Asynchronous JavaScript in the form of Single Page Applications (SPA) offer an incredible opportunity for improving the user experience of your web
applications. CSS frameworks like Bootstrap enable developers to quickly contribute styling as they’re working on the structure and behaviour of things.
Unfortunately, SPA and CSS frameworks tend to result in relatively complex solutions where traditionally separated concerns – HTML-structure, CSS-style, and JS-behaviour – are blended
together as a matter of course — Counter to the lessons learned by previous generations.
This blending of concerns can prevent entry level developers and valued specialists (Eg. visual design, accessibility, search engine optimization, and internationalization) from
making meaningful contributions to a project.
In addition to the increasing cost of the few developers somewhat capable of juggling
all of these concerns, it can also result in other real world business implications.
…
What is a front-end developer? Does anybody know, any more? And more-importantly, how did we get to the point where we’re actively encouraging young developers into habits like
writing (cough React cough) files containing a bloaty, icky mixture of content, HTML (markup), CSS (style), and Javascript (behaviour)? Yes, I get that the idea is that individual components should be packaged
together (if you’re thinking in a React-like worldview), but that alone doesn’t justify this kind of bullshit antipattern.
It seems like the Web used to have developers. Then it got complex so we started differentiating back-end from front-end developers and described those who, like me, spanned the divide,
as full-stack developers We gradually became a minority as more and more new developers, deprived of the opportunity to learn each new facet organically in this newly-complicated
landscape, but that’s fine. But then… we started treating the front-end as the only end, and introducing all kinds of problems as a result… and most people don’t seem to have
noticed, yet, exactly how much damage we’re doing to Web applications’ security, maintainability, future-proofibility, archivability, addressibility…
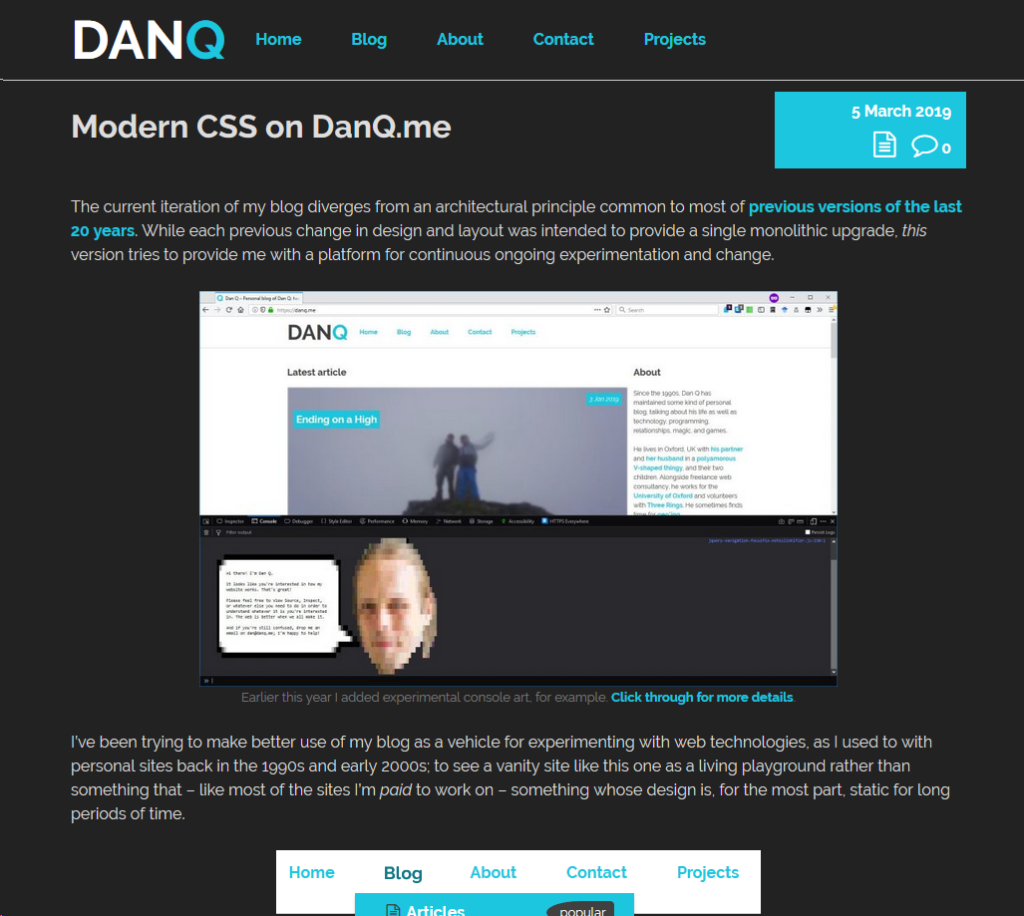
The current iteration of my blog diverges from an architectural principle common to most of previous versions of the last 20 years. While
each previous change in design and layout was intended to provide a single monolithic upgrade, this version tries to provide me with a platform for continuous ongoing
experimentation and change.
I’ve been trying to make better use of my blog as a vehicle for experimenting with web technologies, as I used to with personal sites back in the 1990s and early 2000s; to see a vanity
site like this one as a living playground rather than something that – like most of the sites I’m paid to work on – something whose design is, for the most part, static for
long periods of time.
The “popular” flag and associated background colour in the “Blog” top-level menu became permanent after a period of A/B testing. Thanks, unwitting testers!
I’m not entirely happy with the design of these boxes, but that’s a job for another day.
