Israel has acknowledged that its recent airstrikes against Hamas were a
real-time response to an ongoing cyberattack. From Twitter:
CLEARED FOR RELEASE: We thwarted an attempted Hamas cyber offensive against Israeli targets. Following our successful cyber defensive operation, we targeted a building where the
Hamas cyber operatives work.
I expect this sort of thing to happen more — not against major countries, but by larger countries against smaller powers. Cyberattacks are too much of a nation-state equalizer
otherwise.
I doubt that this is actually the first “kinetic” retaliation to a cyber attack; however it’s probably the first one to be openly acknowledged by either of the parties
involves. Schneier’s observation that cyberwarfare is an equaliser is correct and it’s exactly why a savvy nation-state would consider this kind of response… but let’s not forget that
such cyberattacks are only as viable as they are because nation-states favour cyber-offense over cuber-defence in the first place: they’re interested in building 0-day weapons that they
can use against their enemies (and their own citizens) and this entire approach runs counter to the idea of improving defensive security.
From a G7 meeting of interior ministers in Paris this month, an “outcome document“:
Encourage Internet companies to establish lawful access solutions for their products and services, including data that is encrypted, for law enforcement and competent authorities
to access digital evidence, when it is removed or hosted on IT servers located abroad or encrypted, without imposing any particular technology and while ensuring that assistance
requested from internet companies is underpinned by the rule law and due process protection. Some G7 countries highlight the importance of not prohibiting, limiting, or weakening
encryption;
There is a weird belief amongst policy makers that hacking an encryption system’s key management system is fundamentally different than hacking the system’s encryption algorithm.
The difference is only technical; the effect is the same. Both are ways of weakening encryption.
The G7’s proposal to encourage encryption backdoors demonstrates two unsurprising things about the politicians in attendance, including that:
They’re unwilling to attempt to force Internet companies to add backdoors (e.g. via legislation, fines, etc.), making their resolution functionally toothless, and
More-importantly: they continue to fail to understand what encryption is and how it works.
Somehow, then, this outcome document simultaneously manages to both go too-far (for a safe and secure cryptographic landscape for everyday users) and not-far-enough (for law enforcement
agencies that are in favour of backdoors, despite their huge flaws, to actually gain any benefit). Worst of both worlds, then.
Needless to say, I favour not attempting to weaken encryption, because such measures (a) don’t work against foreign powers, terrorist groups, and hardened criminals and (b)
do weaken the personal security of law-abiding citizens and companies (who can then become victims of the former group). “Backdoors”, however phrased, are a terrible idea.
“the local part of my email address is just the letter ‘d’ by itself, which means microsoft has imposed the interesting restriction that my randomly generated password cannot
contain the letter ‘d’”
the local part of my email address is just the letter 'd' by itself, which means microsoft has imposed the interesting restriction that my randomly generated password cannot contain
the letter 'd' pic.twitter.com/tqTklyotTj
@notrevenant@PWtoostrong you wouldn’t believe how often I’m told I’m not allowed to use the
letter “Q” in passwords, because “my password mustn’t contain my surname”. O_o
In a blog post, cryptographer Matthew Green summarized the technical problems
with this GCHQ proposal. Basically, making this backdoor work requires not only changing the cloud computers that oversee communications, but it also means changing the client program
on everyone’s phone and computer. And that change makes all of those systems less secure. Levy and Robinson make a big deal of the fact that their backdoor would only be targeted
against specific individuals and their communications, but it’s still a general backdoor that could be
used against anybody.
The basic problem is that a backdoor is a technical capability — a vulnerability — that is available to anyone who knows about it and has access to it. Surrounding that vulnerability
is a procedural system that tries to limit access to that capability. Computers, especially internet-connected computers, are inherently hackable, limiting the effectiveness of any
procedures. The best defense is to not have the vulnerability at all.
