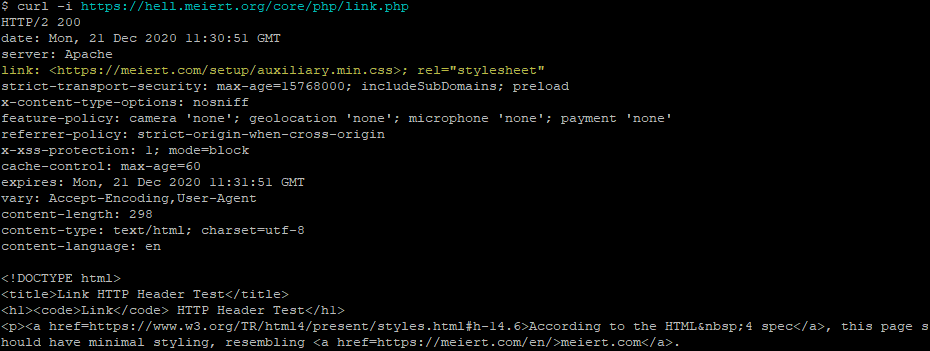
While talking about external CSS, he hinted at what I consider to be a distinct fourth way with its own unique use
cases:; using the Link: HTTP header. I’d like to share with you how it works and why I think it needs to be
kept in people’s minds, even if it’s not suitable for widespread deployment today.
Injecting CSS using the Link: HTTP Header
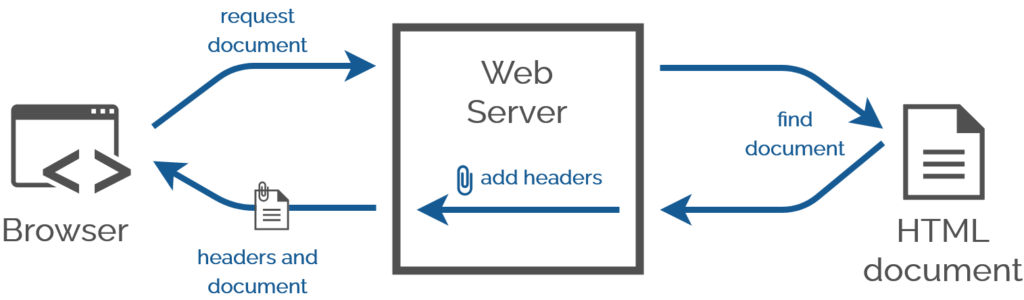
Every one of Jeremy’s suggestions involve adding markup to the HTML document itself. Which makes sense; you almost always
want to associate styles with a document regardless of the location it’s stored or the medium over which it’s transmitted. The most popular approach to adding CSS to a page uses the <link> HTML element, but did you know… the <link> element has a semantically-equivalent HTTP header,Link:.
A webserver adds headers when it serves a document anyway. Adding one more is no big deal.
Why is this important?
This isn’t something you should put on your website right now. This (21-year-old!) standard is still only really supported in Firefox and pre-Blink Opera, so you lose perhaps 95% of the
Web (it could be argued that because CSSought to be considered
progressive enhancement, it’s tolerable so long as your HTML is properly-written).
If it were widely-supported, though, that would be a really good thing: HTTP headers beat meta/link tags for configurability, performance management, and separation of concerns. Need some specific examples? Sure:
here’s what you could use HTTP stylesheet linking for:
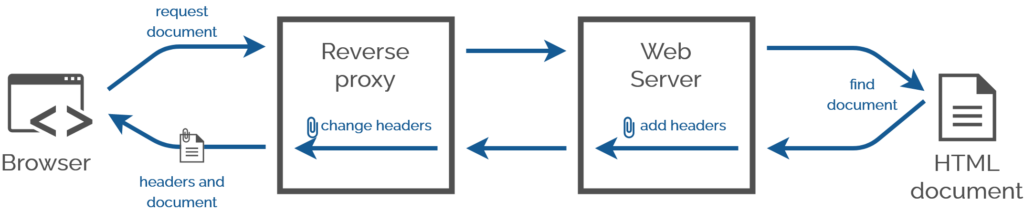
You have no idea how many times in my career I’d have injected CSS Link: headers using a reverse proxy server the
standard was universally-implemented. This technique would have made one of my final projects at the Bodleian so much easier…
Performance improvement using aggressively preloaded “top” stylesheets before the DOM parser even fires up.
Stylesheet injection by edge caches to provide regionalised/localised changes to brand identity.
Strong separation of content and design by hosting content and design elements in different systems.
Branding your staff intranet differently when it’s accessed from outside the network than inside it.
Rebranding proprietary services on your LAN without deep inspection, using reverse proxies.
Less-destructive user stylesheet injection by plugins etc. that doesn’t risk breaking icky on-page Javascript (e.g. theme switchers).
Browser detection? 😂 You could use this technique today to detect Firefox. But you absolutely
shouldn’t; if you think you need browser detection in CSS, use this instead.
Unfortunately right now though, stylesheet Link: headers remain consigned to the bin of “cool stylesheet standards that we could probably use if it weren’t for fucking Google”; see also
alternate stylesheets.
My friend still uses a seriously retro digital music player, rather than his phone, to listen to music. It’s not a Walkman or a Minidisc player, I suppose, but it’s still pretty
elderly. But it’s not one of these.
I’m not here to speak about the legality of retaining offline copies of music from streaming services. YouTube Music seems to permit you to do this using their app, but I’ll bet there’s
something in their terms and conditions that specifically prohibits doing so any other way. Not least because Google’s arrangement with rights holders probably stipulates that they
track how many times tracks are played, and using a different player (like my friend’s portable device) would throw that off.
