The <geolocation> element provides a button that, when activated, prompts the user for permission to access their location. Originally, it was designed as a
general <permission> element, but browser vendors indicated that implementing a “one-size-fits-all” element would be too complex. The result was a single-purpose
element, probably the first of several.
<geolocation><strong>Your browser doesn't support <geolocation>. Try Chrome 144+</strong></geolocation>
…
I’ve been waiting for this one. Given that “requesting permission to access a user’s location” has always required user intervention, at least to begin with, it makes
sense to me that it would exist as a form control, rather than just as a JavaScript API.
Implementing directly in HTML means that it degrades gracefully in the standard “if you don’t understand an element, simply render its contents” way that the Web always has. And
it’s really easy to polyfill support in for the new element so you can start using
it today.
My only niggle with <geolocation> is that it still requires JavaScript. It feels like a trick’s been missed, there. What I’d have really wanted would
have been <input type="geolocation">. This would e.g. renders as a button but when clicked (and permission granted) gets the user’s device location and fills the
field (presumably with a JSON object including any provided values, such as latitude, longitude, altitude, accuracy, provider, and so on). Such an element would still provide
all the same functionality of the new element, but would also be usable in a zero-JS environment, just like <input type="file">, <input
type="datetime-local"> and friends.
This is still a huge leap forward and I look forward to its more-widespread adoption. And meanwhile, I’ll be looking into integrating it into both existing applications that use it
and using it in future applications, by preference over the old API-driven approach. I’m grateful to Manuel for sharing what he’s learned!
Modern CSS is freakin’ amazing. Widespread support for nesting, variables, :has, and :not has unlocked so much potential. But I don’t yet see it used widely
enough.
Suppose I have a form where I’m expecting, but not requiring, a user to choose an option from each of several drop-downs. I want to make it more visually-obvious
which drop-downs haven’t yet had an option selected. Something like this:
It’s a slightly gnarly selector, but thanks to nesting you could choose to break it into multiple blocks if you preferred.
What that’s saying is:
a <select>
that contains an <option>
where that <option> does not have a value="..."
and that <option> is currently selected
gains a dotted red outline around it
Or in short: if the default option is selected, highlight it so the user knows they haven’t chosen a value yet. Sweet!
Obviously you could expand this to have different effects for every value, if you wanted.
I can’t understate how valuable it is that we can do this in CSS, nowadays. Compared to doing it in JavaScript… CSS gives better performance and reliability and is much easier to
implement in a progressively-enhanced manner.
Here’s another example, this time using a fun “dress-up Dan” feature I from a redesign of my blog theme that I’m hoping to launch in the New Year:
If you’ve ever wanted to know what I’d look like if I were an elderly Tom Scott, my new design will answer that question!
Every single bit of interactivity shown in the video above… from the “waving” Dan to the popup menu to the emoji-styled checkboxes to the changes to t-shirt and hair
colours… is implemented in CSS.
The underlying HTML is all semantic, e.g. the drop-down menu is a <details>/<summary> pair (with thanks to Eevee for
the inspiration); its contents are checkbox and radiobutton <input>es; the images are SVGs that use CSS variables (another killer feature these years!) to specify
colours (among other things), and virtually everything else… is CSS.
Consider this:
:root{
/* Default values for Dan's t-shirt, hair, and beard colours used throughout the site: */--dan-tshirt:#c3d4d7;
--dan-hair:#3b6f8f;
--dan-beard:#896a51;
/* ...more variables... */
}
/* When the page contains a "checked" checkbox, update some variables: */
:root:has(#dan-tshirt-color-white:checked){--dan-tshirt:#c3d4d7;}
:root:has(#dan-tshirt-color-purple:checked){--dan-tshirt:#7429a8;}
/* ... */
:root:has(#dan-hair-color-natural:checked){--dan-hair:#896a51;}
:root:has(#dan-hair-color-blue:checked){--dan-hair:#3b6f8f;}
/* When "dye beard" is checked, copy the hair colour: */
:root:has(#dan-dye-beard-toggle:checked){--dan-beard:var(--dan-hair);}
The ability to set :root CSS variables, based on the status of user-controlled elements like checkboxes within the document, unlocks amazing options for interactivity. It
also works in smaller scopes like HTML Web Components, of course, for encapsulated functionality.
If you’re still using JavaScript for things like this, perhaps it’s time you looked at how much CSS has grown up this last decade or so. CSS gives you performance benefits, less
fragility, and makes it easier for you to meet your accessibility and usability goals.
You can still enrich what you create with JavaScript if you like (I’ve got a few lines of JS that save those checkbox states to localStorage so they persist
through page loads, for example).
But a CSS-based approach moves more of your functionality from the “nice to have” to “core” column. And that’s something we can all get behind, right?
An additional thing I wanted to implement – again, for the next version of my blog’s theme – was an “alt text viewer”. Mastodon has one, and it’s excellent2.
Mastodon’s viewer requires JavaScript, but I was inspired when I saw James come up with a
CSS-based version that used a re-styled checkbox.
But I wanted to do one better. Displaying alt text, too, seems like an example of what would semantically be best-represented by a
<details>/<summary> pair.
