What’s wrong with my password, @PostOffice? Is it too secure for you?
It does nothing to fix your “old-fashioned” image that your password policy is still stuck in the 1990s. @PWTooStrong
What’s wrong with my password, @PostOffice? Is it too secure for you?
It does nothing to fix your “old-fashioned” image that your password policy is still stuck in the 1990s. @PWTooStrong
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.

…
This is A.C. Gilbert’s creation, the Polar Cub Electric Vibrator No. B87, and it’s nearly 100 years old. This vibrator is so ancient it was manufactured before any of my grandparents were born, which delights me terribly. The box is in shambles — on the front, a cute flapper holds the vibrator to her throat with a mischievous glint in her eye. A thin, fragile slip of paper serves as the original receipt, dated June 15th, 1925, in the amount of $2.95. I love this vibrator with every fiber of my being. Just thinking about how extremely not alive I was at that time is exciting to me.
And of course, I’m going to have an orgasm with this thing. An orgasm that transcends time. That’s what all of this is about.
…
Fabulous, frequently-funny review of three vibrators from the 1910s through 1960s and are still in some kind of working order.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…why would cookies ever need to work across domains? Authentication, shopping carts and all that good stuff can happen on the same domain. Third-party cookies, on the other hand, seem custom made for tracking and frankly, not much else.
…
Then there’s third-party JavaScript.
In retrospect, it seems unbelievable that third-party JavaScript is even possible. I mean, putting arbitrary code—that can then inject even more arbitrary code—onto your website? That seems like a security nightmare!
I imagine if JavaScript were being specced today, it would almost certainly be restricted to the same origin by default.
…
Jeremy hits the nail on the head with third-party cookies and Javascript: if the Web were invented today, there’s no way that these potentially privacy and security-undermining features would be on by default, globally. I’m not sure that they’d be universally blocked at the browser level as Jeremy suggests, though: the Web has always been about empowering developers, acting as a playground for experimentation, and third-party stuff does provide benefits: sharing a login across multiple subdomains, for example (which in turn can exist as a security feature, if different authors get permission to add content to those subdomains).
Instead, then, I imagine that a Web re-invented today would treat third-party content a little like we treat CORS or we’re beginning to treat resource types specified by Content-Security-Policy and Feature-Policy headers. That is, website owners would need to “opt-in” to which third-party domains could be trusted to provide content, perhaps subdivided into scripts and cookies. This wouldn’t prohibit trackers, but it would make their use less of an assumed-default (develolpers would have to truly think about the implications of what they were enabling) and more transparent: it’d be very easy for a browser to list (and optionally block, sandbox, or anonymise) third-party trackers could potentially target them, on a given site, without having to first evaluate any scripts and their sources.
I was recently inspired by Dave Rupert to remove Google Analytics from this blog. For a while, there’ll have been no third-party scripts being delivered on this site at all, except through iframes (for video embedding etc., which is different anyway because there’s significantly less scope leak). Recently, I’ve been experimenting with Jetpack because I get it for free through my new employer, but I’m always looking for ways to improve how well my site “stands alone”: you can block all third-party resources and this site should still work just fine (I wonder if I can add a feature to my service worker to allow visitors to control exactly what third party content they’re exposed to?).
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Last week I happened to be at an unveiling/premiere event for the new Renault Clio. That’s a coincidence: I was actually there to see the new Zoe, because we’re hoping to be among the first people to get the right-hand-drive version of the new model when it starts rolling off the production line in 2020.
But I’ll tell you what, if they’d have shown me this video instead of showing me the advertising stuff they did, last week, I’d have been all: sure thing, Clio it is, SHUT UP AND TAKE MY MONEY! I’ve watched this ad four times now and seen more things in it every single time. (I even managed to not-cry at it on the fourth watch-through, too; hurrah!).
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly diverged from its original/technical one. Read more evolving words…
The language we use is always changing, like how the word “cute” was originally a truncation of the word “acute”, which you’d use to describe somebody who was sharp-witted, as in “don’t get cute with me”. Nowadays, we use it when describing adorable things, like the subject of this GIF:
![[Animated GIF] Puppy flumps onto a human.](https://bcdn.danq.me/_q23u/2019/09/cute-puppy.gif)
File format (or the files themselves) designed for animations and transparency. Or: any animation without sound.
File format designed for efficient colour images. Animation was secondary; transparency was an afterthought.
Back in the 1980s cyberspace was in its infancy. Sir Tim hadn’t yet dreamed up the Web, and the Internet wasn’t something that most people could connect to, and bulletin board systems (BBSes) – dial-up services, often local or regional, sometimes connected to one another in one of a variety of ways – dominated the scene. Larger services like CompuServe acted a little like huge BBSes but with dial-up nodes in multiple countries, helping to bridge the international gaps and provide a lower learning curve than the smaller boards (albeit for a hefty monthly fee in addition to the costs of the calls). These services would later go on to double as, and eventually become exclusively, Internet Service Providers, but for the time being they were a force unto themselves.

