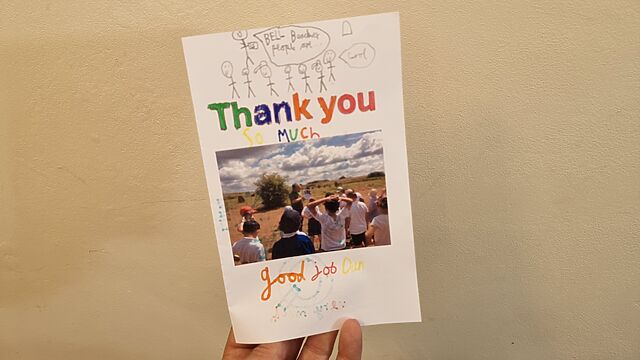on YouTube (also as a “short”, for people who are too lazy to rotate
their phone screen to horizontal and/or don’t have the attention span for more than three minutes of content)
When somebody started repeatedly leaving bottles of urine on top of a utility cabinet in his neighbourhood, filmmaker Derek Milton decided to investigate. During his descent into
insanity as he tries to understand why this person keeps leaving their piss here (and who keeps collecting them, later), somehow sponsored by the Reolink Go PT Ultra range of security
cameras, we see through this entertaining (?) documentary (??) the story of an artist trying to interpret the work of another, more-shy, artist (???).
I don’t know, that’s the best description I can come up with for this weird project. I still don’t know why I watched it from beginning to end. But now you can, too.
or, how to fuck your shit up by ignoring obvious birthday inflammation symptoms. don’t be like me. seek help.
sorry for this barely scripted and low quality video, the next one will be worse.
special thanks to doctor jacobi for the excellent care, and to the manna charitable foundation for the flight logistics.
The ever-excellent Blackle Mori1
posted this about 18 months ago but I don’t think it got the level of attention it deserves. If if you’ve never experienced birthday inflammation or known anybody who has, it’s an
eye-opening experience to hear a first-hand account of this unusual and definitely-real condition.
1 Things that weren’t technically-feasible back when I created the site in 2011 like making the PDF generation happen in the browser, so no personal information ever has to leave
your computer, for example
2 Y’know, those things for people who can’t even be bothered to turn their phone into the
same orientation as virtually every television, cinema screen, and computer monitor that’s ever been made (not that the owners of those larger screens can always turn them to portrait
orientation!). Turns out I have strong feelings about portrait video! But if that’s the way to reach out and help the widest diversity of people, I guess that’s what I’ve got to do…
Today, for the first time ever, I simultaneously published a piece of content across five different media: a Weblog post, a video essay, a podcast episode, a Gemlog post, and a
Spartanlog post.
Must be about something important, right?
Nope, it’s a meandering journey to coming up with a design for a £5 coin that will never exist. Delightfully pointless. Being the Internet I want to see in the world.
Anyway: Acai turns out to be not only a kickass Clone Hero player, but he’s also a fun and charismatic commentator to take along for the ride.
Incidentally, it was fun to see that the same level of attention to detail has been paid to the on-screen lyrics for Clone Hero as were to the subtitles on the video version of the album. For example, they’ll sometimes imply that the next line is what
you’re expecting it to be, based on a familiarity with the song, only to bait-and-switch it out for the actual lyrics at the last second. Genius.
This is the age we’re shifting into: an era in which post-truth politics and deepfake proliferation means that when something looks “a bit off”, we assume (a) it’s AI-generated, and (b)
that this represents a deliberate attempt to mislead. (That’s probably a good defence strategy nowadays in general, but this time around it’s… more-complicated…)
…
So if these fans aren’t AI-generated fakes, what’s going on here?
The video features real performances and real audiences, but I believe they were manipulated on two levels:
Will Smith’s team generated several short AI image-to-video clips from professionally-shot audience photos
YouTube post-processed the resulting Shorts montage, making everything look so much worse
…
I put them side-by-side below. Try going full-screen and pause at any point to see the difference. The Instagram footage is noticeably better throughout, though some of the audience
clips still have issues.
