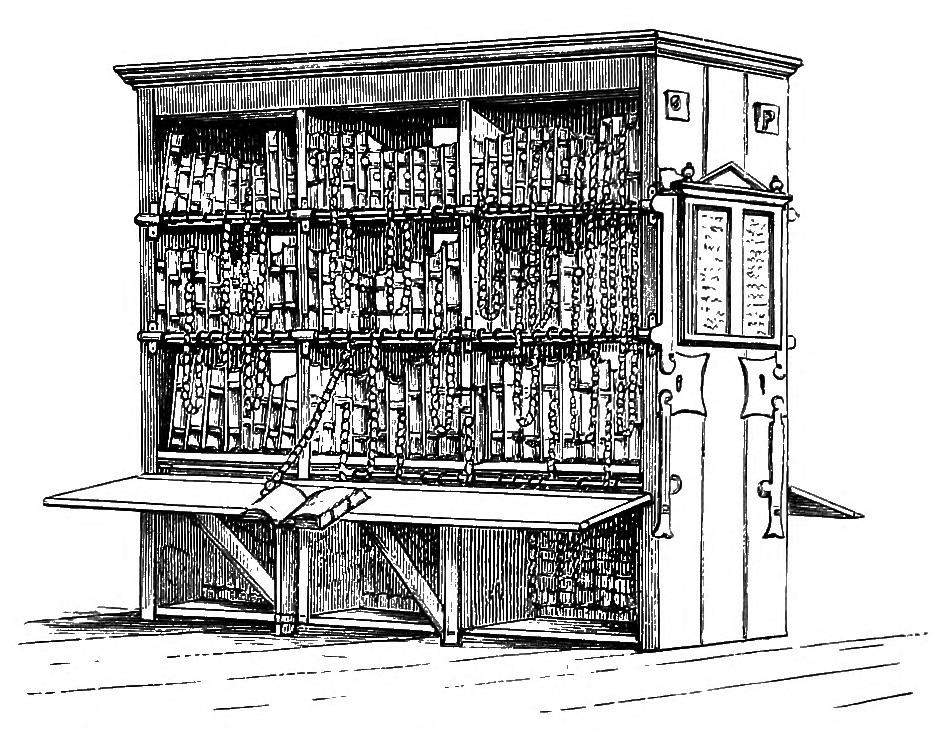
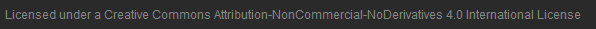What a truly spectacular cache. FP awarded, without hesitation. I’ve seen a similar kind in a library before but never with such depth, such a story, so voluminous a container, nor –
let’s be honest – so beautiful a building!
The Wolfson room was packed, presumably with people studying for their upcoming exams, but I found a seat there to work out the final location. Once there, I made my way up and found it
without difficulty. No trouble with the numbers from me.
I’m going to try to tag one or two more Manchester caches before I catch my train home, but I can’t imagine any will hold a candle to this. TFTC!
I decided to take my meeting with my coach today in our house’s new library, which my metamour
JTA has recently been working hard on decorating, constructing, and filling with books. The room’s not quite finished, but it made for a brilliant space for a bit of quiet
reflection and self-growth work.
(Incidentally: I might be treating “lives in a house with a library” as a measure of personal success. Like: this is what winning at life looks like, right? Because whatever
else goes wrong, at least you can go hide in the library!)
One of my favourite parts of my former role at
the Bodleian Libraries was getting to work on exhibitions. Not just because it was varied and interesting work, but because it let me get
up-close to remarkable artifacts that
most people never even get the chance to see.
We also got to play dollhouse, laying out exhibitions in miniature.
A personal favourite of mine are the Herculaneum Papyri. These charred scrolls were part of a private library near
Pompeii that was buried by the eruption of Mount Vesuvius in 79 CE. Rediscovered from 1752, these ~1,800 scrolls were distributed to
academic institutions around the world, with the majority residing in Naples’ Biblioteca Nazionale Vittorio Emanuele III.
The second time I was in an exhibition room with the Bodleian’s rolled-up Herculaneum Papyri was for an exhibition specifically about humanity’s relationship with volcanoes.
As you might expect of ancient scrolls that got buried, baked, and then left to rot, they’re pretty fragile. That didn’t stop Victorian era researchers trying a variety of techniques to
gently unroll them and read what was inside.
