I’d love to write a longer review to praise the art style and the concept, but there’s not much to say. Just… go and give it a shot; it’ll improve your day, I’m sure.
I think of ElonStan420 standing in that exhibit hall, eyeing those cars with disdain because all that time, energy, care, and expression “doesn’t really matter”. Those hand-painted
pinstripes don’t make the car faster or cheaper. Chrome-plated everything doesn’t make it more efficient. No one is going to look under the hood anyway.
…
Don’t read the comments on HackerNews, Adam! (I say this, but I’ve yet to learn not to do so myself, when occasionally my writing escapes from my site and finds its way over there.)
But anyway, this is a fantastic piece about functionalism. Does it matter whether your website has redundant classes defined in the HTML? It renders the same anyway, and odds are good
that nobody will ever notice! I’m with Adam: yes, of course it can matter. It doesn’t have to, but coding is both a science and an art, and
art matters.
…
Should every website be the subject of maximal craft? No, of course not. But in a industry rife with KPI-obsessed, cookie-cutter, vibe-coded, careless slop, we could use
more lowriders.
“OK,” the young man said, “but what can we do about the crash?” He was clearly very worried.
“I don’t think there’s anything we can do about that. I think it’s already locked in. I mean, maybe if we had a different government, they’d fund a jobs guarantee to pull us out of
it, but I don’t think Trump’ll do that, so –”
“But what can we do?“
We went through a few rounds of this, with this poor kid just repeating the same question in different tones of voice, like an acting coach demonstrating the five stages of grieving
using nothing but inflection. It was an uncomfortable moment, and there was some decidedly nervous chuckling around the room as we pondered the coming AI (economic) apocalypse, and
the fate of this kid graduating with mid-six-figure debts into an economy of ashes and rubble.
I firmly believe the (economic) AI apocalypse is coming.
…
I’m not sure I entirely agree with Doctorow on this one. I’ll probably read his upcoming book on the subject, though.
I agree that, based on the ways in which AI is being used, financed, and marketed… we’re absolutely in an unsustainable bubble. There’s a lot of fishy
accounting, dubious business models, and overpromised marketing. I’m not saying AI’s useless: it’s not! But it’s yet proven
itself to be revolutionary, nor even on the path to being so, and it’s so expensive that it seems unlikely that the current “first dose is free” business model is
almost-certainly unsustainable.
But I’m not convinced that a resulting catastrophic economic collapse is inevitable. Maybe I’m over-optimistic, but I like to imagine that the bubble can
fizzle-out gradually and the actually-valuable uses of AI can continue to be used in a sustainable way. (I’m less-optimistic that we’ll find a happy-solution to prevent AI from being
used to rip off artists, but that’s another story.)
I’ve tried to be pragmatic, but there’s something of a dilemma here.
Users should be free to run whatever code they like.
Vulnerable members of society should be protected from scams.
Do we accept that a megacorporation should keep everyone safe at the expense of a few pesky nerds wanting to run some janky code?
Do we say that the right to run free software is more important than granny being protected from scammers?
Do we pour billions into educating users not to click “yes” to every prompt they see?
Do we try and build a super-secure Operating System which, somehow, gives users complete freedom without exposing them to risk?
Do we hope that Google won’t suddenly start extorting developers, users, and society as a whole?
Do we chase down and punish everyone who releases a scam app?
Do we stick an AI on every phone to detect scam apps and refuse to run them if they’re dodgy?
I don’t know the answers to any of these questions and – if I’m honest – I don’t like asking them.
Google’s gradual locking-down of Android bothers me, too. I’ve rooted many of my phones
in order to unlock features that I benefit from (as a developer… and as a nerd!), and it’s bugged me on the occasions where I’ve been unable to run had to use complicated
workarounds to trick e.g. a bank’s app. Having gone to the effort to root a phone – which remains outside of the reach of most regular users – I’d be happy to accept an appropriate
share of the liability if my mistake, y’know, let a scammer steal all of my money.
That’s the risk you take with any device on which you have root, and it’s why we make it hard to the point of being discouraging. Because you can’t just put up a
warning and hope that users will read and understand it, because they won’t. They’ll just click whatever button looks like it’ll get them to the next step without even glancing at the
danger signs1.
