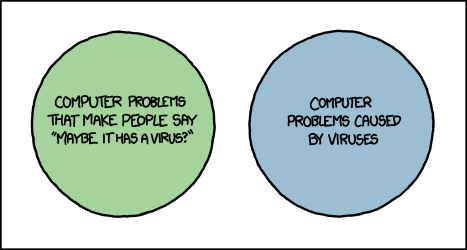
VPNs have long been essential online tools that provide security, freedom, and most importantly, privacy. Each day, hundreds of millions of internet users connect to a VPN to
prevent their online activities from being tracked and monitored so that they can privately access web resources. In other words, the very purpose of a VPN is to prevent the
type of surveillance that Google engages in on a massive and unprecedented scale.
Google knows this, and in their whitepaper discussing VPN by Google One, Google acknowledges that VPN usage is becoming mainstream and that “up to 25% of all internet users accessed a VPN within the
last month of 2019.” Increasing VPN usage unfortunately poses a significant problem for Google, by making it more difficult to track users across the internet, mine their data, and
target them with advertisements. In short, VPNs undermine Google’s power.
…
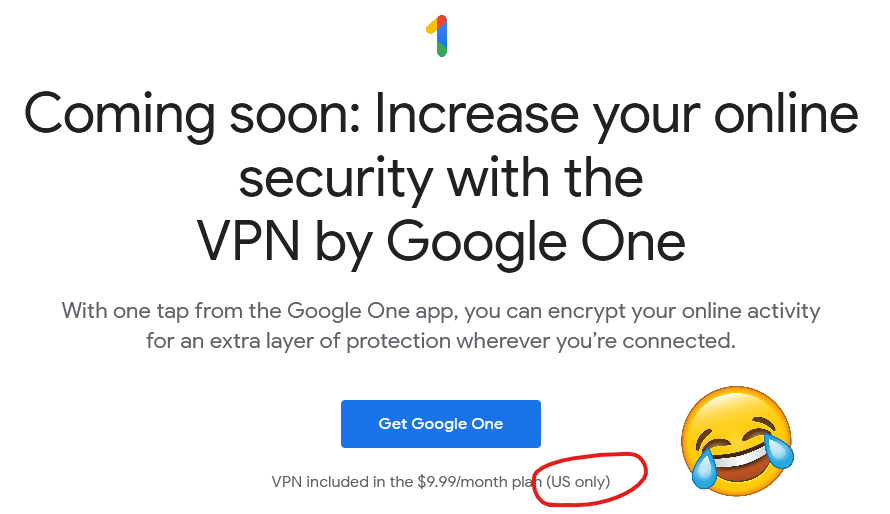
So yeah, it turns out that Google are launching a VPN service. I just checked,
and it’s not available to me anyway because it’s US-only (apparently nobody explained to Google the irony of having a VPN service that’s geofenced), but that’s pretty academic because I wasn’t going to touch it with a barge pole in the first place.
Is it 1 April already, Google?
Google already collect data on your browsing habits if you use their products. And I’m not just talking about Chrome, which of course continues to track you using your Google Account even after you log out and clear your cookies, and Google’s ubiquitous Web
tools, but also the tracking pixels hidden on every other website thanks to Google Analytics, AdWords, reCAPTCHA, Google Fonts, and the like. Sure, you can use e.g. uMatrix to stop all of these (although I’m in need of a
replacement), but that’s not a solution for, y’know, normal people. Container tabs help and you should
absolutely use them, but they don’t quite go far enough. It’s a challenge.
Switch to their VPN, though, and they’re suddenly able to track all of your browsing activity, in any browser on your
device. And probably many of the desktop applications you run, too, as most of them “phone home” for updates or functionality. And because it’s a paid-for VPN service, this data can be instantly linked to your real-world identity. By a company that’s demonstrated its willingness to misuse that data for their own benefit (or for the benefit of overreaching law enforcement agencies). Yeah: no deal,
Google.
Perhaps the only company I’d trust less to provide a VPN service would be Facebook, because you just know they’d be
doing so exclusively to undermine individual privacy. Oh wait;
that’s exactly what they did. Sigh.
I scratched an itch of mine this week and wanted to share the results with you, in case you happen to be one of the few dozen other people on Earth who will cry “finally!” to discover
that this is now a thing.
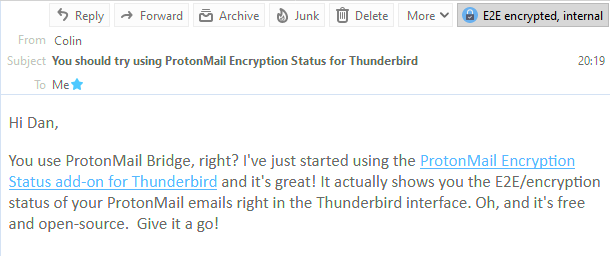
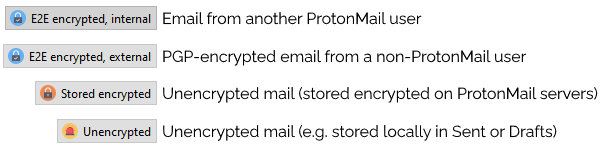
In the top right corner of this email, you can see that it was sent with end-to-end encryption from another ProtonMail user.