Clicking on the image shows a larger version in a lightbox; clicking on the ‘alt’ button shows the alt text… all in semantic HTML and vanilla CSS.3
My first attempt tried to put the alt-text widget inside the <summary> of the original image, but that’s an accessibility no-no, so instead I
wrap both<details> blocks (the lightbox, and the alt-text revealer) inside a container and then reposition the latter over the former.
The rest is all the same kinds of tricks I demonstrated previously, to ensure that you can click in-and-out of both in an intuitive way and that keyboard navigation works as you’d
expect.
I can’t use it on my blog yet (because if I do, it’ll probably break horribly when I add the functionality to my entire theme, later!), but I’ve put together a demonstration page that showcases the technique, plus a GitHub repo with all of the code (which is all public domain/unlicensed). Go have a
play and tell me what you think!
Footnotes
1 As a secondary goal, using <details>/<summary>
means that it’ll behave better when CSS is disabled or unavailable, which’ll make it easier to celebrate Naked CSS Day!
2 Why would I, a sighted person, need an alt text viewer, you ask? All kinds of reasons.
Good alt text is for everybody, and can help by providing context, e.g. “explaining” the joke or identifying the probably-well-known-but-I-didn’t-recognise-them subject of a
photo. Here’s some more reasons.
3 If you love owls and you love accessibility, this is the kind of example you should give
a hoot about.
This weekend, I received my copy of DOCTYPE, and man: it feels like a step back to yesteryear to type in a computer program from a
magazine: I can’t have done that in at least thirty years.
So yeah, DOCTYPE is a dead-tree (only) medium magazine containing the source code to 10 Web pages which, when typed-in to your computer, each provide you with some kind of fun and
interactive plaything. Each of the programs is contributed by a different author, including several I follow and one or two whom I’m corresponded with at some point or another, and each
brings their own personality and imagination to their contribution.
I opted to start with Stuart Langridge‘s The Nine Pyramids, a puzzle game about trying to connect all nodes in a 3×3 grid in a
continuous line bridging adjacent (orthogonal or diagonal) nodes without visiting the same node twice nor moving in the same direction twice in a row (that last provision is described
as “not visiting three in a straight line”, but I think my interpretation would have resulted in simpler code: I might demonstrate this, down the line!).
The puzzle actually made me stop to think about it for a bit, which was unexpected and pleasing!
Per tradition with this kind of programming, I made a couple of typos, the worst of which was missing an entire parameter in a CSS conic-gradient() which resulted in the
majority of the user interface being invisible: whoops! I found myself reminded of typing-in the code for Werewolves and
Wanderer from The Amazing Amstrad Omnibus, whose data section – the part most-liable to be affected by a typographic bug without introducing a syntax error – had
a helpful “checksum” to identify if a problem had occurred, and wishing that such a thing had been possible here!
But thankfully a tiny bit of poking in my browser’s inspector revealed the troublesome CSS and I was able to complete the code, and then the puzzle.
I’ve really been enjoying DOCTYPE, and you can still buy a copy if you’d like one of your own. It manages to simultaneously feel both fresh and nostalgic,
and that’s really cool.
A few years ago I implemented a pure HTML + CSS solution for lightbox images, which I’ve been using on my blog ever since. It works by
pre-rendering an invisible <dialog> for each lightboxable image on the page, linking to the anchor of those dialogs, and exploiting the :target selector
to decide when to make the dialogs visible. No Javascript is required, which means low brittleness and high performance!
It works, but it’s got room for improvement.
One thing I don’t like about it is that it that it breaks completely if the CSS fails for any reason. Depending upon CSS is safer than depending upon JS (which breaks all
the time), but it’s still not great: if CSS is disabled in your browser or just “goes wrong” somehow then you’ll see a hyperlink… that doesn’t seem to go anywhere (it’s an
anchor to a hidden element).
A further thing I don’t like about it is it’s semantically unsound. Linking to a dialog with the expectation that the CSS parser will then make that dialog visible isn’t really
representative of what the content of the page means. Maybe we can do better.
🚀 Wired: <details>-based HTML+CSS lightboxes?
Here’s a thought I had, inspired by Patrick Chia’s <details> overlay trick and by
the categories menu in Eevee’s blog: what if we used a <details> HTML element for a lightbox? The thumbnail image would go in the
<summary> and the full image (with loading="lazy" so it doesn’t download until the details are expanded) beneath, which means it “just works” with or
without CSS… and then some CSS enhances it to make it appear like a modal overlay and allow clicking-anywhere to close it again.
Let me show you what I mean. Click on one of the thumbnails below:
Each appears to pop up in a modal overlay, but in reality they’re just unfolding a <details> panel, and some CSS is making the contents display as if if were
an overlay, complete click-to-close, scroll-blocking, and a blur filter over the background content. Without CSS, it functions as a traditional <details> block.
Accessibility is probably improved over my previous approach, too (though if you know better, please tell me!).