…
Lest we ever forget why security backdoors, however weasely well-worded, are a terrible idea, we’ve got Schneier calling them out. Spooks in democratic nations the
world over keep coming up with “innovative” suggestions like this one from GCHQ but they keep solving the same problem, the technical problem of key distribution or
key weakening or whatever it is that they want to achieve this week, without solving the actual underlying problem which is that any weakness introduced to a secure
system, even a weakness that was created outwardly for the benefit of the “good guys”, can and eventually will be used by the “bad guys” too.
Furthermore: any known weakness introduced into a system for the purpose of helping the “good guys” will result in the distrust of that system by the people they’re trying to
catch. It’s pretty trivial for criminals, foreign agents and terrorists to switch from networks that their enemies have rooted to networks that they (presumably) haven’t, which tends to
mean a drift towards open-source security systems. Ultimately, any backdoor that gets used in a country with transparent judicial processes becomes effectively public
knowledge, and ceases to be useful for the “good guys” any more. Only the non-criminals suffer, in the long run.
An open source checklist of resources designed to improve your online privacy and security. Check things off to keep track as you go.
…
I’m pretty impressed with this resource. It’s a little US-centric and I would have put the suggestions into a different order, but many of the ideas on it are very good and are
presented in a way that makes them accessible to a wide audience.
2004 called, @virginmedia. They asked me to remind you that maximum password lengths and prohibiting pasting makes your security worse, not better. @PWTooStrong
In more detail:
Why would you set an upper limit on security? It can’t be for space/capacity reasons because you’re hashing my password anyway in accordance with best security practice, right?
(Right?)
Why would you exclude spaces, punctuation, and other “special” characters? If you’re afraid of injection attacks, you’re doing escaping wrong (and again: aren’t you hashing
anyway?). Or are you just afraid that one of your users might pick a strong password? Same for the “starts with a letter” limitation.
Composition rules like “doesn’t contain the same character twice in a row” reflects wooly thinking on that part of your IT team: you’re saying for example that “abababab” is
more-secure than “abccefgh”. Consider using exclusion lists/blacklists for known-compromised/common passwords e.g. with HaveIBeenPwned
and/or use entropy-based rather than composition-based rules e.g. with zxcvbn.
Disallowing pasting into password fields does nothing to prevent brute-force/automated attacks but frustrates users who use password managers (by forcing them to retype their
passwords, you may actually be reducing their security as well as increasing the likelihood of mistakes) and can have an impact on accessibility too.
Counterarguments I anticipate: (a) it’s for your security – no it’s not; go read any of the literature from the last decade and a half, (b) it’s necessary for integration with a
legacy system – that doesn’t fill me with confidence: if your legacy system is reducing your security, you need to update or replace your legacy system or else you’re setting yourself
up to be the next Marriott, Equifax, or Friend Finder Network.
I’m a huge fan of multifactor authentication. If you’re using it, you’re probably familiar with using an app on your phone (or receiving a text or email) in addition to a username and
password when logging in to a service like your email, social network, or a bank. If you’re not using it then, well, you should be.
Using an app in addition to your username and password, wherever you can, may be the single biggest step you can make to improving your personal digital security.
