
Remember Winamp (especially Winamp 1/2, back when it was awesome)? Remember Winamp skins?
Webamp does.
This is not only a gallery of skins, they’re all interactive! Click into one and try it out. It really whips the llama’s ass.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Remember Winamp (especially Winamp 1/2, back when it was awesome)? Remember Winamp skins?
Webamp does.
This is not only a gallery of skins, they’re all interactive! Click into one and try it out. It really whips the llama’s ass.
Needed new UPS batteries.
Almost bought from @insight_uk but they require registration to checkout.
Purchased from @SourceUPSLtd instead.
Moral: having no “guest checkout” costs you business.
This last month or so, my digital life has been dramatically improved by Syncthing. So much so that I want to tell you about it.
I started using it last month. Basically, what it does is keeps a pair of directories on remote systems “in sync” with one another. So far, it’s like your favourite cloud storage service, albeit self-hosted and much-more customisable. But it’s got a handful of killer features that make it nothing short of a dream to work with:
Here are some of the ways I’m using it:
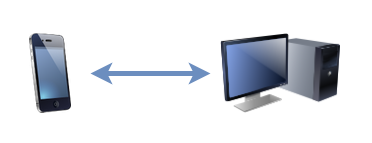
I’ve tried a lot of different solutions for this over the years. Back in the way-back-when, like everybody else in those dark times, I used to plug my phone in using a cable to copy pictures off and sort them. Since then, I’ve tried cloud solutions from Google, Amazon, and Flickr and never found any that really “worked” for me. Their web interfaces and apps tend to be equally terrible for organising or downloading files, and I’m rarely able to simply drag-and-drop images from them into a blog post like I can from Explorer/Finder/etc.
At first, I set this up as a one-way sync, “pushing” photos and videos from my phone to my desktop PC whenever I was on an unmetered WiFi network. But then I switched it to a two-way sync, enabling me to more-easily tidy up my phone of old photos too, by just dragging them from the folder that’s synced with my phone to my regular picture storage.
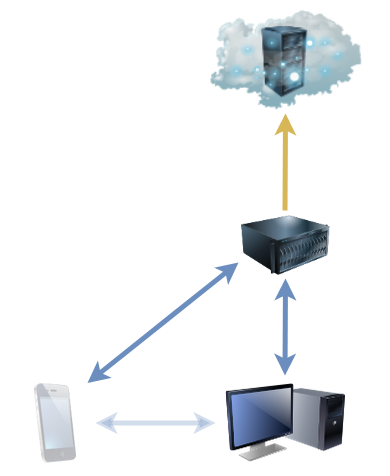
Now I’ve got a fancy NAS device with tonnes of storage, it makes sense to use it as a central point for backups to run fom. Instead of having many separate backup processes running on different computers, I can just have each of them sync to the NAS, and the NAS can back everything up. Computers don’t need to be “on” at a particular time because the NAS runs all the time, so backups can use the Internet connection when it’s quietest. And in the event of a hardware failure, there’s an up-to-date on-site backup in the first instance: the cloud backup’s only needed in the event of accidental data deletion (which could be sync’ed already, of course!). Plus, integrating the sync with ownCloud running on the NAS gives easy access to my files wherever in the world I am without having to fire up a VPN or otherwise remote-in to my house.
Plus: because Syncthing can share a folder between any number of devices, the same sharing mechanism that puts my phone’s photos onto my main desktop can simultaneously be pushing them to the NAS, providing redundant connections. And it was a doddle to set up.
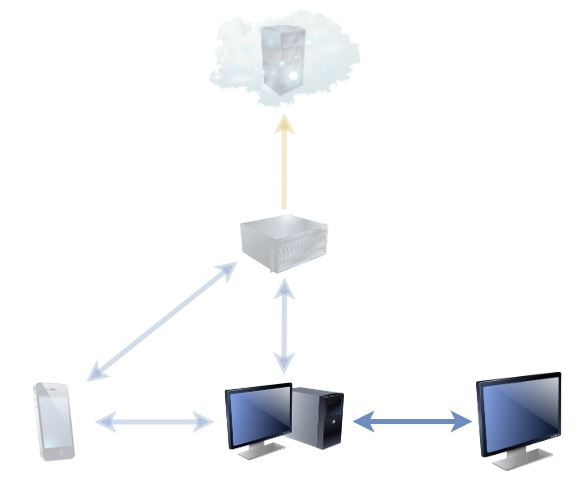
Since the NAS, running Jellyfin, took on most of the media management jobs previously shared between desktop computers and the media centre computer, the household media centre’s had less to do. But one thing that it does, and that gets neglected, is showing a screensaver of family photos (when it’s not being used for anything else). Historically, we’ve maintained the photos in that collection via a shared network folder, but then you’ve got credential management and firewall issues to deal with, not to mention different file naming conventions by different people (and their devices).
But simply sharing the screensaver’s photo folder with the computer of anybody who wants to contribute photos means that it’s as easy as copying the picture to a particular place. It works on whatever device they care to (computer, tablet, mobile) on any operating system, and it’s quick and seamless. I’m just using it myself, for now, but I’ll be offering it to the rest of the family soon. It’s a trivial use-case, but once you’ve got it installed it just makes sense.
In short: this month, I’m in love with Syncthing. And maybe you should be, too.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
As we’ve mentioned in previous blog posts, the $FAMOUS_COMPANY backend has historically been developed in $UNREMARKABLE_LANGUAGE and architected on top of $PRACTICAL_OPEN_SOURCE_FRAMEWORK. To suit our unique needs, we designed and open-sourced $AN_ENGINEER_TOOK_A_MYTHOLOGY_CLASS, a highly-available, just-in-time compiler for $UNREMARKABLE_LANGUAGE.
…
Saagar Jha tells the now-familiar story of how a bunch of techbros solved their scaling problems by reinventing the wheel. And then, when that didn’t work out, moved the goalposts of success. It’s a story as old as time; or at least as old as the modern Web.
(Should’a strangled the code. Or better yet, just refactored what they had.)
Normally this kind of thing would go into the ballooning dump of “things I’ve enjoyed on the Internet” that is my reposts archive. But sometimes something is so perfect that you have to try to help it see the widest audience it can, right? And today, that thing is: Mackerelmedia Fish.

What is Mackerelmedia Fish? I’ve had a thorough and pretty complete experience of it, now, and I’m still not sure. It’s one or more (or none) of these, for sure, maybe:
Rock Paper Shotgun’s article about it opens with “I don’t know where to begin with this—literally, figuratively, existentially?” That sounds about right.