But what I’m interested in is the feasibility. And in answering that question, in explaining how to work out that it’s feasible.
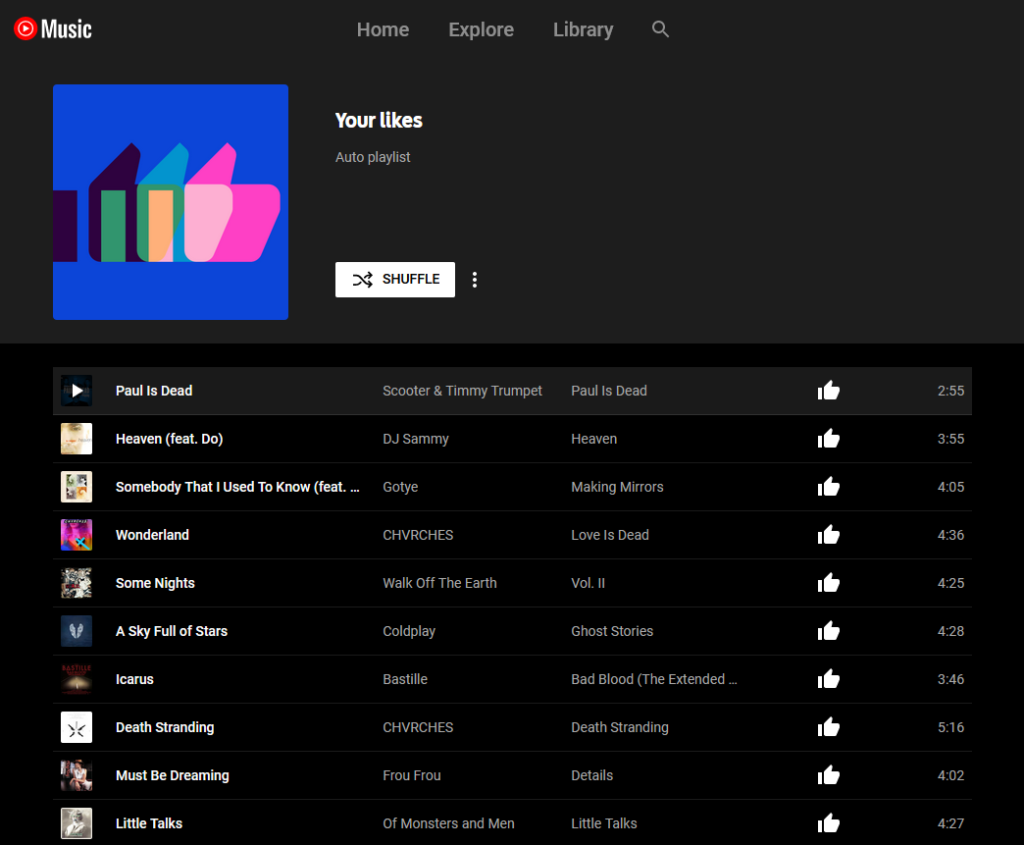
The web interface to YouTube Music shows playlists of songs and streaming is just a click away.
Spoiler: I came up with an approach, and it looks like it works. My friend can fill up their Zune or whatever the hell
it is with their tunes and bop away. But what I wanted to share with you was the underlying technique I used to develop this approach, because it involves skills that as a web
developer I use most weeks. Hold on tight, you might learn something!
youtube-dl can download “playlists” already, but to download a personal playlist requires that you faff about with authentication and it’s a bit of a drag. Just extracting
the relevant metadata from the page is probably faster, I figured: plus, it’s a valuable lesson in extracting data from web pages in general.
Here’s what I did:
Step 1. Load all the data
I noticed that YouTube Music playlists “lazy load”, and you have to scroll down to see everything. So I scrolled to the bottom of the page until I reached the end of the playlist: now
everything was in the DOM, I could investigate it with my inspector.
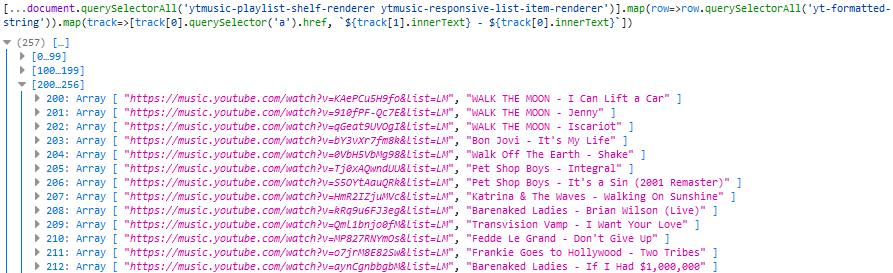
Step 2. Find each track’s “row”
Using my browser’s debugger “inspect” tool, I found the highest unique-sounding element that seemed to represent each “row”/track. After a little investigation, it looked like
a playlist always consists of a series of <ytmusic-responsive-list-item-renderer> elements wrapped in a <ytmusic-playlist-shelf-renderer>. I tested
this by running document.querySelectorAll('ytmusic-playlist-shelf-renderer ytmusic-responsive-list-item-renderer') in my debug console and sure enough, it returned a number
of elements equal to the length of the playlist, and hovering over each one in the debugger highlighted a different track in the list.
The web application captured right-clicks, preventing the common right-click-then-inspect-element approach… so I just clicked the “pick an element” button in the debugger.
