Maybe I’m just hungry, but this morning’s breakfast bagel with brie looks especially scrumptious, right?

Maybe I’m just hungry, but this morning’s breakfast bagel with brie looks especially scrumptious, right?
What if a QR code could look like a maze, hand-drawn with MS Paint?

Inspired by Oscar Cunningham‘s excellent “working QR code in the style of Piet Mondrain” and Andrew Taylor‘s “logical extension of the idea”, earlier this week, I decided to extend upon my much-earlier efforts to (ab)use QR codes and throw together the disgusting thing you see above.
Here’s how I made it:

Obviously this isn’t a clever idea for real-world scenarios. The point of QR codes’ resilience and error correction is to compensate for suboptimal conditions “in the field”, like reflections, glare, dust, grime, low light conditions, and so on.
But it’s kinda fun, right?
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
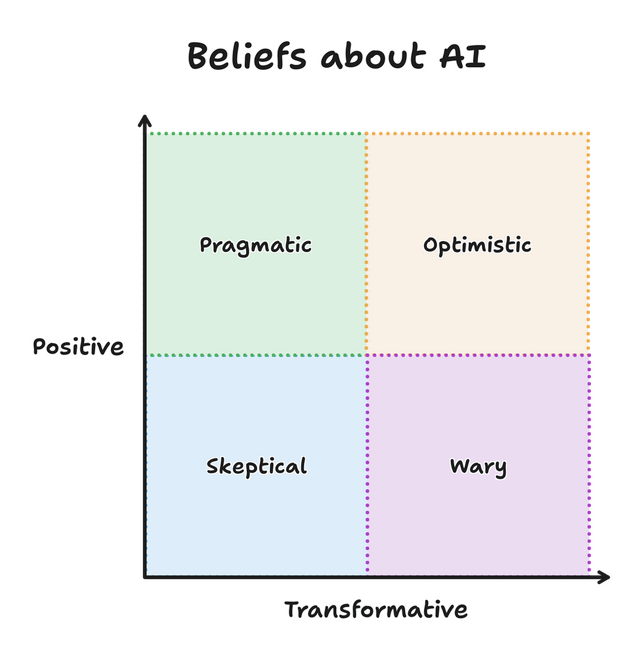
I’ve grouped these four perspectives, but everything here is a spectrum. Depending on the context or day, you might find yourself at any point on the graph. And I’ve attempted to describe each perspectively [sic] generously, because I don’t believe that any are inherently good or bad. I find myself switching between perspectives throughout the day as I implement features, use tools, and read articles. A good team is probably made of members from all perspectives.
Which perspective resonates with you today? Do you also find yourself moving around the graph?
…
An interesting question from Sean McPherson. He sounds like he’s focussed on LLMs for software development, for which I’ve drifted around a little within the left-hand-side of the graph. But perhaps right now, this morning, you could simplify my feelings like this:
![]() My stance is that AI-assisted coding can be helpful (though the question remains open about whether it’s
“worth it”), so long as you’re not trying to do anything that you couldn’t do yourself, and you know how you’d go about doing it yourself. That is: it’s only useful to
accelerate tasks that are in your “known knowns” space.
My stance is that AI-assisted coding can be helpful (though the question remains open about whether it’s
“worth it”), so long as you’re not trying to do anything that you couldn’t do yourself, and you know how you’d go about doing it yourself. That is: it’s only useful to
accelerate tasks that are in your “known knowns” space.
As I’ve mentioned: the other week I had a coding AI help me with some code that interacted with the Google Sheets API. I know exactly how I’d go about it, but that journey would have to start with re-learning the Google Sheets API, getting an API key and giving it the appropriate permissions, and so on. That’s the kind of task that I’d be happy to outsource to a less-experienced programmer who I knew would bring a somewhat critical eye for browsing StackOverflow, and then give them some pointers on what came back, so it’s a fine candidate for an AI to step in and give it a go. Plus: I’d be treating the output as “legacy code” from the get-go, and (because the resulting tool was only for my personal use) I wasn’t too concerned with the kinds of security and accessibility considerations that GenAI can often make a pig’s ear of. So I was able to palm off the task onto Claude Sonnet and get on with something else in the meantime.
If I wanted to do something completely outside of my wheelhouse: say – “write a program in Fortran to control a robot arm” – an AI wouldn’t be a great choice. Sure, I could “vibe code” something like that, but I’d have no idea whether what it produced was any good! It wouldn’t even be useful as a springboard to learning how to do that, because I don’t have the underlying fundamentals in robotics nor Fortran. I’d be producing AI slop in software form: the kind of thing that comes out when non-programmers assume that AI can completely bridge the gap between their great business idea and a fully working app!
They’ll get a prototype that seems to do what you want, if you squint just right, but the hard part of software engineering isn’t making a barebones proof-of-concept! That’s the easy bit! (That’s why AI can do it pretty well!) The hard bit is making it work all the time, every time; making it scale; making it safe to use; making it maintainable; making it production-ready… etc.
But I do benefit from coding AI sometimes. GenAI’s good at summarisation, which in turn can make it good at relatively-quickly finding things in a sprawling codebase where your explanation of those things is too-woolly to use a conventional regular expression search. It’s good at generating boilerplate that’s broadly-like examples its seen before, which means it can usually be trusted to put together skeleton applications. It’s good at “guessing what comes next” – being, as it is, “fancy autocomplete” – which means it can be helpful for prompting you for the right parameters for that rarely-used function or for speculating what you might be about to do with the well-named variable you just created.
Anyway: Sean’s article was pretty good, and it’s a quick and easy read. Once you’ve read it, perhaps you’ll share where you think you sit, on his diagram?
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
Solving problems with LLMs is like solving front-end problems with NPM: the “solution” comes through installing more and more things — adding more and more context, i.e. more and more packages.
- LLM: Problem? Add more context.
- NPM: Problem? There’s a package for that.
…
As I’m typing this, I’m thinking of that image of the evolution of the Raptor engine, where it evolved in simplicity:

