For the last few years, my go-to mobile game1 has been FlipFlop Solitaire.
The game

The premise is simple enough:
- 5-column solitaire game with 1-5 suits.
- 23 cards dealt out into those columns; only the topmost ones face-up.
- 2 “reserve” cards retained at the bottom.
- Stacks can be formed atop any suit based on value-adjacency (in either order, even mixing the ordering within a stack)
- Individual cards can always be moved, but stacks can only be moved if they share a value-adjacency chain and are all the same suit.
- Aim is to get each suit stacked in order at the top.

One of the things that stands out to me is that the game comes with over five thousand pre-shuffled decks to play, all of which guarantee that they are “winnable”.
Playing through these is very satisfying because it means that if you get stuck, you know that it’s because of a choice that you made2, and not (just) because you get unlucky with the deal.
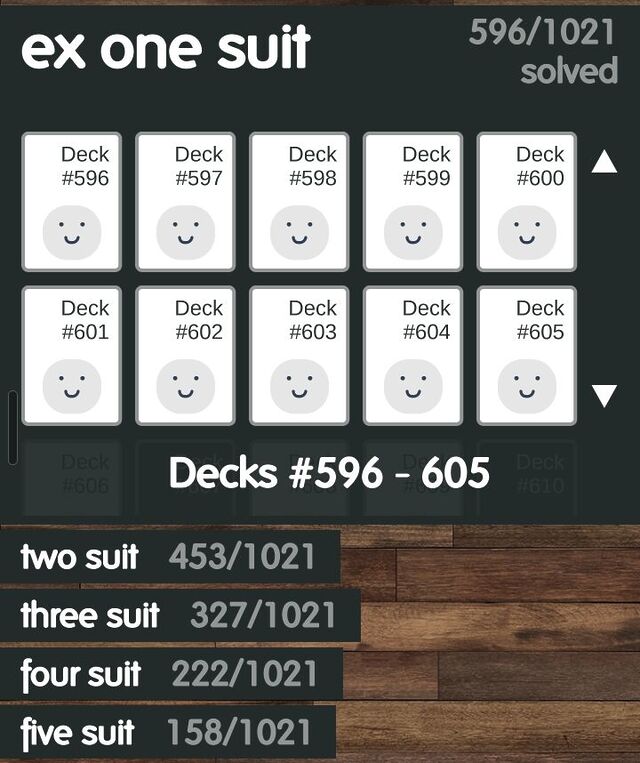
Every deck is “winnable”?
When I first heard that every one of FlipFlop‘s pregenerated decks were winnable, I misinterpreted it as claiming that every conceivable shuffle for a game of FlipFlop was winnable. But that’s clearly not the case, and it doesn’t take significant effort to come up with a deal that’s clearly not-winnable. It only takes a single example to disprove a statement!

That it’s possible for a fairly-shuffled deck of cards to lead to an “unwinnable” game of FlipFlop Solitaire means the author must have necessarily had some mechanism to differentiate between “winnable” (which are probably the majority) and “unwinnable” ones. And therein lies an interesting problem.
If the only way to conclusively prove that a particular deal is “winnable” is to win it, then the developer must have had an algorithm that they were using to test that a given deal was “winnable”: that is – a brute-force solver.
So I had a go at making one3. The code is pretty hacky (don’t judge me) and, well… it takes a long, long time.
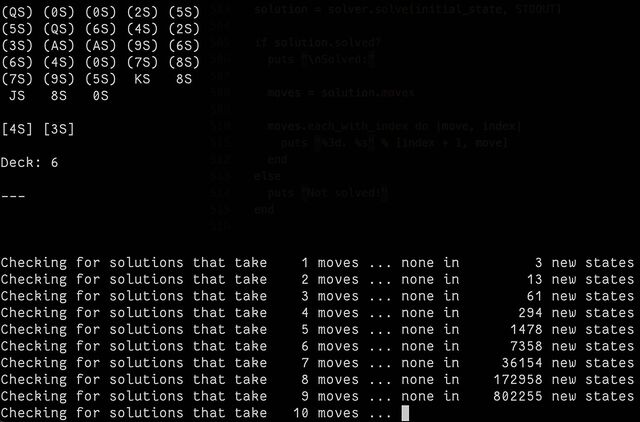
Partially that’s because the underlying state engine I used, BfsBruteForce, is a breadth-first optimising algorithm. It aims to find the absolute fewest-moves solution, which isn’t necessarily the fastest one to find because it means that it has to try all of the “probably stupid” moves it finds4 with the same priority as the the “probably smart” moves5.
I played about with enhancing it with some heuristics, and scoring different play states, and then running that in a pruned depth-first way, but it didn’t really help much. It came to an answer eventually, sure… but it took a long, long time, and it’s pretty easy to see why: the number of permutations for a shuffled deck of cards is greater than the number of atoms on Earth!
If you pull off a genuinely random shuffle, then – statistically-speaking – you’ve probably managed to put that deck into an order that no deck of cards has never been in before!6
And sure: the rules of the game reduce the number of possibilities quite considerably… but there’s still a lot of them.
So how are “guaranteed winnable” decks generated?
I think I’ve worked out the answer to this question: it came to me in a dream!

