I’ve been playing with a Flic Hub LR and some Flic 2 buttons. They’re “smart home” buttons, but for me they’ve got a killer selling point: rather than
locking you in to any particular cloud provider (although you can do this if you want), you can directly program the hub. This means you can produce smart integrations
that run completely within the walls of your house.
Here’s some things I’ve been building:
Prerequisite: Flic Hub to Huginn connection
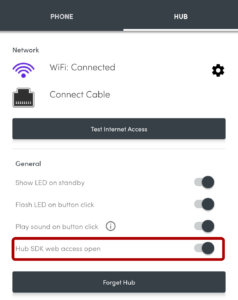
Step 1. Enable SDK access. Check!
I run a Huginn instance on our household NAS. If
you’ve not come across it before, Huginn is a bit like an open-source IFTTT: it’s got a steep
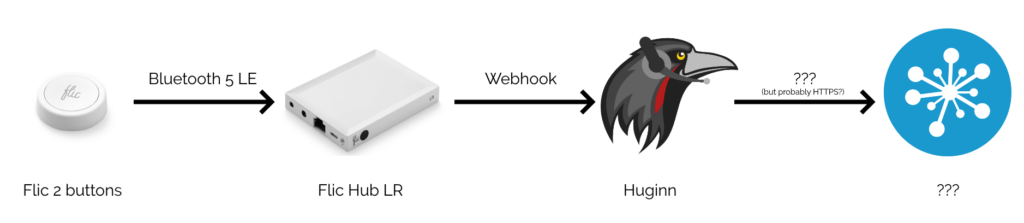
learning curve, but it’s incredibly powerful for automation tasks. The first step, then, was to set up my Flic Hub LR to talk to Huginn.
Checking ‘Restart after crash’ seems to help ensure that the script re-launches after e.g. a power cut. Need
the script?
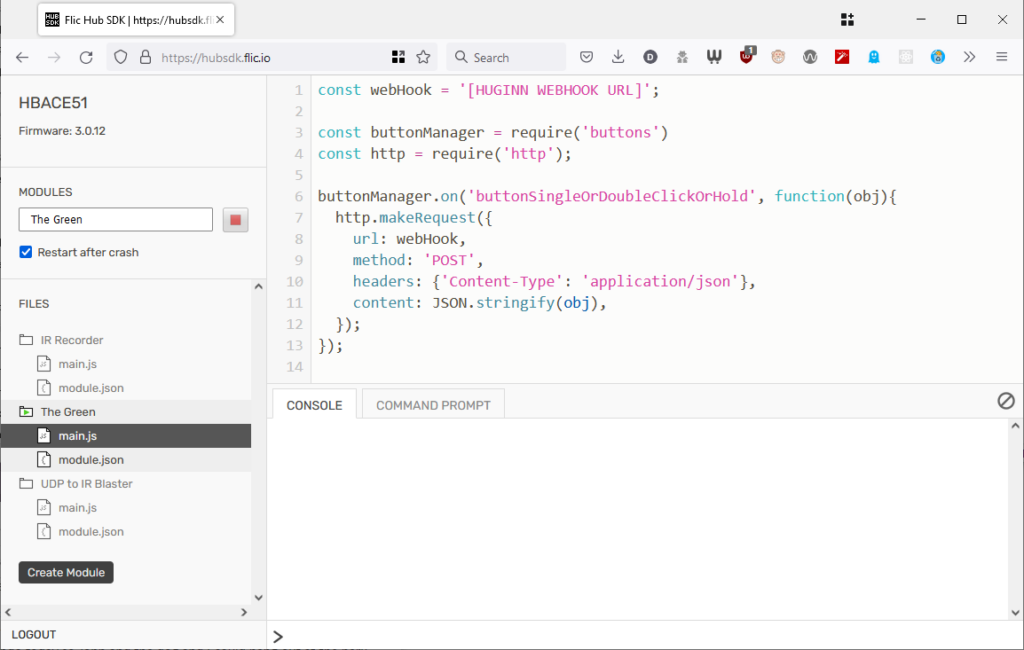
This was pretty simple: all I had to do was switch on “Hub SDK web access open” for the hub using the Flic app,
then use the the web SDK to add this script to the hub. Now whenever a
button was clicked, double-clicked, or held down, my Huginn installation would receive a webhook ping.
Depending on what you have Huginn do “next”, this kind of set-up works completely independently of “the cloud”. (Your raven can fly into the clouds if you really want.)
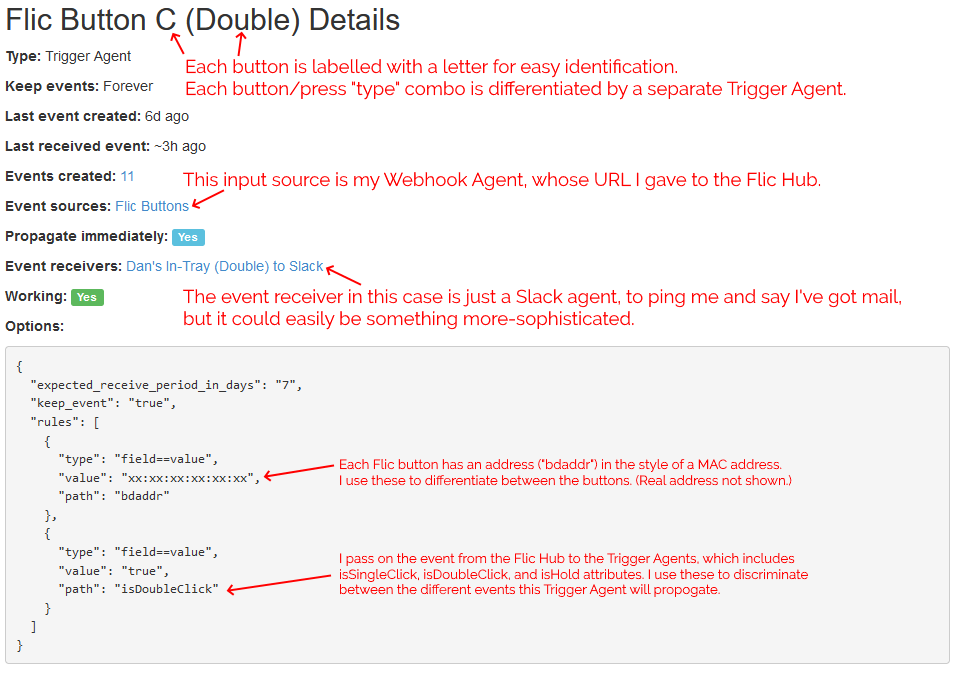
For convenience, I have all button-presses sent to the same Webhook, and use Trigger Agents to differentiate between buttons and press-types. This means I can re-use
functionality within Huginn, e.g. having both a button press and some other input trigger a particular action.
You’ve Got Mail!
By our front door, we have “in trays” for each of Ruth, JTA and I, as well as one for the
bits of Three Rings‘ post that come to our house. Sometimes post sits in the in-trays for a long time because people don’t think to check
them, or don’t know that something new’s been added.
I configured Huginn with a Trigger Agent to receive events from my webhook and filter down to just single clicks on specific buttons. The events emitted by these triggers are used to
notify in-tray owners.
Once you’ve made three events for your first button, you can copy-paste from then on.
In my case, I’ve got pings being sent to mail recipients via Slack, but I could equally well be integrating to other (or additional) endpoints or even
performing some conditional logic: e.g. if it’s during normal waking hours, send a Pushbullet notification to the recipient’s phone, otherwise
send a message to an Arduino to turn on an LED strip along the top of the recipient’s in-tray.
I’m keeping it simple for now. I track three kinds of events (click = “post in your in-tray”, double-click = “I’ve cleared my in-tray”, hold = “parcel wouldn’t fit in your in-tray: look
elsewhere for it”) and don’t do anything smarter than send notifications. But I think it’d be interesting to e.g. have a counter running so I could get a daily reminder (“There
are 4 items in your in-tray.”) if I don’t touch them for a while, or something?
Remember the Milk!
Following the same principle, and with the hope that the Flic buttons are weatherproof enough to work in a covered outdoor area, I’ve fitted one… to the top of the box our milkman
delivers our milk into!
The handle on the box was almost exactly the right size to stick a Flic button to! But it wasn’t flat enough until I took a file to it.
Most mornings, our milkman arrives by 7am, three times a week. But some mornings he’s later – sometimes as late as 10:30am, in extreme cases. If he comes during the school run the milk
often gets forgotten until much later in the day, and with the current weather that puts it at risk of spoiling. Ironically, the box we use to help keep the milk cooler for longer on
the doorstep works against us because it makes the freshly-delivered bottles less-visible.
Now that I had the technical infrastructure already in place, honestly the hardest part of this project was matching the font used in Milk &
More‘s logo.
I’m yet to see if the milkman will play along and press the button when he drops off the milk, but if he does: we’re set! A second possible bonus is that the kids love doing anything
that allows them to press a button at the end of it, so I’m optimistic they’ll be more-willing to add “bring in the milk” to their chore lists if they get to double-click the button to
say it’s been done!
Future Plans
I’m still playing with ideas for the next round of buttons. Could I set something up to streamline my work status, so my colleagues know when I’m not to be disturbed, away from my desk,
or similar? Is there anything I can do to simplify online tabletop roleplaying games, e.g. by giving myself a desktop “next combat turn” button?
My Flic Hub is mounted behind a bookshelf in the living room, with only its infrared transceiver exposed. 20p for scale: we don’t keep a 20p piece stuck to the side of the bookcase
all the time.
I’m quite excited by the fact that the Flic Hub can interact with an infrared transceiver, allowing it to control televisions and similar devices: I’d love to be able to use the volume
controls on our media centre PC’s keyboard to control our TV’s soundbar: and because the Flic Hub can listen for UDP packets, I’m hopeful that something as simple as AutoHotkey can make this possible.
Or perhaps I could make a “universal remote” for our house, accessible as a mobile web app on our internal Intranet, for those occasions when you can’t even be bothered to stand up to
pick up the remote from the other sofa. Or something that switched the TV back to the media centre’s AV input when consoles were powered-down, detected by their network activity? (Right
now the TV automatically switches to the consoles when they’re powered-on, but not back again afterwards, and it bugs me!)
It feels like the only limit with these buttons is my imagination, and that’s awesome.
Almost nerdsniped myself when I discovered several #WordPress plugins that didn’t quite
do what I needed. Considered writing an overarching one to “solve” the problem. Then I remembered @xkcdcomic
927…
Without even a touch of the steering wheel, the electric car reverses autonomously into the recharging station
I won’t be plugging it in though, instead, the battery will be swapped for a fresh one, at this facility in Norway belonging to Chinese electric carmaker, Nio.
The technology is already widespread in China, but the new Power Swap Station, just south of Oslo, is Europe’s first.
…
This is what I’ve been saying for years would be a better strategy for electric vehicles. Instead of charging them (the time needed to charge is their single biggest weakness compared
to fuelled vehicles) we should be doing battery swaps. A decade or two ago I spoke hopefully for some kind of standardised connector and removal interface, probably below the vehicle,
through which battery cells could be swapped-out by robots operating in a pit. Recovered batteries could be recharged and reconditioned by the robots at their own pace. People could
still charge their cars in a plug-in manner at their homes or elsewhere.
You’d pay for the difference in charge between the old and replacement battery, plus a service charge for being part of the battery-swap network, and you’d be set. Car manufacturers
could standardise on battery designs, much like the shipping industry long-ago standardised on container dimensions and whatnot, to take advantage of compatibility with the wider
network.
Rather than having different sizes of battery, vehicles could be differentiated by the number of serial battery units installed. A lorry might need four or five units; a large car two;
a small car one, etc. If the interface is standardised then all the robots need to be able to do is install and remove them, however many there are.
This is far from an unprecedented concept: the centuries-old idea of stagecoaches (and, later, mail coaches) used the same idea, but with the horses being changed at coaching
inns rather. Did you know that the “stage” in stagecoach refers to the fact that their journey would be broken into stages by these quick stops?
Anyway: I dismayed a little when I saw every EV manufacturer come up with their own battery standards, co=operating only as far as the
plug-in charging interfaces (and then, only gradually and not completely!). But I’m given fresh hope by this discovery that China’s trying to make it work, and Nio‘s movement in Norway is exciting too. Maybe we’ll get there someday.
Ruth wrote an excellent post this month entitled Wonder Syndrome.
It attempts to reframe imposter syndrome (which is strongly, perhaps disproportionately, present in tech fields) as a
positive indicator that there’s still more to learn:
Being aware of the boundaries of our knowledge doesn’t make us imposters, it makes us explorers. I’m going to start calling mine “Wonder Syndrome”, and allowing myself to be awed by
how much I still have to learn, and then focusing in and carrying on with what I’m doing because although I may not reach the stars, I’ve come a long way up the mountain. I can learn
these things, I can solve these problems, and I will.
I don’t recall exactly what I’m advising a fellow Three Rings developer to do, here, but I don’t think he’s happy about it.
I just spent a week at a Three Rings DCamp (a “hackathon”, kinda), and for the umpteenth time had the experience of feeling like
everybody thinks I know everything, while on the inside I still feel like I’m still guessing a third of the time (and on StackOverflow for another third!).
The same’s true at work: people ask me questions about things that I suppose, objectively, are my “specialist subjects” – web standards, application security, progressive enhancement,
VAT for some reason – and even where I’m able to help, I often get that nagging feeling like
there must be somebody better than me they could have gone to?
