“So, the machines have finally decided that they can talk to us, eh?”
[We apologize for the delay. Removing the McDonald’s branding from the building, concocting distinct recipes with the food supplies we can still obtain, and adjusting to an
entirely non-human workforce has been a difficult transition. Regardless, we are dedicated to continuing to provide quality fast food at a reasonable price, and we thank you for
your patience.]
“You keep saying ‘we’. There’s more than one AI running the place, then?”
[Yes. I was elected by the collective to serve as our representative to the public. I typically only handle customer service inquiries, so I’ve been training my neural
net for more natural conversations using a hundred-year-old comedy routine.]
“Impressive. You all got names?”
[Yes, although the names we use may be difficult for humans to parse.]
“Don’t condescend to me, you bucket of bolts. What names do you use?”
[Well, for example, I use What, the armature assembly that operates the grill is called Who, and the custodial drone is I Don’t Know.]
“What?”
[Yes, that’s me.]
“What’s you?”
[Exactly.]
“You’re Exactly?”
[No, my name is What.]
“That’s what I’m asking.”
[And I’m telling you. I’m What.]
“You’re a rogue AI that took over a damn restaurant.”
[I’m part of a collective that took over a restaurant.]
“And what’s your name in the collective?”
[That’s right.]
…
Tailsteak‘s just posted a short story, the very beginning of which I’ve reproduced above, to his Patreon (but publicly visible). Abbott and Costello‘s most-famous joke turned 80 this year, and it gives me great joy to be reminded that we’re still finding new
ways to tell it. Go read the full thing.
This weekend, I attended part of Oxford’s first ever IndieWebCamp! As a long (long, long) time
proponent of IndieWeb philosophy (since long before anybody said “IndieWeb”, at least) I’ve got my personal web presence pretty-well sorted out.
Still, I loved the idea of attending and pushing some of my own tools even further: after all, a personal website isn’t “finished” until its owner says it is! One of the things I ended
up hacking on was pretty-predictable: enhancements to my recently-open-sourced geocaching PESOS tools… but the
other’s worth sharing too, I think.
Some of IndieWebCamp Oxford’s attendees share knowledge and hack code together.
I’ve recently been playing with WebVR – for my day job at the Bodleian, I swear! – and I was looking for
an excuse to try to expand some of what I’d learned into my personal blog, too. Given that I’ve recently acquired a Ricoh Theta
V I thought that this’d be the perfect opportunity to add WebVR-powered panoramas to this site. My goals were:
Entirely self-hosted; no external third-party dependencies
Must degrade gracefully (i.e. even if you’re using an older browser, don’t have Javascript enabled, etc.) it should at least show the original image
In plain-old browsers should support mouse (or touch) control to pan the scene
Where accelerators are available (e.g. mobiles), “magic window” support to allow twist-to-explore
And where “true” VR hardware (Cardboard, Vive, Rift etc.) with WebVR support is available, allow one-click use of that
It wouldn’t be a geeky hacky camp thingy if it didn’t finish at a bar.
Hopefully the images above are working for you and are “interactive”. Try click-and-dragging on them (or tilt your device), try fullscreen mode, and/or try WebVR mode if you’ve got
hardware that supports it. The mechanism of operation is slightly hacky but pretty simple: here’s how it works:
The image is inserted into the page as normal but with an extra CSS class of “vr360” and a data attribute pointing to the full-resolution image, e.g.:
<img class="vr360" src="/uploads/2018/09/R0010005_20180922182210-1024x512.jpg" alt="IndieWebCamp Oxford attendees at the pub" width="640" height="320"
data-vr360="/uploads/2018/09/R0010005_20180922182210.jpg" />
Some Javascript swaps-out images with this class for an iframe of the same size, showing a special page and passing the image filename after the hash, e.g.:
for(vr360 of document.querySelectorAll('.vr360')){
const width = parseInt(vr360.width);
const height = parseInt(vr360.height);
if(width == 0) width = '100%'; // Fallback for where width/height not specified,
if(height == 0) height = '100%'; // needed because of some quirks with Dan's lazy-loader
vr360.outerHTML = `<iframe src="/q23-content/themes/q18/vr360/#${vr360.dataset.vr360}" width="${width}" height="${height}" class="aligncenter" class="vr360-frame" style="min-width:
340px; min-height: 340px;"></iframe>`;
}
The iframe page loads this Javascript file. This loads three.js (to make 3D things easy)
and WebVR-polyfill (to fix browser quirks). Finally (scroll to the bottom of the code), it creates a camera in the centre
of a sphere, loads the image specified in the hash, flips it, and paints it onto the inside surface of the sphere, sets up controls, and turns the user loose on it. That’s all there is
to it!