In 1987, CompuServe were about to start rolling out colour graphics as a new feature, but needed a new graphics format to support that. Their engineer Steve Wilhite had the idea for a bitmap image format backed by LZW compression and called it GIF, for Graphics Interchange Format. Each image could be composed of multiple frames each having up to 256 distinct colours (hence the common mistaken belief that a GIF can only have 256 colours). The nature of the palette system and compression algorithm made GIF a particularly efficient format for (still) images with solid contiguous blocks of colour, like logos and diagrams, but generally underperformed against cosine-transfer-based algorithms like JPEG/JFIF for images with gradients (like most photos).

GIF would go on to become most famous for two things, neither of which it was capable of upon its initial release: binary transparency (having “see through” bits, which made it an excellent choice for use on Web pages with background images or non-static background colours; these would become popular in the mid-1990s) and animation. Animation involves adding a series of frames which overlay one another in sequence: extensions to the format in 1989 allowed the creator to specify the duration of each frame, making the feature useful (prior to this, they would be displayed as fast as they could be downloaded and interpreted!). In 1995, Netscape added a custom extension to GIF to allow them to loop (either a specified number of times or indefinitely) and this proved so popular that virtually all other software followed suit, but it’s worth noting that “looping” GIFs have never been part of the official standard!
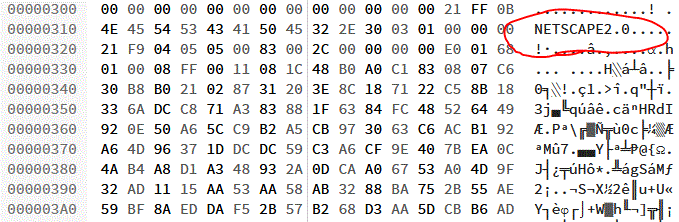
NETSCAPE2.0; evidence of
Netscape’s role in making animated GIFs what they are today.
Compatibility was an issue. For a period during the mid-nineties it was quite possible that among the visitors to your website there would be a mixture of:
This made it hard to depend upon GIFs without carefully considering their use. But people still did, and they just stuck a
![]() button on to warn people, as if that made up for
it. All of this has happened before, etc.
button on to warn people, as if that made up for
it. All of this has happened before, etc.
In any case: as better, newer standards like PNG came to dominate the Web’s need for lossless static (optionally
transparent) image transmission, the only thing GIFs remained good for was animation. Standards like APNG/MNG failed to get off the ground, and so GIFs remained the dominant animated-image standard. As Internet connections became faster and faster in the 2000s, they experienced a
resurgence in popularity. The Web didn’t yet have the <video> element and so embedding videos on pages required a mixture of at least two of
<object>, <embed>, Flash, and black magic… but animated GIFs just worked and
soon appeared everywhere.

Nowadays, when people talk about GIFs, they often don’t actually mean GIFs! If you see a GIF on Giphy or WhatsApp, you’re probably actually seeing an MPEG-4 video file with no audio track! Now that Web video is widely-supported, service providers know that they can save on bandwidth by delivering you actual videos even when you expect a GIF. More than ever before, GIF has become a byword for short, often-looping Internet animations without sound… even though that’s got little to do with the underlying file format that the name implies.

Verdict: We still can’t agree on whether to pronounce it with a soft-G (“jif”), as Wilhite intended, or with a hard-G, as any sane person would, but it seems that GIFs are here to stay in name even if not in form. And that’s okay. I guess.
That moment when you realise, to your immense surprise, that the research you’ve spent most of the year on might actually demonstrate the thing you set out to test after all. 😲
Screw you, null hypothesis.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Spoiler alert: no, they shouldn’t.
Yesterday, Marijn Haverbeke tweeted:
If you make accessibility or internationalization in a code library an optional component, you just know half of the people deploying it will ignore it—out of ignorance or as optimization. So taking the side of the end user versus the dev user means just pre-bundling these things
For very similar reasons, I refuse to make accessibility features configurable in my vanilla JS plugins.
…
Very much this. In short:
Who’d have thought that my onboarding fortnight at @WooCommerce / @Automattic would conclude with a very literal “on-boarding”. Hang five! 🏄🏼♂️

Well, Cape Town, you were a blast. But now it’s time to get back to my normal life for a bit.
🇿🇦✈️🇩🇪✈️🇬🇧
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly diverged from its original/technical one. Read more evolving words…
Until the 17th century, to “fathom” something was to embrace it. Nowadays, it’s more likely to refer to your understanding of something in depth. The migration came via the similarly-named imperial unit of measurement, which was originally defined as the span of a man’s outstretched arms, so you can understand how we got from one to the other. But you know what I can’t fathom? Broadband.