I’ve used ProtonMail as my primary personal email provider for about four years, and I love it. Seamless PGP/GPG for proper end-to-end encryption, privacy as standard, etc. At first, I used their web and mobile app interfaces but over time
I’ve come to rediscover my love affair with “proper” email clients, and I’ve been mostly using Thunderbird for my desktop mail. It’s been
great: lightning-fast search, offline capabilities, and thanks to IMAP (provided by ProtonMail Bridge) my mail’s still just as accessible when I fall-back on the web or mobile clients because I’m out and about.
But the one thing this set-up lacked was the ability to easily see which emails had been delivered encrypted versus those which had merely been delivered “in the clear” (like
most emails) and then encrypted for storage on ProtonMail’s servers. So I fixed it.
There are fundamentally four states a Thunderbird+ProtonMail Bridge email can be in, and here’s how I represent them.
I’ve just released my first ever Thunderbird plugin. If you’re using
ProtonMail Bridge, it adds a notification to the corner of every email to say whether it was encrypted in transit or not. That’s all.
And of course it’s open source with a permissive license (and a doddle to compile using your
standard operating system tools, if you want to build it yourself). If you’re using Thunderbird and ProtonMail Bridge you should give it a whirl. And if you’re not then… maybe you
should consider it?
Everything you see when you use “Inspect Element” was already downloaded to your computer, you just hadn’t asked Chrome to show it to you yet. Just like how the cogs were already in
the watch, you just hadn’t opened it up to look.
But let us dispense with frivolous cog talk. Cheap tricks such as “Inspect Element” are used by programmers to try and understand how the website works. This is ultimately futile:
Nobody can understand how websites work. Unfortunately, it kinda looks like hacking the first time you see it.
A few folks wrote to me to mention something I missed: security.
When you use code you didn’t author, you’re taking a risk. You’re trusting that the third-party code does not have security issues, that the author has good intent.
…
Chris makes a very good point, especially for those developers of the npm install every-damn-thing persuasion: getting an enormous framework that you don’t completely
understand just because you need a small portion of its features is bad security practice. And the target is a juicy one: a bad actor who finds (or introduces) a vulnerability in
a big and widely-used library has a whole lot of power. Security concerns are a major part of why I go vanilla/stdlib where possible.
But as always with security the answer isn’t so clear-cut and simple, and I’d argue that it’s dangerous to encourage people to write their own solutions as a matter of course, for
security reasons. For a start, you should never roll your own cryptographic libraries because
you’re almost certainly going to fuck it up: an undetectable and easy-to-make mistake in your crypto implementation can lead to a catastrophic cascade and completely undermine the value
of your cryptography. If you’re smart enough about crypto to implement crypto properly, you should contribute towards one of the major libraries. And if you’re not smart enough about
crypto (and if you’re not sure, then you’re not), you should use one of those libraries. And even then you should take care to integrate and use it properly: people have been
tripped over before by badly initialised keys or the use of the wrong kind of cipher for their use-case. Crypto
is hard enough that even experts fuck it up and important enough that you can’t afford to get it wrong.
The same rule applies to a much lesser extent to other parts of your application, and especially for beginner developers. Implementing an authentication/authorisation system isn’t
hard, but it’s another thing where getting it wrong can have disastrous consequences. Beginner (and even intermediate) developers routinely make mistakes with this kind of
feature: unhashed, reversibly-encrypted, or incorrectly-hashed (wrong algorithm, no salt, etc.) passwords, badly-thought-out password reset strategies, incompletely applied access
controls, etc. I’m confident that Chris and I would be in agreement that the best approach is for a developer to learn to implement these things properly and then do so. But if
having to learn to implement them properly is a barrier to getting started, I’d rather than a beginner developer instead use a tried-and-tested off-the-shelf like Devise/Warden.
Other examples of things that beginner/intermediate developers sometimes get wrong might be XSS protection and SQL parameter escaping. And again, for languages that don’t have safety features built in, a framework can fill the gap. Rolling your own
DOM whitelisting code for a social application is possible, but using a solution like DOMPurify is almost-certainly going to be more-secure for most developers because, you guessed it, this is another area where it’s
easy to make a mess of things.
My inclination is to adapt Chris’s advice on this issue, to instead say that for the best security:
Ideally: understand what all your code does, for example because you wrote it yourself.
However: if you’re not confident in your ability to implement something securely (and especially with cryptography), use an off-the-shelf library.
If you use a library: use the usual rules (popularity, maintenance cycle, etc.) to filter the list, but be sure to use the library with the smallest possible footprint –
the best library should (a) do only the one specific task you need done, and no more, and (b) be written in a way that lends itself to you learning from it, understanding it, and
hopefully being able to maintain it yourself.
Starting in Edge 82.0.425.0 Canary, a new flag is available.
