I’ve never been even remotely into Sex and the City. But I can’t help but love that this developer was so invested in the characters and their relationships that when
he asked himself “couldn’t all this drama and heartache have been simplified if these characters were willing to consider polyamorous relationships rather than serial
monogamy?”1,
he did the maths to optimise his hypothetical fanfic polycule:
As if his talk at !!Con 2024 wasn’t cool enough, he open-sourced the whole thing, so you’re free to try the calculator online for yourself or expand upon or adapt it to your heart’s content. Perhaps you disagree with his assessment of the
relative relationship characteristics of the characters2: tweak them and
see what the result is!
Or maybe Sex and the City isn’t your thing at all? Well adapt it for whatever your fandom is! How I Met Your Mother,Dawson’s Creek, Mamma
Mia and The L-Word were all crying out for polyamory to come and “fix” them3.
Perhaps if you’re feeling especially brave you’ll put yourself and your circles of friends, lovers, metamours, or whatever into the algorithm and see who it matches up. You never know,
maybe there’s a love connection you’ve missed! (Just be ready for the possibility that it’ll tell you that you’re doing your love life “wrong”!)
Footnotes
1 This is a question I routinely find myself asking of every TV show that presents a love
triangle as a fait accompli resulting from an even moderately-complex who’s-attracted-to-whom.
2 Clearly somebody does, based on his commit “against his will” that increases Carrie and Big’s
validatesOthers scores and reduces Big’s prioritizesKindness.
3 I was especially disappointed with the otherwise-excellent The L-Word, which
did have a go at an ethical non-monogamy storyline but bungled the “ethical” at every hurdle while simultaneously reinforcing the “insatiable bisexual” stereotype. Boo!
Anyway: maybe on my next re-watch I’ll feed some numbers into Juan’s algorithm and see what comes out…
Ever wondered why Oxford’s area code is 01865? The story is more-complicated than you’d think.
As a child, I was told that city STD codes were usually associated to the letters that appear on some telephones… but that
wouldn’t make any sense for Oxford’s code!
I’ll share the story on my blog, of course. But before then, I’ll be telling it from the stage of the Jericho Tavern at 21:15 on Wednesday 17 April as
my third(?) appearance at Oxford Geek Nights! So if you’re interested in learning about some of the quirks of UK telephone numbering
history, I can guarantee that this party’s the only one to be at that Wednesday night!
Not your jam? That’s okay: there’s plenty of more-talented people than I who’ll be speaking, about subjects as diverse as quantum computing with QATboxen, bringing your D&D experience to stakeholder management (!), video games
without screens, learnings from the Horizon scandal, and whatever Freyja Domville means by The Unreasonable Effectiveness of the Scientific Method (but I’m seriously excited by that title).
Anyway: I hope you’ll be coming along to Oxford Geek Nights 57 next month, if not to hear me witter on about the
fossils in our telecommunications networks then to enjoy a beer and hear from the amazing speakers I’ll be sharing the stage with. The event’s always a blast, and I’m looking forward to
seeing you there!
Conveniently just-over-A5 sized, each of the two volumes is light enough to read in bed without uncomfortably clonking yourself in the face.
Set in the early-to-mid-1990s world in which the BBS is still alive and kicking, and the Internet’s gaining traction but still
lacks the “killer app” that will someday be the Web (which is still new and not widely-available), the story follows a handful of teenagers trying to find their place in the world.
Meeting one another in the 90s explosion of cyberspace, they find online communities that provide connections that they’re unable to make out in meatspace.
I loved some of the contemporary nerdy references, like the fact that each chapter page sports the “Geek Code” of the character upon which that chapter focusses.1So yeah: the whole thing feels like a trip back into the naivety of the online world of the last millenium, where small, disparate (and often local) communities flourished and
early netiquette found its feet. Reading Incredible Doom provides the same kind of nostalgia as, say, an afternoon spent on textfiles.com. But
it’s got more than that, too.