Broadband Internet access has become almost ubiquitous over the last decade and a half, but ask people to define “broadband” and they have a very specific idea about what it means. It’s not the technical definition, and this re-invention of the word can cause problems.
High-speed, always-on Internet access.
Communications channel capable of multiple different traffic types simultaneously.
Throughout the 19th century, optical (semaphore) telegraph networks gave way to the new-fangled electrical telegraph, which not only worked regardless of the weather but resulted in
significantly faster transmission. “Faster” here means two distinct things: latency – how long it takes a message to reach its destination, and bandwidth – how much
information can be transmitted at once. If you’re having difficulty understanding the difference, consider this: a man on a horse might be faster than a telegraph if the size of the
message is big enough because a backpack full of scrolls has greater bandwidth than a Morse code pedal, but the latency of an electrical wire beats land transport
every time. Or as Andrew S. Tanenbaum famously put it: Never underestimate the bandwidth of a station wagon full of
tapes hurtling down the highway.

Telegraph companies were keen to be able to increase their bandwidth – that is, to get more messages on the wire – and this was achieved by multiplexing. The simplest approach, time-division multiplexing, involves messages (or parts of messages) “taking turns”, and doesn’t actually increase bandwidth at all: although it does improve the perception of speed by giving recipients the start of their messages early on. A variety of other multiplexing techniques were (and continue to be) explored, but the one that’s most-interesting to us right now was called acoustic telegraphy: today, we’d call it frequency-division multiplexing.
What if, asked folks-you’ll-have-heard-of like Thomas Edison and Alexander Graham Bell, we were to send telegraph messages down the line at different frequencies. Some beeps and bips would be high tones, and some would be low tones, and a machine at the receiving end could separate them out again (so long as you chose your frequencies carefully, to avoid harmonic distortion). As might be clear from the names I dropped earlier, this approach – sending sound down a telegraph wire – ultimately led to the invention of the telephone. Hurrah, I’m sure they all immediately called one another to say, our efforts to create a higher-bandwidth medium for telegrams has accidentally resulted in a lower-bandwidth (but more-convenient!) way for people to communicate. Job’s a good ‘un.
Most electronic communications systems that have ever existed have been narrowband: they’ve been capable of only a single kind of transmission at a time. Even if you’re multiplexing a dozen different frequencies to carry a dozen different telegraph messages at once, you’re still only transmitting telegraph messages. For the most part, that’s fine: we’re pretty clever and we can find workarounds when we need them. For example, when we started wanting to be able to send data to one another (because computers are cool now) over telephone wires (which are conveniently everywhere), we did so by teaching our computers to make sounds and understand one another’s sounds. If you’re old enough to have heard a fax machine call a landline or, better yet used a dial-up modem, you know what I’m talking about.
As the Internet became more and more critical to business and home life, and the limitations (of bandwidth and convenience) of dial-up access became increasingly questionable, a better solution was needed. Bringing broadband to Internet access was necessary, but the technologies involved weren’t revolutionary: they were just the result of the application of a little imagination.

We’d seen this kind of imagination before. Consider teletext, for example (for those of you too young to remember teletext, it was a standard for browsing pages of text and simple graphics using an 70s-90s analogue television), which is – strictly speaking – a broadband technology. Teletext works by embedding pages of digital data, encoded in an analogue stream, in the otherwise-“wasted” space in-between frames of broadcast video. When you told your television to show you a particular page, either by entering its three-digit number or by following one of four colour-coded hyperlinks, your television would wait until the page you were looking for came around again in the broadcast stream, decode it, and show it to you.
Teletext was, fundamentally, broadband. In addition to carrying television pictures and audio, the same radio wave was being used to transmit text: not pictures of text, but encoded characters. Analogue subtitles (which used basically the same technology): also broadband. Broadband doesn’t have to mean “Internet access”, and indeed for much of its history, it hasn’t.
Here in the UK, ISDN (from 1988!) and later ADSL would be the first widespread technologies to provide broadband data connections over the copper wires simultaneously used to carry telephone calls. ADSL does this in basically the same way as Edison and Bell’s acoustic telegraphy: a portion of the available frequencies (usually the first 4MHz) is reserved for telephone calls, followed by a no-mans-land band, followed by two frequency bands of different sizes (hence the asymmetry: the A in ADSL) for up- and downstream data. This, at last, allowed true “broadband Internet”.
But was it fast? Well, relative to dial-up, certainly… but the essential nature of broadband technologies is that they share the bandwidth with other services. A connection that doesn’t have to share will always have more bandwidth, all other things being equal! Leased lines, despite technically being a narrowband technology, necessarily outperform broadband connections having the same total bandwidth because they don’t have to share it with other services. And don’t forget that not all speed is created equal: satellite Internet access is a narrowband technology with excellent bandwidth… but sometimes-problematic latency issues!