This stands in contrast to my working with LLMs, which often wants more and more context from me to get to a generative solution:

…
Jim Nielsen speaks to my experience, here. Because a programming LLM is simply taking inputs (all of your code, plus your prompt), transforming it through statistical analysis, and then producing an output (replacement code), it struggles with refactoring for simplicity unless very-carefully controlled. “Vibe coding” is very much an exercise in adding hacks upon hacks… like the increasingly-ludicrous epicycles introduced by proponents of geocentrism in its final centuries before the heliocentric model became fully accepted.
I don’t think that AIs are useless as a coding tool, and I’ve successfully used them to good effect on several occasions. I’ve even tried “vibe coding”, about which I fully agree with ‘s observation that “vibe code is legacy code”. Being able to knock out something temporary, throwaway, experimental, or for personal use only… while I work on something else… is pretty liberating.
For example: I couldn’t remember my Google Sheets API and didn’t want to re-learn it from the sprawling documentation site, but wanted a quick personal tool to manipulate such a sheet from a remote system. I was able to have an AI knock up what I needed while I cooked dinner for the kids, paying only enough attention to check-in on its work. Is it accessible? Is it secure? Is it performant? Is it maintainable? I can’t answer any of those questions, and so as a professional software engineer I have to reasonably assume the answer to all of them is “no”. But its only user is me, it does what I needed it to do, and I didn’t have to shift my focus from supervising children and a pan in order to throw it together!
Anyway: Jim hits the nail on the head here, as he so often does.
<dialog>-based HTML+CSS lightboxes
A few years ago I implemented a pure HTML + CSS solution for lightbox images, which I’ve been using on my blog ever since. It works by
pre-rendering an invisible <dialog> for each lightboxable image on the page, linking to the anchor of those dialogs, and exploiting the :target selector
to decide when to make the dialogs visible. No Javascript is required, which means low brittleness and high performance!
One thing I don’t like about it is that it that it breaks completely if the CSS fails for any reason. Depending upon CSS is safer than depending upon JS (which breaks all the time), but it’s still not great: if CSS is disabled in your browser or just “goes wrong” somehow then you’ll see a hyperlink… that doesn’t seem to go anywhere (it’s an anchor to a hidden element).
A further thing I don’t like about it is it’s semantically unsound. Linking to a dialog with the expectation that the CSS parser will then make that dialog visible isn’t really representative of what the content of the page means. Maybe we can do better.
<details>-based HTML+CSS lightboxes?
Here’s a thought I had, inspired by Patrick Chia’s <details> overlay trick and by
the categories menu in Eevee’s blog: what if we used a <details> HTML element for a lightbox? The thumbnail image would go in the
<summary> and the full image (with loading="lazy" so it doesn’t download until the details are expanded) beneath, which means it “just works” with or
without CSS… and then some CSS enhances it to make it appear like a modal overlay and allow clicking-anywhere to close it again.
Let me show you what I mean. Click on one of the thumbnails below:






Each appears to pop up in a modal overlay, but in reality they’re just unfolding a <details> panel, and some CSS is making the contents display as if if were
an overlay, complete click-to-close, scroll-blocking, and a blur filter over the background content. Without CSS, it functions as a traditional <details> block.
Accessibility is probably improved over my previous approach, too (though if you know better, please tell me!).
The code’s pretty tidy, too. Here’s the HTML:
<details class="details-lightbox" aria-label="larger image"> <summary> <img src="thumb.webp" alt="Alt text for the thumbnail image."> </summary> <div> <img src="full.webp" alt="Larger image: alt text for the full image." loading="lazy"> </div> </details>
The CSS is more-involved, but not excessive (and can probably be optimised a little further):
.details-lightbox { summary { display: block; cursor: zoom-in; &::before { content: ''; backdrop-filter: none; transition: backdrop-filter 0.5s, background 0.2s; background: transparent; } } & > div img { max-width: 95vw; max-height: 95vh; box-shadow: 0 0 12px #fff6; opacity: 0; transition: filter 0.3s, opacity 0.6s; filter: blur(6px); } &[open] > div { position: fixed; top: 0; left: 0; width: 100vw; height: 100vh; display: flex; align-items: center; justify-content: center; z-index: 110; pointer-events: none; img { opacity: 1; filter: none; } } &[open] > summary { cursor: auto; &::before { content: ''; background: #000a; backdrop-filter: blur(6px); position: fixed; top: 0; left: 0; width: 100vw; height: 100vw; z-index: 109; } } } body:has(.details-lightbox[open]) { overflow: hidden; }
Native CSS nesting is super nice for this kind of thing. Being able to use :has on the body to detect whether there exists an open lightbox and prevent
scrolling, if so, is another CSS feature I’m appreciating today.
I’m not going to roll this out anywhere rightaway, but I’ll keep it in my back pocket for the next time I feel a blog redesign coming on. It feels tidier and more-universal than my current approach, and I don’t think it’s an enormous sacrifice to lose the ability to hotlink directly to an open image in a post.
What do you think?
A moderately-large house spider dropped down and startled my dog as she napped in her basket, so now she’s hiding under my desk and refusing to return to bed. 🙄😂

This checkin to GC2CWQ7 #036 Just Northamptonshire reflects a geocaching.com log entry. See more of Dan's cache logs.
As a semi-regular at Fairport’s Cropredy Convention who likes to get up earlier then the others I share my tent with, I’ve done my fair share of early morning geocaching in this neck of the woods.
Of course: over the years this practice has exhausted most of tree caches local to Cropredy and my morning walks have begun to take me further and further afield. But this is certainly the first time I’ve walked to the next county in search of a cache!

Coming across the fields from Williamscot via Prescote Farm treated me to gorgeous rolling hills free fields of freshly-harvested corn getting picked at by families of deer, while the red kites above went looking for their breakfasts.
The final hill up to the GZ required a bit of a push for my legs which were dancing until late last night, but soon I was close and the cache was quickly found in the second place I looked.

TFTC. Oxfordshire says hello!
This checkin to GCAJH34 Jonah's Oak reflects a geocaching.com log entry. See more of Dan's cache logs.
My little tribe and I have, in some form of another, been attending Cropredy for decades: intermittently in the past, but lately with more regularity every year. For me, it’s coincided with the growth of our family: I’ve been attending with my partner and her husband approximately since our eldest child, now 11, was born.
As our group’s early riser, I’ve a longstanding tradition of getting up while everybody else lies in, to take a walk and perhaps find a geocache or two. Of course I soon ran out of caches in Cropredy itself and my morning walks now take me much further afield!
Last year I was very ill and had to be sent home from Cropredy before I had the opportunity to log this cache, but I’m back again this year and taking a moment at the Oak to reflect on those we’ve all loved and lost.

