I keep my life pretty busy and don’t get as much “outside” as I’d like, but when I do I like to get out on an occasional geohashing expedition (like these
ones). I (somewhat badly) explained geohashing in the vlog attached to my expedition 2018-08-07 51 -1, but the short
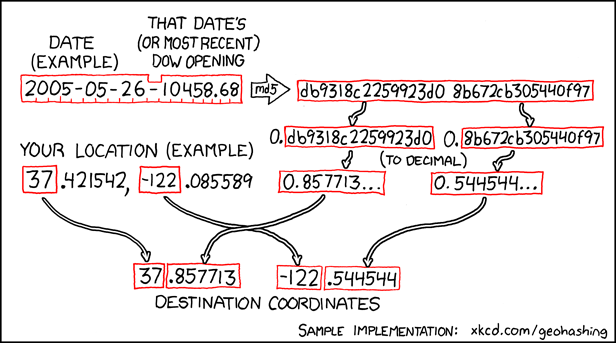
version is this: an xkcd comic proposed an formula to use a stock market index to generate a pair of random coordinates, impossible to predict in
advance, for each date. Those coordinates are (broadly) repeated for each degree of latitude and longitude throughout the planet, and your challenge is to get to them and discover
what’s there. So it’s like geocaching, except you don’t get to find anything at the end and there’s no guarantee that the destination is even remotely accessible. I love it.
My favourite kind of random pointlessness is summarised by this algorithm.
Most geohashers used to use a MediaWiki-powered website to coordinate their efforts and share their stories, until a different application on the server where it resided got hacked and the wiki got taken down as a precaution.
That was last September, and the community became somewhat “lost” this winter as a result. It didn’t stop us ‘hashing, of course: the algorithm’s open-source and so are many of its
implementations, so I was able to sink into a disgusting hole in November, for example. But we’d lost the digital
“village square” of our community.
My dissertation “burndown” is characterised on my whiteboard by two variables: outstanding issues (blue) and wordcount (red). There are… a few problems.
So I emailed Davean, who does techy things for xkcd, and said that I’d like to take over the Geohashing wiki but that I’d first like (a) his or Randall’s blessing to do so, and ideally
(b) a backup of the pages of the site as it last-stood. Apparently I thought that my new job plus finishing my dissertation plus trying to move house plus all of the usual
things I fill my time with wasn’t enough and I needed a mini side-project, because when I finally got the go-ahead at the end of last month I (re)launched geohashing.site. Take a look, if you like. If you’ve never been Geohashing before, there’s never been a more-obscure time to start!
My implementation of the site is mobile-friendly for the benefit of people who might want to use it while out in a muddy ditch. For example. Just hypothetically.
Luckily, it’s not been a significant time-sink for me: members of the geohashing community quickly stepped up to help me modernise content, fix bots, update hyperlinks and the like. I
took the opportunity to fix a few things that had always bugged me about the old site, like the mobile-unfriendly interface and the inability to upload GPX files, and laid the groundwork to make bigger changes down the road (like changing the way that inline maps are displayed, a popular community request).
So yeah: Geohashing’s back, not that it ever went away, and I got to be part of the mission to make it so. I feel like I am, as geohashers say… out standing in my field.
2020 is only three weeks old, but there has been a lot of browser news that decreases rendering engine diversity. It’s time for some good news on that front: a new rendering engine,
Flow. Below I conduct an interview with Piers Wombwell, Flow’s lead developer.
This year alone, on the negative side Mozilla announced it’s
laying off 70 people, most of whom appear to come from the browser side of things, while it turns out that Opera’s main cash cow is now providing loans in Kenya, India, and
Nigeria, and it is looking to use ‘improved credit scoring’ (from browsing data?) for its business practices.
On the positive side, the Chromium-based Edge is here, and it looks good. Still, rendering engine diversity took
a hit, as we knew it would ever since the announcement.
So let’s up the diversity a notch by welcoming a new rendering engine to the desktop space. British company Ekioh is working on a the Flow browser, which sports a completely new multi-threaded rendering engine that does not have any relation to WebKit, Gecko, or Blink.
I’m not convinced that Flow is the solution to all the world’s problems (its target platforms and use-cases alone make it unlikely to make it onto the most-used-browsers leaderboard any
time soon), but I’m really glad that my doomsaying about the death of browser diversity being a one-way street might… might… turn out
not to be true.
Time will tell. But for now, this is Good News for the Web.
I think that CSS would be greatly helped if we solemnly state that “CSS4 is here!” In this post I’ll try to convince you of my viewpoint.
I am proposing that we web developers, supported by the W3C CSS WG, start saying “CSS4 is here!” and excitedly chatter about how it will hit the market any moment now and transform
the practice of CSS.
Of course “CSS4” has no technical meaning whatsoever. All current CSS specifications have their own specific
versions ranging from 1 to 4, but CSS as a whole does not have a version, and it doesn’t need one, either.
Regardless of what we say or do, CSS 4 will not hit the market and will not transform anything. It also does not describe any technical reality.
But if you’ve got more than a little web savvy you might still be surprised to hear me say that CSS4 is here, or even
that it’s a “thing” at all. Welll… that’s because it isn’t. Not officially. Just like JavaScript’s versioning has gone all evergreen these last few years,
CSS has gone the same way, with different “modules” each making their way through the standards and implementation processes
independently. Which is great, in general, by the way – we’re seeing faster development of long-overdue features now than we have through most of the Web’s history – but it
does make it hard to keep track of what’s “current” unless you follow along watching very closely. Who’s got time for that?
When CSS2 gained prominence at around the turn of the millennium it was revolutionary, and part of the reason for that
– aside from the fact that it gave us all some features we’d wanted for a long time – was that it gave us a term to rally behind. This browser already supports it, that browser’s
getting there, this other browser supports it but has a f**ked-up box model (you all know the one I’m talking about)… we at last had an overarching term to discuss what was supported,
what was new, what was ready for people to write articles and books about. Nobody’s going to buy a book that promises to teach them “CSS3 Selectors Level 3, Fonts Level 3, Writing Modes
Level 3, and Containment Level 1”: that title’s not even going to fit on the cover. But if we wrapped up a snapshot of what’s current and called it CSS4… now that’s going to sell.