I’m glad to have been increasingly decoupling myself from Google’s ecosystem, because I’ve been burned by it too. Like Terence, I’ve been hit by “real name” policies that discriminate against people with unusual names or who might be
at risk of impersonation2.
But I’m not convinced that there’s a good alternative for me to running Android on my mobile devices, at the moment: I really enjoyed Maemo back in the day; what’s the status of
Sailfish nowadays?
I get that we need to protect people from dangerous scammy apps. But I’d like to think there’s a middle-ground somewhere between Doctrowian “it’s your device, you’re responsible for
what runs on it” and the growing Apple/Google thinking of “if we don’t have the targetting coordinates of the developer that wrote the code, our OS won’t let you run it”. I’m ready to
concede that user education alone hasn’t worked, but there’s got to be a better solution than this, Google.
Footnotes
1 Incidentally, I don’t blame users for this behaviour. Users have absolutely
been conditioned, and continue to be conditioned, to click-without-reading. Cookie and privacy banners with dark patterns, EULAs and legal small print are notoriously (and often
unnecessarily) long and convoluted, and companies routinely try to blur the line between “serious thing you should really read but we want you not to” and “trivial thing that you
don’t need to read; it’s just a formality that we have to say it”.
2 Right now, my biggest fight with Google has come from the fact that lately, it seems
like every time I upload a Three Rings demo video to YouTube it gets deleted under their harassment policy for doxxing people…
people like “Alan Fakename” from Somewhereville, “Betty Notaperson” from Otherplace, and their friend “Chris McMadeup” who lives at 123 Imaginary Street. The appeals process turns out
to be that you click a button to appeal, but don’t get to provide any further information (e.g. to explain that these are clearly-fake people who won’t mind being doxxed on account of
the fact that they don’t exist), and then a few hours later you get an email to say “nah, we’re keeping it deleted”. I almost expect the YouTube version of my recent video demonstrating FreeDeedPoll.org.uk will be
next to be targetted by this policy for showing me scribbling the purported signature Sam McRealName, formerly known as Jo Genuine-Person.
In 2024, we each seperately submitted Freedom of Information requests to our country’s railway operators, asking for specification about how their barcodes worked. This has made a
lot of people very angry and has been widely regarded as a bad move.
This talk details the drama, lies, and nonsense, that ensued as seemingly every part of the UK’s and Slovenian rail industry set out to stop us from getting access to the
documents we requested.
Train tickets in the UK can be issued in two formats: on security card stock, or as a barcode on a mobile phone. Being the curious beings we are, we were curious about what was in
those barcodes. What information on us is processed in them? How do they encode our journeys? Can we do anything interesting with their contents?
…
In spite of knowledge from the reverse engineering work about these tickets’ use of public/private key cryptography, and the absolute non-issue of making public keys, well, public,
seemingly every part of the UK rail industry put Q’s picture on their office dartboard and vowed to never let them have these documents.
…
A really interesting-sounding session at MRMCD 2025 in a couple of weeks, by that other hacker called Q. Wish I could be there… but
failing that, perhaps the talk, or at least the discoveries, will make their way onto the open Internet?
Mastodon shows an “Alt” button in the bottom right of images that have associated alt text. This button, when clicked, shows the alt text the author has written for the image.
…
After using this button a few times, I realised how much I appreciated reading the alt text for an image. Reading the alt text helped me better understand an image. In some cases, I
saw posts where the alt text contained context about an image I otherwise would not have had (i.e. the specific name of the game from which a screenshot was taken).
…
Like James, I’ve also long enjoy Mastodon’s tools to help explore alt-text more-easily, but until I saw this blog post of his I’d never have considered porting such functionality to my
own sites.
He’s come up with an implementation, described in his post, that works pretty well. I find myself wondering if a <details>/<summary> UI metaphor
might be more appropriate than a visually-hidden checkbox. Where CSS is disabled or fails, James’ approach displays a checkbox, the word “ALT”, and the entire alt text, which is
visually confusing and will result in double-reading by screen readers.
A <details>/<summary> approach would be closer to
semantically-valid (though perhaps I’m at risk of making them a golden hammer?), and would degrade more gracefully
into situations in which CSS wasn’t available.
