


















With thanks to Ruth for the conversation that inspired these pictures, and apologies to the rest of the Internet for creating them.
With thanks to Ruth for the conversation that inspired these pictures, and apologies to the rest of the Internet for creating them.
I’m off work sick today: it’s just a cold, but it’s had a damn good go at wrecking my lungs and I feel pretty lousy. You know how when you’ve got too much of a brain-fog to trust yourself with production systems but you still want to write code (or is that just me?), so this morning I threw together a really, really stupid project which you can play online here.
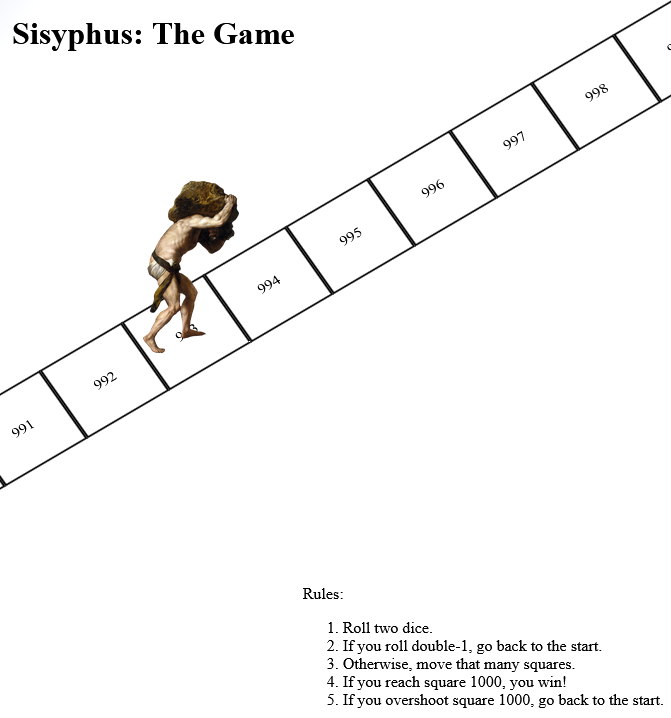
It’s inspired by a toot by Mason”Tailsteak” Williams (whom I’ve mentioned before once or twice). At first I thought I’d try to calculate the odds of winning at his proposed game, or how many times one might expect to play before winning, but I haven’t the brainpower for that in my snot-addled brain. So instead I threw together a terrible, terrible digital implementation.
Go play it if, like me, you’ve got nothing smarter that your brain can be doing today.
Just in time for Robin Sloan to give up on Spring ’83, earlier this month I finally got aroud to launching STS-6 (named for the first mission of the Space Shuttle Challenger in Spring 1983), my experimental Spring ’83 server. It’s been a busy year; I had other things to do. But you might have guessed that something like this had been under my belt when I open-sourced a keygenerator for the protocol the other day.
If you’ve not played with Spring ’83, this post isn’t going to make much sense to you. Sorry.
My server is, as far as I can tell, very different from any others in a few key ways:
{{board:123}}which are
automatically converted to addresses referencing the public key of the “current” keypair for that board. This separates the concept of a board and its content template from that
board’s keypairs, making it easier to link to a board. To put it another way, STS-6 links are self-healing on the server-side (for local boards).
<link rel="next"> connections to keep them current.
I’m sure that there are those who would see this as automating something that was beautiful because it was handcrafted; I don’t know whether or not I agree, but had Spring ’83 taken off in a bigger way, it would always only have been a matter of time before somebody tried my approach.
From a design perspective, I enjoyed optimising an SVG image of my header so it could meaningfully fit into the board. It’s pretty, and it’s tolerably lightweight.
If you want to see my server in action, patch this into your favourite Spring ’83 client:
https://s83.danq.dev/10c3ff2e8336307b0ac7673b34737b242b80e8aa63ce4ccba182469ea83e0623
Without Robin’s active participation, I feel that Spring ’83 is probably coming to a dead end. It’s been a lot of fun to play with and I’d love to see what ideas the experience of it goes on to inspire next, but in its current form it’s one of those things that’s an interesting toy, but not something that’ll make serious waves.
In his last lab essay Robin already identified many of the key issues with the system (too complicated, no interpersonal-mentions, the challenge of keys-as-identifiers, etc.) and while they’re all solvable without breaking the underlying mechanisms (mentions might be handled by Webmention, perhaps, etc.), I understand the urge to take what was learned from this experiment and use it to help inform the decisions of the next one. Just as John Postel’s Quote of the Day protocol doesn’t see much use any more (although maybe if my finger server could support QotD?) but went on to inspire the direction of many subsequent “call-and-response” protocols, including HTTP, it’s okay if Spring ’83 disappears into obscurity, so long as we can learn what it did well and build upon that.
Meanwhile: if you’re looking for a hot new “like the web but lighter” protocol, you should probably check out Gemini. (Incidentally, you can find me at gemini://danq.me, but that’s something I’ll write about another day…)
This is a reply to a post published elsewhere. Its content might be duplicated as a traditional comment at the original source.
This weekend I was experimentally reimplenting how my blog displays comments. For testing I needed to find an old post with both trackbacks and pingbacks on it. I found my post that you linked, here, and was delighted to be reminded that despite both of our blogs changing domain name (from photomatt.net to ma.tt and from blog.scatmania.org to danq.me, respectively), all the links back and forth still work perfectly because clearly we share an apporopriate dedication to the principle that Cool URIs Don’t Change, and set up our redirects accordingly. 🙌
Incidentally, this was about the point in time at which I first thought to myself “hey, I like what Matt’s doing with this Automattic thing; I should work there someday”. It took me like a decade to a decade-and-a-half to get around to applying, though… 😅
Anyway: thanks for keeping your URIs cool so I could enjoy this trip down memory lane (and debug an experimental wp_list_comments callback!).
Via Jeremy Keith I today discovered Jim Nielsen‘s suggestion for a website’s /.well-known/links to be a place where it can host a JSON-formatted list of all of its outgoing links.
That’s a really useful thing to have in this new age of the web, where Refererer: headers are no-longer commonly passed cross-domain and Google Search no longer provides the link: operator. If you want to know if I’ve ever
linked to your site, it’s a bit of a drag to find out.

So, obviously, I’ve written an implementation for WordPress. It’s really basic right now, but the source code can be
found here if you want it. Install it as a plugin and run wp outbound-links to kick it off. It’s fast: it takes 3-5 seconds to parse the entirety of danq.me,
and I’ve got somewhere in the region of 5,000 posts to parse.
You can see the results at https://danq.me/.well-known/links – if you’ve ever wondered “has Dan ever linked to my site?”, now you can find the answer.
If this could be useful to you, let’s collaborate on making this into an actually-useful plugin! Otherwise it’ll just languish “as-is”, which is good enough for my purposes.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
[Nilay:] It is fashionable to run around saying the web is dead and that apps shape the world, but in my mind, the web’s pretty healthy for at least two things: news and shopping.
[Matt:] I think that’s your bubble, if I’m totally honest. That’s what’s cool about the web: We can live in a bubble and that can seem like the whole thing. One thing I would explicitly try to do in 2022 is make the web weirder.
…
The Verge interviewed Matt Mullenweg, and – as both an Automattician and a fan of the Web as a place for fun and weirdness – I really appreciated the direction the interview went in. I maintain that open web standards and platforms (as opposed to closed social media silos) are inspirational and innovative.
Emilie Reed‘s Anything a Maze lives on itch.io, and (outside of selfhosting) that’s clearly the best place for it: you couldn’t tell that story the same way on Medium; even less-so on Facebook or Twitter.
Suppose you’re running an application on a Passenger + Nginx powered server and you want to add caching.
Perhaps your application has a dynamic, public endpoint but the contents don’t change super-frequently or it isn’t critically-important that the user always gets up-to-the-second accuracy, and you’d like to improve performance with microcaching. How would you do that?