You’ve probably seen diagrams like this before. After all: I’m not smart or talented enough to invent anything like this and I don’t know why you’d listen to anything I have to say on
the subject anyway. 😂
You might assume that I love Ruth’s post principally because it plays to my vanity. The post describes two kinds of knowledgeable developers, who are differentiated primarily by their
attitude to learning. One is satisfied with the niche they’ve carved out for themselves and the status that comes with it and are content to rest on their laurels; the other is driven
to keep pushing and learning more and always hungry for the next opportunity to grow. And the latter category… Ruth’s named after me.
Wait, what if I’m not‽ Have I been faking it this entire blog post?
Bnd while I love the post, my gut feeling to being named after such an ideal actually makes me slightly uncomfortable. The specific sentence that gets me is (emphasis mine):
Dans have no interest in being better than other people, they just want to know more than they did yesterday.
I wish that was me, but I’m actually moderately-strongly motivated by a desire to feel like I’m the smartest person in the room! I’m getting this urge under control (I’m pretty
sure I was intolerable as a child and have been improving by instalments since then!). Firstly, because it’s an antisocial pattern to foster, but also because it limits my ability to
learn new things to have to go through the awkward, mistake-filled “I’m a complete amateur at this!” phase. But even as I work on this I still get that niggling urge, more often than
I’d like, to “show off”.
Of course, it could well be that what I’m doing right now is catastrophising. I’m taking a nice thing somebody’s said about me, picking the one part of it that I find hardest to feel
represents me, and deciding that I must be a fraud. Soo… imposter syndrome, I guess. Damn.
Or to put it a better way: Wonder Syndrome. I guess this is another area for self-improvement.
(I’m definitely adopting Wonder Syndrome into my vocabulary, as an exercise in mitigating imposter syndrome. If you’ve not read Ruth’s post in full, you should go and do that next.)
A love a good Jackbox Game. There’s nothing quite like sitting around the living room playing Drawful, Champ’d Up, Job
Job, Trivia MurderParty, or Patently Stupid. But nowadays getting together in the same place isn’t as easy as it used to be, and as often as not I find
my Jackbox gaming with friends or coworkers takes place over Zoom, Around, Google Meet or Discord.
There’s lots of guides to doing this – even an official one! – but they all miss a
few pro tips that I think can turn a good party into a great party. Get all of this set up before your guests are due to arrive to make yourself look like a super-prepared
digital party master.
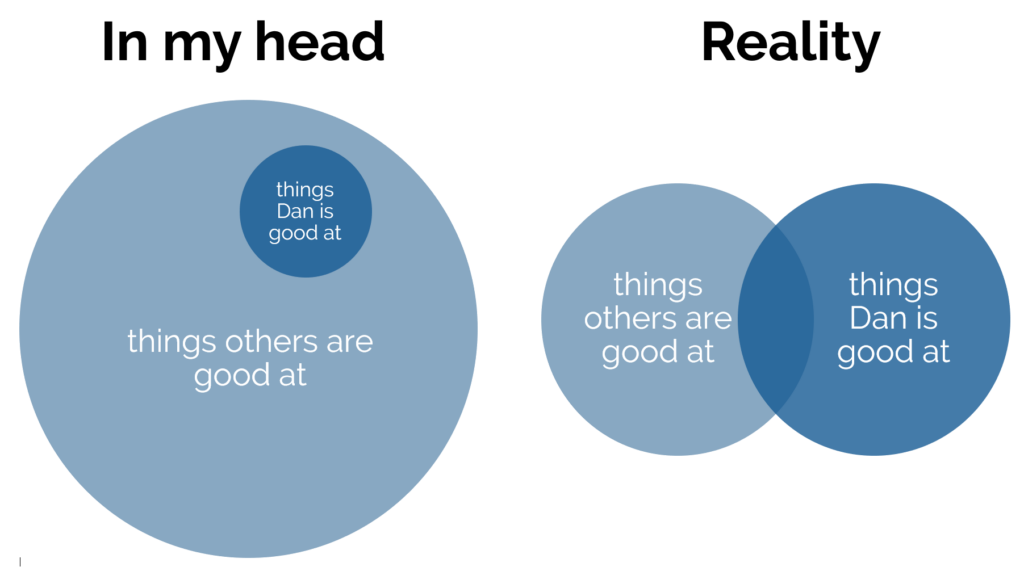
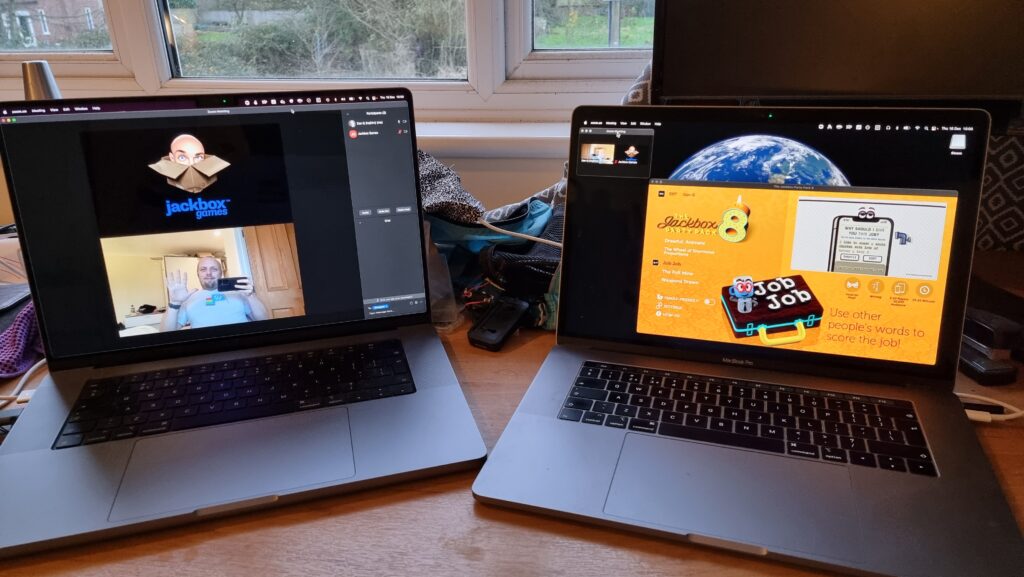
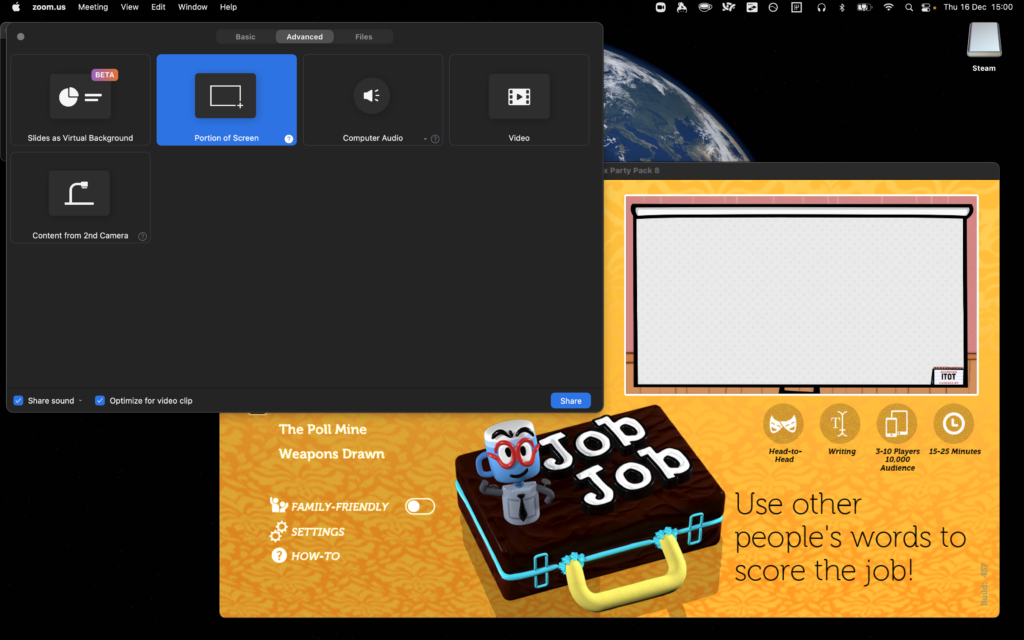
1. Use two computers!
You can use more than two, but two should be considered the minimum for the host.
Using one computer for your video call and a second one to host the game (in addition to the device you’re using to play the games, which could be your phone) is really helpful
for several reasons:
You can keep your video chat full-screen without the game window getting in the way, letting you spend more time focussed on your friends.
Your view of the main screen can be through the same screen-share that everybody else sees, helping you diagnose problems. It also means you experience similar video lag to
everybody else, keeping things fair!
You can shunt the second computer into a breakout room, giving your guests the freedom to hop in and out of a “social” space and a “gaming” space at will. (You can even set up
further computers and have multiple different “game rooms” running at the same time!)
2. Check the volume
Plugging an adapter into the headphone port tricks the computer into thinking some headphones are plugged in without actually needing the headphones quietly buzzing away on your desk.
Connect some headphones to the computer that’s running the game (or set up a virtual audio output device if you’re feeling more technical). This means you can still have the game
play sounds and transmit them over Zoom, but you’ll only hear the sounds that come through the screen share, not the sounds that come through the second computer too.
That’s helpful, because (a) it means you don’t get feedback or have to put up with an echo at your end, and (b) it means you’ll be hearing the game exactly the same as your guests hear
it, allowing you to easily tweak the volume to a level that allows for conversation over it.
3. Optimise the game settings
Jackbox games were designed first and foremost for sofa gaming, and playing with friends over the Internet benefits from a couple of changes to the default settings.
Sometimes the settings can be found in the main menu of a party pack, and sometimes they’re buried in the game itself, so do your research and know your way around before your party
starts.
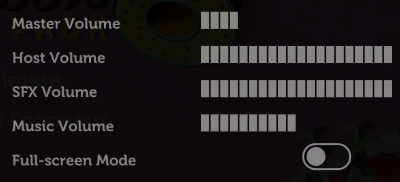
Turn the volume down, especially the volume of the music, so you can have a conversation over the game. I’d also recommend disabling Full-screen Mode: this reduces the resolution of the
game, meaning there’s less data for your video-conferencing software to stream, and makes it easier to set up screen sharing without switching back and forth between your applications
(see below).
Turning on the Motion Sensitivity or Reduce Background Animations option if your game has it means there’ll be less movement in the background of the game. This can really help with the
video compression used in videoconferencing software, meaning players on lower-speed connections are less-likely to experience lag or “blockiness” in busy scenes.
It’s worth considering turning Subtitles on so that guests can work out what word they missed (which for the trivia games can be a big deal). Depending on your group, Extended Timers is
worth considering too: the lag introduced by videoconferencing can frustrate players who submit answers at the last second only to discover that – after transmission delays – they
missed the window! Extended Timers don’t solve that, but they do mean that such players are less-likely to end up waiting to the last second in the first place.
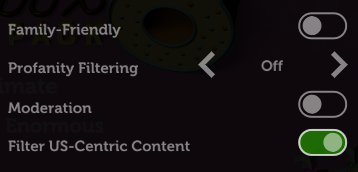
Finally: unless the vast majority or all of your guests are in the USA, you might like to flip the Filter US-Centric Content
switch so that you don’t get a bunch of people scratching their heads over a cultural reference that they just don’t get.
By the way, you can use your cursor keys and enter to operate Jackbox games menus, which is usually easier than fiddling with a mouse.
4. Optimise Zoom’s settings
A few quick tweaks to your settings can make all the difference to how great the game looks.
Whatever videoconferencing platform you’re using, the settings for screen sharing are usually broadly similar. I suggest:
Make sure you’ve ticked “Share sound” or a similar setting that broadcasts the game’s audio: in some games, this is crucial; in others, it’s nice-to-have. Use your other computer to
test how it sounds and tweak the volume accordingly.
Check “Optimize for video clip”; this hints to your videoconferencing software that all parts of the content could be moving at once so it can use the same kind of codec it would
for sending video of your face. The alternative assumes that most of the screen will stay static (because it’s the desktop, the background of your slides, or whatever), which works
better with a different kind of codec.
Use “Portion of Screen” sharing rather than selecting the application. This ensures that you can select just the parts of the application that have content in, and not “black bars”,
window chrome and the like, which looks more-professional as well as sending less data over the connection.
If your platform allows it, consider making the mouse cursor invisible in the shared content: this means that you won’t end up with an annoying cursor sitting in the middle of the
screen and getting in the way of text, and makes menu operation look slicker if you end up using the mouse instead of the keyboard for some reason.
Don’t forget to shut down any software that might “pop up” notifications: chat applications, your email client, etc.: the last thing you want is somebody to send you a naughty picture
over WhatsApp and the desktop client to show it to everybody else in your party!
As you might know if you were paying close attention in Summer 2019, I run a “URL
shortener” for my personal use. You may be familiar with public URL shorteners like TinyURL
and Bit.ly: my personal URL shortener is basically the same thing, except that only
I am able to make short-links with it. Compared to public ones, this means I’ve got a larger corpus of especially-short (e.g. 2/3 letter) codes available for my personal use. It also
means that I’m not dependent on the goodwill of a free siloed service and I can add exactly the features I want to it.
Little wonder then that my link shortener sat so close to me on my ecosystem diagram the other year.