The user interfaces of IRC, Pine, ASCII-art-laden BBS menus etc. are all produced with
a good eye for accuracy, but don’t be fooled: this is a story about humans, not computers. My 9-year-old loved it too, and she’s never even heard of IRC (I hope!).
It touches on experiences of 90s cyberspace that, for many of us, were very definitely real. And while my online “scene” at around the time that the story is set might have been
different from that of the protagonists, there’s enough of an overlap that it felt startlingly real and believable. The online world in which I – like the characters in the story – hung
out… but which occupied a strange limbo-space: both anonymous and separate from the real world but also interpersonal and authentic; a frontier in which we were still working out the
rules but within which we still found common bonds and ideals.
Having had times in the 90s that I met up offline with relative strangers whom I first met online, I can confirm that… yeah, the fear is real!
Anyway, this is all a long-winded way of saying that Incredible Doom is a lot of fun and if it sounds like your cup of tea, you should read it.
Also: shortly after putting the second volume down, I ended up updating my Geek Code for the first time in… ooh, well over a decade. The standards have moved on a little (not entirely
in a good way, I feel; also they’ve diverged somewhat), but here’s my attempt:
----- BEGIN GEEK CODE VERSION 6.0 -----
GCS^$/SS^/FS^>AT A++ B+:+:_:+:_ C-(--) D:+ CM+++ MW+++>++
ULD++ MC+ LRu+>++/js+/php+/sql+/bash/go/j/P/py-/!vb PGP++
G:Dan-Q E H+ PS++ PE++ TBG/FF+/RM+ RPG++ BK+>++ K!D/X+ R@ he/him!
----- END GEEK CODE VERSION 6.0 -----
Footnotes
1 I was amazed to discover that I could still remember most of my Geek Code
syntax and only had to look up a few components to refresh my memory.
On Wednesday this week, three years and two months after Oxford Geek Nights #51, Oxford Geek Night
#52. Originally scheduled for 15 April 2020 and then… postponed slightly because of the pandemic, its reapparance was an epic moment that I’m glad to have been a part of.
A particular highlight of the night was witnessing “Gasman”Matt Westcott show off his
epic demoscene contribution Pharmageddon, which is presented via a “pharmacy sign”. Here’s a video, if you’re interested.
Ben Foxall also put in a sterling performance; hearing him talk – as usual – made me say “wow, I didn’t know you could do that with a
web browser”. And there was more to learn, too: Jake Howard showed us how robots see, Steve Buckley inspired us to think about how technology can make our homes more energy-smart (this is really cool and sent me
down a rabbithole of reading!), and Joe Wass showed adorable pictures of his kid exploring the user interface of his lockdown electronics
project.
Oh, and there was a quiz competition too, and guess who came out on top after an incredibly tight race.
But mostly I just loved the chance to hang out with geeks again; chat to folks, make connections, and enjoy that special Oxford Geek Nights atmosphere. Also great to meet somebody from
Perspectum, who look like they’d be great to work for and – after hearing about – I had in mind somebody to suggest for a job with them… but it
looks like the company isn’t looking for anybody with their particular skills on this side of the pond. Still, one to watch.
My prize for winning the competition was an extremely-limited-edition cap which I love so much I’ve barely taken it off since.
Huge thanks are due to Torchbox, Perspectum and everybody in attendance for making this magical night possible!
Oh, and for anybody who’s interested, I’ve proposed to be a speaker at the next Oxford Geek Nights, which sounds like it’ll be towards Spring 2023. My title is
“Yesterday’s Internet, Today!” which – spoilers! – might have something to do with the kind of technology I’ve been playing with recently, among other things. Hope to see you there!