Your configuration might look something like this:
1 2 3 4 5 6 7 |
server { # listen, server_name, ssl, logging etc. directives go here # ... root /your/application; passenger_enabled on; } |
What you’re looking for is proxy_cache and its sister directives, but you can’t just
insert them here because while Passenger does act act like an upstream proxy (with parallels like e.g. passenger_pass_header which mirrors the behaviour of proxy_pass_header), it doesn’t provide any of the functions you need to implement proxy caching
of non-static files.
Instead, what you need to to is define a second server, mount Passenger in that, and then proxy to that second server. E.g.:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Set up a cache proxy_cache_path /tmp/cache/my-app-cache keys_zone=MyAppCache:10m levels=1:2 inactive=600s max_size=100m; # Define the actual webserver that listens for Internet traffic: server { # listen, server_name, ssl, logging etc. directives go here # ... # You can configure different rules by location etc., but here's a simple microcache: location / { proxy_pass http://127.0.0.1:4863; # Proxy all traffic to the application server defined below proxy_cache MyAppCache; # Use the cache defined above proxy_cache_valid 200 3s; # Treat HTTP 200 responses as valid; cache them for 3 seconds proxy_cache_use_stale updating; # (Optional) send outdated response while background-updating cache proxy_cache_lock on; # (Optional) only allow one process to update cache at once } } # (Local-only) application server on an arbitrary port number to act as the upstream proxy: server { listen 127.0.0.1:4863; root /your/application; passenger_enabled on; } |
The two key changes are:
server block, localhost-only, on an arbitrary port number (doesn’t need HTTPS, of course, but if your application detects/”expects” HTTPS you
might need to tweak your headers).
server block proxies to the second as its upstream, and you can add whatever caching directives you like.
Obviously you’ll need to be smarter if you host a mixture of public and private content (e.g. send Vary: headers from your application) and if you want different cache
durations on different addresses or types of content, but there are already great guides to help with that. I only wrote this post because I spent some time searching for (nonexistent!)
passenger_cache_ etc. rules and wanted to save the next person from the same trouble!
Don’t have time to read? Just start playing:
Am I too late to get onto the “making Wordle clones” bandwagon? Probably; there are quite a few now, including:
But you know what hasn’t been seen before today? A Wordle clone where you have to guess a creature from the Dungeons & Dragons (5e) Monster Manual by putting numeric values into a character sheet (STR, DEX, CON, INT, WIS, CHA):
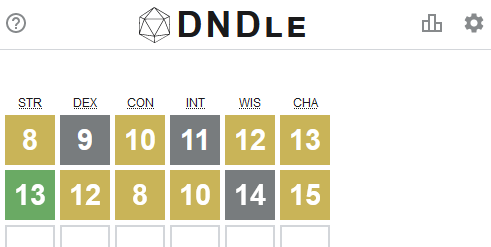
What are you waiting for: go give DNDle a try (I pronounce it “dindle”, but you can pronounce it however you like). A new monster appears at 10:00 UTC each day.
And because it’s me, of course it’s open source and works offline.
import statements and bundles a single JS file for the browser.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
What happens when you give Gutenberg and Elementor to complete Beginners? In this challenge, Meg and Lily (two of my daughters) are tasked with re-creating a webpage. They’ve never used Elementor or Gutenberg before, and I only gave them 30 minutes each.
…
Jamie of Pootlepress challenged his daughters – who are presumably both digital natives, but have no WordPress experience – to build a page to a specific design using both Gutenberg and Elementor. In 30 minutes.
Regardless of what you think about the products under test or the competitors in the challenge (Lily + Gutenberg clearly seems to be the fan favourite, which I’d sort-of expect because IMO Gutenberg’s learning curve is much flatter that Elementor’s), this is a fantastic example of “thinking aloud” (“talkalong”) UX testing. And with (only) a £20 prize on offer, it’s possibly the best-value testing of its type I’ve ever seen too! Both the participants do an excellent job of expressing their praise of and frustration with different parts of the interface of their assigned editing platform, and the developers of both – and other systems besides – could learn a lot from watching this video.
Specifically, this video shows how enormous the gulf is between how developers try to express concepts that are essential to web design and how beginner users assume things will work. Concepts like thinking in terms of “blocks” that can resize or reposition dynamically, breakpoints, assets as cross-references rather than strictly embedded within documents, style as an overarching concept by preference to something applied to individual elements, etc… some as second nature once you’re sixteen levels deep into the DOM and you’ve been doing it for years! But they’re rarely intuitive… or, perhaps, not expressed in a way that makes them intuitive… to new users.
I’ve just launched EGXchange.org, a digital wallet for new currency Emma Goldcoin, which I’ve mentioned previously (including a discussion with the author in my comments section).
You can install it as an offline-first progressive web application, which means that this could be the first ever digital currency to have an app that works without an Internet connection. That’s probably something no other digital currency can claim to have, right?
Here’s what it looks like if I send 0.1 EGX to my friend Chris using the app:
Naturally, I wouldn’t be backing Emma Goldcoin if it didn’t represent such a brilliant step up better-known digital currencies like Bitcoin, Ripple, and Etherium. Specific features unique to Emma Goldcoin include:
Sure, it’s got its downsides, and I’d encourage you to read the specification if you’d like to learn more about what those are. Or if you already know what EGX is all about and just want to try a new way to manage your portfolio, give my new site EGXchange.org a go!
Sometimes a web standard disappears quickly at the whim of some company, perhaps to a great deal of complaint (and at least one joke).
But sometimes, they disappear slowly, like this kind of web address:
http://username:password@example.com/somewhere
If you’ve not seen a URL like that before, that’s fine, because the answer to the question “Can I still use HTTP Basic Auth in URLs?” is, I’m afraid: no, you probably can’t.
But by way of a history lesson, let’s go back and look at what these URLs were, why they died out, and how web browsers handle them today. Thanks to Ruth who asked the original question that inspired this post.
The early Web wasn’t built for authentication. A resource on the Web was theoretically accessible to all of humankind: if you didn’t want it in the public eye, you didn’t put it on the Web! A reliable method wouldn’t become available until the concept of state was provided by Netscape’s invention of HTTP cookies in 1994, and even that wouldn’t see widespread for several years, not least because implementing a CGI (or similar) program to perform authentication was a complex and computationally-expensive option for all but the biggest websites.
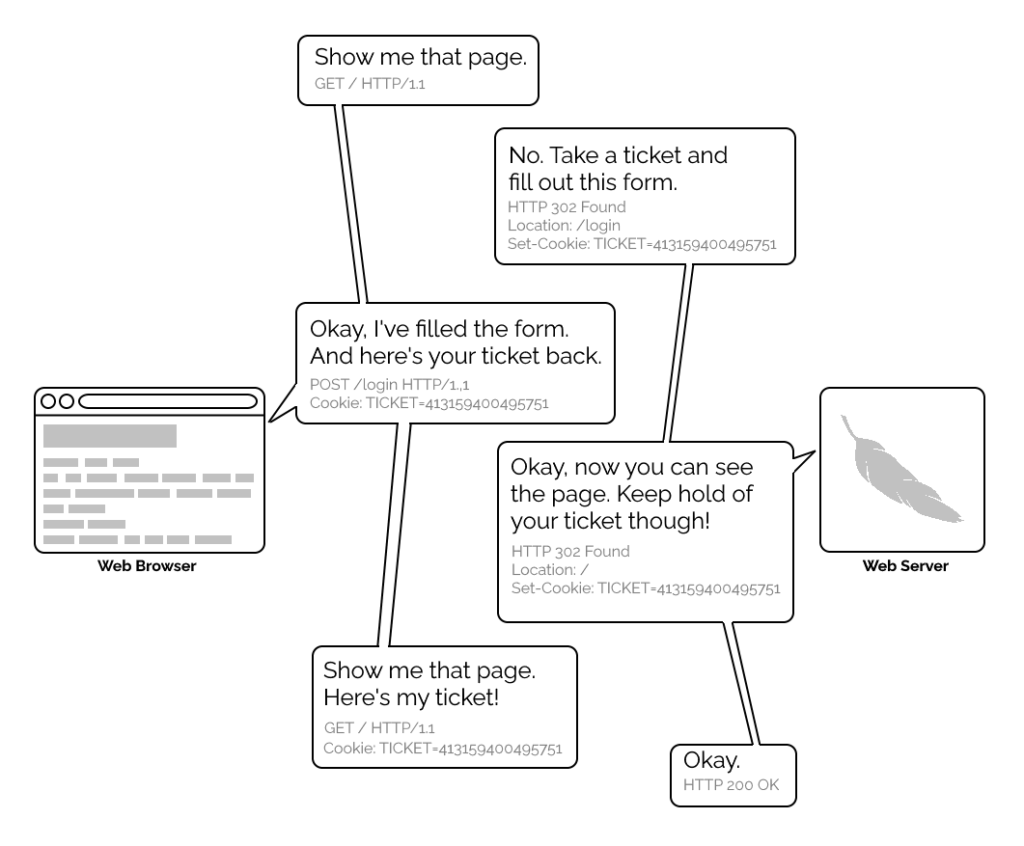
1996’s HTTP/1.0 specification tried to simplify things, though, with the introduction of the WWW-Authenticate header. The idea was that when a browser tried to access something that required
authentication, the server would send a 401 Unauthorized response along with a WWW-Authenticate header explaining how the browser could authenticate
itself. Then, the browser would send a fresh request, this time with an Authorization: header attached providing the required credentials. Initially, only “basic
authentication” was available, which basically involved sending a username and password in-the-clear unless SSL (HTTPS) was in use, but later, digest authentication and a host of others would appear.
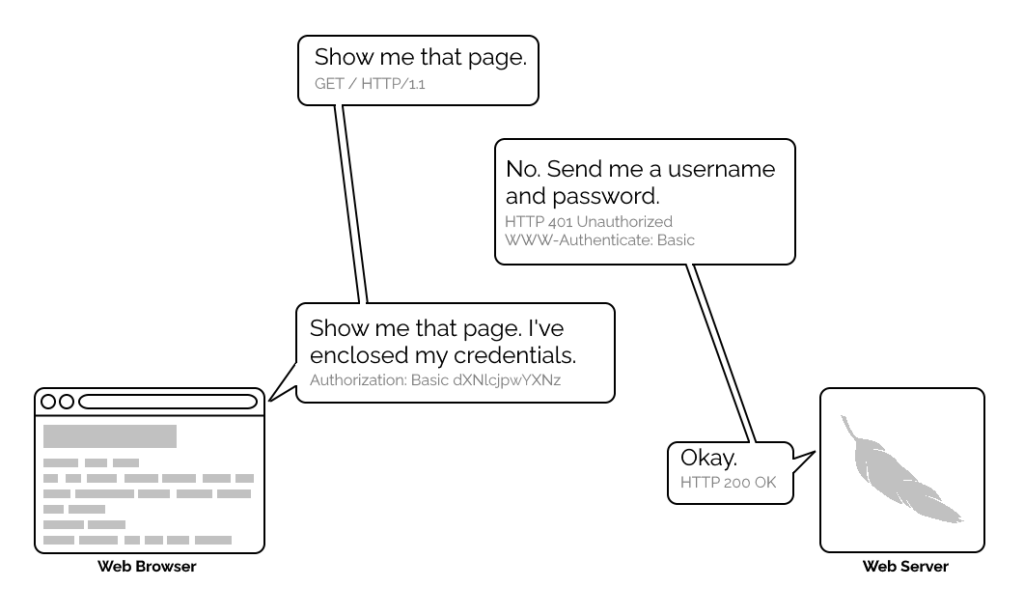
Webserver software quickly added support for this new feature and as a result web authors who lacked the technical know-how (or permission from the server administrator) to implement
more-sophisticated authentication systems could quickly implement HTTP Basic Authentication, often simply by adding a .htaccess file to the relevant directory.
.htaccess files would later go on to serve many other purposes, but their original and perhaps best-known purpose – and the one that gives them their name – was access
control.
A separate specification, not specific to the Web (but one of Tim Berners-Lee’s most important contributions to it), described the general structure of URLs as follows:
<scheme>://<username>:<password>@<host>:<port>/<url-path>#<fragment>
At the time that specification was written, the Web didn’t have a mechanism for passing usernames and passwords: this general case was intended only to apply to protocols that did have these credentials. An example is given in the specification, and clarified with “An optional user name. Some schemes (e.g., ftp) allow the specification of a user name.”
But once web browsers had WWW-Authenticate, virtually all of them added support for including the username and password in the web address too. This allowed for
e.g. hyperlinks with credentials embedded in them, which made for very convenient bookmarks, or partial credentials (e.g. just the username) to be included in a link, with the
user being prompted for the password on arrival at the destination. So far, so good.