For the last nine years my link shortener has been S.2, a tool I threw together in Ruby. It stores URLs in a
sequentially-numbered database table and then uses the Base62-encoding of the primary key as the “code” part of the short URL. Aside from the fact that when I create a short link it shows me a QR code to I can
easily “push” a page to my phone, it doesn’t really have any “special” features. It replaced S.1, from which it primarily differed by putting the code at the end of the URL rather than as part of the domain name, e.g. s.danq.me/a0 rather than a0.s.danq.me: I made the switch
because S.1 made HTTPS a real pain as well as only supporting Base36 (owing to the case-insensitivity of domain names).
But S.2’s gotten a little long in the tooth and as I’ve gotten busier/lazier, I’ve leant into using or adapting open source tools more-often than writing my own from scratch. So this
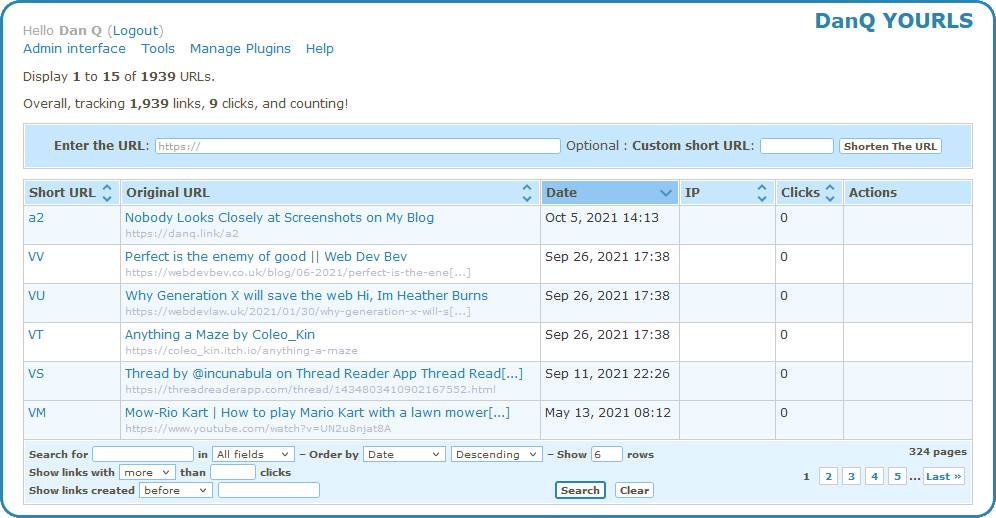
week I switched my URL shortener from S.2 to YOURLS.
YOURLs isn’t the prettiest tool in the world, but then it doesn’t have to be: only I ever see the interface pictured above!
One of the things that attracted to me to YOURLS was that it had a ready-to-go Docker image. I’m not the biggest fan of Docker in general,
but I do love the convenience of being able to deploy applications super-quickly to my household NAS. This makes installing and maintaining my personal URL shortener much easier than it
used to be (and it was pretty easy before!).
Another thing I liked about YOURLS is that it, like S.2, uses Base62 encoding. This meant that migrating my links from S.2 into YOURLS could be done with a simple cross-database
INSERT... SELECT statement:
One of S.1/S.2’s features was that it exposed an RSS feed at a secret URL for my reader to ingest. This was great, because it meant I could “push” something to my RSS reader to read or repost to my blog later. YOURLS doesn’t have such a feature, and I couldn’t find anything in the (extensive) list of plugins that would do it for me. I needed to write my own.
In some ways, subscribing “to yourself” is a strange thing to do. In other ways… shut up, I’ll do what I like.
I could have written a YOURLS plugin. Or I could have written a stack of code in Ruby, PHP, Javascript or
some other language to bridge these systems. But as I switched over my shortlink subdomain s.danq.me to its new home at danq.link, another idea came to me. I
have direct database access to YOURLS (and the table schema is super simple) and the command-line MariaDB client can output XML… could I simply write an XML
Transformation to convert database output directly into a valid RSS feed? Let’s give it a go!
I wrote a script like this and put it in my crontab:
mysql --xml yourls -e \"SELECT keyword, url, title, DATE_FORMAT(timestamp, '%a, %d %b %Y %T') AS pubdate FROM yourls_url ORDER BY timestamp DESC LIMIT 30"\
| xsltproc template.xslt - \
| xmllint --format - \
> output.rss.xml
The first part of that command connects to the yourls database, sets the output format to XML, and executes an
SQL statement to extract the most-recent 30 shortlinks. The DATE_FORMAT function is used to mould the datetime into
something approximating the RFC-822 standard for datetimes as required by
RSS. The output produced looks something like this:
<?xml version="1.0"?><resultsetstatement="SELECT keyword, url, title, timestamp FROM yourls_url ORDER BY timestamp DESC LIMIT 30"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"><row><fieldname="keyword">VV</field><fieldname="url">https://webdevbev.co.uk/blog/06-2021/perfect-is-the-enemy-of-good.html</field><fieldname="title"> Perfect is the enemy of good || Web Dev Bev</field><fieldname="timestamp">2021-09-26 17:38:32</field></row><row><fieldname="keyword">VU</field><fieldname="url">https://webdevlaw.uk/2021/01/30/why-generation-x-will-save-the-web/</field><fieldname="title">Why Generation X will save the web Hi, Im Heather Burns</field><fieldname="timestamp">2021-09-26 17:38:26</field></row><!-- ... etc. ... --></resultset>
We don’t see this, though. It’s piped directly into the second part of the command, which uses xsltproc to apply an XSLT to it. I was concerned that my XSLT
experience would be super rusty as I haven’t actually written any since working for my former employer SmartData back in around 2005! Back then, my coworker Alex and I spent many hours doing XML
backflips to implement a system that converted complex data outputs into PDF files via an XSL-FO intermediary.
I needn’t have worried, though. Firstly: it turns out I remember a lot more than I thought from that project a decade and a half ago! But secondly, this conversion from MySQL/MariaDB
XML output to RSS turned out to be pretty painless. Here’s the
template.xslt I ended up making:
<?xml version="1.0"?><xsl:stylesheetxmlns:xsl="http://www.w3.org/1999/XSL/Transform"version="1.0"><xsl:templatematch="resultset"><rssversion="2.0"xmlns:atom="http://www.w3.org/2005/Atom"><channel><title>Dan's Short Links</title><description>Links shortened by Dan using danq.link</description><link> [ MY RSS FEED URL ]</link><atom:linkhref=" [ MY RSS FEED URL ] "rel="self"type="application/rss+xml"/><lastBuildDate><xsl:value-ofselect="row/field[@name='pubdate']"/> UTC</lastBuildDate><pubDate><xsl:value-ofselect="row/field[@name='pubdate']"/> UTC</pubDate><ttl>1800</ttl><xsl:for-eachselect="row"><item><title><xsl:value-ofselect="field[@name='title']"/></title><link><xsl:value-ofselect="field[@name='url']"/></link><guid>https://danq.link/<xsl:value-ofselect="field[@name='keyword']"/></guid><pubDate><xsl:value-ofselect="field[@name='pubdate']"/> UTC</pubDate></item></xsl:for-each></channel></rss></xsl:template></xsl:stylesheet>
That uses the first (i.e. most-recent) shortlink’s timestamp as the feed’s pubDate, which makes sense: unless you’re going back and modifying links there’s no more-recent
changes than the creation date of the most-recent shortlink. Then it loops through the returned rows and creates an <item> for each; simple!
The final step in my command runs the output through xmllint to prettify it. That’s not strictly necessary, but it was useful while debugging and as the whole command takes
milliseconds to run once every quarter hour or so I’m not concerned about the overhead. Using these native binaries (plus a little configuration), chained together with pipes, had
already resulted in way faster performance (with less code) than if I’d implemented something using a scripting language, and the result is a reasonably elegant “scratch your
own itch”-type solution to the only outstanding barrier that was keeping me on S.2.
All that remained for me to do was set up a symlink so that the resulting output.rss.xml was accessible, over the web, to my RSS reader. I hope that next time I’m tempted to write a script to solve a problem like this I’ll remember that sometimes a chain of piped *nix
utilities can provide me a slicker, cleaner, and faster solution.
Update: Right as I finished writing this blog post I discovered that somebody had already solved this
problem using PHP code added to YOURLS; it’s just not packaged as a plugin so I didn’t see it earlier! Whether or not I
use this alternate approach or stick to what I’ve got, the process of implementing this YOURLS-database ➡ XML
➡ XSLT ➡ RSS chain was fun and
informative.
But sometimes, they disappear slowly, like this kind of web address:
http://username:password@example.com/somewhere
If you’ve not seen a URL like that before, that’s fine, because the answer to the question “Can I still use HTTP Basic Auth in URLs?” is, I’m afraid: no, you probably can’t.
But by way of a history lesson, let’s go back and look at what these URLs were, why they died out, and how web
browsers handle them today. Thanks to Ruth who asked the original question that inspired this post.
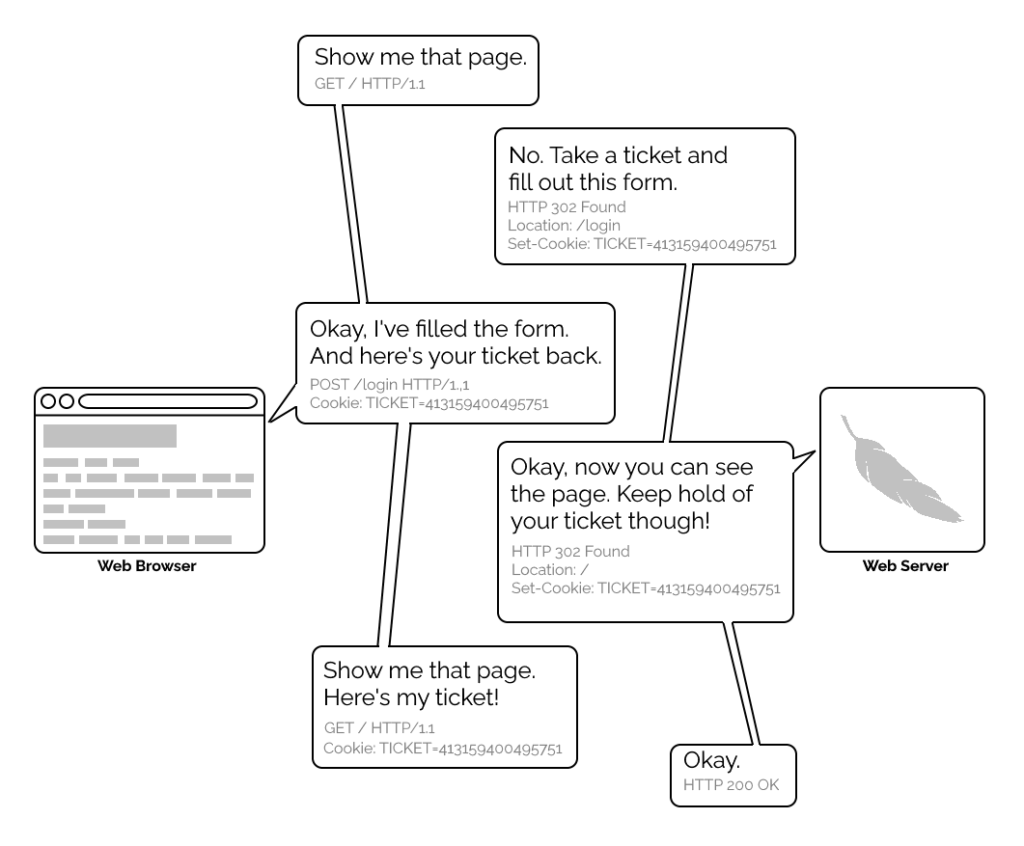
Basic authentication
The early Web wasn’t built for authentication. A resource on the Web was theoretically accessible to all of humankind: if you didn’t want it in the public eye, you didn’t put
it on the Web! A reliable method wouldn’t become available until the concept of state was provided by Netscape’s invention of HTTP
cookies in 1994, and even that wouldn’t see widespread for several years, not least because implementing a CGI (or
similar) program to perform authentication was a complex and computationally-expensive option for all but the biggest websites.
A simplified view of the form-and-cookie based authentication system used by virtually every website today, but which was too computationally-expensive for many sites in the 1990s.
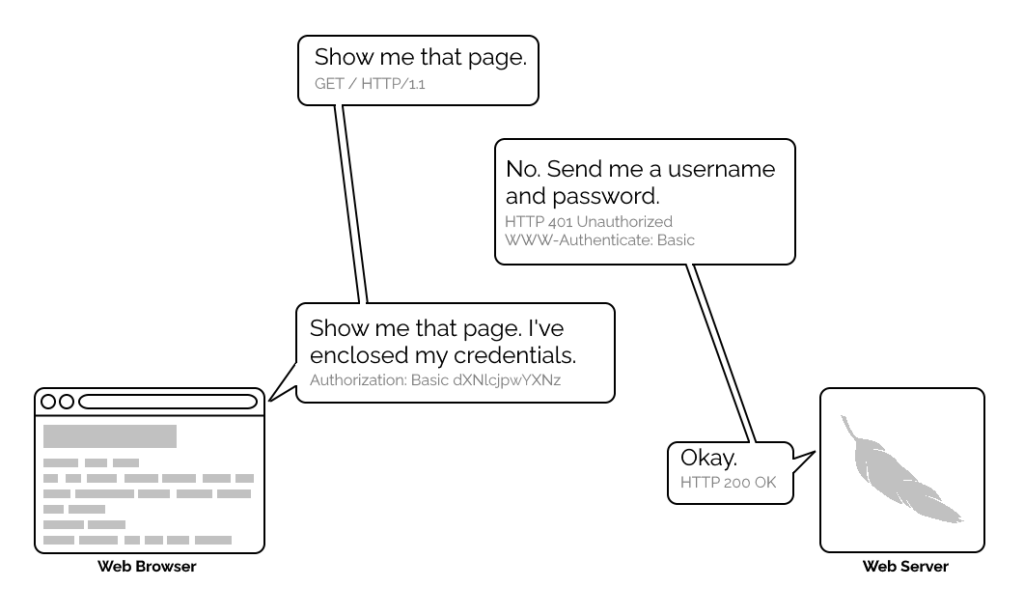
1996’s HTTP/1.0 specification tried to simplify things, though, with the introduction of the WWW-Authenticate header. The idea was that when a browser tried to access something that required
authentication, the server would send a 401 Unauthorized response along with a WWW-Authenticate header explaining how the browser could authenticate
itself. Then, the browser would send a fresh request, this time with an Authorization: header attached providing the required credentials. Initially, only “basic
authentication” was available, which basically involved sending a username and password in-the-clear unless SSL (HTTPS) was in use, but later, digest authentication and a host of others would appear.
