I’ve been doing a course provided through work to try to improve my ability to connect with an audience over
video. For one of my assignments in this, my fourth week, I picked a topic out from the “welcome” survey I filled out when I first started the course. The topic: the Devil’s Quoits. This stone circle – not far from my new house – has such a bizarre
history of construction, demolition, and reconstruction… as well as a fun folk myth about its creation… that I’d thought it’d make a great follow-up to my previous “local history”
piece, Oxford’s Long-Lost Zoo. I’d already hidden a “virtual” geocache at the henge, as I previously did for the zoo: a video seemed like the next logical step.
My brief required that the video be only about a minute long, which presented its own challenge in cutting down the story I’d like to tell to a bare minimum. Then on top of that, it
took me at least eight takes until I was confident that I’d have one I was happy with, and there’s still things I’d do differently if I did it again (including a better windbreak on my
lapel mic, and timing my takes for when geese weren’t honking their way past overhead!).
In any case: part of the ritual of this particular course encourages you to “make videos… as if people will see them”, and I’ve been taking that seriously! Firstly, I’ve been
sharing many of my videos with others either at work or on my blog, like the one about how GPS works or the one about the secret of magic. Secondly, I’ve been doing “extra credit” by
recording many of my daily-standup messages as videos, in addition to providing them through our usual Slack bot.
Anyway, the short of it is: you’re among the folks who get to see this one. Also available on YouTube.
I was chatting with a fellow web developer recently and made a joke about the HTML <blink> and
<marquee> tags, only to discover that he had no idea what I was talking about. They’re a part of web history that’s fallen off the radar and younger developers are
unlikely to have ever come across them. But for a little while, back in the 90s, they were a big deal.
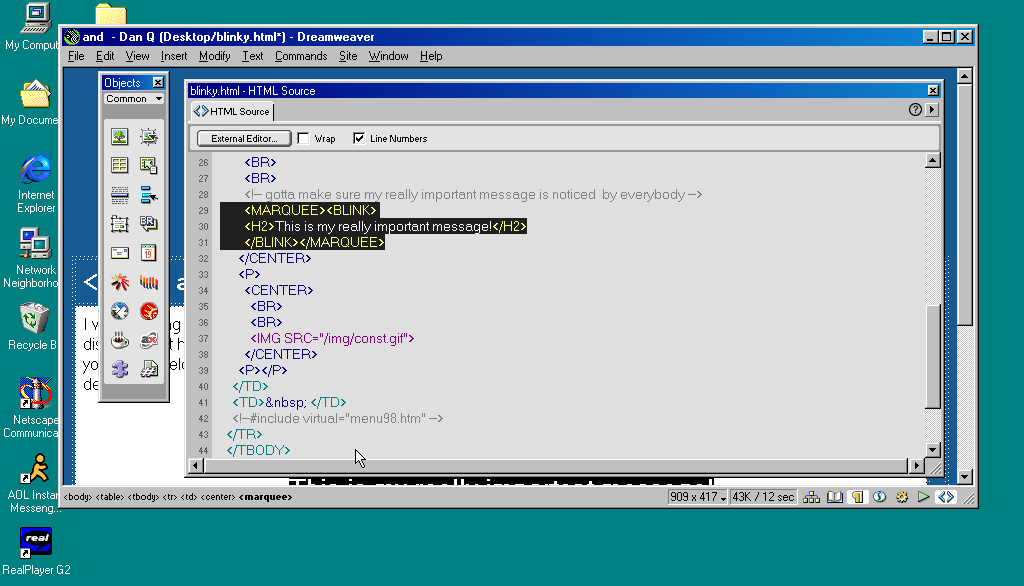
Even Macromedia Dreamweaver, which embodied the essence of 1990s web design, seemed to treat wrapping
<blink> in <marquee> as an antipattern.
Invention of the <blink> element is often credited to Lou Montulli, who wrote pioneering web browser Lynx before being joining Netscape in 1994. He insists that he didn’t write any
of the code that eventually became the first implementation of <blink>. Instead, he claims: while out at a bar (on the evening he’d first meet his wife!), he
pointed out that many of the fancy new stylistic elements the other Netscape engineers were proposing wouldn’t work in Lynx, which is a text-only browser. The fanciest conceivable
effect that would work across both browsers would be making the text flash on and off, he joked. Then another engineer – who he doesn’t identify – pulled a late night hack session and
added it.
And so it was that when Netscape Navigator 2.0 was released in 1995 it added support for
the <blink> tag. Also animated GIFs and the first inklings of JavaScript, which collectively
would go on to define the “personal website” experience for years to come. Here’s how you’d use it:
<BLINK>This is my blinking text!</BLINK>
With no attributes, it was clear from the outset that this tag was supposed to be a joke. By the time HTML4 was
published as a a recommendation two years later, it was documented as being a joke. But the Web of the late 1990s
saw it used a lot. If you wanted somebody to notice the “latest updates” section on your personal home page, you’d wrap a <blink> tag around the title (or,
if you were a sadist, the entire block).
If you missed this particular chapter of the Web’s history, you can simulate it at Cameron’s World.
In the same year as Netscape Navigator 2.0 was released, Microsoft released Internet Explorer