Can we show the CSS WG that there’s mileage in this idea and make it happen? Oh, I hope so. Because while the
modular approach to CSS is beautiful and elegant and progressive… I’m afraid that we can’t use it to inspire junior developers.
Also: I don’t want this joke to forever remain among the top results
when searching for CSS4…
I’m posting this on the last day of 2019. As I write it, the second post I ever made on
meyerweb says it was published “20 years, 6 days ago”. It was published on the second-to-last day of 1999, which was 20 years and one day ago.
What I realized, once the discrepancy was pointed out to me (hat tip: Eric Portis), is the five-day error is there because in the two decades
since I posted it, there have been five leap days. When I wrote the code to construct those relative-time strings, I either didn’t think about leap days, or if I did, I
decided a day or two here and there wouldn’t matter all that much.
Which is to say, I failed to think about the consequences of my code running over long periods of time. Maybe a day or two of error isn’t all that big a deal, in
human-friendly relative-time output. If a post was six years and two days ago but the code says 6 and 1, well, nobody will really care that much even if they notice. But
five days is noticeable, and what’s more, it’s a little human-unfriendly. It’s noticeable. It jars.
…
As I mentioned in my comments on a repost last week, I work to try to make the
things I publish to this site last. But that’s not to say that problems can’t creep in, either because of fundamental bugs left unnoticed until later on (such as the image
recompression problem that’s recently lead to some of my older images going wonky; I’m working on it) or else because because of environmental changes e.g. in the technologies that are
supported and the ways in which they’re used. The latter are helped by standards and by an adherence to them, but the former will trip over Web developers time and time again, and it’s
possible that there’s nothing we can do about it.
No system is perfect, and we don’t have time to engineer every system, every site, every page in a way that near-guarantees its longevity; not by a long shot. I tripped myself over just
the year before last when I added Content-Security-Policy headers to my site and promptly broke every embedded YouTube or Vimeo video
because they didn’t fit the newly (and retroactively) enforced pattern of allowable content. Such problems are easy to create when you’re maintaining a long-running system with a lot of
data. I’m only talking about my blog, but larger, older and/or more-complex systems (of which I’ve worked on a few!) come with their own multitudinous challenges.
That said, the Web has demonstrated a resilience that surpasses most of what is expected in consumer computing. If you want to run a video game from 1994 or even 2001 on a modern
computer, you’re likely to find that you have to put in considerably more work than you would have on the day it was released! But even some of the oldest webpages still-existing remain
usable today.
Occasionally, though: a “hip” modern technology without the backing of widespread browser standards comes along and creates a dark age. Flash created such a dark age; now there are
millions of Flash-dependent web pages that simply don’t work any longer. Java created another. And I worry that the unnecessary overuse of front-end rendering technologies are creating
a third that we’re living through right now, oblivious to the data we’re creating and losing.
How do we make web content that can last and be maintained for at least 10 years? As someone studying human-computer interaction, I naturally think of the stakeholders we aren’t
supporting. Right now putting up web content is optimized for either the professional web developer (who use the latest frameworks and workflows) or the non-tech savvy user (who use
a platform).
But I think we should consider both 1) the casual web content “maintainer”, someone who doesn’t constantly stay up to date with the latest web technologies, which means the website
needs to have low maintenance needs; 2) and the crawlers who preserve the content and personal archivers, the “archiver”, which means the
website should be easy to save and interpret.
So my proposal is seven unconventional guidelines in how we handle websites designed to be informative, to make them easy to maintain and preserve. The guiding intention is that the
maintainer will try to keep the website up for at least 10 years, maybe even 20 or 30 years. These are not controversial views necessarily, but are aspirations that are not
mainstream—a manifesto for a long-lasting website.
…
This page is designed to last, too. In fact, virtually every post of any type I’ve made to this blog (since 2003, older content may vary) has been designed with the intention that it
ought to be accessible without dependence on CSS, Javascript, nor any proprietary technology, that the code should be as
human-readable as posssible, and that the site itself should be as “archivable” as possible, just as a matter of course.
But that’s only 15 years of dedicated effort to longevity and I’ve still not achieved 100% success! For example, consider my blog post of 14 December 2003, describing the preceeding Troma Night, whose content was lost during the great server failure of July 2004 and for which the backups were unable to completely describe. I’m more-careful now, with more
redundancies and backups, but it’s still always going to be the case that a sufficiently-devastating set of simultaneous failures could take this content away. All information has
fragility and we can work to mitigate it but we can never completely solve it.
The large number of dead outbound links on the older parts of my site is both worrying – that most others don’t seem to have the same level of commitment to the retention of articles on
the Web – and reassuring – that I’m doing significantly better than the average. So next, I guess, I need to focus my attention – like Jeff is – on how we can make such efforts usable
by other people, too. The Web belongs to all of us, after all.
…why would cookies ever need to work across domains? Authentication, shopping carts and all that good stuff can happen on the same domain. Third-party cookies, on the other hand,
seem custom made for tracking and frankly, not much else.
…
Then there’s third-party JavaScript.
In retrospect, it seems unbelievable that third-party JavaScript is even possible. I mean, putting arbitrary code—that can then inject
even more arbitrary code—onto your website? That seems like a security nightmare!
I imagine if JavaScript were being specced today, it would almost certainly be restricted to the same origin by default.
…
Jeremy hits the nail on the head with third-party cookies and Javascript: if the Web were invented today, there’s no way that these potentially privacy and security-undermining features
would be on by default, globally. I’m not sure that they’d be universally blocked at the browser level as Jeremy suggests, though: the Web has always been about empowering developers,
acting as a playground for experimentation, and third-party stuff does provide benefits: sharing a login across multiple subdomains, for example (which in turn can exist as a
security feature, if different authors get permission to add content to those subdomains).
Instead, then, I imagine that a Web re-invented today would treat third-party content a little like we treat CORS or we’re
beginning to treat resource types specified by Content-Security-Policy and Feature-Policy headers. That is, website owners would need to “opt-in” to which third-party domains could be
trusted to provide content, perhaps subdivided into scripts and cookies. This wouldn’t prohibit trackers, but it would make their use less of an assumed-default (develolpers would have
to truly think about the implications of what they were enabling) and more transparent: it’d be very easy for a browser to list (and optionally block, sandbox, or anonymise) third-party
trackers could potentially target them, on a given site, without having to first evaluate any scripts and their sources.
