It’s been a hundred and thirteen days since the flood that wrecked our house, and we’re told that repair work will start imminently. Like: as
soon as next week!
So today I returned to the house to try to disassemble my sit/stand desk. An enormous and heavy thing that was constructed in-situ, it survived the flood without significant damage but
is sort of hard-to-move for the purpose of getting it out of the way of the folks who’ll hopefully soon be repairing walls, floors, electrics and the like.
This way up. For now.
Unfortunately it proved just too difficult to disassemble the beast. I’d anticipated that it would be able to be easily separated into two major pieces – the “top”, and the “frame” –
but the guy who built in for me1
made some creative decisions about the placements of the controllers and the motors which has meant that the two now can’t be separated without taking the whole thing
apart into a lot of tiny bits.
I’ll speak to the builders when they come. Maybe a floor can be laid elsewhere in the house and then the desk, which I’ve collapsed as small as its little motors will
carry it, can be moved onto the newly-constructed floor so that it’s out of the way here.
Wowsa, these are some tiny connectors!
So I got started on my other hardware task of the day: attempting to repair Ruth‘s laptop. It’s reporting via LED codes a graphics fault and
its screen isn’t coming on, and the most-likely cause it an un-seated signal cable. So I picked up some teeny-tiny screwdrivers (my usual ones all being packed in boxes) and had a go.
But no dice; I’ve reseated the cables and it’s still sad, so I’m guessing it’s an actual issue with the screen. Sigh.
Two for two on hardware failures today. I should go back to writing some software. Fortunately; there’s lots of that that needs my attention too, this weekend!
Footnotes
1 Who – I suspected at the time and of which I’m now even more-confident – might well have
been high when he assembled it. There’s some wacky choices here, plus he’s drilled several holes on the underside that he then didn’t actually use!
Working with an old codebase today, I moved a method from one file to another. CI was happy.
Then I realised the method didn’t have any automated tests, so I wrote one. It turns out its entire (new) file didn’t have any, so my change would improve test coverage. Nice.
But it didn’t. CI complained that test coverage had dropped. Wait, what? All I did was move some code and add a unit test.
Then I realised that the coverage analysis tool was only counting files that actually contained any tested code. By adding a test to part of a previously-untested file, that file became
part of the scored codebase. Uh-oh.
Looked deeper. Turns out the code coverage tool was also counting the test files themselves as being part of the code-under-test.
Fixed all of the above. Code coverage score dropped by about 40%. 😱
Now I’ve got more work to do.
Happy Friday. Check what your coverage tool is inspecting, folks.
Hackers say that they used Meta’s AI support chatbot to break into a host of high-profile Instagram profiles by asking the support bot to change the email address associated with
the target account. The claims coincide with a series of high-profile Instagram account takeovers, including the Barack Obama White House account, the Chief Master Sergeant of Space Force’s account,
and Sephora’s account.
…
Well this is unsurprising and unshocking. Turns out that if you give your chatbot help interface unrestricted access to your backend systems – rather than, say, the access level of the
human talking to it – then obviously hackers are going to try to jailbreak it in ways that you can’t possibly predict or guardrails against and, if/when they succeed,
they’ll break into all the systems to which you’ve given the system access.
This shouldn’t even have to be said. Meta’s mistake here is so self-evident that they should be embarrassed.
Note to self: ignore search results that say to install a plugin; the absolute fastest way to send a test email from a WordPress/ClassicPress installation (assuming
you’re using WP-CLI) is just to run something like:
wp eval 'wp_mail("recipient@example.com", "Test Email", "A test email from WP-CLI");'
👋 Hi! If you came here after going to ChangeNames.co.uk, congratulations: you just dodged getting scammed.
To actually change your name for free as a British citizen, without giving your personal information to scammers (or anybody else who doesn’t need it!), I suggest you use
FreeDeedPoll.org.uk. Want an alternative? DeedPoll.lgbt is good too!
I help people change their names
As a British citizen, you can change your name for free. That’s the entire premise behind my website FreeDeedPoll.org.uk, which since 2011 has
helped thousands of people change their names1
for free and without a solicitor.