Still, a wonderful example of what can be done and something I might look at replicating during my next bout of blog redesigning!
Anyway: Acai turns out to be not only a kickass Clone Hero player, but he’s also a fun and charismatic commentator to take along for the ride.
Incidentally, it was fun to see that the same level of attention to detail has been paid to the on-screen lyrics for Clone Hero as were to the subtitles on the video version of the album. For example, they’ll sometimes imply that the next line is what
you’re expecting it to be, based on a familiarity with the song, only to bait-and-switch it out for the actual lyrics at the last second. Genius.
Do I need a “spoiler warning” here? Part of what made the album wonderful for me was coming in blind and not understanding that, somehow, it was both a mashup
collection and a concept album. I’d seriously recommend listening to it yourself and making your own mind up first, before you read my or anybody else’s interpretation of
the themes of the piece.
But assuming that you already listened to it, or that you’re ignoring my suggestion, here’s sophie’s review:
… what?
I am floored. Absolutely flummoxed. This is the first album in a minute to leave me completely speechless. Trying to express how incredible what the fuck I just listened to was is
more than difficult, but I suppose I can try because this album is unbelievably underrated and deserves a million times the attention it’s currently getting. There are really two
main pillars holding this up (don’t overthink that analogy, no, a building with two pillars wouldn’t hold up but that doesn’t matter shut up), those being the execution and the
concept. On a purely technical level, this album is unbelievable. These mashups are so well-achieved, so smooth and believable and un-clunky. The execution of the record is to such
a high standard it almost tricks you, like the best mashup albums do, into believing the pieces of song were always meant to be in this iteration. Purely from a how-does-it-sound
perspective, Musical Transients is remarkable.
But the second pillar, the one that really shook me to my core, is the concept. Don’t read past this point if you don’t want it to get spoiled. Essentially, the narrator of Musical
Transients is a person who realizes he is a she. It’s a trans self-realization project, and one handled with an unbelievable amount of telling care. The mashups are placed together
in a very purposeful manner to express this story chronologically, and the result is a pretty incomparable arc and deeply involving experience. Despite not a single note being
original, you really feel the person behind the screen making it, their story. And despite the subject matter often being focused on the confusion and depression a trans person
might feel, Musical Transients feels more like a towering celebration of trans identity and existence than a depressive meditation on trans suffering. It’s a remarkable feat of
storytelling and mashup production that just works on so many different levels. To me, it has to be among the most impeccably crafted, achingly beautiful albums of the year.
Yes. Yes, this.
I absolutely agree with sophie that there are two things which would individually make this an amazing album, but taken together they elevate the work to something even
greater.
The first aspect of its greatness is the technical execution of the album. Effortless transitions1 backed by clever use of pitch and tempo shifts, wonderfully-executed breakspoints between lines,
within lines, even within words, and such carefully-engineered extraction of the parts of each of the component pieces that it’s hard to believe that
Psynwav doesn’t secretly have access to the studio master recordings of many of them2.
But the second is the story the album tells. Can you tell a story entirely through a musical mashup of other people’s words? You absolutely can, and Musical Transients
might be the single strongest example.
I was perhaps in the third or fourth track, on my first listen-through, when I started asking myself… “Wait a minute? Is this the story of a trans person’s journey of
self-discovery, identity, and coming out?” And at first I thought that I might be reading more into it than was actually there. And then it took until the tremendous,
triumphant final track before I realised “Oh shit, that’s exactly what it’s about. How is it even possible to convey that message in an album like this?”
It’s possible I’d have “got it” sooner had my first listen-through had been to the the “music video version” of the album,
which features visual clues both subtle3
and less-subtle, like… well, the colours in this blinds-transition.
This is a concept album unlike any other that I’ve ever heard. It tells a heartwarming story of trans identity and of victory in the face of adversity. You’re taken along with the
protagonist’s journey, discovering and learning as you go, with occasional hints as the the underlying meaning gradually becoming more and more central to the message. It’s as if you,
the listener, are invited along to experience the same curiosity, confusion, and compromise as the past-version of the protagonist, finding meaning as you go along, before “getting it”
and being able to celebrate in her happiness.
