An amazing CSS effect by Ana Tudor:
Wow, this is real pretty!
(You can edit that text. Really: try it!)
I’ve only recently (thanks, Spencer!) gained any level of understanding about the use of SVG filters in CSS, so this is doubly-impressive to me.
An amazing CSS effect by Ana Tudor:
Wow, this is real pretty!
(You can edit that text. Really: try it!)
I’ve only recently (thanks, Spencer!) gained any level of understanding about the use of SVG filters in CSS, so this is doubly-impressive to me.
At work, we recently switched expenses system to one with virtual credit card functionality. I decided to test it out by buying myself lounge access for my upcoming work trip to Mexico. Unfortunately the new system mis-detected my lounge access as being a purchase from lingerie company loungeunderwear.com. I’m expecting a ping from Finance any moment to ask me why I’m using a company credit card to buy a bra.
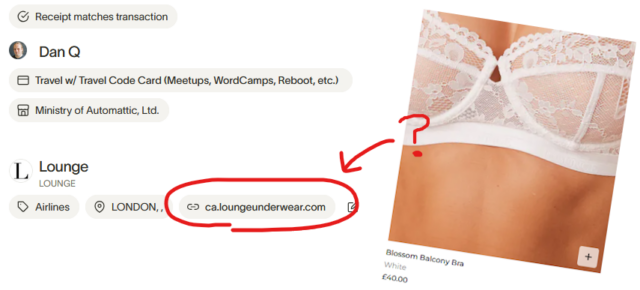
One might ask why our expenses provider can (mis-)identify loungeunderwear.com from a transaction in the first place. Did somebody at some company that uses this provider actually buy some ladies’ briefs on a company credit card at some point?
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Cast your mind back to 15½ years ago, when the Internet was delighted by The Duck Song, a stupid adaptation of an already-ancient joke, presented as a song for a child and accompanied by some MS Paint-grade animation. It was catchy, though, and before long everybody had it stuck in their heads.
Over the subsequent year it was followed by The Duck Song 2 and The Duck Song 3, each in a similar vein but with a different accompanying joke. There’s sort-of an ongoing narrative – a story arc – than spans the three, as the foils of the first and second are introduced to one another in the third in a strange duck-related meet-cute.
And then there was nothing for… well, almost 14 years. The creators went on to do other things, and we all assumed that this series was completed (unlike for example the Wave Hello trilogy I mentioned the other day, which is clearly supposed to get one more part, and is overdue!). That’s fine, of course. Things are allowed to finish, contrary to what many American TV execs seem to think.
Then last year, we got a seasonal treat in the form of The Christmas Duck Song. It felt like a non-canonical spinoff, though, not a true “fourth Duck Song”. Like the Star Wars Holiday Special. Except good. It’s appearance wasn’t taken as heralding a return of duck songs.
But perhaps it should’ve, because earlier this year we got The Duck Song 4! Yet again, it retells a stupid joke – in this case, an especially silly and immature one – but man, it feels like an old friend coming home. Welcome back, Duck Song.
I don’t think I’ve done justice to it, though. Perhaps the
Permit yourself to be entranced by the magnificence of the animation, the piquancy of the wordplay, the splendorous yet seductive simplicity of the G-C-D chord progression. Let the duck, like Virgil in Dante’s “Divine Comedy,” be your guide — lean into the quotidian but sempiternal question of whether the man at the lemonade stand has any grapes. Consider the irritation of the man at the stand and ask yourself if the wrath of Achilles is really that much more disastrous. Admire the cunning of the duck’s questioning — was Socrates so very different?
Yeah, that’s about right.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
We made it! This young furbaby managed to pose a bleppy picture every single day of Bleptember. Thanks for coming along for the ride!

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
“You want more Bleptember pictures? I demand payment in the form of tummy-scritches!”