The code’s pretty tidy, too. Here’s the HTML:
<detailsclass="details-lightbox"aria-label="larger image">
<summary>
<imgsrc="thumb.webp"alt="Alt text for the thumbnail image.">
</summary>
<div>
<imgsrc="full.webp"alt="Larger image: alt text for the full image."loading="lazy">
</div>
</details>
The CSS is more-involved, but not excessive (and can probably be optimised a little further):
Native CSS nesting is super nice for this kind of thing. Being able to use :has on the body to detect whether there exists an open lightbox and prevent
scrolling, if so, is another CSS feature I’m appreciating today.
I’m not going to roll this out anywhere rightaway, but I’ll keep it in my back pocket for the next time I feel a blog redesign coming on. It feels tidier and more-universal than my
current approach, and I don’t think it’s an enormous sacrifice to lose the ability to hotlink directly to an open image in a post.
The video below is presented in portrait orientation, because your screen is taller than it is wide.
The video below is presented in landscape orientation, because your screen is wider than it is tall.
The video below is presented in square orientation (the Secret Bonus Square Video!), because your screen has approximately the same width as as its height. Cool!
This is possible (with a single <video> element, and without any Javascript!) thanks to some cool HTML features you might not be aware of, which I’ll briefly explain
in the video. Or scroll down for the full details.
<videocontrols><sourcesrc="squareish.mp4"media="(min-aspect-ratio: 0.95) and (max-aspect-ratio: 1.05)"/><sourcesrc="portrait.mp4"media="(orientation: portrait)"/><sourcesrc="landscape.mp4"/></video>
This code creates a video with three sources: squareish.mp4 which is shown to people on “squareish” viewports, failing that portrait.mp4 which is shown to
people whose viewports are taller than wide, and failing that landscape.mp4 which is shown to anybody else.
That’s broadly-speaking how the video above is rendered. No JavaScript needed.
Browsers only handle media queries on videos when they initially load, so you can’t just tip your phone over or resize the window: you’ll need to reload the page, too. But it works!
Give it a go: take a look at the video in both portrait and landscape modes and let me know what you think1.
Adding adaptive bitrate streaming with HLS
Here’s another cool technology that you might not have realised you could “just use”: adaptive bitrate streaming with HLS!
You’ve used adaptive bitrate streaming before, though you might not have noticed it. It’s what YouTube, Netflix, etc. are doing when your network connection degrades and you quickly get
dropped-down, mid-video, to a lower-resolution version2.
Turns out you can do it on your own static hosting, no problem at all. I used this guide (which has a great
description of the parameters used) to help me:
This command splits the H.264 video landscape.mp4 into three different resolutions: the original “v1” (1920×1080, in my case, with 96kbit audio), “v2” (1280×720, with
96kbit audio), and “v3” (640×360, with 48kbit audio), each with a resolution-appropriate maximum bitrate, and forced keyframes every 48th frame. Then it breaks each of those into HLS
segments (.ts files) and references them from a .m3u8 playlist.
The output from this includes:
Master playlist landscape.m3u8, which references the other playlists with reference to their resolution and bandwidth, so that browsers can make smart choices,
Playlists landscape_0.m3u8 (“v1”), landscape_1.m3u8 (“v2”), etc., each of which references the “parts” of that video,
Directories landscape_0/, landscape_1/ etc., each of which contain
data00.ts, data01.ts, etc.: the actual “chunks” that contain the video segments, which can be downloaded independently by the browser as-needed
Bringing it all together
We can bring all of that together, then, to produce a variable-aspect, adaptive bitrate, HLS-streamed video player… in pure HTML and suitable for static hosting:
<videocontrols><sourcesrc="squareish.m3u8"type="application/x-mpegURL"media="(min-aspect-ratio: 0.95) and (max-aspect-ratio: 1.05)"/><sourcesrc="portrait.m3u8"type="application/x-mpegURL"media="(orientation: portrait)"/><sourcesrc="landscape.m3u8"type="application/x-mpegURL"/></video>
You could, I suppose, add alternate types, poster images, and all kinds of other fancy stuff, but this’ll do for now.
One solution is to also provide the standard .mp4 files as an alternate <source>, and that’s fine I guess, but you lose the benefit of HLS (and
you have to store yet more files). But there’s a workaround:
Polyfill full functionality for all browsers
If you’re willing to use a JavaScript polyfill, you can make the code above work on virtually any device. I gave this a go, here, by:
Adding some JavaScript code that detects affected `<video>` elements and applying the fix if necessary:
// Find all <video>s which have HLS sources:for( hlsVideo of document.querySelectorAll('video:has(source[type="application/x-mpegurl"]), video:has(source[type="vnd.apple.mpegurl"])') ) {
// If the browser has native support, do nothing:if( hlsVideo.canPlayType('application/x-mpegurl') || hlsVideo.canPlayType('application/vnd.apple.mpegurl') ) continue;
// If hls.js can't help fix that, do nothing:if ( ! Hls.isSupported() ) continue;
// Find the best source based on which is the first one to match any applicable CSS media queriesconst bestSource =Array.from(hlsVideo.querySelectorAll('source')).find(source=>window.matchMedia(source.media).matches)
// Use hls.js to attach the best source:const hls =new Hls();
hls.loadSource(bestSource.src);
hls.attachMedia(hlsVideo);
}
It makes me feel a little dirty to make a <video>depend on JavaScript, but if that’s the route you want to go down while we wait for HLS support to become
more widespread (rather than adding different-typed sources) then that’s fine, I guess.