Unrolling the scrolls tends to go about as well as you’d anticipate. A few have been deciphered this way. Many others have been damaged or destroyed by unrolling efforts.
Like many others, what I love about the Herculaneum Papyri is the air of mystery. Each could be anything from a lost religious text to, I don’t
know, somebody’s to-do list (“buy milk, arrange for annual service of chariot, don’t forget to renew volcano insurance…”).1
In recent years, we’ve tried “virtually unrolling” the scrolls using a variety of related technologies. And – slowly – we’re getting there.
X-ray tomography is amazing, but it’s hampered by the fact that the ink and paper have near-equivalent transparency to x-rays. Plus, all the other problems.
But new techniques are helping to overcome them.
So imagine my delight when this week, for the first time ever, a complete word was extracted from
one of the carbonised, still-rolled-up scrolls from Herculaneum. Something that would have seemed inconceivable to the historians who first discovered and catalogued the scrolls is now
possible, thanks to their careful conservation over the years along with the steady advance of technology.
The word appears to be “purple”: either πορφύ̣ρ̣ας̣ (a noun, similar to how we might say “pass the purple [pen]” or πορφυ̣ρ̣ᾶς̣: if we can decode more words around it then it which
might become clear from the context.
Anyway, I thought that was exciting news so I wanted to share.
I’ve been working in Witney one day every week or two lately, but somehow I’ve never managed to sync up my work times with the hours that this building is accessible! Or, when I do, I’m
in a hurry and don’t have time to stop and hunt!
This morning, though, the stars aligned and I was able to get to the GZ. The cache was pretty much where I expected based on the
coordinates and the hint, but still took a minute out two to lay hands on. Soon, though, I was quietly sitting and reading past log entries.
You know that strange moment when you see your old coworkers on YouTube doing a cover of an Adam and the Ants song? No: just me?
Still good to see the Bodleian put a fun spin on promoting their lockdown-friendly reader services. For some reason they’ve marked this video “not embeddable” (?) in their YouTube
settings, so I’ve “fixed” the copy above for you.
One of the best things about working atThe Bodleian Libraries, University of Oxford? Pretending to be a PhD student for a photo shoot! Watch out for me
appearing in a website near you…
My team and I do get up to some unusual stuff, it’s true. I took part in this photoshoot, too:
I’m absolutely not above selling out myself and my family for the benefit of some stock photos for the University, it seems. The sharp-eyed might even have spotted the kids in this video promoting the Ashmolean or a recent tweet by the Bodleian…
Have you noticed how the titles printed on the spines of your books are all, for the most part, oriented the same way? That’s not a coincidence.
If you can’t see the spines of your books at all, perhaps you’re in a library and it’s the 17th century. Wait: how are you on the Internet?
ISO 6357 defines the standard positioning of titles on the spines of printed books (it’s also
codified as British Standard BS6738). If you assume that your book is stood “upright”, the question is one of which way you tilt your head to read the title printed on the spine. If you
tilt your head to the right, that’s a descending title (as you read left-to-right, your gaze moves down, towards the surface on which the book stands). If you tilt your head to
the left, that’s an ascending title. If you don’t need to tilt your head in either direction, that’s a transverse title.
Not every page in ISO 6357:1985 is as exciting as this one.
The standard goes on to dictate that descending titles are to be favoured: this places the title in a readable orientation when the book lays flat on a surface with the cover
face-up. Grab the nearest book to you right now and you’ll probably find that it has a descending title.
This eclectic shelf includes a transverse title (the Holy Bible), a semi-transverse title (The Book of English Magic) and a rare ascending title (A First
Dictionary) among a multitude of descending titles.
But if the book is lying on a surface, I can usually read the cover of the book. Only if a book is in a stack am I unable to do so, and stacks are usually relatively short and
so it’s easy enough to lift one or more books from the top to see what lies beneath. What really matters when considering the orientation of a spine title is, in my mind, how it appears
when it’s shelved.
It feels to me like this standard’s got things backwards. If a shelf of anglophone books is organised into any kind of order (e.g. alphabetically) then it’ll usually be from left to
right. If I’m reading the titles from left to right, and the spines are printed descending, then – from the perspective of my eyes – I’m reading from bottom to top:
i.e. backwards!