I was recently inspired by Dave Rupert to remove
Google Analytics from this blog. For a while, there’ll have been no third-party scripts being delivered on this site at all, except through iframes (for video embedding etc., which
is different anyway because there’s significantly less scope leak). Recently, I’ve been experimenting with Jetpack because I get it for free through
my new employer, but I’m always looking for ways to improve how well my site “stands alone”: you can block all third-party resources
and this site should still work just fine (I wonder if I can add a feature to my service worker to allow visitors to control exactly what third party content they’re exposed to?).
If you make accessibility or internationalization in a code library an optional component, you just know half of the people deploying it will ignore it—out of ignorance or as
optimization. So taking the side of the end user versus the dev user means just pre-bundling these things
For very similar reasons, I refuse to make accessibility features configurable in my vanilla JS plugins.
…
Very much this. In short:
If you write a library, add accessibility features as standard.
If you fail to do this, you do a disservice to the developers who use your library and, worse, to the users of their software. Accessibility is for everybody, but it’s still
surprisingly hard to get right: don’t make it any harder by neglecting to include it in your library’s design.
Make those accessibility features on-by-default.
You can’t rely on developers to follow your instructions to make the use of your library accessible. Even the most well-meaning developers find themselves hurried by deadlines and by
less-well-meaning managers. Don’t even make accessibility a simple switch: just put it on to begin with.
Don’t provide a feature to disable accessibility features.
If you allow accessibility features to be turned off, developers will turn them off. They’ll do this for all kinds of reasons, like trying to get pixel-perfect accuracy with a design
or to make a web application behave more like a “hip” mobile app. You’ll probably find that you can never fully prevent developers from breaking your accessibility tools, but you must
make it so that doing so must be significantly more-effort than simply toggling a constant.
Perhaps three people will read this essay, including my parents. Despite that, I feel an immense sense of accomplishment. I’ve been sitting on buses for years, but I have more to
show for my last month of bus rides than the rest of that time combined.
Smartphones, I’ve decided, are not evil. This entire essay was composed on an iPhone. What’s evil is passive consumption, in all its forms.
A side-effect of social media culture (repost, reshare, subscribe, like) is that it’s found perhaps the minimum-effort activity that humans can do that still fulfils our need
to feel like we’ve participated in our society. With one tap we can pass on a meme or a funny photo or an outrageous news story. Or we can give a virtual thumbs-up or a heart on a
friend’s holiday snaps, representing the entirety of our social interactions with them. We’re encouraged to create the smallest, lightest content possible: forty words into a Tweet, a
picture on Instagram that we took seconds ago and might never look at again, on Facebook… whatever Facebook’s for these days. The “new ‘netiquette” is complicated.
I, for one, think it’d be a better world if it saw a greater diversity of online content. Instead of many millions of followers of each of a million content creators, wouldn’t it be
nice to see mere thousands of each of billions? I don’t propose to erode the fame of those who’ve achieved Internet celebrity; but I’d love to migrate towards a culture in which we can
all better support one another’s drive to create original content online. And do so ourselves.
The best time to write on your blog is… well, let’s be honest, it was a decade ago. But the second best time is right now. Or if you’d rather draw, or sing, or dance, or make puzzles or
games or films… do that. The barrier to being a content creator has never been lower: publishing is basically free and virtually any digital medium is accessible from even the
simplest of devices. Go make something, and share it with the world.
As part of the preparing to leave the Bodleian I’ve been revisiting a lot of the documentation I’ve written over the last eight
years. It occurred to me that I’ve never written publicly about how the Bodleian’s digital signage/interactives actually work; there are possible lessons to learn.
The Bodleian‘s digital signage is perhaps more-diverse, both in terms of technology and audience, than that of most organisations. We’ve got
signs in areas that are exclusively reader-facing to help students and academics find what they’re looking for, signs in publicly accessible rooms that advertise and educate, and signs
in gallery spaces upon which we try to present engaging and often-interactive content to support exhibitions.
Getting an extra touchscreen for the office for prototyping/user testing purposes was great, even when it wasn’t showing MLP: FiM.
Throughout those three spheres, we’ve routinely delivered a diversity of content (let’s just ignore the countdown clock, for now…). Traditional
directional signage, advertisements, games, digital exhibitions, interpretation, feedback surveys…
In the vast majority of cases – and this is where the Bodleian’s been unusual (though certainly not unique) among cultural sector institutions – we’ve created
those in-house rather than outsourcing them.
Using off-the-shelf technology also allows the Bodleian to in-house much of their hardware maintenance, as a secondary part of other job roles. Singing into your screwdriver remains
optional, though.
To do this economically – the volume of work on interactive signage is inconsistent throughout the year – we needed to align the skills required with skills used elsewhere in the
organisation. To do this, we use the web as our medium! Collectively, the Bodleian’s Digital Communications team already had at least some experience in programming, web design, graphic
design, research, user testing, copyediting etc.: the essential toolkit for web application development.
Whether you were playing Pong on the video wall at the back or testing your Middle-earth knowledge on the touchscreen at the front… behind the
scenes you were interacting with a web page I wrote.
By shifting our digital signage platform to lean heavily on web technologies, we were able to leverage talented people we already had to produce things that we might otherwise
have had to outsource. This, in turn, meant that more exhibitions and displays get digital enhancement, on a shorter turnaround.
It also means that there’s a tighter integration between exhibition content and content for web and social media: it’s easier for us to re-use content across multiple platforms.
Sometimes we’ve even made our digital interactives, or adapted version of them, available directly online, allowing our exhibitions to reach people that can’t get to our physical spaces
at all.
Because we’re able to produce our own content on-demand, even our smaller, shorter-duration displays can have hands-on digital interactives associated with them.
On to the technology! We’re using a real mixture of tech: when it’s donated or reclaimed from previous projects (and when the bidding and acquisition processes are, well… as you’d
expect at the University of Oxford), you learn not to say no to freebies. Our fleet includes:
Samsung Android tablets with freestanding kiosk frames. We run the excellent-value Kiosk Browser Lockdown app on
these, which loads on boot and prevents access to anything but a specified website.
