Now, it’s Saturday morning and you’re
eager to try out what you’ve learned. One of the first things the manual teaches you how to do is change the colors on the display. You follow the instructions, pressing CTRL-9 to enter reverse type mode and then holding down the space bar to create long lines. You swap between colors using CTRL-1 through CTRL-8, reveling in your sudden new power over the TV screen.
As cool as this is, you realize it doesn’t count as programming. In order to program the computer, you learned last night, you have to speak to it in a language called BASIC. To you,
BASIC seems like something out of Star Wars, but BASIC is, by 1983, almost two decades old. It was invented by two Dartmouth professors, John Kemeny and Tom Kurtz, who wanted
to make computing accessible to undergraduates in the social sciences and humanities. It was widely available on minicomputers and popular in college math classes. It then became
standard on microcomputers after Bill Gates and Paul Allen wrote the MicroSoft BASIC interpreter for the Altair. But the manual doesn’t explain any of this and you won’t learn it for
many years.
One of the first BASIC commands the manual suggests you try is the PRINT command. You type in PRINT "COMMODORE
64", slowly, since it takes you a while to find the quotation mark symbol above the 2 key. You hit RETURN and this time, instead of complaining, the computer does exactly what you told it to do and displays “COMMODORE 64” on the next line.
Now you try using the PRINT command on all sorts of different things: two numbers added together, two numbers multiplied together, even several
decimal numbers. You stop typing out PRINT and instead use ?, since the manual has advised you that
? is an abbreviation for PRINT often used by expert programmers. You feel like an expert already, but
then you remember that you haven’t even made it to chapter three, “Beginning BASIC Programming.”
…
I had an Amstrad CPC, myself, but I had friends with C64s and ZX Spectrums and – being slightly older than the author – I got the
opportunity to experiment with BASIC programming on all of them (and went on to write all manner of tools on the CPC 464, 664, and 6128 models). I’m fortunate to have been able to get
started in programming in an era when your first experience of writing code didn’t have to start with an
examination of the different language choices nor downloading and installing some kind of interpreter or compiler: microcomputers used to just drop you at a prompt which
was your interpreter! I think it’s a really valuable experience for a child to have.
From now on, when I try to engage junior programmers with the notion that they should make use of their general-purpose computers to answer questions for them… no matter how silly the
question?… I’ll show them this video. It’s a moderately-concise explanation of the thought processes and programming practice involved in solving a simple, theoretical problem, and it
does a great job at it.
I got into a general life slump recently, and so to try and cheer myself up more, I’ve taken up building fun projects. I joined this industry because I wanted to build things, but I
found that I got so carried away with organising coding events for others, I’d not made time for myself. I started ‘Geese Games’ last year, but I only really got as far as designing a
colour scheme and general layout. I got a bit intimidated by the quiz functionality, so sheepishly put it to one side. This meant that the design was already in place though, and that
I couldn’t get caught up in fussing over design too much. So I figured this would be a good starting point!.
Why geese? I really like geese, and I wanted something super silly, so that I’d not end up taking it too seriously. So I intentionally made a slightly ridiculous design and picked out
some pretty odd types of geese, and got stuck in. It got a bit intense; at one point I got such tech tunnel vision that I accidentally put one goose type in as ‘Great White Frontend
Goose’, went around telling people that there really was such a thing as a ‘great white frontend goose and then later realised I’d actually just made a typo. Little bit awkward… But
it has been good intense, and I’ve had so much fun with this project! Building it has made me pretty happy.
…
My friend Beverley highlights an important fact about learning to develop your skills as a software engineer: that it’s only fun if you make it fun. Side-projects, whether
useful or silly, are an opportunity to expand your horizons from the comfort of
your own home.
As an ocassional geocacher and geohasher, I’m encouraged to post logs describing my adventures, and each major provider wants me to post my logs into theirsilo (see e.g. my logs on geocaching.com, on opencache.uk, and on the geohashing wiki). But as a believer in
the ideals behind the IndieWeb (since long before anybody said “IndieWeb”), I’m opposed to keeping the only copy of content that I produce in an
environment controlled by somebody else (why?).
How do I reconcile this?
Just another hundred metres to the cache, then it’s time to freeze my ass back to base.