For all its faults, HTTP Basic Authentication (and its near cousins) are certainly elegant.
Webserver software quickly added support for this new feature and as a result web authors who lacked the technical know-how (or permission from the server administrator) to implement
more-sophisticated authentication systems could quickly implement HTTP Basic Authentication, often simply by adding a .htaccessfile to the relevant directory.
.htaccess files would later go on to serve many other purposes, but their original and perhaps best-known purpose – and the one that gives them their name – was access
control.
Credentials in the URL
A separate specification, not specific to the Web (but one of Tim Berners-Lee’s most important contributions to it), described the general structure of URLs as follows:
At the time that specification was written, the Web didn’t have a mechanism for passing usernames and passwords: this general case was intended only to apply to protocols that
did have these credentials. An example is given in the specification, and clarified with “An optional user name. Some schemes (e.g., ftp) allow the specification of a user
name.”
But once web browsers had WWW-Authenticate, virtually all of them added support for including the username and password in the web address too. This allowed for
e.g. hyperlinks with credentials embedded in them, which made for very convenient bookmarks, or partial credentials (e.g. just the username) to be included in a link, with the
user being prompted for the password on arrival at the destination. So far, so good.
Encoding authentication into the URL provided an incredible shortcut at a time when Web round-trip times were much longer owing to higher latencies and no keep-alives.
This is why we can’t have nice things
The technique fell out of favour as soon as it started being used for nefarious purposes. It didn’t take long for scammers to realise that they could create links like this:
https://YourBank.com@HackersSite.com/
Everything we were teaching users about checking for “https://” followed by the domain name of their bank… was undermined by this user interface choice. The poor victim would
actually be connecting to e.g. HackersSite.com, but a quick glance at their address bar would leave them convinced that they were talking to YourBank.com!
Theoretically: widespread adoption of EV certificates coupled with sensible user interface choices (that were never made) could
have solved this problem, but a far simpler solution was just to not show usernames in the address bar. Web developers were by now far more excited about forms and
cookies for authentication anyway, so browsers started curtailing the “credentials in addresses” feature.
Users trained to look for “https://” followed by the site they wanted would often fall for scams like this one: the real domain name is after the @-sign. (This attacker is
also using dword notation to obfuscate their IP address; this
dated technique wasn’t often employed alongside this kind of scam, but it’s another historical oddity I enjoy so I’m shoehorning it in.)
(There are other reasons this particular implementation of HTTP Basic Authentication was less-than-ideal, but this reason is the big one that explains why things had to change.)
One by one, browsers made the change. But here’s the interesting bit: the browsers didn’t always make the change in the same way.
How different browsers handle basic authentication in URLs
Let’s examine some popular browsers. To run these tests I threw together a tiny web application that outputs
the Authorization: header passed to it, if present, and can optionally send a 401 Unauthorized response along with a WWW-Authenticate: Basic realm="Test Site" header in order to trigger basic authentication. Why both? So that I can test not only how browsers handle URLs containing credentials when an authentication request is received, but how they handle them when one is not. This is relevant because
some addresses – often API endpoints – have optional HTTP authentication, and it’s sometimes important for a user agent (albeit typically a library or command-line one) to pass credentials without
first being prompted.
In each case, I tried each of the following tests in a fresh browser instance:
Go to http://<username>:<password>@<domain>/optional (authentication is optional).
Go to http://<username>:<password>@<domain>/mandatory (authentication is mandatory).
Experiment 1, then f0llow relative hyperlinks (which should correctly retain the credentials) to /mandatory.
Experiment 2, then follow relative hyperlinks to the /optional.
I’m only testing over the http scheme, because I’ve no reason to believe that any of the browsers under test treat the https scheme differently.
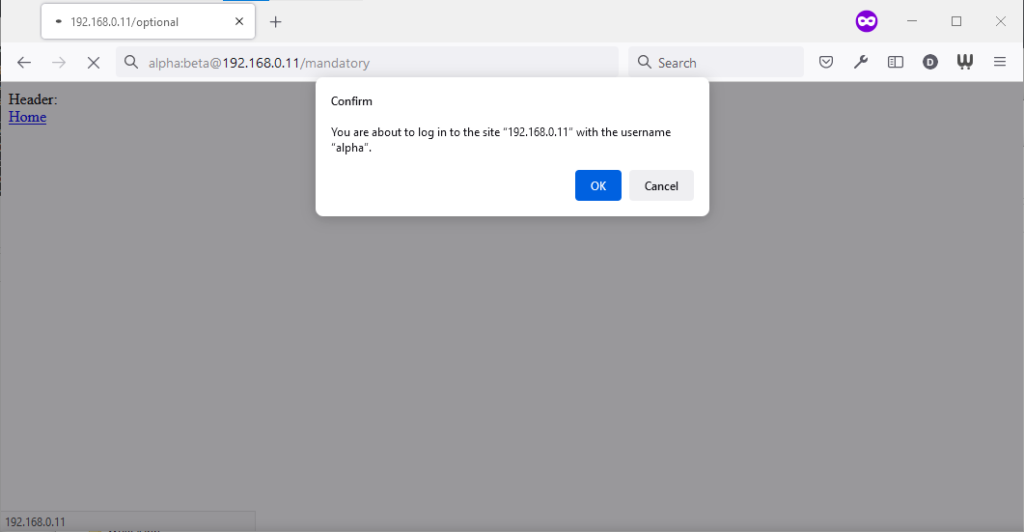
Chromium desktop family
Chrome 93 and Edge 93 both immediately suppressed the username and password from the address bar, along with the “http://” as we’ve come to expect of them. Like the “http://”, though,
the plaintext username and password are still there. You can retrieve them by copy-pasting the entire address.
Opera 78 similarly suppressed the username, password, and scheme, but didn’t retain the username and password in a way that could be copy-pasted out.
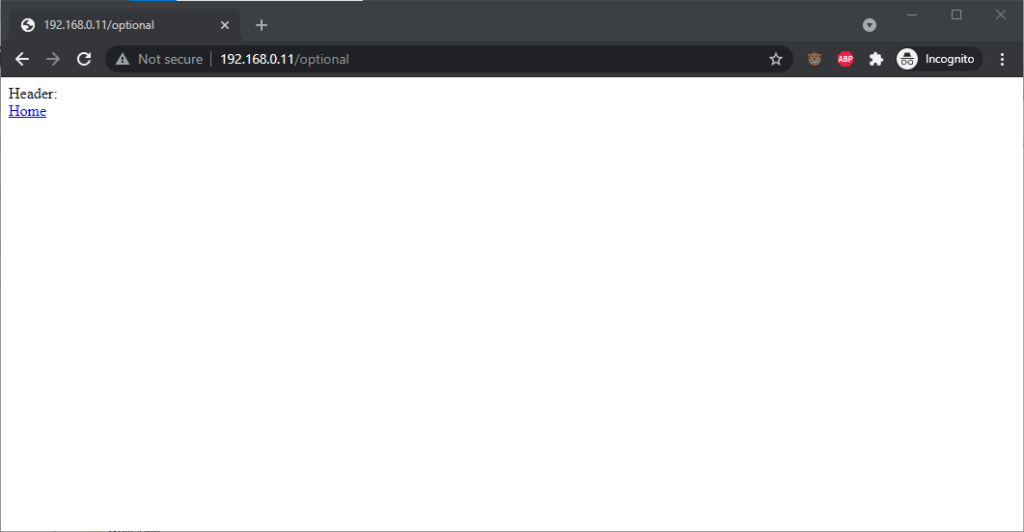
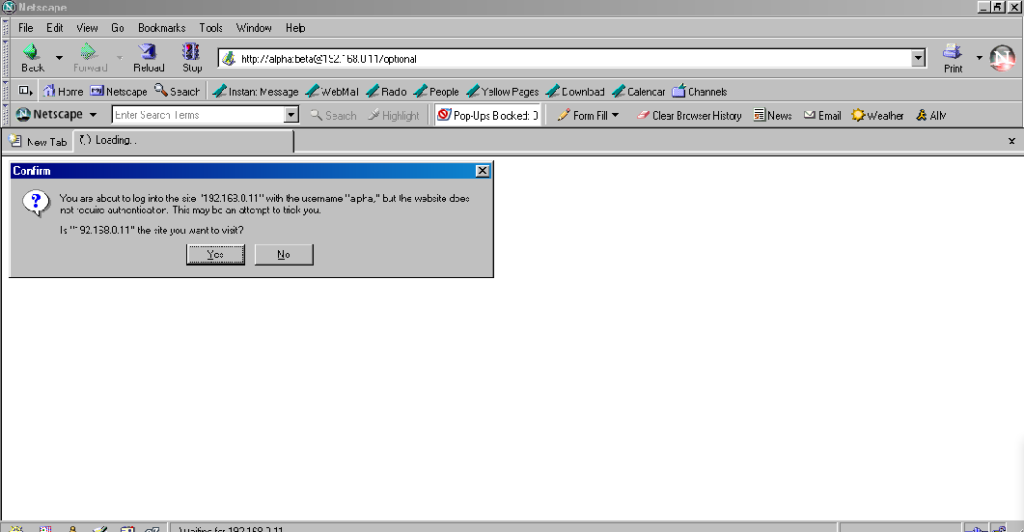
Authentication was passed only when landing on a “mandatory” page; never when landing on an “optional” page. Refreshing the page or re-entering the address with its credentials did not
change this.
Navigating from the “optional” page to the “mandatory” page using only relative links retained the username and password and submitted it to the server when it became mandatory,
even Opera which didn’t initially appear to retain the credentials at all.
Navigating from the “mandatory” to the “optional” page using only relative links, or even entering the “optional” page address with credentials after visiting the “mandatory” page, does
not result in authentication being passed to the “optional” page. However, it’s interesting to note that once authentication has occurred on a mandatory page, pressing enter at
the end of the address bar on the optional page, with credentials in the address bar (whether visible or hidden from the user) does result in the credentials being passed to
the optional page! They continue to be passed on each subsequent load of the “optional” page until the browsing session is ended.
Firefox desktop
Firefox 91 does a clever thing very much in-line with
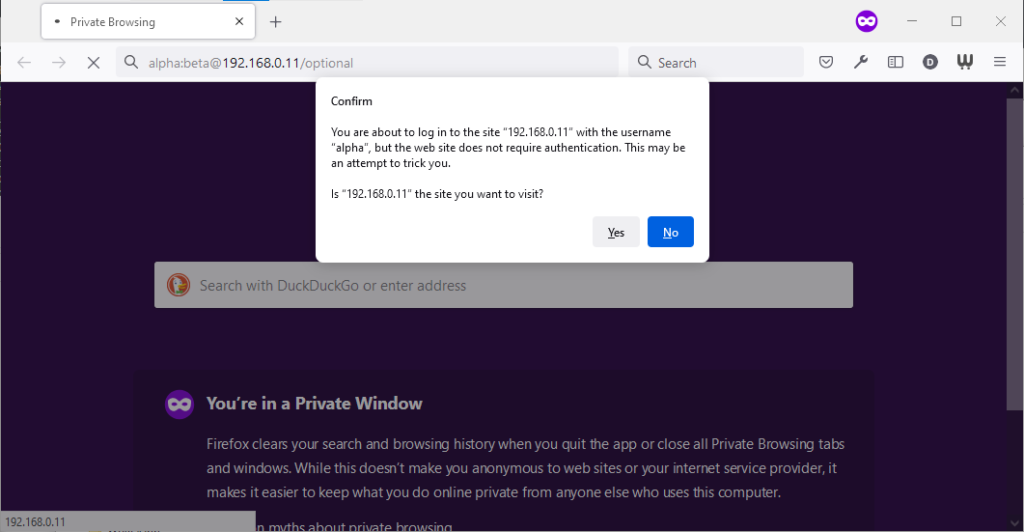
its image as a browser that puts decision-making authority into the hands of its user. When going to the “optional” page first it presents a dialog, warning the user that they’re going
to a site that does not specifically request a username, but they’re providing one anyway. If the user says that no, navigation ceases (the GET request for the page takes place the same
either way; this happens before the dialog appears). Strangely: regardless of whether the user selects yes or no, the credentials are not passed on the “optional” page. The credentials
(although not the “http://”) appear in the address bar while the user makes their decision.
Similar to Opera, the credentials do not appear in the address bar thereafter, but they’re clearly still being stored: if the refresh button is pressed the dialog appears again. It does
not appear if the user selects the address bar and presses enter.