This was a fun dive into some technologies I’ve not had the chance to try before. A fringe benefit of being a generalist full-stack developer is that when you’re “between jobs”
you get to play with all the cool things when you’re brushing up your skills before your next big challenge!
(Incidentally: if you think you might be looking to employ somebody like me, my CV is over there!)
Footnotes
1 There definitely isn’t a super-secret “square” video on this page, though. No
siree. (Shh.)
2 You can tell when you get dropped to a lower-resolution version of a video because
suddenly everybody looks like they’re a refugee from Legoland.
Terence Eden, who’s apparently inspiring several posts this week, recently shared a way to attach a hook to WordPress’s
get_the_post_thumbnail() function in order to remove the extraneous “closing mark” from the (self-closing in HTML) <img> element.
By default, WordPress outputs e.g. <img src="..." />, where <img src="..."> would suffice.
It’s an inconsequential difference for most purposes, but apparently it bugs him, so he fixed it… although he went on to observe that he hadn’t managed to successfully tackle
all the instances in which WordPress was outputting redundant closing marks.
This is a problem that I’ve already solved here on my blog. My solution’s slightly hacky… but it works!
There are many things you could say about the HTML produced to make the page you’re reading now. But “it needs fewer />s” isn’t among them.
My Solution: Runing HTMLTidy over WordPress
Tidy is an excellent tool for tiding up HTML! I used to use its predecessor back in
the day for all kind of things, but it languished for a few years and struggled with support for modern HTML features. But
in 2015 it made a comeback and it’s gone from strength to strength ever since.
I run it on virtually all pages produced by DanQ.me (go on, click “View Source” and see for yourself!), to:
Standardise the style of the HTML code and make it easier for humans to read1.
Bring old-style emphasis tags like <i>, in my older posts, into a more-modern interpretation, like <em>.
Hoist any inline <style> blocks to the <head>, and detect any repeated inline style="..."s to convert to classes.
Repair any invalid HTML (browsers do this for you, of course, but doing it server-side makes parsing easier for the
browser, which might matter on more-lightweight hardware).
WordPress isn’t really designed to have Tidy bolted onto it, so anything it likely to be a bit of a hack, but here’s my approach:
Install libtidy-dev and build the PHP bindings to it.
Note that if you don’t do this the code might appear to work, but it won’t actually tidy anything2.
Add a new output buffer to my theme’s header.php3, with a callback function: ob_start('tidy_entire_page').
Without an corresponding ob_flush or similar, this buffer will close and the function will be called when PHP
finishes generating the page.
Define the function tidy_entire_page($buffer) Have it instantiate Tidy ($tidy = new tidy) and use $tidy->parseString (with your buffer and Tidy preferences) to tidy the code, then
return $tidy.
Ensure that you’re caching the results!
You don’t want to run this every page load for anonymous users! WP Super Cache on “Expert” mode (with the
requisite webserver configuration) might help.
1 I miss the days when most websites were handwritten and View Source typically looked
nice. It was great to learn from, too, especially in an age before we had DOM debuggers. Today: I can’t justify
dropping my use of a CMS, but I can make my code readable.
2 For a few of its extensions, some PHP developer made the interesting choice to fail silently if the required extension is missing. For example: if you don’t have the
zip extension enabled you can still usePHPto make ZIP files, but they won’t be
compressed. This can cause a great deal of confusion for developers! A similar issue exists with tidy: if it isn’t installed, you can still call all of the
methods on it… they just don’t do anything. I can see why this decision might have been made – to make the language as portable as possible in production – but I’d
prefer if this were an optional feature, e.g. you had to set try_to_make_do_if_you_are_missing_an_extension=yes in your php.ini to enable it, or if
it at least logged that it had done so.
3 My approach probably isn’t suitable for FSE (“block”) themes, sorry.
It all started when I saw no-ht.ml, Terence Eden‘s hilarious response to Salma
Alam-Naylor‘s excellent HTML is all you need to make a website. The latter is an
argument against both the silly amount of JavaScript with which websites routinely burden their users, but also even against depending on CSS. As a fan of CSS Naked Day and a firm
believer in using JS only for progressive enhancement, I’m obviously in favour.
Obviously no-ht.ml is to be taken as tongue-in-cheek, but as you’re about to see: it caught my interest and got me thinking: how could I go even further.
Terence’s site works by delivering a document with a
claimed MIME type of text/html, but which contains only the (invalid) “HTML” code
<!doctype UNICODE><meta charset="UTF-8"><plaintext> (to work around browsers’ wish to treat the page as HTML). This is followed by a block of UTF-8 plain text making use of spacing
and emoji to illustrate and decorate the content. It’s frankly very silly, and I love it.1
I think it’s possible to go one step further, though, and create a web page with no code whatsoever. That is, one that you can read as if it were a regular web page, but where
using View Source or e.g. downloading the page with curl will show you… nothing.