It’s possible that this is one of those things that I overthink.
The Bodleian has a specific remit for digital archiving… but sometimes they just like collecting stuff, too, I’m sure.
The team responsible for digital archiving had plans to spend World Digital Preservation Day running a stand in Blackwell Hall for some
time before I got involved. They’d asked my department about using the Heritage Window – the Bodleian’s 15-screen video wall – to show a carousel of slides with relevant content over
the course of the day. Or, they added, half-jokingly, “perhaps we could have Pong up there as it’ll be its 46th birthday?”
Free reign to play about with the Heritage Window while smarter people talk to the public about digital archives? Sure, sign me up.
But I didn’t take it as a joke. I took it as a challenge.
Emulating Pong is pretty easy. Emulating Pong perfectly is pretty hard. Indeed, a lot of the challenge in the preservation of (especially digital) archives in general is in
finding the best possible compromise in situations where perfect preservation is not possible. If these 8″ disks are degrading, is is acceptable to copy them onto a different medium? If this video file is unreadable in
modern devices, is it acceptable to re-encode it in a contemporary format? These are the kinds of questions that digital preservation specialists have to ask themselves all the damn
time.
The JS Gamepad API lets your web browser talk to controller devices.
Emulating Pong in a way that would work on the Heritage Window but be true to the original raised all kinds of complications. (Original) Pong’s aspect ratio doesn’t fit nicely on a 16:9
widescreen, much less on a 27:80 ultrawide. Like most games of its era, the speed is tied to the clock rate of the processor. And of course, it should be controlled using a
“dial”.
By the time I realised that there was no way that I could thoroughly replicate the experience of the original game, I decided to take a different track. Instead, I opted to
reimplement Pong. A reimplementation could stay true to the idea of Pong but serve as a jumping-off point for discussion about how the experience of playing the game
may be superficially “like Pong” but that this still wasn’t an example of digital preservation.
Bip… boop… boop… bip… boop… bip…
Here’s the skinny:
A web page, displayed full-screen, contains both a <canvas> (for the game, sized appropriately for a 3 × 3 section of the video wall) and a
<div> full of “slides” of static content to carousel alongside (filling a 2 × 3 section).
Javascript writes to the canvas, simulates the movement of the ball and paddles, and accepts input from the JS
Gamepad API (which is awesome, by the way). If there’s only one player, a (tough! – only three people managed to beat it over the course of the day!) AI plays the other paddle.
A pair of SNES controllers adapted for use as USB
controllers which I happened to own already.
Increasingly, the Bodleian’s spaces seem to be full of screens running Javascript applications I’ve written.
I felt that the day, event, and game were a success. A few dozen people played Pong and explored the other technology on display. Some got nostalgic about punch tape, huge floppy disks,
and even mechanical calculators. Many more talked to the digital archives folks and I about the challenges and importance of digital archiving. And a good time was had by all.
I’ve open-sourced the entire thing with a super-permissive license so you can deploy it yourself (you know, on your ultrawide
video wall) or adapt it as you see fit. Or if you’d just like to see it for yourself on your own computer, you can (but unless
you’re using a 4K monitor you’ll probably need to use your browser’s mobile/responsive design simulator set to 3200 × 1080 to make it fit your screen). If you don’t have
controllers attached, use W/S to control player 1 and the cursor keys for player 2 in a 2-player game.
Oxfordshire County Library, W Walk, Oxford OX1 1TR, United Kingdom.
Rating: ⭐⭐⭐⭐⭐
Newly-reopened after an extended temporary relocation, this library now features revamped features including a community MakerSpace available for tech/inventive projects, Code Club, and
more.
When I first started working at the Bodleian Libraries in 2011, their websites were looking… a little
dated. I’d soon spend some time working with a vendor (whose premises mysteriously caught fire while I was there, freeing me up to spend my
birthday in a bar) to develop a fresh, modern interface for our websites that, while not the be-all and end-all, was a huge leap forwards and has served us well for the last five years
or so.
The colour scheme, the layout, the fact that it didn’t remotely work on mobiles… there was a lot wrong with the old design of the Bodleian Libraries’ websites.
