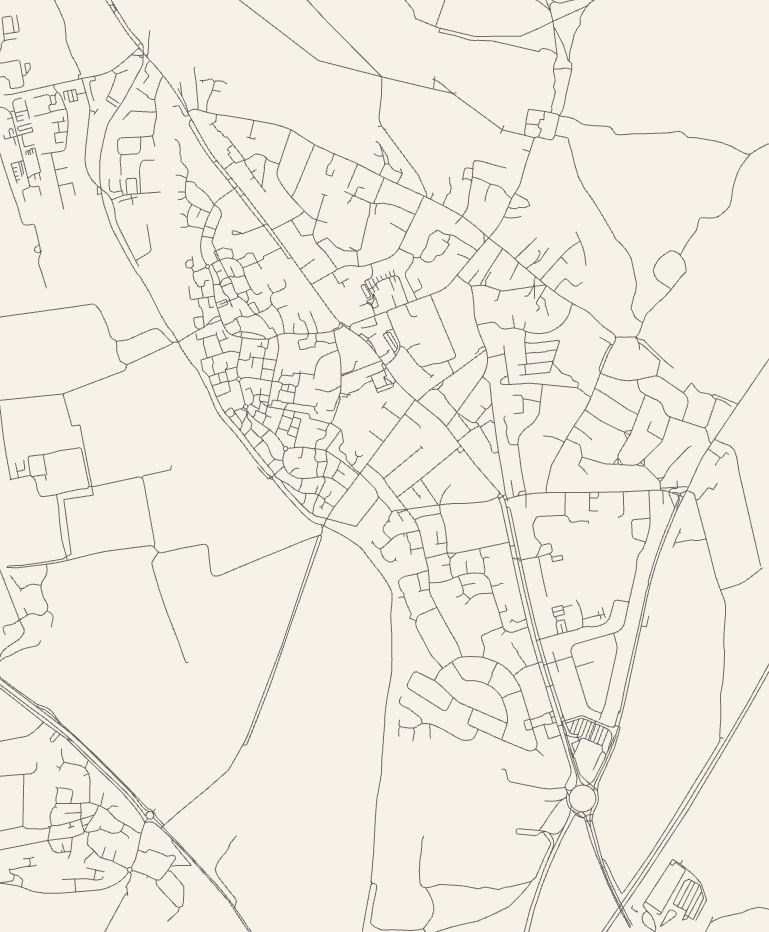
Cute open source project that produces on-demand SVG and PNG maps,
like the one above, based on the roads in OpenStreetMap data. It takes a somewhat liberal view of what a “road” is: I found it momentarily
challenging to get my bearings in the map above, which includes where I live, because the towpath and cycle paths are included which I hadn’t expected. Still a beautiful bit of output
and the source code could be adapted for any number of interesting cartographic projects.
A frisbee, propelled by the wind and balanced upright by some kind of black magic, makes an elegant and hypnotic dance across a frozen pond.
Which would be beautiful and weird enough as it is, and is sufficient reason alone to watch this video. But for the full experience you absolutely have to turn on the subtitles.
(Joe reads the text on IE and clicks on “Suggested Sites”)
Me: “Why did you click on that?”
Joe: “I don’t really know what to do, so I thought this would suggest something to me.”
…
Finding adults who’ve got basically no computer experience whatsoever is getting increasingly rare (and already was very uncommon back in 2011 when this was written), and so I can see
why Jennifer Morrow, when presented with the serendipitous opportunity to perform some user testing with one, made the very most of the occasion.
As well as being a heart-warming story, this post’s a good reminder that we shouldn’t make assumptions about the level of expertise of our users.