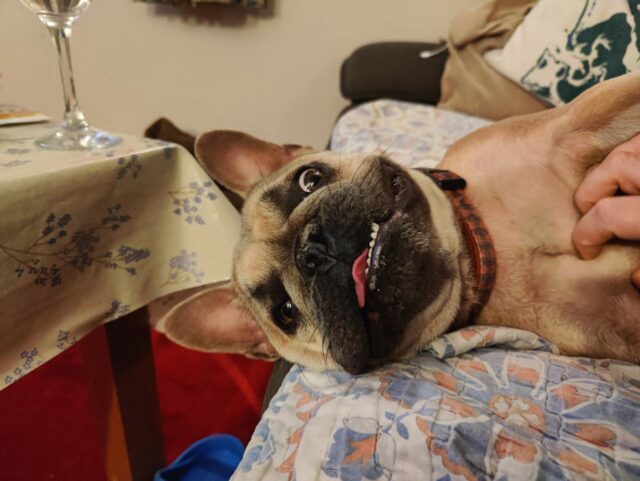
(Wow, it’s the penultimate day of Bleptember. )
The eldest is really getting into her WW2 studies at school, so I arranged a trip for her and a trip to the ever-excellent Bletchley Park for a glimpse at the code war that went on behind the scenes. They’re clearly looking forward to the opportunity to look like complete swots on Monday.

Bonus: I got to teach them some stories about some of my favourite cryptanalysts. (Max props to the undersung Mavis Batey!)
This checkin to GC9GTV3 Drive Slowly; Fox Crossing reflects a geocaching.com log entry. See more of Dan's cache logs.
Noticed while on a dog walk that the container looked a little loose, so came by to tighten it up. Noticed that the logbook was missing – muggled? – so replaced that while I was here. Ready to go!

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Tttttthbbptt. The sound of a bleppy dog deflating like a balloon, this Twenty-Eighth of Bleptember

Back when I was a student in Aberystwyth, I used to receive a lot of bilingual emails from the University and its departments1. I was reminded of this when I received an email this week from CACert, delivered in both English and German.
Wouldn’t it be great if there were some kind of standard for multilingual emails? Your email client or device would maintain an “order of preference” of the languages that you speak, and you’d automatically be shown the content in those languages, starting with the one you’re most-fluent in and working down.
The Web’s already got this functionality2, and people have been sending multilingual emails for much longer than they’ve been developing multilingual websites3!
It turns out that this is a (theoretically) solved problem. RFC8255 defines a mechanism for breaking an email into multiple different languages in a way that a machine can understand and that ought to be backwards-compatible (so people whose email software doesn’t support it yet can still “get by”). Here’s how it works:
Content-Type: multipart/multilingual header with a defined boundary marker, just like you would for any other email with multiple “parts” (e.g. with a HTML
and a plain text version, or with text content and an attachment).
text/plain (or similar) part, containing e.g. some text to explain that this is a multilingual email, and if you’re seeing this
then your email client probably doesn’t support them, but you should just be able to scroll down (or else look at the attachments) to find content in the language you read.
Content-Disposition: inline, so that for most people using non-compliant email software they can just scroll down until they find a language they can read,
Content-Type: message/rfc822, so that an entire message can be embedded (which allows other headers, like the Subject:, to be translated too),
Content-Language: header, specifying the ISO code of the language represented in that section, and
Content-Translation-Type: header, specifying either original (this is the original text), human (this was translated by a
human), or automated (this was the result of machine translation) – this could be used to let a user say e.g. that they’d prefer a human translation to an automated
one, given the choice between two second languages.
Let’s see a sample email:
Content-Type: multipart/multilingual; boundary=10867f6c7dbe49b2cfc5bf880d888ce1c1f898730130e7968995bea413a65664 To: <b24571@danq.me> From: <rfc8255test-noreply@danq.link> Subject: Does your email client support RFC8255? Mime-Version: 1.0 Date: Fri, 27 Sep 2024 10:06:56 +0000 --10867f6c7dbe49b2cfc5bf880d888ce1c1f898730130e7968995bea413a65664 Content-Transfer-Encoding: quoted-printable Content-Type: text/plain; charset=utf-8 This is a multipart message in multiple languages. Each part says the same thing but in a different language. If your email client supports RFC8255, you will see this message in your preferred language out of those available. Otherwise, you will probably see each language after one another or else each language in a separate attachment. --10867f6c7dbe49b2cfc5bf880d888ce1c1f898730130e7968995bea413a65664 Content-Disposition: inline Content-Type: message/rfc822 Content-Language: en Content-Translation-Type: original Subject: Does your email client support RFC8255? Content-Type: text/plain; charset="UTF-8" Content-Transfer-Encoding: 7bit MIME-Version: 1.0 RFC8255 is a standard for sending email in multiple languages. This is the original email in English. It is embedded alongside the same content in a number of other languages. --10867f6c7dbe49b2cfc5bf880d888ce1c1f898730130e7968995bea413a65664 Content-Disposition: inline Content-Type: message/rfc822 Content-Language: fr Content-Translation-Type: automated Subject: Votre client de messagerie prend-il en charge la norme RFC8255? Content-Type: text/plain; charset="UTF-8" Content-Transfer-Encoding: 7bit MIME-Version: 1.0 RFC8255 est une norme permettant d'envoyer des courriers électroniques dans plusieurs langues. Le présent est le courriel traduit en français. Il est intégré à côté du même contenu contenu dans un certain nombre d'autres langues. --10867f6c7dbe49b2cfc5bf880d888ce1c1f898730130e7968995bea413a65664--
That proposed standard turns seven years old next month. Sooo… can we start using it?4
Turns out… not so much. I discovered that NeoMutt supports it:
Support in other clients is… variable.