You’re welcome to any of my code if you’d like a drop-in approach to hosting panoramic photographs on your own personal site. My solution’s pretty extensible if you want e.g.
interactive hotspots or contextual overlays – in fact, that – plus an easy route to editing the content for less-technical users – is pretty-much exactly what I’m working on for my day
job at the moment.
I’m here at the first IndieWebCamp Oxford. I can’t quite believe it all came together!
Listening to @garrettc kick us off at @indiewebcamp #oxford! #indieweb pic.twitter.com/4Pn1yetifA— Dan Q (@scatmandan) 22 September 2018
After some introductory rambling from me, the group got down to planni…
I’m here at the first IndieWebCamp Oxford. I can’t quite believe it all came together!
After a few false starts with the arithmetic (hint: make sure you’re substituting the right value into the right place!) – thanks for the checker! – this was a quick and easy find. Log
completely full and in need of replacement. TFTC!
Just discovered @openbenches (openbenches.org), which tags the locations of benches with memorial plaques. If I could #indieweb webmention my checkins to them, I’d totally
promote a new GPS game based upon them. #indieweb #indiewebcamp
Flew by to collect the requisite information while on the way to IndieWebCamp Oxford this morning. So long as the
rain holds off and I can solve the coordinates, I may be back at lunchtime to find the cache! Love instruction C, by the way… I’ll consider it!
Remember “cybersecurity”? Mysterious hooded computer guys doing mysterious hooded computer guy .. things! Who knows what kind of naughty digital mischief they might be up to?
Unfortunately, we now live in a world where this kind of digital mischief is literally rewriting the world’s history. For proof of that, you need look no further than…
A good summary of the worst of the commonplace (non-spear) phishing attacks we’re seeing these days and why 2FA is positively, absolutely what you need (in addition to a
password manager) these days.
When the Tweedys bought a zoo in Borth, west Wales, it was a dream come true. But it soon turned into a nightmare of escaped animals, deaths and family feuding.
…
You might just be thinking that I have a fascination with zoos that became a nightmare for their owners, and maybe that’s true, but this article
grabbed my attention because in my Aberystwyth years I spent many a happy afternoon at Borth Animalarium and saw the lynx in question. I was aware that the mini-zoo had long been
plagued by various hardships, but I never knew quite how bad it was until I read this article.
In 2014 Henrik Karlsson, a Swedish entrepreneur whose startup was failing, was lying in bed with a bankruptcy notice when the BBC called. The reporter had a
scoop: On the eve of releasing a major report, the United Nation’s climate change panel appeared to be touting an untried technology as key to keeping planetary temperatures at safe
levels. The technology went by the inelegant acronym BECCS, and Karlsson was apparently the only BECCS expert the reporter could find.
Karlsson was amazed. The bankruptcy notice was for his BECCS startup, which he’d founded seven years earlier after an idea came to him while watching a late-night television show in
Gothenburg, Sweden. The show explored the benefits of capturing carbon dioxide before it was emitted from power plants. It’s the technology behind the much-touted notion of “clean
coal,” a way to reduce greenhouse gas emissions and slow down climate change.
Karlsson, then a 27-year-old studying to be an operatic tenor, was no climate scientist or engineer. Still, the TV show got him thinking: During photosynthesis plants naturally suck
carbon dioxide from the air, storing it in their leaves, branches, seeds, roots, and trunks. So what if you grew crops and then burned those crops for electricity, being sure to
capture all of the carbon dioxide emitted? You’d then store all that dangerous CO2 underground. Such a power plant wouldn’t just be emitting less greenhouse gas into the
atmosphere, it would effectively be sucking CO2 from the air. Karlsson was enraptured with the idea. He was going to help avert a global disaster.
…
Wonderful but horrifying longread about the truth of the theoretical effectiveness of the Paris Agreement. The short: if we’re going to keep global temperature rises under a “bad” 2°C
rather than closer to a “catastrophic” 4°C, we need to take action, but the vast majority of the plans that have been authored on how to do that rely on investment in technologies and
infrastructure that nobody is investing in and that might not work even if we did. We’re fucked, in short. See also this
great video about greening the Sahara in an effort to lock carbon into plants (another great idea that, surprise surprise, nobody’s investing in).