The violent and oftentimes ironically ignorant backlash against Fall’s story sheds light on a troublingly regressive, entitled, and puritanical trend in the relationship between
artists and their audiences, particularly when it comes to genre fiction. Readers appear to feel a need to cast their objections to fiction in moral terms, positioning themselves as
protectors of the downtrodden. Trans writer Phoebe Barton went so far as to compare Fall’s story to a “gun” which could be used only to inflict harm, though in a later tweet she,
like Jemisin, admitted she hadn’t read it and had based her reaction solely on its title.
Many reactions to Fall’s story, for all that they come from nominal progressives, fit neatly into a Puritanical mold, attacking it as hateful toward transness, fundamentally evil
for depicting a trans person committing murder, or else as material that right-wing trolls could potentially use to smear trans people as ridiculous. Each analysis positioned the
author as at best thoughtless and at worst hateful, while her attackers are cast as righteous; in such a way of thinking, art is not a sensual or aesthetic experience but a strictly
moral one, its every instance either fundamentally good or evil. This provides aggrieved parties an opportunity to feel righteousness in attacking transgressive art, positioning
themselves as protectors of imagined innocents or of ideals under attack.
…
As few days ago, I shared a short story called I Sexually Identify as an Attack Helicopter. By the time my reshare went live, the
original story had been taken down at its author’s request and I had to amend my post to link to an archived copy. I’d guessed, even at that point, that the story had been seen as
controversial, but I hadn’t anticipated the way in which it had so been seen.
Based on the article in The Outline, it looks like complaints about the story came not as I’d anticipated from right-wingers upset that their mocking, derogatory term had been
subverted in a piece of art but instead from liberals, including arguments that:
despite its best efforts, the story sometimes conflates sex, gender, and occasionally sexual orientation, (yeah, that’s a fair point, but it doesn’t claim to be perfect)
it’s an argument for imperialism by tying aggression to an (assigned, unconventional) gender, thereby saying that “some people are legitimised in their need for war” (I don’t
think we’re at any risk of anybody claiming that their gender made them commit an atrocity)
it identifies a trans person as a potential war criminal (so what? literature doesn’t have to paint every trans person in a perfectly-positive light, and I’d argue that the
empowerment and self-determination of the protagonist are far more-visible factors)
I note that some of the loudest complainants have admitted that they didn’t even read the story, just the title. If you’re claiming to be a trans ally, you really ought to demonstrate
that you don’t literally judge a book by its cover.
I don’t think that the story was perfect. But I think that the important messages – that gender presentation is flexible, not fixed; that personal freedom of gender expression is
laudable; that behaviour can be an expression of gender identity, etc. – are all there, and those relatively-simple messages are the things that carry-over to the audience that
the (sensational) title attracts. Trans folks in fiction are rarely the protagonists and even-more-rarely so relatable, and there’s value in this kind of work.
Sure, there are issues. But rather than acting in a way that gets a (seemingly well-meaning) work taken down, we should be using it as a vehicle for discussion. Where are the problems?
What are our reactions? Why does it make us feel the way it does? We improve trans depictions in fiction not by knee-jerk reactions to relatively-moderate stories and by polarising the
space into “good” and “bad” examples, but by iterative improvements, a little at a time, as we learn from our mistakes and build upon our successes. We should be able to both
celebrate this story and dissect its faults. We can do better, Internet.
A former colleague talks about some of the artefacts from the Bodleian’s collections that didn’t make it into the Talking Maps exhibition (one of the last exhibitions I got to work on during my time there; indeed, you’ll see plenty of
pictures from it in my post about making digital interactives). I was particularly pleased by the Soviet map of Oxford, but everything Nick presents
in this video is pretty awesome: it’s a great reminder that for every fantastic exhibition you see at a good museum, there’s always at least as much material “behind the
scenes” that you’re missing out on!
Last week I tweeted a cow-based academic publishing analogy in response to the prompt in the title, and the replies and quote-tweets extended the metaphor so gloriously, so
creatively, so bleakly and hilariously at the same time, that I’ve pulled my favourites together below.
Here’s the original tweet:
Cows make milk. They milk themselves.
