My 12-year-old’s persuaded me to take her to MegaConLive London this weekend.
As somebody who doesn’t pay much attention to the pop culture circles represented by such an event (and hasn’t for 15+ years, or whenever it was that Asdfbook came out?)…
have you got any advice for me, Internet?
1 Things that weren’t technically-feasible back when I created the site in 2011 like making the PDF generation happen in the browser, so no personal information ever has to leave
your computer, for example
2 Y’know, those things for people who can’t even be bothered to turn their phone into the
same orientation as virtually every television, cinema screen, and computer monitor that’s ever been made (not that the owners of those larger screens can always turn them to portrait
orientation!). Turns out I have strong feelings about portrait video! But if that’s the way to reach out and help the widest diversity of people, I guess that’s what I’ve got to do…
This is the age we’re shifting into: an era in which post-truth politics and deepfake proliferation means that when something looks “a bit off”, we assume (a) it’s AI-generated, and (b)
that this represents a deliberate attempt to mislead. (That’s probably a good defence strategy nowadays in general, but this time around it’s… more-complicated…)
…
So if these fans aren’t AI-generated fakes, what’s going on here?
The video features real performances and real audiences, but I believe they were manipulated on two levels:
Will Smith’s team generated several short AI image-to-video clips from professionally-shot audience photos
YouTube post-processed the resulting Shorts montage, making everything look so much worse
…
I put them side-by-side below. Try going full-screen and pause at any point to see the difference. The Instagram footage is noticeably better throughout, though some of the audience
clips still have issues.
…
The Internet’s gone a bit wild over the YouTube video of Will Smith with a crowd. And if you look at it, you can see why:
it looks very much like it’s AI-generated. And there’d be motive: I mean, we’ve already seen examples where politicians have been accused (falsely, by Trump, obviously) of using AI to exaggerate the size of their crowds, so
it feels believable that a musician’s media team might do the same, right?
But yeah: it turns out that isn’t what happened here. Smith’s team did use AI, but only to make sign-holding fans from other concerts on the same tour appear
to all be in the same place. But the reason the video “looks AI-generated” is because… YouTube fucked about with it!
It turns out that YouTube have been secretly experimenting with upscaling
shorts, using AI to add detail to blurry elements. You can very clearly see the effect in the video above, which puts the Instagram and YouTube versions of the video side-by-side (of
course, if YouTube decide to retroactively upscale this video then the entire demonstration will be broken anyway, but for now it works!). There are many
points where a face in the background is out-of-focus in the Instagram version, but you can see in the YouTube version it’s been brought into focus by adding details. And
some of those details look a bit… uncanny valley.
Every single bit of this story – YouTube’s secret experiments on creator videos, AI “enhancement” which actually makes things objectively worse, and the immediate knee-jerk reaction of
an understandably jaded and hypersceptical Internet to the result – just helps cement that we truly do live in the stupidest timeline.
We’ve been enjoying the latest season of Jet Lag: The Game, which has seen Sam, Ben, and
Adam playing “Snake” across South Korea’s rail network. It’s been interestingly different than their usual games, although the format’s not quite as polished as Hide & Seek or Tag Eur
It, of course.
The Taste Test Buldak roadblock required the Snaker player to do a blindfolded identification of three different noodle flavours.
In any case: after episode 4 and 5 introduced us to Samyang Foods‘ Buldak noodles, JTA
sourced a supply of flavours online and had them shipped to us. Instant ramen’s a convenient and lazy go-to working lunch in our household, and
the Jet Lag boys’ reviews compelled us to give them a go1.
Buldak (불닭) literally means “fire chicken”, and I find myself wondering if the Korean word for domestic chickens
(닭 – usually transliterated as “dak”, “dalg”, or “tak”) might be an onomatopoeic representation of the noise a
chicken makes?2
So for lunch yesterday, while I waited for yet another development environment rebuild to complete, I decided to throw together some
noodles. I went for a packet of the habanero lime flavour, which I padded out with some peas, Quorn3, and a soft-boiled
egg.