I present: The Page With No Code! (It’ll probably only work if you’re using Firefox, for reasons that will become apparent later.)
I’d encourage you to visit The Page With No Code, use View Source to confirm for yourself that it truly has no code, and see if you can work out for yourself how it manages
this feat… before coming back here for an explanation. Again: probably Firefox-only.
Once you’ve had a look for yourself and had a chance to form an opinion, here’s an explanation of the black magic that makes this atrocity possible:
The page is blank. It’s delivered with Content-Type: text/html. Your browser interprets a completely-blank page as faulty and corrects it to a functionally-blank
minimal HTML page: <html><head></head><body></body></html>.
<body> and <html> elements can be styled with CSS; this includes the ability to add
content:::before and ::after each
element. If only we could load a stylesheet then content injection is possible.
We use the fourth way to inject
CSS – a Link: HTTP header – to deliver a CSS payload (this, unfortunately, only works in Firefox). To further obfuscate what’s happening and remove the need for a round-trip, this is encoded
as a data: URI.
The stylesheet – and all the page content – is right there in the Link: header if you just care to decode it! Observe that while 5.84kB of
data are transferred, the browser rightly states that the page is zero bytes in size.
My server-side implementation of this broke in 2023 after I upgraded Nginx; my new version doesn’t support the super-long Link: header needed
to make this hack work, so I’ve updated the page to use the Link: to reference the CSS file rather than embed it via a data URI. It’s not as cool, but it at least means you can
still see the page. Thanks to Thomas Bradshaw for pointing out the problem.
Footnotes
1 My first reaction was “why not just deliver something with Content-Type:
text/plain; charset=utf-8 and dispense with the invalid code, but perhaps that’s just me overthinking the non-existent problem.
Using <input type="text" inputmode="numeric" pattern="[0-9]*"> allows for a degree of separation between how the user enters data (“input mode”), what the browser
expects the user input to contain (type equals number), and potentially how it tries to validate it.
…
I’ve sung the praises of the GDS research team before, and it’s for things like this that I respect them the most: they’re
knowing for taking a deep-dive user-centric approach to understanding usability issues, and they deliver valuable actionable answers off the back of it.
If you’ve got Web forms that ask people for numbers, this is how you should be doing it. If you’re doing so specifically for 2FA purposes, see that post I shared last month on a similar topic.
As part of the preparing to leave the Bodleian I’ve been revisiting a lot of the documentation I’ve written over the last eight
years. It occurred to me that I’ve never written publicly about how the Bodleian’s digital signage/interactives actually work; there are possible lessons to learn.
The Bodleian‘s digital signage is perhaps more-diverse, both in terms of technology and audience, than that of most organisations. We’ve got
signs in areas that are exclusively reader-facing to help students and academics find what they’re looking for, signs in publicly accessible rooms that advertise and educate, and signs
in gallery spaces upon which we try to present engaging and often-interactive content to support exhibitions.
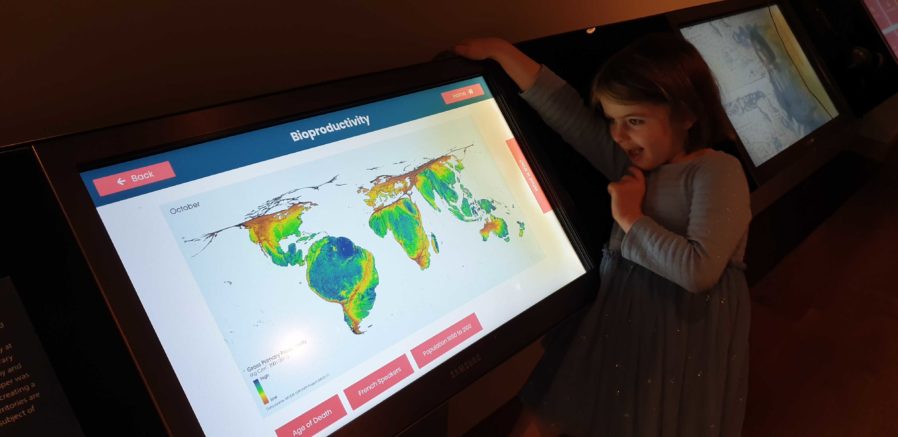
Getting an extra touchscreen for the office for prototyping/user testing purposes was great, even when it wasn’t showing MLP: FiM.
Throughout those three spheres, we’ve routinely delivered a diversity of content (let’s just ignore the countdown clock, for now…). Traditional
directional signage, advertisements, games, digital exhibitions, interpretation, feedback surveys…
In the vast majority of cases – and this is where the Bodleian’s been unusual (though certainly not unique) among cultural sector institutions – we’ve created
those in-house rather than outsourcing them.
Using off-the-shelf technology also allows the Bodleian to in-house much of their hardware maintenance, as a secondary part of other job roles. Singing into your screwdriver remains
optional, though.