Other cows check the milk (for free).
Cows – get this – PAY THE FARMER to take the milk away.
When I took a diversion from my various computer science related qualifications to study psychotherapy for a while, I was amazed to discover how fortunate we computer
scientists are that so much of our literature is published open access. It probably comes from the culture of the discipline, whose forefathers were publishing their work as
open-source software or on the Internet long before academic journals reached the online space. But even here, there’s journal drama and all the kinds of problems that Ned (and the
people who replied to his tweet) joke about.
I’m not sure that I’m physically fit enough for this “sport”, but I’d totally give it a go. If only to troll the BMX and skate kids
at the local skate park…
2020 is only three weeks old, but there has been a lot of browser news that decreases rendering engine diversity. It’s time for some good news on that front: a new rendering engine,
Flow. Below I conduct an interview with Piers Wombwell, Flow’s lead developer.
This year alone, on the negative side Mozilla announced it’s
laying off 70 people, most of whom appear to come from the browser side of things, while it turns out that Opera’s main cash cow is now providing loans in Kenya, India, and
Nigeria, and it is looking to use ‘improved credit scoring’ (from browsing data?) for its business practices.
On the positive side, the Chromium-based Edge is here, and it looks good. Still, rendering engine diversity took
a hit, as we knew it would ever since the announcement.
So let’s up the diversity a notch by welcoming a new rendering engine to the desktop space. British company Ekioh is working on a the Flow browser, which sports a completely new multi-threaded rendering engine that does not have any relation to WebKit, Gecko, or Blink.
I’m not convinced that Flow is the solution to all the world’s problems (its target platforms and use-cases alone make it unlikely to make it onto the most-used-browsers leaderboard any
time soon), but I’m really glad that my doomsaying about the death of browser diversity being a one-way street might… might… turn out
not to be true.
Time will tell. But for now, this is Good News for the Web.
Last week I built Fox, the newest addition to our home network. Fox, whose specification
called for not one, not two, not three but four 12 terabyte hard disk drives was built principally as a souped-up NAS
device – a central place for us all to safely hold and control access to important files rather than having them spread across our various devices – but she’s got a lot more going on
that that, too.
Right now, Fox lives under my desk along with most of our network cables.
Fox has:
Enough hard drive space to give us 36TB of storage capacity plus 12TB of parity, allowing any
one of the drives to fail without losing any data.
“Headroom” sufficient to double its capacity in the future without significant effort.
A mediumweight graphics card to assist with real-time transcoding, helping her to convert and stream audio and videos to our devices in whatever format they prefer.
A beefy processor and sufficient RAM to run a dozen virtual machines supporting a variety of functions like software
development, media ripping and cataloguing, photo rescaling, reverse-proxying, and document scanning (a planned future purpose for Fox is to have a network-enabled scanner near our
“in-trays” so that we can digitise and OCR all of our post and paperwork into a searchable, accessible, space-saving
collection).