2.0. At this point, Internet Explorer was still very-much playing catch-up with the features the Netscape team had implemented, but clearly some senior Microsoft engineer took a
look at the <blink> tag, refused to play along with the joke, but had an innovation of their own: the <marquee> tag! It had a whole suite of attributes to control the scroll direction, speed, and whether it looped or bounced backwards and forwards. While
<blink> encouraged disgusting and inaccessible design as a joke, <marquee> did it on purpose.
<MARQUEE>Oh my god this still works in most modern browsers!</MARQUEE>
But here’s the interesting bit: for a while in the late 1990s, it became a somewhat common practice to wrap content that you wanted to emphasise with animation in both a
<blink> and a <marquee> tag. That way, the Netscape users would see it flash, the IE users
would see it scroll or bounce. Like this:
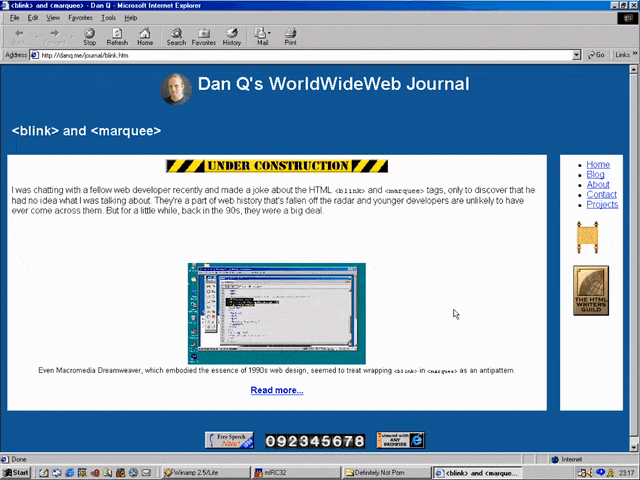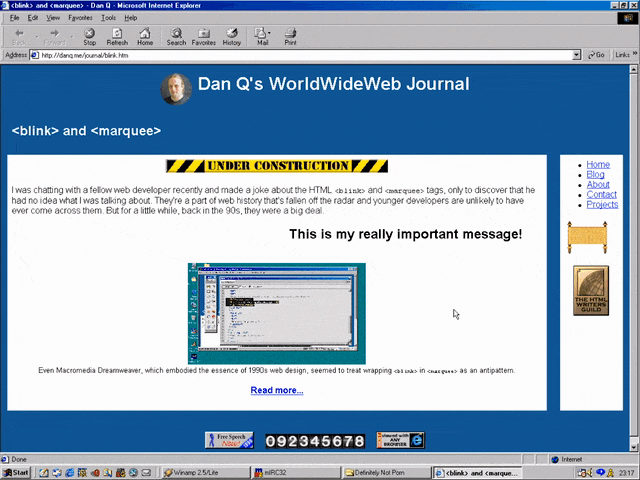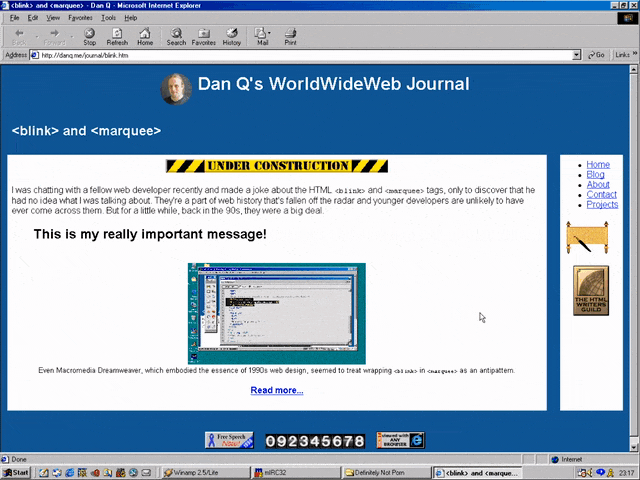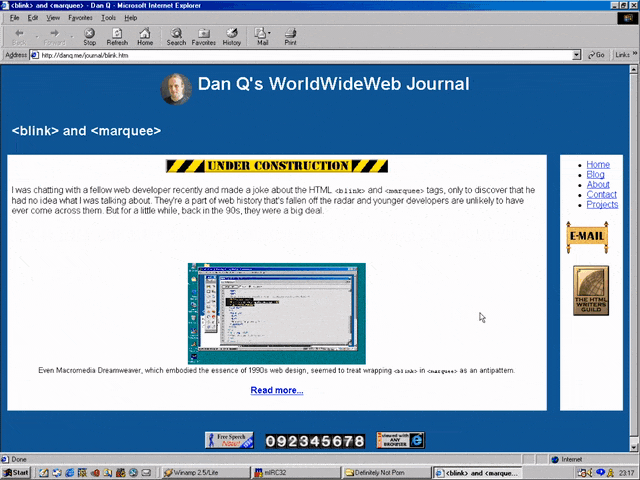
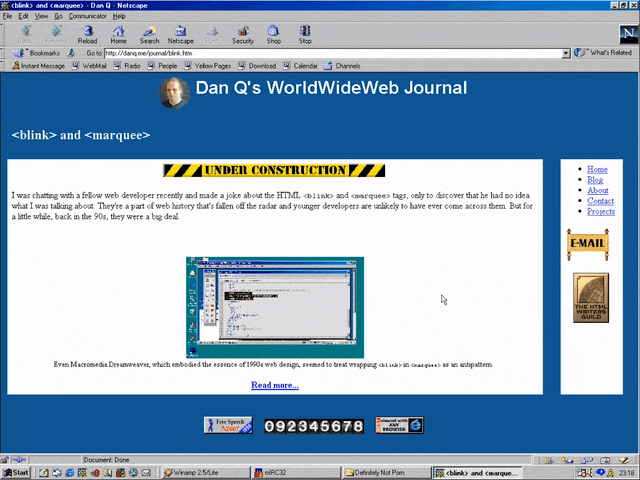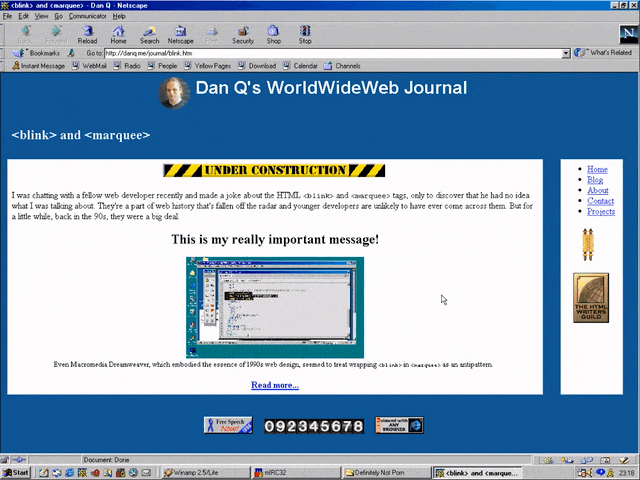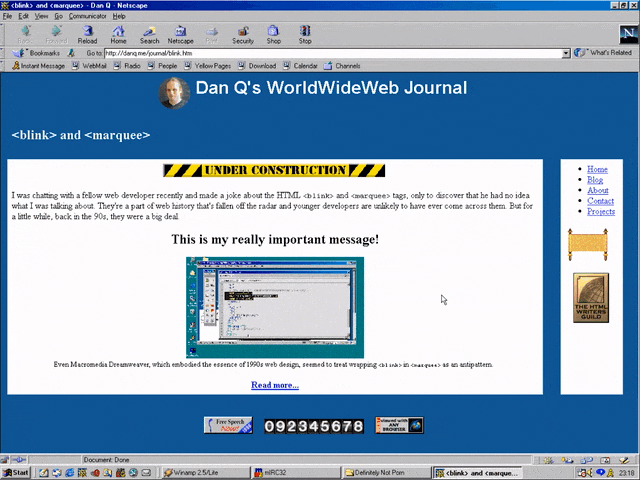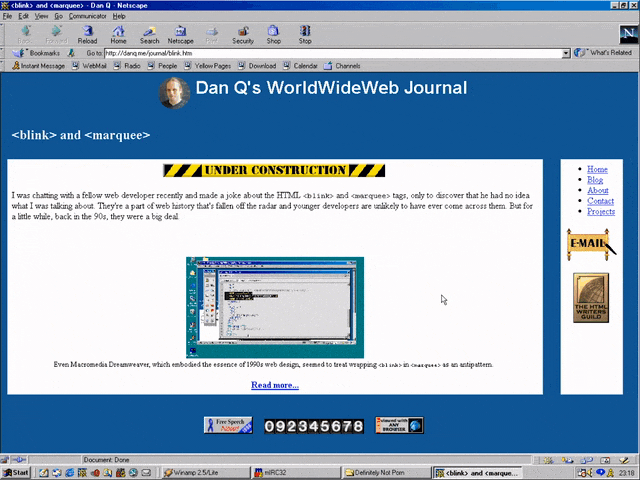
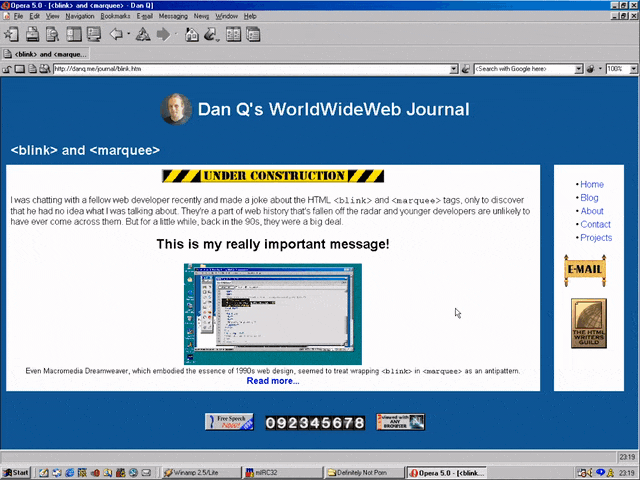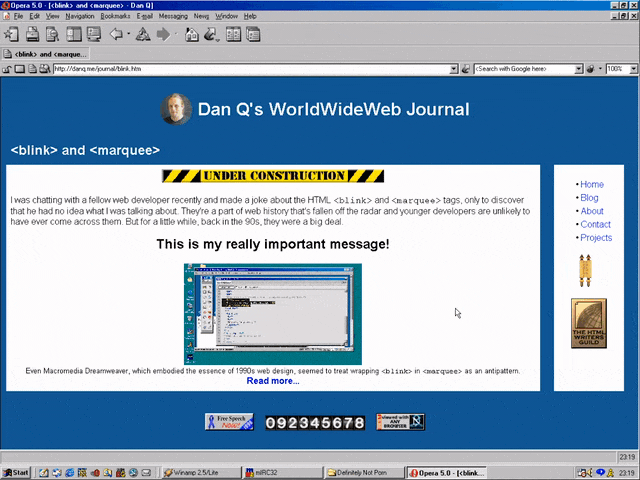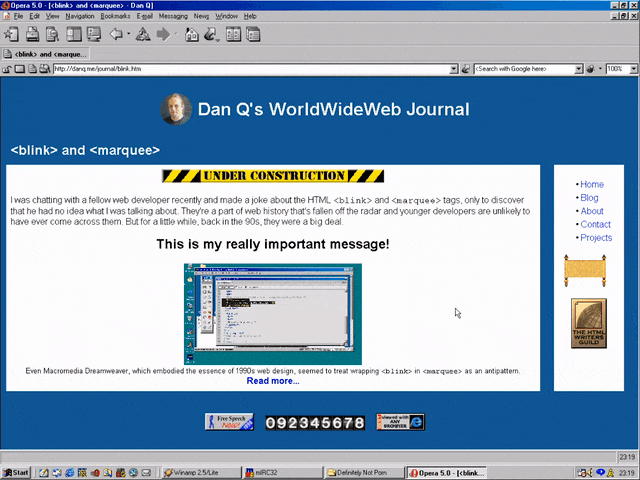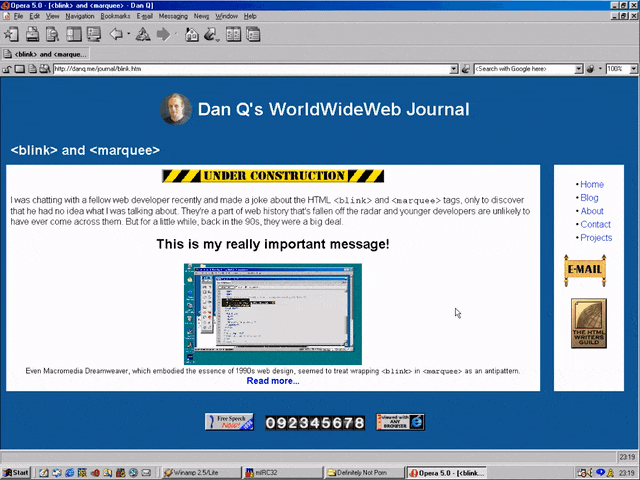
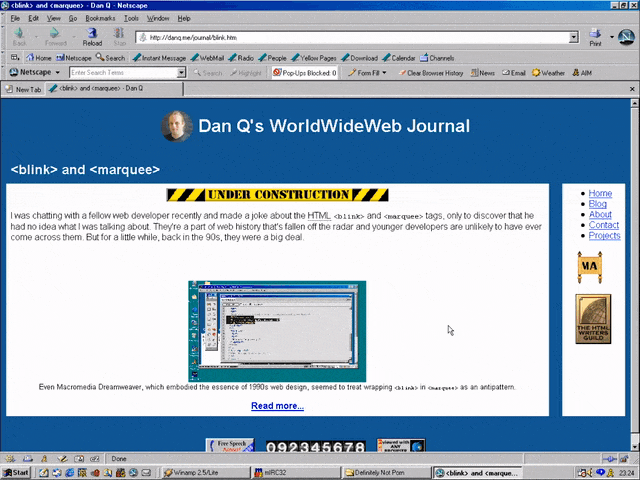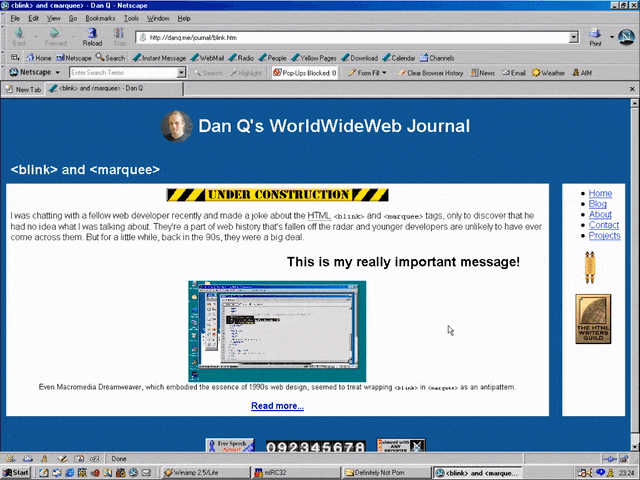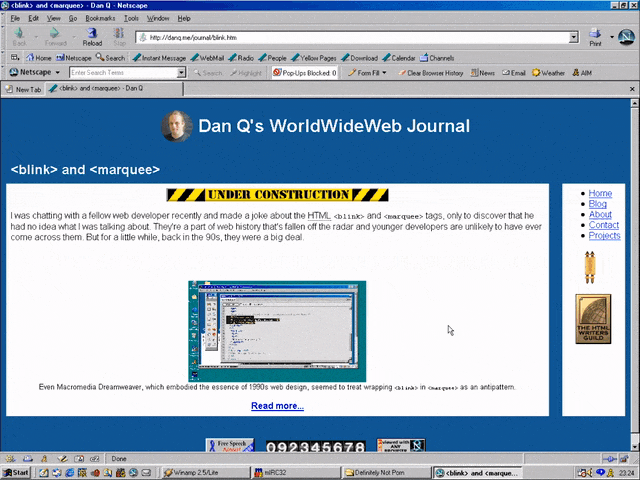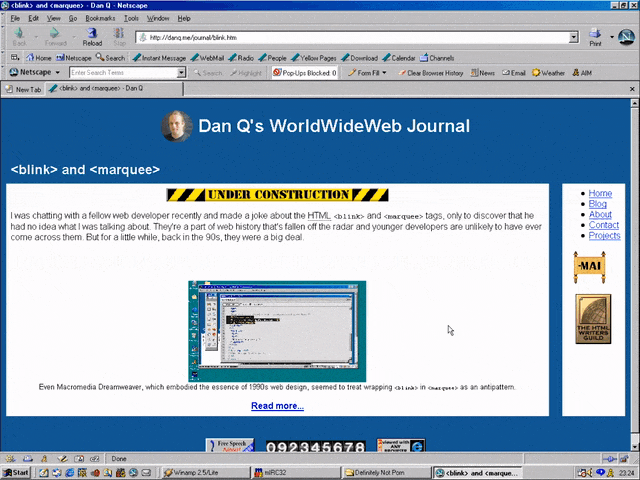
<MARQUEE><BLINK>This is my really important message!</BLINK></MARQUEE>
Wrap a <blink> inside a <marquee> and IE users will see the marquee. Delightful.
The web has always been built on Postel’s Law: a web browser should assume that it won’t understand everything it reads,
but it should provide a best-effort rendering for the benefit of its user anyway. Ever wondered why the modern <video> element is a block rather than a self-closing
tag? It’s so you can embed within it code that an earlier browser – one that doesn’t understand <video> – can read (a browser’s default state when seeing a
new element it doesn’t understand is to ignore it and carry on). So embedding a <blink> in a <marquee> gave you the best of both worlds, right?
(welll…)
Wrap a <blink> inside a <marquee> and Netscape users will see the blink. Joy.
Better yet, you were safe in the knowledge that anybody using a browser that didn’t understand either of these tags could still read your content. Used properly, the
web is about progressive enhancement. Implement for everybody, enhance for those who support the shiny features. JavaScript and CSS can be applied with the same rules, and doing so pays dividends in maintainability and accessibility (though, sadly, that doesn’t stop people writing
sites that needlessly require these technologies).
Personally, I was a (paying! – back when people used to pay for web browsers!) Opera user so I mostly saw neither <blink> nor <marquee> elements.
I don’t feel like I missed out.
I remember, though, the first time I tried Netscape 7, in 2002. Netscape 7 and its close descendent are, as far as I can tell, the only web browsers to support both<blink> and <marquee>. Even then, it was picky about the order in which they were presented and the elements wrapped-within them. But support was
good enough that some people’s personal web pages suddenly began to exhibit the most ugly effect imaginable: the combination of both scrolling and flashing text.
If Netscape 7’s UI didn’t already make your eyes bleed (I’ve toned it down here by installing the “classic skin”), its simultaneous
rendering of <blink> and <marquee> would.
The <blink> tag is very-definitely dead (hurrah!), but you can bring it back with pure CSS if you must.
<marquee>, amazingly, still survives, not only in polyfills but natively, as you might be able to see above. However, if you’re in any doubt as to whether or not