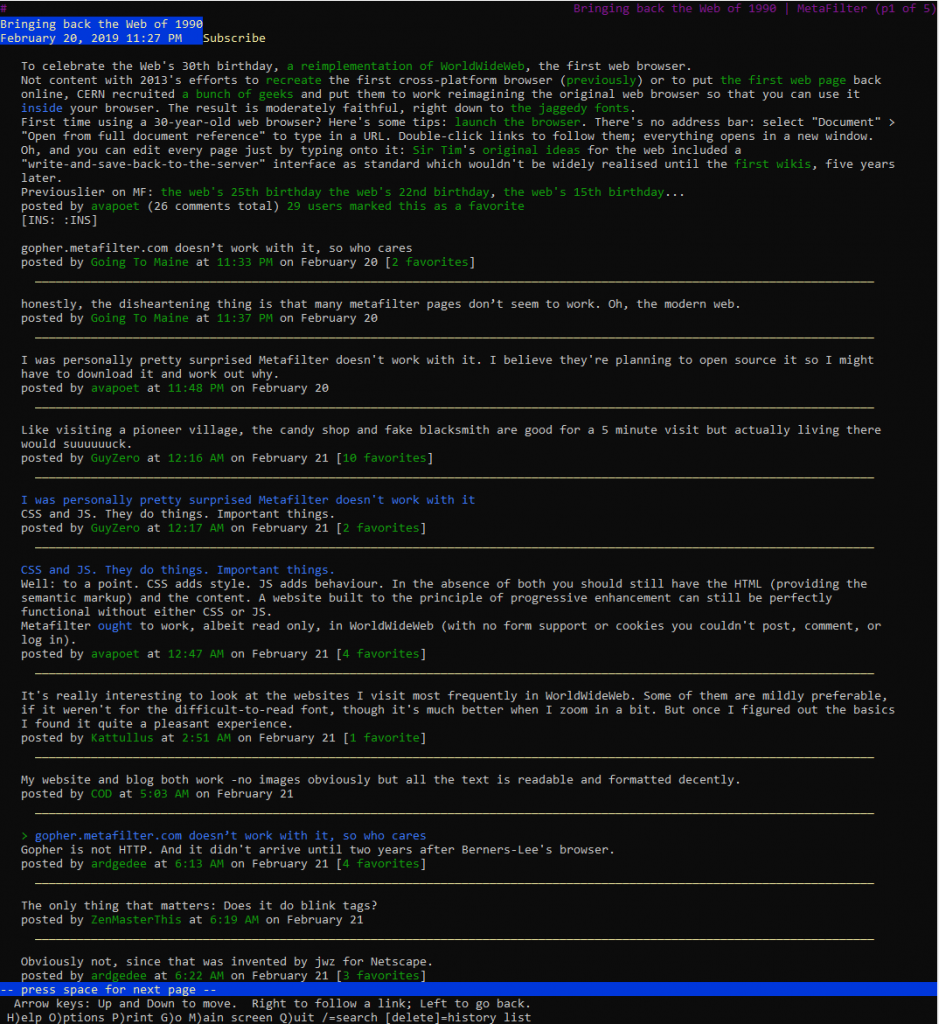
People were quick to point this out and assume that it was something to do with the modernity of MetaFilter:
honestly, the disheartening thing is that many metafilter pages don’t seem to work. Oh, the modern web.
Some even went so far as to speculate that the reason related to MetaFilter’s use of CSS and JS:
CSS and JS. They do things. Important things.
This is, of course, complete baloney, and it’s easy to prove to oneself. Firstly, simply using the View Source tool in your browser on a MetaFilter page reveals source code that’s quite
comprehensible, even human-readable, without going anywhere near any CSS or JavaScript.
As late as the early 2000s I’d occasionally use Lynx for serious browsing, but any time I’ve used it since it’s been by necessity.
