Working with an old codebase today, I moved a method from one file to another. CI was happy.
Then I realised the method didn’t have any automated tests, so I wrote one. It turns out its entire (new) file didn’t have any, so my change would improve test coverage. Nice.
But it didn’t. CI complained that test coverage had dropped. Wait, what? All I did was move some code and add a unit test.
Then I realised that the coverage analysis tool was only counting files that actually contained any tested code. By adding a test to part of a previously-untested file, that file became
part of the scored codebase. Uh-oh.
Looked deeper. Turns out the code coverage tool was also counting the test files themselves as being part of the code-under-test.
Fixed all of the above. Code coverage score dropped by about 40%. 😱
Now I’ve got more work to do.
Happy Friday. Check what your coverage tool is inspecting, folks.
For instance, at the start of the weekend I received an email from somebody called Phil, who asked:
Could you possibly have an alternative ‘HQ’ version of your feeds which replaces standard/240 with standard/1200 in the URL for each article in the XML?
I am obviously pretty desperate for this feature, hence me reaching out.
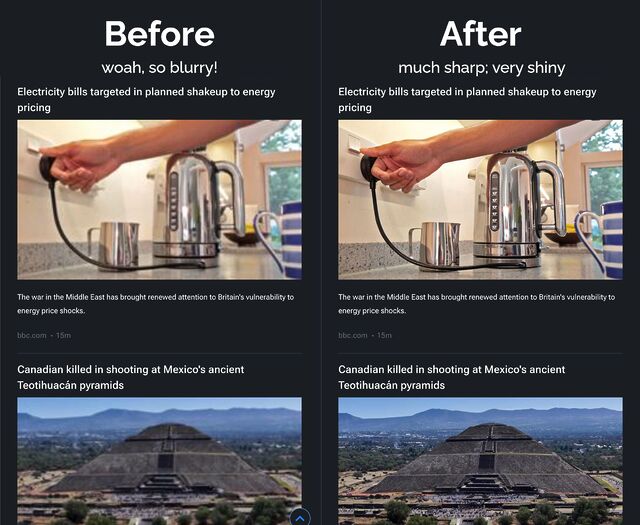
Phil’s right. The BBC News RSS feeds contain thumbnail images that look like this:
You see the /240/ in that URL? If you change it to /1200/ then, as Phil observes, you get a much-higher resolution thumbnail. Naturally you ought
to correct the width and height attributes accordingly, too.
The difference is pretty significant. See:
You’d be forgiven for thinking the left-hand-side of this image was the Lego model of this car.
So I raised Phil’s request as a GitHub issue, like a good maintainer, before realising that – hang on – this would be
a really easy improvement and I should just… do it.
My BBC feeds “improver” leverages one of my very favourite RubyGems, Nokogiri, to perform XML parsing and modification. The code you need to tweak
these URLs is super simple:
# Iterate through each <media:thumbnail> element in the RSS feed:
rss.xpath('//media:thumbnail').eachdo|thumb|# Skip any that don't start the way we expect:nextunlessthumb['url']=~/^https:\/\/ichef.bbci.co.uk\/ace\/(standard|ws)\/240\//# Swap the 240 for 1200 in the url="..." attribute:thumb['url']=thumb['url'].gsub(/\/ace\/(standard|ws)\/240\//,"/ace/\\1/1200/")
# Set width="1200":thumb['width']="1200"# Set the height="..." proportionally (they're not always the same!):thumb['height']=(thumb['height'].to_f/240*1200).round.to_s
end
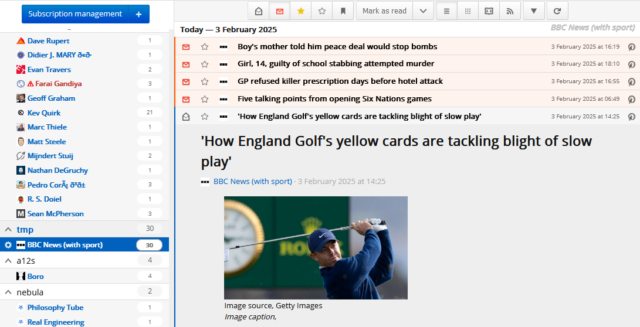
That really is all there is to it, but look at what a difference it makes in an RSS reader:
I got that merged and the GitHub action that makes the magic happen got started on its usual 20-minute schedule soon afterwards. I didn’t even have to finish waiting for my lunchtime
ramen to cool down before the change was out there and, hopefully, helping people. Phil emailed me again soon afterwards:
You managed to fix something in your lunch break that has been bugging me for well over a decade. The difference in quality is night and day.
Anyway: it pleased me to discover that my software is out there, helping people.
As with most of my open source work, I put little to no effort into tracking any kind of metrics of usage, which means I only get to find out if I’ve done good in the world when people
reach out and tell me. So I was delighted to hear from Phil (as well as to take his suggestion and improve the tool for everybody!).
Footnotes
1 Specifically, the code I’ve written makes a few improvements to the BBC News RSS feeds:
(1) removing duplicate news, (2) removing non-news content such as “nudges” towards the app or to iPlayer content, and (3) optionally removing sports news. If that sounds
like a better version of the BBC News RSS feeds, you should take a look!
Some days, developing Three Rings is about being hunched over a keyboard alone in the middle of the night, swearing at Rubygem incompatibilities.
But just ocassionally it’s about getting together in beautiful places with some of the most dedicated geeks I know… to swear about Rubygem incompatibilities.
Either way, a walk in the garden can lead to the insight that gets you to the solution.