you should use it: you shouldn’t. If you’re looking for digital nostalgia, there’s a whole
rabbit hole to dive down, but you don’t need to inflict <marquee> on the rest of us.
With help from a neural network, Denis takes original cinematography of New York City in 1911 and uploads it as an cleaned, upscaled, high-framerate, colourised YouTube video. It’s
pretty remarkable: compare it to the source video to see how much of a difference it makes: side-by-side, the smoothness of the
frame rate alone is remarkable. It’s a shame that nothing can be done about the underexposed bits of the film where contrast detail is lacking: I wonder if additional analysis of the
original print itself might be able to extract some extra information from these areas and them improve them using the same kinds of techniques.
In any event, a really interesting window-to-history!
Today my #distributed #remotework office is provided by @OCFI_OI, which provides me that most #Oxford of views: simultaneously containing architecture of the 1960s… and the 1160s.
The “where’s my elephant?” theory takes it name, of course, from The Simpsons episode in which Bart gets an elephant (Season 5, episode 17, to be precise). For those of you
who don’t know the episode: Bart wins a radio contest where you have to answer a phone call with the phrase, “KBBL is going to give me something stupid.” That “something stupid”
turns out to be either $10,000, or “the gag prize”: a full-grown African elephant. Much to the presenters’ surprise, Bart chooses the elephant — which is a problem for the radio
station, since they don’t actually have an elephant to give him. After some attempts at negotiation (the presenters offer Principal Skinner $10,000 to go about with his pants pulled
down for the rest of the school year; the presenters offer to use the $10,000 to turn Skinner into “some sort of lobster-like creature”), Bart finds himself kicked out of the radio
station, screaming “where’s my elephant?”
…
…the “where’s my elephant?” theory holds the following:
If you give someone a joke option, they will take it.
The joke option is a (usually) a joke option for a reason, and choosing it will cause everyone a lot of problems.
In time, the joke will stop being funny, and people will just sort of lose interest in it.
No one ever learns anything.
…
For those that were surprised when Trump was elected or Brexit passed a referendum, the “Where’s My Elephant?” theory of history may provide some solace. With reference to Boaty
McBoatface and to the assassination of Qasem Soleimani, Tom Whyman pitches that “joke” options will be selected significantly more-often that you’d expect or that they should.
Our society is like Bart Simpson. But can we be a better Bart Simpson?
If that didn’t cheer you up: here’s another article, which more-seriously looks at the
political long-game that Remainers in Britain might consider working towards.
West Germany’s 1974 World Cup victory happened closer to the first World Cup in 1930 than to today.
The Wonder Years aired from 1988 and 1993 and depicted the years between 1968 and 1973. When I watched the show, it felt like it was set in a time long ago. If a new Wonder
Years premiered today, it would cover the years between 2000 and 2005.
Also, remember when Jurassic Park, The Lion King, and Forrest Gump came out in theaters? Closer to the moon landing than today.
…
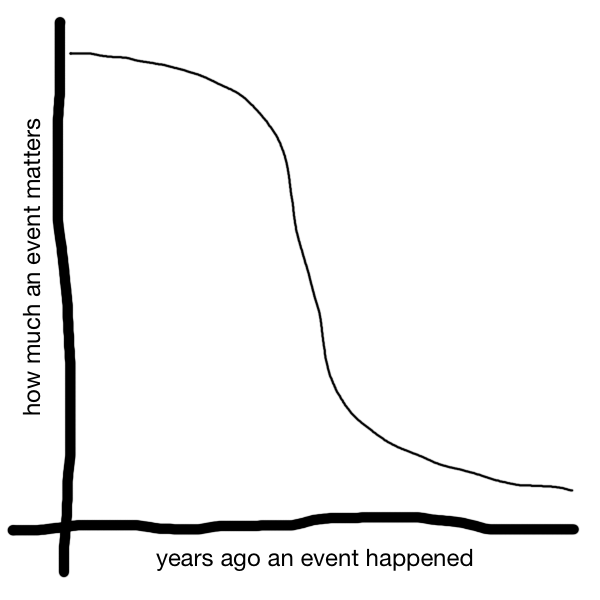
These things come around now and again, but I’m not sure of the universal validity of observing that a memorable event is now closer to another memorable event than it is to the present
day. I don’t think that the relevance of events is as linear as that. Instead, perhaps, it looks something like this:
Recent events matter more than ancient events to the popular consciousness, all other things being equal, but relative to one another the ancient ones are less-relevant and
there’s a steep drop-off somewhere between the two.