…
The Internet’s gone a bit wild over the YouTube video of Will Smith with a crowd. And if you look at it, you can see why:
it looks very much like it’s AI-generated. And there’d be motive: I mean, we’ve already seen examples where politicians have been accused (falsely, by Trump, obviously) of using AI to exaggerate the size of their crowds, so
it feels believable that a musician’s media team might do the same, right?
But yeah: it turns out that isn’t what happened here. Smith’s team did use AI, but only to make sign-holding fans from other concerts on the same tour appear
to all be in the same place. But the reason the video “looks AI-generated” is because… YouTube fucked about with it!
It turns out that YouTube have been secretly experimenting with upscaling
shorts, using AI to add detail to blurry elements. You can very clearly see the effect in the video above, which puts the Instagram and YouTube versions of the video side-by-side (of
course, if YouTube decide to retroactively upscale this video then the entire demonstration will be broken anyway, but for now it works!). There are many
points where a face in the background is out-of-focus in the Instagram version, but you can see in the YouTube version it’s been brought into focus by adding details. And
some of those details look a bit… uncanny valley.
Every single bit of this story – YouTube’s secret experiments on creator videos, AI “enhancement” which actually makes things objectively worse, and the immediate knee-jerk reaction of
an understandably jaded and hypersceptical Internet to the result – just helps cement that we truly do live in the stupidest timeline.
This was an enjoyable video. Nothing cutting-edge, but a description of an imaginative use of an everyday algorithm – DEFLATE, which
is what powers most of the things you consider “ZIP files” – to do pattern-matching and comparison between two files. The tl;dr is pretty simple:
Lossless compression works by looking for repetition, and replacing the longest/most-repeated content with references to a lookup table.
Therefore, the reduction-in-size from compressing a file is an indicator of the amount of repetition within it.
Therefore, the difference in reduction-in-size of compressing a single file to the reduction-in-size of compressing a pair of files is indicative of
their similarity, because the greatest compression gains come from repetition of data that is shared across both files.
This can be used, for example, to compare the same document written in two languages as an indication of the similarity of the languages to one another, or to compare the genomes of
two organisms as an indication of their genetic similarity (and therefore how closely-related they are).
I love it when somebody finds a clever and novel use for an everyday tool.
It started with a fascination after discovering a little-known stone circle near my new house. It grew into an obsession with the history of the place.
Two years later, our eldest was at school and her class was studying the stone age. Each of three groups were tasked with researching a particular neolithic monument, and our eldest was
surprised when she heard my voice coming from a laptop elsewhere in the class. One of her classmates had, in their research into the Quoits, come across my video.
It turns out “local expert” just means “I read the only book ever written about the archaeology of the stones, and a handful of ancillary things.”
And so this year, when another class – this time featuring our youngest – went on a similar school trip, the school asked me to go along again.
I’d tweaked my intro a bit – to pivot from talking about the archaeology to talking about the human stories in the history of the place – and it went down well: the
children raised excellent observations and intelligent questions1,
and clearly took a lot away from their visit. As a bonus, our visit falling shortly after the summer solstice meant that local neopagans had left a variety of curious offerings – mostly
pebbles painted with runes – that the kids enjoyed finding (though of course I asked them to put each back where they were found afterwards).
But the most heartwarming moment came when I later received an amazing handmade card, to which several members of the class had contributed:
I particularly enjoy the pencil drawing of me talking about the breadth of Bell Beaker culture, with a child
interrupting to say “cool!”.
I don’t know if I’ll be free to help out again in another two years, if they do it again2: perhaps I
should record a longer video, with a classroom focus, that shares everything I know about The Devil’s Quoits.
But I’ll certainly keep a fond memory of this (and the previous) time I got to go on such a fun school trip, and to be an (alleged) expert about a place whose history I find so
interesting!