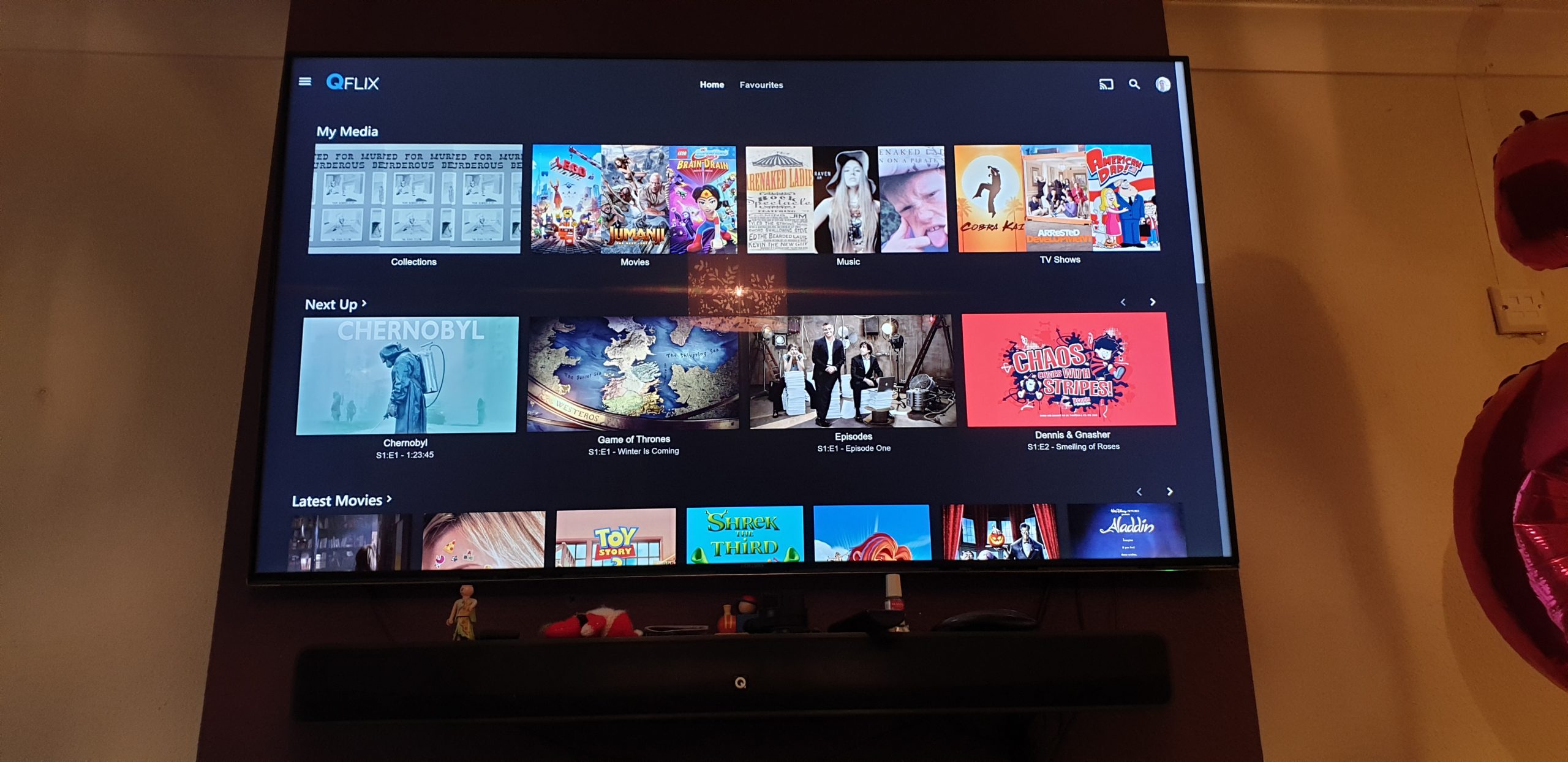
“QFlix” is a lot like Netflix, except geared mostly towards saving us from having to walk over to the DVD shelf or remember which disc we were up to when watching a long-running
series. #firstworldproblems
The last time I filmed myself building a PC was when I built Cosmo, a couple of desktops ago. He
turned out to be a bit of a nightmare: he was my first fully-watercooled computer and he leaked everywhere: by the time I’d done all the fixing and re-fixing to make him behave nicely,
I wasn’t happy with the video footage and I never uploaded it. I’d been wary, almost-superstitious, about filming a build since then, but I shot a timelapse of Fox’s construction and it
turned out pretty well: you can watch it below or on YouTube or QTube.
The timelapse slows to real-time, about a minute in, to illustrate a point about the component test I did with only a CPU (and
cooler), PSU, and RAM attached. Something I routinely do when building
computers but which I only recently discovered isn’t commonly practised is shown: that the easiest way to power on a computer without attaching a power switch is just to bridge the
power switch pins using your screwdriver!