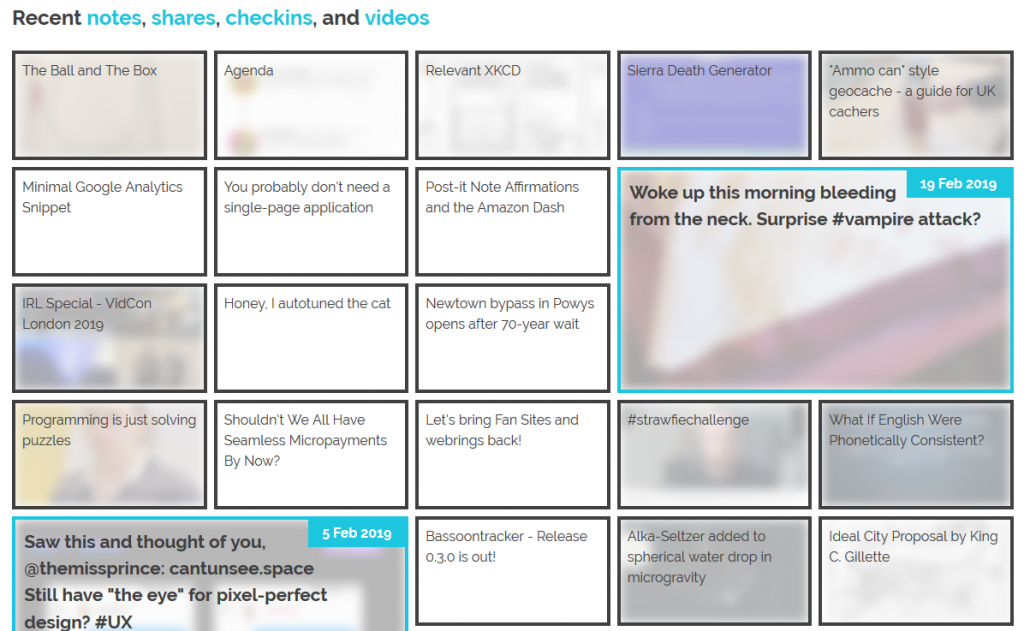
The grid of recent notes, shares, checkins and videos on my
homepage is powered by the display: grid; CSS directive. The number of columns varies by screen width from six
on the widest screens down to three or just one on increasingly small screens. Crucially, grid-auto-flow: dense; is used to ensure an even left-to-right filling of the
available space even if one of the “larger” blocks (with grid-column: span 2; grid-row: span 2;) is forced for space reasons to run onto the next line. This means that
content might occasionally be displayed in a different order from that in which it is written in the HTML (which is reverse
order of publication), but in exchange the items are flush with both sides.
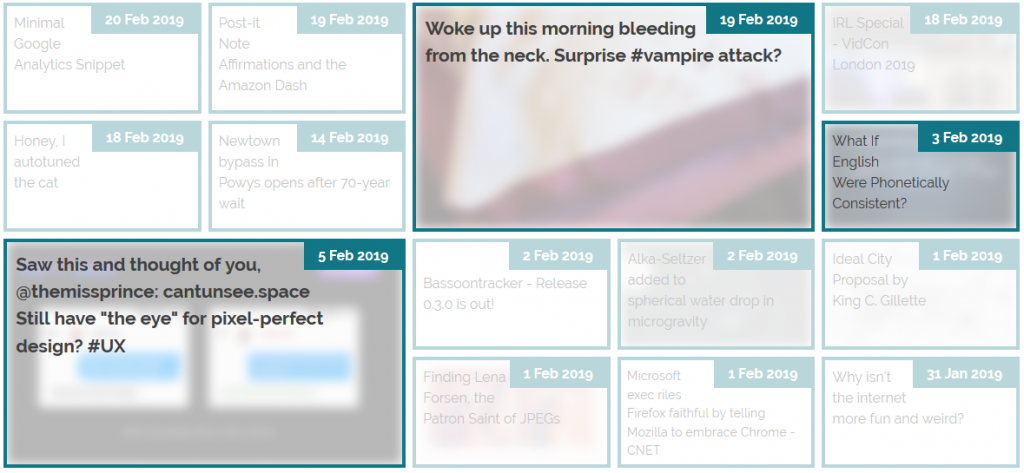
The large “5 Feb” item in this illustration should, reverse-chronologically, appear before the “3 Feb” item, but there isn’t room for it on the previous line. grid-auto-flow:
dense; means that the “3 Feb” item is allowed to bubble-up and fill the gap, appearing out-of-order but flush with the edge.
Not all web browsers support display: grid; and while that’s often only one of design and not of readability because these browsers will fall back to usually-very-safe
default display modes like block and inline, as appropriate, sometimes there are bigger problems. In Internet Explorer 11, for example, I found (with thanks to
@_ignatg) a problem with my directives specifying the size of these cells (which are actually <li> elements because, well,
semantics matter). Because it understood the directives that ought to impact the sizing of the list items but not
the one that redeclared its display type, IE made… a bit of a mess of things…
Thanks, Internet Explorer. That’s totally what I was looking for.
Do websites need to look the same in every browser? No. But the content should be readable
regardless, and here my CSS was rendering my content unreadable. Given that Internet Explorer users represent a little
under 0.1% of visitors to my site I don’t feel the need to hack it to have the same look-and-feel: I just need it to have the same content readability. CSS Feature Queries to the rescue!
CSS Feature Queries – the @supports selector – make it possible to apply parts of your stylesheet if and only if
the browser supports specific CSS features, for example grids. Better yet, using it in a positive manner (i.e. “apply these
rules only if the browser supports this feature”) is progressive enhancement, because browsers that don’t understand the @supports selector act in
the same way as those that understand it but don’t support the specified feature. Fencing off the relevant parts of my stylesheet in a @supports (display: grid) { ... }
block instructed IE to fall back to displaying that content as a boring old list: exactly what I needed.