Equating the word “broadband” with speed is based on a consumer-centric misunderstanding about what broadband is, because it’s necessarily true that if your home “broadband” weren’t configured to be able to support old-fashioned telephone calls, it’d be (a) (slightly) faster, and (b) not-broadband.
But does the word that people use to refer to their high-speed Internet connection matter. More than you’d think: various countries around the world have begun to make legal definitions of the word “broadband” based not on the technical meaning but on the populist one, and it’s becoming a source of friction. In the USA, the FCC variously defines broadband as having a minimum download speed of 10Mbps or 25Mbps, among other characteristics (they seem to use the former when protecting consumer rights and the latter when reporting on penetration, and you can read into that what you will). In the UK, Ofcom‘s regulations differentiate between “decent” (yes, that’s really the word they use) and “superfast” broadband at 10Mbps and 24Mbps download speeds, respectively, while the Scottish and Welsh governments as well as the EU say it must be 30Mbps to be “superfast broadband”.

I’m all in favour of regulation that protects consumers and makes it easier for them to compare products. It’s a little messy that definitions vary so widely on what different speeds mean, but that’s not the biggest problem. I don’t even mind that these agencies have all given themselves very little breathing room for the future: where do you go after “superfast”? Ultrafast (actually, that’s exactly where we go)? Megafast? Ludicrous speed?
What I mind is the redefining of a useful term to differentiate whether a connection is shared with other services or not to be tied to a completely independent characteristic of that connection. It’d have been simple for the FCC, for example, to have defined e.g. “full-speed broadband” as providing a particular bandwidth.
Verdict: It’s not a big deal; I should just chill out. I’m probably going to have to throw in the towel anyway on this one and join the masses in calling all high-speed Internet connections “broadband” and not using that word for all slower and non-Internet connections, regardless of how they’re set up.
Seconds after I took this “penguin selfie”, a third penguin snuck up behind me and bit me on the arse. 🇿🇦🐧😧

I now have no doubt that from the summit of Table Mountain is an absolutely unparalleled place from which to watch the sunset. 🇿🇦🌅😍

This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Now that’s a hot comic. NSFW, so don’t click through if you’re not in a place where you can do so!
Also, RIP Flapjack. 😢
This checkin to GC7B8X0 Into 7th Heaven reflects a geocaching.com log entry. See more of Dan's cache logs.
Wonderful location for a virtual: what a view! I’m in Cape Town for a week of work and teambuilding with my new colleagues: a rare occasion as we normally work completely remotely from many different countries. I was pleased to be able to combine work with a trip up Table Mountain, especially on such beautiful day. Snapped the attached pic, then walked over to the other side to watch the sun set. TFTC!
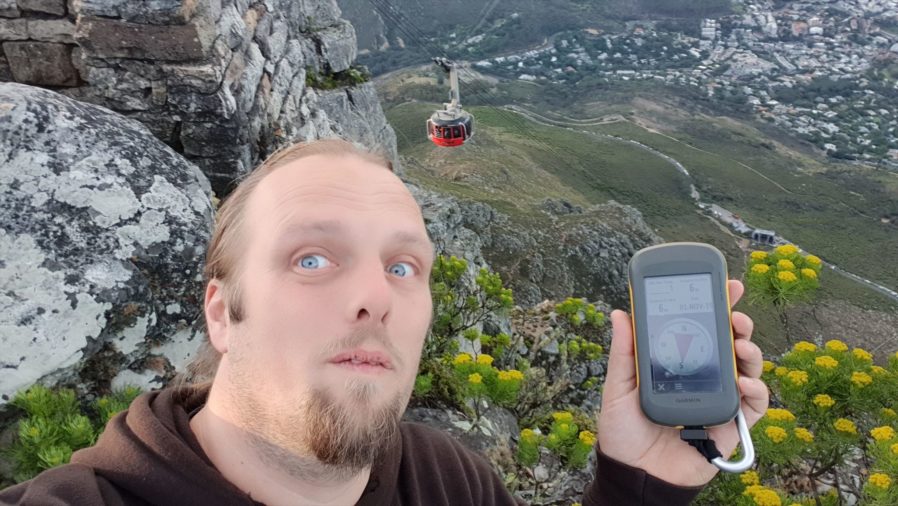
This checkin to GCMYYZ Table Top Trove reflects a geocaching.com log entry. See more of Dan's cache logs.
Despite a thorough search in what seems like all of the likely spots, I couldn’t find a trace of this cache.