What I can tell you with confident is what playing feels like. And what it feels like is the moment when you’ve gotten bored waiting for page 20 of Argon Zark to finish appear so you decide to reread your already-downloaded copy of the 1997 a.r.k bestof book, and for a moment you think to yourself: “Whoah; this must be what living in the future feels like!”
Because back then you didn’t yet have any concept that “living in the future” will involve scavenging for toilet paper while complaining that you can’t stream your favourite shows in 4K on your pocket-sized supercomputer until the weekend.
Mackerelmedia Fish is a mess of half-baked puns, retro graphics, outdated browsing paradigms and broken links. And that’s just part of what makes it great.
It’s also “a short story that’s about the loss of digital history”, its creator Nathalie Lawhead says. If that was her goal, I think she managed it admirably.
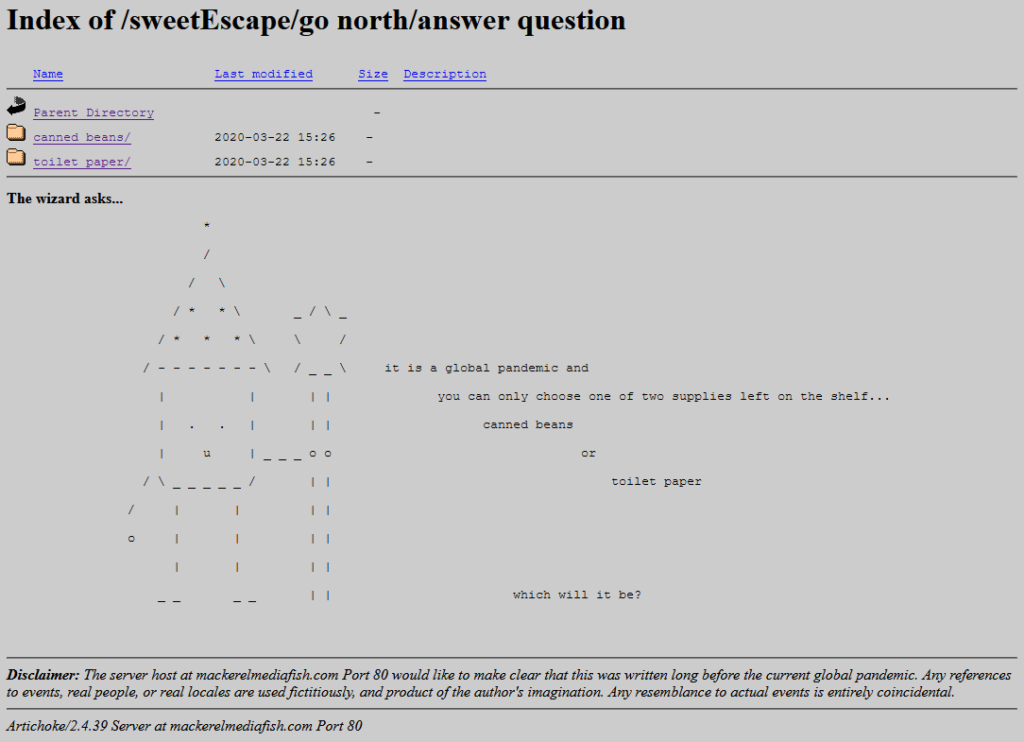
If I wasn’t already in love with the game already I would have been when I got to the bit where you navigate through the directory indexes of a series of deepening folders, choose-your-own-adventure style. Nathalie writes, of it:
One thing that I think is also unique about it is using an open directory as a choose your own adventure. The directories are branching. You explore them, and there’s text at the bottom (an htaccess header) that describes the folder you’re in, treating each directory as a landscape. You interact with the files that are in each of these folders, and uncover the story that way.
Back in the naughties I experimented with making choose-your-own-adventure games in exactly this way. I was experimenting with different media by which this kind of branching-choice game could be presented. I envisaged a project in which I’d showcase the same (or a set of related) stories through different approaches. One was “print” (or at least “printable”): came up with a Twee1-to-PDF converter to make “printable” gamebooks. A second was Web hypertext. A third – and this is the one which was most-similar to what Nathalie has now so expertly made real – was FTP! My thinking was that this would be an adventure game that could be played in a browser or even from the command line on any (then-contemporary: FTP clients aren’t so commonplace nowadays) computer. And then, like so many of my projects, the half-made version got put aside “for later” and forgotten about. My solution involved abusing the FTP protocol terribly, but it worked.
(I also looked into ways to make Gopher-powered hypertext fiction and toyed with the idea of using YouTube annotations to make an interactive story web [subsequently done amazingly by Wheezy Waiter, though the death of YouTube annotations in 2017 killed it]. And I’ve still got a prototype I’d like to get back to, someday, of a text-based adventure played entirely through your web browser’s debug console…! But time is not my friend… Maybe I ought to collaborate with somebody else to keep me on-course.)

In any case: Mackerelmedia Fish is fun, weird, nostalgic, inspiring, and surreal, and you should give it a go. You’ll need to be on a Windows or OS X computer to get everything you can out of it, but there’s nothing to stop you starting out on your mobile, I imagine.
Sso long as you’re capable of at least 800 × 600 at 256 colours and have 4MB of RAM, if you know what I mean.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
Sometimes, code is risky to change and expensive to refactor.
In such a situation, a seemingly good idea would be to rewrite it.
From scratch.
Here’s how it goes:
- You discuss with management about the strategy of stopping new features for some time, while you rewrite the existing app.
- You estimate the rewrite will take 6 months to cover what the existing app does.
- A few months in, a nasty bug is discovered and ABSOLUTELY needs to be fixed in the old code. So you patch the old code and the new one too.
- A few months later, a new feature has been sold to the client. It HAS TO BE implemented in the old code—the new version is not ready yet! You need to go back to the old code but also add a TODO to implement this in the new version.
- After 5 months, you realize the project will be late. The old app was doing way more things than expected. You start hustling more.
- After 7 months, you start testing the new version. QA raises up a lot of things that should be fixed.
- After 9 months, the business can’t stand “not developing features” anymore. Leadership is not happy with the situation, you are tired. You start making changes to the old, painful code while trying to keep up with the rewrite.
- Eventually, you end up with the 2 systems in production. The long-term goal is to get rid of the old one, but the new one is not ready yet. Every feature needs to be implemented twice.
Sounds fictional? Or familiar?
Don’t be shamed, it’s a very common mistake.
…
I’ve rewritten legacy systems from scratch before. Sometimes it’s all worked out, and sometimes it hasn’t, but either way: it’s always been a lot more work than I could have possibly estimated. I’ve learned now to try to avoid doing so: at least, to avoid replacing a single monolithic (living) system in a monolithic way. Nicholas gives an even-better description of the true horror of legacy reimplementation, and promotes progressive strangulation as a candidate solution.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
A new email-based extortion scheme apparently is making the rounds, targeting Web site owners serving banner ads through Google’s AdSense program. In this scam, the fraudsters demand bitcoin in exchange for a promise not to flood the publisher’s ads with so much bot and junk traffic that Google’s automated anti-fraud systems suspend the user’s AdSense account for suspicious traffic.
…
The shape of our digital world grows increasingly strange. As anti-DoS techniques grow better and more and more uptime-critical websites hide behind edge caches, zombie network operators remain one step ahead and find new and imaginative ways to extort money from their victims. In this new attack, the criminal demands payment (in cryptocurrency) under threat that, if it’s not delivered, they’ll unleash an army of bots to act like the victim trying to scam their advertising network, thereby getting the victim’s site demonetised.
This weekend, my sister Sarah challenged me to define the difference between Virtual Reality and Augmented Reality. And the more I talked about the differences between them, the more I realised that I don’t have a concrete definition, and I don’t think that anybody else does either.