…
…
This is a good move; a relatively simple innovation that’s sure to help end-user security. If you can’t see what’s different above without following the link through to the original
article, here’s the short version: an upcoming version of Edge will allow you to authorise a specific site to open a particular application to handle a link… without
having to compromise by choosing either to (a) see the security dialog every single time (which teaches users to “just click OK”) or (b) allow the dialog to be suppressed for links that
open a particular application (which makes it easier for bad guys to make poisonous links).
So you’ll be able to, for example, say “slack.com can open Slack for me, but other websites have to ask”. Nice.
I hope that other browser manufacturers follow suit, especially on mobile where the web/web-launched-native-app boundary has never been fuzzier.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
Anticipatory note: based on the traffic I already get to my blog and the keywords people search for, I imagine that some people will end up here looking to
learn “how to become a hacker”. If that’s your goal, you’re probably already asking the wrong question, but I direct you to Eric S. Raymond’s Guide/FAQ on the subject. Good luck.
Few words have seen such mutation of meaning over their lifetimes as the word “silly”. The earliest references, found in Old English, Proto-Germanic, and Old Norse and presumably having
an original root even earlier, meant “happy”. By the end of the 12th century it meant “pious”; by the end of the 13th, “pitiable” or “weak”; only by the late 16th coming to mean
“foolish”; its evolution continues in the present day.
The Monty Python crew were certainly the experts on the contemporary use of the word.
But there’s little so silly as the media-driven evolution of the word “hacker” into something that’s at least a little offensive those of us who probably would be
described as hackers. Let’s take a look.
Hacker
What people think it means
Computer criminal with access to either knowledge or tools which are (or should be) illegal.
What it originally meant
Expert, creative computer programmer; often politically inclined towards information transparency, egalitarianism, anti-authoritarianism, anarchy, and/or decentralisation of
power.
The Past
The earliest recorded uses of the word “hack” had a meaning that is unchanged to this day: to chop or cut, as you might describe hacking down an unruly bramble. There are clear links
between this and the contemporary definition, “to plod away at a repetitive task”. However, it’s less certain how the word came to be associated with the meaning it would come to take
on in the computer labs of 1960s university campuses (the earliest references seem to come from
around April 1955).
There, the word hacker came to describe computer experts who were developing a culture of:
sharing computer resources and code (even to the extent, in extreme
cases, breaking into systems to establish more equal opportunity of access),
learning everything possible about humankind’s new digital frontiers (hacking to learn, not learning to hack)
discovering and advancing the limits of computers: it’s been said that the difference between a non-hacker and a hacker is that a non-hacker asks of a new gadget “what does it do?”,
while a hacker asks “what can I make it do?”
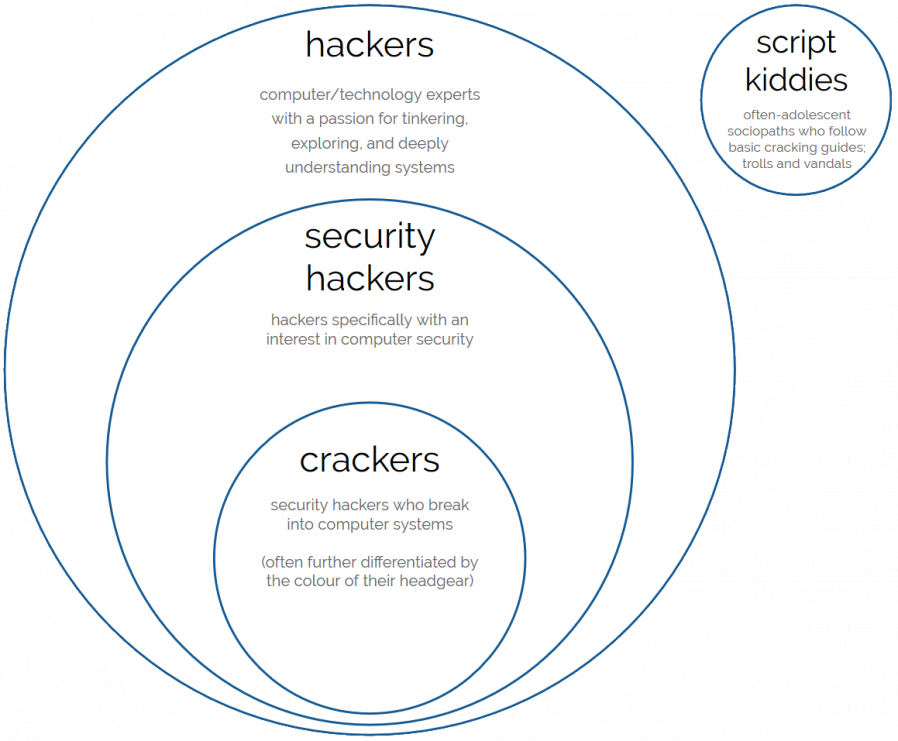
What the media generally refers to as “hackers” would be more-accurately, within the hacker community, be called crackers; a subset of security hackers, in turn a subset of
hackers as a whole. Script kiddies – people who use hacking tools exclusively for mischief without fully understanding what they’re doing – are a separate subset on their own.