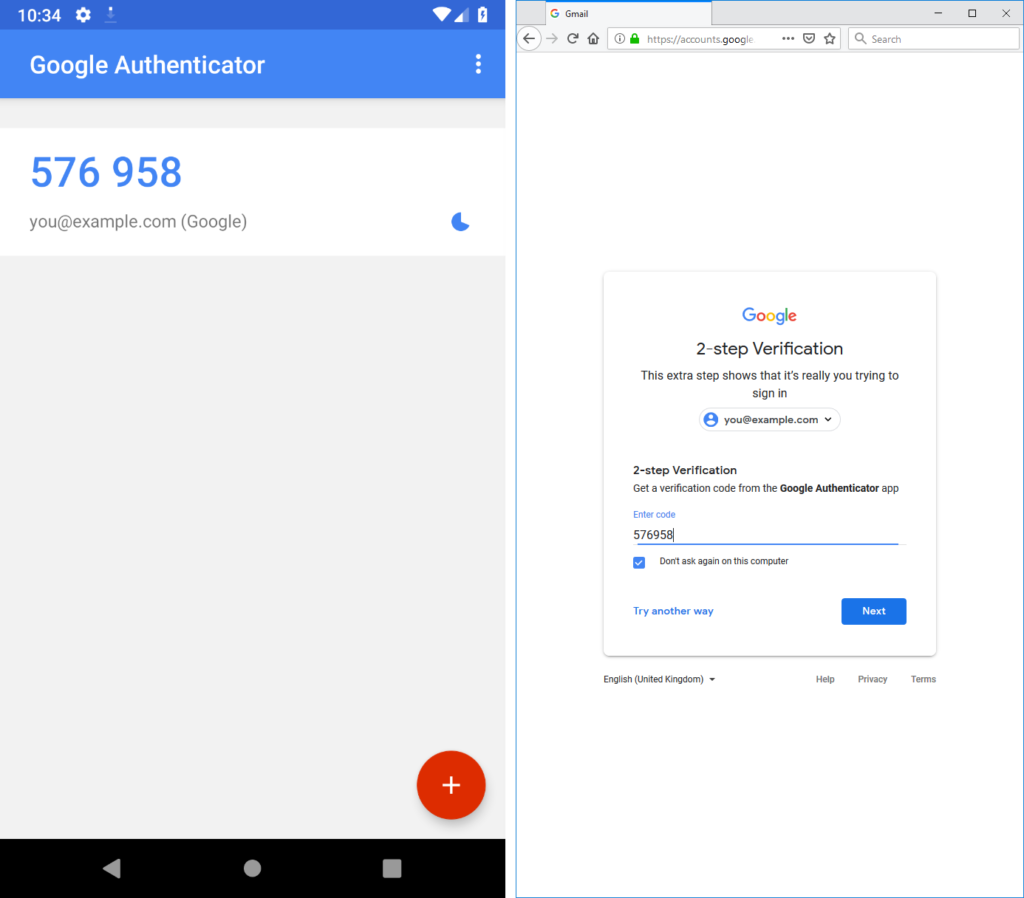
Ruth recently had a problem when she lost her phone and couldn’t connect to a service for which she usually used an authenticator app like the
one pictured above, so I thought I’d share with you my personal strategy for managing multifactor authentication, in case it’s of any use to anybody else. After all: the issue of
not-having-the-right-second-factor-to-hand has happened to me before, it’s certainly now happened to Ruth, and it’s probably
something that’s happened to other people I know by now, too.
It could happen to anybody. What’s your authentication plan?
Here’s my strategy:
Favour fewer different multifactor solutions. Instead of using e.g. text messaging for one, an app for another, a different app for a third, a hardware token
for a fourth, and so on, try to find the fewest number of different solutions that work for your personal digital life. This makes backing up and maintenance easier.
I use RFC6238/TOTP (better known as “Google Authenticator”) for
almost all second factor purposes: the only exceptions are my online bank (who use a proprietary variant of RFC6238 that I’ve not finished reverse-engineering) and Steam (who use a
proprietary implementation of RFC6238 with a larger character set, for some reason, in their Steam Guard app).
Have a backup plan. Here’s the important bit. If you use your phone to authenticate, and you lose access to your phone for a period of time (broken, lost, stolen, out
of battery, in use by a small child playing a game), you can’t authenticate. That’s why it’s important that you have a backup plan.
That’s probably more backup devices than you need, but YMMV.
Some suggested backup strategies to consider (slightly biased towards TOTP):
Multiple devices: (Assuming you’re using TOTP or something like it) there’s nothing to stop you
setting up multiple devices to access the same account. Depending on how the service you’re accessing provides the code you need to set it up, you might feel like you have to
set them all up at the same time, but that’s not strictly true: there’s another way…
Consider setting up a backdoor: Some systems will allow you to print e.g. a set of “backup codes” and store them in a safe place for later use should you lose access
to your second factor. Depending on the other strategies you employ, you should consider doing this: for most (normal) people, this could be the single safest way to retain access to
your account in the event that you lose access to your second factor. Either way, you should understand the backdoors available: if your online bank’s policy is to email you
replacement credentials on-demand then your online bank account’s security is only as good as your email account’s security: follow the chain to work out where the weak links are.