Footnotes
1 Not every question the children asked was the smartest, but every one was gold.
One asked “is it possible aliens did it?” Another asked, “how old are you?”, which I can only assume was an effort to check if I remembered when this 5,000-year-old hengiform monument
was being constructed…
2 By lucky coincidence, this year’s trip fell during a period that I was between jobs, and
so I was very available, but that might not be the case in future!
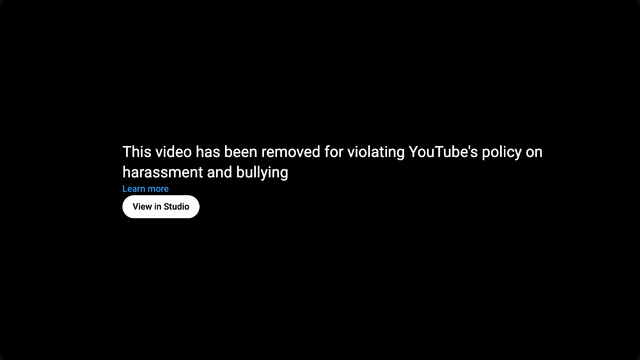
This morning, Google pulled a video from YouTube belonging to my nonprofit Three Rings. This was a bit of a surprise.
Harassment and bullying? Whut?
Apparently the video – which is a demo of some Three Rings features – apparently fell foul of Google’s anti-doxxing rules. I’m glad that they have
anti-doxxing rules, of course.
Let’s see who I doxxed:
Yup… apparently doxxed an imaginary person with two structurally-invalid phone numbers and who’s recently moved house from Some Street to Other Street in the town of Somewhereville. 😂
(Maybe I’m wrong. Do you live on Some Street, Somewhereville?)
Let’s see what YouTube’s appeals process is like, shall we? 🤦
Accessible description: Dan, a white man with a goatee beard and a faded blue ponytail, stands in a darkened kitchen. Turning to the camera, he says “I get up when I want,
except on Wednesdays when I get rudely awakened by the tadpoles.” Then he holds up a book entitled “Pond Life”.
The fundamental difference between streaming and downloading is what your device does with those frames of video:
Does it show them to you once and then throw them away? Or does it re-assemble them all back into a video file and save it into storage?
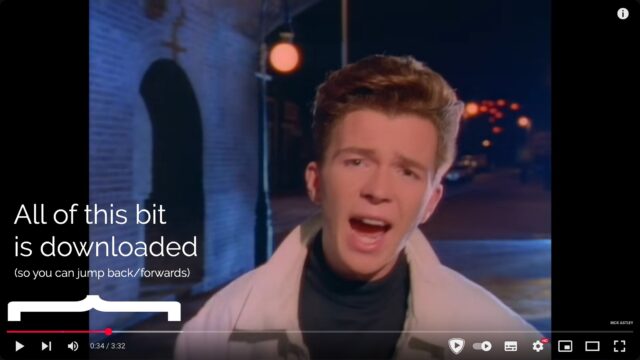
When you’re streaming on YouTube, the video player running on your computer retains a buffer of frames ahead and behind of your current position, so you can skip around easily: the
darker grey part of the timeline shows which parts of the video are stored on – that is, downloaded to – your computer.
Buffering is when your streaming player gets some number of frames “ahead” of where you’re watching, to give you some protection against connection issues. If your WiFi wobbles
for a moment, the buffer protects you from the video stopping completely for a few seconds.
But for buffering to work, your computer has to retain bits of the video. So in a very real sense, all streaming is downloading! The buffer is the part
of the stream that’s downloaded onto your computer right now. The question is: what happens to it next?
All streaming is downloading
So that’s the bottom line: if your computer deletes the frames of video it was storing in the buffer, we call that streaming. If it retains them in a file, we
call that downloading.