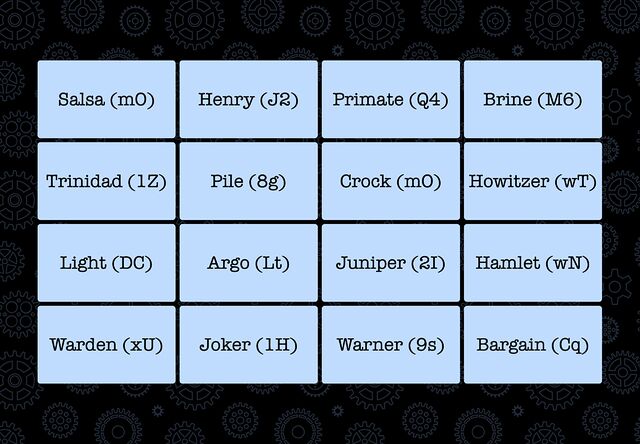
The other day I needed to solve a puzzle1. Here’s the essence of it: there was a grid of 16 words. They needed to be organised into four thematic “groups” of four words each;
then each group needed to be sorted alphabetically.
Each item in each group had a two-character code associated with it: these were to be concatenated together into a string and added to a pastebin.com/... URL. The correct
four URLs would each contain a quarter of the answer to the puzzle.
Apparently this puzzle format is called “Only Connect” and is based on a TV show?2
I’m sure I could have solved the puzzle. But I figured it’d be more satisfying to solve a different puzzle, with the same answer: how to write a program
that finds the correct URLs for me.
I’m confident that this approach was faster.3
Or rather: it would have been if it hadn’t been for the fact that I felt the need to subsequently write a blog post about it.
Here’s how it works:
It creates an array containing the 43,680 possible permutations of 4 from the 16 words.
If sorts the permutations and removes duplicates, reducing the set to just 1,820.
It removes the bit of each that isn’t the two digit code at the end and concatenates them into a URL.
It tries each URL, with short random gaps between them, listing each one that isn’t a 404 “Not found” response.4
I kicked off the program and got on with some work. Meanwhile, in the background, it permuted the puzzle for me. Within a few minutes, I had four working pastebin URLs, which
collectively gave me the geocache’s coordinates. Tada!
Was this cheating?
I still solved a puzzle. It probably took me, as a strong programmer, about as long as it would have taken me to solve the puzzle the conventional way were I a strong… “only
connect”-er5.
But I adapted the puzzle into a programming puzzle and solved it a completely different way, . Here’s the arguments, as I see them:
Yes, this was cheating. This wasn’t the way the puzzle author intended it to be solved. Inelegantly brute-forcing a problem isn’t “solving” it, it’s sidestepping
it. If everybody did this, there’d be no point in the author putting the time into the puzzle in the first place.
No, this wasn’t cheating. This solution still required solving a puzzle, just a different one. A bad human player making a lucky guess would be fine. It’s
a single-player game; play any way that satisfies you. Implementing software to assist is no worse than asking a friend for help, as others have done.
Click on a 😡 or a 🧠 to let me know whether you think I cheated or not, or drop me a comment if you’ve got a more-nuanced opinion.
2 Don’t try to solve this one; it’s randomly generated.
3 This version of the program is adapted to the fake gameboard I showed earlier. You won’t
get any meaningful results by running this program in its current state. But you could quickly adapt it to a puzzle of this format, I suppose.
4 It occurred to me that it could have been more-efficient to eliminate from the list any
possibilities that are ruled-out by any existing finds… but efficiency is a balancing act. For a program that you’ll only run once – and in the background, while you do other things,
to boot – there’s a tipping point at which it’s better to just get it running than it is to improve its performance.
5 There’s a clear parallel here to the various ways in which I’ve
solved jigsaw-puzzle-based geocaches, because I’m far more interested in (a) programming and (b) getting out into the world and finding geocaches in interesting places than I am
in doing a virtual jigsaw puzzle!
Highlight of my workday was debugging an issue that turned out to be nothing like what the reporter had diagnosed.
The report suggested that our system was having problems parsing URLs with colons in the pathname, suggesting perhaps an encoding issue. It wasn’t until I took a deep dive into the logs
that I realised that this was a secondary characteristic of many URLs found in customers’ SharePoint installations. And many of those URLs get redirected. And SharePoint often uses
relative URLs when it sends redirections. And it turned out that our systems’ redirect handler… wasn’t correctly handling relative URLs.
It all turned into a hundred line automated test to mock SharePoint and demonstrate the problem… followed by a tiny two-line fix to the actual code. And probably the
most-satisfying part of my workday!
This is a blog post about things that make me nostalgic for other things that, objectively, aren’t very similar…
When I hear Dawnbreaker, I feel like I’m nine years old…
…and I’ve been allowed to play OutRun on the arcade cabinet at West View
Leisure Centre. My swimming lesson has finished, and normally I should go directly home.
On those rare occasions I could get away1
with a quick pause in the lobby for a game, I’d gravitate towards the Wonderboy machine. But there was something about the tactile
controls of OutRun‘s steering wheel and pedals that gave it a physicality that the “joystick and two buttons” systems couldn’t replicate.
The other thing about OutRun was that it always felt… fast. Like, eye-wateringly fast. This was part of what gave it such appeal2.
OutRun‘s main theme, Magical Sound Shower, doesn’t actually sound much like Dawnbreaker. But
both tracks somehow feel like… “driving music”?
But somehow when I’m driving or cycling and it this song comes on, I’m instantly transported back to those occasionally-permitted childhood games of OutRun4.
When I start a new Ruby project, I feel like I’m eleven years old…
It’s not quite a HELLO WORLD, but it’s pretty-similar.
At first I assumed that the tedious bits and the administrative overhead (linking, compiling, syntactical surprises, arcane naming conventions…) was just what “real”, “grown-up”
programming was supposed to feel like. But Ruby helped remind me that programming can be fun for its own sake. Not just because of the problems you’re solving or the product
you’re creating, but just for the love of programming.
The experience of starting a new Ruby project feels just like booting up my Amstrad CPC and being able to joyfully write code that will just work.
I still learn new programming languages because, well, I love doing so. But I’m yet to find one that makes me want
to write poetry in it in the way that Ruby does.
When I hear In Yer Face, I feel like I’m thirteen years old…
…and I’m painting Advanced HeroQuest miniatures6 in the attic at my dad’s house.
