Google has made much of their Accelerated Mobile Pages project as a solution to bloated websites and frustrated users. But could AMP actually be
bad news for the web, bad news for news, and part of a trend of news distribution that is bad for society in general?
I didn’t start out as strongly anti-AMP. Providing tools for making websites faster is always great, as is supporting users in developing countries with lighter-weight pages that
don’t cost them a month’s wages. It’s totally true that today webpages are in a pretty sorry state…
Together with a friend I recently built Dropshare Cloud. We offer online storage for the file and screenshot sharing app Dropshare for macOS/iOS. After trying out Django for getting started (we both had some experience using Django) I
decided to rewrite the codebase in Rails. My past experience developing in Rails made the process quick — and boring…
In common slang, FTW is an acronym “for the win” and while that’s appropriate here, I think a better expansion is “for the world.”
We’re pleased to announce that we have sponsored the development of TLS 1.3 in OpenSSL. As it is one of the most widely-used TLS libraries, it is a good investment for the overall
health and security of the Internet, so that everyone is able to deploy TLS 1.3 as soon as possible…
All secure crypto on the Internet assumes that the DNS lookup from names to IP addresses are insecure. Securing those DNS lookups therefore enables no meaningful security. DNSSEC does
make some attacks against insecure sites harder. But it doesn’t make those attacks infeasible, so sites still need to adopt secure transports like TLS. With TLS properly
configured, DNSSEC adds nothing…
That’s it – I’m calling it – HTTPS adoption has now reached the moment of critical mass where it’s gathering enough
momentum that it will very shortly become “the norm” rather than the exception it so frequently was in the past. In just the last few months, there’s been some really significant
things happen that have caused me to make this call, here’s why I think we’re now at that tipping point…
As you may know, I’ve lately found an excuse to play with some new web technologies, and I’ve also taken the opportunity to try to gain a deeper
understanding of some less bleeding-edge technologies that I think have some interesting potential. And so it was that, while I was staffing the Three Rings stall at last week’s NCVO conference, I made use of the
time that the conference delegates were all off listening to a presentation to throw together a tech demo I call Steer!
A player uses their mobile phone to steer a car on a desktop computer, using nothing more than a web browser.
As you can see from the GIF above, Steer! is a driving game. The track and your car are displayed in a web browser on a large screen,
for example a desktop or laptop computer, television, or tablet, and your mobile phone is used to steer the car by tilting it to swerve around a gradually-narrowing weaving road. It’s
pretty fun, but what really makes it interesting to me is the combination of moderately-new technologies I’ve woven together to make it possible, specifically:
The Device Orientation API, which enables a web application to detect the angle at which
you’re holding your mobile phone
Websockets as a mechanism to send that data in near-real-time from the phone to the browser, via a web server: for the
fastest, laziest possible development, I used Firebase for this, but I’m aware that I could probably get better performance by running a
local server on the LAN shared by both devices
The desktop browser does all of the real work: it takes the orientation of the device and uses that, and the car’s current speed, to determine how it’s position changes over the time
that’s elapsed since the screen was last refreshed: we’re aiming for 60 frames a second, of course, but we don’t want the car to travel slower when the game is played on a
slower computer, so we use requestAnimationFrame to get the fastest rate possible and calculate the time between renderings to work out how much of a change has
occurred this ‘tick’. We leave the car’s sprite close to the bottom of the screen at all times but change how much it rotates from side to side, and we use it’s rotated to decide how
much of its motion is lateral versus the amount that’s “along the track”. The latter value determines how much track we move down the screen “behind” it.
The track is generated very simply by the addition of three sine waves of different offset and frequency – a form of very basic procedural generation. Despite the predictability of mathematical curves, this results in a moderately organic-feeling road
because the player only sees a fraction of the resulting curve at any given time: the illustration below shows how these three curves combine to make the resulting road. The difficulty
is ramped up the further the player has travelled by increasing the amplitude of the resulting wave (i.e. making the curves gradually more-agressive) and by making the road itself
gradually narrower. The same mathematics are used to determine whether the car is mostly on the tarmac or mostly on the grass and adjust its maximum speed accordingly.
In order to help provide a visual sense of the player’s speed, I added dashed lines down the road (dividing it into three lanes to begin with and two later on) which zip past the car
and provide a sense of acceleration, deceleration, overall speed, and the impact of turning ‘sideways’ (which of course reduces the forward momentum to nothing).