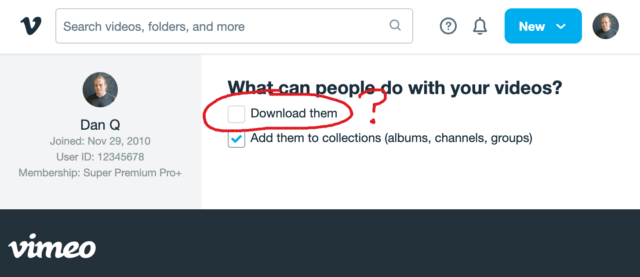
That definition introduces a philosophical problem. Remember that Vimeo checkbox that lets a creator decide whether people can (i.e. are allowed to) download their videos? Isn’t
that somewhat meaningless if all streaming is downloading.
Because if the difference between streaming and downloading is whether their device belonging to the person watching the video deletes the media when they’re done. And in
virtually all cases, that’s done on the honour system.
This kind of conversation happens, over the HTTP protocol, all the time. Probably most of the time the browser is telling the truth, but there’s no way to know for certain.
When your favourite streaming platform says that it’s only possible to stream, and not download, their media… or when they restrict “downloading” as an option to higher-cost paid plans…
they’re relying on the assumption that the user’s device can be trusted to delete the media when the user’s done watching it.
But a user who owns their own device, their own network, their own screen or speakers has many, many opportunities to not fulfil the promise of deleting media it after they’ve consumed
it: to retain a “downloaded” copy for their own enjoyment, including:
Intercepting the media as it passes through their network on the way to its destination device
Using client software that’s been configured to stream-and-save, rather than steam-and-delete, the content
Modifying “secure” software (e.g. an official app) so that it retains a saved copy rather than deleting it
Capturing the stream buffer as it’s cached in device memory or on the device’s hard disk
Outputting the resulting media to a different device, e.g. using a HDMI capture device, and saving it there
Exploiting the “analogue4
hole”5:
using a camera, microphone, etc. to make a copy of what comes out of the screen/speakers6
Okay, so I oversimplified (before you say “well, actually…”)
It’s not entirely true to say that streaming and downloading are identical, even with the caveat of “…from the server’s perspective”. There are three big exceptions worth
thinking about:
Exception #1: downloads can come in any order
When you stream some linear media, you expect the server to send the media in strict chronological order. Being able to start watching before the whole file has
downloaded is a big part of what makes steaming appealing, to the end-user. This means that media intended for streaming tends to be stored in a way that facilitates that
kind of delivery. For example:
Media designed for streaming will often be stored in linear chronological order in the file, which impacts what kinds of compression are available.
Media designed for streaming will generally use formats that put file metadata at the start of the file, so that it gets delivered first.
Video designed for streaming will often have frequent keyframes so that a client that starts “in the middle” can decode the buffer without downloading too much data.
No such limitation exists for files intended for downloading. If you’re not planning on watching a video until it’s completely downloaded, the order in which the chunks arrives is
arbitrary!
But these limitations make the set of “files suitable for streaming” a subset of the set of “files suitable for downloading”. It only makes it challenging or impossible to
stream some media intended for downloading… it doesn’t do anything to prevent downloading of media intended for streaming.
Exception #2: streamed media is more-likely to be transcoded
A server that’s streaming media to a client exists in a sort-of dance: the client keeps the server updated on which “part” of the media it cares about, so the server can jump ahead,
throttle back, pause sending, etc. and the client’s buffer can be kept filled to the optimal level.
This dance also allows for a dynamic change in quality levels. You’ve probably seen this happen: you’re watching a video on YouTube and suddenly the quality “jumps” to something more
(or less) like a pile of LEGO bricks7. That’s the result of your device realising that the rate
at which it’s receiving data isn’t well-matched to the connection speed, and asking the server to send a different quality level8.
The server can – and some do! – pre-generate and store all of the different formats, but some servers will convert files (and particularly livestreams) on-the-fly, introducing
a few seconds’ delay in order to deliver the format that’s best-suited to the recipient9. That’s not necessary for downloads, where the
user will often want the highest-quality version of the media (and if they don’t, they’ll select the quality they want at the outset, before the download begins).
Exception #3: streamed media is more-likely to be encumbered with DRM
And then, of course, there’s DRM.