I’ve cobbled together a stereo system of my very own, mostly from other people’s castoffs, and set it up in “The Den”, our recently-converted attic7,
and my friends and I would make and trade mixtapes with one another. One tape began with 808 State’s In Yer Face8,
and it was often the tape that I would put on when I’d sit down to paint.
Advanced HeroQuest came with some fabulously ornate secondary components, like the doors that were hinged so their their open/closed state could be toggled, and I spent
way too long painting almost the entirety of my base set.
In a world before CD audio took off, “shuffle” wasn’t a thing, and we’d often listen to all of the tracks on a medium in sequence9.
That was doubly true for tapes, where rewinding and fast-forwarding took time and seeking for a particular track was challenging compared to e.g. vinyl. Any given song would loop around
a lot if I couldn’t be bothered to change tapes, instead just flipping again and again10.
But somehow it’s whenever I hear In Yer Face11
that I’m transported right back to that time, in a reverie so corporeal that I can almost smell the paint thinner.
When I see a personal Web page, I (still) feel like I’m fifteen years old…
…and the Web is on the cusp of becoming the hot “killer application” for the Internet. I’ve been lucky enough to be “online” for a few years by now12,
and basic ISP-provided hosting would very soon be competing with cheap, free, and ad-supported services like Geocities to be “the
place” to keep your homepage.
Nowadays, even with a hugely-expanded toolbox, virtually every corporate homepage fundamentally looks the same:
Logo in the top left
Search and login in the top right, if applicable
A cookie/privacy notice covering everything until you work out the right incantation to make it go away without surrendering your firstborn child
A “hero banner“
Some “below the fold” content that most people skip over
A fat footer with several columns of links, to ensure that all the keywords are there so that people never have to see this page and the search engine will drop
them off at relevant child page and not one of their competitors
Finally, a line of icons representing various centralised social networks: at least one is out-of-date, either because (a) it’s been renamed, (b) it’s changed its
branding, or (c) nobody with any moral fortitude uses that network any more14
But before the corporate Web became the default, personal home pages brought a level of personality that for a while I worried was forever dead.
2 Have you played Sonic Racing: CrossWorlds? The first time I played it I was overwhelmed by the speed and colours of the
game: it’s such a high-octane visual feast. Well that’s what OutRun felt like to those of us who, in the 1980s, were used to much-simpler and slower arcade games.
3 Also, how cool is it that Metrik has a blog, in this day and age? Max props.
4 Did you hear, by the way, that there’s talk of a movie adaptation of OutRun, which could turn out to be the worst
videogame-to-movie concept that I’ll ever definitely-watch.
5 In very-approximate order: C, Assembly, Pascal, HTML, Perl, Visual Basic (does that even
count as a “grown-up” language?), Java, Delphi, JavaScript, PHP, SQL, ASP (classic, pre-.NET), CSS, Lisp, C#, Ruby, Python (though I didn’t get on with it so well), Go, Elixir… plus
many others I’m sure!
6 Or possibly they were Warhammer Quest miniatures by this point; probably this memory spans one, and also the other, blended together.
7 Eventually my dad and I gave up on using the partially-boarded loft to intermittently
build a model railway layout, mostly using second-hand/trade-in parts from “Trains & Transport”, which was exactly the nerdy kind of model shop you’re imagining right now: underlit
and occupied by a parade of shuffling neckbeards, between whom young-me would squeeze to see if the mix-and-match bin had any good condition HO-gauge flexitrack. We converted the
attic and it became “The Den”, a secondary space principally for my use. This was, in the most part, a concession for my vacating of a large bedroom and instead switching to the
smallest-imaginable bedroom in the house (barely big enough to hold a single bed!), which in turn enabled my baby sister to have a bedroom of her own.
8 My copy of In Yer Face was possibly recorded from the radio by my friend ScGary, who always had a tape deck set up with his finger primed close to the record key when the singles chart came on.
9 I soon learned to recognise “my” copy of tracks by their particular cut-in and -out
points, static and noise – some of which, amazingly, survived into the MP3 era – and of course the tracks that came before or after them, and
there are still pieces of music where, when I hear them, I “expect” them to be followed by something that they used to some mixtape I listened to a lot 30+ years
ago!
10 How amazing a user interface affordance was it that playing one side of an audio
cassette was mechanically-equivalent to (slowly) rewinding the other side? Contrast other tape formats, like VHS, which were one-sided and so while rewinding there was
literally nothing else your player could be doing. A “full” audio cassette was a marvellous thing, and I especially loved the serendipity where a recognisable “gap” on one
side of the tape might approximately line-up with one on the other side, meaning that you could, say, flip the tape after the opening intro to one song and know that you’d be
pretty-much at the start of a different one, on the other side. Does any other medium have anything quite analogous to that?
11 Which is pretty rare, unless I choose to put it on… although I did overhear it
“organically” last summer: it was coming out of a Bluetooth speaker in a narrowboat moored in the Oxford Canal near Cropredy, where I was using the towpath to return from a long walk to nearby Northamptonshire where I’d been searching for a geocache. This was a particularly surprising
place to overhear such a song, given that many of the boats moored here probably belonged to attendees of Fairport’s Cropredy Convention, at which – being a folk music festival – one
might not expect to see significant overlap of musical taste with “Madchester”-era acid house music!
12 My first online experiences were on BBS systems, of which my very first was on a
mid-80s PC1512 using a 2800-baud acoustic coupler! I got onto the Internet at a point in the early 90s at which the Web
existed… but hadn’t yet demonstrated that it would eventually come to usurp the services that existed before it: so I got to use Usenet, Gopher, Telnet and IRC before I saw
my first Web browser (it was Cello, but I switched to Netscape Navigator soon after it was released).
13 On the rare occasion I close my browser, these days, it re-opens with whatever
hundred or so tabs I was last using right back where I left them. Gosh, I’m a slob for tabs.