Fox is running Unraid, an operating system basically designed for exactly these kinds of purposes. I’ve been super-impressed by the
ease-of-use and versatility of Unraid and I’d recommend it if you’ve got a similar NAS project in your future! I’d also like
to sing the praises of the Fractal Design Node 804 case: it’s not got quite as many bells-and-whistles
as some cases, but its dual-chamber design is spot-on for a multipurpose NAS, giving ample room for both full-sized expansion
cards and heatsinks and lots of hard drives in a relatively compact space.
I think that CSS would be greatly helped if we solemnly state that “CSS4 is here!” In this post I’ll try to convince you of my viewpoint.
I am proposing that we web developers, supported by the W3C CSS WG, start saying “CSS4 is here!” and excitedly chatter about how it will hit the market any moment now and transform
the practice of CSS.
Of course “CSS4” has no technical meaning whatsoever. All current CSS specifications have their own specific
versions ranging from 1 to 4, but CSS as a whole does not have a version, and it doesn’t need one, either.
Regardless of what we say or do, CSS 4 will not hit the market and will not transform anything. It also does not describe any technical reality.
But if you’ve got more than a little web savvy you might still be surprised to hear me say that CSS4 is here, or even
that it’s a “thing” at all. Welll… that’s because it isn’t. Not officially. Just like JavaScript’s versioning has gone all evergreen these last few years,
CSS has gone the same way, with different “modules” each making their way through the standards and implementation processes
independently. Which is great, in general, by the way – we’re seeing faster development of long-overdue features now than we have through most of the Web’s history – but it
does make it hard to keep track of what’s “current” unless you follow along watching very closely. Who’s got time for that?
When CSS2 gained prominence at around the turn of the millennium it was revolutionary, and part of the reason for that
– aside from the fact that it gave us all some features we’d wanted for a long time – was that it gave us a term to rally behind. This browser already supports it, that browser’s
getting there, this other browser supports it but has a f**ked-up box model (you all know the one I’m talking about)… we at last had an overarching term to discuss what was supported,
what was new, what was ready for people to write articles and books about. Nobody’s going to buy a book that promises to teach them “CSS3 Selectors Level 3, Fonts Level 3, Writing Modes
Level 3, and Containment Level 1”: that title’s not even going to fit on the cover. But if we wrapped up a snapshot of what’s current and called it CSS4… now that’s going to sell.
Can we show the CSS WG that there’s mileage in this idea and make it happen? Oh, I hope so. Because while the
modular approach to CSS is beautiful and elegant and progressive… I’m afraid that we can’t use it to inspire junior developers.
Also: I don’t want this joke to forever remain among the top results
when searching for CSS4…
I also ask not to discard all this nonsense right away, but at least give it a fair round of thought. My recommendations, if applied in their entirety, can radically change Git
experience. They can move Git from advanced, hacky league to the mainstream and enable adoption of VCS by very wide groups of people. While this is still a concept and obviosly
requires a hell of a job to become reality, my hope is that somebody working on a Git interface can borrow from these ideas and we all will get better Git client someday.
I love Git. But I love it more conceptually than I do practically. Everything about its technical design is elegant and clever. But most of how you have to act when
you’re using it just screams “I was developed by lots of engineers and by exactly zero UX developers.” I can’t imagine why.
Nikita proposes ways in which it can be “fixed” while retaining 100% backwards-compatibility, and that’s bloody awesome. I hope the Git core team are paying attention, because these
ideas are gold.
I lied. According to US Army Technical Manual 0, The Soldier as a System, “attack helicopter” is a gender identity, not a biological sex. My dog tags and Form 3349 say my body is an
XX-karyotope somatic female.
But, really, I didn’t lie. My body is a component in my mission, subordinate to what I truly am. If I say I am an attack helicopter, then my body, my sex, is too. I’ll prove it to
you.