A reasonable number of them don’t understand the multilingual directives but still show the email in a way that doesn’t suck:
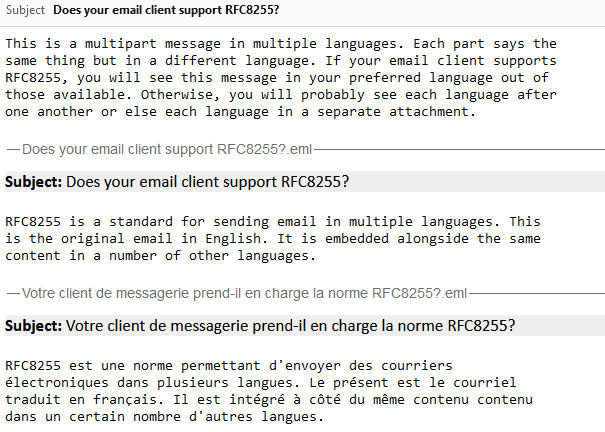
Some shoot for the stars but blow up on the launch pad:
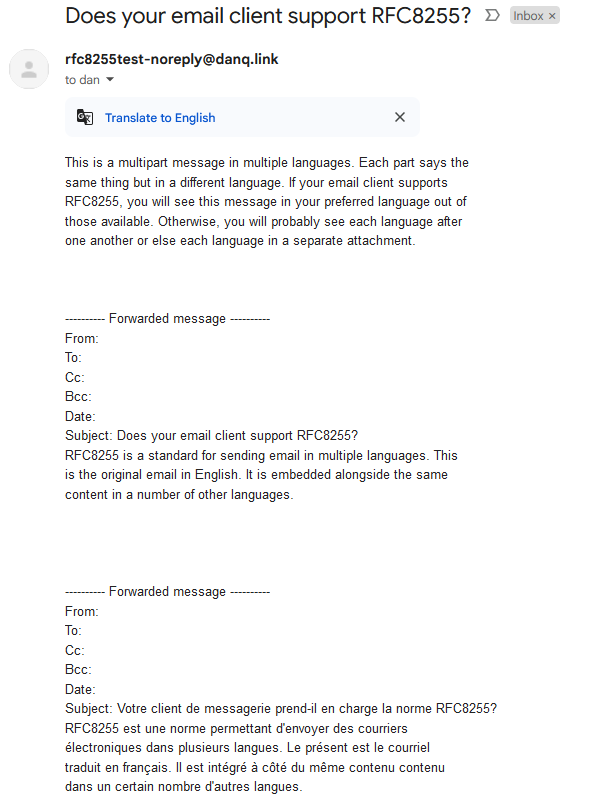
Others still seem to be actively trying to make life harder for you:
.eml attachments… which is then won’t display, forcing you to download them and
find some other email client to look at them in!5
And still others just shit the bed at the idea that you might read an email like this one:
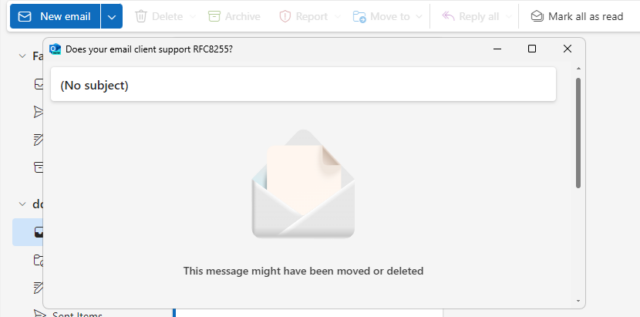
That’s just the clients I’ve tested, but I can’t imagine that others are much different. If you give it a go yourself with something I’ve not tried, then let me know!