Fast-forward a little: in about 2015 we noticed a few strange anomalies in our Google Analytics data. For some reason, web addresses were appearing that didn’t exist anywhere on our
site! Most of these resulted from web visitors in Turkey, so we figured that some Turkish website had probably accidentally put our Google Analytics user ID number into their
code rather than their own. We filtered out the erroneous data – there wasn’t much of it; the other website was clearly significantly less-popular than ours – and carried on. Sometimes
we’d speculate about the identity of the other site, but mostly we didn’t even think about it.
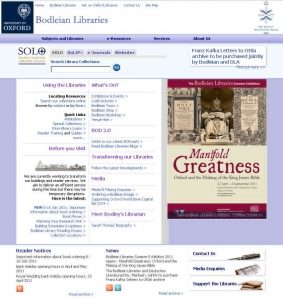
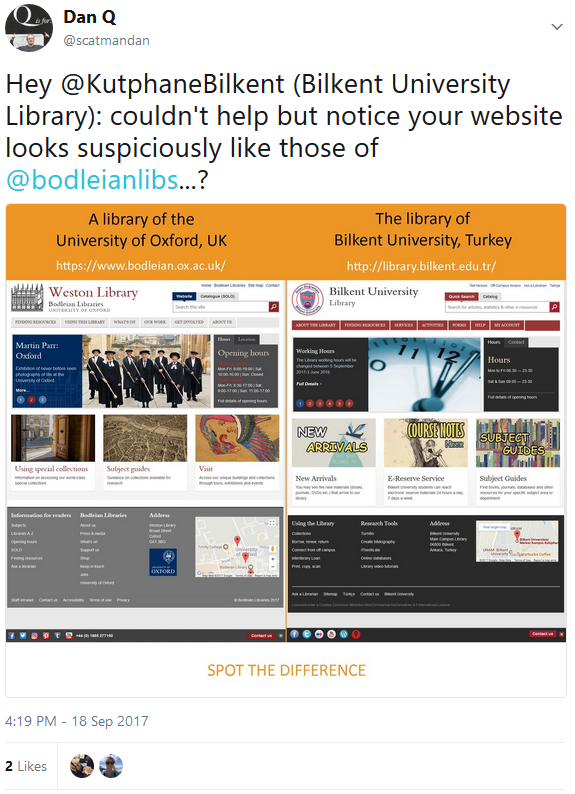
How a Bodleian Libraries’ website might appear today. Pay attention, now: there’ll be a spot-the-difference competition in a moment.
Earlier this year, there was a spike in the volume of the traffic we were having to filter-out, so I took the time to investigate more-thoroughly. I determined that the offending
website belonged to the Library of Bilkent University, Turkey. I figured that some junior web developer there must have copy-pasted the
Bodleian’s Google Analytics code and forgotten to change the user ID, so I went to the website to take a look… but I was in for an even bigger surprise.
Hey, that looks… basically identical!
Whoah! The web design of a British university was completely ripped-off by a Turkish university! Mouth agape at the audacity, I clicked my way through several of their pages to try to
understand what had happened. It seemed inconceivable that it could be a coincidence, but perhaps it was supposed to be more of an homage than a copy-paste job? Or perhaps they
were ripped-off by an unscrupulous web designer? Or maybe it was somebody on the “inside”, like our vendor, acting unethically by re-selling the same custom design? I didn’t believe it
could be any of those things, but I had to be sure. So I started digging…
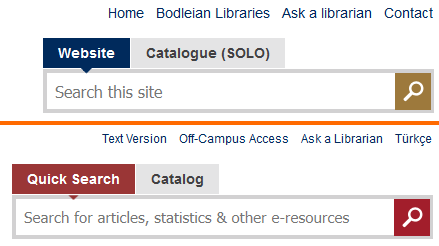
Our user research did indicate that putting the site and catalogue search tools like this was smart. Maybe they did the same research?
Menus are pretty common on many websites. They probably just had a similar idea.
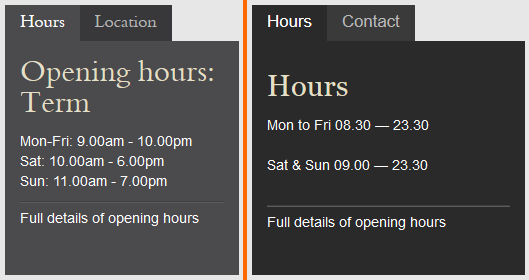
Tabs are a great way to show opening hours. Everybody knows that. And this is obviously just the a popular font.