OnelanNTBs connected to a mixture of
touch and non-touch screens, wall-mounted or in kiosk frames. We use Onelan’s standard digital signage features as well as – for interactive content – their built-in touch-capable web
browser.
Dell PCs of the standard variety supplied by University IT services, connected to wall-mounted touch screens, running Google Chrome in Kiosk Mode. More on this below.
The browsers’ responsive simulators are invaluable when we’re targeting signage at five (!) different resolutions.
When you’re developing content for a very small number of browsers and a limited set of screen sizes, you quickly learn to throw a lot of “best practice” web development out of the
window. You’ll never come across a text browser or screen reader, so alt-text doesn’t matter. You’ll never have to rescale responsively, so you might as well absolutely-position almost
everything. The devices are all your own, so you never need to ask permission to store cookies. And because you control the platform, you can get away with making configuration tweaks
to e.g. allow autoplaying videos with audio. Coming from a conventional web developer background to producing digital signage content makes feels incredibly lazy.
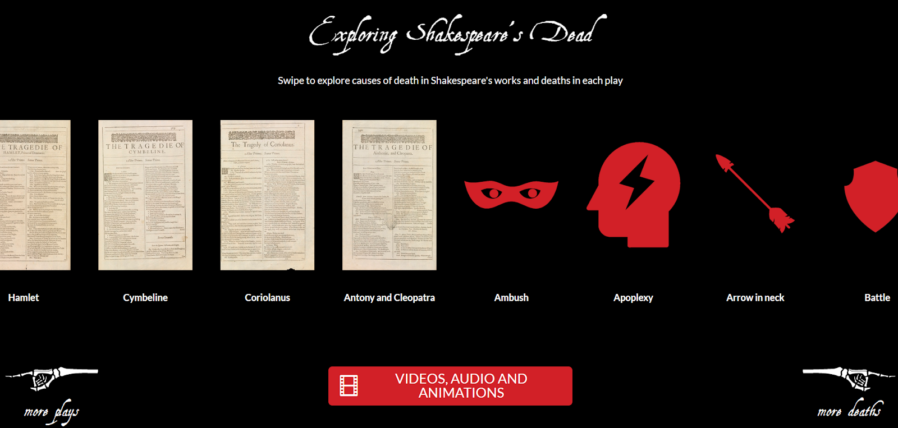
Helping your users see your interactive as “app-like” rather than “web-like” encourages them to feel comfortable engaging with it in ways uncharacteristic of web pages. In our Shakespeare’s Dead interactive, for example, we started the experience in the middle of a long horizontally-scrolling “page”, which might
feel very unusual in a conventional browser.
Using Chrome to run digital signage requires, in the Bodleian’s case, a couple of configuration tweaks and the right command-line switches. We use:
chrome://flags/#overscroll-history-navigation – disabling this prevents users from triggering “back”/”forward” by swiping with two fingers
chrome://flags/#pull-to-refresh – disabling this prevents the user from triggering a “refresh” by scrolling up beyond the top of the page (this only happens on some
kinds of devices)
chrome://flags/#system-keyboard-lock – we don’t use attached keyboards, but if you do, you might want to set this flag so you can use the keyboard.lock()
API to intercept e.g. ALT+F4 so users can’t escape the application
running on startup with e.g. chrome --kiosk --noerrdialogs --allow-file-access-from-files --disable-touch-drag-drop --incognito https://example.com/some/url
Kisok mode makes the browser run fullscreen and prevents e.g. opening additional tabs, giving an instant “app-like” experience. As we don’t have keyboards attached to our
digital signage, this also prevents visitors from closing Chrome.
Turning off error dialogs reduces the risk that an error will result in an unslightly message to the user.
Enabling “file access from files” allows content hosted at file:// addresses to access content at other file:// addresses, which makes it possible to write “offline” sites
(sometimes useful where we’re serving large videos or on previous occasions when WiFi has been shaky) that can still take advantage of features like the Fetch API.
Unless you need drag-and-drop, it’s simpler to disable it; this prevents a user long-press-and-dragging an image around the screen.
Incognito mode ensures that the browser doesn’t remember what site was showing last time it ran; our computers often end up switched off at the wall at the end of the day, and
without this the browser will offer to load the site it had open last time, when it runs.
We usually host our interactives directly on the web, at “secret” addresses, and this is generally preferable to us as we can more-easily make on-the-fly adjustments to
content (plus it makes it easier to hook up analytic tools).
Be sure to test the capabilities of your hardware! Our Onelan NTBs, unlike your desktop PCs, can’t handle multitouch input, which
affects the design of our user interfaces for these devices.
Meanwhile, in the application’s CSS code, we set * { user-select: none; } to prevent the user from highlighting
text by selecting it with their finger. We also make heavy use of absolutely-sized/positioned, overflow: hidden blocks to ensure that scrollbars never appear, and
CSS animations to make content feel dynamic and to draw attention to particular elements.
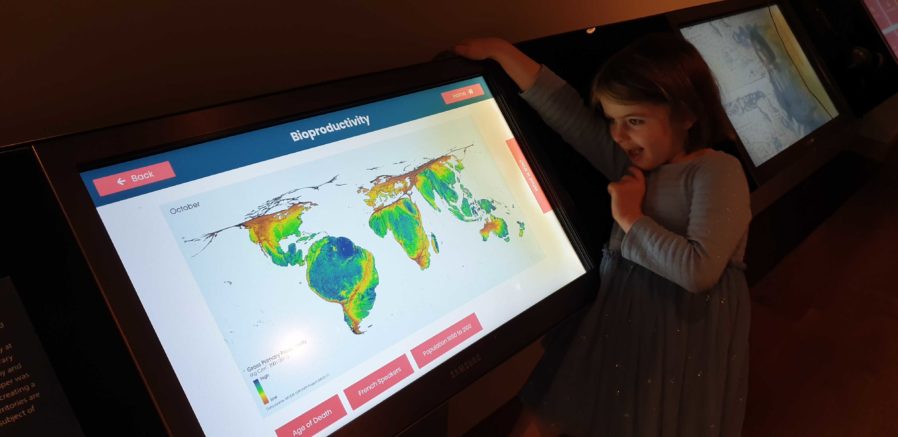
There’s no substitute for good testing. And there’s no stress-testing quite like letting a 5 year-old loose on your work.