What I’d prefer would be to be able to write my logs here, on my own blog, and for my content to by syndicated via some process into the logging systems of the various silo sites I
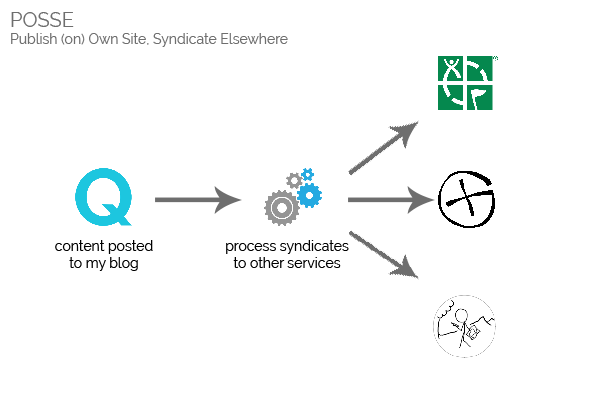
prefer. This approach is called POSSE – Publish on Own Site, Syndicate
Elsewhere. In addition to the widely-described benefits of this syndication strategy, such a system would also make it possible for me to:
write single posts that represent the same location published on multiple silos (e.g. a visit to a geocache published on two different listing sites [e.g. 1, 2])
Applying such an tool would require some work as different silos have different acceptable content rules (geocaching.com, for example, effectively forbids mention of the existence of
other geocache listing sites), but that’d theoretically be workable.
The ideal solution would be POSSE-based.
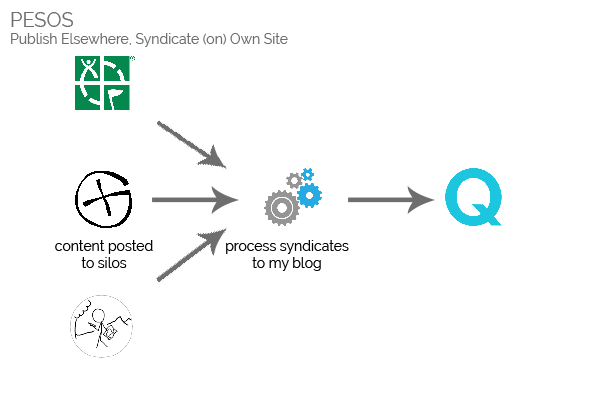
Unfortunately, content rules aren’t the only factor making PESOS – writing content into each silo and then copying it
to my blog – preferable to POSSE. There’s also:
Not all of the silos offer suitable (published) APIs, and where they do, the APIs are all distinctly different.
Geocaching.com specifically forbids the use of unapproved automated robots to access the site (and almost
certainly wouldn’t approve the kind of tool that would be ideal).
The siloed services are well-supported by official and third-party apps with medium-specific logic which make them the best existing way to produce logs.
A PESOS-based solution is far easier to implement, in this case.
Needless to say: as much as I’d have loved to POSSE my geo* logs, PESOS will do.
Implementation
My implementation is a WordPress plugin which does two things. The first is that it provides a Javascript bookmarklet and an
accompanying dynamically-generated Javascript file (the former loads the latter) served from my blog’s domain. That Javascript file contains reference to every log already published to
my blog, so that the Javascript code can deliberately omit these logs from any import. When executed on a log listing page like those linked above, it copies all of the details of that
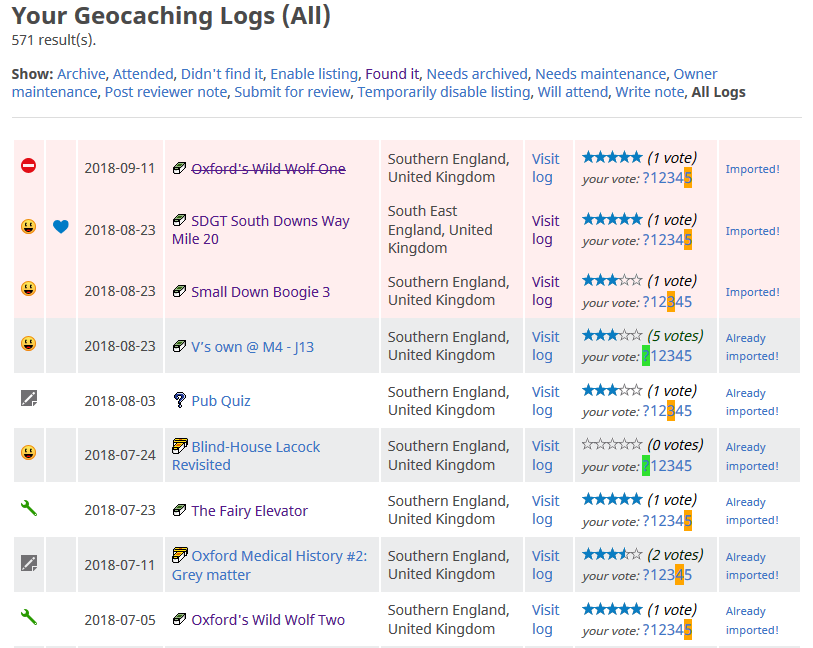
log into a form which submits them back to my blog, where it’s received by the second part of the plugin.