Where the drop-off in relevance occurs is hard to pinpoint and it probably varies a lot by the type of event that’s being remembered: nobody seems to care about what damn terrible thing
Trump did last month or the month before when there’s some new terrible thing he did just this morning, for example (I haven’t looked at the news yet this morning, but honestly
whenever you read this post he’ll probably have done something awful).
Nonetheless, this post on Wait But Why was a fun distraction, even if it’s been done before. Maybe the last time it happened was so long ago it’s irrelevant now?
Of course, there’s a relevant XKCD. And it was published closer to the theatrical releases of Cloudy with a Chance of Meatballs and
Paranormal Activity than it was to today. OoooOOoooOOoh.
In the first century AD, Roman naturalist Pliny the Elder threw a salamander into a fire. He wanted to see if it could indeed not only survive the flames,
but extinguish them, as Aristotle had claimed such creatures could. But the salamander didn’t … uh … make it.
Yet that didn’t stop the legend of the fire-proof salamander (a name derived from the Persian meaning “fire within”) from persisting for 1,500 more years, from the Ancient Romans to the Middle Ages on up to the alchemists
of the Renaissance. Some even believed it was born in fire, like the legendary Phoenix, only slimier and a bit less dramatic. And that its fur (huh?) could be used to weave
fire-resistant garments.
…
Back when the world felt bigger and more-mysterious it was easier for people to come to the conclusion, based on half-understood stories passed-on many times, that creatures like
unicorns, dragons, and whatever the Vegetable Lamb of Tartary was supposed to be, might exist just beyond the
horizons. Nature was full of mystery and the simple answer – that salamanders might live in logs and then run to escape when those logs are thrown onto a fire – was far less-appealing
than the idea that they might be born from the fire itself! Let’s not forget that well into the Middle Ages it was widely believed that many forms of life appeared not through
reproduction but by spontaneous generation: clams forming themselves out of sand, maggots out of meat, and so on… with
this underlying philosophy, it’s easy to make the leap that sure, amphibians from fire makes sense too, right?
Perhaps my favourite example of such things is the barnacle goose, which – prior to the realisation that birds
migrate and coupled with them never being seen to nest in England – lead to the widespread belief that they spontaneously developed (at the appropriate point in the season)
from shellfish… this may be the root of the word “barnacle” as used to describe the filter-feeders with which we’re familiar. So prevalent was this belief that well into the 15th
century (and in some parts of the world the late 18th century) this particular species of goose was treated as being a fish, not a bird, for the purpose of Christian fast-days.
Anyway; that diversion aside, this article’s an interesting look at the history of mythological beliefs about salamanders.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
Anticipatory note: based on the traffic I already get to my blog and the keywords people search for, I imagine that some people will end up here looking to
learn “how to become a hacker”. If that’s your goal, you’re probably already asking the wrong question, but I direct you to Eric S. Raymond’s Guide/FAQ on the subject. Good luck.
Few words have seen such mutation of meaning over their lifetimes as the word “silly”. The earliest references, found in Old English, Proto-Germanic, and Old Norse and presumably having
an original root even earlier, meant “happy”. By the end of the 12th century it meant “pious”; by the end of the 13th, “pitiable” or “weak”; only by the late 16th coming to mean
“foolish”; its evolution continues in the present day.
The Monty Python crew were certainly the experts on the contemporary use of the word.
But there’s little so silly as the media-driven evolution of the word “hacker” into something that’s at least a little offensive those of us who probably would be
described as hackers. Let’s take a look.
Hacker
What people think it means
Computer criminal with access to either knowledge or tools which are (or should be) illegal.
What it originally meant
Expert, creative computer programmer; often politically inclined towards information transparency, egalitarianism, anti-authoritarianism, anarchy, and/or decentralisation of
power.
The Past
The earliest recorded uses of the word “hack” had a meaning that is unchanged to this day: to chop or cut, as you might describe hacking down an unruly bramble. There are clear links
between this and the contemporary definition, “to plod away at a repetitive task”. However, it’s less certain how the word came to be associated with the meaning it would come to take
on in the computer labs of 1960s university campuses (the earliest references seem to come from
around April 1955).
There, the word hacker came to describe computer experts who were developing a culture of:
sharing computer resources and code (even to the extent, in extreme
cases, breaking into systems to establish more equal opportunity of access),
learning everything possible about humankind’s new digital frontiers (hacking to learn, not learning to hack)
discovering and advancing the limits of computers: it’s been said that the difference between a non-hacker and a hacker is that a non-hacker asks of a new gadget “what does it do?”,
while a hacker asks “what can I make it do?”
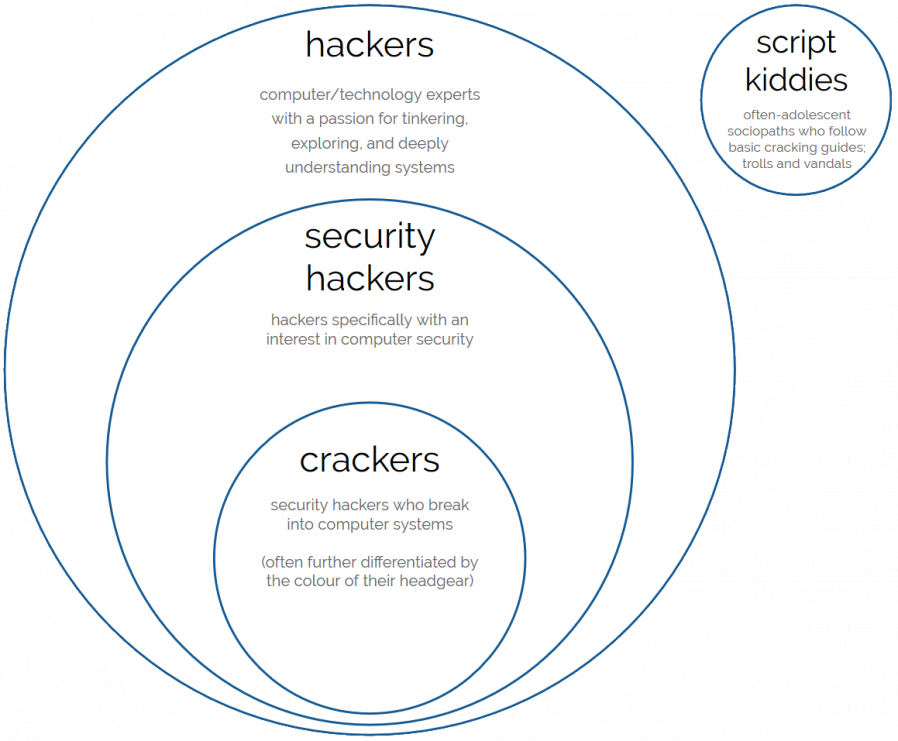
What the media generally refers to as “hackers” would be more-accurately, within the hacker community, be called crackers; a subset of security hackers, in turn a subset of
hackers as a whole. Script kiddies – people who use hacking tools exclusively for mischief without fully understanding what they’re doing – are a separate subset on their own.
It is absolutely possible for hacking, then, to involve no lawbreaking whatsoever. Plenty of hacking involves writing (and sharing) code, reverse-engineering technology and systems you
own or to which you have legitimate access, and pushing the boundaries of what’s possible in terms of software, art, and human-computer interaction. Even among hackers with a specific
interest in computer security, there’s plenty of scope for the legal pursuit of their interests: penetration testing, security research, defensive security, auditing, vulnerability
assessment, developer education… (I didn’t say cyberwarfare because 90% of its
application is of questionable legality, but it is of course a big growth area.)
Hackers have a serious image problem, and the best way to see it is to search on your favourite stock photo
site for “hacker”. If you don’t use a laptop in a darkened room, wearing a hoodie and optionally mask and gloves, you’re not a real hacker. Also, 50% of all text should be
green, 40% blue, 10% red.
So what changed? Hackers got famous, and not for the best reasons. A big tipping point came in the early 1980s when hacking group The
414s broke into a number of high-profile computer systems, mostly by using the default password which had never been changed. The six teenagers responsible were arrested by the
FBI but few were charged, and those that were were charged only with minor offences. This was at least in part because
there weren’t yet solid laws under which to prosecute them but also because they were cooperative, apologetic, and for the most part hadn’t caused any real harm. Mostly they’d just been
curious about what they could get access to, and were interested in exploring the systems to which they’d logged-in, and seeing how long they could remain there undetected. These remain
common motivations for many hackers to this day.
Hoodie: check. Face-concealing mask: check. Green/blue code: check. Is I a l33t hacker yet?
News media though – after being excited by “hacker” ideas introduced by WarGames – rightly realised that a hacker with the
same elementary resources as these teens but with malicious intent could cause significant real-world damage. Bruce
Schneier argued last year that the danger of this may be higher today than ever before. The press ran news stories strongly associating the word “hacker” specifically with the focus
on the illegal activities in which some hackers engage. The release of Neuromancer the following year, coupled
with an increasing awareness of and organisation by hacker groups and a number of arrests on both sides of the Atlantic only fuelled things further. By the end of the decade it was
essentially impossible for a layperson to see the word “hacker” in anything other than a negative light. Counter-arguments like The
Conscience of a Hacker (Hacker’s Manifesto) didn’t reach remotely the same audiences: and even if they had, the points they made remain hard to sympathise with for those outside of
hacker communities.
‘Nuff said.
A lack of understanding about what hackers did and what motivated them made them seem mysterious and otherworldly. People came to make the same assumptions about hackers that
they do about magicians – that their abilities are the result of being privy to tightly-guarded knowledge rather than years of practice – and this
elevated them to a mythical level of threat. By the time that Kevin Mitnick was jailed in the mid-1990s, prosecutors were able to successfully persuade a judge that this “most dangerous
hacker in the world” must be kept in solitary confinement and with no access
to telephones to ensure that he couldn’t, for example, “start a nuclear war by whistling into a pay phone”. Yes, really.