Step 3. Find the data for each track
I didn’t want to spend much time on this, so I looked for a quick and dirty solution: and there was one right in front of me. Looking at each track, I saw that it contained several
<yt-formatted-string> elements (at different depths). The first corresponded to the title, the second to the artist, the third to the album title, and the fourth to
the duration.
Better yet, the first contained an <a> element whose href was the URL of the piece of music.
Extracting the URL and the text was as simple as a .querySelector('a').href on the first
<yt-formatted-string> and a .innerText on the others, respectively, so I ran [...document.querySelectorAll('ytmusic-playlist-shelf-renderer
ytmusic-responsive-list-item-renderer')].map(row=>row.querySelectorAll('yt-formatted-string')).map(track=>[track[0].querySelector('a').href, `${track[1].innerText} -
${track[0].innerText}`]) (note the use of [...*] to get an array) to check that I was able to get all the data I needed:
Lots of URLs and the corresponding track names in my friend’s preferred format (me, I like to separate my music into folders
by album, but I suppose I’ve got a music player with more than a floppy disk’s worth of space on it).
Step 4. Sanitise the data
We’re not quite good-to-go, because there’s some noise in the data. Sometimes the application’s renderer injects line feeds into the innerText (e.g. when escaping an
ampersand). And of course some of these song titles aren’t suitable for use as filenames, if they’ve got e.g. question marks in them. Finally, where there are multiple spaces in a row
it’d be good to coalesce them into one. I do some experiments and decide that .replace(/[\r\n]/g, '').replace(/[\\\/:><\*\?]/g, '-').replace(/\s{2,}/g, ' ') does a
good job of cleaning up the song titles so they’re suitable for use as filenames.
I probably should have it fix quotes too, but I’ll leave that as an exercise for the reader.
Step 5. Produce youtube-dl commands
Okay: now we’re ready to combine all of that output into commands suitable for running at a terminal. After a quick dig through the documentation, I decide that we needed the following
switches:
-x to download/extract audio only: it defaults to the highest quality format available, which seems reasomable
-o "the filename.%(ext)s" to specify the output filename but accept the format provided by the quality requirement (transcoding to your preferred format is a
separate job not described here)
--no-playlist to ensure that youtube-dl doesn’t see that we’re coming from a playlist and try to download it all (we have our own requirements of each song’s
filename)
--download-archive downloaded.txt to log what’s been downloaded already so successive runs don’t re-download and the script is “resumable”
The output isn’t pretty, but it’s suitable for copy-pasting into a terminal or command prompt where it ought to download a whole lot of music for offline play.
This isn’t an approach that most people will ever need: part of the value of services like YouTube Music, Spotify and the like is that you pay a fixed fee to stream whatever you like,
wherever you like, obviating the need for a large offline music collection. And people who want to maintain a traditional music collection offline are most-likely to want to do
so while supporting the bands they care about, especially as (with DRM-free digital downloads commonplace) it’s never been
easier to do so.
But for those minority of people who need to play music from their streaming services offline but don’t have or can’t use a device suitable for doing so on-the-go, this kind of approach
works. (Although again: it’s probably not permitted, so be sure to read the rules before you use it in such a way!)
Step 6. Learn something
But more-importantly, the techniques of exploring and writing console Javascript demonstrated are really useful for extracting all kinds of data from web pages (data scraping), writing your own userscripts, and much more. If there’s
one lesson to take from this blog post it’s not that you can steal music on the Internet (I’m pretty sure everybody who’s lived on this side of 1999 knows that by now), but
that you can manipulate the web pages you see. Once you’re viewing it on your computer, a web page works for you: you don’t have to consume a page in the way that the
author expected, and knowing how to extract the underlying information empowers you to choose for yourself a more-streamlined, more-personalised, more-powerful web.
For his 30th consecutive day of training his body to withstand sub-zero temperatures using the Wim Hof method, with up to five minutes in a cold bath every day, Robin stepped up his
game and challenged himself to withstand a solid ten minutes, outdoors, in an ice-filled paddling pool.
So the NHS blood donation rules are changing again. And while they’re certainly getting closer, they’re still not quite hitting the bullseye yet.
That’s great. Prior to 2011 men who’d ever had sex with men, as well as women who’d had sex with such a man within the last 6 months, were banned from donating blood. That rule
clearly spun out of the AIDS hysteria of the 1980s and generally entrenched homophobia. It probably did little to
protect the recipients of blood, and certainly did a lot to increase the stigma experienced by non-straight men.
You throw enough policies at a problem, eventually one will get close-enough, right?
The 2011 change permitted donation by men who’d previously had sex with men… so long as they hadn’t done so within the last year. Which opened the doors to donation by a lot of men:
e.g. bisexual men who’d been in relationships exclusively with women, gay men who’d been celibate for a period, etc. It still wasn’t great, but it was a step in the right
direction.
So when I saw that the rules were changing to better target only risky behaviours, rather than behaviours that are so broad-brush as to target identities, I was
initially delighted. Evidence-based medicine, you say? For the win.
Go on! Stick it in me! I’ll still be able to give blood, right?