This isn’t meant to be a finished game: it’s an experimental prototype to help explore some technologies that I’d not had time to look seriously at before now. However, you’re welcome
to take a copy – it’s all open source – and adapt or expand it. Particular ways in which it’d be fun to improve it might include:
Allowing the player more control, e.g. over their accelerator and brakes
Adding hazards (trees, lamp posts, and others cars) which must be avoided
Adding bonuses like speed boosts
Making it challenging, e.g. giving time limits to get through checkpoints
Day and night cycles (with headlights!)
Multiplayer capability, like a real race?
Smarter handling of multiple simultaneous users: right now they’d share control of the car (which is the major reason I haven’t given you a live online version to play
with and you have to download it yourself!), but it’d be better if they could “queue” until it was their turn, or else each play in their own split-screen view or something
Improving the graphics with textures
Increasing the entropy of the curves used to generate the road, and perhaps adding pre-scripted scenery or points of interest on a mathematically-different procedural generation
algorithm
Switching to a local LAN websocket server, allowing better performance than the dog-leg via Firebase
Greater compatibility: I haven’t tried it on an iPhone, but I gather than iOS devices report their orientation differently from Android ones… and I’ve done nothing to try to make
Steer! handle more-unusual screen sizes and shapes
Anything else? (Don’t expect me to have time to enhance it, though: but if you do so, I’d love to hear about it!)
Maybe it’s because I was at Render Conf at the end of last month or perhaps it’s because Three
Rings DevCamp – which always gets me inspired – was earlier this month, but I’ve been particularly excited lately to get the chance to play
with some of the more “cutting edge” (or at least, relatively-new) web technologies that are appearing on the horizon. It feels like the Web is having a bit of a renaissance of
development, spearheaded by the fact that it’s no longer Microsoft that are holding development back (but increasingly Apple) and, perhaps for the first time, the fact that the W3C are
churning out standards “ahead” of where the browser vendors are managing to implement technical features, rather than simply reflecting what’s already happening in the world.
Ben Foxall at Render Conf 2017 discusses the accompanying JSOxford Hackathon. Hey, who’s that near the top-right?
It seems to me that HTML5 may well be the final version of HTML. Rather than making grand new releases to the core technology, we’re now – at last! – in a position where it’s possible
to iteratively add new techniques in a resilient, progressive manner. We don’t need “HTML6” to deliver us any particular new feature, because the modern web is more-modular and
is capable of having additional features bolted on. We’re in a world where browser detection has been replaced
with feature detection, to the extent that you can even do non-hacky feature detection in pure CSS, now, and
this (thanks to the nature of the Web as a loosely-coupled, resilient platform) means that it’s genuinely possible to progressively-enhance
content and get on board with each hot new technology that comes along, if you want, while still delivering content to users on older browsers.
And that’s the dream! A web of progressive-enhancement stays true to Sir Tim’s dream of universal interoperability while still moving forward technologically. I’ve no doubt
that there’ll always be people who want to break the Web – even Google do it, sometimes – with single-page Javascript-only web apps, “app
shell” websites, mobile-only or desktop-only experiences and “apps” that really ought to have been websites (and perhaps PWAs) to begin with… but the fact that the tools to make a genuinely “progressively-enhanced” web, and those tools are
mainstream, is a big deal. If you don’t think we’re at that point yet, I invite you to watch Rachel Andrews‘ fantastic presentation,
“Start Using CSS Grid Layout Today”.
Three Rings’ developers hard at work at this year’s DevCamp.
Some of the things I’ve been playing with recently include:
Intersection Observers
Only really supported in Chrome, but there’s a great polyfill, the Intersection Observer API is one of those technologies that make you say “why didn’t we have that
already?” It’s very simple: all an Intersection Observer does is to provide event hooks for target objects entering or leaving the viewport, without resorting to polling or
hacky code on scroll event captures.
What’s it for? Well the single most-obvious use case is lazy-loading images, a-la Medium or Google
Image Search: delivering users a placeholder image or a low-resolution copy until they scroll far enough for the image to come into view (or almost into view) and then
downloading the full-resolution version and dynamically replacing it. My first foray into Intersection Observers was to take Medium’s approach and then improve it with a Service Worker in order to make it behave nicely even if the user’s Internet connection was unreliable, but
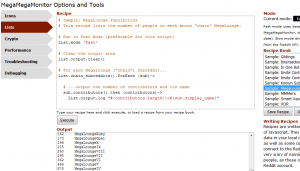
I’ve since applied it to my Reddit browser plugin MegaMegaMonitor: rather than hammering the browser with Javascript the plugin now waits
until relevant content enters the viewport before performing resource-intensive tasks.