As streaming digital media has become the default way for many people to consume video and audio content, rights holders have engaged in a fundamentally-doomed10
arms race of implementing copy-protection strategies to attempt to prevent end-users from retaining usable downloaded copies of streamed media.
Take HDCP, for example, which e.g. Netflix use for their 4K streams. To download these streams, your device has to be running some decryption code that only works if it can trace a path
to the screen that it’ll be outputting to that also supports HDCP, and both your device and that screen promise that they’re definitely only going to show it and not make it
possible to save the video. And then that promise is enforced by Digital Content Protection LLC only granting a decryption key and a license to use it to manufacturers.11
The real hackers do stuff with software, but people who just want their screens to work properly in spite of HDCP can just buy boxes like this (which I bought for a couple of quid on
eBay). Obviously you could use something like this and a capture card to allow you to download content that was “protected” to ensure that you could only stream it, I suppose, too.
Anyway, the bottom line is that all streaming is, by definition, downloading, and the only significant difference between what people call “streaming” and
“downloading” is that when “streaming” there’s an expectation that the recipient will delete, and not retain, a copy of the video. And that’s it.
Footnotes
1 This isn’t the question I expected to be answering. I made the animation in this post
for use in a different article, but that one hasn’t come together yet, so I thought I’d write about the technical difference between streaming and downloading as an excuse to
use it already, while it still feels fresh.
2 I’m using the example of a video, but this same principle applies to any linear media
that you might stream: that could be a video on Netflix, a livestream on Twitch, a meeting in Zoom, a song in Spotify, or a radio show in iPlayer, for example: these are all examples
of media streaming… and – as I argue – they’re therefore also all examples of media downloading because streaming and downloading are fundamentally the same thing.
3 There are a few simplifications in the first half of this post: I’ll tackle them later
on. For the time being, when I say sweeping words like “every”, just imagine there’s a little footnote that says, “well, actually…”, which will save you from feeling like you have to
say so in the comments.
4 Per my style guide, I’m using the British English
spelling of “analogue”, rather than the American English “analog” which you’ll often find elsewhere on the Web when talking about the analog hole.
5 The rich history of exploiting the analogue hole spans everything from bootlegging a
1970s Led Zeppelin concert by smuggling recording equipment
in inside a wheelchair (definitely, y’know, to help topple the USSR and not just to listen to at home while you get high)
to “camming” by bribing your friendly local projectionist to let you set up a video camera at the back of the cinema for their test screening of the new blockbuster. Until some
corporation tricks us into installing memory-erasing DRM chips into our brains (hey, there’s a dystopic sci-fi story idea in there somewhere!) the analogue hole will always be
exploitable.
6 One might argue that recreating a piece of art from memory, after the fact, is a
very-specific and unusual exploitation of the analogue hole: the one that allows us to remember (or “download”) information to our brains rather than letting it “stream” right
through. There’s evidence to suggest that people pirated Shakespeare’s plays this way!
7 Of course, if you’re watching The LEGO Movie, what you’re seeing might already
look like a pile of LEGO bricks.
8 There are other ways in which the client and server may negotiate, too: for example,
what encoding formats are supported by your device.
9My NAS does live transcoding when Jellyfin streams to devices on my network, and it’s magical!
10 There’s always the analogue hole, remember! Although in practice this isn’t even
remotely necessary and most video media gets ripped some-other-way by clever pirate types even where it uses highly-sophisticated DRM strategies, and then ultimately it’s only
legitimate users who end up suffering as a result of DRM’s burden. It’s almost as if it’s just, y’know, simply a bad idea in the first place, or something. Who knew?
11 Like all these technologies, HDCP was cracked almost immediately and every
subsequent version that’s seen widespread rollout has similarly been broken by clever hacker types. Legitimate, paying users find themselves disadvantaged when their laptop won’t let
them use their external monitor to watch a movie, while the bad guys make pirated copies that work fine on anything. I don’t think anybody wins, here.