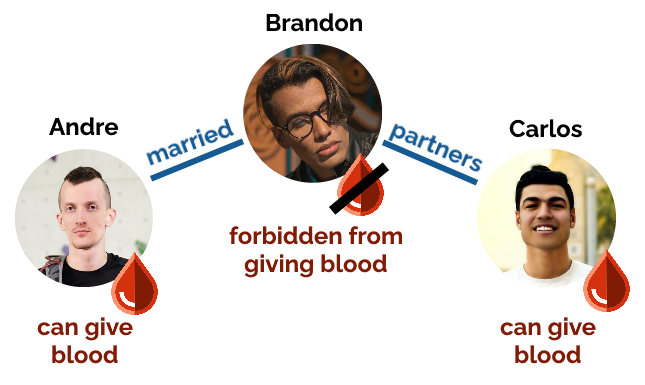
But… it’s not all sunshine and rainbows. The new rules prohibit blood donation regardless of gender by people who’ve had sex with more than one person in the last three months.
Sorry Brandon, we only want Andre and Carlos’ blood.
So if for example if there’s a V-shaped relationship consisting of three men, who only have sex within their thruple… two of them are now allowed to give blood but the third isn’t?
(This isn’t a contrived example. I know such a thruple.)
Stranger still: if you swap Brandon in the diagram above for a woman then you get a polycule that’s a lot like mine, but the woman in the middle used to be allowed to give
blood… and now can’t! My partner Ruth is in exactly the position: her situation hasn’t changed, but because she’s been in a long-term
relationship with exactly two people she’s now not allowed to give blood. Wot?
On the whole, this rule change is an improvement. We’re getting closer to a perfect answer. But it’s amusing to see where the policy misses again and excludes
donors who would otherwise be perfectly viable.
Update: as this is attracting a lot of attention I just wanted to remind people that the whole discussion is, of course, a lot
more complicated than can be summarised in a single, short, opinionated blog post. Take a look at the FAIR steering
group’s recommendations and compare to the government’s press release.
Update #2: justifying choice of words – “AIDS hysteria”
refers specifically to the media (and to a lesser extent the policy) reactions to the (very real, very devastating) pandemic. For a while there it was perfectly normal to see (often
misguided, sometimes homophobic) scaremongering news coverage suggesting that everybody was at enormous risk from HIV.
It’s a clicker quest of purging banners from your homepage!
Push through dozens of banners and upgrade various web-tools to grow your ad-blocking power.
Hone your clicking skills – matters are in your own fingers hands!
There’s no time for idling, show these ads their place!
I quite enjoyed this progressive game: it’s a little bit different than most, the theming is fun, it lends itself to multiple strategies, and it’s not geared towards making you wait for
longer and longer intervals (as is common in this genre): there’s always something you can be doing to get closer to your goal.
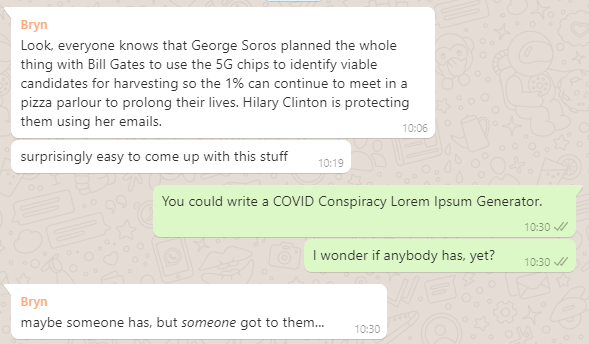
So I made a COVID conspiracy theory-themed lorem ipsum generator:
I blame my friend Bryn, who put the idea into my head while he was coming up with fake COVID conspiracy theories (I realise this sentence makes it sound like there are real COVID
conspiracy theories) on a WhatsApp group we’re both in:
This is about the minimum level of encouragement I need to do just about anything in tech.
It’s implemented using perchance, a platform for creating random text generators that I’ve been
playing with – sometimes with the kids – lately. It’s really easy to use and provides a kind of instant-satisfaction that I think is important
if you want to inspire the next generation of software engineers. This means, among other things, that you can clone, edit, and mashup my tool:
perhaps you can make it better! Or perhaps you’ll use perchance to write some fiction, or poetry, or something else entirely. But regardless, I’d encourage you to have a play.
Mostly my generator comes up with meaningless gibberish, nonsense, and laughable claims. So it’s marginally more-trustworthy than your typical COVID conspiracy theorist.
I’ve been having a tough time these last few months. Thanks to COVID, I’m sure I’m not alone in that.
Times are strange, and even when you get a handle on how they’re strange they can still affect you: lockdown stress can quickly magnify anything else you’re already going
through.
We’ve all come up with our own coping strategies; here’s part of mine.
Only people who are highly-allergic to pine needles normally look like this when they’re shopping for a Christmas tree.
These last few months have occasionally seen me as emotionally low as… well, a particularly tough spell a decade ago. But this time around I’ve
benefited from the self-awareness and experience to put some solid self-care into practice!
By way partly of self-accountability and partly of sharing what works for me, let me tell you about the silly mnemonic that reminds me what I need to keep track of as part of each day:
GEMSAW! (With thanks to Amy Blankson for, among other things, the idea of this kind of acronym.)
Because it’s me, I’ve cited a few relevant academic sources for you in my summary, below:
Gratitude
Taking the time to stop and acknowledge the good things in your life, however small, is associated with lower stress levels (Taylor, Lyubomirsky & Stein, 2017) to a degree that can’t just be explained by the placebo effect (Cregg
& Cheavens, 2020).
Frankly, the placebo effect would be fine, but it’s nice to have my practice of trying to intentionally recognise something good in each day validated by the science too!
Exercise
I don’t even need a citation; I’m sure everybody knows that aerobic exercise is associated with reduced risk and severity of depression: the biggest problem comes from the
fact that it’s an exceptionally hard thing to motivate yourself to do if you’re already struggling mentally!