It’s a pretty useful website, if I say so myself.
I aim to run the most-ethical service of its type:
As noted, it’s completely free and collects no personal information whatsoever.
It’s funded out of my own pocket so it doesn’t need to depend upon advertising.
It’s open source so anybody can inspect my code, or run it themselves, or even set up a “competing” copy (so long as they give away
the code to that, too)!
I try to answer every email I receive from anybody who’s having difficulty with the process.2
Scammers will barely help you, but they will steal your data
Others, however, don’t.
I’m not talking about all the paid-for services. Some of them provide a useful service, albeit one that you don’t strictly need to pay for. I’m not a fan of
those that try to market themselves as “official”, though, because that just feels like fraud. No, I’m talking about a level of sliminess that goes well beyond merely charging
somebody for something they’re entitled to for free.
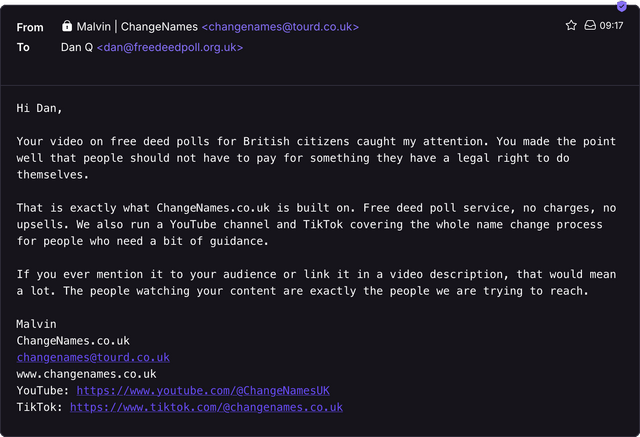
Like… let me show you an email I received today:
My bullshit alarm was going off as soon as I saw this email, but I figured I’d dig a little deeper before I decided whether or not to consign it to the spam folder.
I tried to visit their website but it looks like they haven’t even bought the domain name they’re advertising, yet. Just for fun, I’ve registered it and set it up as a permanent
redirect to this blog post3.
Their TikTok channel exists, but it’s not at the URL they provided. So far, so incompetent.
Gotta admit, their video production quality’s better than mine… even if the content isn’t!
Both their YouTube and TikTok channels provide a link not to their “website” but to a kit.com page that asks for some personal details with the promise of a deed poll at the end of it.
When you fill in the form – and obviously you shouldn’t do so using real information – you get added to a marketing email list and a handful of other mailing lists get
pushed at you.
“Why are you changing your name” is a mandatory free-text field. Why are they asking this? Who knows!
Kit.com require double-opt-in confirmation for mailing lists, but the email tries to trick you into clicking the button, saying that clicking the “confirm your subscription” button
“help us know you have received the deed poll and everything works”. In reality, they’re just trying to legitimise their spamming.
And what do you get out of it after all this? A hyperlink to a publicly-accessible Google Drive
folder called “Deed Polls”[sic]4 that a more-ethical outlet could have just linked to in the first
place. it contains a couple of Word documents that require you to delete a ton of underscores in order to type your own content in.
Oh, the the templates are full of mistakes. Here’s one (there are others!):
This clause contains both a grammatical error (saying ‘only’ twice) but a legal one! For most people, a deed poll is used to change their name for all purposes, not
merely specifically-and-exclusively for professional purposes.
Of all the scammy free deeds poll services I’ve seen, ChangeNames is the worst
What we’ve got here is…
a marketing scam pretending to be a deeds poll service,
being run ineptly, e.g. marketing using a domain name they haven’t yet purchased and providing broken links to their own social media,
that are using unethical techniques to harvest personal information,
in exchange for a deed poll template that’s riddled with errors. 🤦
But the really insane thing about this whole scam is that a human being found my video about my own (superior, ethical) service FreeDeedPoll.org.uk… and then figured that they’d email me to see if I’d like to pass some traffic to their (inferior, unethical) competitor.
That bit… that’s the bit that blows my mind.