To do this economically – the volume of work on interactive signage is inconsistent throughout the year – we needed to align the skills required with skills used elsewhere in the
organisation. To do this, we use the web as our medium! Collectively, the Bodleian’s Digital Communications team already had at least some experience in programming, web design, graphic
design, research, user testing, copyediting etc.: the essential toolkit for web application development.
Whether you were playing Pong on the video wall at the back or testing your Middle-earth knowledge on the touchscreen at the front… behind the
scenes you were interacting with a web page I wrote.
By shifting our digital signage platform to lean heavily on web technologies, we were able to leverage talented people we already had to produce things that we might otherwise
have had to outsource. This, in turn, meant that more exhibitions and displays get digital enhancement, on a shorter turnaround.
It also means that there’s a tighter integration between exhibition content and content for web and social media: it’s easier for us to re-use content across multiple platforms.
Sometimes we’ve even made our digital interactives, or adapted version of them, available directly online, allowing our exhibitions to reach people that can’t get to our physical spaces
at all.
Because we’re able to produce our own content on-demand, even our smaller, shorter-duration displays can have hands-on digital interactives associated with them.
On to the technology! We’re using a real mixture of tech: when it’s donated or reclaimed from previous projects (and when the bidding and acquisition processes are, well… as you’d
expect at the University of Oxford), you learn not to say no to freebies. Our fleet includes:
Samsung Android tablets with freestanding kiosk frames. We run the excellent-value Kiosk Browser Lockdown app on
these, which loads on boot and prevents access to anything but a specified website.
OnelanNTBs connected to a mixture of
touch and non-touch screens, wall-mounted or in kiosk frames. We use Onelan’s standard digital signage features as well as – for interactive content – their built-in touch-capable web
browser.
Dell PCs of the standard variety supplied by University IT services, connected to wall-mounted touch screens, running Google Chrome in Kiosk Mode. More on this below.
The browsers’ responsive simulators are invaluable when we’re targeting signage at five (!) different resolutions.
When you’re developing content for a very small number of browsers and a limited set of screen sizes, you quickly learn to throw a lot of “best practice” web development out of the
window. You’ll never come across a text browser or screen reader, so alt-text doesn’t matter. You’ll never have to rescale responsively, so you might as well absolutely-position almost
everything. The devices are all your own, so you never need to ask permission to store cookies. And because you control the platform, you can get away with making configuration tweaks
to e.g. allow autoplaying videos with audio. Coming from a conventional web developer background to producing digital signage content makes feels incredibly lazy.
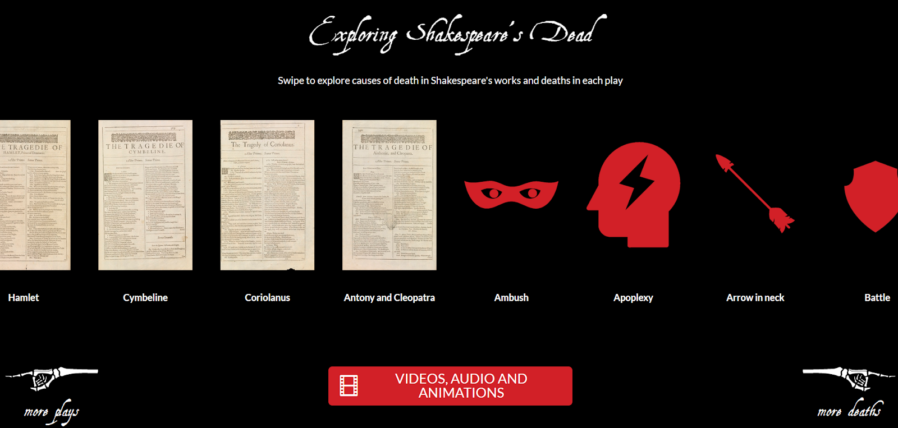
Helping your users see your interactive as “app-like” rather than “web-like” encourages them to feel comfortable engaging with it in ways uncharacteristic of web pages. In our Shakespeare’s Dead interactive, for example, we started the experience in the middle of a long horizontally-scrolling “page”, which might
feel very unusual in a conventional browser.
Using Chrome to run digital signage requires, in the Bodleian’s case, a couple of configuration tweaks and the right command-line switches. We use:
chrome://flags/#overscroll-history-navigation – disabling this prevents users from triggering “back”/”forward” by swiping with two fingers
chrome://flags/#pull-to-refresh – disabling this prevents the user from triggering a “refresh” by scrolling up beyond the top of the page (this only happens on some
kinds of devices)
chrome://flags/#system-keyboard-lock – we don’t use attached keyboards, but if you do, you might want to set this flag so you can use the keyboard.lock()
API to intercept e.g. ALT+F4 so users can’t escape the application
running on startup with e.g. chrome --kiosk --noerrdialogs --allow-file-access-from-files --disable-touch-drag-drop --incognito https://example.com/some/url
Kisok mode makes the browser run fullscreen and prevents e.g. opening additional tabs, giving an instant “app-like” experience. As we don’t have keyboards attached to our
digital signage, this also prevents visitors from closing Chrome.
Turning off error dialogs reduces the risk that an error will result in an unslightly message to the user.