Whistling into a phone to start a nuclear war? That makes CSI: Cyber seem realistic [watch].
The Future
Every decade’s hackers have debated whether or not the next decade’s have correctly interpreted their idea of “hacker ethics”. For me, Steven Levy’s tenets encompass them best:
Access to computers – and anything which might teach you something about the way the world works – should be unlimited and total.
All information should be free.
Mistrust authority – promote decentralization.
Hackers should be judged by their hacking, not bogus criteria such as degrees, age, race, or position.
You can create art and beauty on a computer.
Computers can change your life for the better.
Given these concepts as representative of hacker ethics, I’m convinced that hacking remains alive and well today. Hackers continue to be responsible for many of the coolest and
most-important innovations in computing, and are likely to continue to do so. Unlike many other sciences, where progress over the ages has gradually pushed innovators away from
backrooms and garages and into labs to take advantage of increasingly-precise generations of equipment, the tools of computer science are increasingly available to individuals.
More than ever before, bedroom-based hackers are able to get started on their journey with nothing more than a basic laptop or desktop computer and a stack of freely-available
open-source software and documentation. That progress may be threatened by the growth in popularity of easy-to-use (but highly locked-down) tablets and smartphones, but the barrier to
entry is still low enough that most people can pass it, and the new generation of ultra-lightweight computers like the Raspberry Pi are doing
their part to inspire the next generation of hackers, too.
That said, and as much as I personally love and identify with the term “hacker”, the hacker community has never been less in-need of this overarching label. The diverse variety
of types of technologist nowadays coupled with the infiltration of pop culture by geek culture has inevitably diluted only to be replaced with a multitude of others each describing a
narrow but understandable part of the hacker mindset. You can describe yourself today as a coder, gamer, maker, biohacker, upcycler,cracker, blogger, reverse-engineer, social engineer, unconferencer, or one of dozens of other terms that more-specifically ties you to your
community. You’ll be understood and you’ll be elegantly sidestepping the implications of criminality associated with the word “hacker”.
The original meaning of “hacker” has also been soiled from within its community: its biggest and perhaps most-famous
advocate‘s insistence upon linguistic prescriptivism came under fire just this year after he pushed for a dogmatic interpretation of the term “sexual assault” in spite of a victim’s experience.
This seems to be absolutely representative of his general attitudes towards sex, consent,
women, and appropriate professional relationships. Perhaps distancing ourselves from the old definition of the word “hacker” can go hand-in-hand with distancing ourselves from some of
the toxicity in the field of computer science?
(I’m aware that I linked at the top of this blog post to the venerable but also-problematic Eric S. Raymond; if anybody can suggest an equivalent resource by another
author I’d love to swap out the link.)
Verdict: The word “hacker” has become so broad in scope that we’ll never be able to rein it back in. It’s tainted by its associations with both criminality, on one
side, and unpleasant individuals on the other, and it’s time to accept that the popular contemporary meaning has won. Let’s find new words to define ourselves, instead.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
The language we use is always changing, like how the word “cute” was originally a truncation of the word “acute”, which you’d use to describe somebody who was sharp-witted, as in “don’t
get cute with me”. Nowadays, we use it when describing adorable things, like the subject of this GIF:
Cute, but not acute.
But hang on a minute: that’s another word that’s changed meaning: GIF. Want to see how?
GIF
What people think it means
File format (or the files themselves) designed for animations and transparency. Or: any animation without sound.
What it originally meant
File format designed for efficient colour images. Animation was secondary; transparency was an afterthought.
The Past
Back in the 1980s cyberspace was in its infancy. Sir Tim hadn’t yet dreamed up the Web, and the Internet wasn’t something that most
people could connect to, and bulletin board systems (BBSes) –
dial-up services, often local or regional, sometimes connected to one another in one of a variety of ways – dominated the scene. Larger services like CompuServe acted a little like huge
BBSes but with dial-up nodes in multiple countries, helping to bridge the international gaps and provide a lower learning curve
than the smaller boards (albeit for a hefty monthly fee in addition to the costs of the calls). These services would later go on to double as, and eventually become
exclusively, Internet Service Providers, but for the time being they were a force unto themselves.
My favourite bit of this 1983 magazine ad for CompuServe is the fact that it claims a trademark on the word “email”. They didn’t try very hard to cling on to that claim, unlike their
controversial patent on the GIF format…
In 1987, CompuServe were about to start rolling out colour graphics as a new feature, but needed a new graphics format to support that. Their engineer Steve Wilhite had the
idea for a bitmap image format backed by LZW compression
and called it GIF, for Graphics Interchange Format. Each image could be composed of multiple frames each having up to 256
distinct colours (hence the common mistaken belief that a GIF can only have 256 colours). The nature of the palette system
and compression algorithm made GIF a particularly efficient format for (still) images with solid contiguous blocks of
colour, like logos and diagrams, but generally underperformed against cosine-transfer-based algorithms like
JPEG/JFIF for images with gradients (like most
photos).
This animated GIF (of course) shows how it’s possible to have more than 256 colours in a GIF by separating it into multiple non-temporal frames.
GIF would go on to become most famous for two things, neither of which it was capable of upon its initial release: binary
transparency (having “see through” bits, which made it an excellent choice for use on Web pages with background images or non-static background colours; these would become popular in
the mid-1990s) and animation. Animation involves adding a series of frames which overlay one another in sequence: extensions to the format in 1989 allowed the creator to specify the
duration of each frame, making the feature useful (prior to this, they would be displayed as fast as they could be downloaded and interpreted!). In 1995, Netscape added a custom extension to GIF to allow them to
loop (either a specified number of times or indefinitely) and this proved so popular that virtually all other software followed suit, but it’s worth noting that “looping” GIFs have never been part of the official standard!
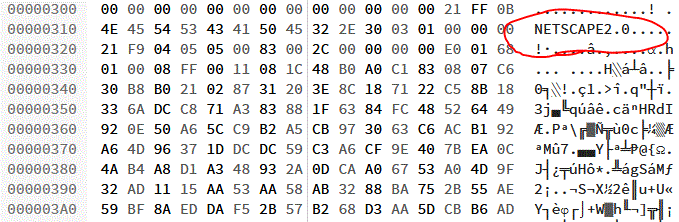
Open almost any animated GIF file in a hex editor and you’ll see the word NETSCAPE2.0; evidence of
Netscape’s role in making animated GIFs what they are today.
Compatibility was an issue. For a period during the mid-nineties it was quite possible that among the visitors to your website there would be a mixture of:
people who wouldn’t see your GIFs at all, owing to browser, bandwidth, preference, or accessibility limitations,
people who would only see the first frame of your animated GIFs, because their browser didn’t support animation,
people who would see your animation play once, because their browser didn’t support looping, and
people who would see your GIFs as you intended, fully looping
This made it hard to depend upon GIFs without carefully considering their use. But people still did, and they just stuck a
button on to warn people, as if that made up for
it. All of this has happened before, etc.
In any case: as better, newer standards like PNG came to dominate the Web’s need for lossless static (optionally
transparent) image transmission, the only thing GIFs remained good for was animation. Standards like APNG/MNG failed to get off the ground, and so GIFs remained the dominant animated-image standard. As Internet connections became faster and faster in the 2000s, they experienced a
resurgence in popularity. The Web didn’t yet have the <video> element and so embedding videos on pages required a mixture of at least two of
<object>, <embed>, Flash, and black magic… but animated GIFs just worked and
soon appeared everywhere.
How animation online really works.
The Future
Nowadays, when people talk about GIFs, they often don’t actually mean GIFs! If you see a GIF on Giphy or WhatsApp, you’re probably actually seeing an MPEG-4 video file with no audio track! Now that Web video
is widely-supported, service providers know that they can save on bandwidth by delivering you actual videos even when you expect a GIF. More than ever before, GIF has become a byword for short, often-looping Internet
animations without sound… even though that’s got little to do with the underlying file format that the name implies.
What’s a web page? What’s anything?
Verdict: We still can’t agree on whether to pronounce it with a soft-G (“jif”), as Wilhite intended, or with a hard-G, as any sane person would, but it seems that GIFs are here to stay
in name even if not in form. And that’s okay. I guess.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
Until the 17th century, to “fathom” something was to embrace it. Nowadays, it’s more likely to refer to your understanding of something in depth. The migration came via the
similarly-named imperial unit of measurement, which was originally defined as the span of a man’s outstretched arms, so you can
understand how we got from one to the other. But you know what I can’t fathom? Broadband.
I can’t fathom dalmatians. But this woman can.
Broadband Internet access has become almost ubiquitous over the last decade and a half, but ask people to define “broadband” and they have a very specific idea about what it means. It’s
not the technical definition, and this re-invention of the word can cause problems.
Broadband
What people think it means
High-speed, always-on Internet access.
What it originally meant
Communications channel capable of multiple different traffic types simultaneously.
The Past
Throughout the 19th century, optical (semaphore) telegraph networks gave way to the new-fangled electrical telegraph, which not only worked regardless of the weather but resulted in
significantly faster transmission. “Faster” here means two distinct things: latency – how long it takes a message to reach its destination, and bandwidth – how much
information can be transmitted at once. If you’re having difficulty understanding the difference, consider this: a man on a horse might be faster than a telegraph if the size of the
message is big enough because a backpack full of scrolls has greater bandwidth than a Morse code pedal, but the latency of an electrical wire beats land transport
every time. Or as Andrew S. Tanenbaum famously put it: Never underestimate the bandwidth of a station wagon full of
tapes hurtling down the highway.