14 Or, if it’s a Twitter icon: all three of these.
15 Of course, they’re harder to find. SEO-manipulating behemoths dominate the search
results while social networks push their “apps” and walled gardens to try to keep us off the bigger, wider Web… and the more you cut both our of your online life, the calmer and
happier you’ll be.
But I’m pretty sure there are some people who’d rather receive updates to my blog via WhatsApp. And
now, they can. Here’s how I set up an RSS-to-WhatsApp gateway, in case you want to run one of your own2.
A Whapi account connected to your WhatsApp account3
– when you set up an account you’ll get a free trial; when it ends you need to find the link to say that you want to carry on with the free tier (or upgrade to the paid tier if you
expect to send more messages than the free tier’s limit)
A WhatsApp channel to which you want to push your RSS feed: I’d recommend that you make a newsletter (from the Updates tab in WhatsApp, press the kekab menu then
Create Channel) rather than a traditional group: groups are designed for multiple people to talk and discuss and everybody can see one another’s identity, but a newsletter
keeps everybody’s identity private and only allows the administrator(s) permission to post updates.
You probably want to use the kind of channel that’s for one-to-many ‘push’ communication, not a discussion group.
In Settings > Secrets and Variables > Actions, add two new Repository Secrets:
WHATSAPP_API_TOKEN: set to the token on your Whapi dashboard
WHATSAPP_CHANNEL: set to your newsletter ID (will look like 123456789012345678@newsletter) or group ID (will look
like 123456789012345678@g.us): you can get this from the Newsletters or Groups section of Whapi by executing a test GET /newsletters or GET /groups request4.
Do a test run: from the Actions tab select the “Process feeds” action and click “Run workflow”. If it finishes successfully (and you get the WhatsApp message), you’re done! If it
fails, click on the failed action and drill-in to the failed task to see the error message and correct accordingly.
By default, the processor will run on-demand and every 30 minutes, but you can modify that in.github/workflows/process-feeds.yml. It’s configured to send the single oldest
un-sent item in any of the RSS feeds it’s subscribed to, on each run (it tracks which ones it’s sent already by their guids, in a "seen": [...] array in
feeds.json): sending a single link per run ensures that WhatsApp’s link previews work as expected. At that rate, you could theoretically run it once every 10 minutes and
never hit the 150-messages-per-day limit of Whapi’s free tier5), but you’ll want to work out your own optimal rate based on the
anticipated update frequency of your feeds and the number of RSS-to-WhatsApp channels you’re running.
You can, of course, run it on your own infrastructure in a similar way. Just check out the repository to your local system with Ruby 3.2+ running, run bundle to install the
dependencies, then set up a cron job or some other automation to run ./process_feeds.rb. Doing this could be used to hook it up to your RSS feed updating pipeline, for
example, to check for new feed items right after a new post is published.
Footnotes
1 Their own incomprehensible, illogical, weird reasons.
2 I hope that the title gives it away, but you can do this completely for free.
So long as you keep your fork of the GitHub repository open-source then you can run GitHub Actions for free, and so long as you’re pushing out no more than 150 updates per day to no
more than 5 different channels in a month then you can do it within Whapi’s free tier: that’s probably fine for a personal blogger, and there’s a reasonable pricing structure (plus
some value-added extras) for companies that want to use this same workflow as part of a grander WhatsApp offering.
3 Setting this up requires giving Whapi access to your WhatsApp account. If you don’t like
the security implications of that, you could get a cheap eSIM, set that up with WhatsApp, and use that account: if you do this, just remember to “warm up” your new WhatsApp
account with some conversations with yourself so it doesn’t look so much like a spammer! Also note that the way Whapi works “uses up” one of the ~4 devices on which you can
simultaneously use WhatsApp Web/WhatsApp Desktop etc.
4 Prefer the command-line? So long as you’ve got curl and jq
then you can get a list of your newsletters (or groups) and their IDs with curl -H 'Authorization: Bearer YOUR_API_TOKEN' -H 'accept: application/json'
https://gate.whapi.cloud/newsletters?count=100 | jq '.newsletters[] | { id: .id, name: .name }' or curl -H 'Authorization: Bearer YOUR_API_TOKEN' -H 'accept:
application/json' https://gate.whapi.cloud/groups?count=100 | jq '.groups[] | { id: .id, name: .name }', respectively.
5 Going beyond the free tier would require sending one message, on average, every 9
minutes and 36 seconds.
I was updating my CV earlier this week in anticipation of applying for a handful of interesting-looking roles1
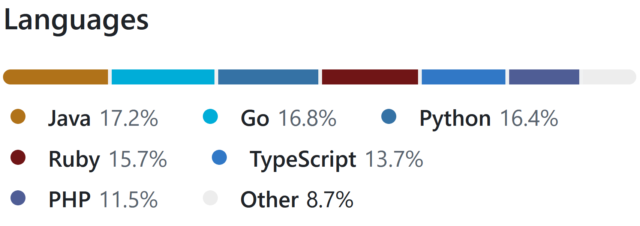
and I was considering quite how many different tech stacks I claim significant experience in, nowadays.
There are languages I’ve been writing in every single week for the last 15+ years, of course, like PHP, Ruby, and JavaScript. And my underlying fundamentals are solid.
But is it really fair for me to be able to claim that I can code in Java, Go, or Python: languages that I’ve not used commercially within the last 5-10 years?
What kind of developer writes the same program six times… for a tech test they haven’t even been asked to do? If you guessed “Dan”, you’d be correct!
Obviously, I couldn’t just let that question lie2.
Let’s find out!