It is absolutely possible for hacking, then, to involve no lawbreaking whatsoever. Plenty of hacking involves writing (and sharing) code, reverse-engineering technology and systems you
own or to which you have legitimate access, and pushing the boundaries of what’s possible in terms of software, art, and human-computer interaction. Even among hackers with a specific
interest in computer security, there’s plenty of scope for the legal pursuit of their interests: penetration testing, security research, defensive security, auditing, vulnerability
assessment, developer education… (I didn’t say cyberwarfare because 90% of its
application is of questionable legality, but it is of course a big growth area.)
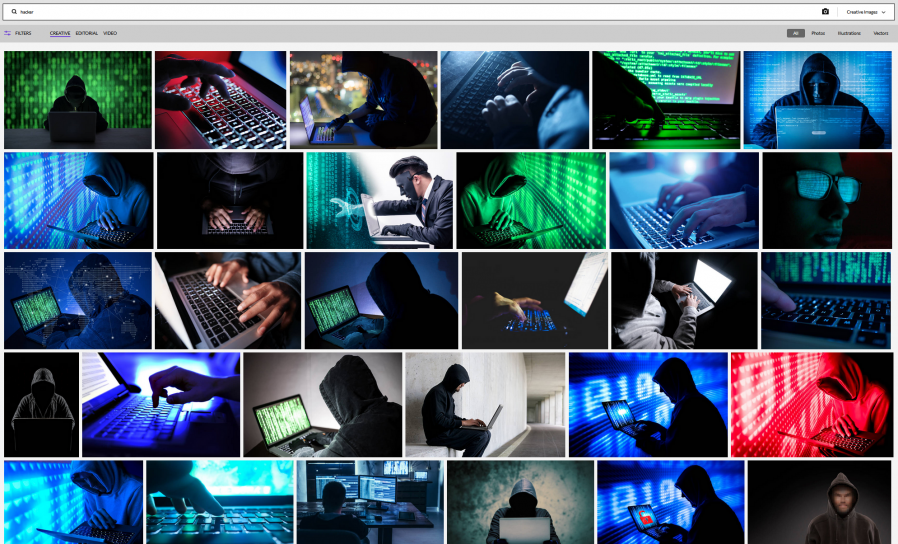
Hackers have a serious image problem, and the best way to see it is to search on your favourite stock photo
site for “hacker”. If you don’t use a laptop in a darkened room, wearing a hoodie and optionally mask and gloves, you’re not a real hacker. Also, 50% of all text should be
green, 40% blue, 10% red.
So what changed? Hackers got famous, and not for the best reasons. A big tipping point came in the early 1980s when hacking group The
414s broke into a number of high-profile computer systems, mostly by using the default password which had never been changed. The six teenagers responsible were arrested by the
FBI but few were charged, and those that were were charged only with minor offences. This was at least in part because
there weren’t yet solid laws under which to prosecute them but also because they were cooperative, apologetic, and for the most part hadn’t caused any real harm. Mostly they’d just been
curious about what they could get access to, and were interested in exploring the systems to which they’d logged-in, and seeing how long they could remain there undetected. These remain
common motivations for many hackers to this day.
Hoodie: check. Face-concealing mask: check. Green/blue code: check. Is I a l33t hacker yet?
News media though – after being excited by “hacker” ideas introduced by WarGames – rightly realised that a hacker with the
same elementary resources as these teens but with malicious intent could cause significant real-world damage. Bruce
Schneier argued last year that the danger of this may be higher today than ever before. The press ran news stories strongly associating the word “hacker” specifically with the focus
on the illegal activities in which some hackers engage. The release of Neuromancer the following year, coupled
with an increasing awareness of and organisation by hacker groups and a number of arrests on both sides of the Atlantic only fuelled things further. By the end of the decade it was
essentially impossible for a layperson to see the word “hacker” in anything other than a negative light. Counter-arguments like The
Conscience of a Hacker (Hacker’s Manifesto) didn’t reach remotely the same audiences: and even if they had, the points they made remain hard to sympathise with for those outside of
hacker communities.
‘Nuff said.
A lack of understanding about what hackers did and what motivated them made them seem mysterious and otherworldly. People came to make the same assumptions about hackers that
they do about magicians – that their abilities are the result of being privy to tightly-guarded knowledge rather than years of practice – and this
elevated them to a mythical level of threat. By the time that Kevin Mitnick was jailed in the mid-1990s, prosecutors were able to successfully persuade a judge that this “most dangerous
hacker in the world” must be kept in solitary confinement and with no access
to telephones to ensure that he couldn’t, for example, “start a nuclear war by whistling into a pay phone”. Yes, really.
Whistling into a phone to start a nuclear war? That makes CSI: Cyber seem realistic [watch].
The Future
Every decade’s hackers have debated whether or not the next decade’s have correctly interpreted their idea of “hacker ethics”. For me, Steven Levy’s tenets encompass them best:
Access to computers – and anything which might teach you something about the way the world works – should be unlimited and total.