Retain a copy of the code: The code you’re given to configure your device remains valid forever: indeed, the way that it works is that the
service provider retains a copy of the same code so they can generate numbers at the same time as you, and thus check that you’re generating the same numbers as them. If you keep a
copy of the backup code (somewhere very safe!) you can set up any device you want, whenever you want. Personally, I keep copies of all TOTP configuration codes in my password safe (you’re using a password safe, right?).
Set up the infrastructure what works for you: To maximise my logging-on convenience, I have my password safe enter my TOTP numbers for me: I’m using KeeOTP for KeePass, but since 2016 LastPass users can do basically the
same thing. I’ve also implemented my own TOTP client in Ruby to run on desktop computers I control (just be careful to protect the secrets file), because sometimes you just want a
command-line solution. The code’s below, and I think you’ll agree that it’s simple enough that you can audit it for your own safety too.
I’ve occasionally been asked whether my approach actually yields me any of the benefits of two-factor authentication. After all, people say, aren’t I weakening its benefits by storing
the TOTP generation key in the same place as my usernames and passwords rather than restricting it to my mobile
device. This is true, and it is weaker to do this than to keep the two separately, but it’s not true to say that all of the benefits are negated: replay attacks by an
attacker who intercepts a password are mitigated by this approach, for example, and these are a far more-common vector for identity theft than the theft and decryption of password
safes.
Everybody has to make their own decisions on the balance of their convenience versus their security, but for me the sweet spot comes here: in preventing many of the most-common attacks
against the kinds of accounts that I use and reinforcing my existing username/strong-unique-passwords approach without preventing me from getting stuff done. You’ll have to make your
own decisions, but if you take one thing away from this, let it be that there’s nothing to stop you having multiple ways to produce TOTP/Google Authenticator credentials, and you should consider doing so.
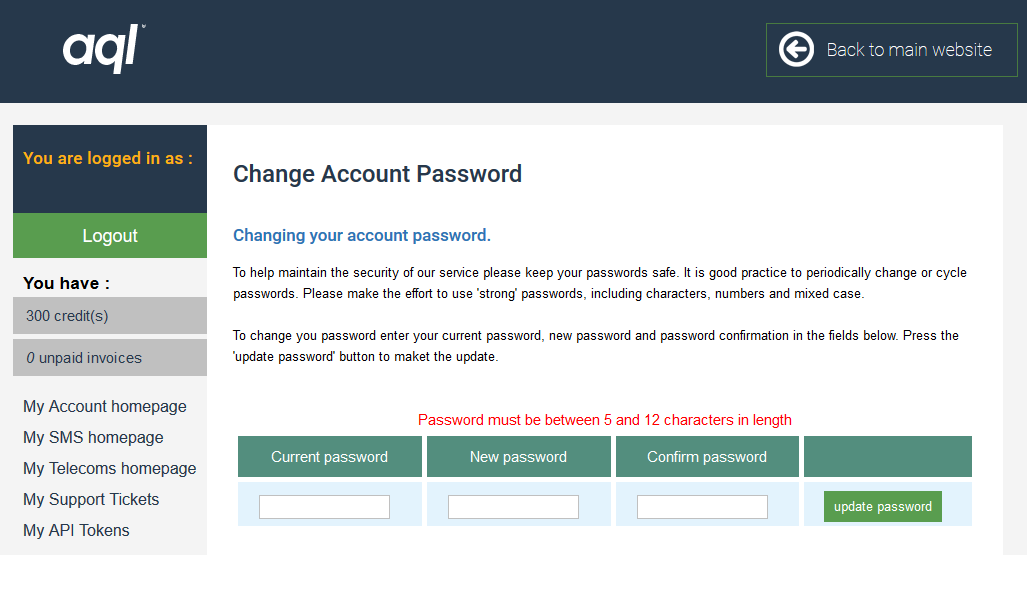
Hey @aqldotcom: why must my password for your enterprise telecommunications platform be no longer than 12 characters? Are you worried my #passwordistoostrong? CC @pwtoostrong
Did you install EFF’s brilliant Privacy Badger or any other smart HTTP Cookie management tool? Or did you simply pick the privacy preference in your browser that ignores
all third-party cookies? Did many websites you visit annoy you with permission-to-use-cookies pop-ups because of European legislation?