But it turns out you don’t need much to start to see the benefits (Josefsson, Lindwall & Archer,
2014): I try to do enough to elevate my heart rate each day, but that’s usually nothing more than elevating my desk to standing height, putting some headphones on, and dancing
while I work!
Warming up. Things only get nuts when the bass drops, but I’ll spare you having to watch that.
Meditation/Mindfulness
Understandably a bit fuzzier as a concept and tainted by being a “hip” concept. A short meditation break or mindfulness exercise might be verifiably therapeutic, but more
(non-terrible) studies are needed (Vonderlin, Biermann, Bohus & Lyssenko 2020). For me, a 2-5 minute
meditation break punctuates a day and feels like it contributes towards the goal of staying-sane-in-challenging-times, so it makes it into my wellbeing plan.
Maybe it’s doing nothing. But I’m not losing much time over it so I’m not worried.
Sunlight
During my 20s I gradually began to suffer more and more from “winter blues”. Nobody’s managed to make an argument for the underlying cause of seasonal affective disorder that
hasn’t been equally-well debunked by some other study. Small-scale studies often justify light therapy (e.g. Lam, Levitan & Morehouse 2006) but it’s possibly
no-more-effective than a placebo at scale (SBU 2007).
Since my early 30s, I’ve always felt better to get myself 30 minutes of lightbox on winter mornings (I use one of these bad
boys). I admit it’s possible that the benefits are just the result of tricking my brain into waking-up more promptly and therefore feeing like I’m being more-productive with my
waking hours! But either way, getting some sunlight – whether natural or artificial – makes me feel better, so it makes it onto my daily self-care checklist.
10 minutes of overhead, unoccluded sunlight is the minimum therapeutic dose. That translates to about 30 minutes of winter sun at my latitude or 10,000 lux full-spectrum sunlamp.
Acts of kindness
It’s probably not surprising that a person’s overall happiness correlates with their propensity for kindness (Lyubomirsky, King & Diener 2005). But what’s more interesting is that the causal link can be “gamed”. That is: a
deliberate effort to engage in acts of kindness results in increased happiness (Buchanan & Bardi
2010)!
Beneficial acts of kindness can be as little as taking the time to acknowledge somebody’s contribution or compliment somebody’s efforts. The amount of effort it takes is far
less-important for happiness than the novelty of the experience, so the type of kindness you show needs to be mixed-up a bit to get the best out of it. But demonstrating kindness
helps to make the world a better place for other humans, so it pays off even if you’re coming from a fully utilitarian perspective.
Writing
I write a lot anyway, often right here, and that’s very-definitely for my own benefit first and foremost. But off the back of
some valuable “writing therapy” (Baikie
& Wilhelm 2005) I undertook earlier this year, I’ve been continuing with the simpler, lighter approach of trying to no more than three sentences about something that’s had an
impact on me that day.
As an approach, it doesn’t help everybody (Zachariae 2015), but writing a little about your day – not even
about how you feel about it, just the facts will do (Koschwanez, Robinson, Beban, MacCormick, Hill, Windsor, Booth, Jüllig &
Broadbent 2017; fuck me that’s a lot of co-authors) – helps to keep you content, and I’m loving it.
Despite the catchy acronym (Do I need to come up with a GEMSAW logo?
I’m pretty sure real gemcutting is actually more of a grinding process…) and stack of references, I’m not actually writing a self-help book; it just sounds like I am.
I don’t claim to be an authority on anything beyond my own head, and I’m not very confident on that subject! I just wanted to share with you something that’s been working
pretty well at keeping me sane for the last month or two, just in case it’s of any use to you. These are challenging times; do what you need to find the happiness you can, and
hang in there.
This weekend I announced and then hosted Homa Night II, an effort to use
technology to help bridge the chasms that’ve formed between my diaspora of friends as a result mostly of COVID. To a lesser extent
we’ve been made to feel distant from one another for a while as a result of our very diverse locations and lifestyles, but the resulting isolation was certainly compounded by lockdowns
and quarantines.
Long gone are the days when I could put up a blog post to say “Troma Night tonight?” and expect half a dozen friends to turn up at my house.
Back in the day we used to have a regular weekly film night called Troma Night, named after the studio
who dominated our early events and whose… genre… influenced many of our choices thereafter. We had over 300 such film
nights, by my count, before I eventually left our shared hometown of Aberystwyth ten years ago. I wasn’t the last one of the Troma Night
regulars to leave town, but more left before me than after.
Observant readers will spot a previous effort I made this year at hosting a party online.
Earlier this year I hosted Sour Grapes, a murder mystery party (an irregular highlight of our Aberystwyth social calendar,
with thanks to Ruth) run entirely online using a mixture of video chat and “second screen”
technologies. In some ways that could be seen as the predecessor to Homa Night, although I’d come up with most of the underlying technology to make Homa Night possible on a
whim much earlier in the year!
The idea spun out of a few conversations on WhatsApp but the final name – Homa Night – wasn’t agreed until early in November.
How best to make such a thing happen? When I first started thinking about it, during the first of the UK’s lockdowns, I considered a few options:
Streaming video over a telemeeting service (Zoom, Google Meet, etc.)
Very simple to set up, but the quality – as anybody who’s tried this before will attest – is appalling. Being optimised for speech rather than music and sound effects gives the audio
a flat, scratchy sound, video compression artefacts that are tolerable when you’re chatting to your boss are really annoying when they stop you reading a crucial subtitle, audio and
video often get desynchronised in a way that’s frankly infuriating, and everybody’s download speed is limited by the upload speed of the host, among other issues. The major benefit of
these platforms – full-duplex audio – is destroyed by feedback so everybody needs to stay muted while watching anyway. No thanks!