Altogether, this approach gives the Bodleian the capability to produce engaging interactive content at low cost and using the existing skills of their digital and exhibitions teams.
It’s not an approach that would work for every cultural institution: in particular, some of the Bodleian’s sister institutions already
outsource the technical parts of their web work, and so don’t have the expertise in-house to share with a web-powered digital signage solution.
A few minor CSS tweaks to make the buttons finger-friendly and our Halloween game Shadows Out Of
Time, which I’d already made web-friendly, was touchscreen-ready too. I wonder if they’ll get this one out again, this
Halloween?
But for those museums that can fit into this model – or can adapt to do so in future – using the web to produce interactive digital content and digital signage is a highly
cost-effective way to engage with visitors, even (or especially!) when dealing with short-lived and/or rotating displays.
It’s also been among my favourite parts of my job at the Bod these last 8½ years, and I’m sure I’ll miss it!
To enable users to easily navigate to specific content in a web page, we propose adding support for specifying a text snippet in the URL. When navigating to such a URL, the browser
will find the first instance of the text snippet in the page and bring it into view.
Web standards currently specify support for scrolling to anchor elements with name attributes, as well as DOM elements with ids, when navigating to a fragment. While named anchors and elements with ids enable
scrolling to limited specific parts of web pages, not all documents make use of these elements, and not all parts of pages are addressable by named anchors or elements with ids.
Current Status
This feature is currently implemented as an experimental feature in Chrome 74.0.3706.0 and newer. It is not yet shipped to users by default. Users who wish to experiment with it can
use chrome://flags#enable-text-fragment-anchor. The implementation is incomplete and doesn’t necessarily match the specification in this document.
…
tl;dr
Allow specifying text to scroll and highlight in the URL:
This is a feature that I’ve wished that the Web had on many, many occasions. I’m sure you’ve needed it before, too: you’ve wanted to give somebody the URL of (or link to) a particular part of a page but there’s been no appropriately-placed anchor to latch on to. Being able to select part of the text
on the page and just copy that after a ## in the address bar would be so much simpler.
Naturally, I tried this experimental feature out on this very web page; it worked pretty nicely!
Chrome’s implementation is somewhat conservative, requiring a prefix of ##targetText= (this minimises the risk of collision with other applications which store/pass data
via hashes), but it’s still pretty full-featured, with support for prefixes and suffixes to the text to-be-selected. I quite like it, but of course it needs running down the standards
track before it can be relied upon as anything other than a progressive enhancement.
I do wonder, though, whether this will be met with resistance by ad/subscription-supported content creators as a new example of the deep linking they seem to hate so much.
The <a> tag is one of the most important building blocks of the Internet. It lets you create a hyperlink: a piece of text, usually colored blue, that you can use to go to a new
page. When you click on a hyperlink, your web browser downloads the new page from the server and displays it on the screen. Most web browsers also store the pages you previously
visited so you can quickly go back to them. The best part is, the <a> tag gives you all of that behavior for free! Just tell the browser
where you want to go, and it handles the rest.
Lately, though, that hasn’t been enough for website developers. The new fad is “client-side navigation”, where instead of relying on the browser to load new pages for you, you write
a bunch of JavaScript code to do it instead. It’s actually really hard to get it right—loading the new page is simple enough, but you also have to write code to display a loading
bar, make the Back and Forward buttons work, show an error page if the connection drops, and so on.
For a while, I didn’t understand why anyone did this. Was it just silly make-work, like how every social network redesigns their website every couple years for no discernable
reason? Do <a> tags interfere with some creepy ad-tracking technique? Was there some really complicated technical reason why you
shouldn’t use them?
…
Spoiler: good old-fashioned <a> hyperlinks tend to outperform Javascript-driven client-side navigation. We already learned about one reason for this – that adding more Javascript code just to get back what the browser gives you for free increases the payload you deliver to the user – but
Carter demonstrates that progressive rendering goes a long way to explaining it, too. You see: browsers understand traditional navigation and are well-equipped with a
suite of shortcuts to help them optimise for it. They can start rendering content before it’s all downloaded, offset (hinted-at) asynchronous data for later, and of course they already
contain a pretty solid caching engine and you don’t even have to implement it yourself.
With IndieWebCamp Oxford 2019 scheduled to take place during the
Summer of Hacks, I drew a diagram (click to embiggen) of the current ecosystem that powers
and propogates the content on DanQ.me. It’s mostly for my own benefit – to be able to get a big-picture view of the ways my website talks to the world and plan for what
improvements I might be able to make in the future… but it also works as a vehicle to explain what my personal corner of the IndieWeb does and how it
does it. Here’s a summary:
DanQ.me
Since fifteen years ago today, DanQ.me has been powered by a self-hosted WordPress installation. I
know that WordPress isn’t “hip” on the IndieWeb this week and that if you’re not on the JAMstack you’re yesterday’s news, but at 15 years and counting my
love affair with WordPress has lasted longer than any romantic relationship I’ve ever had with another human being, so I’m sticking with it. What’s cool in Web technologies comes and
goes, but what’s important is solid, dependable tools that do what you need them to, and between WordPress, half a dozen off-the-shelf plugins and about a dozen homemade ones I’ve got
everything I need right here.
I’d been “blogging” – not that we called it that, yet – since late 1998, but my original collection of content-mangling Perl scripts wasn’t all that. More history…
I write articles (long posts like this) and notes (short, “tweet-like” updates) directly into the site, and just occasionally
other kinds of content. But for the most part, different kinds of content come from different parts of the ecosystem, as described below.