It isn’t pretty, but it’s pretty usable!
Reduced-motion support
I like to put a few “fun” features into each design for my blog, and while it’s nowhere near as quirky as having my head play peek-a-boo when you
hover your cursor over it, the current header’s animations are in the same ballpark: hover over or click on some of the items in the header menu to see for yourself..
I’m most-pleased with the playful “bounce” of the letter Q when you hover over my name.
These kinds of animations are fun, but they can also be problematic. People with inner ear disorders (as well as people who’re just trying to maximise the battery life on their portable
devices!) might prefer not to see them, and web designers ought to respect that choice where possible. Luckily, there’s an emerging standard to acknowledge that: prefers-reduced-motion. Alongside its cousins inverted-colors, prefers-reduced-transparency, prefers-contrast and
prefers-color-scheme (see below for that last one!), these new CSS tools allow developers to optimise based on the accessibility
features activated by the user within their operating system.
In Windows you turn off animations while in MacOS you turn on not-having animations, but the principle’s the same.
If you’ve tweaked your accessibility settings to reduce the amount of animation your operating system shows you, this website will respect that choice as well by not animating the
contents of the title, menu, or the homepage “tiles” any more than is absolutely necessary… so long as you’re using a supported browser, which right now means Safari or Firefox (or the
“next” version of Chrome). Making the change itself is pretty simple: I just added a @media screen and (prefers-reduced-motion: reduce) { ... } block to disable or
otherwise cut-down on the relevant animations.
Dark-mode support
…
Similarly, operating systems are beginning to
support “dark mode”, designed for people trying to avoid eyestrain when using their computer at night. It’s possible for your browser to respect this and try to “fix” web pages for
you, of course, but it’s better still if the developer of those pages has anticipated your need and designed them to acknowledge your choice for you. It’s only supported in Firefox and
Safari so far and only on recent versions of Windows and MacOS, but it’s a start and a helpful touch for those nocturnal websurfers out there.
Come to the dark side, Luke. Or just get f.lux, I suppose.
It’s pretty simple to implement. In my case, I just stacked some overrides into a @media (prefers-color-scheme: dark) { ... } block, inverting the background and primary
foreground colours, softening the contrast, removing a few “bright” borders, and darkening rather than lightening background images used on homepage tiles. And again, it’s an example of
progressive enhancement: the (majority!) of users whose operating systems and/or browsers don’t yet support this feature won’t be impacted by its inclusion in my stylesheet, but those
who can make use of it can appreciate its benefits.
This isn’t the end of the story of CSS experimentation on my blog, but it’s a part of the it that I hope you’ve enjoyed.
One of the most common and effective ways to manage the caching of your assets is via the Cache-Control HTTP header. This header applies to
individual assets, meaning everything on our pages can have a very bespoke and granular cache policy. The amount of control we’re granted makes for very intricate and powerful caching
strategies.
A Cache-Control header might look something like this:
Cache-Control: public, max-age=31536000
Cache-Control is the header, and each of public and max-age=31536000 are directives. The Cache-Control header can accept one or more directives, and it is these
directives, what they really mean, and their optimum use-cases that I want to cover in this post.
…
A great reference for configuring your HTTP caching headers.
…Jesse James Garett of Adaptive Path finally gave this use of Javascript a name. He called it Asynchronous Javascript and XML (thankfully shortened to Ajax). Ajax wasn’t a single
method or technology, but a group of principles based on the work being done at Google that described how to handle JavaScript in more demanding web applications. The short version is
actually fairly simple. Use XMLHttpRequest to make request to the server, take the XML data returned, and lay it out on the page using JavaScript and semantic HTML.
Ajax took off after that. It underpins major parts of modern web development, and has spawned a number of frameworks and methodologies. The technology itself has been swapped out over
time. XML was replaced by JSON, and XMLHttpRequest by fetch. That doesn’t matter though. Ajax showed a lot of developers that the web wasn’t just about documents.
The web could be used to build applications. That might seem like a small notion, but trust me when I say, it was momentous.
The History of The Web is great, and you should read it, but this piece is particularly interesting. Ajax and its spiritual successors laid the groundwork for rich Internet
applications, shell apps, and the real-time Web, but they also paved the way for a handful of the inevitable practices that went alongside: Javascript-required websites, API-driven web
and mobile applications with virtually no HTML content whatsoever… and these things have begun to become problematic for the health of the Web as a whole.
I love Ajax, but it absolutely must be employed as progressive enhancement where possible.
Human beings leave physical impressions upon the things they love and use just as much as their do upon the lives of people and the planet they live upon. For every action, there’s a
reaction. For every pressure, there’s an affect on mass and volume. And in the impressions left by that combination, particularly if you’re lucky enough to see the sides of a rare,
unrestored vintage Pac-Man cabinet, lies the never before told story of how we really played the game.
Until now, I don’t believe anyone has ever written about it.
…
Interesting exploration of the history of the cabinets housing Pac-Man, observing the ergonomic impact of the controls on the way that people would hold the side of the machine and, in
turn, how that would affect where and how the paint would wear off.
Apparently the NCSF (US) are typing to make 28 February into Metamour Day: a
celebration of one’s lover’s lovers. While I’m not convinced that’ll ever get Hallmark’s interest, I thought it provided a good opportunity to sing the praises of my metamour, JTA.
This is a man who knows how to use Greek myths and legends to add magic to his daughter’s museum visit.
I first met JTA 15 years ago at Troma Night XX, when his girlfriend Ruth – an attendee of Troma Night since its earliest days the previous year – brought him along and we all mocked his three-letter initialism.