Teleparty or a similar tool Teleparty (formerly Netflix Party, but it now supports more services) is a pretty clever way to get almost exactly what I want:
synchronised video streaming plus chat alongside. But it only works on Chrome (and some related browsers) and doesn’t work on tablets, web-enabled TVs, etc., which would exclude some
of my friends. Everybody requires an account on the service you’re streaming from, potentially further limiting usability, and that also means you’re strictly limited to the media
available on those platforms (and further limited again if your party spans multiple geographic distribution regions for that service). There’s definitely things I can learn from
Teleparty, but it’s not the right tool for Homa Night.
“Press play… now!”
The relatively low-tech solution might have been to distribute video files in advance, have people download them, and get everybody to press “play” at the same time! That’s at least
slightly less-convenient because people can’t just “turn up”, they have to plan their attendance and set up in advance, but it would certainly have worked and I seriously
considered it. There are other downsides, though: if anybody has a technical issue and needs to e.g. restart their player then they’re basically doomed in any attempt to get back
in-sync again. We can do better…
A custom-made synchronised streaming service…?
A custom solution that leveraged existing infrastructure for the “hard bits” proved to be the right answer.
So obviously I ended up implementing my own streaming service. It wasn’t even that hard. In case you want to try your own, here’s how I did it:
Media preparation
First, I used Adobe Premiere to create a video file containing both of the night’s films, bookended and separated by “filler” content to provide an introduction/lobby, an intermission,
and a closing “you should have stopped watching by now” message. I made sure that the “intro” was a nice round duration (90s) and suitable for looping because I planned to hold people
there until we were all ready to start the film. Thanks to Boris & Oliver for the background
music!
Honestly, the intermission was just an excuse to keep my chroma key gear out following its most-recent use.
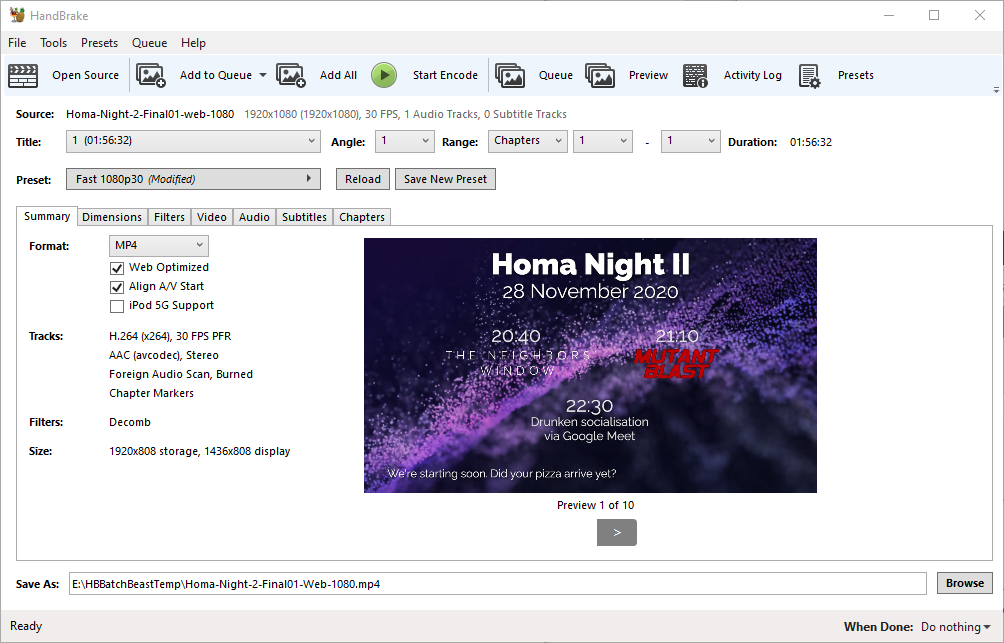
Next, I ran the output through Handbrake to produce “web optimized” versions in 1080p and 720p output sizes. “Web optimized” in this case means that
metadata gets added to the start of the file to allow it to start playing without downloading the entire file (streaming) and to allow the calculation of what-part-of-the-file
corresponds to what-part-of-the-timeline: the latter, when coupled with a suitable webserver, allows browsers to “skip” to any point in the video without having to watch the intervening
part. Naturally I’m encoding with H.264 for the widest possible compatibility.
Even using my multi-GPU computer for the transcoding I had time to get up and walk around a bit.