The trick to generating “guaranteed winnable” decks for FlipFlop Solitaire (and, probably, any similar game) is to work backwards.
Instead of starting with a random deck and checking if it’s solvable by performing every permutation of valid moves… start with a “solved” deck (with all the cards stacked up neatly) and perform a randomly-selected series of valid reverse-moves! E.g.:
- The first move is obvious: take one of the kings off the “finished” piles and put it into a column.
- For the next move, you’ll either take a different king and do the same thing, or take the queen that was exposed from under the first king and place it either in an empty column or atop the first king (optionally, but probably not, flipping the king face down).
- With each subsequent move, you determine what the valid next-reverse-moves are, choose one at random (possibly with some kind of weighting), and move on!
In computational complexity theory, you just transformed an NP-Hard problem7 into a P problem.
Once you eliminate repeat states and weight the randomiser to gently favour moving “towards” a solution that leaves the cards set-up and ready to begin the game, you’ve created a problem that may take an indeterminate amount of time… but it’ll be finite and its complexity will scale linearly. And that’s a big improvement.
I started implementing a puzzle-creator that works in this manner, but the task wasn’t as interesting as the near-impossible brute-force solver so I gave up, got distracted, and wrote some even more-pointless code instead.
If you go ahead and make an open source FlipFlop deck generator, let me know: I’d be interested to play with it!
Footnotes
1 I don’t get much time to play videogames, nowadays, but I sometimes find that I’ve got time for a round or two of a simple “droppable” puzzle game while I’m waiting for a child to come out of school or similar. FlipFlop Solitaire is one of only three games I have installed on my phone for this purpose, the other two – both much less frequently-played – being Battle of Polytopia and the buggy-but-enjoyable digital version of Twilight Struggle.
2 Okay, it feels slightly frustrating when you make a series of choices that are perfectly logical and the most-rational decision under the circumstances. But the game has an “undo” button, so it’s not that bad.
3 Mostly I was interested in whether such a thing was possible, but folks who’re familiar with how much I enjoy “cheating” at puzzles (don’t get me started on Jigidi jigsaws…) by writing software to do them for me will also realise that this is Just What I Am Like.
4 An example of a “probably stupid” move would be splitting a same-suit stack in order to sit it atop a card of a different suit, when this doesn’t immediately expose any new moves. Sometimes – just sometimes – this is an optimal strategy, but normally it’s a pretty bad idea.
5 Moving a card that can go into the completed stacks at the top is usually a good idea… although just sometimes, and especially in complex mid-game multi-suit scenarios, it can be beneficial to keep a card in play so that you can use it as an anchor for something else, thereby unblocking more flexible play down the line.
6 Fun fact: shuffling a deck of cards is a sufficient source of entropy that you can use it to generate cryptographic keystreams, as Bruce Schneier demonstrated in 1999.
7 I’ve not thought deeply about it, but determining if a given deck of cards will result in a winnable game probably lies somewhere between the travelling salesman and the halting problem, in terms of complexity, right? And probably not something a right-thinking person would ask their desktop computer to do for fun!