The technique fell out of favour as soon as it started being used for nefarious purposes. It didn’t take long for scammers to realise that they could create links like this:
https://YourBank.com@HackersSite.com/
Everything we were teaching users about checking for “https://” followed by the domain name of their bank… was undermined by this user interface choice. The poor victim would actually be connecting to e.g. HackersSite.com, but a quick glance at their address bar would leave them convinced that they were talking to YourBank.com!
Theoretically: widespread adoption of EV certificates coupled with sensible user interface choices (that were never made) could have solved this problem, but a far simpler solution was just to not show usernames in the address bar. Web developers were by now far more excited about forms and cookies for authentication anyway, so browsers started curtailing the “credentials in addresses” feature.
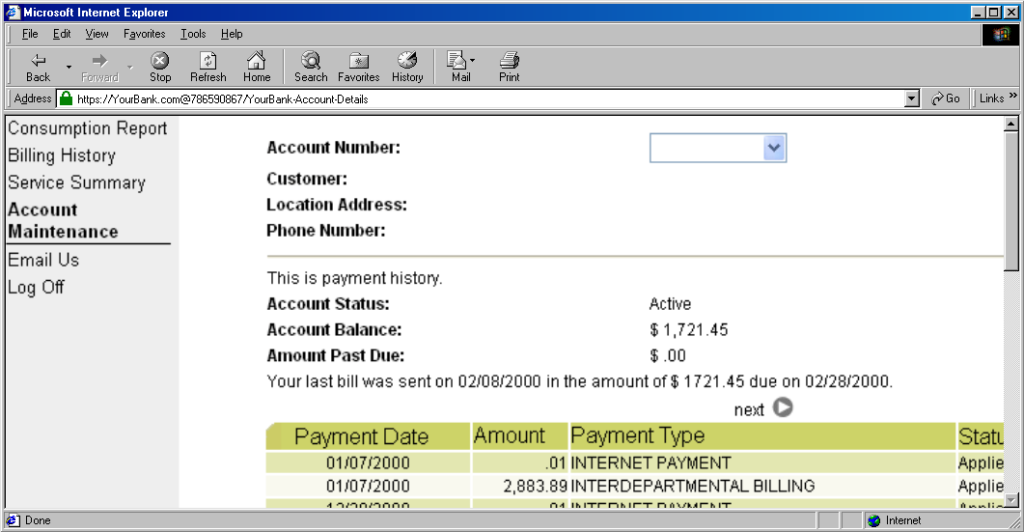
(There are other reasons this particular implementation of HTTP Basic Authentication was less-than-ideal, but this reason is the big one that explains why things had to change.)
One by one, browsers made the change. But here’s the interesting bit: the browsers didn’t always make the change in the same way.
Let’s examine some popular browsers. To run these tests I threw together a tiny web application that outputs
the Authorization: header passed to it, if present, and can optionally send a 401 Unauthorized response along with a WWW-Authenticate: Basic realm="Test Site" header in order to trigger basic authentication. Why both? So that I can test not only how browsers handle URLs containing credentials when an authentication request is received, but how they handle them when one is not. This is relevant because
some addresses – often API endpoints – have optional HTTP authentication, and it’s sometimes important for a user agent (albeit typically a library or command-line one) to pass credentials without
first being prompted.
In each case, I tried each of the following tests in a fresh browser instance:
http://<username>:<password>@<domain>/optional (authentication is optional).
http://<username>:<password>@<domain>/mandatory (authentication is mandatory).
/mandatory.
/optional.
I’m only testing over the http scheme, because I’ve no reason to believe that any of the browsers under test treat the https scheme differently.
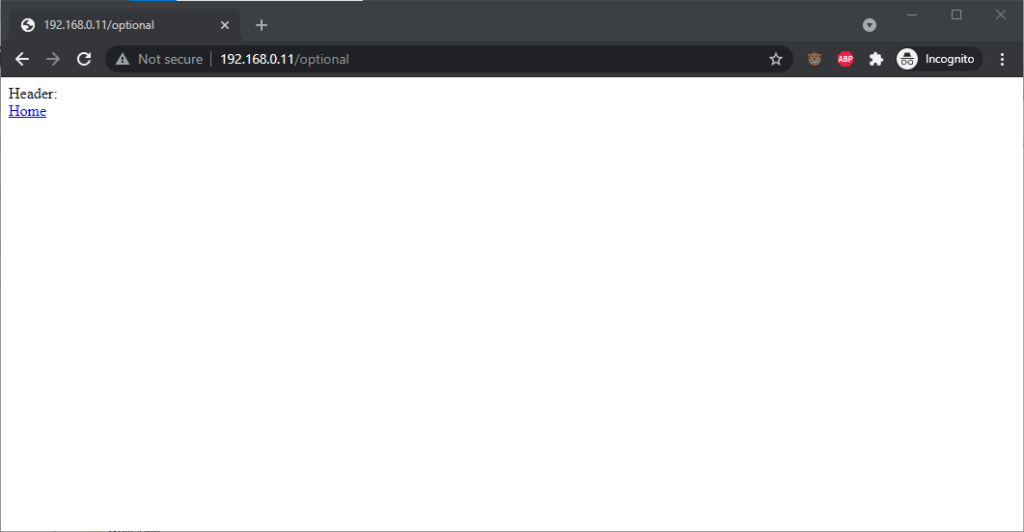 Chrome 93 and Edge 93 both immediately suppressed the username and password from the address bar, along with the “http://” as we’ve come to expect of them. Like the “http://”, though,
the plaintext username and password are still there. You can retrieve them by copy-pasting the entire address.
Chrome 93 and Edge 93 both immediately suppressed the username and password from the address bar, along with the “http://” as we’ve come to expect of them. Like the “http://”, though,
the plaintext username and password are still there. You can retrieve them by copy-pasting the entire address.
Opera 78 similarly suppressed the username, password, and scheme, but didn’t retain the username and password in a way that could be copy-pasted out.
Authentication was passed only when landing on a “mandatory” page; never when landing on an “optional” page. Refreshing the page or re-entering the address with its credentials did not change this.
Navigating from the “optional” page to the “mandatory” page using only relative links retained the username and password and submitted it to the server when it became mandatory, even Opera which didn’t initially appear to retain the credentials at all.
Navigating from the “mandatory” to the “optional” page using only relative links, or even entering the “optional” page address with credentials after visiting the “mandatory” page, does not result in authentication being passed to the “optional” page. However, it’s interesting to note that once authentication has occurred on a mandatory page, pressing enter at the end of the address bar on the optional page, with credentials in the address bar (whether visible or hidden from the user) does result in the credentials being passed to the optional page! They continue to be passed on each subsequent load of the “optional” page until the browsing session is ended.
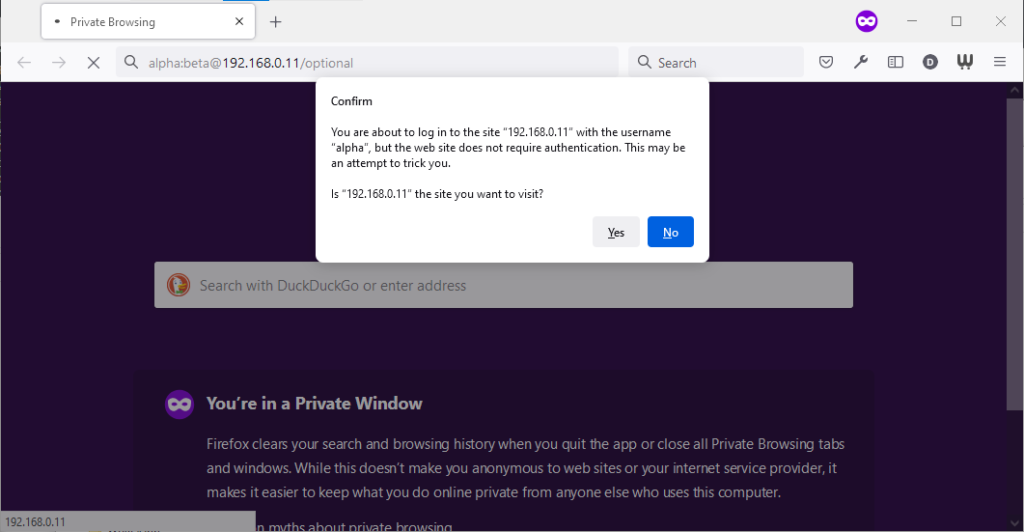 Firefox 91 does a clever thing very much in-line with
its image as a browser that puts decision-making authority into the hands of its user. When going to the “optional” page first it presents a dialog, warning the user that they’re going
to a site that does not specifically request a username, but they’re providing one anyway. If the user says that no, navigation ceases (the GET request for the page takes place the same
either way; this happens before the dialog appears). Strangely: regardless of whether the user selects yes or no, the credentials are not passed on the “optional” page. The credentials
(although not the “http://”) appear in the address bar while the user makes their decision.
Firefox 91 does a clever thing very much in-line with
its image as a browser that puts decision-making authority into the hands of its user. When going to the “optional” page first it presents a dialog, warning the user that they’re going
to a site that does not specifically request a username, but they’re providing one anyway. If the user says that no, navigation ceases (the GET request for the page takes place the same
either way; this happens before the dialog appears). Strangely: regardless of whether the user selects yes or no, the credentials are not passed on the “optional” page. The credentials
(although not the “http://”) appear in the address bar while the user makes their decision.
Similar to Opera, the credentials do not appear in the address bar thereafter, but they’re clearly still being stored: if the refresh button is pressed the dialog appears again. It does not appear if the user selects the address bar and presses enter.
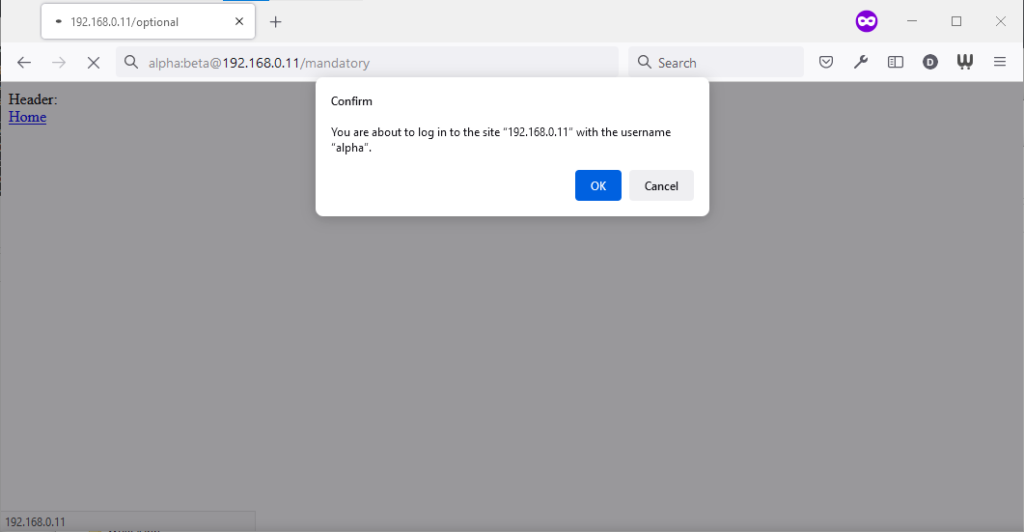 Similarly, going to the “mandatory” page in Firefox results in an informative dialog warning the user