When I joined the Army I consented to tactical-role gender reassignment. It was mandatory for the MOS I’d tested into. I was nervous. I’d never been anything but a woman before.
But I decided that I was done with womanhood, over what womanhood could do for me; I wanted to be something furiously new.
To the people who say a woman would’ve refused to do what I do, I say—
Isn’t that the point?
…
This short story almost-certainly isn’t what you’d expect, based on the title. What it is sits at the intersection of science fiction and gender identity, and it’s pretty damn
good.
While being driven around England it struck me that humans are currently like the filling in a sandwich between one slice of machine — the satnav — and another — the car. Before the
invention of sandwiches the vehicle was simply a slice of machine with a human topping. But now it’s a sandwich, and the two machine slices are slowly squeezing out the human filling
and will eventually be stuck directly together with nothing but a thin layer of API butter. Then the human will be a superfluous thing, perhaps a little gherkin on the side of the
plate.
While we were driving I was reading the directions from a mapping app on my phone, with the sound off, checking the upcoming turns, and giving verbal directions to Mary, the driver. I
was an extra layer of human garnish — perhaps some chutney or a sliced tomato — between the satnav slice and the driver filling.
What Phil’s describing is probably familiar to you: the experience of one or more humans acting as the go-between to allow two machines to communicate. If you’ve ever re-typed a
document that was visible on another screen, read somebody a password over the phone, given directions from a digital map, used a pendrive to carry files between computers that weren’t
talking to one another properly then you’ve done it: you’ve been the soft wet meaty middleware that bridged two already semi-automated (but not quite automated enough)
systems.
Sigourney Weaver as Gwen DeMarco as Tawny Madison realised what she was doing back in 1999. Should I be alarmed that a science fiction spoof is a better indicator of the future that
the science fiction it parodies?
This generally happens because of the lack of a common API (a communications protocol) between two systems. If your
phone and your car could just talk it out then the car would know where to go all by itself! Or, until we get self-driving cars, it could at least provide the directions in a
way that was appropriately-accessible to the driver: heads-up display, context-relative directions, or whatever.
It also sometimes happens when the computer-to-human interface isn’t good enough; for example I’ve often offered to navigate for a driver (and used my phone for the purpose) because I
can add a layer of common sense. There’s no need for me to tell my buddy to take the second exit from every roundabout in Milton Keynes (did you know that the town has 930 of them?) – I can just tell them that I’ll let them know when
they have to change road and trust that they’ll just keep going straight ahead until then.
Finally, we also sometimes find ourselves acting as a go-between to filter and improve information flow when the computers don’t have enough information to do better by themselves. I’ll
use the fact that I can see the road conditions and the lane markings and the proposed route ahead to tell a driver to get into the right lane with an appropriate amount of
warning. Or if the driver says “I can see signs to our destination now, I’ll just keep following them,” I can shut up unless something goes awry. Your in-car SatNav can’t do that
because it can’t see and interpret the road ahead of you… at least not yet!
I was certainly glad that this prototype self-driving car could “see” me when it overtook my bike the other day.
But here’s my thought: claims of an upcoming AI
winter aside, it feels to me like we’re making faster progress in technologies related to human-computer interaction – voice and natural languages interfaces, popularised
by virtual assistants like Siri and Alexa and by chatbots – than we are in technologies related to universal computer interoperability. Voice-controller computers are hip and exciting
and attract a lot of investment but interoperable systems are hampered by two major things. The first thing holding back interoperability is business interests: for the longest while,
for example, you couldn’t use Amazon Prime Video on a Google Chromecast for a long while because the two companies couldn’t play nice. The second thing is a lack of interest by
manufacturers in developing open standards: every smart home appliance manufacturer wants you to use their app, and so your smart speaker manufacturer needs to implement code
to talk to each and every one of them, and when they stop supporting one… well, suddenly your thermostat switches jumps permanently from smart mode to dumb mode.