Secondly, it’s pretty simple to try browsing MetaFilter without CSS or JavaScript enabled! I tried in two ways: first,
by using Lynx, a text-based browser that’s never supported either of those technologies. I also tried by using
Firefox but with them disabled (honestly, I slightly miss when the Web used to look like this):
It only took me three clicks to disable stylesheets and JavaScript in my copy of Firefox… but I’ll be the first to admit that I don’t keep my browser configured like “normal people”
probably do.
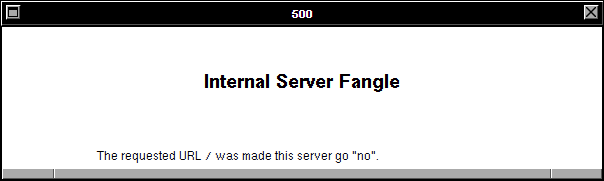
And thirdly: the error code being returned by the simulated WorldWideWeb browser is a HTTP code 500. Even if you don’t
know your HTTP codes (I mean, what kind of weirdo would take the time to memorise them all anyway <ahem>),
it’s worth learning this: the first digit of a HTTP response code tells you what happened:
1xx means “everything’s fine, keep going”;
2xx means “everything’s fine and we’re done”;
3xx means “try over there”;
4xx means “you did something wrong” (the infamous 404, for example, means you asked for a page that doesn’t exist);
5xx means “the server did something wrong”.
Simple! The fact that the error code begins with a 5 strongly implies that the problem isn’t in the (client-side) reimplementation of WorldWideWeb: if this had have been a
CSS/JS problem, I’d expect to see a blank page, scrambled content, “filler”
content, or incomplete content.
So I found myself wondering what the real problem was. This is, of course, where my geek flag becomes most-visible: what we’re talking about, let’s not forget, is a fringe
problem in an incomplete simulation of an ancient computer program that nobody uses. Odds are incredibly good that nobody on Earth cares about this except, right now, for me.
I searched for a “Geek Flag” and didn’t like anything I saw, so I came up with this one based on… well, if you recognise what it’s based on, good for you, you’re certainly allowed to
fly it. If not… well, you can too: there’s no geek-gatekeeping here.
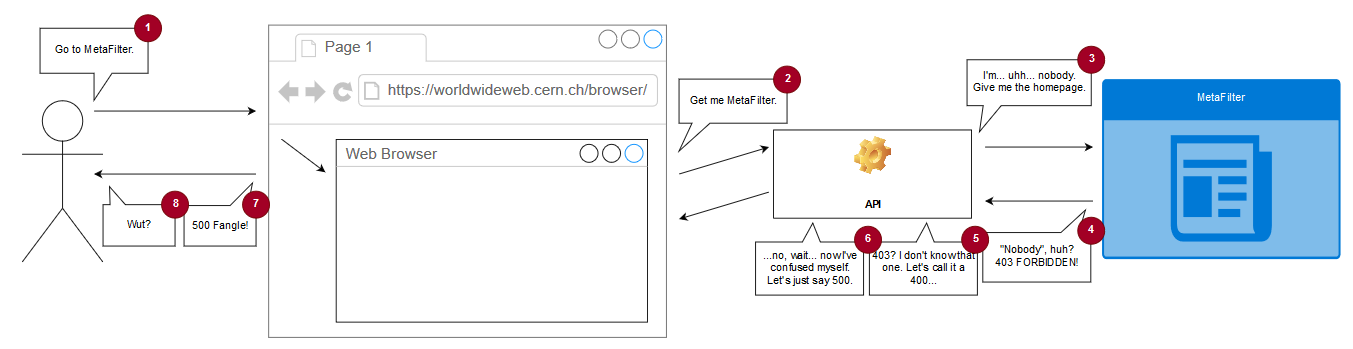
The (simulated) copy of WorldWideWeb is asked to open a document by reference, e.g. “https://www.metafilter.com/”.
To work around same-origin policy restrictions, the request is sent to an API which acts as a proxy server.