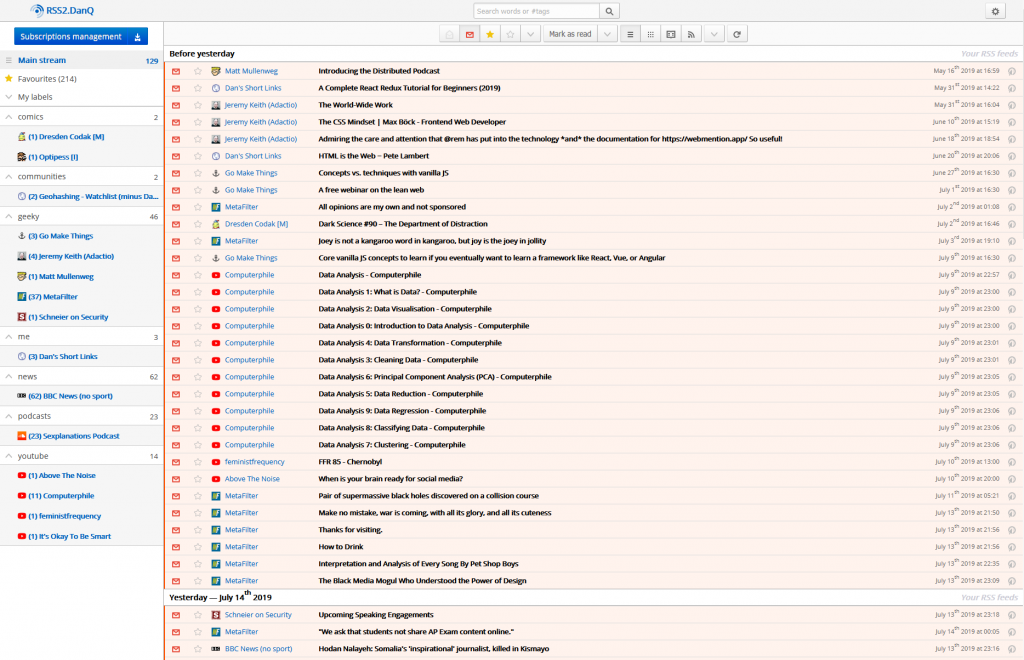
RSS reader
DanQ.me sits at the centre of the diagram, but it’s worth remembering that the diagram is deliberately incomplete: it only contains information flows directly relevant to my blog (and
it doesn’t even contain all of those!). The last time I tried to draw a diagram like this that described my online life in general, then my RSS reader found its way to the centre. Which figures: my RSS reader is usually the first
and often the last place I visit on the Internet, and I’ve worked hard to funnel everything through it.
129 unread items is a reasonable-sized queue: I try to process to “RSS zero”, but there are invariably things I want to return to on a second-pass and I’ve not yet reimplemented the
“snooze button” I added to my previous RSS reader.
Right now I’m using FreshRSS – plus a handful of plugins, including some homemade ones – as my RSS reader: I switched from Tiny Tiny RSS about a year ago to take advantage of FreshRSS’s excellent responsive
themes, among other features. Because some websites don’t have RSS feeds, even where they ought to, I use my own tool
RSSey to retroactively “fix” people’s websites for them, dynamically adding feeds for my
consumption. It’s also a nice reminder that open source and remixability were cornerstones of the original Web. My RSS reader
collates information from a variety of sources and additionally gives me a one-click mechanism to push content I enjoy to my blog as a repost.
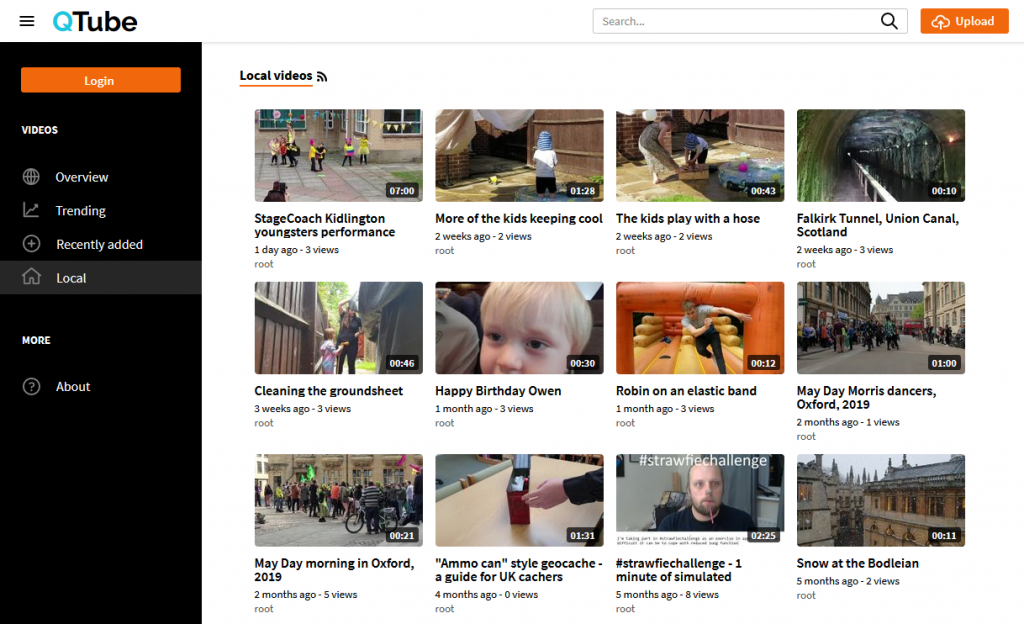
QTube
QTube is my video hosting platform; it’s a PeerTube node. If you haven’t seen it, that’s fine: most content
on it is consumed indirectly either through my YouTube channel or directly on my blog as posts of the “video” kind. Also, I don’t actually vlog very often. When I do publish videos onto QTube, their republication onto YouTube or DanQ.me is optional: sometimes I plan to
use a video inside an article post, for example, and so don’t need to republish it by itself.
I’m gradually exporting or re-uploading my backlog of YouTube videos from my current and previous channels to QTube in an effort to
recentralise and regain control over their hosting, but I’m in no real hurry. PeerTube certainly makes it easy, though!
Link Shortener
I operate a private link shortener which I mostly use for the expected purpose: to make links shorter and so easier to read out and memorise or else to make them take up less space in a
chat window. But soon after I set it up, many years ago, I realised that it could also act as a mechanism to push content to my RSS reader to “read later”. And by the time I’m using it for that, I figured, I might as well also be using it to repost content to my blog
from sources that aren’t things my RSS reader subscribes to. This leads to a process that’s perhaps unnecessarily
complex: if I want to share a link with you as a repost, I’ll push it into my link shortener and mark it as going “to me”, then I’ll tell my RSS reader to push it to my blog and there it’ll be published to the world! But it works and it’s fast enough: I’m not in the habit
of reposting things that are time-critical anyway.