Web Workers
I’d briefly played with Service Workers before and indeed we’re adding a Service Worker to the next
version of Three Rings, which, in conjunction with a manifest.json and the service’s
(ongoing) delivery over HTTPS (over H2, where available, since last year), technically makes it a Progressive Web App… and I’ve been
looking for opportunities to make use of Service Workers elsewhere in my work, too… but my first dive in to Web Workers was in introducing one to the next upcoming version of MegaMegaMonitor.
MegaMegaMonitor’s processor-intensive “Lists” feature sees the most benefit from Web Workers
Web Workers add true multithreading to Javascript, and in the case of MegaMegaMonitor this means the possibility of pushing the more-intensive work that the plugin has to do out of the
main thread and into the background, allowing the user to enjoy an uninterrupted browsing experience while the heavy-lifting goes on in the background. Because I don’t control the
domain on which this Web Worker runs (it’s reddit.com, of course!), I’ve also had the opportunity to play with Blobs,
which provided a convenient way for me to inject Worker code onto somebody else’s website from within a userscript. This has also lead me to the discovery that it ought to be possible
to implement userscripts that inject Service Workers onto websites, which could be used to mashup additional functionality into websites far in advance of that which is typically
possible with a userscript… more on that if I get around to implementing such a thing.
Fetch
The final of the new technologies I’ve been playing with this month is the Fetch API. I’m not pulling any punches
when I say that the Fetch API is exactly what XMLHttpRequests should have been from the very beginning. Understanding them properly has finally given me the confidence to stop
using jQuery for the one thing for which I always seemed to have had to depend on it for – that is, simplifying Ajax requests! I mean, look at
this elegant code:
Whether or not you’re a fan of Javascript, you’ve got to admit that that’s infinitely more readable than XMLHttpRequest hackery (at least, without the help of a heavyweight library like
jQuery).
Other things I’ve been up to include Laser Duck Hunt, but that’s another story.
So that’s some of the stuff I’ve been playing with lately: Intersection Observers, Web Workers, Blobs, and the Fetch API. And I feel all full of optimism on behalf of the Web.
Chrome comes with built-in developer tools. This comes with a wide variety of features, such as Elements, Network, and Security. Today, we’ll focus 100% on its JavaScript console.
When I started coding, I only used the JavaScript console for logging values like responses from the server, or the value of variables. But over time, and with the help of tutorials,
I discovered that the console can do way more than I ever imagined…
In the beginning there was NCSA Mosaic, and Mosaic called itself NCSA_Mosaic/2.0 (Windows 3.1), and Mosaic displayed pictures along with text, and there was much rejoicing…
Have you ever wondered why every major web browser identifies itself as “Mozilla”? Wonder no longer…
A cross-site scripting vulnerability (shortened to XSS, because
CSS already means other things) occurs when a website can be tricked into showing a visitor unsafe content that came from another site
visitor. Typically when we talk about an XSS attack, we’re talking about tricking a website into sending Javascript code to the user: that Javascript code can then be used to steal
cookies and credentials, vandalise content, and more.
Good web developers know to sanitise input – making anything given to their pages by a user safe before ever displaying it on a page – but even the best can forget quite how many things
really are “user input”.
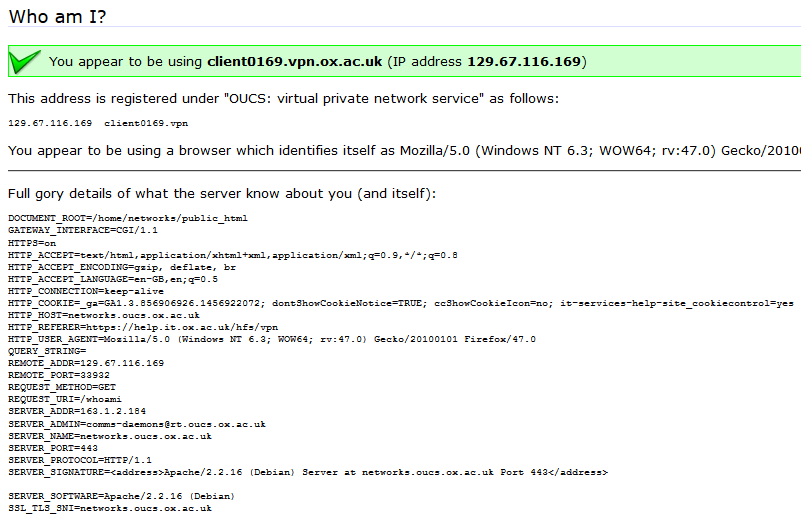
This page outputs a variety of your inputs right back at you.