The API makes a request using the Node package “request” with this line of code: request(url, (error, response, body) =>
{ ... }). When the first parameter to request is a (string) URL, the module uses its default settings for all of
the other options, which means that it doesn’t set the User-Agent header (an optional part of a Web request where the computer making the request identifies the software
that’s asking).
MetaFilter, for some reason, blocks requests whose User-Agent isn’t set. This is weird! And nonstandard: while web browsers should – in RFC2119 terms – set their User-Agent: header, web servers shouldn’t require
that they do so. MetaFilter returns a 403 and a message to say “Forbidden”; usually a message you only see if you’re trying to access a resource that requires session authentication and
you haven’t logged-in yet.
The API is programmed to handle response codes 200 (okay!) and 404 (not found), but if it gets anything else back
it’s supposed to throw a 400 (bad request). Except there’s a bug: when trying to throw a 400, it requires that an error message has been set by the request module and if there
hasn’t… it instead throws a 500 with the message “Internal Server Fangle” and no clue what actually went wrong. So MetaFilter’s 403 gets translated by the proxy into a 400 which
it fails to render because a 403 doesn’t actually produce an error message and so it gets translated again into the 500 that you eventually see. What a knock-on effect!
If you’re having difficulty visualising the process, this diagram might help you to continue your struggle with that visualisation.
This then sets a User-Agent header and makes servers that require one, such as MetaFilter, respond appropriately. I don’t know whether WorldWideWeb originally set a User-Agent header
(CERN’s source file archive seems to be missing the relevant C sources so I can’t check) but I
suspect that it did, so this change actually improves the fidelity of the emulation as a bonus. A better fix would also add support for and appropriate handling of other HTTP response
codes, but that’s a story for another day, I guess.
I know the hackathon’s over, but I wonder if they’re taking pull requests…
My geek-crush Ben Foxall posted on Twitter on Monday morning to share
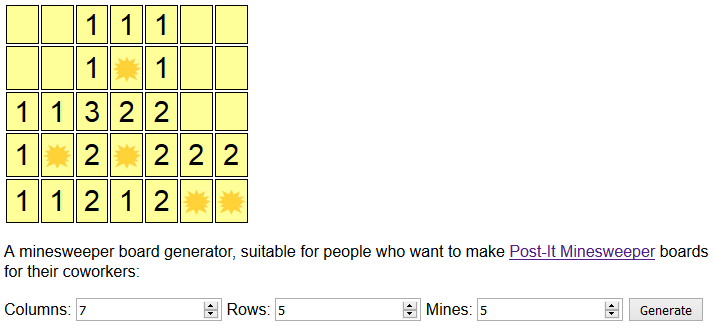
that he’d had a moment of fun nostalgia when he’d come into the office to discover that somebody in his team had covered his monitor with two layers of Post-It notes. The bottom layer
contained numbers – and bombs! – to represent the result of a Minesweeper board, and the upper layer ‘covered’ them so that individual Post-Its could be removed to reveal what lay
beneath. Awesome.
Unlike most computerised implementations of Minesweeper, the first move isn’t guaranteed to be safe. Tread carefully…
Not to be outdone, I hunted around my office and found some mini-Post-Its. Being smaller meant that I could fit more of them onto a monitor and thus make a more-sophisticated (and
more-challenging!) play space. But how to generate the board? Sure: I could do it by hand, but that doesn’t seem very elegant at all – plus, humans make really bad random number generators! I didn’t need quantum-tunnelling-seeded Minesweeper (yes, that’s a thing) levels of entropy, sure, but it’d still be nice to outsource the heavy lifting
to a computer, right?
Yes, I’m quite aware of the irony of using a computer to generate a paper-based version of a computer game, why do you ask?
So naturally, I wrote a program to do it for me. Want to see? It’s at danq.me/minesweeper. Just line up some Post-Its on a co-worker’s monitor to work out
how many you can fit across it in each dimension (I found that I could get 6 × 4 standard-sized Post-Its but 7× 5 or even 8× 5 mini-sized Post-Its very comfortablyonto one of the typical widescreen monitors in my office), decide how many mines you want, and click
Generate. Don’t like the board you get? Click it again!