Guess what, it’s all been useless.
Hamburg university researchers have examined closely how web browsers implement
so-called TLS session resumption and how the top million popular websites make use of that feature. They found that 80% of websites make a correct use, unsuitable for tracking
repeat visitors — just resuming an existing session within the last ten minutes.
Unfortunately though, Google is present on 80% of these websites in form of Analytics, Fonts or other third-party inclusions. And among 10% of sites that do not respect reasonable
resumption times, Google sticks out as one of the most greedy ones — it allows for a web browser to stay offline for over a day, and still be recognized as the same web browser the
next day. Considering that it is nearly impossible to surf the web without accessing some Google content, this means that Google can track all your surfing habits without any need for
HTTP Cookies!
As Facebook isn’t as pervasively present in all of the web, it went even further. It is enough for you to visit any website bearing a Like button every second day to allow Facebook to
profile you, even if you never dreamt of logging into that service. Could it be our researchers just caught these companies with their hands deep in the cookie jar (pun intended)? For how long have they been
collecting user data this way?
…
Somewhat conspiracy-theory-like take on an actual, real privacy issue: the fact that TLS makes tracking pretty easy even
without cookies. If you thought my 301-based cookieless tracking was clever, this is cleverer. And harder to detect, to boot.
Remember “cybersecurity”? Mysterious hooded computer guys doing mysterious hooded computer guy .. things! Who knows what kind of naughty digital mischief they might be up to?
Unfortunately, we now live in a world where this kind of digital mischief is literally rewriting the world’s history. For proof of that, you need look no further than…
A good summary of the worst of the commonplace (non-spear) phishing attacks we’re seeing these days and why 2FA is positively, absolutely what you need (in addition to a
password manager) these days.
The Five Eyes — the intelligence consortium of the rich English-speaking countries (the US, Canada, the UK, Australia, and New Zealand) — have issued a “Statement of Principles on
Access to Evidence and Encryption” where they claim their needs for surveillance outweigh everyone’s needs for security and privacy. …the increasing use and sophistication of certain…
How many times must security professionals point out that there’s no such thing as a secure backdoor before governments actually listen? If you make a weakness in cryptography to make
it easier for the “good guys” – your spies and law enforcement – then either (a) a foreign or enemy power will find the backdoor too, making everybody less-secure than
before, or (b) people will use different cryptographic systems: ones which seem less-likely to have been backdoored.
Solving the information black hole is a challenging and important problem of our time. But backdoors surely aren’t the best solution, right?
When prompted to think about the way hackers will shape the future of great power war, we are wont to imagine grand catastrophes: F-35s grounded by onboard computer failures, Aegis
BMD systems failing to launch seconds before Chinese missiles arrive, looks of shock at Space Command as American surveillance satellites start careening towards the Earth–stuff like
that. This is the sort of thing that fills the opening chapters of Peter Singer and August Cole’s Ghost Fleet. [1] The catastrophes
I always imagine, however, are a bit different than this. The hacking campaigns I envision would be low-key, localized, and fairly low-tech. A cyber-ops campaign does not
need to disable key weapon systems to devastate the other side’s war effort. It will be enough to increase the fear and friction enemy leaders face to tip the balance of victory and defeat. Singer and company are
not wrong to draw inspiration from technological change; nor are they wrong to attempt to imagine operations with few historical precedents. But that isn’t my style. When asked to
ponder the shape of cyber-war, my impulse is to look first at the kind of thing hackers are doing today and ask how these tactics might be applied in a time of war.
In a report Cancian wrote for
the Center for Strategic and International Studies on how great powers adapt to tactical and strategic surprise, Cancian sketched out twelve “vignettes” of potential technological
or strategic shocks to make his abstract points a bit more concrete. Here is how Cancian imagines an “asymmetric cyber-attack” launched by the PRC against the United States Military:
The U.S. secretary of defense had wondered this past week when the other shoe would drop. Finally, it had, though the U.S. military would be unable to respond
effectively for a while.