Contrary to our previous experience, thanks to Liz, of people bringing boyfriends once but never again (we always assumed that we
scared them off), JTA became a regular, even getting to relive some of the early nights that he’d missed in our nostalgic 50th event. Before long, I felt glad to count him among my friends.
Almost 13 years ago I described JTA thusly, and I stand by it:
You have a fantastic temper which you keep carefully bottled away and of which you draw out only a little at a time and only where it is genuinely justly deserved. Conversely, your
devotion to the things you love and care about is equally inspiring.
We’d be friends anyway, but having a partner-in-common has given us the opportunity for a closer relationship still. I love you, man: y’know, in the Greek way. Happy metamour
appreciation day.
Thread by @LaurenHerschel: “After what has been a surprisingly okayish Christmas, I had a moment today in SuperStore. Saw a lady who remindedndma, who even in the early stages of
dementia, completely understood that my mom died. I thought I’d share t […]”
After what has been a surprisingly okayish Christmas, I had a moment today in SuperStore. Saw a lady who reminded me of my 92yo grandma, who even in the early stages of
dementia, completely understood that my mom died.
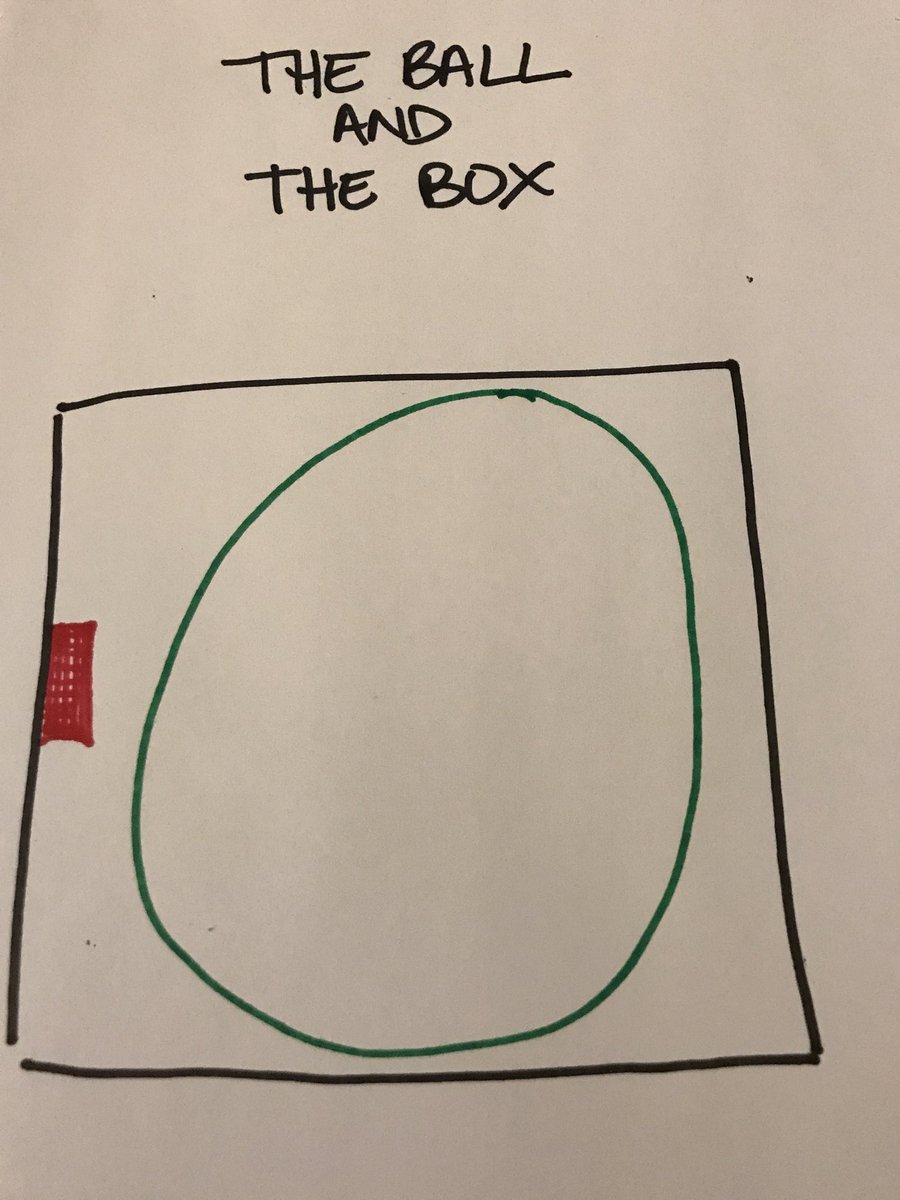
I thought I’d share the Ball in the Box analogy my Dr told me
So grief is like this:
There’s a box with a ball in it. And a pain button.
And no, I am not known for my art skills.