that credentials are being passed. I like this approach: not only does it help protect the user from the use of authentication as a tracking technique (an old technique that I’ve not
seen used in well over a decade, mind), it also helps the user be sure that they’re logging in using the account they mean to, when following a link for that purpose. Again, clicking
cancel stops navigation, although the initial request (with no credentials) and the 401 response has already occurred.
Similarly, going to the “mandatory” page in Firefox results in an informative dialog warning the user
that credentials are being passed. I like this approach: not only does it help protect the user from the use of authentication as a tracking technique (an old technique that I’ve not
seen used in well over a decade, mind), it also helps the user be sure that they’re logging in using the account they mean to, when following a link for that purpose. Again, clicking
cancel stops navigation, although the initial request (with no credentials) and the 401 response has already occurred.
Visiting any page within the scope of the realm of the authentication after visiting the “mandatory” page results in credentials being sent, whether or not they’re included in the address. This is probably the most-true implementation to the expectations of the standard that I’ve found in a modern graphical browser.
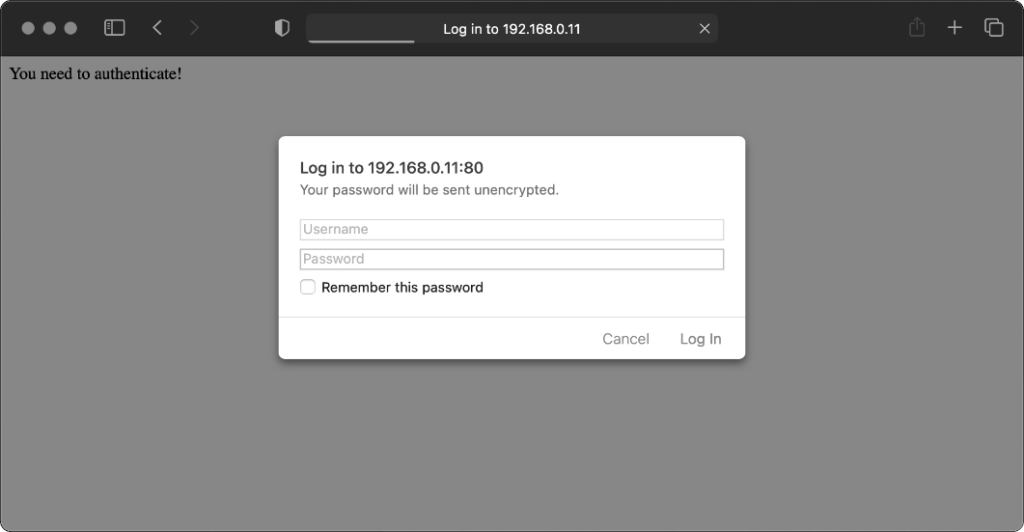 Safari 14 never displays or uses credentials provided via the web address, whether or not
authentication is mandatory. Mandatory authentication is always met by a pop-up dialog, even if credentials were provided in the address bar. Boo!
Safari 14 never displays or uses credentials provided via the web address, whether or not
authentication is mandatory. Mandatory authentication is always met by a pop-up dialog, even if credentials were provided in the address bar. Boo!
Once passed, credentials are later provided automatically to other addresses within the same realm (i.e. optional pages).
Let’s try some older browsers.
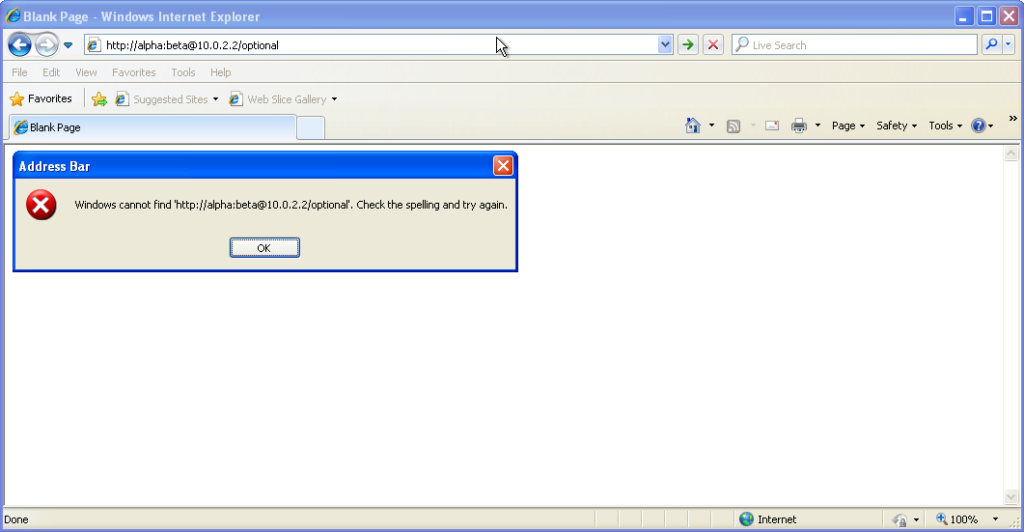 From version 7 onwards – right up to the final version 11 – Internet Explorer fails to even recognise
addresses with authentication credentials in as legitimate web addresses, regardless of whether or not authentication is requested by the server. It’s easy to assume that this is yet
another missing feature in the browser we all love to hate, but it’s interesting to note that credentials-in-addresses is permitted for
From version 7 onwards – right up to the final version 11 – Internet Explorer fails to even recognise
addresses with authentication credentials in as legitimate web addresses, regardless of whether or not authentication is requested by the server. It’s easy to assume that this is yet
another missing feature in the browser we all love to hate, but it’s interesting to note that credentials-in-addresses is permitted for ftp:// URLs…
 …and if you go back a little way, Internet Explorer 6 and below supported credentials in the address bar pretty
much as you’d expect based on the standard. The error message seen in IE7 and above is a deliberate design
decision, albeit a somewhat knee-jerk reaction to the security issues posed by the feature (compare to the more-careful approach of other browsers).
…and if you go back a little way, Internet Explorer 6 and below supported credentials in the address bar pretty
much as you’d expect based on the standard. The error message seen in IE7 and above is a deliberate design
decision, albeit a somewhat knee-jerk reaction to the security issues posed by the feature (compare to the more-careful approach of other browsers).
These older versions of IE even (correctly) retain the credentials through relative hyperlinks, allowing them to be passed when they become mandatory. They’re not passed on optional pages unless a mandatory page within the same realm has already been encountered.
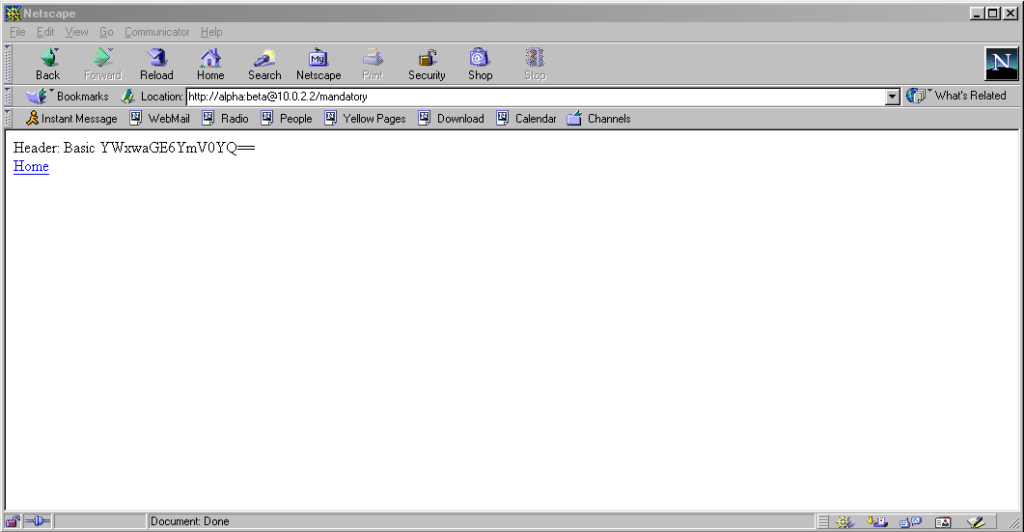 Pre-Mozilla Netscape behaved the same way. Truly this was the de facto standard for a long period on the Web, and the varied approaches we see today are the
anomaly. That’s a strange observation to make, considering how much the Web of the 1990s was dominated by incompatible implementations of different Web features (I’ve written about the
Pre-Mozilla Netscape behaved the same way. Truly this was the de facto standard for a long period on the Web, and the varied approaches we see today are the
anomaly. That’s a strange observation to make, considering how much the Web of the 1990s was dominated by incompatible implementations of different Web features (I’ve written about the <blink> and <marquee> tags before, which was perhaps the most-visible division between
the Microsoft and Netscape camps, but there were many, many more).
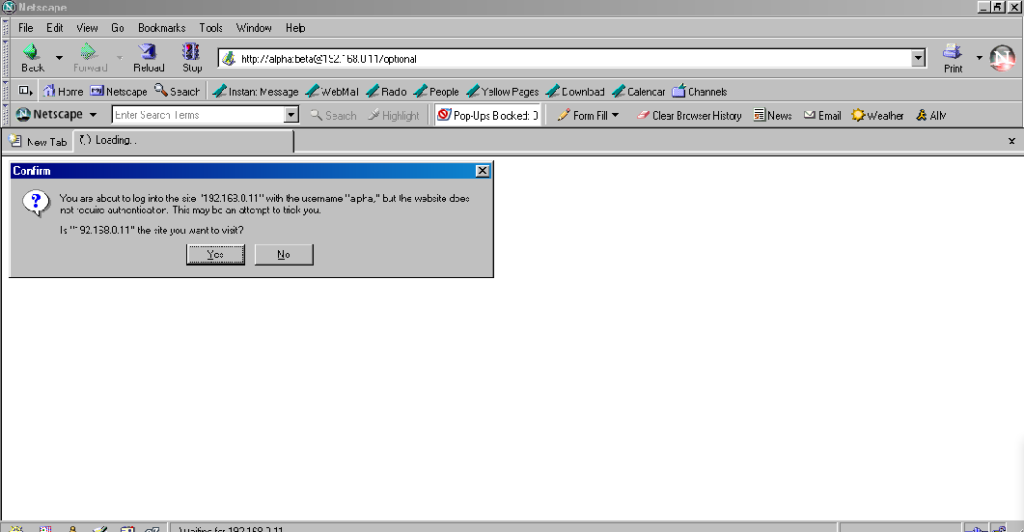 Interestingly: by Netscape 7.2 the browser’s behaviour had evolved
to be the same as modern Firefox’s, except that it still displayed the credentials in the address bar for all to see.
Interestingly: by Netscape 7.2 the browser’s behaviour had evolved
to be the same as modern Firefox’s, except that it still displayed the credentials in the address bar for all to see.
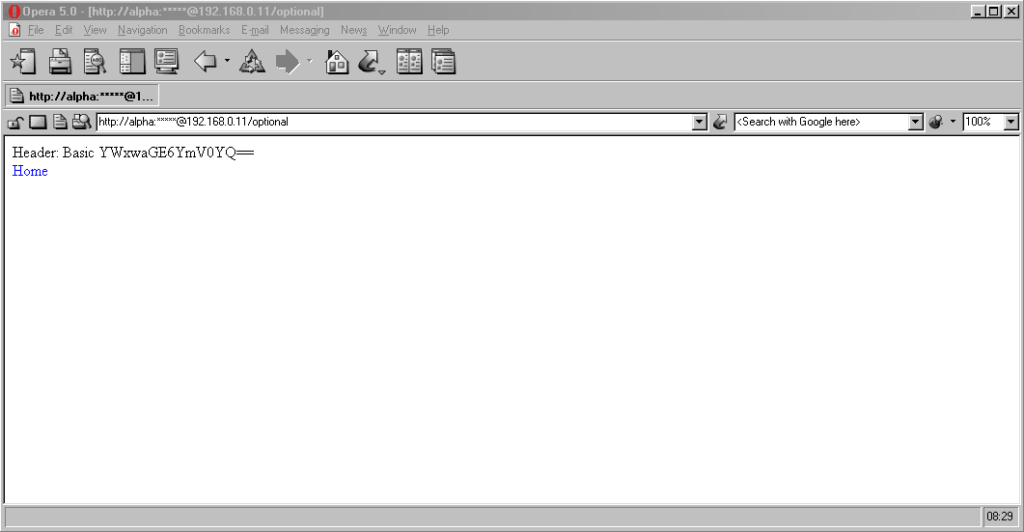 Now here’s a real gem: pre-Chromium Opera. It would send credentials to “mandatory” pages and remember them for the
duration of the browsing session, which is great. But it would also send credentials when passed in a web address to “optional” pages. However, it wouldn’t remember
them on optional pages unless they remained in the address bar: this feels to me like an optimum balance of features for power users. Plus, it’s one of very few browsers that
permitted you to change credentials mid-session: just by changing them in the address bar! Most other browsers, even to this day, ignore changes to HTTP Authentication credentials, which was sometimes be a source of frustration back in the day.
Now here’s a real gem: pre-Chromium Opera. It would send credentials to “mandatory” pages and remember them for the
duration of the browsing session, which is great. But it would also send credentials when passed in a web address to “optional” pages. However, it wouldn’t remember