After all: from a technical perspective, any fully-immersive AR system – for example a hypothetical future version of the Microsoft Hololens that solves the current edition’s FOV problems – exists in a theoretical superset of any current-generation VR system. That AR augments the reality you can genuinely see, rather than replacing it entirely, becomes irrelevant if that AR system could superimpose a virtual environment covering your entire view. So the argument that compared to VR, AR only covers part of your vision is not a reliable definition of the difference.

This isn’t a new conundrum. Way back in 1994 back when the Sega VR-1 was our idea of cutting edge, Milgram et al. developed a series of metaphorical spectra to describe the relationship between different kinds of “mixed reality” systems. The core difference, they argue, is whether or not the computer-generated content represents a “world” in itself (VR) is just an “overlay” (AR).
But that’s unsatisfying for the same reason as above. The HTC Vive headset can be configured to use its front-facing camera(s) to fade seamlessly from the game world to the real world as the player gets close to the boundaries of their play space. This is a safety feature, but it doesn’t have to be: there’s no reason that a HTC Vive couldn’t be adapted to function as what Milgram would describe as a “class 4” device, which is functionally the same as a headset-mounted AR device. So what’s the difference?
You might argue that the difference between AR and VR is content-based: that is, it’s the thing that you’re expected to focus on that dictates which is which. If you’re expected to look at the “real world”, it’s an augmentation, and if not then it’s a virtualisation. But that approach fails to describe Google’s tech demo of putting artefacts in your living room via augmented reality (which I’ve written about before), because your focus is expected to be on the artefact rather than the “real world” around it. The real world only exists to help with the interpretation of scale: it’s not what the experience is about and your countertop is as valid a real world target as the Louvre: Google doesn’t care.
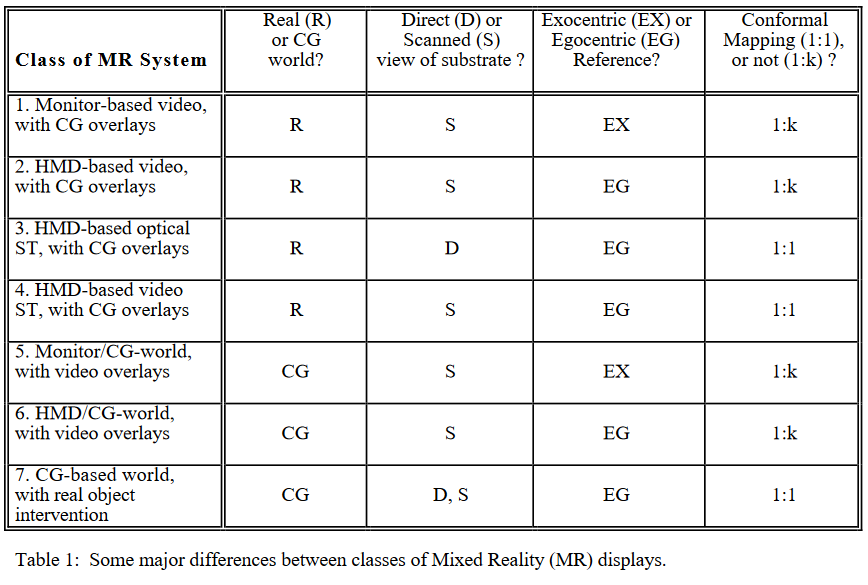
Many researchers echo Milgram’s idea that what turns AR into VR is when the computer-generated content completely covers your vision.
But even if we accept this explanation, the definition gets muddied by the wider field of “extended reality” (XR). Originally an umbrella term to cover both AR and VR (and “MR“, if you believe that’s a separate and independent thing), XR gets used to describe interactive experiences that cover other senses, too. If I play a VR game with real-world “props” that I can pick up and move around, but that appear differently in my vision, am I not “augmenting” reality? Is my experience, therefore, more or less “VR” than if the interactive objects exist only on my screen? What about if – as in a recent VR escape room I attended – the experience is enhanced by fans to simulate the movement of air around you? What about smell? (You know already that somebody’s working on bridging virtual reality with Smell-O-Vision.)

Increasingly, then, I’m beginning to feel that XR itself is a spectrum, and a pretty woolly one. Just as it’s hard to specify in a concrete way where the boundary exists between being asleep and being awake, it’s hard to mark where “our” reality gives way to the virtual and vice-versa.
It’s based upon the addition of information to our senses, by a computer, and there can be more (as in fully-immersive VR) or less (as in the subtle application of AR) of it… but the edges are very fuzzy. I guess that the spectrum of the visual experience of XR might look a little like this:

Honestly, I don’t know any more. But I don’t think my sister does either.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
I don’t care whether anything materially bad will or won’t happen as a consequence of Wacom taking this data from me. I simply resent the fact that they’re doing it.
The second is that we can also come up with scenarios that involve real harms. Maybe the very existence of a program is secret or sensitive information. What if a Wacom employee suddenly starts seeing entries spring up for “Half Life 3 Test Build”? Obviously I don’t care about the secrecy of Valve’s new games, but I assume that Valve does.
We can get more subtle. I personally use Google Analytics to track visitors to my website. I do feel bad about this, but I’ve got to get my self-esteem from somewhere. Google Analytics has a “User Explorer” tool, in which you can zoom in on the activity of a specific user. Suppose that someone at Wacom “fingerprints” a target person that they knew in real life by seeing that this person uses a very particular combination of applications. The Wacom employee then uses this fingerprint to find the person in the “User Explorer” tool. Finally the Wacom employee sees that their target also uses “LivingWith: Cancer Support”.
Remember, this information is coming from a device that is essentially a mouse.
…
Interesting deep-dive investigation into the (immoral, grey-area illegal) data mining being done by Wacom when you install the drivers for their tablets. Horrifying, but you’ve got to remember that Wacom are unlikely to be a unique case. I had a falling out with Razer the other year when they started bundling spyware into the drivers for their keyboards and locking-out existing and new customers from advanced features unless they consented to data harvesting.
I’m becoming increasingly concerned by the normalisation of surveillance capitalism: between modern peripherals and the Internet of Things, we’re “willingly” surrendering more of our personal lives than ever before. If you haven’t seen it, I’d also thoroughly recommend Data, the latest video from Philosophy Tube (of which I’ve sung the praises before).
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
Back in 2016, I made an iMessage app called Overreactions. Actually, the term “app” is probably generous: It’s a collection of static and animated silly faces you can goof around with in iMessage. Its “development” involved many PNGs but zero lines of code.
Just before the 2019 holidays, I received an email from Apple notifying me that the app “does not follow one or more of the App Store Review Guidelines.” I signed in to Apple’s Resource Center, where it elaborated that the app had gone too long without an update. There were no greater specifics, no broken rules or deprecated dependencies, they just wanted some sort of update to prove that it was still being maintained or they’d pull the app from the store in December.
Here’s what it took to keep that project up and running…
…
There’s always a fresh argument about Web vs. native (alongside all the rehashed ones, of course). But here’s one you might not have heard before: nobody ever wrote a Web page that met all the open standards only to be told that they had to re-compile it a few years later for no reason other than that the browser manufacturers wanted to check that the author was still alive.
But that’s basically what happened here. The author of an app which had been (and still did) work fine was required to re-install the development environment and toolchain, recompile, and re-submit a functionally-identical version of their app (which every user of the app then had to re-download along with their other updates)… just because Apple think that an app shouldn’t ever go more than 3 years between updates.
Last week I built Fox, the newest addition to our home network. Fox, whose specification called for not one, not two, not three but four 12 terabyte hard disk drives was built principally as a souped-up NAS device – a central place for us all to safely hold and control access to important files rather than having them spread across our various devices – but she’s got a lot more going on that that, too.

Fox has:
The last time I filmed myself building a PC was when I built Cosmo, a couple of desktops ago. He turned out to be a bit of a nightmare: he was my first fully-watercooled computer and he leaked everywhere: by the time I’d done all the fixing and re-fixing to make him behave nicely, I wasn’t happy with the video footage and I never uploaded it. I’d been wary, almost-superstitious, about filming a build since then, but I shot a timelapse of Fox’s construction and it turned out pretty well: you can watch it below or on YouTube or QTube.
The timelapse slows to real-time, about a minute in, to illustrate a point about the component test I did with only a CPU (and cooler), PSU, and RAM attached. Something I routinely do when building computers but which I only recently discovered isn’t commonly practised is shown: that the easiest way to power on a computer without attaching a power switch is just to bridge the power switch pins using your screwdriver!
Fox is running Unraid, an operating system basically designed for exactly these kinds of purposes. I’ve been super-impressed by the ease-of-use and versatility of Unraid and I’d recommend it if you’ve got a similar NAS project in your future! I’d also like to sing the praises of the Fractal Design Node 804 case: it’s not got quite as many bells-and-whistles as some cases, but its dual-chamber design is spot-on for a multipurpose NAS, giving ample room for both full-sized expansion cards and heatsinks and lots of hard drives in a relatively compact space.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly diverged from its original/technical one. Read more evolving words…
Few words have seen such mutation of meaning over their lifetimes as the word “silly”. The earliest references, found in Old English, Proto-Germanic, and Old Norse and presumably having an original root even earlier, meant “happy”. By the end of the 12th century it meant “pious”; by the end of the 13th, “pitiable” or “weak”; only by the late 16th coming to mean “foolish”; its evolution continues in the present day.

But there’s little so silly as the media-driven evolution of the word “hacker” into something that’s at least a little offensive those of us who probably would be described as hackers. Let’s take a look.
Computer criminal with access to either knowledge or tools which are (or should be) illegal.
Expert, creative computer programmer; often politically inclined towards information transparency, egalitarianism, anti-authoritarianism, anarchy, and/or decentralisation of power.
The earliest recorded uses of the word “hack” had a meaning that is unchanged to this day: to chop or cut, as you might describe hacking down an unruly bramble. There are clear links between this and the contemporary definition, “to plod away at a repetitive task”. However, it’s less certain how the word came to be associated with the meaning it would come to take on in the computer labs of 1960s university campuses (the earliest references seem to come from around April 1955).
There, the word hacker came to describe computer experts who were developing a culture of:
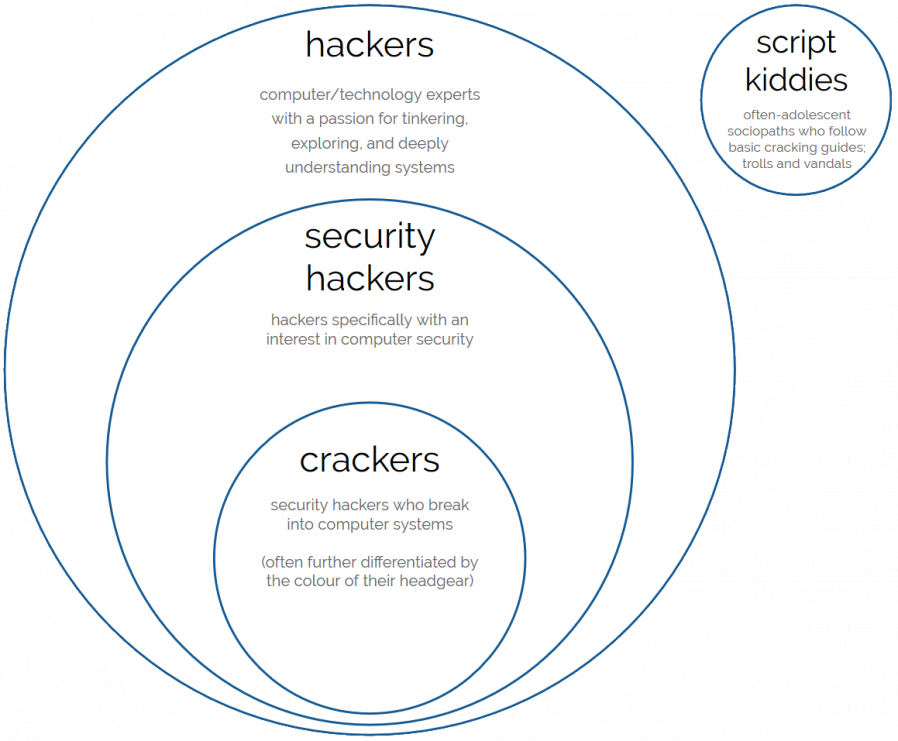
It is absolutely possible for hacking, then, to involve no lawbreaking whatsoever. Plenty of hacking involves writing (and sharing) code, reverse-engineering technology and systems you own or to which you have legitimate access, and pushing the boundaries of what’s possible in terms of software, art, and human-computer interaction. Even among hackers with a specific interest in computer security, there’s plenty of scope for the legal pursuit of their interests: penetration testing, security research, defensive security, auditing, vulnerability assessment, developer education… (I didn’t say cyberwarfare because 90% of its application is of questionable legality, but it is of course a big growth area.)
So what changed? Hackers got famous, and not for the best reasons. A big tipping point came in the early 1980s when hacking group The 414s broke into a number of high-profile computer systems, mostly by using the default password which had never been changed. The six teenagers responsible were arrested by the FBI but few were charged, and those that were were charged only with minor offences. This was at least in part because there weren’t yet solid laws under which to prosecute them but also because they were cooperative, apologetic, and for the most part hadn’t caused any real harm. Mostly they’d just been curious about what they could get access to, and were interested in exploring the systems to which they’d logged-in, and seeing how long they could remain there undetected. These remain common motivations for many hackers to this day.