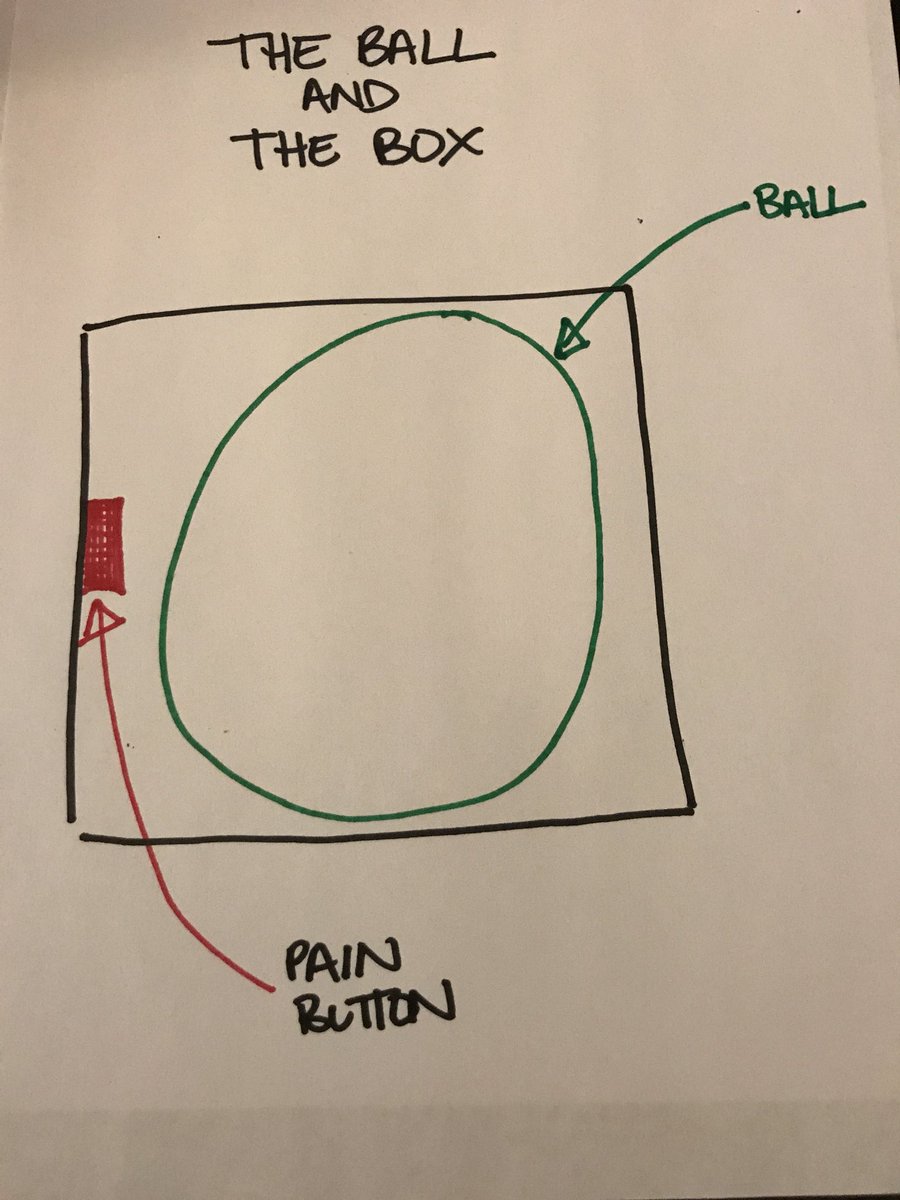
In the beginning, the ball is huge. You can’t move the box without the ball hitting the pain button. It rattles around on its own in there and hits the button over and over. You
can’t control it – it just keeps hurting. Sometimes it seems unrelenting.
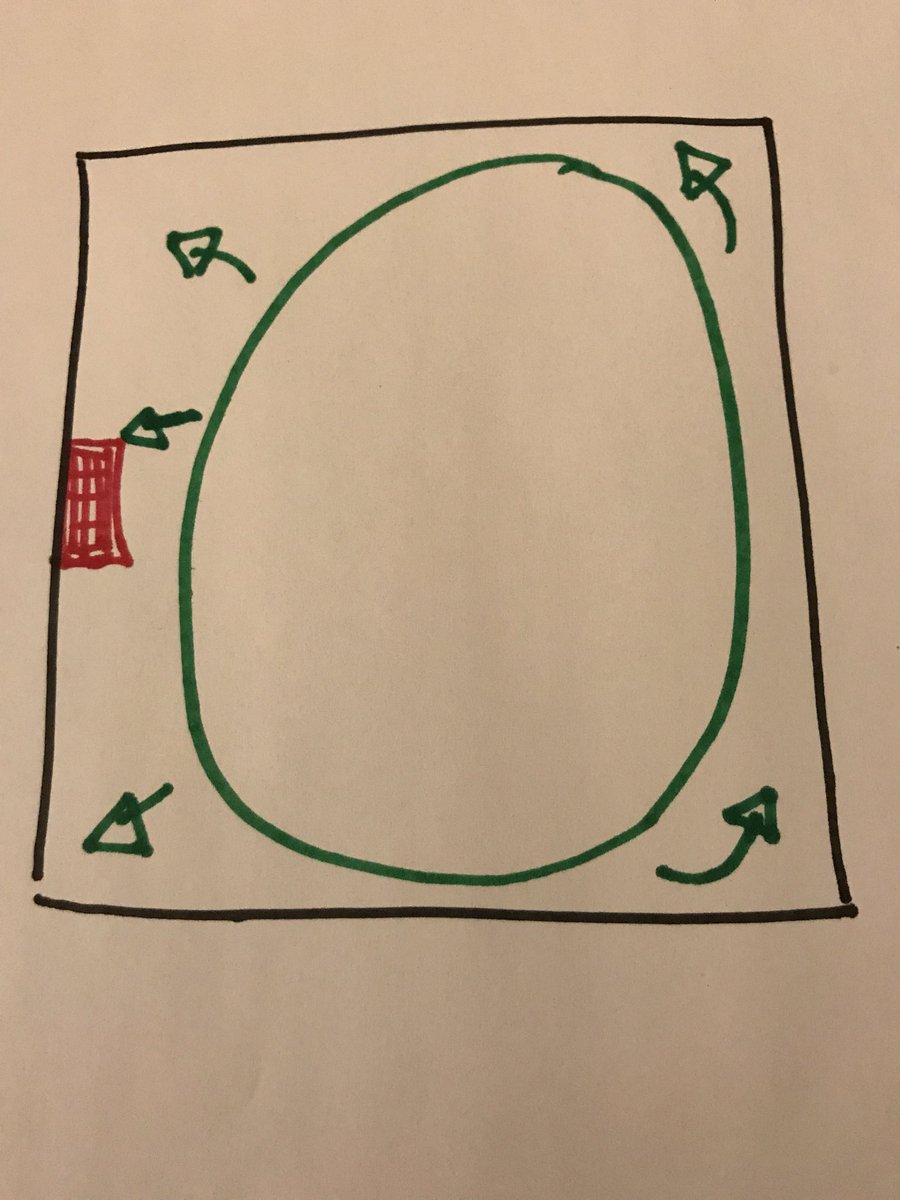
Over time, the ball gets smaller. It hits the button less and less but when it does, it hurts just as much. It’s better because you can function day to day more easily. But the
downside is that the ball randomly hits that button when you least expect it.