I fished around on Glassdoor for a bit to find a medium-sized single-sitting tech test, and found a couple of different briefs that I mashed together to create this:
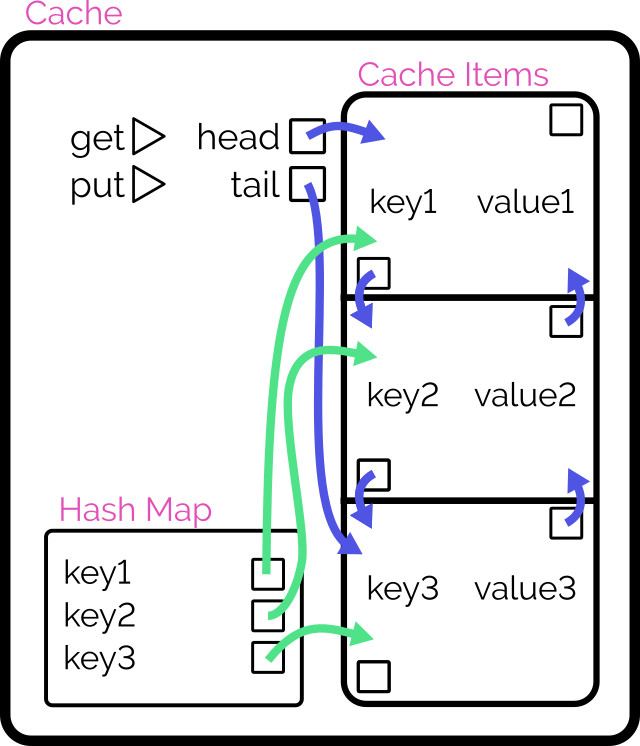
In an object-oriented manner, implement an LRU (Least-Recently Used) cache:
The size of the cache is specified at instantiation.
Arbitrary objects can be put into the cache, along with a retrieval key in the form of a string. Using the same string, you can get the objects back.
If a put operation would increase the number of objects in the cache beyond the size limit, the cached object that was least-recently accessed (by either a
put or get operation) is removed to make room for it.
putting a duplicate key into the cache should update the associated object (and make this item most-recently accessed).
Both the get and put operations should resolve within constant (O(1)) time.
Add automated tests to support the functionality.
My plan was to implement a solution to this challenge, in as many of the languages mentioned on my CV as possible in a single sitting.
But first, a little Data Structures & Algorithms theory:
The Theory
Simple case with O(n) complexity
The simplest way to implement such a cache might be as follows:
Use a linear data structure like an array or linked list to store cached items.
On get, iterate through the list to try to find the matching item.
If found: move it to the head of the list, then return it.
On put, first check if it already exists in the list as with get:
If it already exists, update it and move it to the head of the list.
Otherwise, insert it as a new item at the head of the list.
If this would increase the size of the list beyond the permitted limit, pop and discard the item at the tail of the list.
It’s simple, elegant and totally the kind of thing I’d accept if I were recruiting for a junior or graduate developer. But we can do better.
The problem with this approach is that it fails the requirement that the methods “should resolve within constant (O(1)) time”3.
Of particular concern is the fact that any operation which might need to re-sort the list to put the just-accessed item at the top
4. Let’s try another design:
Achieving O(1) time complexity
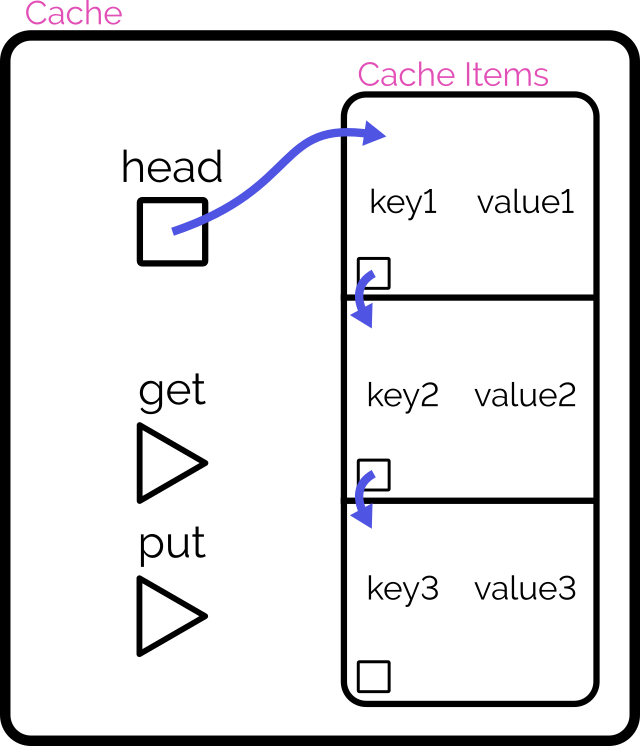
Here’s another way to implement the cache:
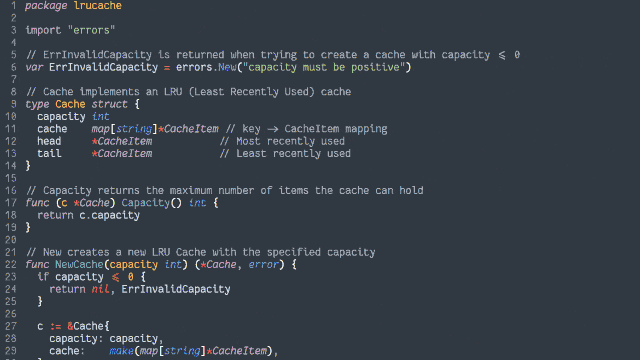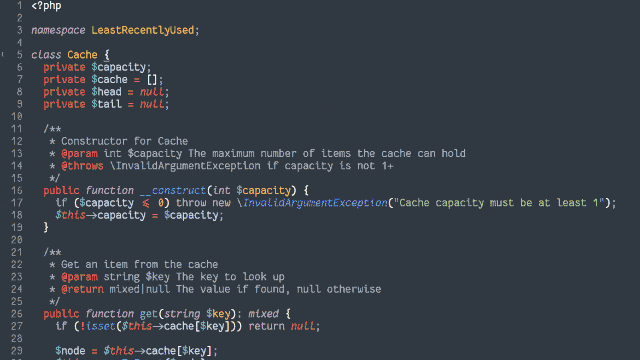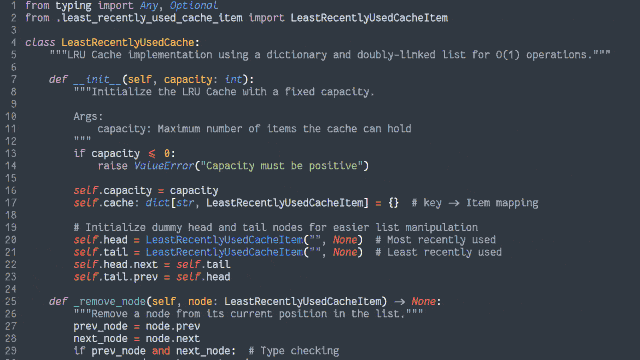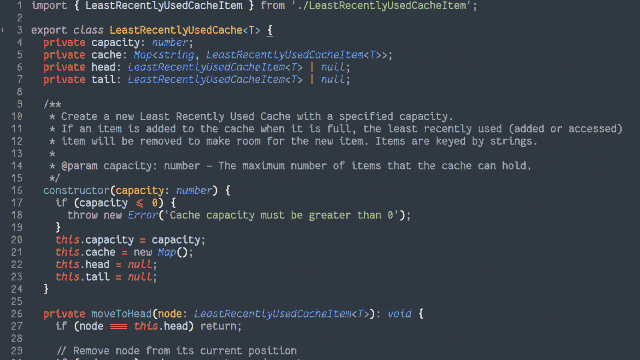
Retain cache items in a doubly-linked list, with a pointer to both the head and tail
Add a hash map (or similar language-specific structure) for fast lookups by cache key
On get, check the hash map to see if the item exists.