Answers to follow as soon as signal permits. TFTC.
This checkin to GC8Z1F6 Church Micro 13672...Great Bourton ⛪️ reflects a geocaching.com log entry. See more of Dan's cache logs.
My family and I have made a tradition of our regular attendance of Fairport’s Cropredy Convention. There I – being the earliest riser of us – have in turn made a tradition of getting up early to find a nearby geocache on any morning that I’m up before the kids.
This practice has already eliminated all of the caches in Cropredy itself, and so now my morning walks take me further afield. This morning I opted to follow the footpath over the fields to Great Bourton to investigate the two multicaches commencing in the churchyard.
Having determined the coordinates for both and (unsuccessfully) attempting the other cache first, I was optimistic for a smiley face here. The GZ was easy to find – I’d stopped here to check my map on the way out! – and I was soon searching in earnest.
In the low-angled light of the morning sun, the shade of the thick leafy canopy made for challenging conditions, so I flicked my torch on and pointed it in the direction of the host object… and there, clear as day despite its camouflage, was the cache. Easy as pie! SL.
I was briefly tempted to re-try the cache I failed to find earlier, under the assumption that the container would look similar to this and the same technique might bear fruit. But I didn’t feel like doubling back twice more while my stomach was rumbling, so I carried on towards Cropredy to see whether any others if my party were yet ready for some grub.
TFTC.
This checkin to GC91EH6 War Memorial #1,340 ~ Great Bourton 🌹 reflects a geocaching.com log entry. See more of Dan's cache logs.
My family and I have made a tradition of our regular attendance of Fairport’s Cropredy Convention. There I – being the earliest riser of us – have in turn made a tradition of getting up early to find a nearby geocache on any morning that I’m up before the kids.
This practice has already eliminated all of the caches in Cropredy itself, and so now my morning walks take me further afield. This morning I opted to follow the footpath over the fields to Great Bourton to investigate the two multicaches commencing in the churchyard.
Solving for both was easy enough, and I opted to seek this one first, given that the other could become part of my route back to my tent. As others have observed, finding the right footpath was slightly tricky: it looks a bit like a communal driveway, to begin with… and then, for the moment at least, looks as though it might become a building site!
But I pressed on towards the target coordinates and soon spotted a likely host. I searched for a bit without luck, then hit up the hint: looks like I need to go deeper, I figured, and pushed into the foliage.
But after 20 minutes or so of searching all around the conceivable spots, I was still struggling. Plus I’d narrowly avoided kneeling in something truly gross and couldn’t face another round of crawling about under a hedge. And further, I realised I’d soon need some breakfast so I gave up on this one and made a move for the second. Maybe another year!
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…