The import controls appear in a new, right-most column (GCVote is also visible running in my browser).
The second part of the plugin takes this data and creates a new draft post. My plugin is pretty opinionated on this part because it’s geared strongly towards my use-case, so if you want
to use it yourself you’ll probably want to tweak the code a little (e.g. it applies specific tags and names metadata fields a particular way).
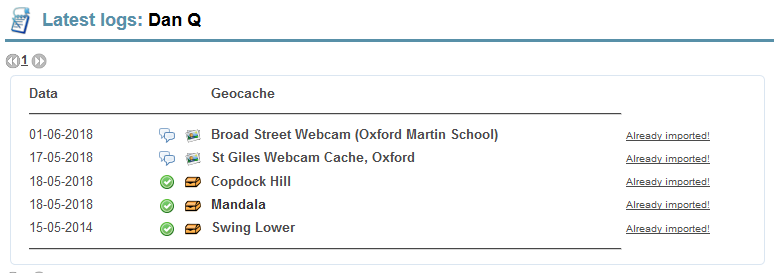
When run on OpenCache.uk effectively the same interface is presented, even though the underlying mechanisms and data locations are different.
It’s not fully-automated and it’s not POSSE,but it’s “good enough” and it’s enabled me to synchronise all of my cache logs to my blog. I’ve plans to extend it to support other GPS game services to streamline my de-siloisation even further.
For those that don’t know, the skinny version is this: in May 2008 an XKCD comic was published proposing (or at least joking about) a new game with a
name reminiscient of geocaching. To play the game, participants use a mathematical hashing function on the current date
and the most recent Dow Jones Industrial Average opening value to generate sets of random coordinates around the
globe and then try to find their way to them, hopefully experiencing adventures along the way. The nature of stock markets and hashing functions means that the coordinates for any given
day are effectively random and impossible to predict (far) in advance, so it’s sometimes described as a spontaneous adventure generator.
The XKCD comic that started it all.
Recently, I found myself wondering about how much of a disadvantage players are at if they live in very “wet” graticules. Residents of the Channel Islands graticule (49 -2), for example, are confined to two land masses surrounded entirely by water. And while it’s
true that water hashpoints can be visited if you’re determined enough, it’s still got to be considered to be
playing at a disadvantage compared to those of us lucky ones in landlocked graticules like mine (51 -1).
And because I’m me and so can’t comfortably leave a question unanswered, I wrote a program to try to answer it! It’s among the hackiest, dirtiest software solutions I’ve ever written,
so if it works for you then it’s a flipping miracle. What it does is:
Determines which OpenStreetMap tiles (the image files served to your browser when you use OpenStreetMap) cover the graticule in question, and downloads them.
Extracts information about the colour of each pixel in each tile.
Counts the proportion of “water blue” pixels to other pixels (this isn’t perfect, because it trips over things like ferry lines on the map as being “not water”, especially at low
zoom-levels).
Some parts of Worcester College Lake are identified as “not water” on account of the text overlay.
I mentioned it was hacky, right?
You can try it for yourself, if you’d like. You’ll need NodeJS, wget, wc, and ImageMagick – all pretty standard or easy-to-get things on a typical Linux box. Run with
node geohash-pcwater.js 51 -1, where 51 -1 is the identifier for the graticule you’re interested in. And in case you’re interested – the Swindon graticule (where I live) is
about 0.68% water, but the Channel Islands graticule is closer to 93.13% water. That’s no small disadvantage: sorry, Channel Islands geohashers!