Enabling “file access from files” allows content hosted at file:// addresses to access content at other file:// addresses, which makes it possible to write “offline” sites
(sometimes useful where we’re serving large videos or on previous occasions when WiFi has been shaky) that can still take advantage of features like the Fetch API.
Unless you need drag-and-drop, it’s simpler to disable it; this prevents a user long-press-and-dragging an image around the screen.
Incognito mode ensures that the browser doesn’t remember what site was showing last time it ran; our computers often end up switched off at the wall at the end of the day, and
without this the browser will offer to load the site it had open last time, when it runs.
We usually host our interactives directly on the web, at “secret” addresses, and this is generally preferable to us as we can more-easily make on-the-fly adjustments to
content (plus it makes it easier to hook up analytic tools).
Be sure to test the capabilities of your hardware! Our Onelan NTBs, unlike your desktop PCs, can’t handle multitouch input, which
affects the design of our user interfaces for these devices.
Meanwhile, in the application’s CSS code, we set * { user-select: none; } to prevent the user from highlighting
text by selecting it with their finger. We also make heavy use of absolutely-sized/positioned, overflow: hidden blocks to ensure that scrollbars never appear, and
CSS animations to make content feel dynamic and to draw attention to particular elements.
There’s no substitute for good testing. And there’s no stress-testing quite like letting a 5 year-old loose on your work.
Altogether, this approach gives the Bodleian the capability to produce engaging interactive content at low cost and using the existing skills of their digital and exhibitions teams.
It’s not an approach that would work for every cultural institution: in particular, some of the Bodleian’s sister institutions already
outsource the technical parts of their web work, and so don’t have the expertise in-house to share with a web-powered digital signage solution.
A few minor CSS tweaks to make the buttons finger-friendly and our Halloween game Shadows Out Of
Time, which I’d already made web-friendly, was touchscreen-ready too. I wonder if they’ll get this one out again, this
Halloween?
But for those museums that can fit into this model – or can adapt to do so in future – using the web to produce interactive digital content and digital signage is a highly
cost-effective way to engage with visitors, even (or especially!) when dealing with short-lived and/or rotating displays.
It’s also been among my favourite parts of my job at the Bod these last 8½ years, and I’m sure I’ll miss it!
When I write a blog post, it generally becomes a static thing: its content always
usually stays the same for the rest of its life (which is, in my case, pretty much forever). But sometimes, I go back and make an
amendment. When I make minor changes that don’t affect the overall meaning of the work, like fixing spelling mistakes and repointing broken links, I just edit the page, but for
more-significant changes I try to make it clear what’s changed and how.
This blog post from 2007, for example, was amended after its publication with the insertion of content at the top and the deletion
of content within.
Historically, I’d usually marked up deletions with the HTML <strike>/<s> elements (or
other visually-similar approaches) and insertions by clearly stating that a change had been made (usually accompanied by the date and/or time of the change), but this isn’t a good
example of semantic code. It also introduces an ambiguity when it clashes with the times I use <s> for comedic effect in the Web equivalent of the old caret-notation joke:
Be nice to this fool^H^H^H^Hgentleman, he's visiting from corporate HQ.
Better, then, to use the <ins> and <del> elements, which were designed for exactly this purpose and even accept attributes to specify the date/time
of the modification and to cite a resource that explains the change, e.g. <ins datetime="2019-05-03T09:00:00+00:00"
cite="https://alices-blog.example.com/2019/05/03/speaking.html">The last speaker slot has now been filled; thanks Alice</ins>. I’ve worked to retroactively add such
semantic markup to my historical posts where possible, but it’ll be an easier task going forwards.
Of course, no browser I’m aware of supports these attributes, which is a pity because the metadata they hold may well have value to a reader. In order to expose them I’ve added a little
bit of CSS that looks a little like this, which makes their details (where available) visible as a sort-of tooltip when hovering
over or tapping on an affected area. Give it a go with the edits at the top of this post!
ins[datetime],del[datetime]{position:relative;}ins[datetime]::before,del[datetime]::before{position:absolute;top:-24px;font-size:12px;color:#fff;border-radius:4px;padding:2px6px;opacity:0;transition:opacity0.25s;
hyphens:none;/* suppresses sitewide line break hyphenation rules */white-space:nowrap;/* suppresses extraneous line breaks in Chrome */}ins[datetime]:hover::before,del[datetime]:hover::before{opacity:0.75;}ins[datetime]::before{content:'inserted 'attr(datetime)''attr(cite);background:#050;/* insertions are white-on-green */}del[datetime]::before{content:'deleted 'attr(datetime)''attr(cite);background:#500;/* deletions are white-on-red */}
CSS facilitating the display of <ins>/<del> datetimes and citations on hover or touch.
I’m aware that the intended use-case of <ins>/<del> is change management, and that the expectation is that the “final” version of a
document wouldn’t be expected to show all of the changes that had been made to it. Such a thing could be simulated, I suppose, by appropriately hiding and styling the
<ins>/<del> blocks on the client-side, and that’s something I might look into in future, but in practice my edits are typically small and rare
enough that nobody would feel inconvenienced by their inclusion/highlighting: after all, nobody’s complained so far and I’ve been doing exactly that, albeit in a non-semantic way, for
many years!
