR and
VR lies. 5%? 50%? 99%?
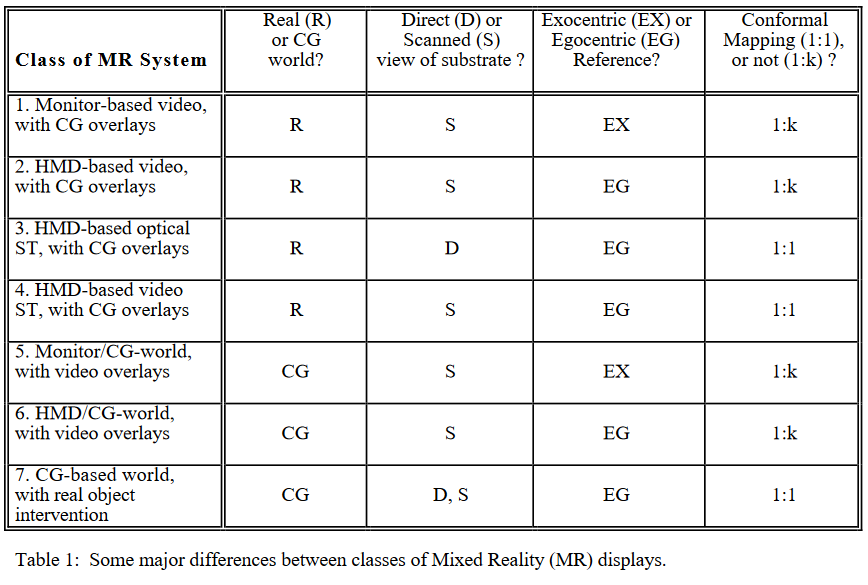
This isn’t a new conundrum. Way back in 1994 back when the Sega VR-1 was our idea of cutting edge, Milgram et al. developed a series of metaphorical spectra to describe the relationship between
different kinds of “mixed reality” systems. The core difference, they argue, is whether or not the computer-generated content represents a “world” in itself (VR) is just an “overlay” (AR).
But that’s unsatisfying for the same reason as above. The HTC Vive headset can be configured to use its front-facing camera(s) to fade seamlessly from the game world to the real world
as the player gets close to the boundaries of their play space. This is a safety feature, but it doesn’t have to be: there’s no reason that a HTC Vive couldn’t be
adapted to function as what Milgram would describe as a “class 4” device, which is functionally the same as a headset-mounted AR
device. So what’s the difference?
You might argue that the difference between AR and VR is content-based:
that is, it’s the thing that you’re expected to focus on that dictates which is which. If you’re expected to look at the “real world”, it’s an augmentation, and if not then
it’s a virtualisation. But that approach fails to describe Google’s tech demo of putting artefacts in your living room via
augmented reality (which I’ve written about before), because your focus is expected to be on the artefact rather than the “real world” around it.
The real world only exists to help with the interpretation of scale: it’s not what the experience is about and your countertop is as valid a real world target as the Louvre:
Google doesn’t care.
Categories 3 and 4 would probably be used to describe most contemporary AR; categories 6 and 7 to describe contemporary
VR.
But even if we accept this explanation, the definition gets muddied by the wider field of “extended reality” (XR). Originally an
umbrella term to cover both AR and VR (and “MR“, if you believe that’s a separate and independent thing), XR gets used to describe interactive experiences
that cover other senses, too. If I play a VR game with real-world “props” that I can pick up and move around, but that appear
differently in my vision, am I not “augmenting” reality? Is my experience, therefore, more or less “VR” than if the
interactive objects exist only on my screen? What about if – as in a recent VR escape room I attended – the experience is enhanced by
fans to simulate the movement of air around you? What about smell? (You know already that somebody’s working on bridging virtual reality with Smell-O-Vision.)
Not sure if you’re real or if you’re dreaming? Don’t ask an XR researcher; they don’t know either.
Increasingly, then, I’m beginning to feel that XR itself is a spectrum, and a pretty woolly one. Just as it’s hard to specify
in a concrete way where the boundary exists between being asleep and being awake, it’s hard to mark where “our” reality gives way to the virtual and vice-versa.