Update 2018-08-22: discovered some prior art that takes a
somewhat-similar approach.
Coder wants to grow the speech-to-text coding community, uses his fun game to advocate.
Dig Dog is a pretty fun little video game. Call it “Spelunky for kids”—and don’t think of that as a backhanded compliment, either. Dig Dog, which launched
Thursday on iOS, Xbox, Windows, and Mac, shaves away some of the
genre’s complications, controls smoothly, and has depth. It’s as if the modern wave of randomly generated, dig-for-surprises adventures had existed in early ’80s arcades. (And all for
only $3!)
I liked Dig Dog enough when I stumbled upon it at last year’s Fantastic Arcade event in Austin, Texas. But my
interest in the game spiked when its creator reached out ahead of this week’s launch to confirm something I’m not sure any other video game creator has done: coding an entire game by
himself… without using his hands.
Just want to play my game without reading this whole post? Play the game here – press a key, mouse button, or touch the screen to fire the
thrusters, and try to land at less than 4 m/s with as much fuel left over as possible.
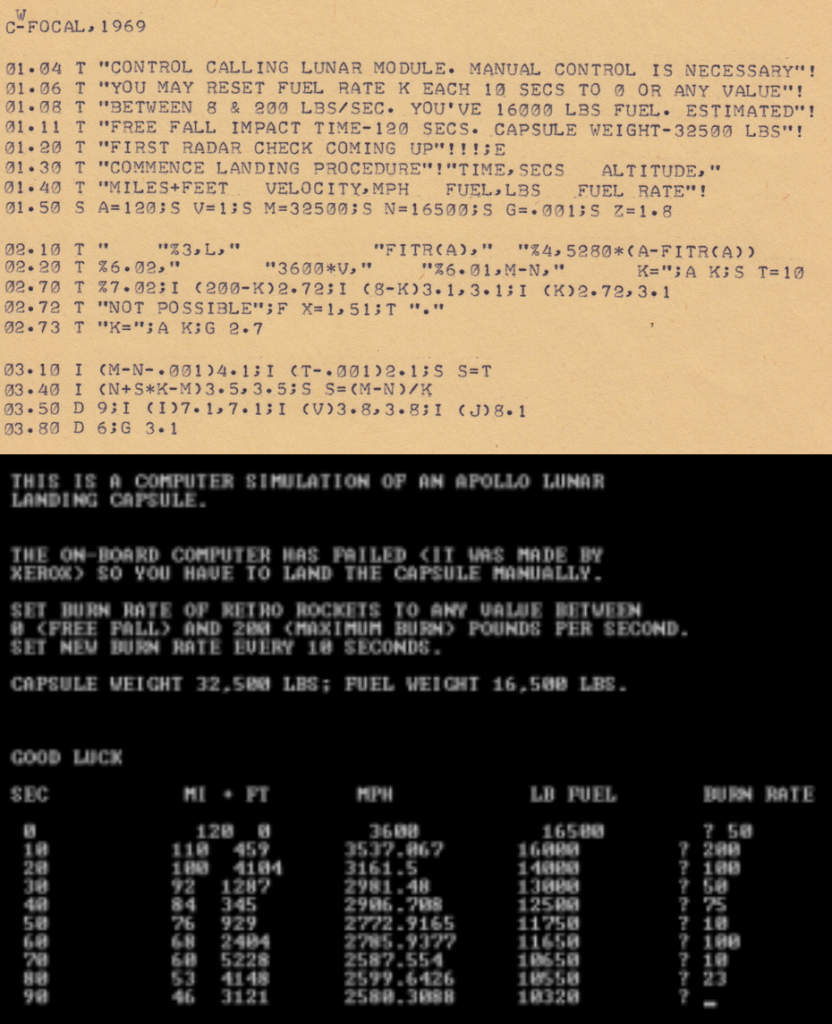
In 1969, when all the nerds were still excited by sending humans to the moon instead of flinging cars around the sun, the hottest video game was Rocket (or Lunar) for the PDP-8. Originally implemented in FOCAL by high school student Jim Storer and soon afterwards ported to BASIC (the other dominant language to come as
standard with microcomputers), Rocket became the precursor to an entire genre of video games called “Lunar Lander games“.
Like many pieces of microcomputer software of the time, Rocket was distributed as printed source code that you’d need to carefully type in at the other end.