I wish I’d watched the music video version first. Maybe I should be recommending that to people.
And it does all of this using a surprising and entertaining medium that’s so wonderfully-executed that it can be enjoyed even without the obvious4
message that underpins it.
Okay, maybe now I can be done gushing about this album. Maybe.
2 Seriously: how do you isolate the vocals from the chorus of We Will Rock
You while cleanly discarding the guitar sounds? They’re at almost-exactly the same pitch!
3 A subtle visual affordance in the music video might the VHS lines that indicate when
we’re being told “backstory”, which unceremoniously disappear for the glorious conclusion, right after Eminem gets cut off, saying “My name is…”.
4 Yes, obvious. No, seriously; I’m not reaching here. Trans identity is a clear
and unambiguous theme, somehow, without any lyrics explicitly talking about that topic being written; just the careful re-use of the words of other. Just go listen to it and you’ll
see!
This is the age we’re shifting into: an era in which post-truth politics and deepfake proliferation means that when something looks “a bit off”, we assume (a) it’s AI-generated, and (b)
that this represents a deliberate attempt to mislead. (That’s probably a good defence strategy nowadays in general, but this time around it’s… more-complicated…)
…
So if these fans aren’t AI-generated fakes, what’s going on here?
The video features real performances and real audiences, but I believe they were manipulated on two levels:
Will Smith’s team generated several short AI image-to-video clips from professionally-shot audience photos
YouTube post-processed the resulting Shorts montage, making everything look so much worse
…
I put them side-by-side below. Try going full-screen and pause at any point to see the difference. The Instagram footage is noticeably better throughout, though some of the audience
clips still have issues.
…
The Internet’s gone a bit wild over the YouTube video of Will Smith with a crowd. And if you look at it, you can see why:
it looks very much like it’s AI-generated. And there’d be motive: I mean, we’ve already seen examples where politicians have been accused (falsely, by Trump, obviously) of using AI to exaggerate the size of their crowds, so
it feels believable that a musician’s media team might do the same, right?
But yeah: it turns out that isn’t what happened here. Smith’s team did use AI, but only to make sign-holding fans from other concerts on the same tour appear
to all be in the same place. But the reason the video “looks AI-generated” is because… YouTube fucked about with it!
It turns out that YouTube have been secretly experimenting with upscaling
shorts, using AI to add detail to blurry elements. You can very clearly see the effect in the video above, which puts the Instagram and YouTube versions of the video side-by-side (of
course, if YouTube decide to retroactively upscale this video then the entire demonstration will be broken anyway, but for now it works!). There are many
points where a face in the background is out-of-focus in the Instagram version, but you can see in the YouTube version it’s been brought into focus by adding details. And
some of those details look a bit… uncanny valley.
Every single bit of this story – YouTube’s secret experiments on creator videos, AI “enhancement” which actually makes things objectively worse, and the immediate knee-jerk reaction of
an understandably jaded and hypersceptical Internet to the result – just helps cement that we truly do live in the stupidest timeline.
Musical Transients from Psynwav1 is without a
doubt the best mashup/mixtape-album I’ve heard since Neil Cicierega’s Mouth Moods (which I’ve listened to literally
hundreds of times since its release in 2017). Well-done, Psynwav.
It’s possible, of course… that my taste in music is not the same as your taste in music, and that’s fine.
Footnotes
1 If you’ve heard of Psynwav already it’s probably thanks to 2021’s Slamilton, which is probably the best Space Jam/Hamilton crossover soundtrack ever made.