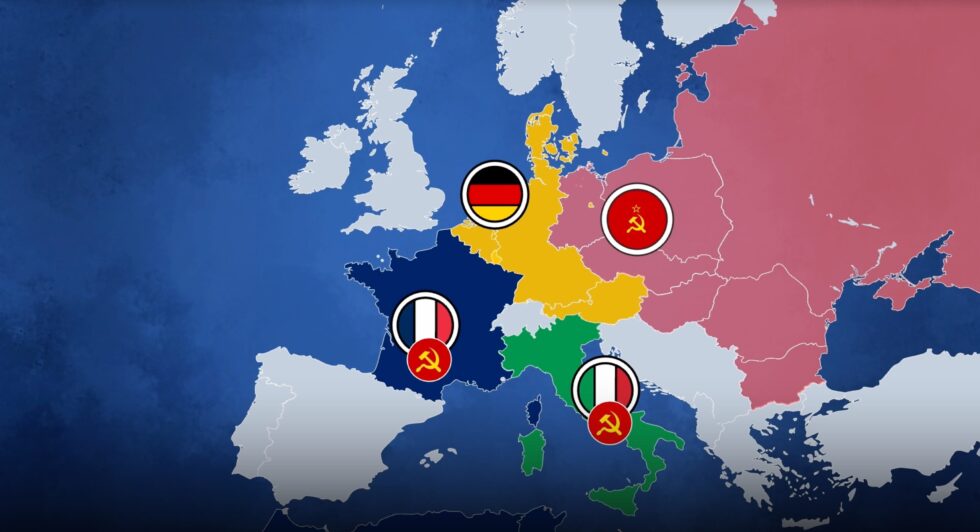
This video, which I saw on Nebula but which is also available on YouTube, explores a hypothetical alternate history in which the Schuman Plan/European Coal & Steel Community never happened, and the knock-on effects lead to no EU, a more fragmented Europe,
and an ultimately more-fractured and more-complicated Europe of the late 20th/early 21st century.
Obviously it’s highly-speculative and you could easily come up with your own alternative alternative history! But the Twilight Struggle player in me as well as the alternate
history lover (and, of course, European Union fan) especially loves the way this story is told.
It’s worth remembering that for the last half-millenium or more, the default state of Europe has been to be fighting one another: if not outright war then at least agressive
economic and political rivals. Post-WWII gave Europe perhaps its longest ever period of relative peace, and that’s great enough that all of the other benefits of a harmonised
and cooperative union are just icing on the cake.
EU Made Simple is a fantastic channel in general, and I’d recommend you give it a look. It ties news and history in with its creators
outlook, but it’s always clear which bits are opinion and it’s delightfully bitesized. For Europeans-in-exile in this post-Brexit age, it’s hopeful and happy, and I like it.
The video below is presented in portrait orientation, because your screen is taller than it is wide.
The video below is presented in landscape orientation, because your screen is wider than it is tall.
The video below is presented in square orientation (the Secret Bonus Square Video!), because your screen has approximately the same width as as its height. Cool!
This is possible (with a single <video> element, and without any Javascript!) thanks to some cool HTML features you might not be aware of, which I’ll briefly explain
in the video. Or scroll down for the full details.
<videocontrols><sourcesrc="squareish.mp4"media="(min-aspect-ratio: 0.95) and (max-aspect-ratio: 1.05)"/><sourcesrc="portrait.mp4"media="(orientation: portrait)"/><sourcesrc="landscape.mp4"/></video>
This code creates a video with three sources: squareish.mp4 which is shown to people on “squareish” viewports, failing that portrait.mp4 which is shown to
people whose viewports are taller than wide, and failing that landscape.mp4 which is shown to anybody else.
That’s broadly-speaking how the video above is rendered. No JavaScript needed.
Browsers only handle media queries on videos when they initially load, so you can’t just tip your phone over or resize the window: you’ll need to reload the page, too. But it works!
Give it a go: take a look at the video in both portrait and landscape modes and let me know what you think1.