them on optional pages unless they remained in the address bar: this feels to me like an optimum balance of features for power users. Plus, it’s one of very few browsers that
permitted you to change credentials mid-session: just by changing them in the address bar! Most other browsers, even to this day, ignore changes to HTTP Authentication credentials, which was sometimes be a source of frustration back in the day.
Finally, classic Opera was the only browser I’ve seen to mask the password in the address bar, turning it into a series of asterisks. This ensures the user knows that a password was used, but does not leak any sensitive information to shoulder-surfers (the length of the “masked” password was always the same length, too, so it didn’t even leak the length of the password). Altogether a spectacular design and a great example of why classic Opera was way ahead of its time.
Most people using web addresses with credentials embedded within them nowadays are probably working with code, APIs, or the command line, so it’s unsurprising to see that this is where the most “traditional” standards-compliance is found.
I was unsurprised to discover that giving curl a username and password in the URL meant that username and password was sent to the server (using Basic authentication, of course, if no authentication was requested):
$ curl http://alpha:beta@localhost/optional
Header: Basic YWxwaGE6YmV0YQ==
$ curl http://alpha:beta@localhost/mandatory
Header: Basic YWxwaGE6YmV0YQ==
However, wget did catch me out. Hitting the same addresses with wget didn’t result in the credentials being sent
except where it was mandatory (i.e. where a HTTP 401 response and a WWW-Authenticate: header was received on the initial attempt). To force wget to
send credentials when they haven’t been asked-for requires the use of the --http-user and --http-password switches:
$ wget http://alpha:beta@localhost/optional -qO-
Header:
$ wget http://alpha:beta@localhost/mandatory -qO-
Header: Basic YWxwaGE6YmV0YQ==
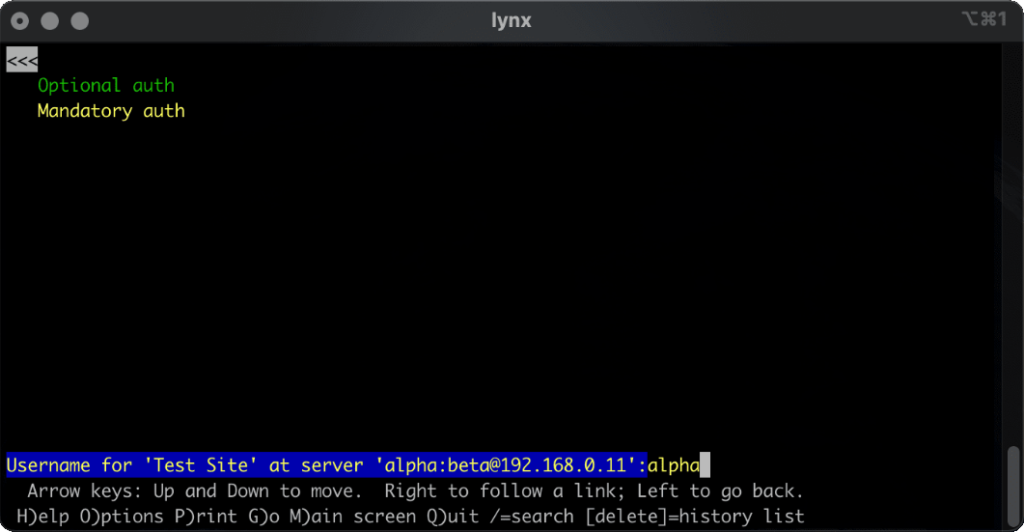
lynx does a cute and clever thing. Like most modern browsers, it does not submit credentials unless specifically requested, but if they’re in the address bar when they become mandatory (e.g. because of following relative hyperlinks or hyperlinks containing credentials) it prompts for the username and password, but pre-fills the form with the details from the URL. Nice.
HTTP Basic Authentication and its close cousin Digest Authentication (which overcomes some of the security limitations of running Basic Authentication over an
unencrypted connection) is very much alive, but its use in hyperlinks can’t be relied upon: some browsers (e.g. IE, Safari)
completely munge such links while others don’t behave as you might expect. Other mechanisms like Bearer see widespread use in APIs, but nowhere else.
The WWW-Authenticate: and Authorization: headers are, in some ways, an example of the best possible way to implement authentication on the Web: as an
underlying standard independent of support for forms (and, increasingly, Javascript), cookies, and complex multi-part conversations. It’s easy to imagine an alternative
timeline where these standards continued to be collaboratively developed and maintained and their shortfalls – e.g. not being able to easily log out when using most graphical browsers!
– were overcome. A timeline in which one might write a login form like this, knowing that your e.g. “authenticate” attributes would instruct the browser to send credentials using an
Authorization: header:
<form method="get" action="/" authenticate="Basic">
<label for="username">Username:</label> <input type="text" id="username" authenticate="username">
<label for="password">Password:</label> <input type="text" id="password" authenticate="password">
<input type="submit" value="Log In">
</form>
In such a world, more-complex authentication strategies (e.g. multi-factor authentication) could involve encoding forms as JSON. And single-sign-on systems would simply involve the browser collecting a token from the authentication provider and passing it on to the
third-party service, directly through browser headers, with no need for backwards-and-forwards redirects with stacks of information in GET parameters as is the case today.
Client-side certificates – long a powerful but neglected authentication mechanism in their own right – could act as first class citizens directly alongside such a system, providing
transparent second-factor authentication wherever it was required. You wouldn’t have to accept a tracking cookie from a site in order to log in (or stay logged in), and if your
browser-integrated password safe supported it you could log on and off from any site simply by toggling that account’s “switch”, without even visiting the site: all you’d be changing is
whether or not your credentials would be sent when the time came.
The Web has long been on a constant push for the next new shiny thing, and that’s sometimes meant that established standards have been neglected prematurely or have failed to evolve for
longer than we’d have liked. Consider how long it took us to get the <video> and <audio> elements because the “new shiny” Flash came to dominate,
how the Web Payments API is only just beginning to mature despite over 25 years of ecommerce on the Web, or how we still can’t
use Link: headers for all the things we can use <link> elements for despite them being semantically-equivalent!
The new model for Web features seems to be that new features first come from a popular JavaScript implementation, and then eventually it evolves into a native browser feature: for example HTML form validations, which for the longest time could only be done client-side using scripting languages. I’d love to see somebody re-think HTTP Authentication in this way, but sadly we’ll never get a 100% solution in JavaScript alone: (distributed SSO is almost certainly off the table, for example, owing to cross-domain limitations).
Or maybe it’s just a problem that’s waiting for somebody cleverer than I to come and solve it. Want to give it a go?
I got lost on the Web this week, but it was harder than I’d have liked.