All information should be free.
Mistrust authority – promote decentralization.
Hackers should be judged by their hacking, not bogus criteria such as degrees, age, race, or position.
You can create art and beauty on a computer.
Computers can change your life for the better.
Given these concepts as representative of hacker ethics, I’m convinced that hacking remains alive and well today. Hackers continue to be responsible for many of the coolest and
most-important innovations in computing, and are likely to continue to do so. Unlike many other sciences, where progress over the ages has gradually pushed innovators away from
backrooms and garages and into labs to take advantage of increasingly-precise generations of equipment, the tools of computer science are increasingly available to individuals.
More than ever before, bedroom-based hackers are able to get started on their journey with nothing more than a basic laptop or desktop computer and a stack of freely-available
open-source software and documentation. That progress may be threatened by the growth in popularity of easy-to-use (but highly locked-down) tablets and smartphones, but the barrier to
entry is still low enough that most people can pass it, and the new generation of ultra-lightweight computers like the Raspberry Pi are doing
their part to inspire the next generation of hackers, too.
That said, and as much as I personally love and identify with the term “hacker”, the hacker community has never been less in-need of this overarching label. The diverse variety
of types of technologist nowadays coupled with the infiltration of pop culture by geek culture has inevitably diluted only to be replaced with a multitude of others each describing a
narrow but understandable part of the hacker mindset. You can describe yourself today as a coder, gamer, maker, biohacker, upcycler,cracker, blogger, reverse-engineer, social engineer, unconferencer, or one of dozens of other terms that more-specifically ties you to your
community. You’ll be understood and you’ll be elegantly sidestepping the implications of criminality associated with the word “hacker”.
The original meaning of “hacker” has also been soiled from within its community: its biggest and perhaps most-famous
advocate‘s insistence upon linguistic prescriptivism came under fire just this year after he pushed for a dogmatic interpretation of the term “sexual assault” in spite of a victim’s experience.
This seems to be absolutely representative of his general attitudes towards sex, consent,
women, and appropriate professional relationships. Perhaps distancing ourselves from the old definition of the word “hacker” can go hand-in-hand with distancing ourselves from some of
the toxicity in the field of computer science?
(I’m aware that I linked at the top of this blog post to the venerable but also-problematic Eric S. Raymond; if anybody can suggest an equivalent resource by another
author I’d love to swap out the link.)
Verdict: The word “hacker” has become so broad in scope that we’ll never be able to rein it back in. It’s tainted by its associations with both criminality, on one
side, and unpleasant individuals on the other, and it’s time to accept that the popular contemporary meaning has won. Let’s find new words to define ourselves, instead.
…why would cookies ever need to work across domains? Authentication, shopping carts and all that good stuff can happen on the same domain. Third-party cookies, on the other hand,
seem custom made for tracking and frankly, not much else.
…
Then there’s third-party JavaScript.
In retrospect, it seems unbelievable that third-party JavaScript is even possible. I mean, putting arbitrary code—that can then inject
even more arbitrary code—onto your website? That seems like a security nightmare!
I imagine if JavaScript were being specced today, it would almost certainly be restricted to the same origin by default.
…
Jeremy hits the nail on the head with third-party cookies and Javascript: if the Web were invented today, there’s no way that these potentially privacy and security-undermining features
would be on by default, globally. I’m not sure that they’d be universally blocked at the browser level as Jeremy suggests, though: the Web has always been about empowering developers,
acting as a playground for experimentation, and third-party stuff does provide benefits: sharing a login across multiple subdomains, for example (which in turn can exist as a
security feature, if different authors get permission to add content to those subdomains).
Instead, then, I imagine that a Web re-invented today would treat third-party content a little like we treat CORS or we’re
beginning to treat resource types specified by Content-Security-Policy and Feature-Policy headers. That is, website owners would need to “opt-in” to which third-party domains could be
trusted to provide content, perhaps subdivided into scripts and cookies. This wouldn’t prohibit trackers, but it would make their use less of an assumed-default (develolpers would have
to truly think about the implications of what they were enabling) and more transparent: it’d be very easy for a browser to list (and optionally block, sandbox, or anonymise) third-party
trackers could potentially target them, on a given site, without having to first evaluate any scripts and their sources.
I was recently inspired by Dave Rupert to remove
Google Analytics from this blog. For a while, there’ll have been no third-party scripts being delivered on this site at all, except through iframes (for video embedding etc., which
is different anyway because there’s significantly less scope leak). Recently, I’ve been experimenting with Jetpack because I get it for free through
my new employer, but I’m always looking for ways to improve how well my site “stands alone”: you can block all third-party resources
and this site should still work just fine (I wonder if I can add a feature to my service worker to allow visitors to control exactly what third party content they’re exposed to?).
That moment when you realise, to your immense surprise, that the research you’ve spent most of the year on might actually demonstrate the thing you set out to test after all. 😲
Screw you, null hypothesis.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
A few hundred years ago, the words “awesome” and “awful” were synonyms. From their roots, you can see why: they mean “tending to or causing awe” and “full or or characterised by awe”,
respectively. Nowadays, though, they’re opposites, and it’s pretty awesome to see how our language continues to evolve. You know what’s awful, though? Computer viruses. Right?