If so, return it and promote it to the head (as described below).
On put, check the hash map to see if the item exists.
If so, promote it to the head (as described below).
If not, insert it at the head by:
Updating the prev of the current head item and then pointing the head to the new item (which will have the old head item as its
next), and
Adding it to the hash map.
If the number of items in the hash map would exceed the limit, remove the tail item from the hash map, point the tail at the tail item’s prev, and
unlink the expired tail item from the new tail item’s next.
To promote an item to the head of the list:
Follow the item’s prev and next to find its siblings and link them to one another (removes the item from the list).
Point the promoted item’s next to the current head, and the current head‘s prev to the promoted item.
Point the head of the list at the promoted item.
Looking at a plate of pointer-spaghetti makes me strangely hungry.
It’s important to realise that this alternative implementation isn’t better. It’s just different: the “right” solution depends on the use-case5.
The Implementation
That’s enough analysis and design. Time to write some code.
Turns out that if you use enough different languages in your project, GitHub begins to look like itwants to draw a rainbow.
Picking a handful of the more-useful languages on my CV6,
I opted to implement in:
Ruby (with RSpec for testing and Rubocop for linting)
PHP (with PHPUnit for testing)
TypeScript (running on Node, with Jest for testing)
Java (with JUnit for testing)
Go (which isn’t really an object-oriented language but acts a bit like one, amirite?)
Python (probably my weakest language in this set, but which actually ended up with quite a tidy solution)
Naturally, I open-sourced everything if you’d like to see for yourself. It all works, although if you’re actually in need of such a
cache for your project you’ll probably find an alternative that’s at least as good (and more-likely to be maintained!) in a third-party library somewhere!
What did I learn?
This was actually pretty fun! I might continue to expand my repo by doing the same challenge with a few of the other languages I’ve used professionally at some point or
another7.
And there’s a few takeaways I got from this experience –
Lesson #1: programming more languages can make you better at all of them
As I went along, one language at a time, I ended up realising improvements that I could make to earlier iterations.
For example, when I came to the TypeScript implementation, I decided to use generics so that the developer can specify what kind of objects they want to store in the cache,
rather than just a generic Object, and better benefit type-safety. That’s when I remembered that Java supports generics, too, so I went back and used them there as well.
In the same way as speaking multiple (human) languages or studying linguistics can help unlock new ways of thinking about your communication, being able to think in terms of multiple
different programming languages helps you spot new opportunities. When in 2020 PHP 8 added nullsafe operators, union types, and
named arguments, I remember feeling confident using them from day one because those features were already familiar to me from Ruby8, TypeScript9, and Python10,
respectively.
Lesson #2: even when I’m rusty, I can rely on my fundamentals
I’ve applied for a handful of jobs now, but if one of them had invited me to a pairing session on a language I’m rusty on (like Java!) I might’ve felt intimidated.
But it turns out I shouldn’t need to be! With my solid fundamentals and a handful of other languages under my belt, I understand when I need to step away from the code editor and hit
the API documentation. Turns out, I’m in a good position to demo any of my language skills.
I remember when I was first learning Go, I wanted to make use of a particular language feature that I didn’t know whether it had. But because I’d used that feature in Ruby, I knew what
to search for in Go’s documentation to see if it was supported (it wasn’t) and if so, what the syntax was11.
Lesson #3: structural rules are harder to gearshift than syntactic ones
Switching between six different languages while writing the same application was occasionally challenging, but not in the ways I expected.
I’ve had plenty of experience switching programming languages mid-train-of-thought before. Sometimes you just have to flit between the frontend and backend of your application!
But this time around I discovered: changes in structure are apparently harder for my brain than changes in syntax. E.g.:
Switching in and out of Python’s indentation caught me out at least once (might’ve been better if I took the time to install the language’s tools into my text editor first!).
Switching from a language without enforced semicolon line ends (e.g. Ruby, Go) to one with them (e.g. Java, PHP) had me make the compiler sad several times.
This gets even tougher when not writing the language but writing about the language: my first pass at the documentation for the Go version somehow ended up with
Ruby/Python-style #-comments instead of Go/Java/TypeScript-style //-comments; whoops!
I’m guessing that the part of my memory that looks after a language’s keywords, how a method header is structured, and which equals sign to use for assignment versus comparison… are
stored in a different part of my brain than the bit that keeps track of how a language is laid-out?12
Okay, time for a new job
I reckon it’s time I got back into work, so I’m going to have a look around and see if there’s any roles out there that look exciting to me.