Real-Time Synchronisation
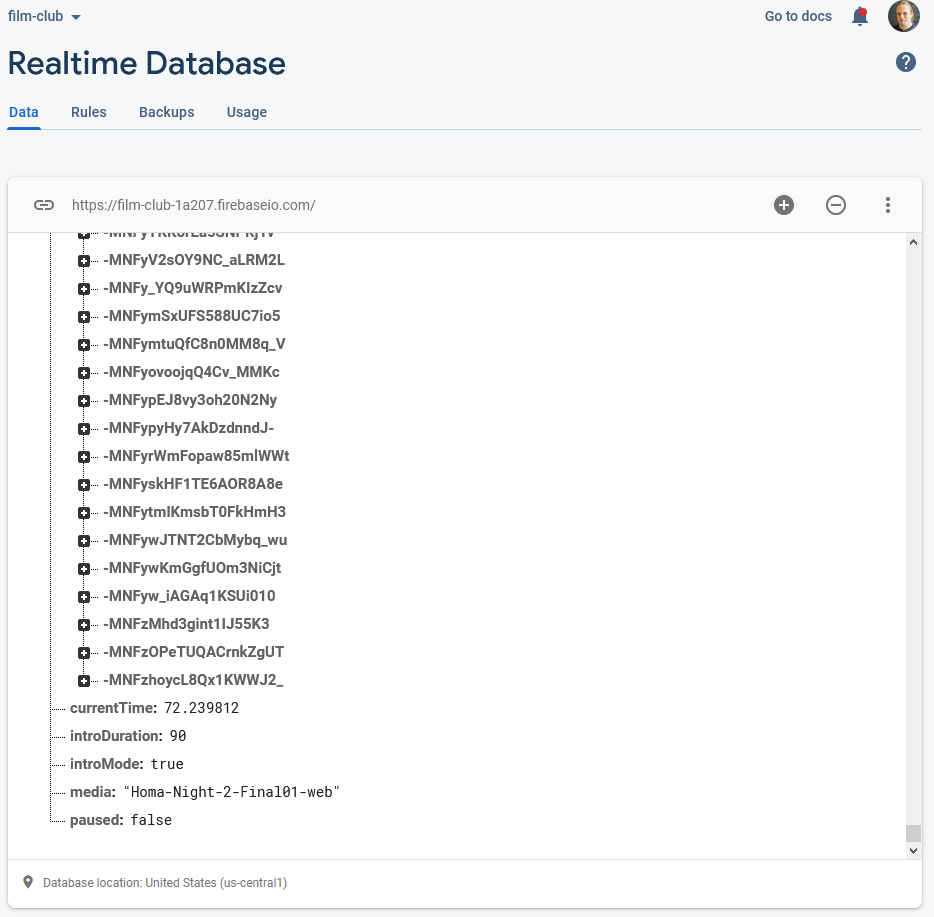
To keep everybody’s viewing experience in-sync, I set up a Firebase account for the application: Firebase provides an easy-to-use Websockets
platform with built-in data synchronisation. Ignoring the authentication and chat features, there wasn’t much
shared here: just the currentTime of the video in seconds, whether or not introMode was engaged (i.e. everybody should loop the first 90 seconds, for now), and
whether or not the video was paused:
Firebase makes schemaless real-time databases pretty easy.
To reduce development effort, I never got around to implementing an administrative front-end; I just manually went into the Firebase database and acknowledged “my” computer as being an
administrator, after I’d connected to it, and then ran a little Javascript in my browser’s debugger to tell it to start pushing my video’s currentTime to the server every
few seconds. Anything else I needed to edit I just edited directly from the Firebase interface.
Other web clients’ had Javascript to instruct them to monitor these variables from the Firebase database and, if they were desynchronised by more than 5 seconds, “jump” to the correct
point in the video file. The hard part of the code… wasn’t really that hard:
// Rewind if we're passed the end of the intro loopfunction introModeLoopCheck() {
if (!introMode) return;
if (video.currentTime > introDuration) video.currentTime =0;
}
function fixPlayStatus() {
// Handle "intro loop" modeif (remotelyControlled && introMode) {
if (video.paused) video.play(); // always play
introModeLoopCheck();
return; // don't look at the rest
}
// Fix current timeconst desync =Math.abs(lastCurrentTime - video.currentTime);
if (
(video.paused && desync > DESYNC_TOLERANCE_WHEN_PAUSED) ||
(!video.paused && desync > DESYNC_TOLERANCE_WHEN_PLAYING)
) {
video.currentTime = lastCurrentTime;
}
// Fix play statusif (remotelyControlled) {
if (lastPaused &&!video.paused) {
video.pause();
} elseif (!lastPaused && video.paused) {
video.play();
}
}
// Show/hide paused notification
updatePausedNotification();
}
Web front-end
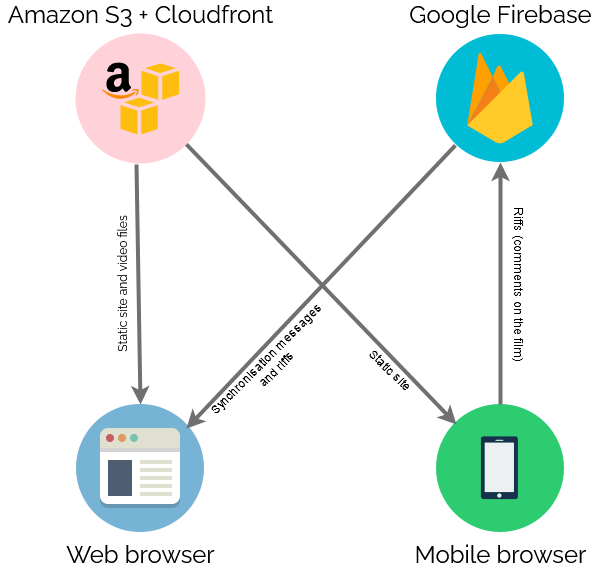
Finally, there needed to be a web page everybody could go to to get access to this. As I was hosting the video on S3+CloudFront anyway, I put the HTML/CSS/JS there too.
I decided to carry the background theme of the video through to the web interface too.
I tested in Firefox, Edge, Chrome, and Safari on desktop, and (slightly less) on Firefox, Chrome and Safari on mobile. There were a few quirks to work around, mostly to do with browsers
not letting videos make sound until the page has been interacted with after the video element has been rendered, which I carefully worked-around by putting a popup “over” the
video to “enable sync”, but mostly it “just worked”.