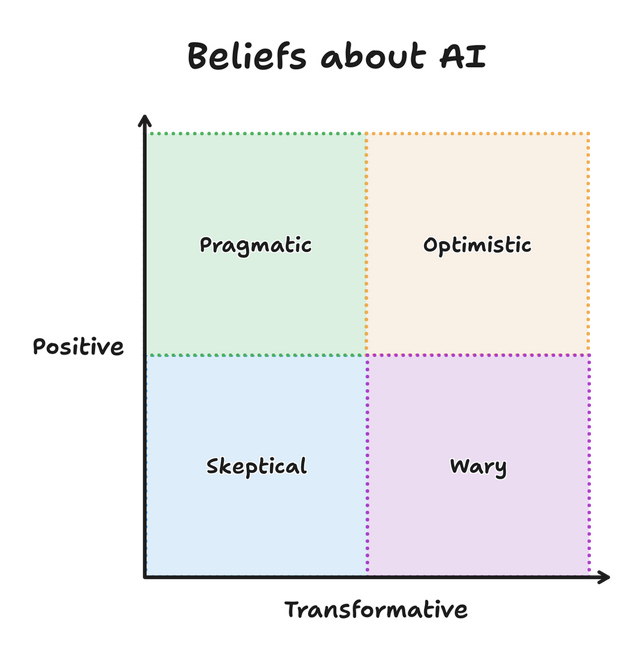
I’ve grouped these four perspectives, but everything here is a spectrum. Depending on the context or day, you might find yourself at any point on the graph. And I’ve attempted to
describe each perspectively [sic] generously, because I don’t believe that any are inherently good or bad. I find myself switching between perspectives throughout the
day as I implement features, use tools, and read articles. A good team is probably made of members from all perspectives.
Which perspective resonates with you today? Do you also find yourself moving around the graph?
…
An interesting question from Sean McPherson. He sounds like he’s focussed on LLMs for software development, for which I’ve drifted around a little within the left-hand-side of the
graph. But perhaps right now, this morning, you could simplify my feelings like this:
My stance is that AI-assisted coding can be helpful (though the question remains open about whether it’s “worth
it”), so long as you’re not trying to do anything that you couldn’t do yourself, and you know how you’d go about doing it yourself. That is: it’s only useful to
accelerate tasks that are in your “known knowns” space.
As I’ve mentioned: the other week I had a coding AI help me with some code that interacted
with the Google Sheets API. I know exactly how I’d go about it, but that journey would have to start with re-learning the Google Sheets API, getting an API key and giving
it the appropriate permissions, and so on. That’s the kind of task that I’d be happy to outsource to a less-experienced programmer who I knew would bring a somewhat critical eye for
browsing StackOverflow, and then give them some pointers on what came back, so it’s a fine candidate for an AI to step in and give it a go. Plus: I’d be treating the output as “legacy
code” from the get-go, and (because the resulting tool was only for my personal use) I wasn’t too concerned with the kinds of security and accessibility considerations that GenAI can
often make a pig’s ear of. So I was able to palm off the task onto Claude Sonnet and get on with something else in the meantime.
If I wanted to do something completely outside of my wheelhouse: say – “write a program in Fortran to control a robot arm” – an AI wouldn’t be a great choice. Sure, I
could “vibe code” something like that, but I’d have no idea whether what it produced was any good! It wouldn’t even be useful as a springboard to learning how to do that, because I
don’t have the underlying fundamentals in robotics nor Fortran. I’d be producing AI slop in software form: the kind of thing that comes out when non-programmers assume that AI can
completely bridge the gap between their great business idea and a fully working app!
The latest episode of South Park kinda nailed parodying the unrealistic expectations that some folks
seem to put on generative AI: treating it as intelligent or as a friend is unhealthy and dangerous!
They’ll get a prototype that seems to do what you want, if you squint just right, but the hard part of software engineering isn’t making a barebones proof-of-concept! That’s the easy
bit! (That’s why AI can do it pretty well!) The hard bit is making it work all the time, every time; making it scale; making it safe to use; making it maintainable; making it
production-ready… etc.
But I do benefit from coding AI sometimes. GenAI’s good at summarisation, which in turn can make it good at relatively-quickly finding things in a sprawling
codebase where your explanation of those things is too-woolly to use a conventional regular expression search. It’s good at generating boilerplate that’s broadly-like examples its seen
before, which means it can usually be trusted to put together skeleton applications. It’s good at “guessing what comes next” – being, as it is, “fancy autocomplete” – which means it can
be helpful for prompting you for the right parameters for that rarely-used function or for speculating what you might be about to do with the well-named variable you just
created.
Solving problems with LLMs is like solving front-end problems with NPM: the “solution” comes through installing more and more things — adding more and more context, i.e. more and
more packages.
LLM: Problem? Add more context.
NPM: Problem? There’s a package for that.