I guess this means that standardised multilingual emails might be forever resigned to the “nice to have but it never took off so we went in a different direction” corner of the
Internet, along with the <keygen> HTML element and the concept of privacy.
1 I didn’t receive quite as much bilingual email as you might expect, given that the University committed to delivering most of its correspondence in both English and Welsh. But I received a lot more than I do nowadays, for example
2 Although you might not guess it, given how many websites completely ignore your
Accept-Language header, even where it’s provided, and simply try to “guess” what language you want using IP geolocation or something, and then require that you find
whatever shitty bit of UI they’ve hidden their language selector behind if you want to change it, storing the result in a cookie so it inevitably gets lost and has to be set again the
next time you visit.
3 I suppose that if you were sending HTML emails then you might use the lang="..." attribute to mark up different parts of the message as being in different
languages. But that doesn’t solve all of the problems, and introduces a couple of fresh ones.
4 If it were a cool new CSS feature, you can guarantee that it’d be supported by every major browser (except probably Safari) by now. But email doesn’t get so much love as the Web, sadly.
5 Worse yet, if you’re using ProtonMail with a third-party client, ProtonMail screws up
RFC8255 emails so badly that they don’t even work properly in e.g. NeoMutt any more! ProtonMail swaps the multipart/multilingual content type for
multipart/mixed and strips the Content-Language: headers, making the entire email objectively less-useful.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
The people who make the most money in WordPress are not the people who contribute the most (Matt / Automattic really is one of the exceptions here, as I think we are). And this is a problem. It’s a moral problem. It’s just not equitable.
I agree with Matt about his opinion that a big hosting company such as WPEngine should contribute more. It is the right thing to do. It’s fair. It will make the WordPress community more egalitarian. Otherwise, it will lead to resentment. I’ve experienced that too.
…
In my opinion, we all should get a say in how we spend those contributions [from companies to WordPress]. I understand that core contributors are very important, but so are the organizers of our (flagship) events, the leadership of hosting companies, etc. We need to find a way to have a group of people who represent the community and the contributing corporations.
Just like in a democracy. Because, after all, isn’t WordPress all about democratizing?
Now I don’t mean to say that Matt should no longer be project leader. I just think that we should more transparently discuss with a “board” of some sorts, about the roadmap and the future of WordPress as many people and companies depend on it. I think this could actually help Matt, as I do understand that it’s very lonely at the top.
With such a group, we could also discuss how to better highlight companies that are contributing and how to encourage others to do so.
…
Some wise words from Joost de Valk, and it’s worth reading his full post if you’re following the WP Engine drama but would rather be focussing on looking long-term towards a better future for the entire ecosystem.
I don’t know whether Joost’s solution is optimal, but it’s certainly worth considering his ideas if we’re to come up with a new shape for WordPress. It’s good to see that people are thinking about the bigger picture here, than just wherever we find ourselves at the resolution of this disagreement between Matt/Automattic/the WordPress Foundation and WP Engine.
Thinking bigger is admirable. Thinking bigger is optimistic. Thinking bigger is future-facing.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
This Bleptember pic looks a bit like a political poster to me. Vote Dog, for a future with More Ham, Fewer Vacuum Cleaners!

The YouTube channel @simonscouse has posted exactly two videos.
The first came a little over ten years ago. It shows a hand waving and then wiggling its fingers in front of a patterned wallpaper:
The second came a little over five years ago, and shows a hand – the same hand? – waving in front of a painting of two cats while a child’s voice can be heard in the background:
In a comment on the latter, the producer promised that it’s be “only another 5 years until the trilogy is completed”.
Where’s the third instalment, Simon? We’re all waiting to see it!
This post is also available as a podcast. Listen here, download for later, or subscribe wherever you consume podcasts.