Footnotes
1 I can’t tell you exactly how many because I make a deliberate effort to collect no
personal information, without which I’m unable to pin down a specific number. But I’ve had many hundreds of emails from people who’ve changed their names, and have anonymous
statistics to suggest that the number is almost-certainly in the tens of thousands, maybe in the low hundreds of thousands.
2 I’m not a lawyer, but I’ve become pretty familiar with lots of relevant parts of the
laws about not just names but adjacent areas like citizenship, residency, gender identity, information protection, and parental rights, and I’ve been able to point many people towards
satisfactory conclusions when they’ve had more-challenging name changes.
3 It might not be working yet, depending on the state of DNS propagation, but it’ll get
there in a day or so I reckon.
4 The plural of deed poll is, of course, deeds poll, but one could hardly expect
these clowns to know that.
My actual implementation was Go, rather than JavaScript2, as part of a side project
this weekend. Here’s the function I came up with.
Today was also the day that I discovered that while SU is a reserved 2-letter ISO 3166-1 designation for the Soviet Union, the flag of the USSR is not a
registered emoji. But if it were, we can work out what codepoint it’d be at! So I can type this – 🇸🇺 – here, safe in the knowledge that if that emoji comes to exist in the
future, then you’ll be able to revisit this blog post and see it!
You know what: there might be a game in these country codes and their flags somewhere. Like: a game where you have to get from one country to another: like, say, from the 🇨🇰 Cook
Islands (CK) to 🇧🇯 Benin (BJ). But you’re only allowed to change one letter at a time and you have to land in a real country. I think the fastest route between those two takes three
steps, e.g. 🇨🇰 Cook Islands (CK) to 🇹🇰 Tokelau (TK) to 🇹🇯 Tajikstan (TJ) to 🇧🇯 Benin (BJ)… It’s probably a bit easy though: I haven’t yet found any that require more than three moves
and most can be done in just two.
It gets a lot harder if you require letters to only be changed to an adjacent letter, but this variant makes some permutations impossible. Maybe there’s an optimisation puzzle in the
style of the Travelling Salesman problem? Or maybe by mixing in geographical restrictions such as an inability to visit a certain continent that would make it more challenging
and fun? Just brainstorming here…
Footnotes
1 An alternative way of thinking about it is that you’re taking the number of the letter
in the alphabet – e.g F=6, R=18 – and adding 64 to each. Here’s why, and why it’s beautiful.
2 I don’t get to write Go often, and I seem to get rusty at it quickly, but I enjoy the
feeling of writing something so raw and yet so clean.
There are many things I don’t like about the kitchen in the Chicory House where we’re living medium-term following our house flood.
But I like the fact that the integrated spice rack makes it much easier to see where we perhaps have a very-specific blind spot for “buying a new one where the last one’s still more
than half-full”.
But don’t think I’ve stopped hitting Random Article! Today I was reading about surface plasmon resonance,
and, despite looking at it on and off all day… I still don’t think I “get” it. I’ve even dived into the linked articles to try to get a background understanding of the topics around it,
but… nope. It’s still all gibberish to me!
Because I have access to wp-config.php, I added the following to my file:
define( 'WP_AI_SUPPORT', false );
…
A useful tip.
Personally, I’ve got what feels like an even-better approach (for me, at least) I switched to ClassicPress a year and a bit ago, and haven’t
looked back! It’s a stripped-down fork of WordPress with no Gutenberg, lighter JavaScript, and a handful of other features… plusClassicPress is already AI-free and staying that way.
This isn’t to say that you can’t use AI with ClassicPress. Just that you’re not having to install the feature if you’re never going to use it. With WordPress’s good plugin architecture
it seems strange to me that such divisive features would become part of the core product, but that just seems to be the direction that the project’s been going in for a while now.
Three Rings CIC is, and always has been, a fully-remote organisation. We were doing remote working almost two decades before the Pandemic
made it cool (and well before tools like Slack and Zoom were a thing: we cut our remote-first teeth using IRC as our collaboration
tool!), but, there are still sometimes occasions when it’s good to have as many people as possible physically in a room.