For most people, the ball never really goes away. It might hit less and less and you have more time to recover between hits, unlike when the ball was still giant.
I thought this was the best description of grief I’ve heard in a long time.
I told my step dad about the ball in the box (with even worse pictures). He now uses it to talk about how he’s feeling.
“The Ball was really big today. It wouldn’t lay off the button. I hope it gets smaller soon.”
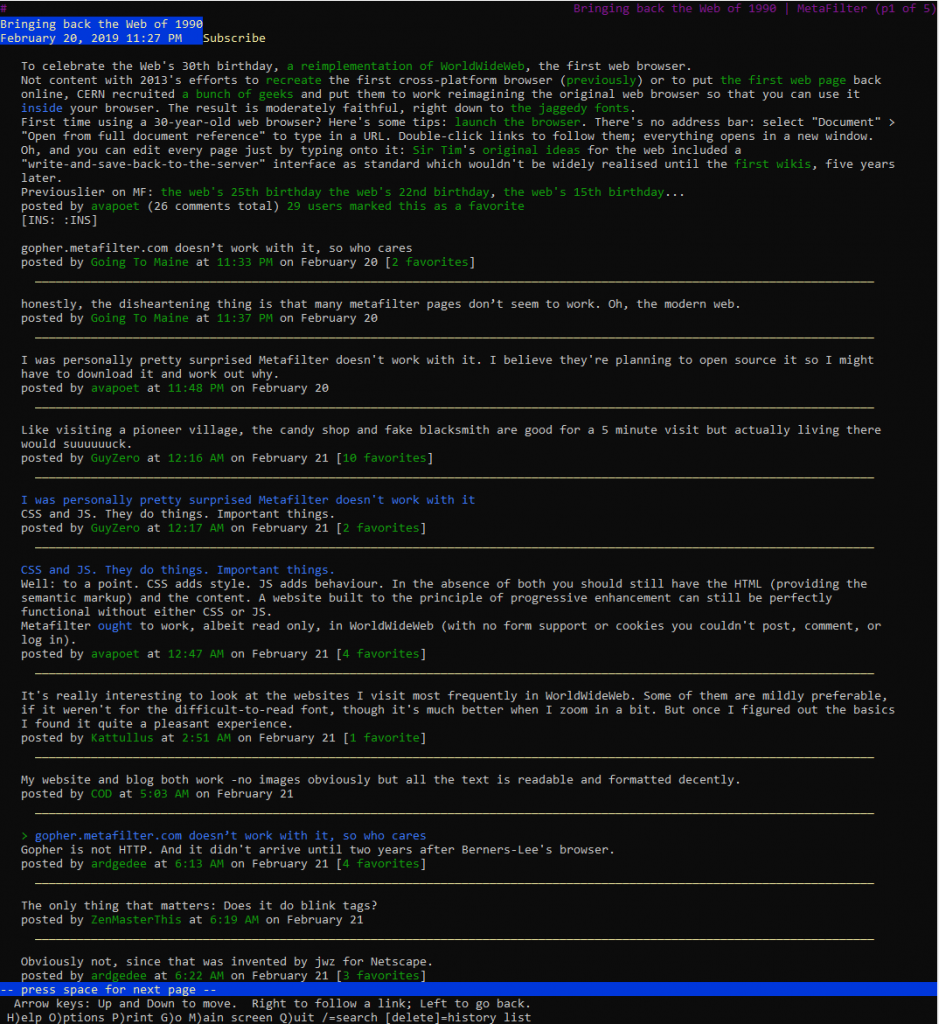
People were quick to point this out and assume that it was something to do with the modernity of MetaFilter:
honestly, the disheartening thing is that many metafilter pages don’t seem to work. Oh, the modern web.
Some even went so far as to speculate that the reason related to MetaFilter’s use of CSS and JS:
CSS and JS. They do things. Important things.
This is, of course, complete baloney, and it’s easy to prove to oneself. Firstly, simply using the View Source tool in your browser on a MetaFilter page reveals source code that’s quite
comprehensible, even human-readable, without going anywhere near any CSS or JavaScript.
As late as the early 2000s I’d occasionally use Lynx for serious browsing, but any time I’ve used it since it’s been by necessity.
Secondly, it’s pretty simple to try browsing MetaFilter without CSS or JavaScript enabled! I tried in two ways: first,
by using Lynx, a text-based browser that’s never supported either of those technologies. I also tried by using
Firefox but with them disabled (honestly, I slightly miss when the Web used to look like this):
It only took me three clicks to disable stylesheets and JavaScript in my copy of Firefox… but I’ll be the first to admit that I don’t keep my browser configured like “normal people”
probably do.