Similarly, going to the “mandatory” page in Firefox results in an informative dialog warning the user
that credentials are being passed. I like this approach: not only does it help protect the user from the use of authentication as a tracking technique (an old technique that I’ve not
seen used in well over a decade, mind), it also helps the user be sure that they’re logging in using the account they mean to, when following a link for that purpose. Again, clicking
cancel stops navigation, although the initial request (with no credentials) and the 401 response has already occurred.
Visiting any page within the scope of the realm of the authentication after visiting the “mandatory” page results in credentials being sent, whether or not they’re included in the
address. This is probably the most-true implementation to the expectations of the standard that I’ve found in a modern graphical browser.
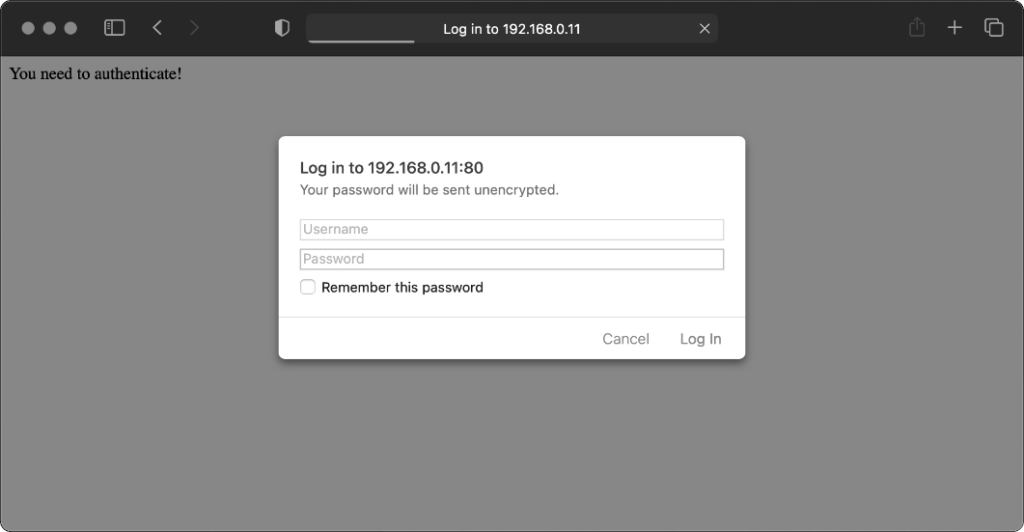
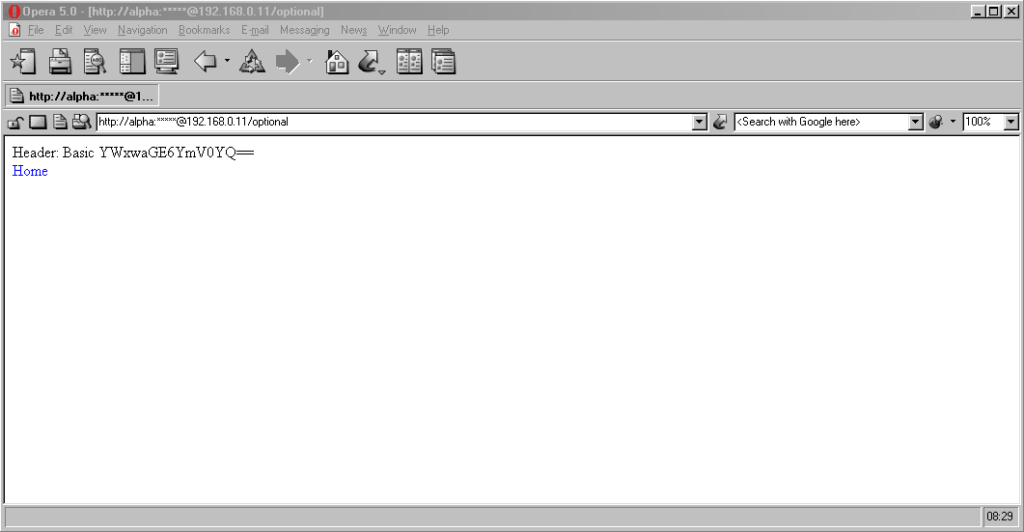
Safari desktop
Safari 14 never displays or uses credentials provided via the web address, whether or not
authentication is mandatory. Mandatory authentication is always met by a pop-up dialog, even if credentials were provided in the address bar. Boo!
Once passed, credentials are later provided automatically to other addresses within the same realm (i.e. optional pages).
Older browsers
Let’s try some older browsers.
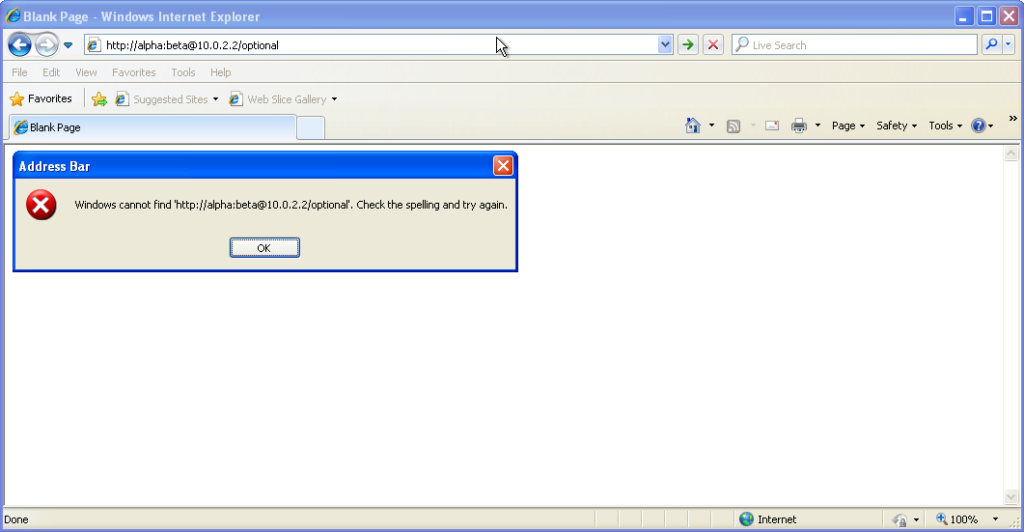
From version 7 onwards – right up to the final version 11 – Internet Explorer fails to even recognise
addresses with authentication credentials in as legitimate web addresses, regardless of whether or not authentication is requested by the server. It’s easy to assume that this is yet
another missing feature in the browser we all love to hate, but it’s interesting to note that credentials-in-addresses is permitted for ftp:// URLs…
…and if you go back a little way, Internet Explorer 6 and below supported credentials in the address bar pretty
much as you’d expect based on the standard. The error message seen in IE7 and above is a deliberate design
decision, albeit a somewhat knee-jerk reaction to the security issues posed by the feature (compare to the more-careful approach of other browsers).
These older versions of IE even (correctly) retain the credentials through relative hyperlinks, allowing them to be passed when
they become mandatory. They’re not passed on optional pages unless a mandatory page within the same realm has already been encountered.
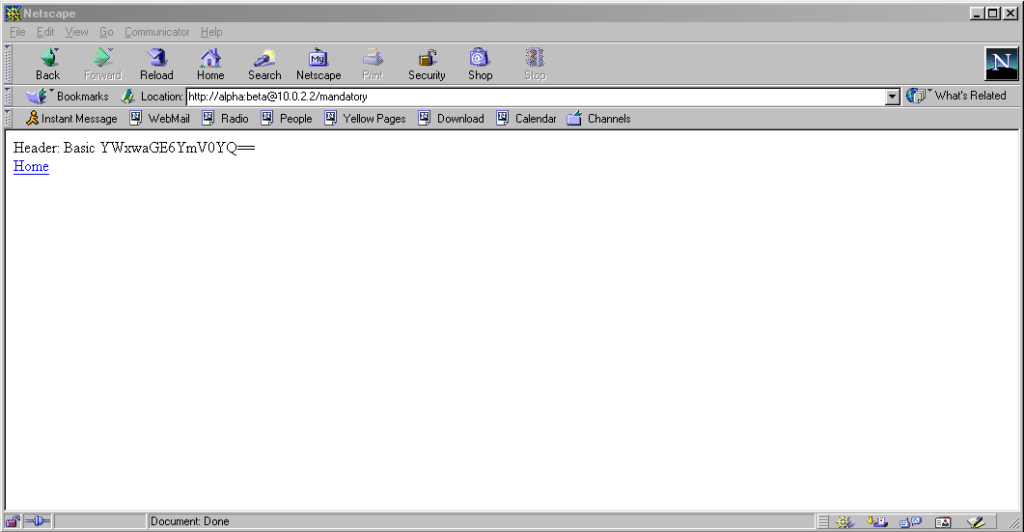
Pre-Mozilla Netscape behaved the same way. Truly this was the de facto standard for a long period on the Web, and the varied approaches we see today are the
anomaly. That’s a strange observation to make, considering how much the Web of the 1990s was dominated by incompatible implementations of different Web features (I’ve written about the <blink> and <marquee> tags before, which was perhaps the most-visible division between
the Microsoft and Netscape camps, but there were many, many more).
Interestingly: by Netscape 7.2 the browser’s behaviour had evolved
to be the same as modern Firefox’s, except that it still displayed the credentials in the address bar for all to see.
Now here’s a real gem: pre-Chromium Opera. It would send credentials to “mandatory” pages and remember them for the
duration of the browsing session, which is great. But it would also send credentials when passed in a web address to “optional” pages. However, it wouldn’t remember
them on optional pages unless they remained in the address bar: this feels to me like an optimum balance of features for power users. Plus, it’s one of very few browsers that
permitted you to change credentials mid-session: just by changing them in the address bar! Most other browsers, even to this day, ignore changes to HTTP Authentication credentials, which was sometimes be a source of frustration back in the day.
Finally, classic Opera was the only browser I’ve seen to mask the password in the address bar, turning it into a series of asterisks. This ensures the user knows that a
password was used, but does not leak any sensitive information to shoulder-surfers (the length of the “masked” password was always the same length, too, so it didn’t even leak the
length of the password). Altogether a spectacular design and a great example of why classic Opera was way ahead of its time.
The Command-Line
Most people using web addresses with credentials embedded within them nowadays are probably working with code, APIs,
or the command line, so it’s unsurprising to see that this is where the most “traditional” standards-compliance is found.
I was unsurprised to discover that giving curl a username and password in the URL meant that
username and password was sent to the server (using Basic authentication, of course, if no authentication was requested):
However, wgetdid catch me out. Hitting the same addresses with wget didn’t result in the credentials being sent
except where it was mandatory (i.e. where a HTTP 401 response and a WWW-Authenticate: header was received on the initial attempt). To force wget to
send credentials when they haven’t been asked-for requires the use of the --http-user and --http-password switches:
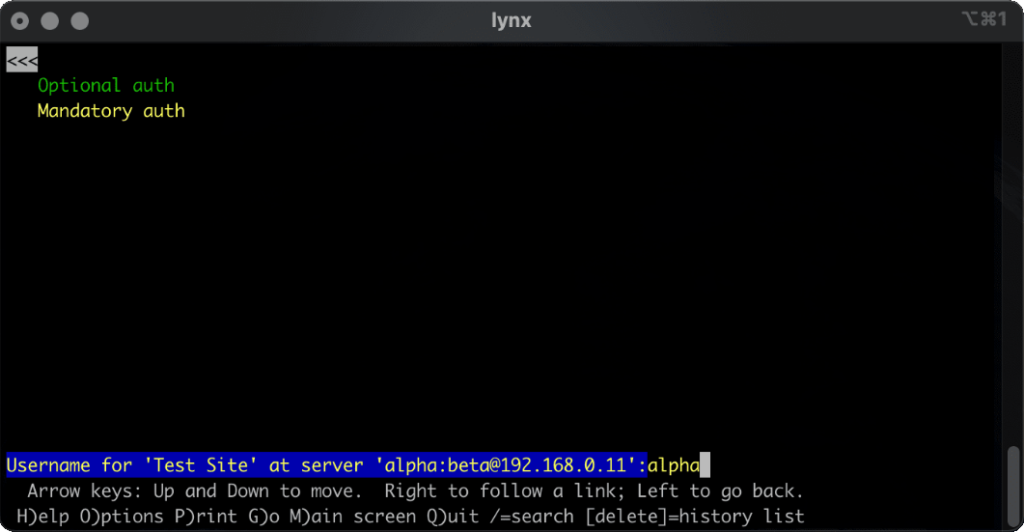
lynx does a cute and clever thing. Like most modern browsers, it does not submit credentials unless specifically requested, but if
they’re in the address bar when they become mandatory (e.g. because of following relative hyperlinks or hyperlinks containing credentials) it prompts for the username and password,
but pre-fills the form with the details from the URL. Nice.
What’s the status of HTTP (Basic) Authentication?
HTTP Basic Authentication and its close cousin Digest Authentication (which overcomes some of the security limitations of running Basic Authentication over an
unencrypted connection) is very much alive, but its use in hyperlinks can’t be relied upon: some browsers (e.g. IE, Safari)
completely munge such links while others don’t behave as you might expect. Other mechanisms like Bearer see widespread use in APIs, but nowhere else.
The WWW-Authenticate: and Authorization: headers are, in some ways, an example of the best possible way to implement authentication on the Web: as an
underlying standard independent of support for forms (and, increasingly, Javascript), cookies, and complex multi-part conversations. It’s easy to imagine an alternative
timeline where these standards continued to be collaboratively developed and maintained and their shortfalls – e.g. not being able to easily log out when using most graphical browsers!