Oh, you’ve got a slider too. With circles? And you’ve got an identical Javascript bug? Okay… now that’s a bit of a coincidence…
Okay, I’m getting a mite suspicious now. Surely we didn’t independently come up with this particular bit of design?
Well these are clearly different. Ours has a copyright notice, for example…
Oh, you DO have a copyright notice. Hang on, wait: you’ve not only stolen our design but you’ve declared it to be open-source???
I was almost flattered as I played this spot-the-difference competition, until I saw the copyright notice: stealing our design was galling enough, but then relicensing it in such a way
that they specifically encourage others to steal it too was another step entirely. Remember that we’re talking about an academic library, here: if anybody ought to
have a handle on copyright law then it’s a library!
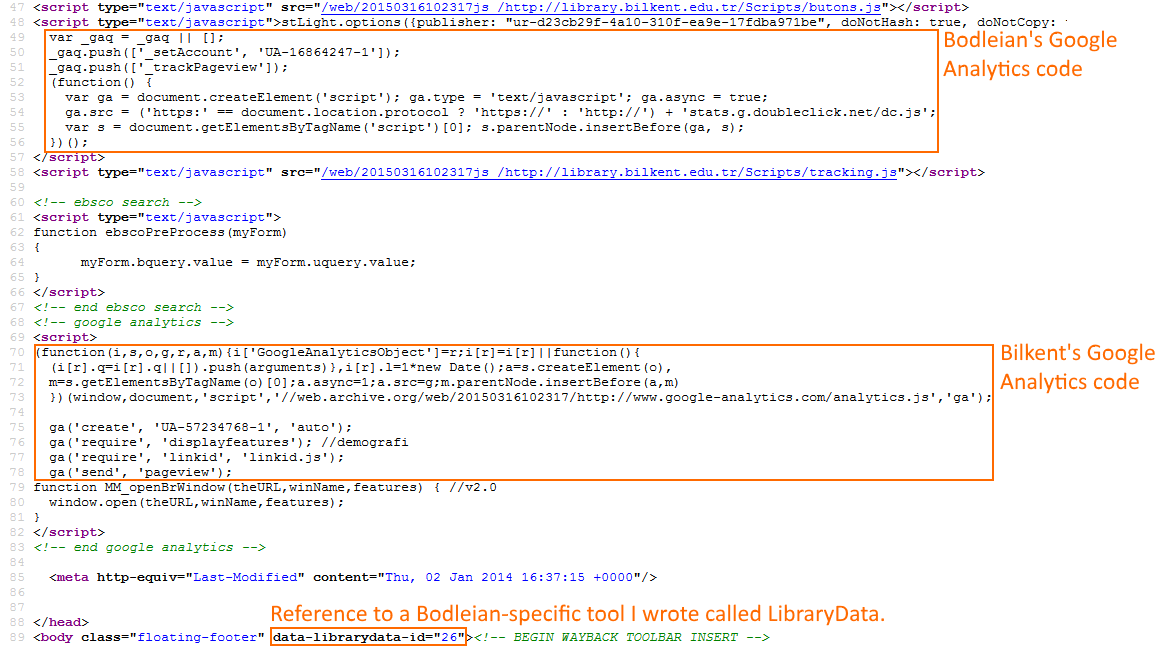
I took a dive into the source code to see if this really was, as it appeared to be, a copy-paste-and-change-the-name job (rather than “merely” a rip-off of the entire graphic design),
and, sure enough…
In their HTML source code, you can see both the Bodleian’s Google Analytics code (which they failed to remove) but also their own. And a data- attribute related to a project I wrote
and that means nothing to their site.
It looks like they’d just mirrored the site and done a search-and-replace for “Bodleian”, replacing it with “Bilkent”. Even the code’s spelling errors, comments, and indentation were
intact. The CSS was especially telling (as well as being chock-full of redundant code relating to things that appear on our website but not on theirs)…
The search-replace resulted in some icky grammar, like “the Bilkent” appearing in their code. And what’s this? That’s MY NAME in the middle of their source code!