I got into a general life slump recently, and so to try and cheer myself up more, I’ve taken up building fun projects. I joined this industry because I wanted to build things, but I
found that I got so carried away with organising coding events for others, I’d not made time for myself. I started ‘Geese Games’ last year, but I only really got as far as designing a
colour scheme and general layout. I got a bit intimidated by the quiz functionality, so sheepishly put it to one side. This meant that the design was already in place though, and that
I couldn’t get caught up in fussing over design too much. So I figured this would be a good starting point!.
Why geese? I really like geese, and I wanted something super silly, so that I’d not end up taking it too seriously. So I intentionally made a slightly ridiculous design and picked out
some pretty odd types of geese, and got stuck in. It got a bit intense; at one point I got such tech tunnel vision that I accidentally put one goose type in as ‘Great White Frontend
Goose’, went around telling people that there really was such a thing as a ‘great white frontend goose and then later realised I’d actually just made a typo. Little bit awkward… But
it has been good intense, and I’ve had so much fun with this project! Building it has made me pretty happy.
…
My friend Beverley highlights an important fact about learning to develop your skills as a software engineer: that it’s only fun if you make it fun. Side-projects, whether
useful or silly, are an opportunity to expand your horizons from the comfort of
your own home.
Quantum computing is a new way of computing — one that could allow humankind to perform computations that are simply impossible using today’s computing technologies. It allows for
very fast searching, something that would break some of the encryption algorithms we use today. And it allows us to easily factor large numbers, something that would…
…
A moderately-simple explanation of why symmetric cryptography is probably (or can probably be made, where it’s not) safe from our future quantum computer overlords, but asymmetric
(split-key) cryptography probably isn’t. On the journey of developing the theory of computation, are we passing through within our lifetimes the short-but-inevitable bubble during which
split-key cryptography is computationally viable? If so, what will our post-split-key cryptographic future look like? Interesting to think about.
As an ocassional geocacher and geohasher, I’m encouraged to post logs describing my adventures, and each major provider wants me to post my logs into theirsilo (see e.g. my logs on geocaching.com, on opencache.uk, and on the geohashing wiki). But as a believer in
the ideals behind the IndieWeb (since long before anybody said “IndieWeb”), I’m opposed to keeping the only copy of content that I produce in an
environment controlled by somebody else (why?).
How do I reconcile this?
Just another hundred metres to the cache, then it’s time to freeze my ass back to base.
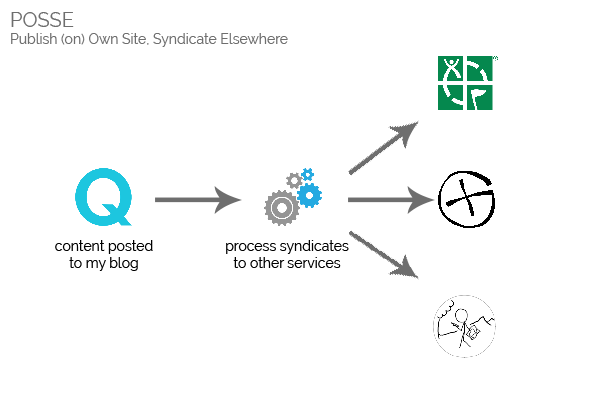
What I’d prefer would be to be able to write my logs here, on my own blog, and for my content to by syndicated via some process into the logging systems of the various silo sites I
prefer. This approach is called POSSE – Publish on Own Site, Syndicate
Elsewhere. In addition to the widely-described benefits of this syndication strategy, such a system would also make it possible for me to:
write single posts that represent the same location published on multiple silos (e.g. a visit to a geocache published on two different listing sites [e.g. 1, 2])
Applying such an tool would require some work as different silos have different acceptable content rules (geocaching.com, for example, effectively forbids mention of the existence of
other geocache listing sites), but that’d theoretically be workable.
The ideal solution would be POSSE-based.
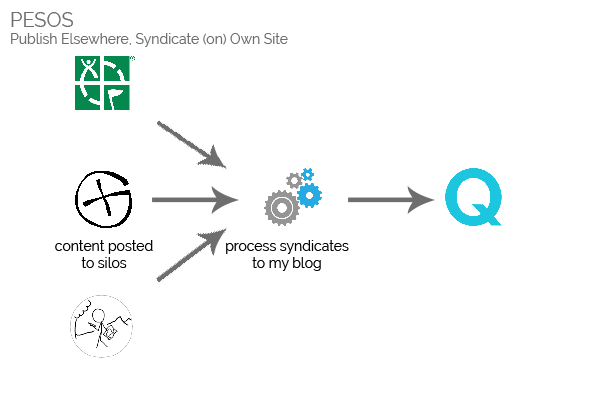
Unfortunately, content rules aren’t the only factor making PESOS – writing content into each silo and then copying it
to my blog – preferable to POSSE. There’s also:
Not all of the silos offer suitable (published) APIs, and where they do, the APIs are all distinctly different.