Adding adaptive bitrate streaming with HLS
Here’s another cool technology that you might not have realised you could “just use”: adaptive bitrate streaming with HLS!
You’ve used adaptive bitrate streaming before, though you might not have noticed it. It’s what YouTube, Netflix, etc. are doing when your network connection degrades and you quickly get
dropped-down, mid-video, to a lower-resolution version2.
Turns out you can do it on your own static hosting, no problem at all. I used this guide (which has a great
description of the parameters used) to help me:
This command splits the H.264 video landscape.mp4 into three different resolutions: the original “v1” (1920×1080, in my case, with 96kbit audio), “v2” (1280×720, with
96kbit audio), and “v3” (640×360, with 48kbit audio), each with a resolution-appropriate maximum bitrate, and forced keyframes every 48th frame. Then it breaks each of those into HLS
segments (.ts files) and references them from a .m3u8 playlist.
The output from this includes:
Master playlist landscape.m3u8, which references the other playlists with reference to their resolution and bandwidth, so that browsers can make smart choices,
Playlists landscape_0.m3u8 (“v1”), landscape_1.m3u8 (“v2”), etc., each of which references the “parts” of that video,
Directories landscape_0/, landscape_1/ etc., each of which contain
data00.ts, data01.ts, etc.: the actual “chunks” that contain the video segments, which can be downloaded independently by the browser as-needed
Bringing it all together
We can bring all of that together, then, to produce a variable-aspect, adaptive bitrate, HLS-streamed video player… in pure HTML and suitable for static hosting:
<videocontrols><sourcesrc="squareish.m3u8"type="application/x-mpegURL"media="(min-aspect-ratio: 0.95) and (max-aspect-ratio: 1.05)"/><sourcesrc="portrait.m3u8"type="application/x-mpegURL"media="(orientation: portrait)"/><sourcesrc="landscape.m3u8"type="application/x-mpegURL"/></video>
You could, I suppose, add alternate types, poster images, and all kinds of other fancy stuff, but this’ll do for now.
One solution is to also provide the standard .mp4 files as an alternate <source>, and that’s fine I guess, but you lose the benefit of HLS (and
you have to store yet more files). But there’s a workaround:
Polyfill full functionality for all browsers
If you’re willing to use a JavaScript polyfill, you can make the code above work on virtually any device. I gave this a go, here, by:
Adding some JavaScript code that detects affected `<video>` elements and applying the fix if necessary:
// Find all <video>s which have HLS sources:for( hlsVideo of document.querySelectorAll('video:has(source[type="application/x-mpegurl"]), video:has(source[type="vnd.apple.mpegurl"])') ) {
// If the browser has native support, do nothing:if( hlsVideo.canPlayType('application/x-mpegurl') || hlsVideo.canPlayType('application/vnd.apple.mpegurl') ) continue;
// If hls.js can't help fix that, do nothing:if ( ! Hls.isSupported() ) continue;
// Find the best source based on which is the first one to match any applicable CSS media queriesconst bestSource =Array.from(hlsVideo.querySelectorAll('source')).find(source=>window.matchMedia(source.media).matches)
// Use hls.js to attach the best source:const hls =new Hls();
hls.loadSource(bestSource.src);
hls.attachMedia(hlsVideo);
}
It makes me feel a little dirty to make a <video>depend on JavaScript, but if that’s the route you want to go down while we wait for HLS support to become
more widespread (rather than adding different-typed sources) then that’s fine, I guess.
This was a fun dive into some technologies I’ve not had the chance to try before. A fringe benefit of being a generalist full-stack developer is that when you’re “between jobs”
you get to play with all the cool things when you’re brushing up your skills before your next big challenge!
(Incidentally: if you think you might be looking to employ somebody like me, my CV is over there!)
Footnotes
1 There definitely isn’t a super-secret “square” video on this page, though. No
siree. (Shh.)
2 You can tell when you get dropped to a lower-resolution version of a video because
suddenly everybody looks like they’re a refugee from Legoland.