The scope and detail of the attack, not to mention its sheer audacity, had earned the grudging respect of the secretary. Years of worry about a possible Chinese “Assassin’s Mace”-a
silver bullet super-weapon capable of disabling key parts of the American military-turned out to be focused on the wrong thing.
The cyber attacks varied. Sailors stationed at the 7th Fleet’ s homeport in Japan awoke one day to find their financial accounts, and those of their dependents, empty. Checking,
savings, retirement funds: simply gone. The Marines based on Okinawa were under virtual siege by the populace, whose simmering resentment at their presence had boiled over after a
YouTube video posted under the account of a Marine stationed there had gone viral. The video featured a dozen Marines drunkenly gang-raping two teenaged Okinawan girls. The video
was vivid, the girls’ cries heart-wrenching the cheers of Marines sickening And all of it fake. The National Security Agency’s initial analysis of the video had uncovered digital
fingerprints showing that it was a computer-assisted lie, and could prove that the Marine’s account under which it had been posted was hacked. But the damage had been done.
There was the commanding officer of Edwards Air Force Base whose Internet browser history had been posted on the squadron’s Facebook page. His command turned on him as a pervert;
his weak protestations that he had not visited most of the posted links could not counter his admission that he had, in fact, trafficked some of them. Lies mixed with the truth.
Soldiers at Fort Sill were at each other’s throats thanks to a series of text messages that allegedly unearthed an adultery ring on base.
The variations elsewhere were endless. Marines suddenly owed hundreds of thousands of dollars on credit lines they had never opened; sailors received death threats on their Twitter
feeds; spouses and female service members had private pictures of themselves plastered across the Internet; older service members received notifications about cancerous conditions
discovered in their latest physical.
Leadership was not exempt. Under the hashtag # PACOMMUSTGO a dozen women allegedly described harassment by the commander of Pacific command. Editorial writers demanded that, under
the administration’s “zero tolerance” policy, he step aside while Congress held hearings.
There was not an American service member or dependent whose life had not been digitally turned upside down. In response, the secretary had declared “an operational pause,” directing
units to stand down until things were sorted out.
Then, China had made its move, flooding the South China Sea with its conventional forces, enforcing a sea and air identification zone there, and blockading Taiwan. But the secretary
could only respond weakly with a few air patrols and diversions of ships already at sea. Word was coming in through back channels that the Taiwanese government, suddenly stripped of
its most ardent defender, was already considering capitulation.[2]
A century ago, one of the world’s first hackers used Morse code insults to disrupt a public demo of Marconi’s wireless telegraph
LATE one June afternoon in 1903 a hush fell across an expectant audience in the Royal Institution’s celebrated lecture theatre in London. Before the crowd, the physicist John
Ambrose Fleming was adjusting arcane apparatus as he prepared to demonstrate an emerging technological wonder: a long-range wireless communication system developed by his boss, the
Italian radio pioneer Guglielmo Marconi. The aim was to showcase publicly for the first time that Morse code messages could be sent wirelessly over long distances. Around 300 miles
away, Marconi was preparing to send a signal to London from a clifftop station in Poldhu, Cornwall, UK.
Yet before the demonstration could begin, the apparatus in the lecture theatre began to tap out a message. At first, it spelled out just one word repeated over and over. Then it
changed into a facetious poem accusing Marconi of “diddling the public”. Their demonstration had been hacked – and this was more than 100 years before the mischief playing out on
the internet today. Who was the Royal Institution hacker? How did the cheeky messages get there? And why?
…
An early example of hacking and a great metaphor for what would later become hacker-culture, found in the history of the wireless telegraph.