There was a discussion this week in the Abnib WhatsApp group about whether a particular illustration of a farm was full of phallic imagery (it was). This left me wondering if anybody had ever tried to identify the most-priapic buildings in the world. Of course towers often look at least a little bit like their architects were compensating for something, but some – like the Ypsilanti Water Tower in Michigan pictured above – go further than others.
I quickly found the Wikipedia article for the Most Phallic Building Contest in 2003, so that was my jumping-off point. It’s easy enough to get lost on Wikipedia alone, but sometimes you feel the need for a primary source. I was delighted to discover that the web pages for the Most Phallic Building Contest are still online 18 years after the competition ended!

Link rot is a serious problem on the Web, to such an extent that it’s pleasing when it isn’t present. The other year, for example, I revisited a post I wrote in 2004 and was pleased to find that a linked 2003 article by Nicholas ‘Aquarion’ Avenell is still alive at its original address! Contrast Jonathan Ames, the author/columnist/screenwriter who created the Most Phallic Building Contest until as late as 2011 before eventually letting his site and blog lapse and fall off the Internet. It takes effort to keep Web content alive, but it’s worth more effort than it’s sometimes given.
Anyway: a shot tower in Bristol – a part of the UK with a long history of leadworking – was among the latecomer entrants to the competition, and seeing this curious building reminded me about something I’d read, once, about the manufacture of lead shot. The idea (invented in Bristol by a plumber called William Watts) is that you pour molten lead through a sieve at the top of a tower, let surface tension pull it into spherical drops as it falls, and eventually catch it in a cold water bath to finish solidifying it. I’d seen an animation of the process, but I’d never seen a video of it, so I went about finding one.