So I reached out to them with a tweet:
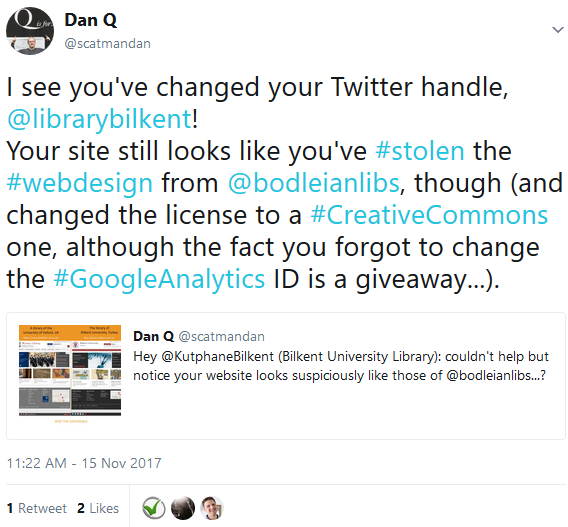
My first tweet to Bilkent University Library contained a “spot the difference” competition.
I didn’t get any response, although I did attract a handful of Turkish followers on Twitter. Later, they changed their Twitter handle and I thought I’d take advantage of the then-new
capability for longer tweets to have another go at getting their attention:
This time, I was a little less-sarcastic and a little more-aggressive. Turns out that’s all that was needed.
Clearly this was what it took to make the difference. I received an email from the personal email account of somebody claiming to be Taner
Korkmaz, Systems Librarian with Bilkent’s Technical Services team. He wrote (emphasis mine):
Dear Mr. Dan Q,
My name is Taner Korkmaz and I am the systems librarian at Bilkent. I am writing on behalf of Bilkent University Library, regarding your share about Bilkent on
your Twitter account.
Firstly, I would like to explain that there is no any relation between your tweet and our library Twitter handle change. The librarian who is Twitter admin at Bilkent did not notice
your first tweet. Another librarian took this job and decided to change the twitter handle because of the Turkish letters, abbreviations, English name requirement etc. The first name
was @KutphaneBilkent (kutuphane means library in Turkish) which is not clear and not easy to understand. Now, it is @LibraryBilkent.
About 4 years ago, we decided to change our library website, (and therefore) we reviewed the appearance and utility of the web pages.
We appreciated the simplicity and clarity of the user interface of University of Oxford Bodlien Library & Radcliffe Camera, as an academic pioneer in many fields. As a not profit institution, we took advantage of your template by using CSS and HTML, and added our own original content.
We thought it would not create a problem the idea of using CSS codes since on the web page there isn’t any license notice or any restriction related to
the content of the template, and since the licenses on the web pages are mainly more about content rather than templates.
The Library has its own Google Analytics and Search Console accounts and the related integrations for the web site statistical data tracking. We would like to point out that there is
a misunderstanding regarding this issue.
In 2017, we started to work on creating a new web page and we will renew our current web page very soon.
Thank you in advance for your attention to this matter and apologies for possible inconveniences.
Yours sincerely,
Or to put it another way: they decided that our copyright notice only applied to our content and not our design and took a copy of the latter.
Do you remember when I pointed out earlier that librarians should be expected to know their way around copyright law? Sigh.
They’ve now started removing evidence of their copy-pasting such as the duplicate Google Analytics code fragment and the references to LibraryData, but you can still find the unmodified
code via archive.org, if you like.
That probably ends my part in this little adventure, but I’ve passed everything on to the University of Oxford’s legal team in case any of them have anything to say about it. And now
I’ve got a new story to tell where web developers get together over a pint: the story of the time that I made a website for a university… and a different university stole it!
Two weeks ago I asked Twitter if anyone had favourite obscure and/or delightful library or archival words. Here are some of the best replies:
Tête-bêche: From philately, meaning printed upside down or sideways relative to another. (Tara Robertson)
Respect des fonds: A principle in archival theory that proposes to group collections of archival records according to their
fonds — that is to say, according to the administration, organization, individual, or entity by which they were created or from which they were received. (Ed Summers)
Realia: Objects and material from everyday life. (Deb Chachra)
There’s a very famous Neil Gaiman quote among librarians and lovers of libraries: “Google will bring you back, you know, a hundred thousand answers. A librarian will bring you back
the right one.”…