Checkins
You know your sport is fringe when you need to reference another fringe sport to describe it. “Geohashing? It’s… a little like geocaching, but…”
I’ve been involved in brainstorming ways in which the act of finding (or failing to find, etc.) a geocache or reaching (or failing to
reach) a geohashpoint could best be represented as a “checkin“, and last year I open-sourced my plugin for pulling logs (with as much automation as is permitted by the terms of service of some of the
silos involved) from geocaching websites and posting them to WordPress blogs: effectively PESOS-for-geocaching. I’d prefer to be publishing on my own blog in the first instance, but syndicating my adventures from various
silos into my blog is “good enough”.
Syndication
New notes get pushed out to my Twitter account, for the benefit of my Twitter-using friends. Articles get advertised on Facebook, Twitter and LiveJournal (yes, really) in teaser form, for the benefit of friends
who prefer to get notifications via those platforms. Facebook have been fucking around with their APIs and terms of
service lately and this is now less-automatic than it used to be, which is a bit of an annoyance. My RSS feeds carry copies
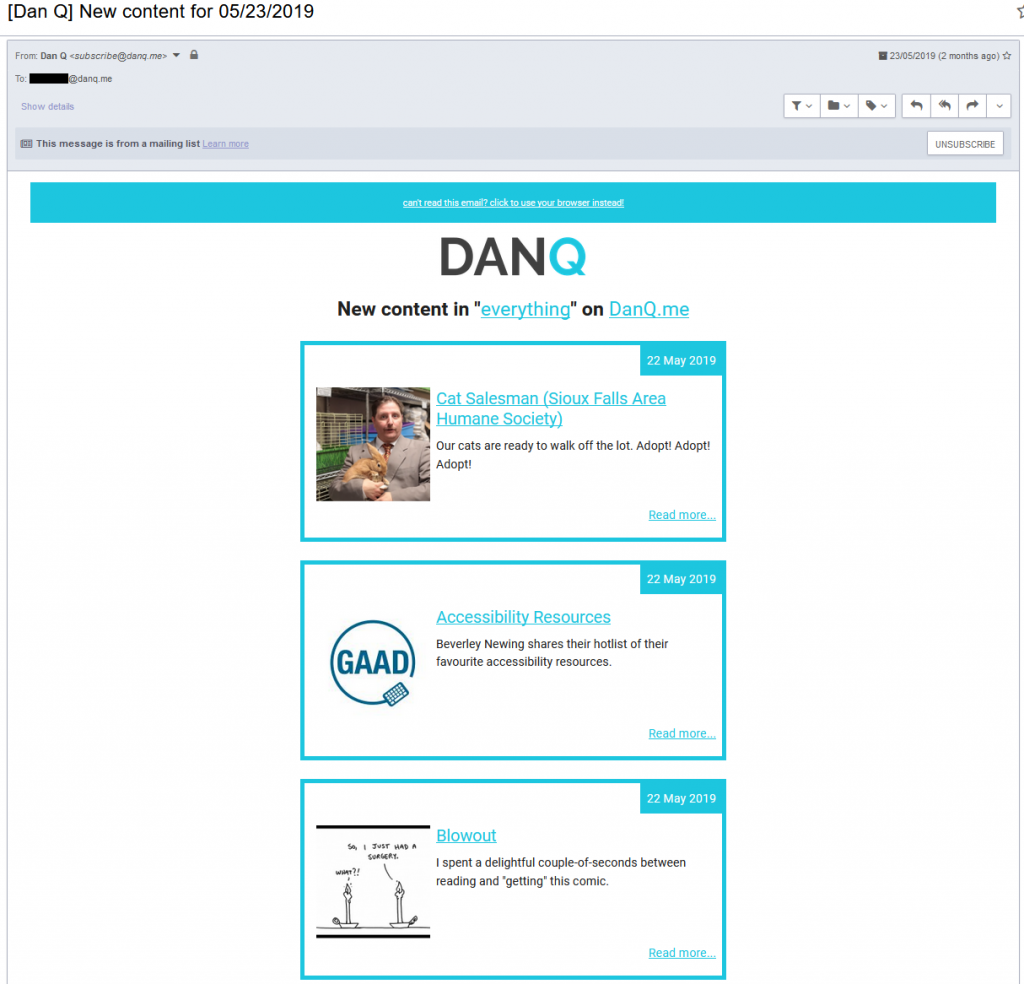
of content out to people who prefer to subscribe via that medium, and I’ve also been using this to power an experimental MailChimp “daily digest” mailing list of “what Dan’s been up to”
to a small number of friends, right in their email inboxes: I’ve not made it available to everybody yet, but if you’re happy to help test it then give me a shout
and I’ll hook you up.
Most days don’t see an email sent or see an email with only one item, but some days – like this one – are busier. I still need to update the brand colours here, too!
Finally, a couple of IFTTT recipes push my articles and my reposts to Reddit communities: I don’t
really use Reddit myself, any more, but I’ve got friends in a few places there who prefer to keep up-to-date with what I’m up to via that medium. For historical reasons, my reposts to
Reddit don’t go directly via my blog’s RSS feeds but “shortcut” directly from my RSS reader: this is suboptimal because I don’t get to tweak post titles for Reddit but it’s not a big deal.
What IFTTT does isn’t magic, but it’s often indistinguishable from it.
I used to syndicate content to Google+ (before it joined the long list of Things Google Have Killed) and to Ello
(but it never got much traction there). I’ve probably historically syndicated to other places too: I’ve certainly manually-republished content to other blogs, from time to time, too.
I use Ryan Barrett‘s excellent Brid.gy to convert Twitter replies and likes back into Webmentions for publication as comments on my blog. This used to work for Facebook, too, but again: Facebook
fucked it over. I’ve occasionally manually backfed significant Facebook comments, but it’s not ideal: I might like to look at using similar technologies to RSSey to subvert
Facebook’s limitations.
I’ve never had a need for Brid.gy’s “publishing” (i.e. POSSE) features, but its backfeed features “just work”, and it’s awesome.