A thing that annoys me is that from a technical perspective making an open standard should be a much easier task than making an AI that can understand what a human is asking for or drive a car safely or whatever we’re using them for this week. That’s not to say that technical
standards aren’t difficult to get right – they absolutely are! – but we’ve been practising doing it for many, many decades! The very existence of the Internet over which you’ve been
delivered this article is proof that computer interoperability is a solvable problem. For anybody who thinks that the interoperability brought about by the Internet was inevitable or
didn’t take lots of hard work, I direct you to Darius Kazemi’s re-reading of the early standards discussions, which I first plugged a year ago; but the important thing is that people were working on it. That’s something we’re not really seeing in the Internet of
Things space.
Engineers: “Standards are good. Let’s have lots of them.”
Everybody else: “…?”
On our current trajectory, it’s absolutely possible that our virtual assistants will reach a point of becoming perfectly “human” communicators long before we can reach agreements about
how they should communicate with one another. If that’s the case, those virtual assistants will probably fall back on using English-language voice communication as their lingua
franca. In that case, it’s not unbelievable that ten to twenty years from now, the following series of events might occur:
You want to go to your friends’ house, so you say out loud “Alexa, drive me to Bob’s house in five minutes.” Alexa responds “I’m on it; I’ll let you know more in a few
minutes.”
Alexa doesn’t know where Bob’s house is, but it knows it can get it from your netbook. It opens a voice channel over your wireless network (so you don’t have to “hear” it) and says
“Hey Google, it’s Alexa [and here’s my credentials]; can you give me the address that [your name] means when they say ‘Bob’s house’?” And your netbook responds by reading
out the address details, which Alexa then understands.
Alexa doesn’t know where your self-driving car is right now and whether anybody’s using it, but it has a voice control system and a cellular network connection, so Alexa phones
up your car and says: “Hey SmartCar, it’s Alexa [and here’s my credentials]; where are you and when were you last used?”. The car replies “I’m on the driveway, I’m
fully-charged, and I was last used three hours ago by [your name].” So Alexa says “Okay, boot up, turn on climate control, and prepare to make a journey to [Bob’s
address].” In this future world, most voice communication over telephones is done by robots: your virtual assistant calls your doctor’s virtual assistant to make you an
appointment, and you and your doctor just get events in your calendars, for example, because nobody manages to come up with a universal API for medical appointments.
Alexa responds “Okay, your SmartCar is ready to take you to Bob’s house.” And you have no idea about the conversations that your robots have been having behind your back
I’m not saying that this is a desirable state of affairs. I’m not even convinced that it’s likely. But it’s certainly possible if IoT development keeps focussing on shiny friendly conversational interfaces at the expense of practical, powerful technical standards. Our already
topsy-turvy technologies might get weirder before they get saner.
But if English does become the “universal API” for robot-to-robot communication, despite all engineering common
sense, I suggest that we call it “sandwichware”.
It’s worth noting here that the idea that a parent should be a caretaker, educator, and entertainer rolled into one is not only historically, but also culturally specific. “There
are lots of cultures where [parent-child play is] considered absolutely inappropriate—a parent would never get down on their knees and play with the children. Playing is something
children do, not something adults do,” developmental psychologist Angeline Lillard said in an interview. “And that’s just
fine. There’s no requirement for playing.”
Differences in practices around parent-child play exist within American subgroups, too. Sociologist Annette Lareau has
observed a gap in beliefs about parent-child play between working-class/poor parents and middle-class parents in the United States. Working-class and poor parents in her study
held a view that they were responsible for “supervision in custodial matters” (Did the child get to sleep on time? Does the child have sneakers that fit?) and “autonomy in leisure
matters,” while the middle-class parents engaging in what Lareau termed “concerted cultivation” invested themselves heavily in children’s play. Ultimately, the poorer kids, Lareau
found, “tended to show more creativity, spontaneity, enjoyment, and initiative in their leisure pastimes than we saw among middle-class children at play in organized activities.”