British Pathé‘s YouTube Channel provided me with this 1950 film, and if you follow only one hyperlink from this article, let it be this one! It’s a well-shot (pun intended, but there’s a worse pun in the video!), and while I needed to translate all of the references to “hundredweights” and “Fahrenheit” to measurements that I can actually understand, it’s thoroughly informative.
But there’s a problem with that video: it’s been badly cut from whatever reel it was originally found on, and from about 1 minute and 38 seconds in it switches to what is clearly a very different film! A mother is seen shepherding her young daughter off to bed, and a voiceover says:
Bedtime has a habit of coming round regularly every night. But for all good parents responsibility doesn’t end there. It’s just the beginning of an evening vigil, ears attuned to cries and moans and things that go bump in the night. But there’s no reason why those ears shouldn’t be your neighbours ears, on occasion.

Now my interest’s piqued. What was this short film going to be about, and where could I find it? There’s no obvious link; YouTube doesn’t even make it easy to find the video uploaded “next” by a given channel. I manipulated some search filters on British Pathé’s site until I eventually hit upon the right combination of magic words and found a clip called Radio Baby Sitter. It starts off exactly where the misplaced prior clip cut out, and tells the story of “Mr. and Mrs. David Hurst, Green Lane, Coventry”, who put a microphone by their daughter’s bed and ran a wire through the wall to their neighbours’ radio’s speaker so they can babysit without coming over for the whole evening.
It’s a baby monitor, although not strictly a radio one as the title implies (it uses a signal wire!), nor is it groundbreakingly innovative: the first baby monitor predates it by over a decade, and it actually did use radiowaves! Still, it’s a fun watch, complete with its contemporary fashion, technology, and social structures. Here’s the full thing, re-merged for your convenience:
Wait, what was I trying to do when I started, again? What was I even talking about…
It used to be easier than this to get lost on the Web, and sometimes I miss that.
Obviously if you go back far enough this is true. Back when search engines were much weaker and Internet content was much less homogeneous and more distributed, we used to engage in this kind of meandering walk all the time: we called it “surfing” the Web. Second-generation Web browsers even had names, pretty often, evocative of this kind of experience: Mosaic, WebExplorer, Navigator, Internet Explorer, IBrowse. As people started to engage in the noble pursuit of creating content for the Web they cross-linked their sources, their friends, their affiliations (remember webrings? here’s a reminder; they’re not quite as dead as you think!), your favourite sites etc. You’d follow links to other pages, then follow their links to others still, and so on in that fashion. If you went round the circles enough times you’d start seeing all those invariably-blue hyperlinks turn purple and know you’d found your way home.
But even after that era, as search engines started to become a reliable and powerful way to navigate the wealth of content on the growing Web, links still dominated our exploration. Following a link from a resource that was linked to by somebody you know carried the weight of a “web of trust”, and you’d quickly come to learn whose links were consistently valuable and on what subjects. They also provided a sense of community and interconnectivity that paralleled the organic, chaotic networks of acquaintances people form out in the real world.
In recent times, that interpersonal connectivity has, for many, been filled by social networks (let’s ignore their failings in this regard for now). But linking to resources “outside” of the big social media silos is hard. These advertisement-funded services work hard to discourage or monetise activity that takes you off their platform, even at the expense of their users. Instagram limits the number of external links by profile; many social networks push for resharing of summaries of content or embedding content from other sources, discouraging engagement with the wider Web, Facebook and Twitter both run external links through a linkwrapper (which sometimes breaks); most large social networks make linking to the profiles of other users of the same social network much easier than to users anywhere else; and so on.
The net result is that Internet users use fewer different websites today than they did 20 years ago, and spend most of their “Web” time in app versions of websites (which often provide a better experience only because site owners strategically make it so to increase their lock-in and data harvesting potential). Truly exploring the Web now requires extra effort, like exercising an underused muscle. And if you begin and end your Web experience on just one to three services, that just feels kind of… sad, to me. Wasted potential.

It sounds like I’m being nostalgic for a less-sophisticated time on the Web (that would certainly be in character!). A time before we’d fully-refined the technology that would come to connect us in an instant to the answers we wanted. But that’s not exactly what I’m pining for. Instead, what I miss is something we lost along the way, on that journey: a Web that was more fun-and-weird, more interpersonal, more diverse. More Geocities, less Facebook; there’s a surprising thing to find myself saying.
Somewhere along the way, we ended up with the Web we asked for, but it wasn’t the Web we wanted.
I’ve written before about the trend in web development to take what the web gives you for free, throw it away, and then rebuild it in Javascript. The rebuilt version is invariably worse in many ways – less-accessible, higher-bandwidth, reduced features, more fragile, etc. – but it’s more convenient for developers. Personally, I try not to value developer convenience at the expense of user experience, but that’s an unpopular opinion lately.
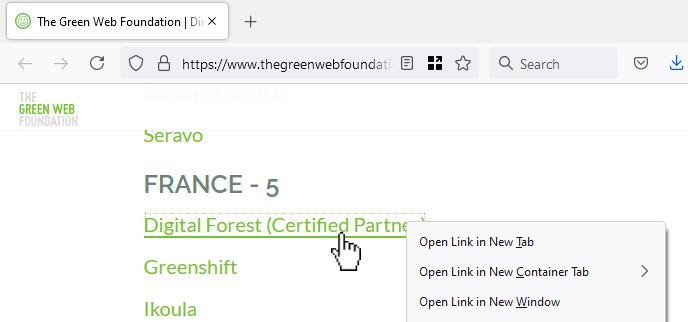
In the site shown in the screenshot above, the developer took something the web gave them for free (a hyperlink), threw it away (by making it a link-to-nowhere), and rebuilt its functionality with Javascript (without thinking about the fact that you can do more with hyperlinks than click them: you can click-and-drag them, you can bookmark them, you can share them, you can open them in new tabs etc.). Ugh.
Particularly egregious are the date pickers. Entering your date of birth on a web form ought to be pretty simple: gov.uk pretty much solved it based on user testing they did in 2013.
Here’s the short of it:
<select> elements keyboard
users can still “type” to filter.
<select>s but are really funky React <div>s, is pretty terrible.
My fellow Automattician Enfys recently tweeted:
People designing webforms that require me to enter my birthdate:
I am begging you: just let me type it in.
Typing it in is 6-8 quick keystrokes. Trying to navigate a little calendar or spinny wheels back to the 1970s is time-consuming, frustrating and unnecessary.
They’re right. Those little spinny wheels are a pain in the arse if you’ve got to use one to go back 40+ years.

If there’s one thing we learned from making the worst volume control in the world, the other year, it’s that you can always find a worse UI metaphor. So here’s my attempt at making a date of birth field that’s somehow even worse than “date spinners”:
My datepicker implements a game of “higher/lower”. Starting from bounds specified in the HTML code and a random guess, it narrows-down its guess as to what your date of birth is as you click the up or down buttons. If you make a mistake you can start over with the restart button.
Amazingly, this isn’t actually the worst datepicker into which I’ve entered my date of birth! It’s cognitively challenging compared to most, but it’s relatively fast at narrowing down the options from any starting point. Plus, I accidentally implemented some good features that make it better than plenty of the datepickers out there:
<input type="date"> control, your browser takes responsibility for localising, so if you’re from one of those weird countries that prefers
mm-dd-yyyy then that’s what you should see.
It turns out that even when you try to make something terrible, so long as you’re building on top of the solid principles the web gives you for free, you can accidentally end up with something not-so-bad. Who knew?
I recreated a 16-year old interactive ad. Experience it here. Get the source code here. Or keep reading for the full story.
Back in 2005 I reblogged a Flash-based interactive advert I’d discovered via del.icio,us. And if that sentence wasn’t early-naughties enough for you, buckle up…

At the end of 2004, Unilever brand Axe (Lynx here in the UK) continued their strategy of marketing their deodorant as magically transforming young men into hyper-attractive sex gods. This is, of course, an endless battle, pitting increasingly sexually-charged advertisements against the fundamental experience of their product, which smells distinctly like locker rooms and school discos. To launch 2005’s new fragrance Feather, they teamed up with London-based design agency Dare Digital to create a game at domain AxeFeather.com (long since occupied by domain squatters).
In the game, the player’s mouse pointer becomes a feather which they can use to tickle an attractive young woman lying on a bed. The woman’s movements – which vary based on where she’s tickled – have been captured in digital video. This was aggressively compressed using the then-new H.263-ish Sorensen Spark codec to make a download just-about small enough to be tolerable for people still on dial-up Internet access (which was still almost as popular as broadband). The ad became a viral hit. I can’t tell you whether it paid for itself in sales, but it must have paid for itself in brand awareness: on Valentines Day 2005 it felt like it was all the Internet wanted to talk about.

I suspect its success also did wonders for the career of its creative consultant Olivier Rabenschlag, who left Dare a few years later, hopped around Silicon Valley for a bit, then landed himself a job as Head of Creative (now Chief Creative Officer) with Google. Kudos.
I told you about the site 16 years ago: why am I telling you again? Because this site, which made headlines at the time, is gone.
And not just a little bit gone, like a television ad no longer broadcast but which might still exist on YouTube somewhere (and here it is – you’re welcome for the earworm). The website went down in 2009, and because it was implemented in Flash the content was locked away in a compiled, proprietary format, which has ceased to be meaningfully usable on the modern web.