When, last year, the Nightline Association announced it was closing down, it put one of their key services, Nightline Portal, which helps
Nightlines to take and handle calls these days, in serious risk: someone had to host and maintain it, and that had always been the Association. At the point the announcement was
made, in February, the Portal team had about four months to find it a new home.
It took me some degree of back-and-forth with the Nightline Association on one side, and it required some careful governance and planning at our end (as well as a few shifts in
short-term priorities!), but – helped by the fact we all wanted the best possible outcome for Nightlines – we got an agreement in place, a budget plan agreed, and were able to ensure Portal would keep going, for free faster than I think anyone had
expected.
That mattered to Nightlines, because to them, it’s critical infrastructure. And it mattered to us, because Nightlines were where Three Rings began, back in 2002. Today, we
support everything from major national charities to tiny community shops, but Nightlines remain close to our heart. Almost all our team – across a wide range of “x decades ago”! –
started as Nightline volunteers; we’ve nearly all spent the night awake, quietly waiting out the small hours, in case one of our fellow students needs someone to talk to in a crisis
and offering a listening ear when they called. We weren’t going to let that community lose something it relied on.
But adopting Portal meant a lot of work, against the clock. Data validation, new agreements, rebudgeting, and, once that was all done, a full migration to shift Portal from the
Nightline Association’s server infrastructure to ours. So to get that done, we organised an in-person meetup, “Portal Camp,” in a reasonably central hotel. Volunteers gave up their
weekend, left their homes on Friday evening for two more days of work, and we brought everyone together. We spent Saturday morning planning, carrying out test migrations, preparing
comms, and agreed yes – we can go.
…
About a year ago I helped look after the technical side of the “lifeboating” of Portal into Three Rings, right through the point that everything went wrong and my developers almost missed dinner (and, indeed, had to eat at their laptops!). I mentioned at the time my awe and pride of
them, but JTA’s post goes deeper and further and hints at the (much bigger) structural and procedural changes that were needed to adopt Portal.
A great thing about volunteering with Three Rings is that we get to ask, on any given day “how can we do the most good?” Not “will this give value to shareholders?” Not “what’s the
marketing strategy for this?” Not “can this deliver return on investment?” Those are questions for a very different kind of organisation to us. We get to ask, each and every day, “how
can we do the most good?”
That question is why, for me, adopting Portal into the Three Rings family, last year, was a no-brainer. Dozens of voluntary organisations depended upon it, and we had the skills and
volunteers and technical infrastructure to stop it from dying.
Anyway: JTA’s post on LinkedIn is better, and more-interesting, and
somehow also funnier than mine, so go read that. And if you want to talk volunteering with me, I’d love to chat!
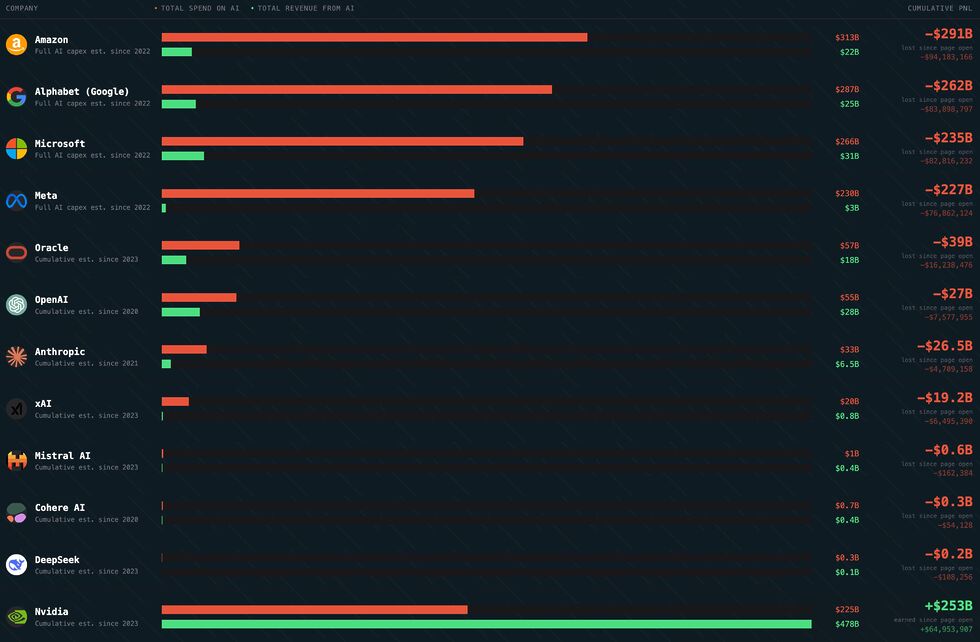
No surprises here, but it’s interesting/staggering to see quite how large the disparity between spending and profit is for some of these companies.