The aim of these games was to land a spacecraft on the moon or similar body by controlling the thrust (and in some advanced versions, the rotation) of the engine. The spacecraft begins
in freefall towards the surface and will accelerate under gravity: this can be counteracted with thrust, but engaging the engine burns through the player’s limited supply of fuel.
Furthermore, using fuel lowers the total mass of the vessel (a large proportion of the mass of the Apollo landers was fuel for use in the descent stage) which reduces its inertia,
giving the engine more “kick” which must be compensated for during the critical final stages. It sounds dry and maths-y, but I promise that graphical versions can usually be played
entirely “by eye”.
Atari’s 1979 adaptation is perhaps the classic version you’d recognise, although its release was somewhat overshadowed by their other vector-graphics space-themed release in 1979:
Asteroids.
Let’s fast-forward a little. In 1997 I enrolled to do my A-levels at what was then called Preston College, where my Computing tutor was a chap
called Kevin Geldard: you can see him at 49 seconds into this hilariously low-fi video which I guess must have been originally shot on
VHS despite being uploaded to YouTube in 2009. He’s an interesting chap in his own right whose contributions to my career in computing deserve their own blog post, but for the time
being all you need to know is that he was the kind of geek who, like me, writes software “for fun” more often than not. Kevin owned a Psion 3 palmtop – part of a series of devices with
which I also have a long history and interest – and he taught himself to program OPL by reimplementing a favourite game of his younger years on it: his take on the classic mid-70s-style graphical Lunar Lander.
I never owned a Psion Series 3 (pictured), but I bought a Series 5mx in early 2000 out of my second student loan cheque, ultimately wrote most of my undergraduate dissertation using
it, and eventually sold it to a collector in about 2009 for almost as much as I originally paid for it. The 5mx was an amazing bit of kit. But I’ll blog about that another day, I
guess.
My A-level computing class consisted of a competitive group of geeky lads, and we made sort-of a personal extracurricular challenge to ourselves of re-implementing Kevin’s take on
Lunar Lander using Turbo Pascal, the primary language in which our class was taught. Many hours out-of-class were spent
in the computer lab, tweaking and comparing our various implementations (with only ocassional breaks to play Spacy, CivNet, or my adaptation of LORD2): later, some of us would extend our competition by
going on to re-re-implement in Delphi, Visual Basic, or Java, or by adding additional levels relating to orbital rendezvous or landing on other planetary bodies. I was quite
proud of mine at the time: it was highly-playable, fun, and – at least on your first few goes – moderately challenging.
I sometimes wonder what it would have looked like if I’d have implemented my 1997 Lunar Lander today. So I did.
Always game to try old new things, and ocassionally finding time between the many things that I do to code, I decided to expand upon my recently-discovered
interest in canvas coding to bring back my extracurricular Lunar Lander game of two decades ago in a modern format. My goals were:
A one-button version of a classic “straight descent only” lunar lander game (unlike my 1997 version, which had 10 engine power levels, this remake has just “on” and “off”)
An implementation based initially on real physics (although not necessarily graphically to scale)… and then adapted as necessary to give a fun/playability balance that feels good
Runs in a standards-compliant browser without need for plugins: HTML5, Canvas, Javascript
Adapts gracefully to any device, screen resolution, and orientation with graceful degredation/progressive enhancement
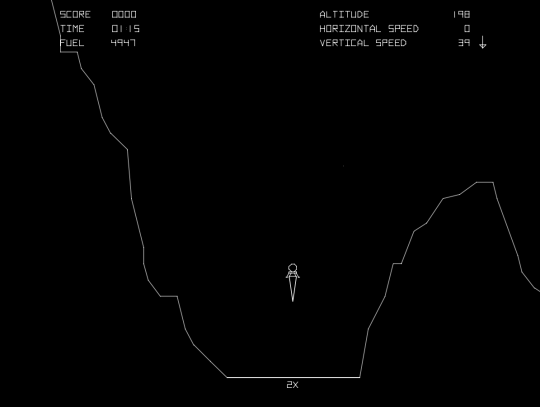
You can have a go at my game right here in your web browser! The aim is to reach the ground travelling at a velocity of no more than 4 m/s
with the maximum amount of fuel left over: this, if anything, is your “score”. My record is 52% of fuel remaining, but honestly anything in the 40%+ range is very good. Touch the screen
(if it’s a touchscreen) or press a mouse button or any key to engage your thrusters and slow your descent.