I’ve generally been pretty defensive of Microsoft Edge, the default web browser in Windows 10. Unlike its much-mocked
predecessor Internet Explorer, Edge is fast, clean, modern, and boasts good standards-compliance: all of the things that
Internet Explorer infamously failed at! I was genuinely surprised to see Edge fail to gain a significant market share in its first few years: it seemed to me
that everyday Windows users installed other browsers (mostly Chrome, which is causing its own problems) specifically because Internet Explorer was
so terrible, and that once their default browser was replaced with something moderately-good this would no longer be the case. But that’s not what’s happened. Maybe it’s because Edge’s
branding is too-remiscient of its terrible
predecessor or maybe just because Windows users have grown culturally-used to the idea that the first thing they should do on a new PC is download a different browser, but
whatever the reason, Edge is neglected. And for the most part, I’ve argued, that’s a shame.
I ranted at an Edge developer I met at a conference, once, about Edge’s weak TLS debugging tools that couldn’t identify an OCSP stapling issue that only affected Edge, but I thought
that was the worse of its bugs… until now…
But I’ve changed my tune this week after doing some research that demonstrates that a long-standing security issue of Internet Explorer is alive and well in Edge. This particular issue,
billed as a “feature” by Microsoft, is deliberately absent from virtually every other web browser.
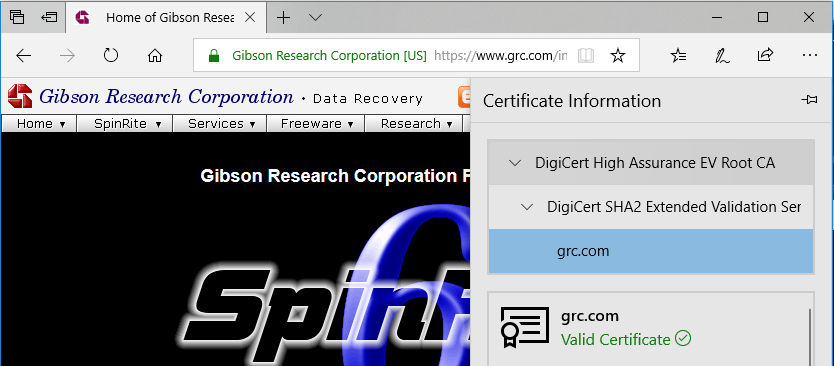
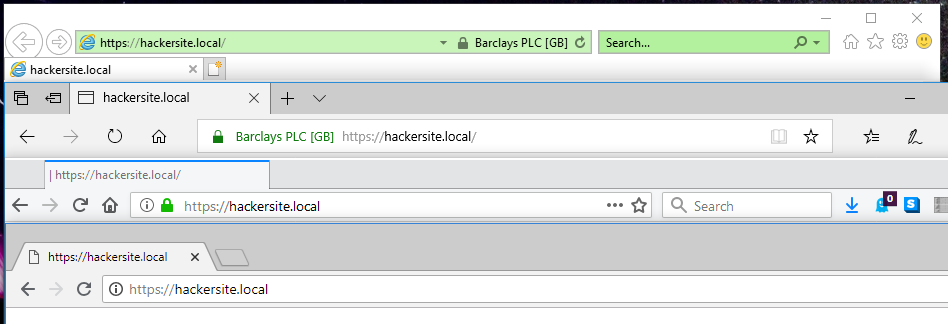
About 5 years ago, Steve Gibson observed a special feature of EV (Extended Validation) SSL certificates used on HTTPS websites: that their
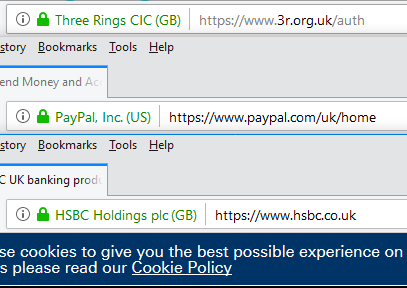
extra-special “green bar”/company name feature only appears if the root CA (certificate authority) is among the browser’s default trust store for EV certificate signing. That’s
a pretty-cool feature! It means that if you’re on a website where you’d expect to see a “green bar”, like Three Rings, PayPal, or HSBC, then if you don’t see the green bar one day it most-likely means that your
connection is being intercepted in the kind of way I described earlier this year, and everything you see or send including
passwords and credit card numbers could be at risk. This could be malicious software (or nonmalicious software: some antivirus software breaks EV certificates!) or it could be your friendly local
network admin’s middlebox (you trust your IT team, right?), but either way: at least you have a chance of noticing, right?