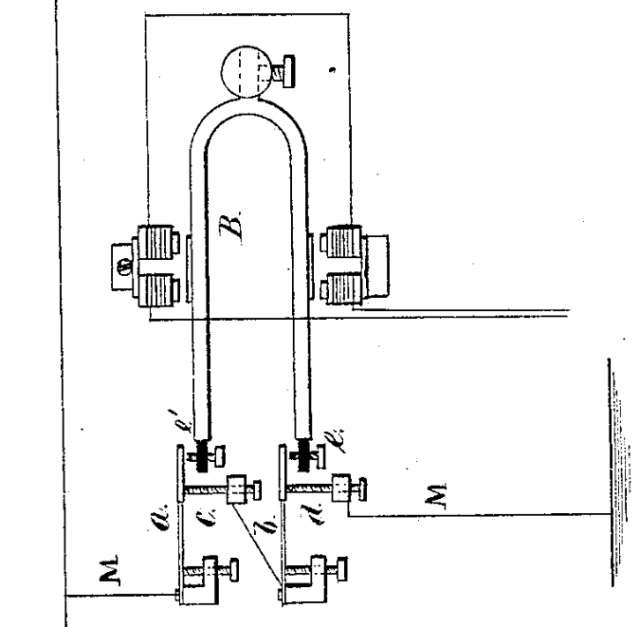
There were transitional periods. This man, photographed in 1912, is relaying a telephone message into a heliograph. I’m not sure
what message he’s transmitting, but I’m guessing it ends with a hashtag.
Telegraph companies were keen to be able to increase their bandwidth – that is, to get more messages on the wire – and this was achieved by multiplexing. The simplest approach,
time-division multiplexing, involves messages (or parts of messages) “taking turns”, and doesn’t actually increase bandwidth at all: although it does improve the perception of
speed by giving recipients the start of their messages early on. A variety of other multiplexing techniques were (and continue to be) explored, but the one that’s most-interesting to us
right now was called acoustic telegraphy: today, we’d call it frequency-division multiplexing.
What if, asked folks-you’ll-have-heard-of like Thomas Edison and Alexander Graham Bell, we were to send telegraph messages down the line at different frequencies. Some beeps and bips
would be high tones, and some would be low tones, and a machine at the receiving end could separate them out again (so long as you chose your frequencies carefully, to avoid harmonic
distortion). As might be clear from the names I dropped earlier, this approach – sending sound down a telegraph wire – ultimately led to the invention of the
telephone. Hurrah, I’m sure they all immediately called one another to say, our efforts to create a higher-bandwidth medium for telegrams has accidentally resulted in a
lower-bandwidth (but more-convenient!) way for people to communicate. Job’s a good ‘un.
If this part of Edison’s 1878 patent looks like a tuning fork, that’s not a coincidence. These early multiplexers made distinct humming sounds as they operated, owing to the movement
of the synchronised forks within.
Most electronic communications systems that have ever existed have been narrowband: they’ve been capable of only a single kind of transmission at a time. Even if you’re
multiplexing a dozen different frequencies to carry a dozen different telegraph messages at once, you’re still only transmitting telegraph messages. For the most part, that’s
fine: we’re pretty clever and we can find workarounds when we need them. For example, when we started wanting to be able to send data to one another (because computers are cool now)
over telephone wires (which are conveniently everywhere), we did so by teaching our computers to make sounds and understand one another’s sounds. If you’re old enough to have heard
a fax machine call a landline or, better yet used a dial-up modem, you know what I’m talking about.
As the Internet became more and more critical to business and home life, and the limitations (of bandwidth and convenience) of dial-up access became increasingly questionable,
a better solution was needed. Bringing broadband to Internet access was necessary, but the technologies involved weren’t revolutionary: they were just the result of the application of a
little imagination.
I’ve felt your pain, Dawson. I’ve felt your pain.
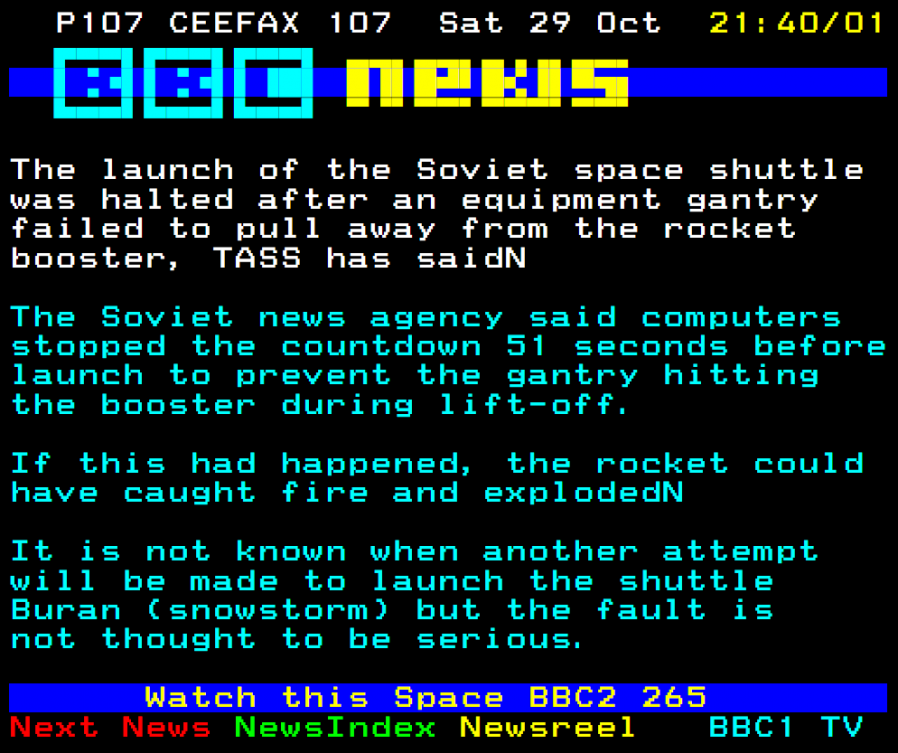
We’d seen this kind of imagination before. Consider teletext, for example (for those of you too young to remember teletext, it was a
standard for browsing pages of text and simple graphics using an 70s-90s analogue television), which is – strictly speaking – a broadband technology. Teletext works by embedding pages
of digital data, encoded in an analogue stream, in the otherwise-“wasted” space in-between frames of broadcast video. When you told your television to show you a particular page, either
by entering its three-digit number or by following one of four colour-coded hyperlinks, your television would wait until the page you were looking for came around again in the
broadcast stream, decode it, and show it to you.
Teletext was, fundamentally, broadband. In addition to carrying television pictures and audio, the same radio wave was being used to transmit text: not pictures of text, but
encoded characters. Analogue subtitles (which used basically the same technology): also broadband. Broadband doesn’t have to mean “Internet access”, and indeed for much of its history,
it hasn’t.
My family started getting our news via broadband in about 1985. Not broadband Internet, but broadband nonetheless.
Here in the UK, ISDN (from 1988!) and later ADSL would be the first widespread technologies to provide broadband data connections over the copper wires simultaneously used to
carry telephone calls. ADSL does this in basically the same way as Edison and Bell’s acoustic telegraphy: a portion
of the available frequencies (usually the first 4MHz) is reserved for telephone calls, followed by a no-mans-land band, followed by two frequency bands of different sizes (hence the
asymmetry: the A in ADSL) for up- and downstream data. This, at last, allowed true “broadband Internet”.
But was it fast? Well, relative to dial-up, certainly… but the essential nature of broadband technologies is that they share the bandwidth with other services. A connection
that doesn’t have to share will always have more bandwidth, all other things being equal! Leased lines, despite
technically being a narrowband technology, necessarily outperform broadband connections having the same total bandwidth because they don’t have to share it with other services. And
don’t forget that not all speed is created equal: satellite Internet access is a narrowband technology with excellent bandwidth… but sometimes-problematic latency issues!
Did you have one of these tucked behind your naughties router? This box filtered out the data from the telephone frequencies, helping to ensure that you can neither hear the pops and
clicks of your ADSL connection nor interfere with it by shouting.
Equating the word “broadband” with speed is based on a consumer-centric misunderstanding about what broadband is, because it’s necessarily true that if your home “broadband” weren’t
configured to be able to support old-fashioned telephone calls, it’d be (a) (slightly) faster, and (b) not-broadband.
The Future
But does the word that people use to refer to their high-speed Internet connection matter. More than you’d think: various countries around the world have begun to make legal
definitions of the word “broadband” based not on the technical meaning but on the populist one, and it’s becoming a source of friction. In the USA, the FCC variously defines broadband as having a minimum download speed of
10Mbps or 25Mbps, among other characteristics (they seem to use the former when protecting consumer rights and the latter when reporting on penetration, and you can read into that what
you will). In the UK, Ofcom‘s regulations differentiate between “decent” (yes, that’s really the word they use) and “superfast” broadband at
10Mbps and 24Mbps download speeds, respectively, while the Scottish and Welsh governments as well as the EU say it must be 30Mbps to be
“superfast broadband”.
At full-tilt, going from 10Mbps to 24Mbps means taking only 4 seconds, rather than 11 seconds, to download the music video to Faster! Harder! Scooter!
I’m all in favour of regulation that protects consumers and makes it easier for them to compare products. It’s a little messy that definitions vary so widely on what different speeds
mean, but that’s not the biggest problem. I don’t even mind that these agencies have all given themselves very little breathing room for the future: where do you go after “superfast”?
Ultrafast (actually, that’s exactly where we go)? Megafast? Ludicrous speed?