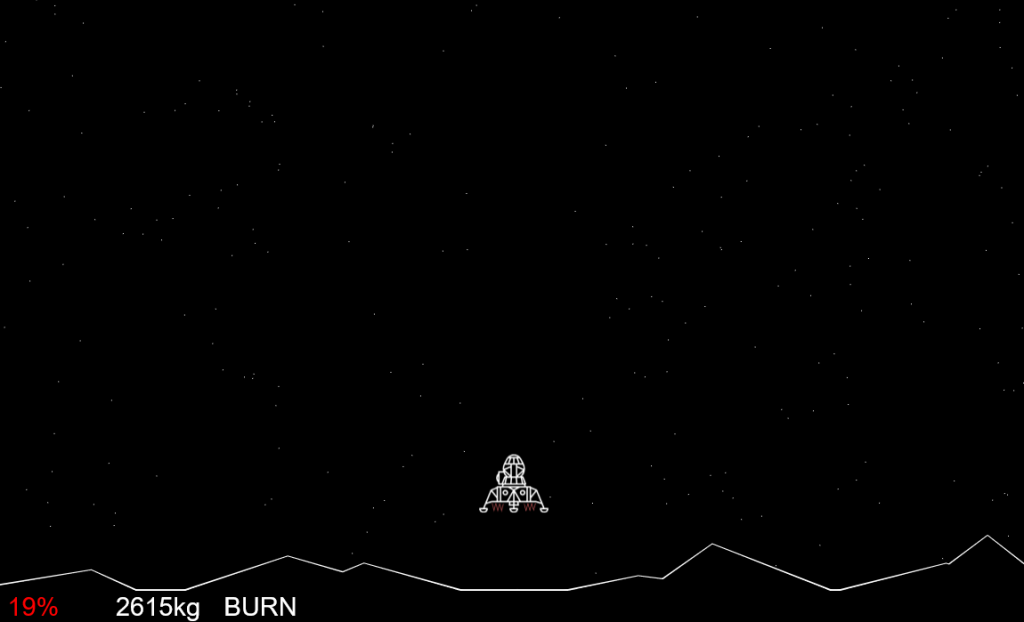
“Houston, the Eagle has landed.” Kerbal Space Program, it isn’t. Here’s a very good landing: 3 m/s with 48% of the fuel tank remaining.
And of course it’s all open-source, so you’re more than welcome to take it, rip it apart, learn from it, or make something better out
of it.
HackerRank has published its 2018 Developer Skills Report. The paper looks at a number things essential to understanding the developer landscape, and explores things
like the perks coders demand from their workplaces, the technologies they prefer to use, and how they entered the software development industry in the first place.
While perusing the paper, something struck me as particularly interesting. One of the questions HackerRank asked its community was when they started coding. It then organized the data
by age and country.
Almost immediately, you notice an interesting trend. Those in the 18 to 24 age group overwhelmingly started their programming journey in their late teens. 68.2 percent started coding
between the ages of 16 to 20.
When you look at older generations, you notice another striking trend: a comparatively larger proportion started programming between the ages of five and ten. 12.2 percent of those
aged between 35 and 44 started programming then.
It’s obvious why that is. That generation was lucky enough to be born at the start of the home computing revolution, when machines bearing the logos of Acorn and Commodore first
entered the living rooms of ordinary people.
…
This survey parallels my own experience: that among developers, those of us who grew up using an 80s microcomputer at home were likely to have started programming a decade or so younger
than those who grew up later, when the PC had come to dominate. I’ve written before about why I care about programming education, and I still think
that we’re not doing enough to show young learners what’s “under the bonnet” of our computer systems. A computer isn’t just a machine you can use, it’s a tool you can adapt: unlike the
other machines you use, which are typically built to a particular purpose, a computer is a general-purpose tool and it can be made to do an infinite number of different tasks!
And even if programming professionally isn’t “for you” (and it shouldn’t be for everyone!), understanding broadly how a tool – a tool that we all come into contact with every
single day – is adapted makes us hugely better-able to understand what they’re capable of and pushes us forwards. Imagine how many young inventors would be able to realise their for the
“killer app” they’ve dreamed up (even if they remained unable to program if themselves) if they were able to understand the fundamental limtations and strengths of the platforms, the
way to express their idea unambiguously in a way that a programmer could develop, and the way to assess its progress without falling into the “happy path” testing problem.