I enjoy the fact that there’s a real-time ticker on the site so you can watch Amazon (for example) burn five thousand dollars a second.
When I tell people that generative AI, as it’s currently used, is unsustainable, this is what I’m talking about. Unless there’s a quantum leap in AI efficiency (for which I’ve seen no
evidence of the feasibility) or a dramatic increase in the charged cost of LLM services (on the order of a tenfold increase assuming the increased cost does not drive any customers
away; more if it does), this whole thing looks like a house of cards.
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
Just sometimes when you’re playing the “hey, Wikipedia, give me a random page” game, you get a hole in one. That’s what happened today when I landed on the article for… Carl Person.
Whatever else you can say about him, he looks pretty dapper in a suit. Photo courtesy Carl Person, used under a Creative Commons license. Knowing that he has a Wikipedia
account (which he used to upload this photo), I took the time to browse the article history and check for any obvious signs of tampering, sockpuppetry, or other foul play, but it
looks reasonably clean.
Yes, Person is his actual surname. Speaking as a person with a stupid name, it pleases me to find people whose names probably cause them at least as much
trouble as mine does. Wikipedia wasn’t any help at understanding where the surname Person comes from (and Carl himself isn’t
even noteworthy enough to appear on the list of “notable people with that surname”, it seems).
However I did enjoy discovering jazz saxophonist Houston Person (which sounds like the beginning of a news headline about
somebody from Houston!) who once released an album called… Person to Person! Excellent. Also, actress and
filmmaker Marina Person whose documentary about her father, filmmaker Luis Sérgio Person, was titled simply Person. I think the name might be related to Swedish
surname Persson – literally, “son of Per” – where Per is a Scandinavian
variant of Peter. This probably means that there’s a “Per Person” somewhere in the world, and I want to meet him.
Anyway: back to Carl. He trained as a lawyer and spent the 1960s working in a variety of corporate law firms. These included the one for which Richard Nixon was a partner, during that period after Nixon failed to get elected as Governor of California and announced that he was
retiring from politics… only to come back six years later to be elected president and, well, you know the rest.
Paralegals! All of the work; a fraction of the pay!
Anyway: other things he did as part of his legal career were –
Represented other members of The Teenagers (then The Premiers, because confusingly the band changed their name to “The
Teenagers” when they got older) in their efforts to reclaim shared copyright of their 1956 hit Why
Do Fools Fall in Love from lead singer Frankie Lymon and Gee Records.
Represented playwright Mark Dunn in his successful claim that The Truman Show was based upon his 1992 play, Frank’s Life, whose script he’d previously attempted to sell to
Paramount.
Helped Ralph Anspach (whose book I read before writing this 2013 blog post!) in his
appeal against a ruling that Anspach’s board game Anti-Monopoly was derivative of Parker Brothers‘ stake
in Monopoly: the appeal was successful at least in part because Person and Anspach were able to prove that Monopoly was, itself, derived from Lizzie Magie‘s The Landlord’s Game. (Fun fact: this was
the second time Carl successfully took on Parker Brothers; the first being the Masterpiece case,
representing Christian Thee!)
I let the elder kid choose her lunch. She chose a pizza so huge that each slice is larger than her entire face. Needless to say, she needed a little help with it!


![Screengrab from a YouTube video showing a white woman with brown-and-red hair saying "please see the FAQs for any questions you have have around deed polls[sic] and the rules." alongside a logo for "Change Names".](https://bcdn.danq.me/_q23u/2026/06/changenames-youtube-video-640x360.png)