If you know anybody who’s looking for a UK-based, remote-first, senior+, full-stack web developer with 25+ years experience and more languages than you can shake a stick at… point them at my CV, would you?
Footnotes
1 I suspect that when most software engineers look for a new job, they filter to the
languages, frameworks, they feel they’re strongest at. I do a little of that, I suppose, but I’m far more-motivated by culture, sector, product and environment than I am by the shape
of your stack, and I’m versatile enough that technology specifics can almost come second. So long as you’re not asking me to write VB.NET.
2 It’s sort-of a parallel to how I decided to check
the other week that my Gutenberg experience was sufficiently strong that I could write standard ReactJS, too.
3 I was pleased to find a tech test that actually called for an understanding of algorithm
growth/scaling rates, so I could steal this requirement for my own experiment! I fear that sometimes, in their drive to be pragmatic and representative of “real work”, the value of a
comprehension of computer science fundamentals is overlooked by recruiters.
4 Even if an algorithm takes the approach of creating a new list with the
inserted/modified item at the top, that’s still just a very-specific case of insertion sort when you think about it, right?
5 The second design will be slower at writing but faster at
reading, and will scale better as the cache gets larger. That sounds great for a read-often/write-rarely cache, but your situation may differ.
6 Okay, my language selection was pretty arbitrary. But if I’d have also come up with
implementations in Perl, and C#, and Elixir, and whatever else… I’d have been writing code all day!
7 So long as I’m willing to be flexible about the “object-oriented” requirement, there are
even more options available to me. Probably the language that I last wrote longest ago would be Pascal: I wonder how much of that I remember?
8 Ruby’s safe navigation/”lonely” operator did the same thing as PHP’s nullsafe operator
since 2015.
9 TypeScript got union types back in 2015, and apart from them being more-strictly-enforced they’re basically identical to
PHP’s.
10 Did you know that Python had keyword arguments since its very first public release
way back in 1994! How did it take so many other interpreted languages so long to catch up?
11 The feature was the three-way comparison or “spaceship operator”, in case you were wondering.
12 I wonder if anybody’s ever laid a programmer in an MRI machine while they code? I’d
be really interested to see if different bits of the brain light up when coding in functional programming languages than in procedural ones, for example!
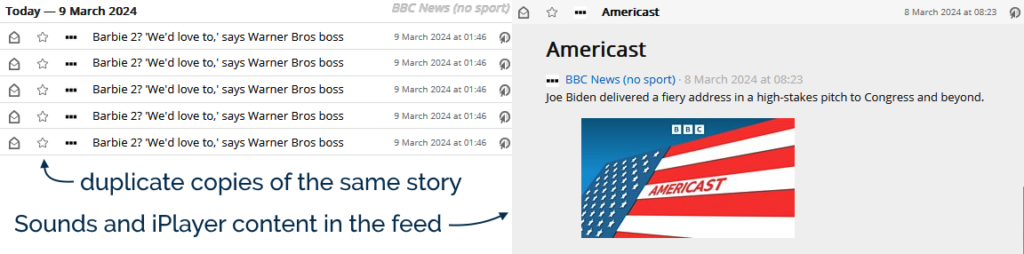
It turns out my seriesofefforts to improve the BBC News RSS feeds are more-popular
than I thought. People keep asking for variants of them, and it’s probably time I stopped hosting the resulting feeds on my NAS (which does a good job,
but it’s in a highly-kickable place right under my desk).
The new site isn’t pretty. But it works.
So I’ve launched BBC-Feeds.DanQ.dev. On a 20-minute schedule, it generates both UK and World editions of the BBC News feeds,
filtered to remove iPlayer, Sounds, app “nudges”, duplicates, and other junk, and optionally with the sports news filtered out too.
Their inclusion of non-news content such as plugs for iPlayer and their apps,
Their repeating of identical news stories with marginally-different GUIDs, and
All of the sports news, which I don’t care about one jot.
Well, it turns out that some people want #3: the sport. But still don’t want the other two.
Some people actually want to read this crap, apparently.
I shan’t be subscribing to this RSS feed, and I can’t promise I’ll fix it if it gets broken. But if “without the crap, but with the sports” is the way you like your BBC News RSS feed,
I’ve got you covered:
The Beeb continue to keep adding more and more non-news content to the BBC News RSS feed (like this ad for the iPlayer app!), so I’ve once again had to update my script to “fix” the feed so that it only contains, y’know, news.
I used to have a single minor niggle with the BBC News RSS feed: that it included sports news, which I didn’t care
about. So I wrote a script that downloaded it, stripped
sports news, and re-exported the feed for me to subscribe to. Magic.
Lately my BBC News feed has caused me some annoyance and frustration.
But lately – presumably as a result of technical changes at the Beeb’s side – this feed has found two fresh ways to annoy me:
The feed now re-publishes a story if it gets re-promoted to the front page… but with a different<guid> (it appears to get a #0 after it
when first published, a #1 the second time, and so on). In a typical day the feed reader might scoop up new stories about once an hour, any by the time I get to reading them the
same exact story might appear in my reader multiple times. Ugh.
They’ve started adding iPlayer and BBC Sounds content to the BBC News feed. I don’t follow BBC News in my feed reader because I want to watch or listen to things. If
you do, that’s fine, but I don’t, and I’d rather filter this content out.