The ad was pioneering. Flash had only recently gained video support (this would be used the following year for the first version of YouTube), and it had so far been used mostly for non-interactive linear video. This ad was groundbreaking… but now it’s disappeared like so much other Flash work. And for all that Flash might have been bad for the web, it’s an important part of our digital history [recommended reading].

So on a whim… I decided to see if I could recreate the ad.
Call it lockdown fever if you like, because it’s certainly not the work of a sane mind to attempt to resurrect a 16-year-old Internet advertisement. But that’s what I did.
My plan: to reverse-engineer the digital assets (video, audio, cursor etc.) out of the original Flash file, and use them to construct a moderately-faithful recreation of the ad, suitable for use on the modern web. My version must:
.flv support to mobile devices…
Let’s get started.
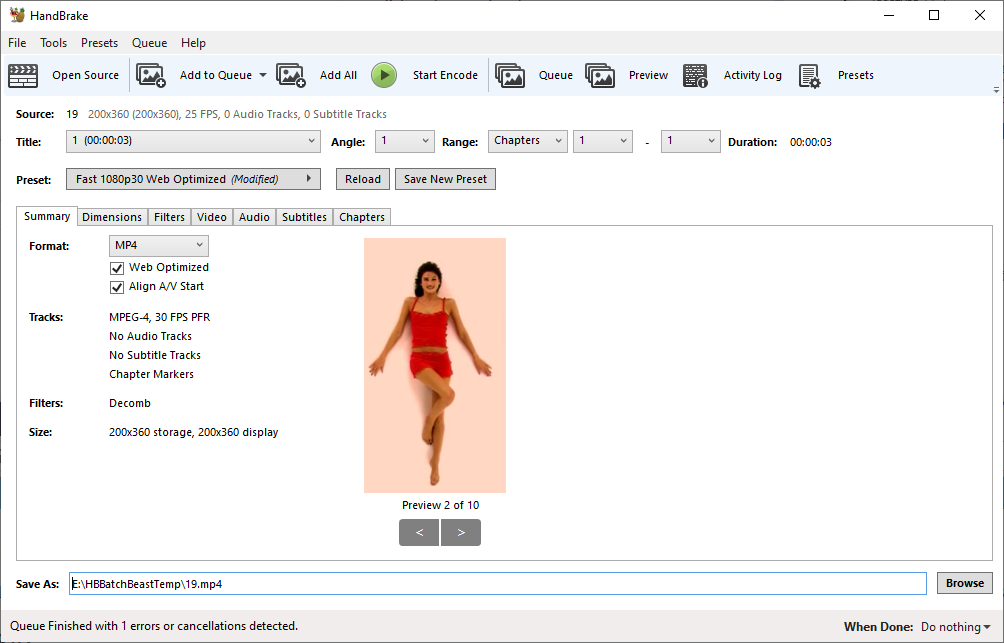
I grabbed the compiled .swf file from archive.org and ran it through
SWFExtract and an online decompiler: neither was individually able to extract
all of the assets, but together they gave me a full set. I ran the .flv files through Handbrake to get myself a set of
.mp4 files instead.

Seeing that the extracted video files were clearly designed to be carefully-positioned on a static background, and not all in the exact same position, I decided to make my job easier by combining them all together, and including the background layer (the picture of the bed) as a single video. Integrating the background with the subject meant that I was able to use video editing software to tweak the position, which I imagined would be much easier than doing so in code. Combining all of the video clips into a single file provides compression benefits as well as making it easier to encourage a browser to precache the entire video to begin with.

The longest clip was a little over 6 seconds long, so I split my timeline into blocks of 7 seconds, padding each clip with a freeze-frame of its final image to make each exactly 7 seconds long. This meant that calculating the position in the finished video to which I wanted to jump was as simply as multiplying the (0-indexed) clip number by 7 and seeking to that position. The additional “frozen” frames acted as a safety buffer in case my JavaScript code was delayed by a few milliseconds in jumping to the “next” block.

An additional challenge was that in the original binary, the audio files were stored separately from the video clips… and slightly longer than them! A little experimentation revealed that the ends of each clip lined up, presumably something to do with how Flash preloads and synchronises media streams. Luckily for me, the audio clips were numbered such that they mostly mapped to the order in which the videos appeared.
Once I had a video file suitable for use on the web (you can watch the entire clip here, if you really want to), it was time to write some code.

The theory was simple: web page, video, loop the first seven seconds until you click on it, then animate the cursor (a feather) and jump to another seven-second block before jumping back or, in some cases, on to a completely new seven second block. Simple!
Of course, any serious web development is always a little more complex than you first anticipate.

.swf 34 distinct animated clips, which I numbered 0 through 33. 6 and 30 appeared to be duplicates of others. 0 and 33 are each two “idling” states
from which interaction can lead to other states. Note that my interpretation of the order and relationship of animation sequences differs from the original.
For example: nowadays, putting a video on a web page is as easy as a <video> tag. But, in an effort to prevent background web pages from annoying you with unexpected
audio, modern browsers won’t let a video play sound unless user interaction is the reason that the video starts playing (or unmutes, if it was playing-but-muted to
begin with). Broadly-speaking, that means that a definitive user action like a “click” event has to be in the call stack when your code makes the video play/unmute.
But changing the .currentTime of a video to force it into a loop: that’s fine! So I set the video to autoplay muted on page load, with a script to make it loop
within its first seven-second block. The actress doesn’t make any sound in block 0 (position A) anyway; so I can unmute the video when the user interacts with a hotspot.
For best performance, I used window.requestAnimationFrame to synchronise my non-interactive events (video loops, virtual cursor repositioning). This posed a slight problem
in that animationframes wouldn’t be triggered if the tab was moved to the background: the video would play through each seven-second block and into the next! Fortunately the
visibilitychange event came to the rescue and I was able to pause the video when it wasn’t being actively watched.
I originally hoped to use the cursor: CSS directive to make the “feather” cursor, but there’d be no nice way to
animate it. Comet Cursor may have been able to use animated GIFs
as cursors back in 1997 (when it wasn’t busy selling all your personal information to advertisers, back when that kind of thing used to attract widespread controversy), but modern
browsers don’t… presumably because it would be super annoying. They also don’t all respect cursor: none, so I used the old trick of using cursor: url(null.png),
none (where null.png is an almost-entirely transparent 1×1 pixel image) to hide the original cursor, then position an image dynamically. I
usegetBoundingClientRect() to allow the video to resize dynamically in CSS and convert coordinates on it represented
as percentages into actual pixel values and vice-versa: this allows it to react responsively to any screen size without breakpoints or excessive code.
Once I’d gone that far I was able to drop the GIF idea entirely and used a CSS animation for the “tickling” motion.

I added a transparent <canvas> element on top of the <video> on which the hit areas are dynamically drawn to help me test the “hotspots” and tweak
their position. I briefly considered implementing a visual tool to help me draw the hotspots, but figured it wasn’t quite worth the time it would take.
As I implemented more and more of the game, I remembered one feature from the original that I’d missed: the “blowaway”. If you trigger block 31 – a result of tickling the woman’s nose – she’ll blow your cursor off the screen. It’s particularly fun because it subverts the player’s expectations of their user interface: once you’ve got past the surprise of your cursor being a feather, you quickly settle in to it moving like a regular cursor… but then control’s stolen from you and the cursor vanishes! (Well I thought it was cool… 16 years ago.)

So yeah: that was my project this weekend.
I can’t even begin to explain why anybody would do this. But I did it. If you haven’t already: go have a play. And if you’re interested in how it works, the source code’s free for you to explore.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
I’ve been changing my relationship to being online.
Some of it is keeping in touch with friends who are fascinated by the same sorts of hybrid creations I am. Friends who build things. Friends in different professional communities. Paying attention when they mention some new discovery or avenue of interest.
Some of it is using an RSS reader to change the cadence and depth of my consumption—pulling away from the quick-hit likes of social media in favor of a space where I can run my thoughts to their logical conclusion (and then sit on them long enough to consider whether or not they’re true).
…
I wish I could get more people to see the value in the “slow Web”. The participatory Web. The creative Web. The personalised Web.
When you use an app to browse a “stream” in most social media, you’re seeing a list of posts curated to keep you watching, keep you seeing adverts, keep you on the app so that as much personal data as possible can be leeched from your behaviour. If it feels satisfying and especially if it feels addictive, the social network has done its job, but don’t be fooled: its job is not to improve social connections – it’s job is to keep you from doing anything else.
You don’t have to use the Web this way. You can subscribe to the content creators and topics that actually interest you. You can get that content on basically any device or medium you like, or across a mixture: want notifications by email? Slack? IRC? Discord? In a browser? In an app? As-it-happens or digests? You can filter for what interests you most at any given moment, save content for later, and resharing is supported thanks to an old-school invention called a “URL“. And you’ll see fewer ads and experience less misuse of your behavioural data.
Sure, there’s a learning curve. But it’s worth it. I wish I could get more people to see that.
I’m happy to see that Lucy Belwood does.
{kind=link}