News media though – after being excited by “hacker” ideas introduced by WarGames – rightly realised that a hacker with the same elementary resources as these teens but with malicious intent could cause significant real-world damage. Bruce Schneier argued last year that the danger of this may be higher today than ever before. The press ran news stories strongly associating the word “hacker” specifically with the focus on the illegal activities in which some hackers engage. The release of Neuromancer the following year, coupled with an increasing awareness of and organisation by hacker groups and a number of arrests on both sides of the Atlantic only fuelled things further. By the end of the decade it was essentially impossible for a layperson to see the word “hacker” in anything other than a negative light. Counter-arguments like The Conscience of a Hacker (Hacker’s Manifesto) didn’t reach remotely the same audiences: and even if they had, the points they made remain hard to sympathise with for those outside of hacker communities.
A lack of understanding about what hackers did and what motivated them made them seem mysterious and otherworldly. People came to make the same assumptions about hackers that they do about magicians – that their abilities are the result of being privy to tightly-guarded knowledge rather than years of practice – and this elevated them to a mythical level of threat. By the time that Kevin Mitnick was jailed in the mid-1990s, prosecutors were able to successfully persuade a judge that this “most dangerous hacker in the world” must be kept in solitary confinement and with no access to telephones to ensure that he couldn’t, for example, “start a nuclear war by whistling into a pay phone”. Yes, really.

Every decade’s hackers have debated whether or not the next decade’s have correctly interpreted their idea of “hacker ethics”. For me, Steven Levy’s tenets encompass them best:
- Access to computers – and anything which might teach you something about the way the world works – should be unlimited and total.
- All information should be free.
- Mistrust authority – promote decentralization.
- Hackers should be judged by their hacking, not bogus criteria such as degrees, age, race, or position.
- You can create art and beauty on a computer.
- Computers can change your life for the better.
Given these concepts as representative of hacker ethics, I’m convinced that hacking remains alive and well today. Hackers continue to be responsible for many of the coolest and most-important innovations in computing, and are likely to continue to do so. Unlike many other sciences, where progress over the ages has gradually pushed innovators away from backrooms and garages and into labs to take advantage of increasingly-precise generations of equipment, the tools of computer science are increasingly available to individuals. More than ever before, bedroom-based hackers are able to get started on their journey with nothing more than a basic laptop or desktop computer and a stack of freely-available open-source software and documentation. That progress may be threatened by the growth in popularity of easy-to-use (but highly locked-down) tablets and smartphones, but the barrier to entry is still low enough that most people can pass it, and the new generation of ultra-lightweight computers like the Raspberry Pi are doing their part to inspire the next generation of hackers, too.
That said, and as much as I personally love and identify with the term “hacker”, the hacker community has never been less in-need of this overarching label. The diverse variety of types of technologist nowadays coupled with the infiltration of pop culture by geek culture has inevitably diluted only to be replaced with a multitude of others each describing a narrow but understandable part of the hacker mindset. You can describe yourself today as a coder, gamer, maker, biohacker, upcycler, cracker, blogger, reverse-engineer, social engineer, unconferencer, or one of dozens of other terms that more-specifically ties you to your community. You’ll be understood and you’ll be elegantly sidestepping the implications of criminality associated with the word “hacker”.
The original meaning of “hacker” has also been soiled from within its community: its biggest and perhaps most-famous advocate‘s insistence upon linguistic prescriptivism came under fire just this year after he pushed for a dogmatic interpretation of the term “sexual assault” in spite of a victim’s experience. This seems to be absolutely representative of his general attitudes towards sex, consent, women, and appropriate professional relationships. Perhaps distancing ourselves from the old definition of the word “hacker” can go hand-in-hand with distancing ourselves from some of the toxicity in the field of computer science?
(I’m aware that I linked at the top of this blog post to the venerable but also-problematic Eric S. Raymond; if anybody can suggest an equivalent resource by another author I’d love to swap out the link.)
Verdict: The word “hacker” has become so broad in scope that we’ll never be able to rein it back in. It’s tainted by its associations with both criminality, on one side, and unpleasant individuals on the other, and it’s time to accept that the popular contemporary meaning has won. Let’s find new words to define ourselves, instead.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly diverged from its original/technical one. Read more evolving words…
The language we use is always changing, like how the word “cute” was originally a truncation of the word “acute”, which you’d use to describe somebody who was sharp-witted, as in “don’t get cute with me”. Nowadays, we use it when describing adorable things, like the subject of this GIF:
![[Animated GIF] Puppy flumps onto a human.](https://bcdn.danq.me/_q23u/2019/09/cute-puppy.gif)
File format (or the files themselves) designed for animations and transparency. Or: any animation without sound.
File format designed for efficient colour images. Animation was secondary; transparency was an afterthought.
Back in the 1980s cyberspace was in its infancy. Sir Tim hadn’t yet dreamed up the Web, and the Internet wasn’t something that most people could connect to, and bulletin board systems (BBSes) – dial-up services, often local or regional, sometimes connected to one another in one of a variety of ways – dominated the scene. Larger services like CompuServe acted a little like huge BBSes but with dial-up nodes in multiple countries, helping to bridge the international gaps and provide a lower learning curve than the smaller boards (albeit for a hefty monthly fee in addition to the costs of the calls). These services would later go on to double as, and eventually become exclusively, Internet Service Providers, but for the time being they were a force unto themselves.