Luckily, I already have a recipe for improving this feed, thanks to my prior work. Let’s look at my newly-revised script (also available on GitHub):
#!/usr/bin/env rubyrequire'bundler/inline'# # Sample crontab:# # At 41 minutes past each hour, run the script and log the results# */20 * * * * ~/bbc-news-rss-filter-sport-out.rb > ~/bbc-news-rss-filter-sport-out.log 2>>&1# Dependencies:# * open-uri - load remote URL content easily# * nokogiri - parse/filter XML
gemfile do
source 'https://rubygems.org'
gem 'nokogiri'endrequire'open-uri'# Regular expression describing the GUIDs to reject from the resulting RSS feed# We want to drop everything from the "sport" section of the website, also any iPlayer/Sounds linksREJECT_GUIDS_MATCHING=/^https:\/\/www\.bbc\.co\.uk\/(sport|iplayer|sounds)\//# Load and filter the original RSS
rss =Nokogiri::XML(open('https://feeds.bbci.co.uk/news/rss.xml?edition=uk'))
rss.css('item').select{|item| item.css('guid').text =~REJECT_GUIDS_MATCHING }.each(&:unlink)
# Strip the anchors off the <guid>s: BBC News "republishes" stories by using guids with #0, #1, #2 etc, which results in duplicates in feed readers
rss.css('guid').each{|g|g.content=g.content.gsub(/#.*$/,'')}
File.open( '/www/bbc-news-no-sport.xml', 'w' ){ |f| f.puts(rss.to_s) }
It’s amazing what you can do with Nokogiri and a half dozen lines of Ruby.
That revised script removes from the feed anything whose <guid> suggests it’s sports news or from BBC Sounds or iPlayer, and also strips any “anchor” part of the
<guid> before re-exporting the feed. Much better. (Strictly speaking, this can result in a technically-invalid feed by introducing duplicates, but your feed reader
oughta be smart enough to compensate for and ignore that: mine certainly is!)
You’re free to take and adapt the script to your own needs, or – if you don’t mind being tied to my opinions about what should be in BBC News’ RSS feed – just subscribe to my copy at:https://fox.q-t-a.uk/bbc-news-no-sport.xml
Update: nowadays, the best place to get this feed and more like it is at bbc-feeds.danq.dev.
My work colleague Simon was looking for a way to add all of the
upcoming UK strike action to their calendar, presumably so they know when not to try to catch a bus or require an ambulance or maybe
just so they’d know to whom they should be giving support on any particular day. Thom was able to suggest a
few places to see lists of strikes, such as this BBC News page and the comprehensive strikecalendar.co.uk, but neither provided a handy machine-readable feed.
Gosh, there’s a lot of strikes going on. ✊
If only they knew somebody who loves an excuse to throw a screen-scraper together. Oh wait, that’s me!
I threw together a 36-line Ruby program that extracts all the data from strikecalendar.co.uk and outputs an
.ics file. I guess if you wanted you could set it up to automatically update the file a couple of times a day and host it at a URL that people can subscribe to; that’s an exercise left for the reader.
If you just want a one-off import based on the state-of-play right now, though, you can save this .ics file to your computer
and import it to your calendar. Simple.
Suppose you’re running an application on a Passenger + Nginx powered server and you want to add caching.
Perhaps your application has a dynamic, public endpoint but the contents don’t change super-frequently or it isn’t critically-important that the user always gets up-to-the-second
accuracy, and you’d like to improve performance with microcaching. How would you do that?
Where you’re at
Not pictured: the rest of the Internet.
Your configuration might look something like this:
1
2
3
4
5
6
7
server {
# listen, server_name, ssl, logging etc. directives go here# ...root/your/application;
passenger_enabledon;
}
What you’re looking for is proxy_cache and its sister directives, but you can’t just
insert them here because while Passenger does act act like an upstream proxy (with parallels like e.g. passenger_pass_header which mirrors the behaviour of proxy_pass_header), it doesn’t provide any of the functions you need to implement proxy caching
of non-static files.
Where you need to be
Instead, what you need to to is define a second server, mount Passenger in that, and then proxy to that second server. E.g.:
# Set up a cacheproxy_cache_path/tmp/cache/my-app-cachekeys_zone=MyAppCache:10mlevels=1:2inactive=600smax_size=100m;
# Define the actual webserver that listens for Internet traffic:server {
# listen, server_name, ssl, logging etc. directives go here# ...# You can configure different rules by location etc., but here's a simple microcache:location/ {
proxy_passhttp://127.0.0.1:4863; # Proxy all traffic to the application server defined belowproxy_cacheMyAppCache; # Use the cache defined aboveproxy_cache_valid2003s; # Treat HTTP 200 responses as valid; cache them for 3 secondsproxy_cache_use_staleupdating; # (Optional) send outdated response while background-updating cacheproxy_cache_lock on; # (Optional) only allow one process to update cache at once
}
}
# (Local-only) application server on an arbitrary port number to act as the upstream proxy:server {
listen 127.0.0.1:4863;
root/your/application;
passenger_enabledon;
}
The two key changes are:
Passenger moves to a second server block, localhost-only, on an arbitrary port number (doesn’t need HTTPS, of course, but if your application detects/”expects” HTTPS you
might need to tweak your headers).
Your main server block proxies to the second as its upstream, and you can add whatever caching directives you like.
Obviously you’ll need to be smarter if you host a mixture of public and private content (e.g. send Vary: headers from your application) and if you want different cache
durations on different addresses or types of content, but there are already great guides to help with that. I only wrote this post because I spent some time searching for (nonexistent!)
passenger_cache_ etc. rules and wanted to save the next person from the same trouble!
Yesterday I recommended that you go read Aaron Uglum‘s webcomic LABS which had just completed its final strip. I’m a big fan of “completed”
webcomics – they feel binge-able in the same way as a complete Netflix series does! – but Spencer quickly pointed out that it’s annoying
for we enlightened modern RSS users who hook RSS up to everything to have to binge completed comics in a different way to reading ongoing ones: what he wanted was an RSS feed covering the entire history of LABS.
With apologies to Aaron Uglum who I hope won’t mind me adapting his comic in this way.
So naturally (after the intense heatwave woke me early this morning anyway) I made one: complete RSS feed of
LABS. And, of course, I open-sourced the code I used to generate it so that others can jumpstart their
projects to make static RSS feeds from completed webcomics, too.
Even if you’re not going to read it via this medium, you should go read LABS.