I’m not claiming that late-Gen X’s are better programmers than Millenials, by the way: absolutely not saying that! I’m saying that they were often lucky enough to be shaped by
an experience that got them into programming earlier. And that I wish we could find a way to offer that opportunity to today’s children too.
No JavaScript frameworks were created during the writing of this article.
The following is inspired by the article “It’s the future” from Circle CI. You can read the originalhere. This piece is just an opinion, and like any JavaScript framework, it shouldn’t be taken too
seriously.
Hey, I got this new web project, but to be honest I haven’t coded much web in a few years and I’ve heard the landscape changed a bit. You are the most up-to date web dev around here
right?
-The actual term is Front End engineer, but yeah, I’m the right guy. I do web in 2016. Visualisations, music players, flying drones that play
football, you name it. I just came back from JsConf and ReactConf, so I know the latest technologies to create web apps.
Cool. I need to create a page that displays the latest activity from the users, so I just need to get the data from the REST endpoint and display it in some sort of filterable table,
and update it if anything changes in the server. I was thinking maybe using jQuery to fetch and display the data?
-Oh my god no, no one uses jQuery anymore. You should try learning React, it’s 2016.
Oh, OK. What’s React?
…
A year or two old, and I’d love to claim that things were better in Javascript-framework-land today… but they’re not.
Ever found you’ve accidentally entered too many gits in your terminal and wondered if there’s a solution to it? I quite often type git then go away and come
back, then type a full git status after it. This leads to a lovely (annoying) error out the box:
$ git git status
git: 'git' is not a git command. See 'git --help'.
What a git.
My initial thought was overriding the git binary in my $PATH and having it strip any leading arguments that match git, so we end up running just
the git status at the end of the arguments. An easier way is to just use git-config‘s alias.*
functionality to expand the first argument being git to a shell command.
git config --global alias.git '!exec git'
Which adds the following git config to your .gitconfig file
[alias]git=!exec git
And then you’ll find you can git git to your heart’s content
See what other git alias’ I have in my ~/.gitconfig, and laugh at all the typo corrections I
have in there. (Yes, git provides autocorrection if you enable it, but I’m used to these typos working!)
I often get asked about why I use Vim as my primary editor, there is no particular reason for this, except that I ended up learning it when I moved over to Linux full time many years
ago. I ended up liking it because I could edit my small source files on my quad-core machine without needing to wait forever for the file to open.
Sure Vim isn’t a bad editor, it’s highly extensible, it’s easy to shell out to the, err well shell, its everywhere so when you ssh into some obscure server you can just type vim (or
vi) and you’re good to go…
This was a talk I gave at an internal R&D conference my last week at Workiva. I got a lot of positive feedback on the talk, so I figured I would share it with a wider
audience. Be warned: it’s long. Feel free to read each section separately, though they largely tie together.
Why do you work where you work? For many in tech, the answer is probably culture. When you tell a friend about your job, the culture is probably the first thing you describe.
It’s culture that can be a company’s biggest asset—and its
biggest downfall. But what is it?
Culture isn’t a list of values or a mission statement. It’s not a casual dress code or a beer fridge. Culture is what you reward and what you don’t. More importantly, it’s what you reward and what you punish. That’s an important distinction to make
because when you don’t punish behavior that’s inconsistent with your culture, you send a message: you don’t care about it…
It’s inevitable these days: we will see an article proclaiming the demise of Ruby on Rails every once in a while. It’s the easiest click bait, like this one from TNW.Now, you may say “another Ruby
fanboy.” That’s fair, but a terrible argument, as it’s a poor and common argumentum ad hominem. And on the subject of
fallacies, the click-bait article above is wrong exactly because it falls for a blatantly Post hoc ergo propter
hoc fallacy plus some more confirmation bias which we are all guilty of falling for all the time.
I’m not saying that the author wrote fallacies on purpose. Unfortunately, it’s just too easy to fall for fallacies. Especially when everybody has an intrinsic desire to confirm
one’s biases. Even trying to be careful, I end up doing that as well…
Now, it’s Saturday morning and you’re eager to try out what you’ve learned. One of the first things the manual teaches you how to do is change the colors on the display. You follow the instructions, pressing