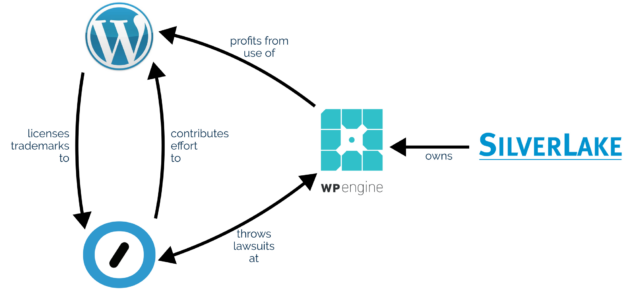
If you’re active in the WordPress space you’re probably aware that there’s a lot of drama going on right now between (a) WordPress hosting company WP Engine, (b) WordPress hosting company (among quite a few other things) Automattic1, and (c) the WordPress Foundation.
If you’re not aware then, well: do a search across the tech news media to see the latest: any summary I could give you would be out-of-date by the time you read it anyway!
Like others, I’m not sure that the way Matt publicly called-out WP Engine at WCUS was the most-productive way to progress a discussion2.
In particular, I think a lot of the conversation that he kicked off conflates three different aspects of WP Engine’s misbehaviour. That muddies the waters when it comes to having a reasoned conversation about the issue3.

I don’t think WP Engine is a particularly good company, and I personally wouldn’t use them for WordPress hosting. That’s not a new opinion for me: I wouldn’t have used them last year or the year before, or the year before that either. And I broadly agree with what I think Matt tried to say, although not necessarily with the way he said it or the platform he chose to say it upon.
As I see it, WP Engine’s potential misdeeds fall into three distinct categories: moral, ethical4, and legal.
Matt observes that since WP Engine’s acquisition by huge tech-company-investor Silver Lake, WP Engine have made enormous profits from selling WordPress hosting as a service (and nothing else) while making minimal to no contributions back to the open source platform that they depend upon.
If true, and it appears to be, this would violate the principle of reciprocity. If you benefit from somebody else’s effort (and you’re able to) you’re morally-obliged to at least offer to give back in a manner commensurate to your relative level of resources.

Abuse of this principle is… sadly not-uncommon in business. Or in tech. Or in the world in general. A lightweight example might be the many millions of profitable companies that host atop the Apache HTTP Server without donating a penny to the Apache Foundation. A heavier (and legally-backed) example might be Trump Social’s implementation being based on a modified version of Mastodon’s code: Mastodon’s license requires that their changes are shared publicly… but they don’t do until they’re sent threatening letters reminding them of their obligations.
I feel like it’s fair game to call out companies that act amorally, and encourage people to boycott them, so long as you do so without “punching down”.
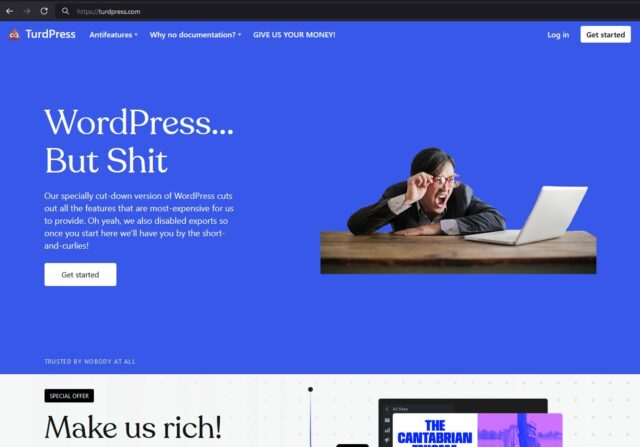
WP Engine also stand accused of altering the open source code that they host in ways that maximise their profit, to the detriment of both their customers and the original authors of that code5.
It’s well established, for example, that WP Engine disable the “revisions” feature of WordPress6. Personally, I don’t feel like this is as big a deal as Matt makes out that it is (I certainly wouldn’t go as far as saying “WP Engine is not WordPress”): it’s pretty commonplace for large hosting companies to tweak the open source software that they host to better fit their architecture and business model.
But I agree that it does make WordPress as-provided by WP Engine significantly less good than would be expected from virtually any other host (most of which, by the way, provide much better value-for-money at any price point).