I’m also slightly conscious that my approach to the “tooltip” might cause it to obstruct interactivity with something directly above an insertion or deletion: e.g. making a hyperlink
inaccessible. I’ve tested with a variety of browsers and devices and it doesn’t seem to happen (my line height works in my favour) but it’s something I’ll need to be mindful of if I
change my typographic design significantly in the future.
A final observation: I love the CSS attr() function, and I’ve been using it (and counter()) for all
kinds of interesting things lately, but it annoys me that I can only use it in a content: statement. It’d be amazingly valuable to be able to treat integer-like attribute
values as integers and combine it with a calc() in order to facilitate more-dynamic styling of arbitrary sets of HTML elements. Maybe one day…
For the time being, I’m happy enough with my new insertion/deletion markers. If you’d like to see them in use in their natural environment, see the final paragraph of my 2012 review of The Signal and The Noise.
As I indicated in my last blog post, my new blog theme has a “pop up” Dan in the
upper-left corner. Assuming that you’re not using Internet Explorer, then when you move your mouse cursor over it, my head will “duck” back behind the bar below it.
My head "pops up" in the top-left hand corner of the site, and hides when you hover your mouse cursor over it.
This is all done without any Javascript whatsoever: it’s pure CSS. Here’s how it’s done:
<divclass="sixteen columns"> <divid="dans-creepy-head"></div> <h1id="site-title"class="graphic">
<ahref="/"title="Scatmania">Scatmania</a>
</h1> <spanclass="site-desc graphic">
The adventures and thoughts of "Scatman" Dan Q
</span> </div>
The HTML for the header itself is pretty simple: there’s a container (the big blue bar) which contains, among other things, a <div> with the id
"dans-creepy-head". That’s what we’ll be working with. Here’s the main CSS:
The CSS sets a size, position, and background image to the <div>, in what is probably a familiar way. A :hover selector changes the style to increase the
distance from the top of the container (from -24px to 100px) and to decrease the height, cropping the image (from 133px to 60px – this was necessary
in this case to prevent the bottom of the image from escaping out from underneath the masking bar that it’s supposed to be “hiding behind”). With just that code, you’d have a perfectly
workable “duck”, but with a jerky, one-step animation.
The transition directive (and browser-specific prefix versions -o-transition, -webkit-transition, and -moz-transition, for compatability) are what
makes the magic happen. This element specifies that any ("all") style is changed on this element (whether via CSS directives, as in this case, or by a change of class or
properties by a Javascript function), that a transition effect will be applied to those changes. My use of "all" is a lazy catch-all – I could have specified the
individual properties ( top and height) that I was interested in changing, and even put different periods on each, but I’ll leave it to you to learn about CSS3 transition options for yourself. The 800ms is the
duration of the transition: in my case, 0.8 seconds.
I apply some CSS to prevent the :hover effect from taking place in Internet Explorer, which doesn’t support transitions. The "ie" class is applied to the
<html> tag using Paul Irish’s technique, so it’s easy to detect and handle IE users without
loading separate stylesheet files for them. And finally, in order to fit with my newly-responsive design, I make the pop-up head disappear when the window is under 780px wide (at which
point there’d be a risk of it colliding with the title).
That’s all there is to it! A few lines of CSS, and you’ve got an animation that degrades gracefully. You could equally-well apply transformations to links (how about making them fade in
or out, or change the position of their background image?) or, with a little Javascript, to your tabstrips and drop-down menus.
Oh yeah: I changed the look-and-feel of scatmania.org the other week, in case you hadn’t noticed. It’s become a
sort-of-traditional January activity for me, these years, to redesign the theme of my blog at this point in the year.
This year’s colours are black, white, greys, and red, and you’ll note also that serifed fonts are centre-stage again, appearing pretty-much-universally throughout the site for the first
time since 2004. Yes, I know that it’s heavier and darker than previous versions of the site: but it’s been getting fluffier and lighter year on year for ages, now, and I thought it was
time to take a turn. You know: like the economy did.
This new design has elements in common with the theme before last: a big blue header, an off-white background, and sans-serif faces.
Aside from other cosmetic changes, it’s also now written using several of the new technologies of HTML5 (I may put the shiny new logo on it, at some point). So apologies to those of you running archaic and non-standards-compliant browsers (I’m looking at you, Internet
Explorer 6 users) if it doesn’t look quite right, but really: when your browser is more than half as old as the web itself, it’s time to upgrade.
I’ve also got my site running over IPv6 – the next generation Internet protocol – for those of you who care about those sorts of things. If you don’t know why IPv6 is important and “a
big thing”, then here’s a simple explanation.
Right now you’re probably viewing the IPv4 version: but if you’re using an IPv6-capable Internet connection, you might be viewing the IPv6 version. You’re not missing out, either way:
the site looks identical: but this is just my tiny contribution towards building the Internet of tomorrow.
(if you really want to, you can go to ipv6.scatmania.org to see the IPv6 version – but it’ll only work if your Internet Service
Provider is on the ball and has set you up with an IPv6 address!)