Reintegration
I’ve routinely retroactively reintegrated content that I’ve produced elsewhere on the Web. This includes my previous blogs (which is why you can browse my archives, right here on this
site, all the way back to some of the cringeworthy angsty-teenager posts I made in the 1990s) but also some Reddit posts,
some replies originally posted directly to other people’s blogs, all my old del.icio.us bookmarks, long-form forum
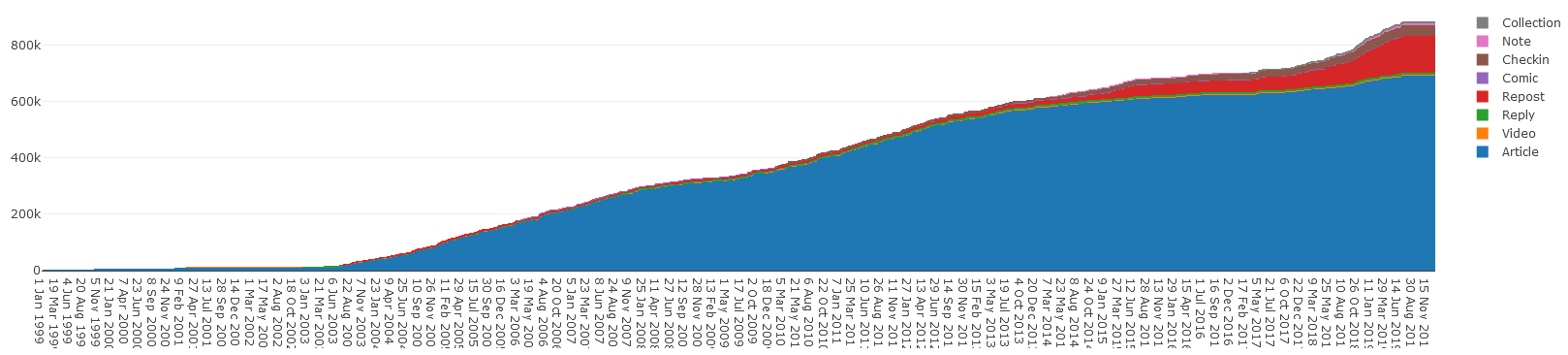
posts, posts I made to mailing lists and newsgroups, and more. As a result, there’s a lot of backdated content on this site, nowadays: almost a million words, and significantly
more than the 600,000 or so I counted a few years ago, before my biggest push for reintegration!
Cumulative wordcount per day, by content type. The lion’s share has always been articles, but reposts are creeping up as I’ve been writing more about the things I reshare, lately.
It’d be interesting to graph the differentiation of this chart to see the periods of my life that I was writing the most: I have a hypothesis, and centralising my own content under my
control makes it easier
Why do I do this? Because I really, really like owning my identity online! I’ve tried the “big” silo alternatives like Facebook, Twitter, Medium, Instagram etc., and they’ve eventually
always lead to disappointment, either because they get shut down or otherwise made-unusable, because
of inappropriately-applied “real names” policies, because they give too much power to
untrustworthy companies, because they impose arbitrary limitations on my content, because they manipulate output
promotion (and exacerbate filter bubbles), or because they make the walls of their walled gardens taller and stop you integrating with them how you used to.
A handful of silos have shown themselves to be more-trustworthy than the average – in particular, eschewing techniques that promote “lock-in” – and I’d love to tell you more about them
and what I think you should look for in a silo, another time. But for now: suffice to say that just like I don’t use YouTube like most people do, I
elect not to use Facebook or Twitter in the conventional ways either. And it’s awesome, thanks.
There are plenty of reasons that people choose to take control of their own Web presence – and everybody who puts content online ought to consider
it – but I imagine that few individuals have such a complicated publishing ecosystem as I do! Now you’ve got a picture of how my digital content production workflow works, and
perhaps start owning your online identity, too.
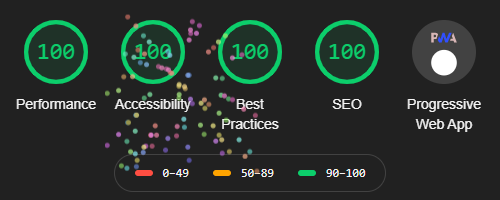
#TodayILearned that if you get a perfect 100-100-100-100 + #PWA score from @Google‘s site performance/accessibility/best practice/SEO tool “@____lighthouse” then you’re treated
to an animated fireworks display alongside your scores. (Yes, this is for danq.me.)
You know how sometimes you get an idea, and you already wrote and extended the code that makes it possible
so surely you only need to do a little audio editing and CSS animation tweaking and graphic design and HOLY SHIT HOW DID IT GET
SO LATE?
Single-page apps (or SPAs as they’re sometimes called) serve all of the code for an entire multi-UI app from a single index.html file.
They use JavaScript to handle URL routing with real URLs. For this to work, you need to:
Configure the server to point all paths on a domain back to the root index.html file. For example, todolist.com and todolist.com/lists
should both point to the same file.
Suppress the default behavior when someone clicks a link that points to another page in the app.
Use more JavaScript—history.pushState()—to update the URL without triggering a page reload.
Match the URL against a map of routes, and serve the right content based on it.
If your URL has variable information in it (like a todolist ID, for example), parse that data out of the URL.
Detect when someone clicks the browser’s back button/forward button, and update the URL and UI.
Update the title element on the page.
Use even more JavaScript to dynamically focus the content area when the content changes (for screen-reader users).
You end up recreating with JavaScript a lot of the features the browser gives you out-of-the-box.
This becomes more code to maintain, more complexity to manage, and more things to break. It makes the whole app more fragile and bug-prone than it has to be.
I’m going to share some alternatives that I prefer.
…
Like – it seems – Chris Ferdinandi, I’ve got nothing against Single Page Applications in their place.
My biggest concern with SPAs is that they’re routinely seen as an inevitable progression of web development: that is,
that an increasing number of web developers have been brainwashed into thinking that they’re intrinsically superior to traditional multi-page websites. As Adam Silver observed the other year, using your heavyweight Javascript framework to Ajaxify your page loads
does make the application feel faster… but only because the download and processing time of the heavyweight Javascript framework made it feel slow in the first place! The net
result: web bloat, penalising of mobile users, and brittle applications with many failure points.
Whenever I see a new front-end framework sing the praises of its routing engine I wonder how we got to this point. After all: the Web’s had a routing engine since 1990, and
most efforts to reinvent it invariably make it worse: less-accessible, less-archivable, less-sharable, less-discoverable, less-reliable, or several of these.