“Oh no! A virus has stolen all my selfies and uploaded them to a stock photos site!”
You know what I mean by a virus, right? A malicious computer program bent on causing destruction, spying on your online activity, encrypting your files and ransoming them back to you,
showing you unwanted ads, etc… but hang on: that’s not right at all…
Virus
What people think it means
Malicious or unwanted computer software designed to cause trouble/commit crimes.
What it originally meant
Computer software that hides its code inside programs and, when they’re run, copies itself into other programs.
The Past
Only a hundred and thirty years ago it was still widely believed that “bad air” was the principal cause of disease. The idea that tiny germs could be the cause of infection was only
just beginning to take hold. It was in this environment that the excellent scientist Ernest Hankin travelled around
India studying outbreaks of disease and promoting germ theory by demonstrating that boiling water prevented cholera by killing the (newly-discovered) vibrio cholerae bacterium.
But his most-important discovery was that water from a certain part of the Ganges seemed to be naturally inviable as a home for vibrio cholerae… and that boiling this
water removed this superpower, allowing the special water to begin to once again culture the bacterium.
Hankin correctly theorised that there was something in that water that preyed upon vibrio cholerae; something too small to see with a microscope. In doing so, he was probably
the first person to identify what we now call a bacteriophage: the most common kind of virus. Bacteriophages were briefly seen as exciting for their medical potential. But then
in the 1940s antibiotics, which were seen as far more-convenient, began to be manufactured in bulk, and we stopped seriously looking at “phage therapy” (interestingly, phages are seeing a bit of a resurgence as antibiotic resistance becomes increasingly problematic).
It took until the development of the scanning electron microscope in the mid-20th century before we’d actually “see” a virus.
But the important discovery kicked-off by the early observations of Hankin and others was that viruses exist. Later, researchers would discover how these viruses
work1:
they inject their genetic material into cells, and this injected “code” supplants the unfortunate cell’s usual processes. The cell is “reprogrammed” – sometimes after a dormant
period – to churns out more of the virus, becoming a “virus factory”.
Let’s switch to computer science. Legendary mathematician John von Neumann, fresh from showing off his expertise in
calculating how shaped charges should be used to build the first atomic bombs, invented the new field of cellular autonoma. Cellular autonoma are computationally-logical,
independent entities that exhibit complex behaviour through their interactions, but if you’ve come across them before now it’s probably because you played Conway’s Game of Life, which made the concept popular decades after their invention. Von Neumann was very interested
in how ideas from biology could be applied to computer science, and is credited with being the first person to come up with the idea of a self-replicating computer program which would
write-out its own instructions to other parts of memory to be executed later: the concept of the first computer virus.
This is a glider factory… factory. I remember the first time I saw this pattern, in the 1980s, and it sank in for me that cellular autonoma must logically be capable of any
arbitrary level of complexity. I never built a factory-factory-factory, but I’ll bet that others have.
Retroactively-written lists of early computer viruses often identify 1971’s Creeper as the first computer virus:
it was a program which, when run, moved (later copied) itself to another computer on the network and showed the message “I’m the creeper: catch me if you can”. It was swiftly followed
by a similar program, Reaper, which replicated in a similar way but instead of displaying a message attempted to
delete any copies of Creeper that it found. However, Creeper and Reaper weren’t described as viruses at the time and would be more-accurately termed
worms nowadays: self-replicating network programs that don’t inject their code into other programs. An interesting thing to note about them, though, is that – contrary
to popular conception of a “virus” – neither intended to cause any harm: Creeper‘s entire payload was a relatively-harmless message, and Reaper actually tried to do
good by removing presumed-unwanted software.
Another early example that appears in so-called “virus timelines” came in 1975. ANIMAL presented as a twenty
questions-style guessing game. But while the user played it would try to copy itself into another user’s directory, spreading itself (we didn’t really do directory permissions back
then). Again, this wasn’t really a “virus” but would be better termed a trojan: a program which pretends to be something that it’s not.
“Malware? Me? No siree… nothing here but this big executable horse.”
It took until 1983 before Fred Cooper gave us a modern definition of a computer virus, one which – ignoring usage by laypeople –
stands to this day:
A program which can ‘infect’ other programs by modifying them to include a possibly evolved copy of itself… every program that gets infected may also act as a virus and thus the
infection grows.
This definition helps distinguish between merely self-replicating programs like those seen before and a new, theoretical class of programs that would modify host programs such
that – typically in addition to the host programs’ normal behaviour – further programs would be similarly modified. Not content with leaving this as a theoretical, Cooper wrote the
first “true” computer virus to demonstrate his work (it was never released into the wild): he also managed to prove that there can be no such thing as perfect virus detection.
(Quick side-note: I’m sure we’re all on the same page about the evolution of language here, but for the love of god don’t say viri. Certainly don’t say virii.