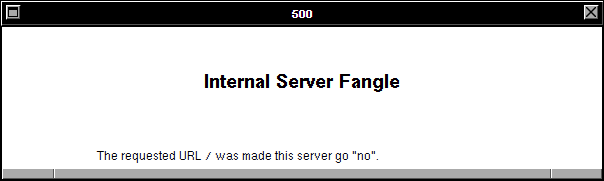
And thirdly: the error code being returned by the simulated WorldWideWeb browser is a HTTP code 500. Even if you don’t
know your HTTP codes (I mean, what kind of weirdo would take the time to memorise them all anyway <ahem>),
it’s worth learning this: the first digit of a HTTP response code tells you what happened:
1xx means “everything’s fine, keep going”;
2xx means “everything’s fine and we’re done”;
3xx means “try over there”;
4xx means “you did something wrong” (the infamous 404, for example, means you asked for a page that doesn’t exist);
5xx means “the server did something wrong”.
Simple! The fact that the error code begins with a 5 strongly implies that the problem isn’t in the (client-side) reimplementation of WorldWideWeb: if this had have been a
CSS/JS problem, I’d expect to see a blank page, scrambled content, “filler”
content, or incomplete content.
So I found myself wondering what the real problem was. This is, of course, where my geek flag becomes most-visible: what we’re talking about, let’s not forget, is a fringe
problem in an incomplete simulation of an ancient computer program that nobody uses. Odds are incredibly good that nobody on Earth cares about this except, right now, for me.
I searched for a “Geek Flag” and didn’t like anything I saw, so I came up with this one based on… well, if you recognise what it’s based on, good for you, you’re certainly allowed to
fly it. If not… well, you can too: there’s no geek-gatekeeping here.
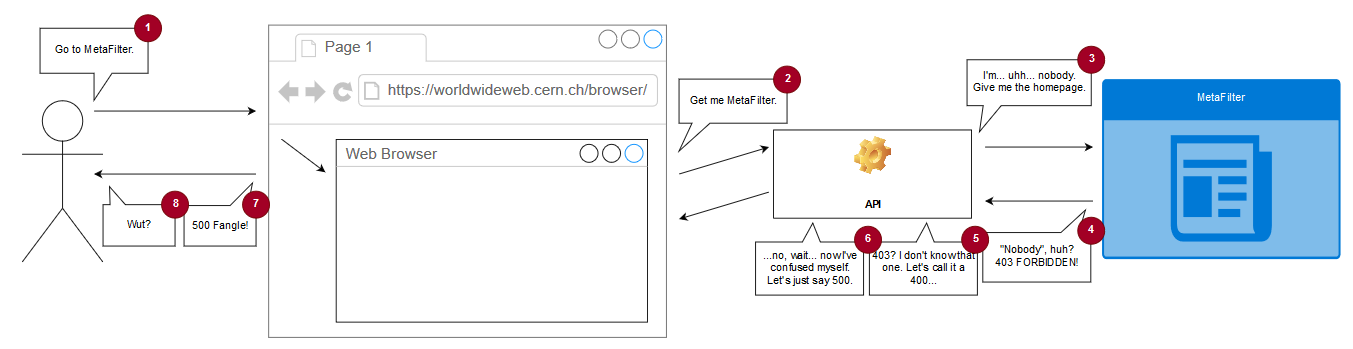
The (simulated) copy of WorldWideWeb is asked to open a document by reference, e.g. “https://www.metafilter.com/”.
To work around same-origin policy restrictions, the request is sent to an API which acts as a proxy server.
The API makes a request using the Node package “request” with this line of code: request(url, (error, response, body) =>
{ ... }). When the first parameter to request is a (string) URL, the module uses its default settings for all of
the other options, which means that it doesn’t set the User-Agent header (an optional part of a Web request where the computer making the request identifies the software
that’s asking).
MetaFilter, for some reason, blocks requests whose User-Agent isn’t set. This is weird! And nonstandard: while web browsers should – in RFC2119 terms – set their User-Agent: header, web servers shouldn’t require
that they do so. MetaFilter returns a 403 and a message to say “Forbidden”; usually a message you only see if you’re trying to access a resource that requires session authentication and
you haven’t logged-in yet.
The API is programmed to handle response codes 200 (okay!) and 404 (not found), but if it gets anything else back
it’s supposed to throw a 400 (bad request). Except there’s a bug: when trying to throw a 400, it requires that an error message has been set by the request module and if there
hasn’t… it instead throws a 500 with the message “Internal Server Fangle” and no clue what actually went wrong. So MetaFilter’s 403 gets translated by the proxy into a 400 which
it fails to render because a 403 doesn’t actually produce an error message and so it gets translated again into the 500 that you eventually see. What a knock-on effect!
If you’re having difficulty visualising the process, this diagram might help you to continue your struggle with that visualisation.
This then sets a User-Agent header and makes servers that require one, such as MetaFilter, respond appropriately. I don’t know whether WorldWideWeb originally set a User-Agent header
(CERN’s source file archive seems to be missing the relevant C sources so I can’t check) but I
suspect that it did, so this change actually improves the fidelity of the emulation as a bonus. A better fix would also add support for and appropriate handling of other HTTP response
codes, but that’s a story for another day, I guess.
I know the hackathon’s over, but I wonder if they’re taking pull requests…
“Ammo can” style cache containers are commonplace in the USA but very rare in the UK. As a result, British cachers coming across them for the first time sometimes report difficulty in
opening or closing the containers or accidentally removing the lid and being unable to reattach it. This video quickly examines an ammo can cache so that you might know your way around
it.