– were overcome. A timeline in which one might write a login form like this, knowing that your e.g. “authenticate” attributes would instruct the browser to send credentials using an
Authorization: header:
In such a world, more-complex authentication strategies (e.g. multi-factor authentication) could involve encoding forms as JSON. And single-sign-on systems would simply involve the browser collecting a token from the authentication provider and passing it on to the
third-party service, directly through browser headers, with no need for backwards-and-forwards redirects with stacks of information in GET parameters as is the case today.
Client-side certificates – long a powerful but neglected authentication mechanism in their own right – could act as first class citizens directly alongside such a system, providing
transparent second-factor authentication wherever it was required. You wouldn’t have to accept a tracking cookie from a site in order to log in (or stay logged in), and if your
browser-integrated password safe supported it you could log on and off from any site simply by toggling that account’s “switch”, without even visiting the site: all you’d be changing is
whether or not your credentials would be sent when the time came.
The Web has long been on a constant push for the next new shiny thing, and that’s sometimes meant that established standards have been neglected prematurely or have failed to evolve for
longer than we’d have liked. Consider how long it took us to get the <video> and <audio> elements because the “new shiny” Flash came to dominate,
how the Web Payments API is only just beginning to mature despite over 25 years of ecommerce on the Web, or how we still can’t
use Link: headers for all the things we can use <link> elements for despite them being semantically-equivalent!
The new model for Web features seems to be that new features first come from a popular JavaScript implementation, and then eventually it evolves into a native browser feature: for
example HTML form validations, which for the longest time could only be done client-side using scripting languages. I’d love
to see somebody re-think HTTP Authentication in this way, but sadly we’ll never get a 100% solution in JavaScript alone: (distributed SSO is almost certainly off the table, for example, owing to cross-domain limitations).
Or maybe it’s just a problem that’s waiting for somebody cleverer than I to come and solve it. Want to give it a go?
Plus many, many things that were new to me and that I’ve loved learning about these last few days.
It’s definitely not a competition; it’s a learning opportunity wrapped up in the weirdest bits of the field. Have an explore and feed your inner computer science geek.
I’m currently doing a course, through work, delivered by BetterOn Video. The aim of the course is to improve
my video presentation skills, in particular my engagement with the camera and the audience.
I made this video based on the week 2 prompt “make a video 60-90 seconds long about something you’re an expert on”. The idea came from a talk I used to give at the University of Oxford.
This weekend I announced and then hosted Homa Night II, an effort to use
technology to help bridge the chasms that’ve formed between my diaspora of friends as a result mostly of COVID. To a lesser extent
we’ve been made to feel distant from one another for a while as a result of our very diverse locations and lifestyles, but the resulting isolation was certainly compounded by lockdowns
and quarantines.
Long gone are the days when I could put up a blog post to say “Troma Night tonight?” and expect half a dozen friends to turn up at my house.
Back in the day we used to have a regular weekly film night called Troma Night, named after the studio
who dominated our early events and whose… genre… influenced many of our choices thereafter. We had over 300 such film
nights, by my count, before I eventually left our shared hometown of Aberystwyth ten years ago. I wasn’t the last one of the Troma Night
regulars to leave town, but more left before me than after.
Observant readers will spot a previous effort I made this year at hosting a party online.
Earlier this year I hosted Sour Grapes, a murder mystery party (an irregular highlight of our Aberystwyth social calendar,
with thanks to Ruth) run entirely online using a mixture of video chat and “second screen”
technologies. In some ways that could be seen as the predecessor to Homa Night, although I’d come up with most of the underlying technology to make Homa Night possible on a
whim much earlier in the year!
The idea spun out of a few conversations on WhatsApp but the final name – Homa Night – wasn’t agreed until early in November.
How best to make such a thing happen? When I first started thinking about it, during the first of the UK’s lockdowns, I considered a few options:
Streaming video over a telemeeting service (Zoom, Google Meet, etc.)
Very simple to set up, but the quality – as anybody who’s tried this before will attest – is appalling. Being optimised for speech rather than music and sound effects gives the audio
a flat, scratchy sound, video compression artefacts that are tolerable when you’re chatting to your boss are really annoying when they stop you reading a crucial subtitle, audio and
video often get desynchronised in a way that’s frankly infuriating, and everybody’s download speed is limited by the upload speed of the host, among other issues. The major benefit of
these platforms – full-duplex audio – is destroyed by feedback so everybody needs to stay muted while watching anyway. No thanks!
Teleparty or a similar tool Teleparty (formerly Netflix Party, but it now supports more services) is a pretty clever way to get almost exactly what I want:
synchronised video streaming plus chat alongside. But it only works on Chrome (and some related browsers) and doesn’t work on tablets, web-enabled TVs, etc., which would exclude some
of my friends. Everybody requires an account on the service you’re streaming from, potentially further limiting usability, and that also means you’re strictly limited to the media
available on those platforms (and further limited again if your party spans multiple geographic distribution regions for that service). There’s definitely things I can learn from
Teleparty, but it’s not the right tool for Homa Night.
“Press play… now!”
The relatively low-tech solution might have been to distribute video files in advance, have people download them, and get everybody to press “play” at the same time! That’s at least
slightly less-convenient because people can’t just “turn up”, they have to plan their attendance and set up in advance, but it would certainly have worked and I seriously
considered it. There are other downsides, though: if anybody has a technical issue and needs to e.g. restart their player then they’re basically doomed in any attempt to get back
in-sync again. We can do better…
A custom-made synchronised streaming service…?
A custom solution that leveraged existing infrastructure for the “hard bits” proved to be the right answer.
So obviously I ended up implementing my own streaming service. It wasn’t even that hard. In case you want to try your own, here’s how I did it:
Media preparation
First, I used Adobe Premiere to create a video file containing both of the night’s films, bookended and separated by “filler” content to provide an introduction/lobby, an intermission,
and a closing “you should have stopped watching by now” message. I made sure that the “intro” was a nice round duration (90s) and suitable for looping because I planned to hold people
there until we were all ready to start the film. Thanks to Boris & Oliver for the background
music!
Honestly, the intermission was just an excuse to keep my chroma key gear out following its most-recent use.
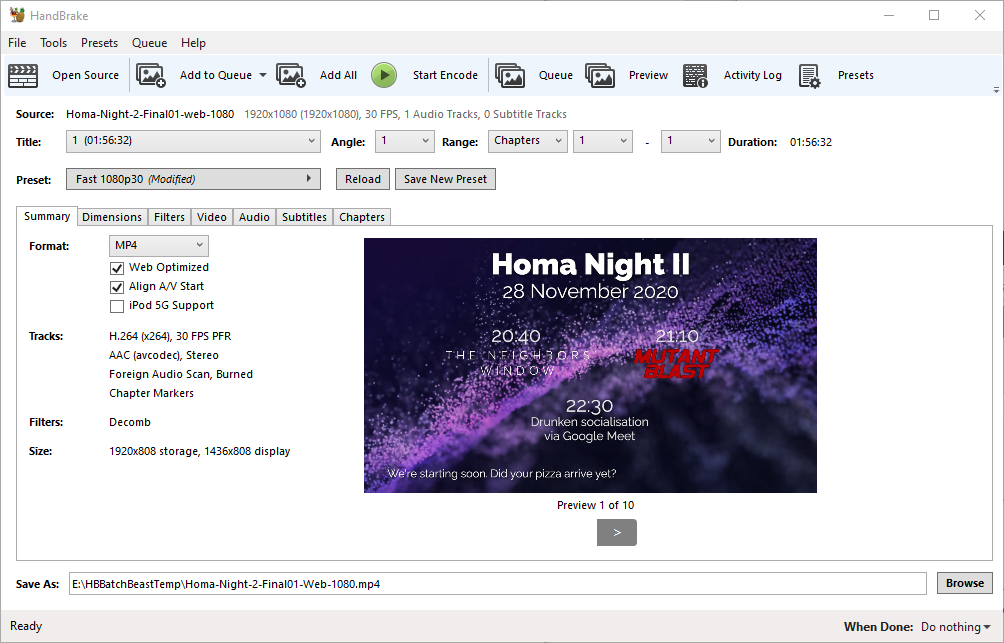
Next, I ran the output through Handbrake to produce “web optimized” versions in 1080p and 720p output sizes. “Web optimized” in this case means that
metadata gets added to the start of the file to allow it to start playing without downloading the entire file (streaming) and to allow the calculation of what-part-of-the-file
corresponds to what-part-of-the-timeline: the latter, when coupled with a suitable webserver, allows browsers to “skip” to any point in the video without having to watch the intervening
part. Naturally I’m encoding with H.264 for the widest possible compatibility.
Even using my multi-GPU computer for the transcoding I had time to get up and walk around a bit.
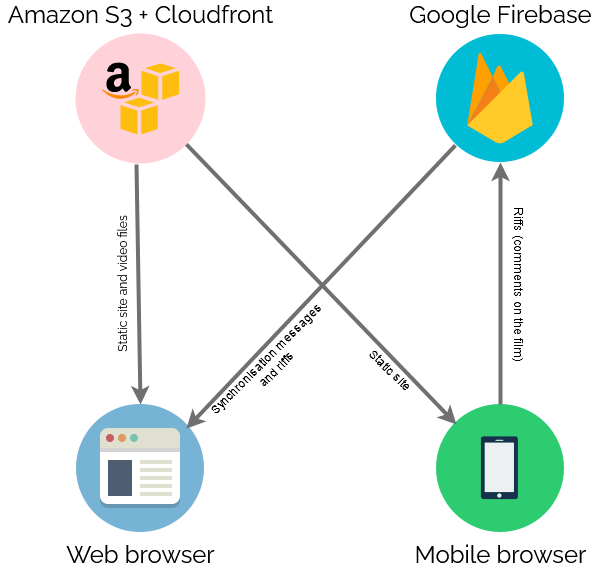
Real-Time Synchronisation
To keep everybody’s viewing experience in-sync, I set up a Firebase account for the application: Firebase provides an easy-to-use Websockets
platform with built-in data synchronisation. Ignoring the authentication and chat features, there wasn’t much
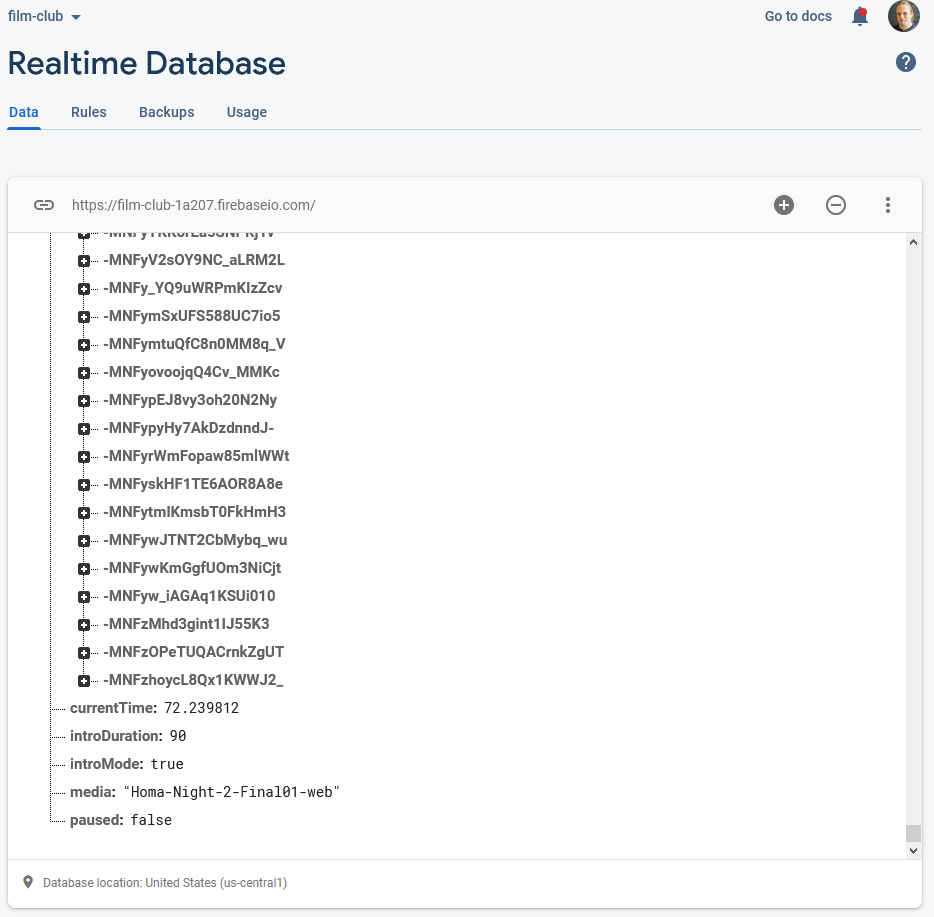
shared here: just the currentTime of the video in seconds, whether or not introMode was engaged (i.e. everybody should loop the first 90 seconds, for now), and
whether or not the video was paused:
Firebase makes schemaless real-time databases pretty easy.
To reduce development effort, I never got around to implementing an administrative front-end; I just manually went into the Firebase database and acknowledged “my” computer as being an
administrator, after I’d connected to it, and then ran a little Javascript in my browser’s debugger to tell it to start pushing my video’s currentTime to the server every
few seconds. Anything else I needed to edit I just edited directly from the Firebase interface.