What I mind is the redefining of a useful term to differentiate whether a connection is shared with other services or not to be tied to a completely independent characteristic of that
connection. It’d have been simple for the FCC, for example, to have defined e.g. “full-speed broadband” as
providing a particular bandwidth.
Verdict: It’s not a big deal; I should just chill out. I’m probably going to have to throw in the towel anyway on this one and join the masses in calling all high-speed
Internet connections “broadband” and not using that word for all slower and non-Internet connections, regardless of how they’re set up.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
A few hundred years ago, the words “awesome” and “awful” were synonyms. From their roots, you can see why: they mean “tending to or causing awe” and “full or or characterised by awe”,
respectively. Nowadays, though, they’re opposites, and it’s pretty awesome to see how our language continues to evolve. You know what’s awful, though? Computer viruses. Right?
“Oh no! A virus has stolen all my selfies and uploaded them to a stock photos site!”
You know what I mean by a virus, right? A malicious computer program bent on causing destruction, spying on your online activity, encrypting your files and ransoming them back to you,
showing you unwanted ads, etc… but hang on: that’s not right at all…
Virus
What people think it means
Malicious or unwanted computer software designed to cause trouble/commit crimes.
What it originally meant
Computer software that hides its code inside programs and, when they’re run, copies itself into other programs.
The Past
Only a hundred and thirty years ago it was still widely believed that “bad air” was the principal cause of disease. The idea that tiny germs could be the cause of infection was only
just beginning to take hold. It was in this environment that the excellent scientist Ernest Hankin travelled around
India studying outbreaks of disease and promoting germ theory by demonstrating that boiling water prevented cholera by killing the (newly-discovered) vibrio cholerae bacterium.
But his most-important discovery was that water from a certain part of the Ganges seemed to be naturally inviable as a home for vibrio cholerae… and that boiling this
water removed this superpower, allowing the special water to begin to once again culture the bacterium.
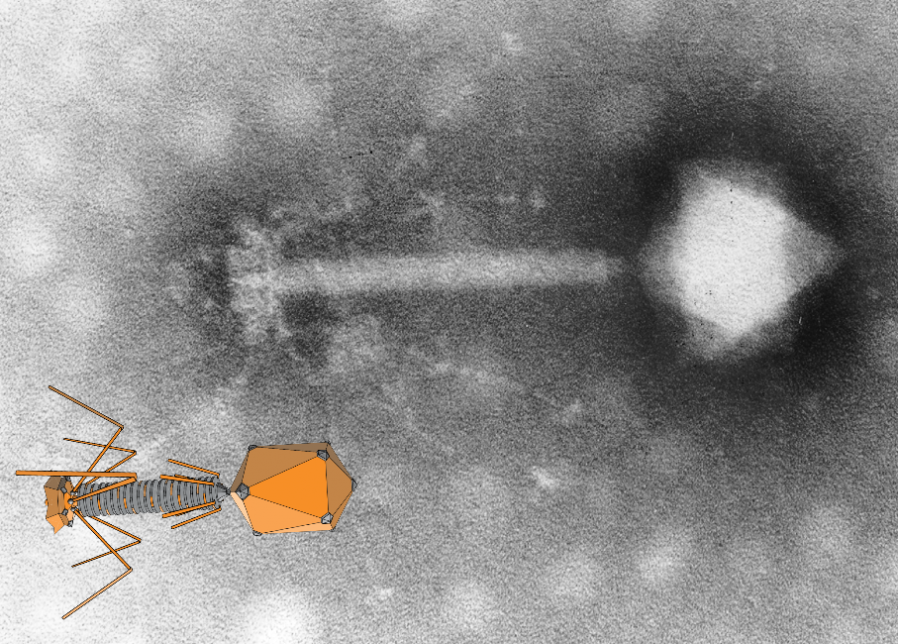
Hankin correctly theorised that there was something in that water that preyed upon vibrio cholerae; something too small to see with a microscope. In doing so, he was probably
the first person to identify what we now call a bacteriophage: the most common kind of virus. Bacteriophages were briefly seen as exciting for their medical potential. But then
in the 1940s antibiotics, which were seen as far more-convenient, began to be manufactured in bulk, and we stopped seriously looking at “phage therapy” (interestingly, phages are seeing a bit of a resurgence as antibiotic resistance becomes increasingly problematic).
It took until the development of the scanning electron microscope in the mid-20th century before we’d actually “see” a virus.
But the important discovery kicked-off by the early observations of Hankin and others was that viruses exist. Later, researchers would discover how these viruses
work1:
they inject their genetic material into cells, and this injected “code” supplants the unfortunate cell’s usual processes. The cell is “reprogrammed” – sometimes after a dormant
period – to churns out more of the virus, becoming a “virus factory”.
Let’s switch to computer science. Legendary mathematician John von Neumann, fresh from showing off his expertise in
calculating how shaped charges should be used to build the first atomic bombs, invented the new field of cellular autonoma. Cellular autonoma are computationally-logical,
independent entities that exhibit complex behaviour through their interactions, but if you’ve come across them before now it’s probably because you played Conway’s Game of Life, which made the concept popular decades after their invention. Von Neumann was very interested
in how ideas from biology could be applied to computer science, and is credited with being the first person to come up with the idea of a self-replicating computer program which would
write-out its own instructions to other parts of memory to be executed later: the concept of the first computer virus.
This is a glider factory… factory. I remember the first time I saw this pattern, in the 1980s, and it sank in for me that cellular autonoma must logically be capable of any
arbitrary level of complexity. I never built a factory-factory-factory, but I’ll bet that others have.
Retroactively-written lists of early computer viruses often identify 1971’s Creeper as the first computer virus:
it was a program which, when run, moved (later copied) itself to another computer on the network and showed the message “I’m the creeper: catch me if you can”. It was swiftly followed
by a similar program, Reaper, which replicated in a similar way but instead of displaying a message attempted to
delete any copies of Creeper that it found. However, Creeper and Reaper weren’t described as viruses at the time and would be more-accurately termed
worms nowadays: self-replicating network programs that don’t inject their code into other programs. An interesting thing to note about them, though, is that – contrary
to popular conception of a “virus” – neither intended to cause any harm: Creeper‘s entire payload was a relatively-harmless message, and Reaper actually tried to do
good by removing presumed-unwanted software.
Another early example that appears in so-called “virus timelines” came in 1975. ANIMAL presented as a twenty
questions-style guessing game. But while the user played it would try to copy itself into another user’s directory, spreading itself (we didn’t really do directory permissions back
then). Again, this wasn’t really a “virus” but would be better termed a trojan: a program which pretends to be something that it’s not.
“Malware? Me? No siree… nothing here but this big executable horse.”
It took until 1983 before Fred Cooper gave us a modern definition of a computer virus, one which – ignoring usage by laypeople –
stands to this day:
A program which can ‘infect’ other programs by modifying them to include a possibly evolved copy of itself… every program that gets infected may also act as a virus and thus the
infection grows.
This definition helps distinguish between merely self-replicating programs like those seen before and a new, theoretical class of programs that would modify host programs such
that – typically in addition to the host programs’ normal behaviour – further programs would be similarly modified. Not content with leaving this as a theoretical, Cooper wrote the
first “true” computer virus to demonstrate his work (it was never released into the wild): he also managed to prove that there can be no such thing as perfect virus detection.
(Quick side-note: I’m sure we’re all on the same page about the evolution of language here, but for the love of god don’t say viri. Certainly don’t say virii.
The correct plural is clearly viruses. The Latin root virus is a mass noun and so has no plural, unlike e.g.
fungus/fungi, and so its adoption into a count-noun in English represents the creation of a new word which should therefore, without a precedent to the
contrary, favour English pluralisation rules. A parallel would be bonus, which shares virus‘s linguistic path, word ending, and countability-in-Latin: you wouldn’t say
“there were end-of-year boni for everybody in my department”, would you? No. So don’t say viri either.)
No, no, no, no, no. The only wholly-accurate part of this definition is the word “program”.
Viruses came into their own as computers became standardised and commonplace and as communication between them (either by removable media or network/dial-up connections) and Cooper’s
theoretical concepts became very much real. In 1986, The Virdim method brought infectious viruses to the DOS platform, opening up virus writers’ access to much of the rapidly growing business and home computer markets.
The Virdim method has two parts: (a) appending the viral code to the end of the program to be infected, and (b) injecting early into the program a call to the appended code. This
exploits the typical layout of most DOS executable files and ensures that the viral code is run first, as an infected program
loads, and the virus can spread rapidly through a system. The appearance of this method at a time when hard drives were uncommon and so many programs would be run from floppy disks
(which could be easily passed around between users) enabled this kind of virus to spread rapidly.
For the most part, early viruses were not malicious. They usually only caused harm as a side-effect (as we’ve already seen, some – like Reaper – were intended to be not just
benign but benevolent). For example, programs might run slower if they’re also busy adding viral code to other programs, or a badly-implemented virus might
even cause software to crash. But it didn’t take long before viruses started to be used for malicious purposes – pranks, adware, spyware, data ransom, etc. – as well as to carry
political messages or to conduct cyberwarfare.
XKCD already explained all of this in far fewer words and a diagram.
The Future
Nowadays, though, viruses are becoming less-common. Wait, what?
Yup, you heard me right: new viruses aren’t being produced at remotely the same kind of rate as they were even in the 1990s. And it’s not that they’re easier for security software to
catch and quarantine; if anything, they’re less-detectable as more and more different types of file are nominally “executable” on a typical computer, and widespread access to
powerful cryptography has made it easier than ever for a virus to hide itself in the increasingly-sprawling binaries that litter modern computers.
Soo… I click this and all the viruses go away, right? Why didn’t we do this sooner?