The correct plural is clearly viruses. The Latin root virus is a mass noun and so has no plural, unlike e.g.
fungus/fungi, and so its adoption into a count-noun in English represents the creation of a new word which should therefore, without a precedent to the
contrary, favour English pluralisation rules. A parallel would be bonus, which shares virus‘s linguistic path, word ending, and countability-in-Latin: you wouldn’t say
“there were end-of-year boni for everybody in my department”, would you? No. So don’t say viri either.)
No, no, no, no, no. The only wholly-accurate part of this definition is the word “program”.
Viruses came into their own as computers became standardised and commonplace and as communication between them (either by removable media or network/dial-up connections) and Cooper’s
theoretical concepts became very much real. In 1986, The Virdim method brought infectious viruses to the DOS platform, opening up virus writers’ access to much of the rapidly growing business and home computer markets.
The Virdim method has two parts: (a) appending the viral code to the end of the program to be infected, and (b) injecting early into the program a call to the appended code. This
exploits the typical layout of most DOS executable files and ensures that the viral code is run first, as an infected program
loads, and the virus can spread rapidly through a system. The appearance of this method at a time when hard drives were uncommon and so many programs would be run from floppy disks
(which could be easily passed around between users) enabled this kind of virus to spread rapidly.
For the most part, early viruses were not malicious. They usually only caused harm as a side-effect (as we’ve already seen, some – like Reaper – were intended to be not just
benign but benevolent). For example, programs might run slower if they’re also busy adding viral code to other programs, or a badly-implemented virus might
even cause software to crash. But it didn’t take long before viruses started to be used for malicious purposes – pranks, adware, spyware, data ransom, etc. – as well as to carry
political messages or to conduct cyberwarfare.
XKCD already explained all of this in far fewer words and a diagram.
The Future
Nowadays, though, viruses are becoming less-common. Wait, what?
Yup, you heard me right: new viruses aren’t being produced at remotely the same kind of rate as they were even in the 1990s. And it’s not that they’re easier for security software to
catch and quarantine; if anything, they’re less-detectable as more and more different types of file are nominally “executable” on a typical computer, and widespread access to
powerful cryptography has made it easier than ever for a virus to hide itself in the increasingly-sprawling binaries that litter modern computers.
Soo… I click this and all the viruses go away, right? Why didn’t we do this sooner?
The single biggest reason that virus writing is on the decline is, in my opinion, that writing something as complex as a a virus is longer a necessary step to illicitly getting your
program onto other people’s computers2!
Nowadays, it’s far easier to write a trojan (e.g. a fake Flash update, dodgy spam attachment, browser toolbar, or a viral free game) and trick people into running it… or else to write a
worm that exploits some weakness in an open network interface. Or, in a recent twist, to just add your code to a popular library and let overworked software engineers include it in
their projects for you. Modern operating systems make it easy to have your malware run every time they boot and it’ll quickly get lost amongst the noise of all the
other (hopefully-legitimate) programs running alongside it.
In short: there’s simply no need to have your code hide itself inside somebody else’s compiled program any more. Users will run your software anyway, and you often don’t even
have to work very hard to trick them into doing so.
Verdict: Let’s promote use of the word “malware” instead of “virus” for popular use. It’s more technically-accurate in the vast majority of cases, and it’s actually a
more-useful term too.
Footnotes
1 Actually, not all viruses work this way. (Biological) viruses are, it turns out, really
really complicated and we’re only just beginning to understand them. Computer viruses, though, we’ve got a solid understanding of.
2 There are other reasons, such as the increase in use of cryptographically-signed
binaries, protected memory space/”execute bits”, and so on, but the trend away from traditional viruses and towards trojans for delivery of malicious payloads began long before these
features became commonplace.
I’ve just cleared out my desk at the Bodleian in anticipation of my imminent departure and discovered that I’ve managed to
successfully keep not only my P60s but also every payslip I’ve ever received in the 8½ years I’ve worked there. At a stretch, I
might just end up requiring those for the current tax year but I can’t conceive of any reason I’ll ever need the preceding hundred or so of them, so the five year-old and I
shredded them all.
If you’ve ever wanted to watch five solid minutes of cross-cut shredding shot from an awkwardly placed mobile phone camera, this is the video for you. Everybody else can move along.
Can we solve [the problem of supply-chain attacks] by building trustworthy systems out of untrustworthy parts?
It sounds ridiculous on its face, but the Internet itself was a solution to a similar problem: a reliable network built out of unreliable parts. This was the result of decades of
research. That research continues today, and it’s how we can have highly resilient distributed systems like Google’s network even though none of the individual components are
particularly good. It’s also the philosophy behind much of the cybersecurity industry today: systems watching one another, looking for vulnerabilities and signs of attack.
Security is a lot harder than reliability. We don’t even really know how to build secure systems out of secure parts, let alone out of parts and processes that we can’t trust and
that are almost certainly being subverted by governments and criminals around the world. Current security technologies are nowhere near good enough, though, to defend against these
increasingly sophisticated attacks. So while this is an important part of the solution, and something we need to focus research on, it’s not going to solve our near-term problems.