Other web clients’ had Javascript to instruct them to monitor these variables from the Firebase database and, if they were desynchronised by more than 5 seconds, “jump” to the correct
point in the video file. The hard part of the code… wasn’t really that hard:
// Rewind if we're passed the end of the intro loopfunction introModeLoopCheck() {
if (!introMode) return;
if (video.currentTime > introDuration) video.currentTime =0;
}
function fixPlayStatus() {
// Handle "intro loop" modeif (remotelyControlled && introMode) {
if (video.paused) video.play(); // always play
introModeLoopCheck();
return; // don't look at the rest
}
// Fix current timeconst desync =Math.abs(lastCurrentTime - video.currentTime);
if (
(video.paused && desync > DESYNC_TOLERANCE_WHEN_PAUSED) ||
(!video.paused && desync > DESYNC_TOLERANCE_WHEN_PLAYING)
) {
video.currentTime = lastCurrentTime;
}
// Fix play statusif (remotelyControlled) {
if (lastPaused &&!video.paused) {
video.pause();
} elseif (!lastPaused && video.paused) {
video.play();
}
}
// Show/hide paused notification
updatePausedNotification();
}
Web front-end
Finally, there needed to be a web page everybody could go to to get access to this. As I was hosting the video on S3+CloudFront anyway, I put the HTML/CSS/JS there too.
I decided to carry the background theme of the video through to the web interface too.
I tested in Firefox, Edge, Chrome, and Safari on desktop, and (slightly less) on Firefox, Chrome and Safari on mobile. There were a few quirks to work around, mostly to do with browsers
not letting videos make sound until the page has been interacted with after the video element has been rendered, which I carefully worked-around by putting a popup “over” the
video to “enable sync”, but mostly it “just worked”.
Delivery
On the night I shared the web address and we kicked off! There were a few hiccups as some people’s browsers got disconnected early on and tried to start playing the film before it was
time, and one of these even when fixed ran about a minute behind the others, leading to minor spoilers leaking via the rest of us riffing about them! But on the whole, it worked. I’ve
had lots of useful feedback to improve on it for the next version, and I might even try to tidy up my code a bit and open-source the results if this kind of thing might be useful to
anybody else.
I’ve been working as part of the team working on the new application framework called the Endpoint Encabulator and wanted to share with you what I think makes our project so
exciting: I promise it’ll make for two minutes of your time you won’t seen forget!
Naturally, this project wouldn’t have been possible without the pioneering work that preceded it by John Hellins Quick, Bud Haggart, and others. Nothing’s invented in a vacuum. However,
my fellow developers and I think that our work is the first viable encabulator implementation to provide inverse reactive data binding suitable for deployment in front of a
blockchain-driven backend cache. I’m not saying that all digital content will one day be delivered through Endpoint Encabulator, but… well; maybe it will.
If the technical aspects go over your head, pass it on to a geeky friend who might be able to make use of my work. Sharing is caring!
Over the last six years I’ve been on a handful of geohashing expeditions, setting out to functionally-random GPS coordinates to see if I can get there, and documenting what I find when I do. The comic that inspired the
sport was already six years old by the time I embarked on my first outing, and I’m far from the most-active member
of the ‘hasher community, but I’ve a certain closeness to them as a result of my work to resurrect and host the “official” website. Either way: I love the sport.
I even managed to drag-along Ruth and Annabel to a hashpoint (2014-04-21 51 -1) once.
But even when I’ve not been ‘hashing, it occurs to me that I’ve been tracking my location a lot. Three mechanisms in particular dominate:
Google’s somewhat-invasive monitoring of my phones’ locations (which can be exported via Google Takeout)
My personal GPSr logs (I carry the device moderately often, and it provides excellent precision)
The personal μlogger server I’ve been running for the last few years (it’s like Google’s system, but – y’know –
self-hosted, tweakable, and less-creepy)
If I could mine all of that data, I might be able to answer the question… have I ever have accidentally visited a geohashpoint?
Let’s find out.
There’s a lot to my process, but it’s technically quite simple.
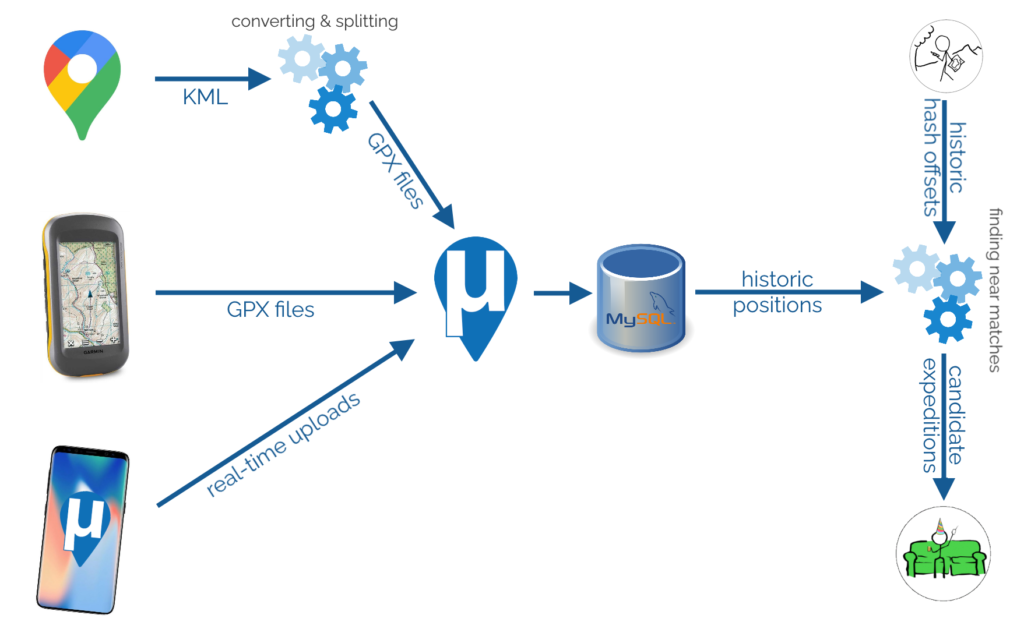
Data mining my own movements
To begin with, I needed to get all of my data into μLogger. The Android app syncs to it automatically and uploading from my GPSr was
simple. The data from Google Takeout was a little harder.
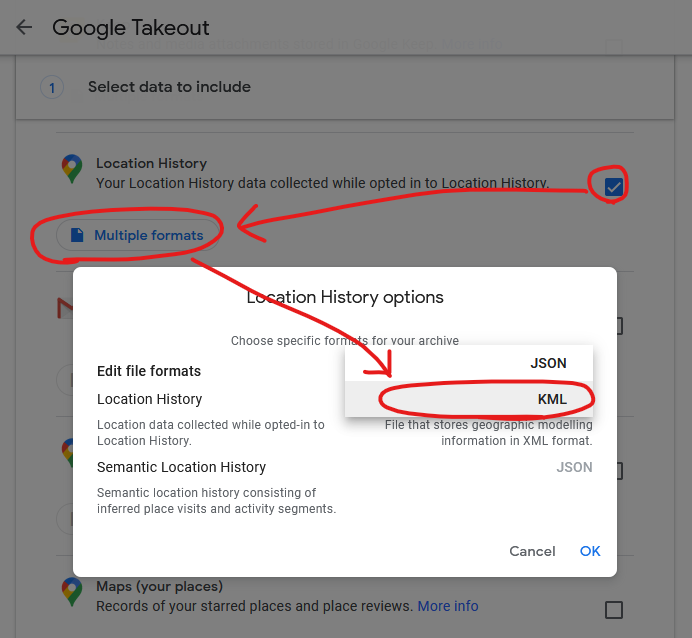
I found a setting in Google Takeout to export past location data in KML, rather than JSON, format. KML is understood by GPSBabel which
can convert it into GPX. I can “cut up” the resulting GPX file using a little grep-fu (relevant xkcd?) to get month-long files and import them into
μLogger. Easy!
It’s slightly hidden, but Google Takeout choose your geoposition output format (from a limited selection).
Well.. μLogger’s web interface sometimes times-out if you upload enormous files like a whole month of Google Takeout logs. So instead I wrote a Nokogiri script to convert the GPX into SQL
to inject directly into μLogger’s database.
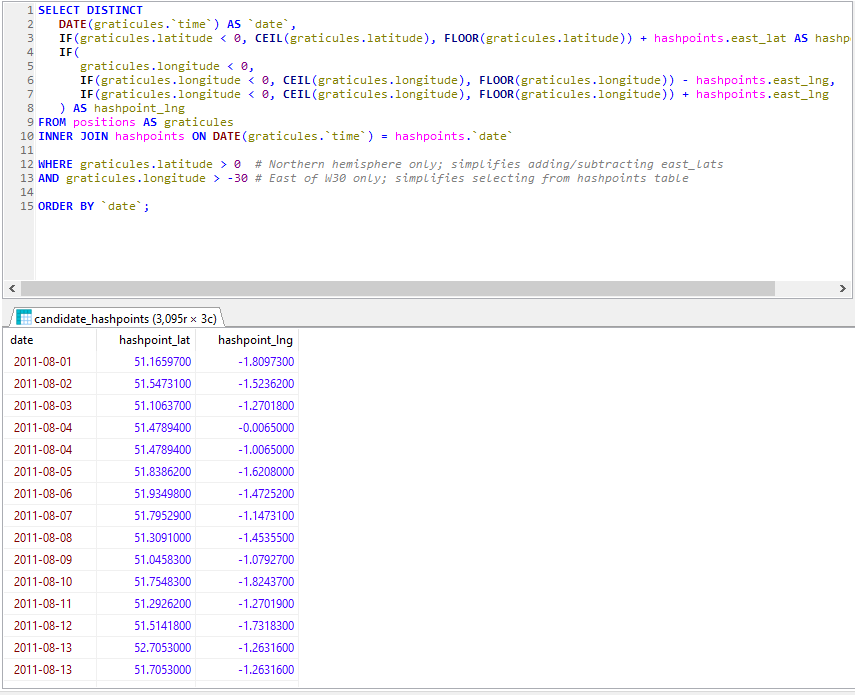
Next, I got a set of hashpoint offsets. I only had personal positional data going back to around 2010, so I didn’t need to accommodate for the pre-2008 absence of the 30W time zone rule. I’ve had only one trip to the Southern hemisphere in that period, and I
checked that manually. A little rounding and grouping in SQL gave me each graticule I’d been in on every date.
Unsurprisingly, I spend most of my time in the 51 -1 graticule. Adding (or subtracting, for the Western
hemisphere) the offset provided the coordinates for each graticule that I visited for the date that I was in that graticule. Nice.
Preloading the offsets into a temporary table made light work of listing all the hashpoints in all the graticules I’d visited, by date. Note that some dates (e.g. 2011-08-04, above)
saw me visit multiple graticules.
The correct way to find the proximity of my positions to each geohashpoint is, of course, to use WGS84. That’s an
easy thing to do if you’re using a database that supports it. My database… doesn’t. So I just used Pythagoras’ theorem to find positions I’d visited that were within 0.15° of a that
day’s hashpoint.
Using Pythagoras for geopositional geometry is, of course, wrong. Why? Because the physical length of a “degree” varies dependent on latitude, and – more importantly – a degree of
latitude is not the same distance as a degree of longitude. The ratio varies by latitude: only an idealised equatorial graticule would be square!
But for this case, I don’t care: the data’s going to be fuzzy and require some interpretation anyway. Not least because Google’s positioning has the tendency to, for example, spot a
passing train’s WiFi and assume I’ve briefly teleported to Euston Station, which is apparently where Google thinks that hotspot “lives”.