In 1987, CompuServe were about to start rolling out colour graphics as a new feature, but needed a new graphics format to support that. Their engineer Steve Wilhite had the idea for a bitmap image format backed by LZW compression and called it GIF, for Graphics Interchange Format. Each image could be composed of multiple frames each having up to 256 distinct colours (hence the common mistaken belief that a GIF can only have 256 colours). The nature of the palette system and compression algorithm made GIF a particularly efficient format for (still) images with solid contiguous blocks of colour, like logos and diagrams, but generally underperformed against cosine-transfer-based algorithms like JPEG/JFIF for images with gradients (like most photos).

GIF would go on to become most famous for two things, neither of which it was capable of upon its initial release: binary transparency (having “see through” bits, which made it an excellent choice for use on Web pages with background images or non-static background colours; these would become popular in the mid-1990s) and animation. Animation involves adding a series of frames which overlay one another in sequence: extensions to the format in 1989 allowed the creator to specify the duration of each frame, making the feature useful (prior to this, they would be displayed as fast as they could be downloaded and interpreted!). In 1995, Netscape added a custom extension to GIF to allow them to loop (either a specified number of times or indefinitely) and this proved so popular that virtually all other software followed suit, but it’s worth noting that “looping” GIFs have never been part of the official standard!
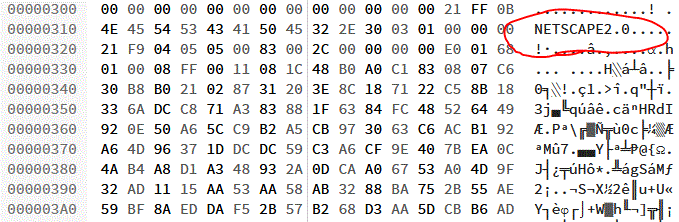
NETSCAPE2.0; evidence of
Netscape’s role in making animated GIFs what they are today.
Compatibility was an issue. For a period during the mid-nineties it was quite possible that among the visitors to your website there would be a mixture of:
This made it hard to depend upon GIFs without carefully considering their use. But people still did, and they just stuck a
![]() button on to warn people, as if that made up for
it. All of this has happened before, etc.
button on to warn people, as if that made up for
it. All of this has happened before, etc.
In any case: as better, newer standards like PNG came to dominate the Web’s need for lossless static (optionally
transparent) image transmission, the only thing GIFs remained good for was animation. Standards like APNG/MNG failed to get off the ground, and so GIFs remained the dominant animated-image standard. As Internet connections became faster and faster in the 2000s, they experienced a
resurgence in popularity. The Web didn’t yet have the <video> element and so embedding videos on pages required a mixture of at least two of
<object>, <embed>, Flash, and black magic… but animated GIFs just worked and
soon appeared everywhere.

Nowadays, when people talk about GIFs, they often don’t actually mean GIFs! If you see a GIF on Giphy or WhatsApp, you’re probably actually seeing an MPEG-4 video file with no audio track! Now that Web video is widely-supported, service providers know that they can save on bandwidth by delivering you actual videos even when you expect a GIF. More than ever before, GIF has become a byword for short, often-looping Internet animations without sound… even though that’s got little to do with the underlying file format that the name implies.

Verdict: We still can’t agree on whether to pronounce it with a soft-G (“jif”), as Wilhite intended, or with a hard-G, as any sane person would, but it seems that GIFs are here to stay in name even if not in form. And that’s okay. I guess.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly diverged from its original/technical one. Read more evolving words…
Until the 17th century, to “fathom” something was to embrace it. Nowadays, it’s more likely to refer to your understanding of something in depth. The migration came via the similarly-named imperial unit of measurement, which was originally defined as the span of a man’s outstretched arms, so you can understand how we got from one to the other. But you know what I can’t fathom? Broadband.

Broadband Internet access has become almost ubiquitous over the last decade and a half, but ask people to define “broadband” and they have a very specific idea about what it means. It’s not the technical definition, and this re-invention of the word can cause problems.
High-speed, always-on Internet access.
Communications channel capable of multiple different traffic types simultaneously.
Throughout the 19th century, optical (semaphore) telegraph networks gave way to the new-fangled electrical telegraph, which not only worked regardless of the weather but resulted in
significantly faster transmission. “Faster” here means two distinct things: latency – how long it takes a message to reach its destination, and bandwidth – how much
information can be transmitted at once. If you’re having difficulty understanding the difference, consider this: a man on a horse might be faster than a telegraph if the size of the
message is big enough because a backpack full of scrolls has greater bandwidth than a Morse code pedal, but the latency of an electrical wire beats land transport
every time. Or as Andrew S. Tanenbaum famously put it: Never underestimate the bandwidth of a station wagon full of
tapes hurtling down the highway.

Telegraph companies were keen to be able to increase their bandwidth – that is, to get more messages on the wire – and this was achieved by multiplexing. The simplest approach, time-division multiplexing, involves messages (or parts of messages) “taking turns”, and doesn’t actually increase bandwidth at all: although it does improve the perception of speed by giving recipients the start of their messages early on. A variety of other multiplexing techniques were (and continue to be) explored, but the one that’s most-interesting to us right now was called acoustic telegraphy: today, we’d call it frequency-division multiplexing.
What if, asked folks-you’ll-have-heard-of like Thomas Edison and Alexander Graham Bell, we were to send telegraph messages down the line at different frequencies. Some beeps and bips would be high tones, and some would be low tones, and a machine at the receiving end could separate them out again (so long as you chose your frequencies carefully, to avoid harmonic distortion). As might be clear from the names I dropped earlier, this approach – sending sound down a telegraph wire – ultimately led to the invention of the telephone. Hurrah, I’m sure they all immediately called one another to say, our efforts to create a higher-bandwidth medium for telegrams has accidentally resulted in a lower-bandwidth (but more-convenient!) way for people to communicate. Job’s a good ‘un.
Most electronic communications systems that have ever existed have been narrowband: they’ve been capable of only a single kind of transmission at a time. Even if you’re multiplexing a dozen different frequencies to carry a dozen different telegraph messages at once, you’re still only transmitting telegraph messages. For the most part, that’s fine: we’re pretty clever and we can find workarounds when we need them. For example, when we started wanting to be able to send data to one another (because computers are cool now) over telephone wires (which are conveniently everywhere), we did so by teaching our computers to make sounds and understand one another’s sounds. If you’re old enough to have heard a fax machine call a landline or, better yet used a dial-up modem, you know what I’m talking about.
As the Internet became more and more critical to business and home life, and the limitations (of bandwidth and convenience) of dial-up access became increasingly questionable, a better solution was needed. Bringing broadband to Internet access was necessary, but the technologies involved weren’t revolutionary: they were just the result of the application of a little imagination.

