I’ve been spending a while running on reduced brain capacity lately so, to ease myself back into thinking like a programmer, I upgraded my preferred feed reader FreshRSS to version 1.20.0 – which was released a couple of weeks ago – and tried out what I believe is its killer new feature: HTML + XPath scraping.
I’ve been using RSS1 for about 20 years and I love it. It feels great to be able to curate my updates based on “what I care about”, and not on “what some social network thinks I should care about”, to keep things to read later, to prioritise effectively based on my own categorisation, to consume content offline and have my to-read list synchronise later, etc.
RSS never went away, of course (what do you think a podcast is?), but it got steamrollered out of the public eye by big companies who make their money out of keeping your eyes on their platforms and off the open Web. But it feels like it’s slowly coming back: even Substack – whose entire thing is that an email client is more-convenient than a feed reader for most people – launched an RSS reader this week!

I love RSS so much that I routinely retrofit other people’s websites with feeds just so I can subscribe to them: I even published the tool I use to do so! Whether filtering sports headlines out of BBC News, turning retro webcomics into “reading lists” so I can track my progress, or just working around sites that really should have feeds but refuse to, I just love sidestepping these “missing feeds”. My friend Beverley has a blog without any kind of feed, so I added one so I could subscribe to it. Magic.
But with FreshRSS 1.20.0, I no longer have to maintain my own tool to get this brilliant functionality, and I’m overjoyed. Let’s look at how it works by re-subscribing to Beverley’s blog but without a middleware tool.
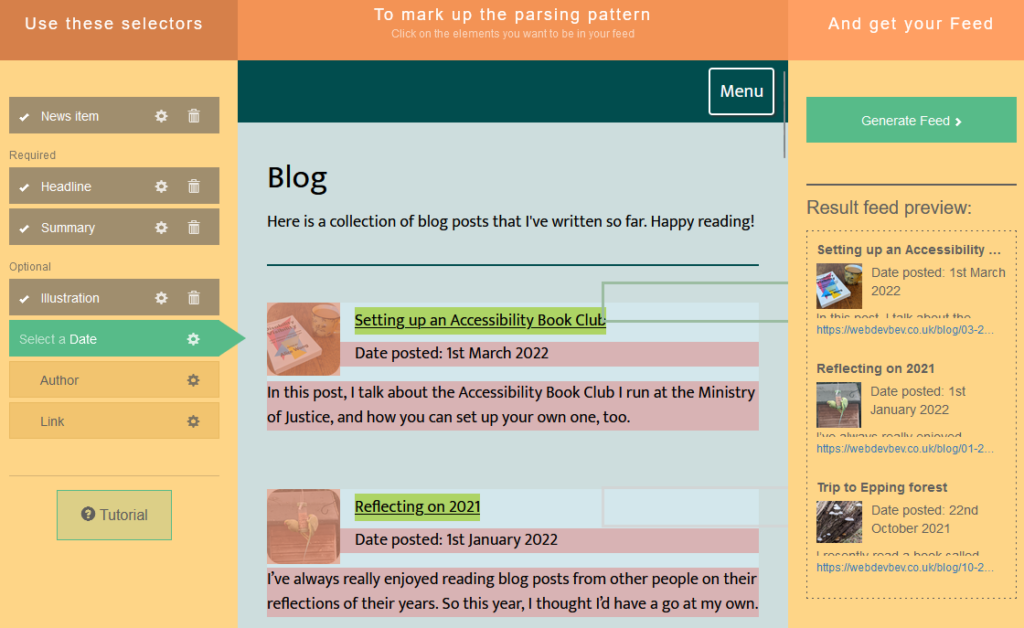
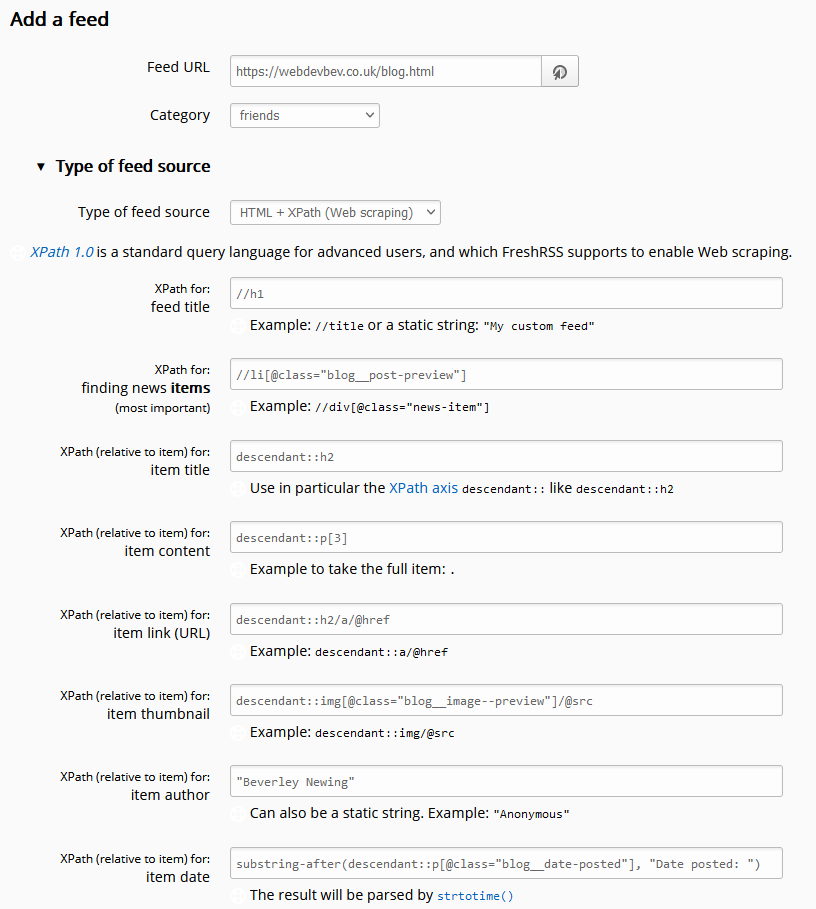
In the latest version of FreshRSS, when you add a new feed to your reader, a new section “Type of feed source” is available. Unfold it, and you can change from the default (“RSS / Atom”) to the new option “HTML + XPath (Web scraping)”. Put a human-readable page address rather than a feed address into the “Feed URL” field and fill these fields to tell FreshRSS how to parse the page to get the content you want. Note that it doesn’t matter if the web page isn’t valid XML (e.g. missing closing tags) because it’s going to get run through PHP’s DOMDocument anyway which will “correct” for some really sloppy code if needed.