…
As I’m typing this, I’m thinking of that image of the evolution of the Raptor engine, where it evolved in simplicity:
This stands in contrast to my working with LLMs, which often wants more and more context from me to get to a generative solution:
…
Jim Nielsen speaks to my experience, here. Because a programming LLM is simply taking inputs (all of your code, plus your prompt), transforming it through statistical analysis, and then
producing an output (replacement code), it struggles with refactoring for simplicity unless very-carefully controlled. “Vibe coding” is very much an exercise in adding hacks upon hacks…
like the increasingly-ludicrous epicycles introduced by proponents of geocentrism in its final centuries before the heliocentric model became fully accepted.
This mess used to be how many perfectly smart people imagined the movements of the planets. When observations proved it couldn’t be right, they’d just add more
complexity to catch the edge cases.
I don’t think that AIs are useless as a coding tool, and I’ve successfully used them to good effect on
several occasions. I’ve even tried “vibe coding”, about which I fully agree with Steve Krouse‘s observation that
“vibe code is legacy code”. Being able to knock out something temporary, throwaway, experimental, or for personal use only… while I work on
something else… is pretty liberating.
For example: I couldn’t remember my Google Sheets API and didn’t want to re-learn it from the sprawling documentation site, but wanted a quick personal tool to manipulate such a sheet
from a remote system. I was able to have an AI knock up what I needed while I cooked dinner for the kids, paying only enough attention to check-in on its work. Is it accessible? Is it
secure? Is it performant? Is it maintainable? I can’t answer any of those questions, and so as a professional software engineer I have to reasonably assume the answer to
all of them is “no”. But its only user is me, it does what I needed it to do, and I didn’t have to shift my focus from supervising children and a pan in order to throw it together!
Anyway: Jim hits the nail on the head here, as he so often does.
“For years, starting in the late ‘70s, I was taking pictures of hitchhikers. A hitchhiker is someone you may know for an hour, or a day, or, every so often, a little longer, yet,
when you leave them, they’re gone. If I took a picture, I reasoned, I’d have a memory. I kept a small portfolio of photos in the car to help explain why I wanted to take their
picture. This helped a lot. It also led me to look for hitchhikers, so that I could get more pictures.
“I almost always had a camera… I finally settled on the Olympus XA – a wonderful little pocket camera. (I’ve taken a picture of the moon rising with this camera.) One time I asked a
chap if I could take a photo, and he said, “You took my picture a few years ago.” I showed him the album and he picked himself out. “That’s me,” he said, pointing…”
…
Not that hitch-hiking is remotely as much a thing today as it was 50 years ago, but even if it were then it wouldn’t be so revolutionary to, say, take a photo of everybody you give a
ride to. We’re all carrying cameras all the time, and the price of taking a snap is basically nothing.
But for Doug Biggert, who died in 2023, began doing this with an analogue camera as he drove around California from 1973 onwards? That’s quite something. Little wonder he had
to explain his project to his passengers (helped, later on, by carrying a copy of the photo album he’d collected so-far that he could show them).
A really interesting gallery with a similarly-compelling story. Also: man – look at the wear-and-tear on his VW Bug!
I can’t begin to fathom the courage it takes to get on-stage in front of an ultra-conservative crowd (well, barely a crowd…) in a right-leaning US state to protest their
event by singing a song about a trans boy. But that’s exactly what Hamrick did. After
catching spectators off-guard, perhaps, by taking the perhaps-“masculine-telegraphing” step of drawing attention to part of his army uniform, the singer swiftly switched outfit to show
off a “Keep Canyon County Queer” t-shirt, slip on a jacket with various Pride-related patches, and then immediately launched into Boy, a song lamenting the persecution of
a trans child by their family and community.
Needless to say, this was the first, last, and only song Daniel Hamrick got to play at Hetero Awesome Fest. But man, what a beautiful protest!
(There are other videos online that aren’t nabbed from the official event feed and so don’t cut-out abruptly.)
I still get that powerful feeling that anything is possible when I open a web browser — it’s not as strong as it was 20 years ago, but it’s still there.
As cynical as you can get at the state of the Web right now… as much as it doesn’t command the level of inspirational raw potential of “anything is possible” that it might have once…
it’s still pretty damn magical, and we should lean into that.