It’s based upon the addition of information to our senses, by a computer, and there can be more (as in fully-immersive VR) or
less (as in the subtle application of AR) of it… but the edges are very fuzzy. I guess that the spectrum of the visual
experience of XR might look a little like this:
Honestly, I don’t know any more. But I don’t think my sister does either.
I’ll be travelling North through England all day on 2020-02-22 and it’s not a huge diversion to go and climb a hill as a break, so long as I set off early enough in the
morning. We’ll see…
Expedition
It’s a beautiful part of the world, the Peak District, although I could have picked a day when I’d be less-hampered by floods and wind. Nonetheless, I was able to climb a short way up
Haven Hill, divert around an impromptu lake, and scramble into a thicket in order to reach the hashpoint at around 13:40. And to leave a “the Internet was here” sign at the nearest
footpath
Tracklog
Taken by GPSr, but I seem to have lost the charging/data cable for it. Will find at some point.
I’m travelling today from Oxford to Preston with a diversion to see if I can make it to the 2022-02-22 53 – 1 geohashpoint, which looks likely to be on a hill at the South end of the
Peak District. Pulled over here to check my directions and buy myself a snack and find this cache. Ascent up the roundabout was a little slippy and muddy but I was soon able to find the
cache. SL, TFTC!
North end of the village of Curbridge in Oxfordshire. Street View and satellite photography shows it as being alongside a nondescript road, but I’m aware that there’s a housing estate under
construction nearby and there’s a new roundabout which appears on maps but not on satellite views which was constructed nearby last year: I’m hoping that the location is still
accessible.
I don’t know whether I’ll be able to make it to this hashpoint; it depends on how work goes as well as the weather (while I’m not directly in the path of Storm Dennis I’m still in an area that’s getting lots of wind and rain). I’m not committed yet to whether
I’d drive or cycle: it depends on how long I can spare, whether the car’s available for my use, and – again – the weather (I’d prefer to cycle, but I’m not going to do it if it means I
get completely soaked on my lunch break).
Okay: I need to vacate my house anyway because some estate agents are bring some potential buyers around, so I’m setting out to the hashpoint now (12:20) after which I’ll aim to work in
a coworking space for the afternoon. Wish me luck!
Expedition
I drove out to the village of Curbridge and parked in a lane, then walked to the hashpoint, arriving about 13:05. Conveniently there’s a pole (holding a speed detecting sign) within a
metre of the hashpoint so I was able to attach a “The Internet Was Here” sign in accordance with the tradition. Then I made my way to a coworking space half a mile to the North to carry
on with my day’s work.
Tracklog
My GPSr keeps a tracklog:
Obtained, but I didn’t bring the right cable to the coworking space so I can’t get it yet. [to follow]
I don’t care whether anything materially bad will or won’t happen as a consequence of Wacom taking this data from me. I simply resent the fact that they’re doing it.
The second is that we can also come up with scenarios that involve real harms. Maybe the very existence of a program is secret or sensitive information. What if a Wacom employee
suddenly starts seeing entries spring up for “Half Life 3 Test Build”? Obviously I don’t care about the secrecy of Valve’s new games, but I assume that Valve does.
We can get more subtle. I personally use Google Analytics to track visitors to my website. I do feel bad about this, but I’ve got to get my self-esteem from somewhere. Google
Analytics has a “User Explorer” tool, in which you can zoom in on the activity of a specific user. Suppose that someone at Wacom “fingerprints” a target person that they knew in
real life by seeing that this person uses a very particular combination of applications. The Wacom employee then uses this fingerprint to find the person in the “User Explorer”
tool. Finally the Wacom employee sees that their target also uses “LivingWith: Cancer Support”.
Remember, this information is coming from a device that is essentially a mouse.
…
Interesting deep-dive investigation into the (immoral, grey-area illegal) data mining being done by Wacom when you install the drivers for their tablets. Horrifying, but you’ve got to
remember that Wacom are unlikely to be a unique case. I had a falling out with Razer the other year when they started bundling spyware into the drivers for their keyboards and
locking-out existing and new customers from advanced features unless they consented to data harvesting.
I’m becoming increasingly concerned by the normalisation of surveillance capitalism: between modern peripherals and the Internet of Things, we’re “willingly” surrendering more
of our personal lives than ever before. If you haven’t seen it, I’d also thoroughly recommend Data, the latest video from
Philosophy Tube (of which I’ve sung the praises before).