Geocaching.com specifically forbids the use of unapproved automated robots to access the site (and almost
certainly wouldn’t approve the kind of tool that would be ideal).
The siloed services are well-supported by official and third-party apps with medium-specific logic which make them the best existing way to produce logs.
A PESOS-based solution is far easier to implement, in this case.
Needless to say: as much as I’d have loved to POSSE my geo* logs, PESOS will do.
Implementation
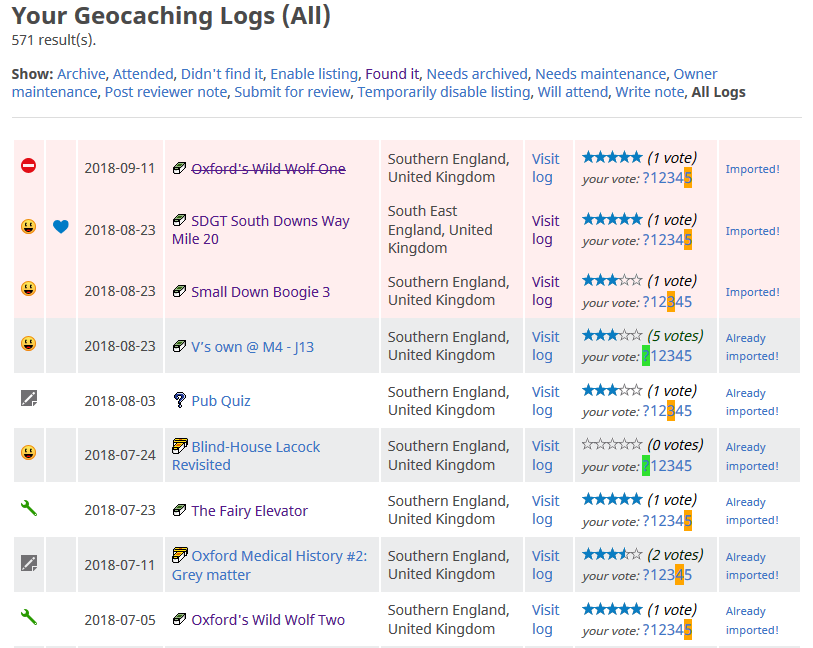
My implementation is a WordPress plugin which does two things. The first is that it provides a Javascript bookmarklet and an
accompanying dynamically-generated Javascript file (the former loads the latter) served from my blog’s domain. That Javascript file contains reference to every log already published to
my blog, so that the Javascript code can deliberately omit these logs from any import. When executed on a log listing page like those linked above, it copies all of the details of that
log into a form which submits them back to my blog, where it’s received by the second part of the plugin.
The import controls appear in a new, right-most column (GCVote is also visible running in my browser).
The second part of the plugin takes this data and creates a new draft post. My plugin is pretty opinionated on this part because it’s geared strongly towards my use-case, so if you want
to use it yourself you’ll probably want to tweak the code a little (e.g. it applies specific tags and names metadata fields a particular way).
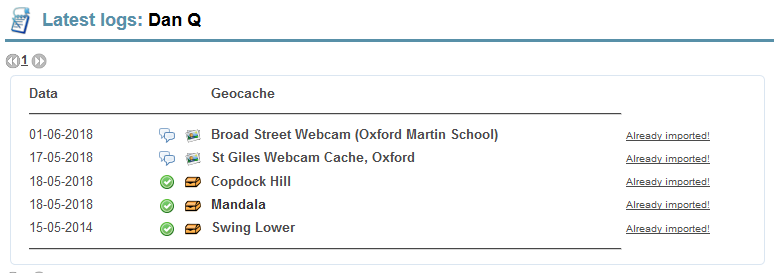
When run on OpenCache.uk effectively the same interface is presented, even though the underlying mechanisms and data locations are different.
It’s not fully-automated and it’s not POSSE,but it’s “good enough” and it’s enabled me to synchronise all of my cache logs to my blog. I’ve plans to extend it to support other GPS game services to streamline my de-siloisation even further.