“For years, starting in the late ‘70s, I was taking pictures of hitchhikers. A hitchhiker is someone you may know for an hour, or a day, or, every so often, a little longer, yet, when you leave them, they’re gone. If I took a picture, I reasoned, I’d have a memory. I kept a small portfolio of photos in the car to help explain why I wanted to take their picture. This helped a lot. It also led me to look for hitchhikers, so that I could get more pictures.
“I almost always had a camera… I finally settled on the Olympus XA – a wonderful little pocket camera. (I’ve taken a picture of the moon rising with this camera.) One time I asked a chap if I could take a photo, and he said, “You took my picture a few years ago.” I showed him the album and he picked himself out. “That’s me,” he said, pointing…”
…
Not that hitch-hiking is remotely as much a thing today as it was 50 years ago, but even if it were then it wouldn’t be so revolutionary to, say, take a photo of everybody you give a ride to. We’re all carrying cameras all the time, and the price of taking a snap is basically nothing.
But for Doug Biggert, who died in 2023, began doing this with an analogue camera as he drove around California from 1973 onwards? That’s quite something. Little wonder he had to explain his project to his passengers (helped, later on, by carrying a copy of the photo album he’d collected so-far that he could show them).
A really interesting gallery with a similarly-compelling story. Also: man – look at the wear-and-tear on his VW Bug!
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
I somehow missed this “most punk rock thing ever” moment the other month. If you did too, let me catch you up:
For a weekend in June, in what was clearly designed to act as a protest to Pride month events, human turd/bar owner Mark Fitzpatrick decided to put on a “straight pride” festival in Boise, Idaho. Called “Hetero Awesome Fest”, it was as under-subscribed as perhaps it ought to be (having a similar turnout to the “world’s smallest pride parade”). And that would have made it a non-story, except for the moment when local singer-songwriter Daniel Hamrick got up to perform his set:
I can’t begin to fathom the courage it takes to get on-stage in front of an ultra-conservative crowd (well, barely a crowd…) in a right-leaning US state to protest their event by singing a song about a trans boy. But that’s exactly what Hamrick did. After catching spectators off-guard, perhaps, by taking the perhaps-“masculine-telegraphing” step of drawing attention to part of his army uniform, the singer swiftly switched outfit to show off a “Keep Canyon County Queer” t-shirt, slip on a jacket with various Pride-related patches, and then immediately launched into Boy, a song lamenting the persecution of a trans child by their family and community.
Needless to say, this was the first, last, and only song Daniel Hamrick got to play at Hetero Awesome Fest. But man, what a beautiful protest!
(There are other videos online that aren’t nabbed from the official event feed and so don’t cut-out abruptly.)
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
I still get that powerful feeling that anything is possible when I open a web browser — it’s not as strong as it was 20 years ago, but it’s still there.
This. This is the optimistic side of the coin represented by the things I’ve been expressing in notes like this, articles like that, and reposts like the other.
As cynical as you can get at the state of the Web right now… as much as it doesn’t command the level of inspirational raw potential of “anything is possible” that it might have once… it’s still pretty damn magical, and we should lean into that.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
A freaking excellent longread by Eevee (Evelyn Woods), lamenting the direction of popular technological progress and general enshittification of creator culture. It’s ultimately uplifting, I feel, but it’s full of bitterness until it gets there. I’ve pulled out a couple of highlights to try to get you interested, but you should just go and read the entire thing:
…
And so the entire Web sort of congealed around a tiny handful of gigantic platforms that everyone on the fucking planet is on at once. Sometimes there is some sort of partitioning, like Reddit. Sometimes there is not, like Twitter.
That’s… fine, I guess. Things centralize. It happens. You don’t get tubgirl spam raids so much any more, at least.
But the centralization poses a problem. See, the Web is free to look at (by default), but costs money to host. There are free hosts, yes, but those are for static things getting like a thousand visitors a day, not interactive platforms serving a hundred million. That starts to cost a bit. Picture logs being shoveled into a steam engine’s firebox, except it’s bundles of cash being shoveled into… the… uh… website hole.
…
I don’t want to help someone who opens with “I don’t know how to do this so I asked ChatGPT and it gave me these 200 lines but it doesn’t work”. I don’t want to know how much code wasn’t actually written by anyone. I don’t want to hear how many of my colleagues think Whatever is equivalent to their own output.
…
I glimpsed someone on Twitter a few days ago, also scoffing at the idea that anyone would decide not to use the Whatever machine. I can’t remember exactly what they said, but it was something like: “I created a whole album, complete with album art, in 3.5 hours. Why wouldn’t I use the make it easier machine?”
This is kind of darkly fascinating to me, because it gives rise to such an obvious question: if anyone can do that, then why listen to your music? It takes a significant chunk of 3.5 hours just to listen to an album, so how much manual work was even done here? Apparently I can just go generate an endless stream of stuff of the same quality! Why would I want your particular brand of Whatever?
Nobody seems to appreciate that if you can make a computer do something entirely on its own, then that becomes the baseline.
…
Do things. Make things. And then put them on your website so I can see them.
Clearly this all ties in to stuff that I’ve been thinking, lately. Expect more posts and reposts in this vein, I guess?
Do you remember when your domestic ISP – Internet Service Provider – used to be an Internet Services Provider? They were only sometimes actually called that, but what I mean is: when ISPs provided more than one Internet service? Not just connectivity, but… more.

It used to just be expected that your ISP would provide you with not only an Internet connection, but also some or all of:
![Stylish (for circa 2000) webpage for HoTMetaL Pro 6.0, advertising its 'unrivaled [sic] editing, site management and publishing tools'.](/_q23u/2025/08/hotmetal-pro-6-640x396.jpg)
The ISP I hinted at above doesn’t exist any more, after being bought out and bought out and bought out by a series of owners. But I checked the Website of the current owner to see what their “standard services” are, and discovered that they are:
The connection is faster, which is something, but we’re still talking about the “baseline” for home Internet access then-versus-now. Which feels a bit galling, considering that (a) you’re clearly, objectively, getting fewer services, and (b) you’re paying more for them – a cheap basic home Internet subscription today, after accounting for inflation, seems to cost about 25% more than it did in 2000.4
Are we getting a bum deal?