Recently, I reported a vulnerability in a the University of Oxford’s IT Services‘ web pages that’s a great example of this. The page (which
isn’t accessible from the public Internet, and now fixed) is designed to help network users diagnose problems. When you connect to it, it tells you a lot of information about your
connection: what browser you’re using, your reverse DNS lookup and IP address, etc.. The developer clearly understood that XSS was a risk, because if you pass a query string to the
page, it’s escaped before it’s returned back to you. But unfortunately, the developer didn’t consider the fact that virtually anything given to you by the browser can’t be
trusted.
To demonstrate this vulnerability, I had the option of writing Perl or Javascript. For some reason, I chose Perl.
In this case, I noticed that the page would output any cookies that you had from the .ox.ac.uk domain, without escaping them. .ox.ac.uk cookies can be manipulated by anybody
who has access to write pages on the domain, which – thanks to the users.ox.ac.uk webspace – means any staff or students at the University (or, in
an escalation attack, anybody’s who’s already compromised the account of any staff member or student). The attacker can then set up a web page that sets up such a “poisoned” cookie and
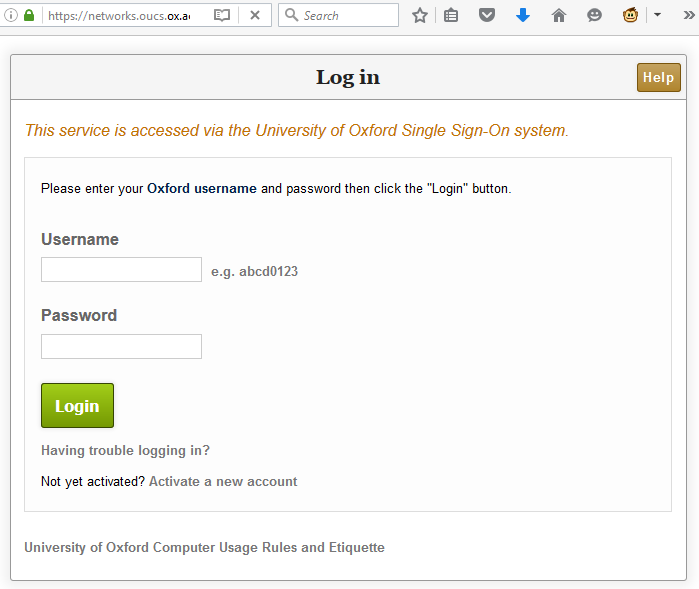
then redirects the user to the affected page and from there, do whatever they want. In my case, I experimented with showing a fake single sign-on login page, almost indistinguishable
from the real thing (it even has a legitimate-looking .ox.ac.uk domain name served over a HTTPS connection, padlock and all). At this stage, a real attacker could use a spear phishing scam to trick users into clicking a link to their page and start stealing credentials.
The padlock, the HTTPS url, and the convincing form make this page look legitimate. But it’s actually spoofed.
I’m sure that I didn’t need to explain why XSS vulnerabilities are dangerous. But I wanted to remind you all that truly anything that comes from the user’s web browser, even if
you think that you probably put it there yourself, can’t be trusted. When you’re defending against XSS attacks, your aim isn’t just to sanitise obvious user input like GET and POST
parameters but also anything that comes from a browser header including cookies and referer headers, especially if your domain name carries websites managed by many different people. In
an ideal world, Content Security Policy would mitigate all these kinds of attacks: but in our real world – sanitise
those inputs!
I am increasingly of the opinion that the general software engineering adage “Don’t Repeat Yourself” does not always apply to web development. Also, I found that web development
classes in CS academia are not very realistic. These two problems turn out to have the same root cause: a lack of appreciation of what browsers do…
In 2007 I wrote about using PNGout to produce amazingly small PNG images. I still refer to this topic
frequently, as seven years later, the average PNG I encounter on the Internet is very unlikely to be optimized.
It’s common for a Ruby developer to describe themselves as a Rails developer. It’s also common for someone’s entire Ruby experience to be through Rails. Rails began in 2003 by David
Heinemeier Hansson, quickly becoming the most popular web framework and also serving as an introduction to Ruby for many developers.
Rails is great. I use it every day for my job, it was my introduction to Ruby, and this is the most fun I’ve ever had as a developer. That being said, there are a number of great
framework options out there that aren’t Rails.
This article intends to highlight the differences between Cuba, Sinatra, Padrino, Lotus, and how they compare to or differ from Rails. Let’s have a look at some Non-Rails Frameworks
in Ruby.