I set up the first game on my colleague Liz’s computer, before she came in this morning.
And because I was looking for a fresh excuse to play with Periscope, I broadcast the first game I set up live to the Internet. In the end, 66
people ended up watching some or all of a paper-based game of Minesweeper played by my colleague Liz, including moments of cheering her on
and, in one weird moment, despair at the revelation that she was married. The internet’s strange, yo.
Anyway: in case you missed the Periscope broadcast, I’ve put it on YouTube. Sorry about the portrait-orientation filming: I
think it’s awful, too, but it’s a Periscope thing and I haven’t installed the new update that
fixes it yet.
Now go set up a game of Post-It Minesweeper for a friend or co-worker.
Remember about four-and-a-bit years ago, I downloaded Dadadodo, which I
described at the time as a “word disassociator?” The program itself is a Markov chain
generator/randomiser that works on sentence structures: in other words, given some text (speeches, poetry, blog posts, whatever – other kinds have been demonstrated to work on things
like music) it will learn the frequencies in which words and punctuation follow other words and punctuation and use that to build resulting sentences.
Imagine the fun you could have if you took the combined speeches of any politician particularly famous for waffling through their answers. Like, say, US presidential election Republican
party running mate Sarah Palin…
Well, imagine no more – Interview Sarah Palin has you covered. Kick-starting paragraphs (“winding her up”) with
particular topics (e.g. “Iraq and Afghanistan,” “John McCain,” etc.) sets off this fabulous little Markov-chain-speechbot. Even if you don’t understand even the theories of the
mathematics, you can enjoy this site so long as you’ve got a suitable sense of humour around political waffling.
There’s been quite a lot said recently on abnib about class. JTA opened up the debate; Claire
followed up by listing some of her least favourite things about the stereotypes of the middle class, and attracted a lot of debate in her comments; Matt P argued that the class system doesn’t exist
(or, at least, isn’t relevant) in the UK any more anyway; and even Beth weighed in with her opinions on the whole thing, although it did take me prodding her with a virtual stick before she did so.
I thought it was about time that I rode in like a knight in slimy armour (wearing my helm of peripheral vision, of course) and closed the argument once and for all:
Whosays I can’t be a half-middle-class, half-lower-class half-Elf, half-Orc?
(with insincere apologies to those who don’t play Munchkin)
Incidentally, Geek Night this week will be on Friday at Ele and Penny‘s house.
This page was posted to one of my first websites, on 25 March 1998 (as well as appearing in my email/usenet signatures etc.). It was republished here on 22 March 2021.



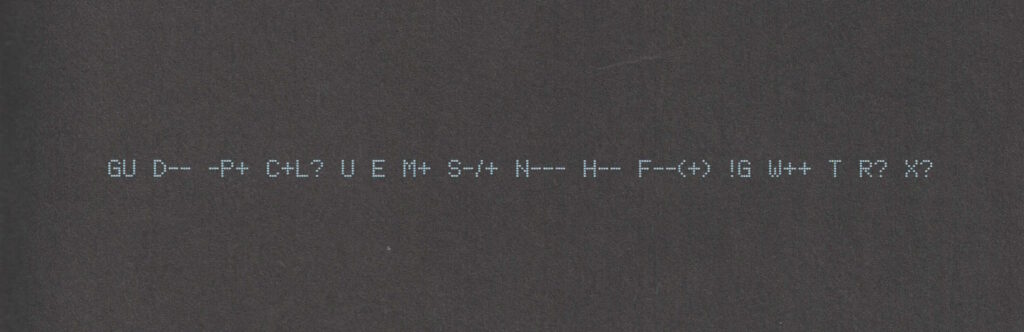








 from Munchkin")