This month, a collection of some of my favourite geeks got invited to CERN in Geneva to
participate in a week-long hackathon with the aim of reimplementing WorldWideWeb –
the first web browser, circa 1990-1994 – as a web application. I’m super jealous, but I’m also really pleased with what they managed
to produce.
This represents a huge leap forward from their last similar project, which aimed to recreate the line mode browser: the first web browser that
didn’t require a NeXT computer to run it and so a leap forward in mainstream appeal. In some ways, you might expect
reimplementing WorldWideWeb to be easier, because its functionality is more-similar that of a modern browser, but there were doubtless some challenges too: this early browser predated the concept of the DOM and so there are distinct
processing differences that must be considered to get a truly authentic experience.
It’s just like any other hackathon, if you ignore the enormous particle collider underneath it.
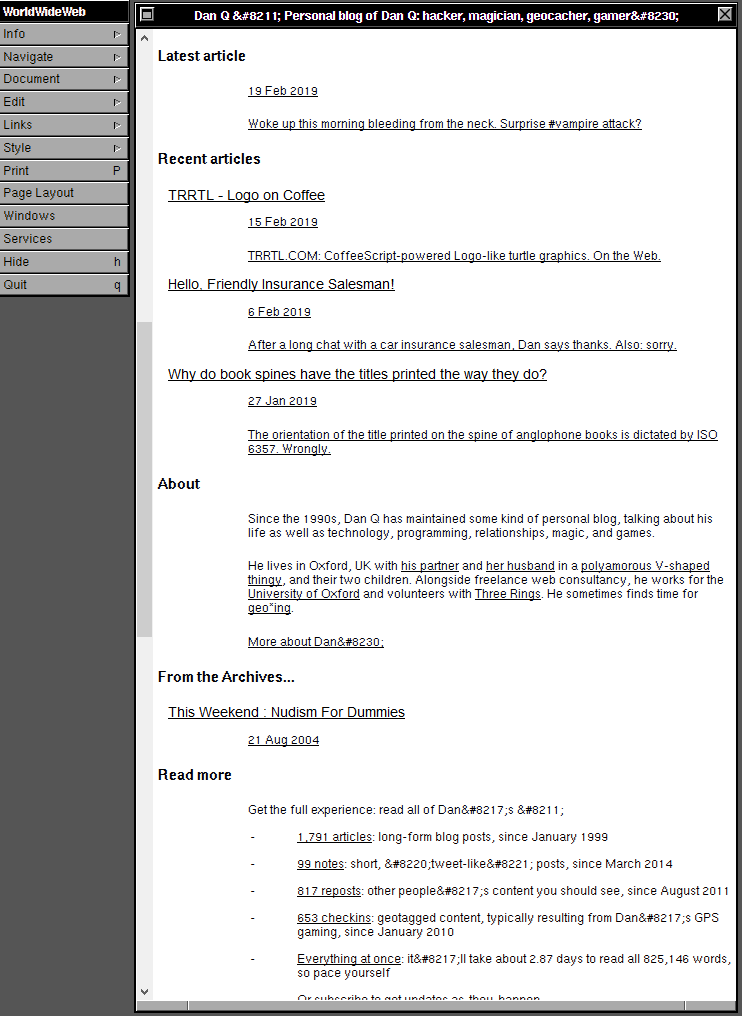
Among their outputs, the team also produced a cool timeline of the Web, which – thanks to some careful authorship – is as legible in WorldWideWeb as it is in a modern browser (if, admittedly, a little less pretty).
When Sir Tim took this screenshot, he could never have predicted the way the Web would change, technically, over the next
25-30 years. But I’m almost more-interested in how it’s stayed the same.
In an age of increasing Single Page Applications and API-driven sites and “apps”, it’s nice to be reminded that if you develop right for the Web, your content will be visible
(sort-of; I’m aware that there are some liberties taken here in memory and processing limitations, protocols and negotiation) on machines 30 years old, and that gives me hope that
adherence to the same solid standards gives us a chance of writing pages today that look just as good in 30 years to come. Compare that to a proprietary technology like Flash whose heyday 15 years ago is overshadowed by its imminent death (not to
mention Java applets or ActiveX <shudders>), iOS apps which stopped working when the operating system went 64-bit, and websites which only work
in specific browsers (traditionally Internet Explorer, though as I’ve complained before we’re getting more and more Chrome-only sites).
The Web is a success story in open standards, natural and by-design progressive enhancement, and the future-proof archivability of human-readable code. Long live the Web.
This is cute: a Google Analytics code snippet that results in a payload about a fiftieth of the size of the one provided by Google but still provides most of the important features.
The meteoric rise of front-end frameworks like React, Angular, Vue.js, Elm, etc. has made single-page applications ubiquitous on the web. For many developers, these have become part
of their ‘default’ toolset. When they start a new project, they grab the tools they know already: a REST API on the backend, and a React/Angular/Vue/Elm frontend.
Is there something wrong with these tools? Absolutely not. In fact, I love working with them. However, I would only choose this architecture when an actual requirement is pushing me
in that direction. If there are no specific reasons to build a single-page application, I will go with a traditional server-rendered architecture every day of the week. It is simpler
and allows you to move faster.
…
There’s been an increasing trend towards delivering web applications as SPAs backed by an API. I can see the attraction: disposing of the browser’s navigation cycle lets you develop that coveted “app-like” interaction experience,
pushing only data around lets you implement multiple clients backed by the same single middleware, and it results in a development workflow that fits tightly with many of the hippest
frameworks (go jamstack, backendless, Node-backed, or whatever). I love REST and all, but I feel that it works
best when it’s used to deliver multiformat results (whether by content negotiation or whatever): web pages for the humans, JSON or whatever for the computers.
For an increasing number of developers, SPAs are a golden hammer.
Let’s fix that.