We’d seen this kind of imagination before. Consider teletext, for example (for those of you too young to remember teletext, it was a standard for browsing pages of text and simple graphics using an 70s-90s analogue television), which is – strictly speaking – a broadband technology. Teletext works by embedding pages of digital data, encoded in an analogue stream, in the otherwise-“wasted” space in-between frames of broadcast video. When you told your television to show you a particular page, either by entering its three-digit number or by following one of four colour-coded hyperlinks, your television would wait until the page you were looking for came around again in the broadcast stream, decode it, and show it to you.
Teletext was, fundamentally, broadband. In addition to carrying television pictures and audio, the same radio wave was being used to transmit text: not pictures of text, but encoded characters. Analogue subtitles (which used basically the same technology): also broadband. Broadband doesn’t have to mean “Internet access”, and indeed for much of its history, it hasn’t.
Here in the UK, ISDN (from 1988!) and later ADSL would be the first widespread technologies to provide broadband data connections over the copper wires simultaneously used to carry telephone calls. ADSL does this in basically the same way as Edison and Bell’s acoustic telegraphy: a portion of the available frequencies (usually the first 4MHz) is reserved for telephone calls, followed by a no-mans-land band, followed by two frequency bands of different sizes (hence the asymmetry: the A in ADSL) for up- and downstream data. This, at last, allowed true “broadband Internet”.
But was it fast? Well, relative to dial-up, certainly… but the essential nature of broadband technologies is that they share the bandwidth with other services. A connection that doesn’t have to share will always have more bandwidth, all other things being equal! Leased lines, despite technically being a narrowband technology, necessarily outperform broadband connections having the same total bandwidth because they don’t have to share it with other services. And don’t forget that not all speed is created equal: satellite Internet access is a narrowband technology with excellent bandwidth… but sometimes-problematic latency issues!

Equating the word “broadband” with speed is based on a consumer-centric misunderstanding about what broadband is, because it’s necessarily true that if your home “broadband” weren’t configured to be able to support old-fashioned telephone calls, it’d be (a) (slightly) faster, and (b) not-broadband.
But does the word that people use to refer to their high-speed Internet connection matter. More than you’d think: various countries around the world have begun to make legal definitions of the word “broadband” based not on the technical meaning but on the populist one, and it’s becoming a source of friction. In the USA, the FCC variously defines broadband as having a minimum download speed of 10Mbps or 25Mbps, among other characteristics (they seem to use the former when protecting consumer rights and the latter when reporting on penetration, and you can read into that what you will). In the UK, Ofcom‘s regulations differentiate between “decent” (yes, that’s really the word they use) and “superfast” broadband at 10Mbps and 24Mbps download speeds, respectively, while the Scottish and Welsh governments as well as the EU say it must be 30Mbps to be “superfast broadband”.

I’m all in favour of regulation that protects consumers and makes it easier for them to compare products. It’s a little messy that definitions vary so widely on what different speeds mean, but that’s not the biggest problem. I don’t even mind that these agencies have all given themselves very little breathing room for the future: where do you go after “superfast”? Ultrafast (actually, that’s exactly where we go)? Megafast? Ludicrous speed?
What I mind is the redefining of a useful term to differentiate whether a connection is shared with other services or not to be tied to a completely independent characteristic of that connection. It’d have been simple for the FCC, for example, to have defined e.g. “full-speed broadband” as providing a particular bandwidth.
Verdict: It’s not a big deal; I should just chill out. I’m probably going to have to throw in the towel anyway on this one and join the masses in calling all high-speed Internet connections “broadband” and not using that word for all slower and non-Internet connections, regardless of how they’re set up.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly diverged from its original/technical one. Read more evolving words…
A few hundred years ago, the words “awesome” and “awful” were synonyms. From their roots, you can see why: they mean “tending to or causing awe” and “full or or characterised by awe”, respectively. Nowadays, though, they’re opposites, and it’s pretty awesome to see how our language continues to evolve. You know what’s awful, though? Computer viruses. Right?

You know what I mean by a virus, right? A malicious computer program bent on causing destruction, spying on your online activity, encrypting your files and ransoming them back to you, showing you unwanted ads, etc… but hang on: that’s not right at all…
Malicious or unwanted computer software designed to cause trouble/commit crimes.
Computer software that hides its code inside programs and, when they’re run, copies itself into other programs.
Only a hundred and thirty years ago it was still widely believed that “bad air” was the principal cause of disease. The idea that tiny germs could be the cause of infection was only just beginning to take hold. It was in this environment that the excellent scientist Ernest Hankin travelled around India studying outbreaks of disease and promoting germ theory by demonstrating that boiling water prevented cholera by killing the (newly-discovered) vibrio cholerae bacterium. But his most-important discovery was that water from a certain part of the Ganges seemed to be naturally inviable as a home for vibrio cholerae… and that boiling this water removed this superpower, allowing the special water to begin to once again culture the bacterium.
Hankin correctly theorised that there was something in that water that preyed upon vibrio cholerae; something too small to see with a microscope. In doing so, he was probably the first person to identify what we now call a bacteriophage: the most common kind of virus. Bacteriophages were briefly seen as exciting for their medical potential. But then in the 1940s antibiotics, which were seen as far more-convenient, began to be manufactured in bulk, and we stopped seriously looking at “phage therapy” (interestingly, phages are seeing a bit of a resurgence as antibiotic resistance becomes increasingly problematic).
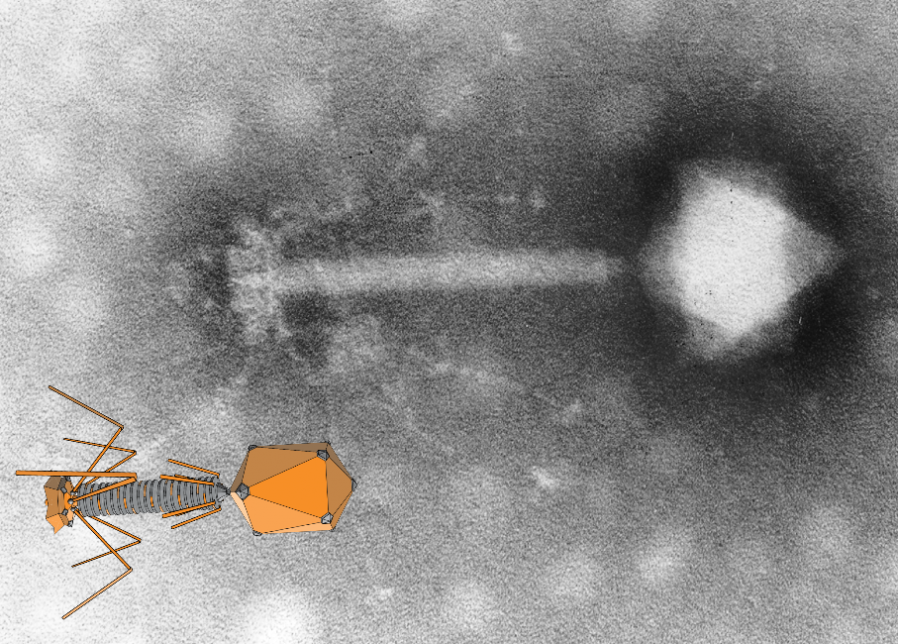
But the important discovery kicked-off by the early observations of Hankin and others was that viruses exist. Later, researchers would discover how these viruses work1: they inject their genetic material into cells, and this injected “code” supplants the unfortunate cell’s usual processes. The cell is “reprogrammed” – sometimes after a dormant period – to churns out more of the virus, becoming a “virus factory”.
Let’s switch to computer science. Legendary mathematician John von Neumann, fresh from showing off his expertise in calculating how shaped charges should be used to build the first atomic bombs, invented the new field of cellular autonoma. Cellular autonoma are computationally-logical, independent entities that exhibit complex behaviour through their interactions, but if you’ve come across them before now it’s probably because you played Conway’s Game of Life, which made the concept popular decades after their invention. Von Neumann was very interested in how ideas from biology could be applied to computer science, and is credited with being the first person to come up with the idea of a self-replicating computer program which would write-out its own instructions to other parts of memory to be executed later: the concept of the first computer virus.