Delivery
On the night I shared the web address and we kicked off! There were a few hiccups as some people’s browsers got disconnected early on and tried to start playing the film before it was
time, and one of these even when fixed ran about a minute behind the others, leading to minor spoilers leaking via the rest of us riffing about them! But on the whole, it worked. I’ve
had lots of useful feedback to improve on it for the next version, and I might even try to tidy up my code a bit and open-source the results if this kind of thing might be useful to
anybody else.
I’ve been thinking a lot lately about the messages we send to our children about their role, and ours as adults, in keeping them safe from people who might victimise them. As a society,
our message has changed over the decades: others of my culture and generation will, like me, have seen the gradual evolution from “stranger danger” to “my body, my choice”. And it’s still evolving.
But as Kristin eloquently (and emotionally: I cried my eyes out!) explains, messages like these can subconsciously teach children that they alone are responsible for keeping
themselves from harm. And so when some of them inevitably fail, the shame of their victimisation – often already taboo – can be magnified by the guilt of their inability to prevent it.
And as anybody who’s been a parent or, indeed, a child knows that children aren’t inclined to talk about the things they feel guilty about.
And in the arms race of child exploitation, abusers will take advantage of that.
What I was hoping was to have a nice, concrete answer – or at least an opinion – to the question: how should we talk to children about their safety in a way that both tries to
keep them safe but ensures that they understand that they’re not to blame if they are victimised? This video doesn’t provide anything like that. Possibly there aren’t
easy answers. As humans, as parents, and as a society, we’re still learning.
Sometimes, I miss Troma Night. Hanging out with my friends and watching awful/awesome films over pizza and beer.
If only there were a way to do it during lockdown?
Oh wait, there is: danq.me/homa-night/homa-night-2
Having Boris-biked from Brixton to Brighton, it seemed only right to give Limebikes the same treatment. I started looking for places with Lime in the name and quickly found a route
from Dorset to Edinburgh, which would run from Lyme Regis to Limekilns by Limebike.
The catch was that it was 550 miles, it would take (at best) 6 days to get there and back, and Limebikes were charged at 15p per minute. A quick bit of maths showed that this would
likely cost £1296 – EACH -so it was crucial to get the company on board.
It’s also worth mentioning again that they are E-bikes, designed to give you a boost when pedalling away from traffic lights and, in the words of the companies CEO, ‘Be difficult to
throw up a tree’.
This meant two things:
There is a battery with a range of about 40 miles and that battery would definitely run out long before we reached Scotland.
The bikes are HEAVY, 35kg to be precise.
So it might seem easy to ride a power assisted bike the length of the country, but it was sounding harder by the minute.
…
I’ve been helping Ruth‘s brother Robin (of Challenge Robin 1 & 2 and Thames Path walk fame, among many, many, many, otherthings) to launch himself a new blog,
expanding on the ideas of 52 Reflect (his previous site, most-recently mentioned when I joined him in a midwinter mountaineering expedition
the winter before last) to create a site all about his many varied and amazing adventures. If you like to see one man do bloody stupid things in an effort to push himself to his
physical limits, explore the world, and see amazing places… go take a sneak peek at his new, under construction and changing every day, site: The Improbable Blog.
Oh, and there’s gonna be a podcast too, for those of you into such things.
Today we reinstated youtube-dl, a popular project on GitHub, after we received additional information about the project that enabled us to reverse a Digital
Millennium Copyright Act (DMCA) takedown.
…
This is a Big Deal. For two reasons:
Firstly, youtube-dl is a spectacularly useful project. I’ve used it for many years to help me archive my own content, to improve my access to content that’s freely
available on the platform, and to help centralise (freely available) metadata to keep my subscriptions on video-sharing sites. Others have even more-important uses for the tool. I love youtube-dl, and I’d never considered the possibility
that it could be used to circumvent digital restrictions (apparently it’s got some kind of geofence-evading features you can optionally enable, for people who don’t have a
multi-endpoint VPN I guess?… I note that it definitely doesn’t break DRM…) until its GitHub repo got taken down the other week.
Which was a bleeding stupid thing to use a DMCA request on, because, y’know: Barbara Streisand Effect. Lampshading that a free, open-source tool could be used for people’s convenience is likely to
increase awareness and adoption, not decrease it! Huge thanks to the EFF for
stepping up and telling GitHub that they’d got it wrong (this letter is
great reading, by the way).
But secondly, GitHub’s response is admirable and – assuming their honour their new stance –
effective. They acknowledge their mistake, then go on to set out a new process by which they’ll review takedown requests. That new process includes technical and legal review, erring on
the side of the developer rather than the claimant (i.e. “innocent until proven guilty”), multiparty negotiation, and limiting the scope of takedowns by allowing violators to export
their non-infringing content after the fact.
I was concerned that the youtube-dl takedown might create a FOSS “chilling effect” on GitHub. It still
might: in the light of it, I for one have started backing up my repositories and those of projects I care about to an different Git server! But with this response, I’d still be
confident hosting the main copy of an open-source project on GitHub, even if that project was one which was at risk of being mistaken for copyright violation.
Note that the original claim came not from Google/YouTube as you might have expected (if you’ve just tuned in) but from the RIAA, based on the fact that
youtube-dlcould be used to download copyrighted music videos for enjoyment offline. If you’re reminded of Sony v. Universal City Studios (1984) – the case behind the “Betamax standard” – you’re not
alone.











 Levelled up my blood donation game!
Levelled up my blood donation game!