…
Interesting article (about 10 minutes reading), so long as you come at it from at least a little bit of an academic, anthropological perspective and so aren’t expecting to come
out of it with concrete, actionable parenting advice!
Engaging in some kinds of play with your kids can be difficult. I’ve lost count of the hours spent in imaginative play with our 6-year-old, trying to follow-along with the
complex narrative and characters she’s assembled and ad-lib along (and how many times she’s told me off for my character not making the choices she’d hoped they would, because she’s at
least a little controlling over the stories she tells!). But I feel like it’s also a great way to engage with them, so it’s worth putting your devices out of sight, getting down on the
carpet, and playing along… at least some of the time. The challenge is finding the balance between being their perpetual playmate and ensuring that they’re encouraged to “make their own
fun”, which can be an important skill in being able to fight off boredom for the rest of their lives.
If I ever come up with a perfect formula, I’ll tell you; don’t hold your breath! In the meantime, reading this article might help reassure you that despite there almost-certainly not
being a “right way”, there are plenty of “pretty good ways”, and the generally-good human values of authenticity and imagination and cooperation are great starting points for
playing with your children, just like they are for so many other endeavours. Your kids are probably going to be okay.
I’m posting this on the last day of 2019. As I write it, the second post I ever made on
meyerweb says it was published “20 years, 6 days ago”. It was published on the second-to-last day of 1999, which was 20 years and one day ago.
What I realized, once the discrepancy was pointed out to me (hat tip: Eric Portis), is the five-day error is there because in the two decades
since I posted it, there have been five leap days. When I wrote the code to construct those relative-time strings, I either didn’t think about leap days, or if I did, I
decided a day or two here and there wouldn’t matter all that much.
Which is to say, I failed to think about the consequences of my code running over long periods of time. Maybe a day or two of error isn’t all that big a deal, in
human-friendly relative-time output. If a post was six years and two days ago but the code says 6 and 1, well, nobody will really care that much even if they notice. But
five days is noticeable, and what’s more, it’s a little human-unfriendly. It’s noticeable. It jars.
…
As I mentioned in my comments on a repost last week, I work to try to make the
things I publish to this site last. But that’s not to say that problems can’t creep in, either because of fundamental bugs left unnoticed until later on (such as the image
recompression problem that’s recently lead to some of my older images going wonky; I’m working on it) or else because because of environmental changes e.g. in the technologies that are
supported and the ways in which they’re used. The latter are helped by standards and by an adherence to them, but the former will trip over Web developers time and time again, and it’s
possible that there’s nothing we can do about it.
No system is perfect, and we don’t have time to engineer every system, every site, every page in a way that near-guarantees its longevity; not by a long shot. I tripped myself over just
the year before last when I added Content-Security-Policy headers to my site and promptly broke every embedded YouTube or Vimeo video
because they didn’t fit the newly (and retroactively) enforced pattern of allowable content. Such problems are easy to create when you’re maintaining a long-running system with a lot of
data. I’m only talking about my blog, but larger, older and/or more-complex systems (of which I’ve worked on a few!) come with their own multitudinous challenges.
That said, the Web has demonstrated a resilience that surpasses most of what is expected in consumer computing. If you want to run a video game from 1994 or even 2001 on a modern
computer, you’re likely to find that you have to put in considerably more work than you would have on the day it was released! But even some of the oldest webpages still-existing remain
usable today.
Occasionally, though: a “hip” modern technology without the backing of widespread browser standards comes along and creates a dark age. Flash created such a dark age; now there are
millions of Flash-dependent web pages that simply don’t work any longer. Java created another. And I worry that the unnecessary overuse of front-end rendering technologies are creating
a third that we’re living through right now, oblivious to the data we’re creating and losing.