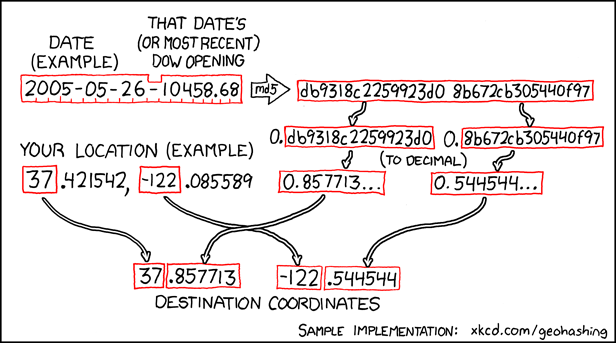
A conversation about staying private and stripping EXIF tags on blogs lead to shdwcat asking the question “what would happen if you took a picture on the moon?”
…
However, I figured we could do better than “a point high above the Earth.” If you could state the coordinate system, you should be able to list an actual point on the moon.
…
It’s a fun question. Sure, you need to shoot down the naysayers who, like colin, rightly point out that you couldn’t reasonably expect to get a GPS/GNSS signal on the moon, but still.
GPS on Earth
GPS (and most other GNSS technologies) fundamentally work by the principle of trilateration. Here’s the skinny of what happens when your GPS receiver – whether that’s your phone, smartwatch, SatNav, or indeed digital camera – needs to work out where on Earth it is:
- It listens for the signal that’s transmitted from the satellites. This is already an amazing feat of engineering given that the signal is relatively quiet and it’s being transmitted from around 20,000km above the surface of the planet1.
- The signal fundamentally says, for example “Hi, I’m satellite #18, and the time is [some time].” Assuming your GPS receiver doesn’t contain an atomic clock2, it listens for the earliest time – i.e. the closest satellite (the signals “only” travel at the speed of light) – and assumes that this satellite’s time represents the actual time at your location.
- Your GPS receiver keeps listening until it’s found three more satellites, and compares the times that they claim it is. Using this, and knowing the speed of light, it’s able to measure the distance to each of those three satellites. The satellites themselves are on reasonably-stable orbits, so as long as you’ve been installing your firmware updates at least once every 5-10 years, your device knows where those satellites are expected to be.
- If you know your distance from one satellite, in 3D space, you know that your location is on the surface of an imaginary sphere with a radius of that distance, centered on the satellite. Once you’ve measured your distance from a second satellite, you know that you must be at a point where those two spheres intersect: i.e. somewhere on a circle. With a third satellite found and the distance measured, you’re able to cut that down to just two points (of which one is likely to be about 40,000km into space, so it’s probably not that one3).
- Your device will keep finding more passing satellites, measuring and re-measuring, and refining/averaging your calculated location for maximum accuracy.
So yeah: that tiny computer on top of your camera or within your wristwatch? It’s differentiating to miniscule precision measurements of the speed of light, from spacecraft as far away as half the circumference of the planet, while compensating for not being a timekeeping device accurate enough to do so and working-around the time dilation resulting from the effect of general relativity on the satellites4.
GPS on Luna
Supposing you could pick out GPS signals from Earth orbit, from the surface of the moon (which – again – you probably can’t – especially if you were on the dark side of the moon where you wouldn’t get a view of the Earth). Could it work?
I can’t see why not. You’d want to recalibrate your GPS receiver to assume that the “time” satellite – the one with the earliest-apparent clock – was much further away (and therefore that the real time was later than it appears to be) than an Earth-based GPS receiver would: the difference in the order of 1.3 seconds, which is a long time in terms of GNSS calculation.
Again, once you had distance measurements from three spatial satellites you’d be able to pinpoint your location, to within some sphere of uncertainty, to one of two points. One would be on the moon (where you know that you are5), and one would be on the far side of the Earth by almost the same distance. That’s a good start. And additional satellites could help narrow it down even more.
You might even be able to get a slightline to more satellites than is typically possible on Earth, not being limited by Earth curvature, nor being surrounded by relatively-large Earth features like mountains, buildings, trees, and unusually-tall humans. It’s feasible.
How about… LPS?
If we wanted to go further – and some day, if we aim to place permanent human settlements on the moon, we might – then we might consider a Lunar Positioning System: a network of a dozen or so orbiters whizzing around the moon to facilitate accurate positioning on its surface. They’d want to be in low orbits to avoid the impact of tidal forces from the much-larger nearby Eath, and with no atmosphere to scrape against there’s little harm in that.
By the time you’re doing that, though, you might as well ditch trilateration and use the doppler effect, Transit-style. It works great in low orbits but its accuracy on Eath was always limited by the fact that you can’t make the satellites fly low enough without getting atmospheric drag. There’s no such limitation on the moon. Maybe that’s the way forward.
Maybe far-future mobile phones and cameras will support satellite positioning and navigation networks on both Earth and Luna. And maybe then we’ll start seeing EXIF metadata spanning both the WGS-84 datum and the LRO-ME datum.
Footnotes
1 That’s still only about a twentieth of the way to the moon, by the way. But there are other challenging factors, like our atmosphere and all of the obstructions both geographic and human-made that litter our globe.
2 Protip: it doesn’t.
3 Satnav voice: “After falling for forty thousand kilometres, you will reach your destination.”
4 The relativistic effects on GPS satellites cannot be understated. Without compensation, GPS accuracy would drift by up to 10km for every day that the satellites were in orbit, which I reckon would make them useless for anything more than telling you what hemisphere you were in within 5½ years!
5 If you’re on the moon and don’t know it, you have a whole different problem.