…
Schneier provides a great summary of the state of play with nation-state supply-chain attacks, using the Huawei 5G controversy as a jumping-off point but with reference to the fact that
China are far from the only country that weaken the security and privacy of the world’s citizens in order to gain an international spying advantage. He goes on to explain what
he sees as the two broad schools of thought are in providing technical solutions to this class of problems, and demonstrates that both are for the time being beyond our reach. The
excerpt above comes from his examination of the second school of thought, and it’s a pretty-compelling illustration of why this is a different class of problem that the ones we’ve used
to build a reliable Internet.
Let’s face the truth. We are in an abusive relationship with our phones.
Ask yourself the first three questions that UK non-profit Women’s Aid
suggests to determine if you’re in an abusive relationship:
Has your partner tried to keep you from seeing your friends or family?
Has your partner prevented you or made it hard for you to continue or start studying, or from going to work?
Does your partner constantly check up on you or follow you?
If you substitute ‘phone’ for ‘partner’, you could answer yes to each question. And then you’ll probably blame yourself.
…
A fresh take by an excellent article. Bringing a feminist viewpoint to our connection to our smartphones helps to expose the fact that our relationship with the devices would easily be
classified as abusive were they human. The article goes on to attempt to diffuse the inevitable self-blame that comes from this realisation and move forward to propose a more-utopian
future in which our devices might work for us, rather than for the companies that provide the services for which we use them.
But while we’ve learned to distrust user names and text more generally, pictures are different. You can’t synthesize a picture out of nothing, we assume; a picture had to be of
someone. Sure a scammer could appropriate someone else’s picture, but doing so is a risky strategy in a world with google reverse search and so forth. So we tend to trust pictures.
A business profile with a picture obviously belongs to someone. A match on a dating site may turn out to be 10 pounds heavier or 10 years older than when a picture was taken, but if
there’s a picture, the person obviously exists.
No longer. New adverserial machine learning algorithms allow people to rapidly generate synthetic ‘photographs’ of people who have never existed. Already faces of this sort are
being used in espionage.
Computers are good, but your visual processing systems are even better. If you know what to look for, you can spot these fakes at a single glance — at least for the time being. The
hardware and software used to generate them will continue to improve, and it may be only a few years until humans fall behind in the arms race between forgery and detection.
Our aim is to make you aware of the ease with which digital identities can be faked, and to help you spot these fakes at a single glance.
…
I was at a conference last month where research was presented which concluded pretty solidly that the mechanisms used to
make “deepfakes” meant that it was probably impossible to create artificial intelligence that can learn to distinguish between real and fake pictures of humans. Simply put, this is
because the way we make such images is with generative adversarial networks, an AI technique which thrives upon having an effective discriminator component, and any research into differentiating between real and fake images
feeds the capability of the next generation of discriminators!
Instead, then, the best medium-term defence against deepfakes is training humans to be able to identify them, and that’s what this website aims to do. I was pleased that I did
very well on my first attempt (I sort-of knew what to look for already, based on a basic understanding of the underlying technologies) but I was also pleased that I was able to learn to
do better with the aid of the authors’ tips. Nice.
The other day, I saw someone on Twitter say (I’m not linking to the original tweet because I don’t want to pile-on the author):
I don’t bother with frameworks, I just use vanilla JS.
Roughly translated:
I’m smarter than the thousands of people who tried to solve the problems I’m about to solve. I’m an expert on security, a11y, browser support, and perf. I don’t care about ROI, I
just want to code.
Here’s the thing: frameworks don’t really help you with this stuff.
Very much this. People who use Javascript frameworks because they think they protect them from common web development pitfalls are simply trading away a set of known, solvable problems
and taking on a different set of unknown, unsolvable ones.
I’m not anti-framework, but I am pro-informed-developer. If security, accessibility, performance, and browser support are things you care about – and they absolutely should be – then
you need to know the impact that the tools you choose have upon those things. It’s easy to learn the impact that vanilla JS has on them, but
it’s harder to understand exactly what impact a framework might have or how that impact might be affected by interactions between it and all of the other frameworks and
libraries you mix-in. And many developers don’t bother to learn.
Use frameworks if they’re the right tool for your job. But you should work towards understanding your tools. Incidentally: in doing so, you’ll probably come to discover that
frameworks are the right tool for fewer jobs than you thought.
The reality is that your sensitive data has likely already been stolen, multiple times. Cybercriminals have your credit card information. They have your social
security number and your mother’s maiden name. They have your address and phone number. They obtained the data by hacking any one of the hundreds of companies you entrust with the
data — and you have no visibility into those companies’ security practices, and no recourse when they lose your data.
Given this, your best option is to turn your efforts toward trying to make sure that your data isn’t used against you. Enable two-factor authentication for all important
accounts whenever possible. Don’t reuse passwords for anything important — and get a password manager to remember them all.
![Edge Canary showing an "Always allow [this website] to open links of this type..." checkbox](https://bcdn.danq.me/_q23u/2020/03/teamswithcb.png)