The single biggest reason that virus writing is on the decline is, in my opinion, that writing something as complex as a a virus is longer a necessary step to illicitly getting your
program onto other people’s computers2!
Nowadays, it’s far easier to write a trojan (e.g. a fake Flash update, dodgy spam attachment, browser toolbar, or a viral free game) and trick people into running it… or else to write a
worm that exploits some weakness in an open network interface. Or, in a recent twist, to just add your code to a popular library and let overworked software engineers include it in
their projects for you. Modern operating systems make it easy to have your malware run every time they boot and it’ll quickly get lost amongst the noise of all the
other (hopefully-legitimate) programs running alongside it.
In short: there’s simply no need to have your code hide itself inside somebody else’s compiled program any more. Users will run your software anyway, and you often don’t even
have to work very hard to trick them into doing so.
Verdict: Let’s promote use of the word “malware” instead of “virus” for popular use. It’s more technically-accurate in the vast majority of cases, and it’s actually a
more-useful term too.
Footnotes
1 Actually, not all viruses work this way. (Biological) viruses are, it turns out, really
really complicated and we’re only just beginning to understand them. Computer viruses, though, we’ve got a solid understanding of.
2 There are other reasons, such as the increase in use of cryptographically-signed
binaries, protected memory space/”execute bits”, and so on, but the trend away from traditional viruses and towards trojans for delivery of malicious payloads began long before these
features became commonplace.
The tradition of buying cheap, joke souvenirs for your loved ones while travelling dates back at least two millennia.
During an archaeological excavation at a Roman-era site in London, researchers found around 200 iron styluses used for writing on wax-filled wooden tablets. One of those styluses,
which just debuted in its first public exhibition, holds a message written in tiny lettering along its sides. The inscription’s sentiment, according to the researchers who translated it, is
essentially, “I went to Rome and all I got you was this pen.”
…
Also found in this excavation, I assume, were t-shirts printed with “I ❤ Pompeii” and moneyboxes in the shape of the Parthenon.
Let’s talk about the point after WW2 where the Knights Hospitaller, of medieval crusading fame, ‘accidentally’ became a major European air power.
I shitteth ye not. ?️?️
So, if I asked you to imagine the Knights Hospitaller you probably picture:
1) Angry Christians on armoured horses
2) Them being wiped out long ago like the Templars.
3) Some Dan Brown bullshit
And you would be (mostly) wrong about all three. Which is sort of how this happened.
From the beginning (1113 or so), the Hospitallers were never quite as committed to the angry, horsey thing as the Templars. They had always (ostensibly) been more about
protecting pilgrims and healthcare.
They also quite liked boats. Which were useful for both.
Over the next 150 years (or so), as the Christian grip on the Holy Lands waned, both military orders got more involved in their other hobbies – banking for the Templars, mucking
around in boats for the Hospitaller.
This proved to be a surprisingly wise decision on the Hospitaller part. By 1290ish, both Orders were homeless and weakened.
As the Templars fatally discovered, being weak AND having the King of France owe you money is a bad combo.
Being a useful NAVY, however, wins you friends.
And this is why your first vision of the Hospitallers is wrong. Because they spent the next 500 YEARS, backed by France and Spain, as one of the most powerful naval forces in
the Mediterranean, blocking efforts by the Ottomans to expand westwards by sea.
To give you an idea of the trouble they caused: in 1480 Mehmet II sent 70,000 men (against the Knights 4000) to try and boot them out of Rhodes. He failed.
Suleiman the Magnificent FINALLY managed it in 1522 with 200,000 men. But even he had to agree to let the survivors leave.
The surviving Hospitallers hopped on their ships (again) and sailed away. After some vigorous lobbying, in 1530 the King of Spain agreed to rent them Malta, in return for a
single maltese falcon every year.
Because that’s how good rents were pre-housing crisis in Europe.
The Knights turned Malta into ANOTHER fortified island. For the next 200 years ‘the Pope’s own navy’ waged a war of piracy, slavery and (occasionally) pitched sea battles
against the Ottomans.
From Malta, they blocked Ottoman strategic access to the western med. A point that was not lost on the Ottomans, who sent 40,000 men to try and take the island in 1565 – the
‘Great Siege of Malta’.
The Knights, fighting almost to the last man, held out and won.
Now the important thing here is the CONTINUED EXISTENCE AS A SOVEREIGN STATE of the Knights Hospitaller. They held Malta right up until 1798, when Napoleon finally managed to
boot them out on his way to Egypt.
(Partly because the French contingent of the Knights swapped sides)
The British turned up about three months later and the French were sent packing, but, well, It was the British so:
THE KNIGHTS: Can we have our strategically important island back please?
THE BRITISH: What island?
THE KNIGHT: That island
THE BRITISH: Nope. Can’t see an island
After the Napoleonic wars no one really wanted to bring up the whole Malta thing with the British (the Putin’s Russia of the era) so the European powers fudged it. They said the
Knights were still a sovereign state and they tried to sort them out with a new country. But never did
The Russian Emperor let them hang out in St Petersburg for a while, but that was awkward (Catholicism vs Orthodox). Then the Swedes were persuaded to offer them Gotland.
But every offer was conditional on the Knights dropping their claim to Malta. Which they REFUSED to do.
~ wobbly lines ~
It’s the 1900s. The Knights are still a stateless state complaining about Malta. What that means legally is a can of worms NO ONE wants to open in international law but
they’ve also rediscovered their original mission (healthcare) so everyone kinda ignores them
The Knights become a pseudo-Red Cross organisation. In WW1 they run ambulance trains and have medical battalions, loosely affiliated with the Italian army (still do). In WW2
they do it too.
Italy surrenders. The allies move on then…
Oh dear.
Who wrote this peace deal again?
It turns out the Treaty of Peace with Italy should go FIRMLY into the category of ‘things that seemed a good idea at the time’.
This is because it presupposes that relations between the west and the Soviets will be good, and so limits Italy’s MILITARY.
This is a problem.
Because as the early Cold War ramps up, the US needs to build up its Euro allies ASAP.
But the treaty limits the Italians to 400 airframes, and bans them from owning ANYTHING that might be a bomber.
This can be changed, but not QUICKLY.
Then someone remembers about the Knights
The Knights might not have any GEOGRAPHY, but because everyone avoided dealing with the tricky international law problem it can be argued – with a straight face – that they are
still TECHNICALLY A EUROPEAN SOVEREIGN STATE.
And they’re not bound by the WW2 peace treaty.
Italy (with US/UK/French blessing) approaches the Knights and explains the problem.
The Knights reasonably point out that they’re not in the business of fighting wars anymore, but anything that could be called a SUPPORT aircraft is another matter.
So, in the aftermath of WW2, this is the ballet that happens:
The Italians transfer all of their support and training aircraft to the Knights.
This then frees up the ‘cap room’ to allow the US to boost Italy’s warfighting ability WITHOUT breaking the WW2 peace treaty.
This is why, in the late forties/fifties, a good chunk of the ‘Italian’ air force is flying with a Maltese Cross Roundel.
Because they were not TECHNICALLY Italian. They were the air force of the Sovereign Military Order of Malta.
And that’s how the Knights Hospitaller ended up becoming a major air power.
Eventually the treaties were reworked, and everything was quietly transferred back. I suspect it’s a reason why the sovereign status of the Knights remains unchallenged still
today though.
And that’s why today, even thought they are now fully committed to the Red-Cross-esque stuff, they can still issue passports, are a permanent observer at the UN, have a
currency…
You could fit almost the entire history of videogames into the time span covered by the silent film era, yet we consider it a mature medium, rather than one just breaking out of its
infancy. Like silent movies, classic games are often incomplete, damaged, or technically limited, but have a beauty all their own. In this spirit, indie game developer Joe Blair and I
built Metropoloid, a remix of Fritz Lang’s Metropolis which replaces its famously lost score with that of its contemporaries from the early days of games.
I’ve watched Metropolis a number of times over the decades, in a variety of the stages of its recovery, and I
love it. I’ve watched it with a pre-recorded but believed-to-be-faithful soundtrack and I’ve watched it with several diolive accompaniment. But this is the first time I’ve watched it to
the soundtrack of classic (and contemporary-retro) videogames: the Metroid, Castlevania, Zelda, Mega Man and Final Fantasy
series, Doom,Kirby, F-Zero and more. If you’ve got a couple of hours to spare and a love of classic film and classic videogames, then you’re in
the slim minority that will get the most out of this fabulous labour of love (which, at the time of my writing, has enjoyed only a few hundred views and a mere 26 “thumbs up”: it
certainly deserves a wider audience!).
Hi @avapoet, I’m the author of the JavaScript for the WorldWideWeb project, and I did read your thread on the user-agent missing and I thought I’d land the fix ;-)
The original WorldWideWeb browser that we based our work on was 0.12 with screenshots from 0.16. Both browsers supported HTTP 0.9 which didn’t send headers. Obviously unintentional
that I send the `request` user-agent, so I spent some painful hours trying to get my emulator running NeXT with a networked connection _and_ the WorldWideWeb version 1.0 – which
_did_ use HTTP 1.0 and would send a User-Agent, so I could copy it accurately into the emulator code base.
So now metafilter.com renders in the emulator, and the User Agent sent is: CERN-NextStep-WorldWideWeb.app/1.1 libwww/2.07
This comment on the MetaFilter thread, which I only just noticed, is by Remy Sharp, who was part of the team that reimplemented WorldWideWeb as part
of that hackathon (his blog posts about the experience: 1, 2,
3, 4, 5),
and acknowledges my contribution. Squee!






![[Animated GIF] Puppy flumps onto a human.](https://bcdn.danq.me/_q23u/2019/09/cute-puppy.gif)