![Browser debugger running document.evaluate('//li[@class="blog__post-preview"]', document).iterateNext() on Beverley's weblog and getting the first blog entry.](https://bcdn.danq.me/_q23u/2022/09/debugger-select-from-xpath-1024x256.png)
document.evaluate('//li[@class="blog__post-preview"]', document).iterateNext() and
got back the first blog post on the page, so I know I’m on the right track.
-
Feed title:
//h1
I override this anyway in FreshRSS, so I could just have used the a string, but I wanted the XPath practice. There’s only one<h1>on the page, and it can be considered the “title” of the feed. -
Finding items:
//li[@class="blog__post-preview"]
Each “post” on the page is an<li class="blog__post-preview">. -
Item titles:
descendant::h2
Each post has a<h2>which is the post title. The descendant:: selector scopes the search to each post as found above. -
Item content:
descendant::p[3]
Beverley’s static site generator template puts the post summary in the third paragraph of the<li>, which we can select like this. -
Item link:
descendant::h2/a/@href
This expects a URL, so we need the /@href to make sure we get the value of the<h2><a href="...">, rather than its contents. -
Item thumbnail:
descendant::img[@class="blog__image--preview"]/@src
Again, this expects a URL, which we get from the<img src="...">. -
Item author:
"Beverley Newing"
Beverley’s blog doesn’t host any guest posts, so I just use a string literal here. -
Item date:
substring-after(descendant::p[@class="blog__date-posted"], "Date posted: ")
This is the only complicated one: the published dates on Beverley’s blog aren’t explicitly marked-up, but part of a string that begins with the words “Date posted: “, so I use XPath’ssubstring-afterfunction to strtip this. The result gets passed to PHP’sstrtotime(), which is pretty tolerant of different date formats (although not of the words “Date posted:” it turns out!).
I hope that this is just the beginning for this new killer feature in FreshRSS: there’s so much more it can be and do. But for now, I’m still mighty impressed that I can begin to phase-out my use of my relatively resource-intensive feed-building middleware and use my feed reader to do more and more of the heavy lifting for which I love it so much.
I also love that this functionally adds h-feed support in by the back door. I’d still prefer there to be a “h-feed” option in the “Type of feed source” drop-down, but at least I can add such support manually, now!