Some of them were great conveniences at the time, but perhaps not-so-much now: a caching server, FTP site, or IRC node in the building right at the end of my dial-up connection? That’s a speed boost that was welcome over a slow connection to an unencrypted service, but is redundant and ineffectual today. And if you’re still using a fax-to-email service for any purpose, then I think you have bigger problems than your ISP’s feature list!
Some of them were things I wouldn’t have recommend that you depend on, even then: tying your email and Web hosting to your connectivity provider traded one set of problems for another. A particular joy of an email address, as opposed to a postal address (or, back in the day, a phone number), is that it isn’t tied to where you live. You can move to a different town or even to a different country and still have the same email address, and that’s a great thing! But it’s not something you can guarantee if your email address is tied to the company you dial-up to from the family computer at home. A similar issue applies to Web hosting, although for a true traditional “personal home page”: a little information about yourself, and your bookmarks, it would be fine.
But some of them were things that were actually useful and I miss: honestly, it’s a pain to have to use a third-party service for newsgroup access, which used to be so-commonplace that you’d turn your nose up at an ISP that didn’t offer it as standard. A static IP being non-standard on fixed connections is a sad reminder that the ‘net continues to become less-participatory, more-centralised, and just generally more watered-down and shit: instead of your connection making you “part of” the Internet, nowadays it lets you “connect to” the Internet, which is a very different experience.5
But the Web hosting, for example, wasn’t useless. In fact, it served an important purpose in lowering the barrier to entry for people to publish their first homepage! The magical experience of being able to just FTP some files into a directory and have them be on the Web, as just a standard part of the “package” you bought-into, was a gateway to a participatory Web that’s nowadays sadly lacking.
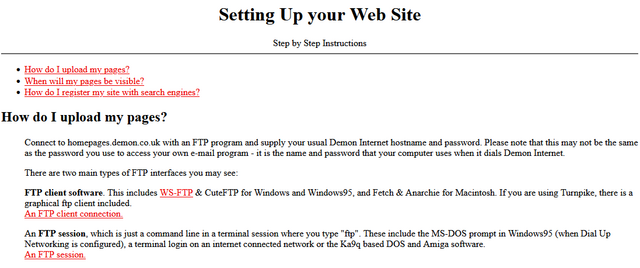
Yeah, sure, you can set up a static site (unencumbered by any opinionated stack) for free on Github Pages, Neocities, or wherever, but the barrier to entry has been raised by just enough that, doubtless, there are literally millions of people who would have taken that first step… but didn’t.
And that makes me sad.
1 ISP-provided shared FTP servers would also frequently provide locally-available copies of Internet software essentials for a variety of platforms. This wasn’t just a time-saver – downloading Netscape Navigator from your ISP rather than from half-way across the world was much faster! – it was also a way to discover new software, curated by people like you: a smidgen of the feel of a well-managed BBS, from the comfort of your local ISP!
2 ISP-provided routers are, in my experience, pretty crap 50% of the time… although they’ve been improving over the last decade as consumers have started demanding that their WiFi works well, rather than just works.
3 These streaming services vouchers are probably just a loss-leader for the streaming service, who know that you’ll likely renew at full price afterwards.
4 Okay, in 2000 you’d have also have had to pay per-minute for the price of the dial-up call… but that money went to BT (or perhaps Mercury or KCOM), not to your ISP. But my point still stands: in a world where technology has in general gotten cheaper and backhaul capacity has become underutilised, why has the basic domestic Internet connection gotten less feature-rich and more-expensive? And often with worse customer service, to boot.
5 The problem of your connection not making you “part of” the Internet is multiplied if you suffer behind carrier-grade NAT, of course. But it feels like if we actually cared enough to commit to rolling out IPv6 everywhere we could obviate the need for that particular turd entirely. And yet… I’ll bet that the ISPs who currently use it will continue to do so, even as the offer IPv6 addresses as-standard, because they buy into their own idea that it’s what their customers want.
6 I think we can all be glad that we no longer write “Web Site” as two separate words, but you’ll note that I still usually correctly capitalise Web (it’s a proper noun: it’s the Web, innit!).