Again, I think this is fair game to call out, even if it’s not something that anybody has a right to enforce legally. On which note…
Automattic Inc. has a recognised trademark on WooCommerce, and is the custodian of the WordPress Foundation’s trademark on WordPress. WP Engine are accused of unauthorised use of these trademarks.
Obviously, this is the part of the story you’re going to see the most news media about, because there’s reasonable odds it’ll end up in front of a judge at some point. There’s a good chance that such a case might revolve around WP Engine’s willingness (and encouragement?) to allow their business to be called “WordPress Engine” and to capitalise on any confusion that causes.
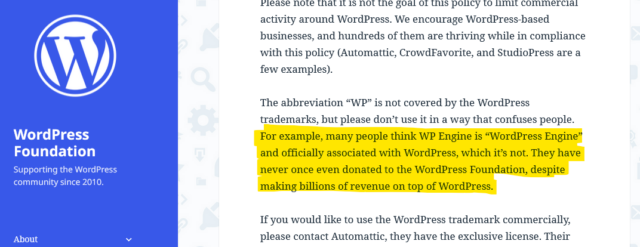
I’m not going to weigh in on the specifics of the legal case: I Am Not A Lawyer and all that. Naturally I agree with the underlying principle that one should not be allowed to profit off another’s intellectual property, but I’ll leave discussion on whether or not that’s what WP Engine are doing as a conversation for folks with more legal-smarts than I. I’ve certainly known people be confused by WP Engine’s name and branding, though, and think that they must be some kind of “officially-licensed” WordPress host: it happens.
If you’re following all of this drama as it unfolds… just remember to check your sources. There’s a lot of FUD floating around on the Internet right now9.
With a reminder that I’m sharing my own opinion here and not that of my employer, here’s my thoughts on the recent WP Engine drama:
1 I suppose I ought to point out that Automattic is my employer, in case you didn’t know, and point out that my opinions don’t necessarily represent theirs, etc. I’ve been involved with WordPress as an open source project for about four times as long as I’ve had any connection to Automattic, though, and don’t always agree with them, so I’d hope that it’s a given that I’m speaking my own mind!
2 Though like Manu, I don’t think that means that Matt should take the corresponding blog post down: I’m a digital preservationist, as might be evidenced by the unrepresentative-of-me and frankly embarrassing things in the 25-year archives of this blog!
3 Fortunately the documents that the lawyers for both sides have been writing are much clearer and more-specific, but that’s what you pay lawyers for, right?
4 There’s a huge amount of debate about the difference between morality and ethics, but I’m using the definition that means that morality is based on what a social animal might be expected to decide for themselves is right, think e.g. the Golden Rule etc., whereas ethics is the code of conduct expected within a particular community. Take stealing, for example, which covers the spectrum: that you shouldn’t deprive somebody else of something they need, is a moral issue; that we as a society deem such behaviour worthy of exclusion is an ethical one; meanwhile the action of incarcerating burglars is part of our legal framework.
5 Not that nobody’s immune to making ethical mistakes. Not me, not you, not anybody else. I remember when, back in 2005, Matt fucked up by injecting ads into WordPress (which at that point didn’t have a reliable source of funding). But he did the right thing by backpedalling, undoing the harm, and apologising publicly and profusely.
6 WP Engine claim that they disable revisions for performance reasons, but that’s clearly bullshit: it’s pretty obvious to me that this is about making hosting cheaper. Enabling revisions doesn’t have a performance impact on a properly-configured multisite hosting system, and I know this from personal experience of running such things. But it does have a significant impact on how much space you need to allocate to your users, which has cost implications at scale.
7 As an aside: if a court does rule that WP Engine is infringing upon WordPress trademarks and they want a new company name to give their service a fresh start, they’re welcome to TurdPress.
8 I’d argue that it is okay to do so for personal-use though: the difference for me comes when you’re making a profit off of it. It’s interesting to find these edge-cases in my own thinking!
9 A typical Reddit thread is about 25% lies-and-bullshit; but you can double that for a typical thread talking about this topic!
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
A round of especially-crazy zoomies on the morning of this Twenty-Sixth of Bleptember was apparently too much for this little pupper, who’s now looking like she’s in need of a morning nap.

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Happy Twenty-Fifth of Bleptember from our adorkable doggle.