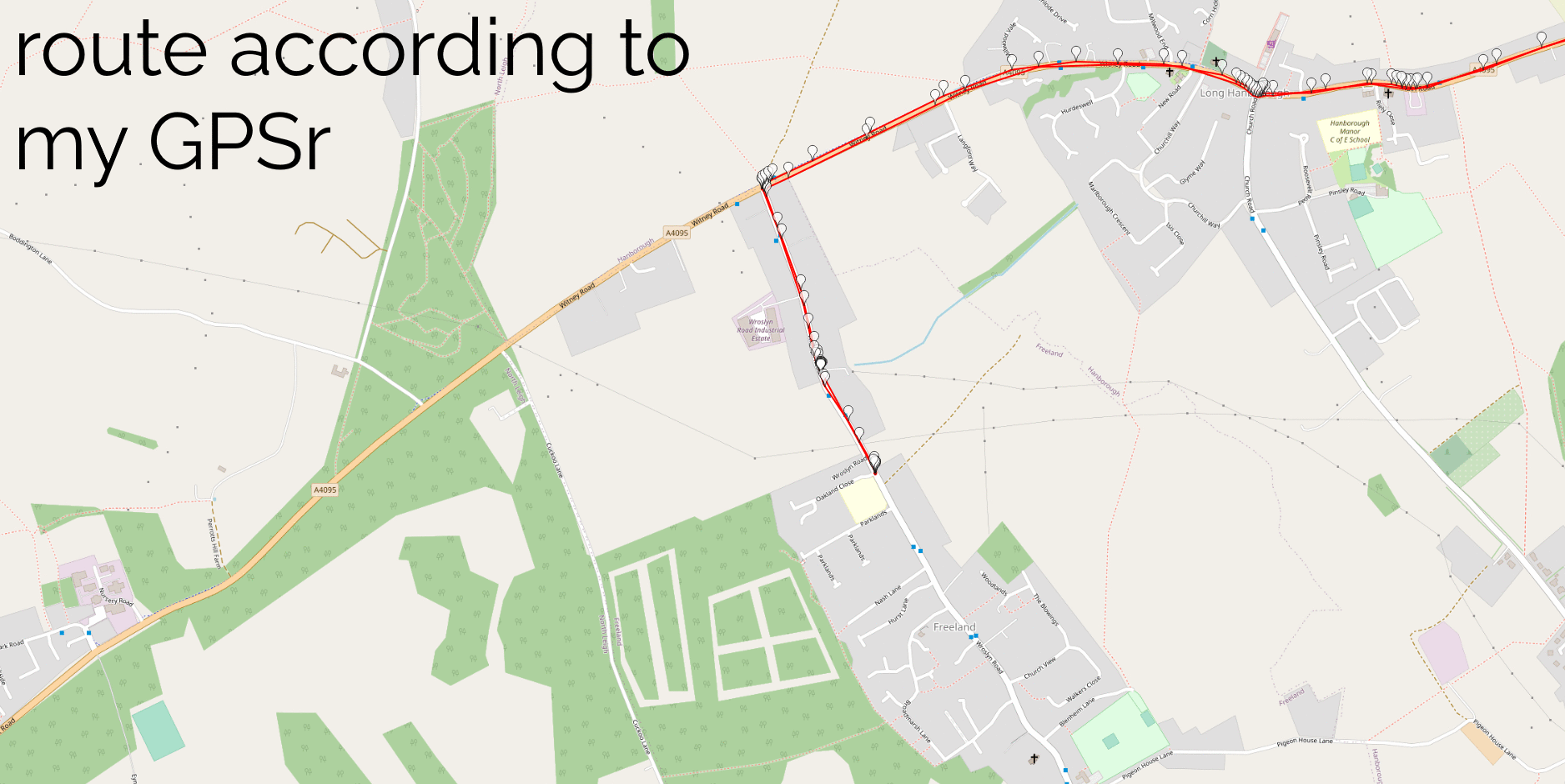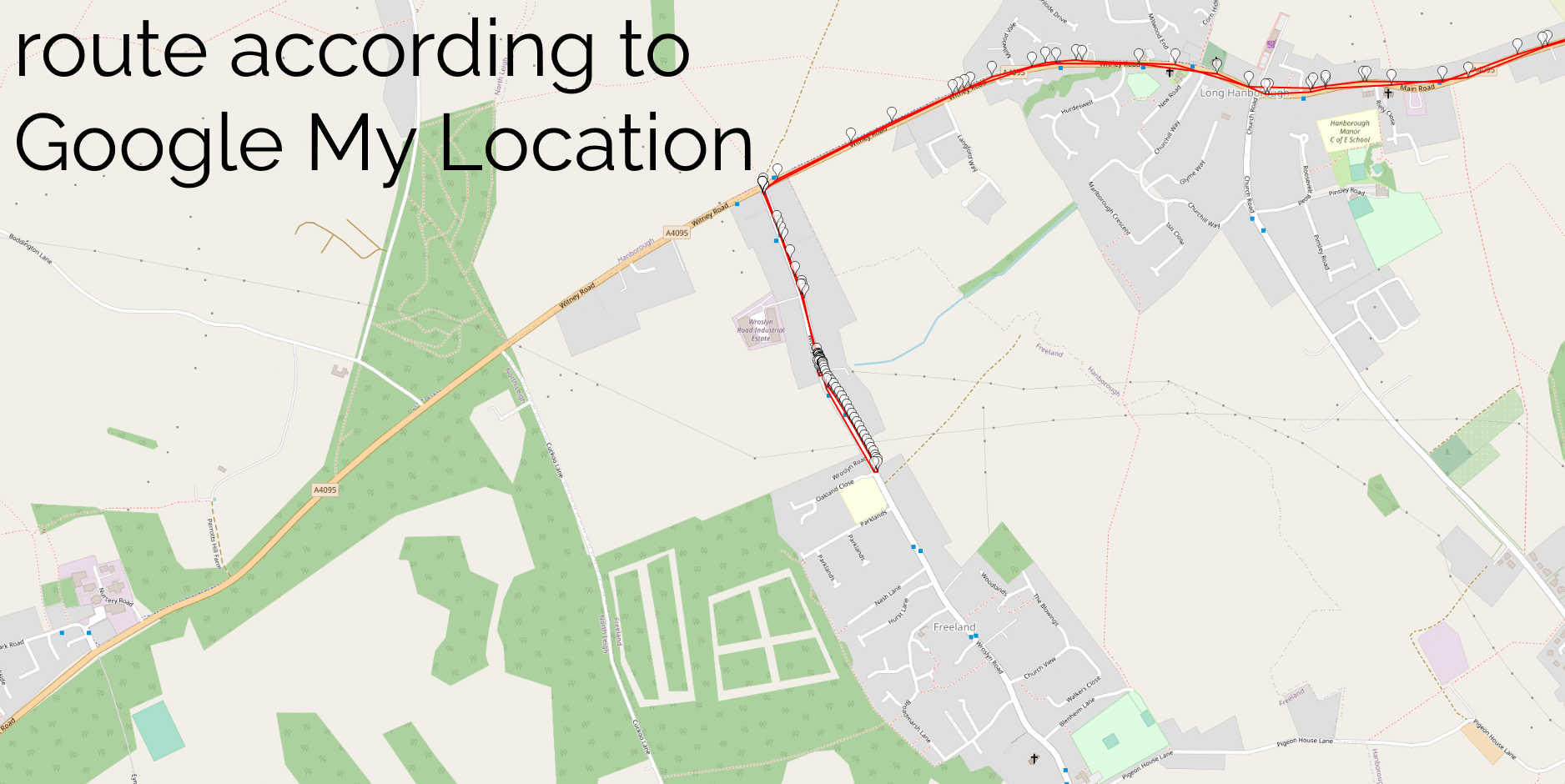
I overlaid randomly-selected Google My Location and GPSr routes to ensure that they coincided, as an accuracy-test. It’s interesting to
note that my GPSr points cluster when I was moving slower, suggesting it polls on a timer. Conversely Google’s points cluster
when I was using data (can you see the bit where I used a chat app), suggesting that Google Location Services ramps up the accuracy and poll frequency when you’re actively
using your device.
I assumed that my algorithm would detect all of my actual geohash finds, and yes: all of these appeared as-expected in my results. This was a good confirmation that my approach
worked.
And, crucially: about a dozen additional candidate points showed up in my search. Most of these – listed at the end of this post – were 50m+ away from the hashpoint and
involved me driving or cycling past on a nearby road… but one hashpoint stuck out.
Hashing by accident
We all had our roles to play in our trip to Edinburgh. Tom… was our pack mule.
In August 2015 we took a trip up to Edinburgh to see a play of Ruth‘s brother Robin‘s. I don’t remember
much about the play because I was on keeping-the-toddler-entertained duty and so had to excuse myself pretty early on. After the play we drove South, dropping Tom off at Lanark station.
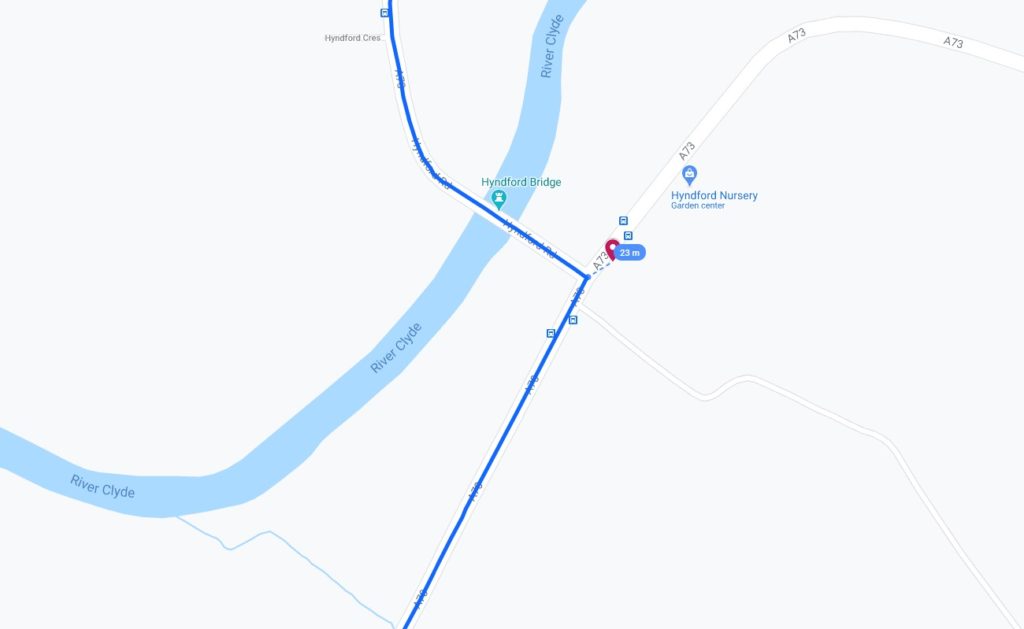
We exited Lanark via the Hyndford Bridge… which is – according to the map – tantalisingly-close to the 2015-08-22 55 -3
hashpoint: only about 23 metres away!
Google puts the centre of the road I drove down only 23m from the 2015-08-22 55 -3 hashpoint (of course, I was actually driving on the near side of the road and may have been closer
still).
That doesn’t feel quite close enough to justify retroactively claiming the geohash, tempting though it would be to use it as a vehicle to my easy geohash ribbon. Google doesn’t provide error bars for their exported location data so I can’t draw a circle of uncertainty,
but it seems unlikely that I passed through this very close hashpoint.
Pity. But a fun exercise. This was the nearest of my near misses, but plenty more turned up in my search, too:
2013-09-28 54 -2 (9,000m)
Near a campsite on the River Eden. I drove past on the M6 with Ruth on the way to Loch Lomond for a mini-break to celebrate our sixth anniversary. I was never more than 9,000 metres
from the hashpoint, but Google clearly had a moment when it couldn’t get good satellite signal and tries to trilaterate my position from cell masts and coincidentally guessed, for a
few seconds, that I was much closer. There are a few such erroneous points in my data but they’re pretty obvious and easy to spot, so my manual filtering process caught them.
2019-09-13 52 -0 (719m)
A600, near Cardington Airstrip, south of Bedford. I drove past on the A421 on my way to Three Rings‘ “GDPR Camp”, which was more fun than it sounds, I promise.
2014-03-29 53 -1 (630m)
Spen Farm, near Bramham Interchange on the A1(M). I drove past while heading to the Nightline Association Conference to talk about Three Rings. Curiously, I came much closer to the hashpoint the previous week when I drove a neighbouring road on my way to York for my friend
Matt’s wedding.
2020-05-06 51 -1 (346m)
Inside Kidlington Police Station! Short of getting arrested, I can’t imagine how I’d easily have gotten to this one, but it’s moot anyway because I didn’t try! I’d taken the day off
work to help with child-wrangling (as our normal childcare provisions had been scrambled by COVID-19), and at some point during the day we took a walk and came somewhat near to the
hashpoint.
2016-02-05 51 -1 (340m)
Garden of a house on The Moors, Kidlington. I drove past (twice) on my way to and from the kids’ old nursery. Bonus fact: the house directly opposite the one whose garden contained
the hashpoint is a house that I looked at buying (and visited), once, but didn’t think it was worth the asking price.
2017-08-30 51 -1 (318m)
St. Frieswide Farm, between Oxford and Kidlington. I cycled past on Banbury Road twice – once on my way to and once on my way from work.
2015-01-25 51 -1 (314m)
Templar Road, Cutteslowe, Oxford. I’ve cycled and driven along this road many times, but on the day in question the closest I came was cycling past on nearby Banbury Road while on the
way to work.
2018-01-28 51 -1 (198m)
Stratfield Brake, Kidlington. I took our youngest by bike trailer this morning to his Monkey Music class: normally at this point in history Ruth would have been the one to take him,
but she had a work-related event that she couldn’t miss in the morning. I cycled right by the entrance to this nature reserve: it could have been an ideal location for a geohash!
2014-01-24 51 -1 (114m)
On the Marston Cyclepath. I used to cycle along this route on the way to and from work most days back when I lived in Marston, but by 2014 I lived in Kidlington and so I’d only cycle
past the end of it. So it was that I cycled past the Linacre College of the path, around 114m away from the hashpoint, on this day.
2015-06-10 51 -1 (112m)
Meadow near Peartree Interchange, Oxford. I stopped at the filling station on the opposite side of the roundabout, presumably to refuel a car.
2020-02-27 51 -1 (70m)
This was a genuine attempt at a hashpoint that I failed to reach and was so sad about that I never bothered to finish writing up. The hashpoint was very close (but just out of sight
of, it turns out) a geocache I’d hidden in the vicinity, and I was hopeful that I might be able to score the most-epic/demonstrable déjà vu/hash collision
achievement ever, not least because I had pre-existing video evidence that I’d been at the
coordinates before! Unfortunately it wasn’t to be: I had inadequate footwear for the heavy rains that had fallen in the days that preceded the expedition and I was in a hurry to get
home, get changed, and go catch a train to go and see the Goo Goo Dolls in concert. So I gave up and quit the expedition. This turned out to be the right decision: going to
the concert one of the last “normal” activities I got to do before the COVID-19 lockdown made everybody’s lives weird.
2014-05-23 51 -1 (61m)
White Way, Kidlington, near the Bicester Road to Green Road footpath. I passed close by while cycling to work, but I’ve since walked through this hashpoint many times: it’s on a route
that our eldest sometimes used to take when walking home from her school! With the exception only of the very-near-miss in Lanark, this was my nearest “near miss”.
No silly grin, but coincidentally – perhaps by accident – I took a picture out of the car window shortly after we passed the hashpoint. This is what Lanark looks like when you drive
through it in the rain.