Retroactively-written lists of early computer viruses often identify 1971’s Creeper as the first computer virus: it was a program which, when run, moved (later copied) itself to another computer on the network and showed the message “I’m the creeper: catch me if you can”. It was swiftly followed by a similar program, Reaper, which replicated in a similar way but instead of displaying a message attempted to delete any copies of Creeper that it found. However, Creeper and Reaper weren’t described as viruses at the time and would be more-accurately termed worms nowadays: self-replicating network programs that don’t inject their code into other programs. An interesting thing to note about them, though, is that – contrary to popular conception of a “virus” – neither intended to cause any harm: Creeper‘s entire payload was a relatively-harmless message, and Reaper actually tried to do good by removing presumed-unwanted software.
Another early example that appears in so-called “virus timelines” came in 1975. ANIMAL presented as a twenty questions-style guessing game. But while the user played it would try to copy itself into another user’s directory, spreading itself (we didn’t really do directory permissions back then). Again, this wasn’t really a “virus” but would be better termed a trojan: a program which pretends to be something that it’s not.

It took until 1983 before Fred Cooper gave us a modern definition of a computer virus, one which – ignoring usage by laypeople – stands to this day:
A program which can ‘infect’ other programs by modifying them to include a possibly evolved copy of itself… every program that gets infected may also act as a virus and thus the infection grows.
This definition helps distinguish between merely self-replicating programs like those seen before and a new, theoretical class of programs that would modify host programs such that – typically in addition to the host programs’ normal behaviour – further programs would be similarly modified. Not content with leaving this as a theoretical, Cooper wrote the first “true” computer virus to demonstrate his work (it was never released into the wild): he also managed to prove that there can be no such thing as perfect virus detection.
(Quick side-note: I’m sure we’re all on the same page about the evolution of language here, but for the love of god don’t say viri. Certainly don’t say virii. The correct plural is clearly viruses. The Latin root virus is a mass noun and so has no plural, unlike e.g. fungus/fungi, and so its adoption into a count-noun in English represents the creation of a new word which should therefore, without a precedent to the contrary, favour English pluralisation rules. A parallel would be bonus, which shares virus‘s linguistic path, word ending, and countability-in-Latin: you wouldn’t say “there were end-of-year boni for everybody in my department”, would you? No. So don’t say viri either.)

Viruses came into their own as computers became standardised and commonplace and as communication between them (either by removable media or network/dial-up connections) and Cooper’s theoretical concepts became very much real. In 1986, The Virdim method brought infectious viruses to the DOS platform, opening up virus writers’ access to much of the rapidly growing business and home computer markets.
The Virdim method has two parts: (a) appending the viral code to the end of the program to be infected, and (b) injecting early into the program a call to the appended code. This exploits the typical layout of most DOS executable files and ensures that the viral code is run first, as an infected program loads, and the virus can spread rapidly through a system. The appearance of this method at a time when hard drives were uncommon and so many programs would be run from floppy disks (which could be easily passed around between users) enabled this kind of virus to spread rapidly.
For the most part, early viruses were not malicious. They usually only caused harm as a side-effect (as we’ve already seen, some – like Reaper – were intended to be not just benign but benevolent). For example, programs might run slower if they’re also busy adding viral code to other programs, or a badly-implemented virus might even cause software to crash. But it didn’t take long before viruses started to be used for malicious purposes – pranks, adware, spyware, data ransom, etc. – as well as to carry political messages or to conduct cyberwarfare.
Nowadays, though, viruses are becoming less-common. Wait, what?
Yup, you heard me right: new viruses aren’t being produced at remotely the same kind of rate as they were even in the 1990s. And it’s not that they’re easier for security software to catch and quarantine; if anything, they’re less-detectable as more and more different types of file are nominally “executable” on a typical computer, and widespread access to powerful cryptography has made it easier than ever for a virus to hide itself in the increasingly-sprawling binaries that litter modern computers.

The single biggest reason that virus writing is on the decline is, in my opinion, that writing something as complex as a a virus is longer a necessary step to illicitly getting your program onto other people’s computers2! Nowadays, it’s far easier to write a trojan (e.g. a fake Flash update, dodgy spam attachment, browser toolbar, or a viral free game) and trick people into running it… or else to write a worm that exploits some weakness in an open network interface. Or, in a recent twist, to just add your code to a popular library and let overworked software engineers include it in their projects for you. Modern operating systems make it easy to have your malware run every time they boot and it’ll quickly get lost amongst the noise of all the other (hopefully-legitimate) programs running alongside it.
In short: there’s simply no need to have your code hide itself inside somebody else’s compiled program any more. Users will run your software anyway, and you often don’t even have to work very hard to trick them into doing so.
Verdict: Let’s promote use of the word “malware” instead of “virus” for popular use. It’s more technically-accurate in the vast majority of cases, and it’s actually a more-useful term too.
1 Actually, not all viruses work this way. (Biological) viruses are, it turns out, really really complicated and we’re only just beginning to understand them. Computer viruses, though, we’ve got a solid understanding of.
2 There are other reasons, such as the increase in use of cryptographically-signed binaries, protected memory space/”execute bits”, and so on, but the trend away from traditional viruses and towards trojans for delivery of malicious payloads began long before these features became commonplace.