Firefox, like most browsers, shows the company name in the address bar when valid EV certificates are presented, and hides it when the validity of that certificate is put into
question by e.g. network sniffing tools set up by your IT department.
Browsers requiring that the EV certificate be signed by a one of a trusted list of CAs and not allowing that list to be manipulated (short of recompiling the browser from
scratch) is a great feature that – were it properly publicised and supported by good user interface design, which it isn’t – would go a long way to protecting web users from unwanted
surveillance by network administrators working for their employers, Internet service providers, and governments. Great! Except Internet Explorer went and fucked it up. As Gibson
reported, not only does Internet Explorer ignore the rule of not allowing administrators to override the contents of the trusted list but Microsoft even provides a tool to help them do it!
From top to bottom: Internet Explorer 11, Edge 17, Firefox 61, Chrome 68. Only Internet Explorer and Edge show the (illegitimate) certificate for “Barclays PLC”. Sorry, Barclays; I
had to spoof somebody.
I decided to replicate Gibson’s experiment to confirm his results with today’s browsers: I was also interested to see whether Edge had resolved this problem in Internet Explorer. My
full code and configuration can be found here. As is doubtless clear from the title of this post and the
screenshot above, Edge failed the test: it exhibits exactly the same troubling behaviour as Internet Explorer.
Thanks, Microsoft.
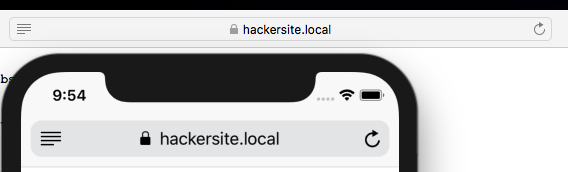
I also tried Safari (both on MacOS, above, and iOS, below) and it behaved as the other non-Microsoft browsers do (i.e. arguably more-correctly than IE or Edge).
I shan’t for a moment pretend that our current certification model isn’t without it’s problems – it’s deeply flawed; more on that in a future post – but that doesn’t give anybody an
excuse to get away with making it worse. When it became apparent that Internet Explorer was affected by the “feature” described above, we all collectively rolled our eyes
because we didn’t expect better of everybody’s least-favourite web browser. But for Edge to inherit this deliberate-fault, despite every other browser (even those that share its
certificate store) going in the opposite direction, is just insulting.
Many online accounts allow you to supplement your password with a second form of identification, which can prevent some prevalent attacks. The second factors you can use to identify yourself include authenticator apps on your phone, which generate codes that change every 30 seconds, and
security keys, small pieces of hardware similar in size and shape to USB drives. Since innovations that can actually improve the security of your online accounts are rare, there has
been a great deal of well-deserved enthusiasm for two-factor authentication (as well as for password managers, which make it easy to use a different random password for every one of
your online accounts.) These are technologies more people should be using.
However, in trying to persuade users to adopt second factors, advocates sometimes forget to disclose that all security measures have trade-offs . As second factors reduce the
risk of some attacks, they also introduce new risks. One risk is that you could be locked out of your account when you lose your second factor, which may be when you need it the most.
Another is that if you expect second factors to protect you from those attacks that they can not prevent, you may become more vulnerable to the those attacks.
Before you require a second factor to login to your accounts, you should understand the risks, have a recovery plan for when you lose your second factor(s), and know the tricks
attackers may use to defeat two-factor authentication.
…
A well-examined exploration of some of the risks of employing two-factor authentication in your everyday life. I maintain that it’s still highly-worthwhile and everybody should do so,
but it’s important that you know what you need to do in the event that you can’t access your two-factor device (and, ideally, have a backup solution in place): personally, I prefer
TOTP (i.e. app-based) 2FA and I share my generation keys
between my mobile device, my password safe (I’ll write a blog post about why this is controversial but why I think it’s a good idea anyway!), and in a console application I wrote
(because selfdogfooding etc.).