There’s no photogenic way to be captured while eating ramen. I promise that this is the least-awful of the snaps I grabbed as I enjoyed my lunch.
It was spicy, for sure: a pleasant, hot, flavourful and aromatic kind of heat. Firey on the tongue, but quick to subside.
Anyway: I guess the lesson here is that if you want me to try your product, you should get it used in a challenge on Jet Lag: The Game.
Footnotes
1 I suppose it’s also possible that I was influenced by K-Pop Demon Hunters, which also features a surprising quantity of Korean instant noodles. Turns out there’s all kinds of
noodle-centric pop culture .
2 Does anybody know enough Korean to research the etymology of the word?
3 I checked the ingredients list and, as I expected, there’s no actual chicken in
these chicken noodles, so my resulting lunch was completely vegetarian.
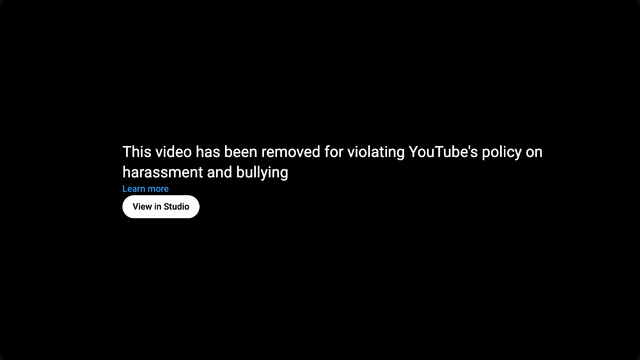
This morning, Google pulled a video from YouTube belonging to my nonprofit Three Rings. This was a bit of a surprise.
Harassment and bullying? Whut?
Apparently the video – which is a demo of some Three Rings features – apparently fell foul of Google’s anti-doxxing rules. I’m glad that they have
anti-doxxing rules, of course.
Let’s see who I doxxed:
Yup… apparently doxxed an imaginary person with two structurally-invalid phone numbers and who’s recently moved house from Some Street to Other Street in the town of Somewhereville. 😂
(Maybe I’m wrong. Do you live on Some Street, Somewhereville?)
Let’s see what YouTube’s appeals process is like, shall we? 🤦
My friend still uses a seriously retro digital music player, rather than his phone, to listen to music. It’s not a Walkman or a Minidisc player, I suppose, but it’s still pretty
elderly. But it’s not one of these.
I’m not here to speak about the legality of retaining offline copies of music from streaming services. YouTube Music seems to permit you to do this using their app, but I’ll bet there’s
something in their terms and conditions that specifically prohibits doing so any other way. Not least because Google’s arrangement with rights holders probably stipulates that they
track how many times tracks are played, and using a different player (like my friend’s portable device) would throw that off.
But what I’m interested in is the feasibility. And in answering that question, in explaining how to work out that it’s feasible.
The web interface to YouTube Music shows playlists of songs and streaming is just a click away.
Spoiler: I came up with an approach, and it looks like it works. My friend can fill up their Zune or whatever the hell
it is with their tunes and bop away. But what I wanted to share with you was the underlying technique I used to develop this approach, because it involves skills that as a web
developer I use most weeks. Hold on tight, you might learn something!
youtube-dl can download “playlists” already, but to download a personal playlist requires that you faff about with authentication and it’s a bit of a drag. Just extracting
the relevant metadata from the page is probably faster, I figured: plus, it’s a valuable lesson in extracting data from web pages in general.
Here’s what I did:
Step 1. Load all the data
I noticed that YouTube Music playlists “lazy load”, and you have to scroll down to see everything. So I scrolled to the bottom of the page until I reached the end of the playlist: now
everything was in the DOM, I could investigate it with my inspector.
Step 2. Find each track’s “row”
Using my browser’s debugger “inspect” tool, I found the highest unique-sounding element that seemed to represent each “row”/track. After a little investigation, it looked like
a playlist always consists of a series of <ytmusic-responsive-list-item-renderer> elements wrapped in a <ytmusic-playlist-shelf-renderer>. I tested
this by running document.querySelectorAll('ytmusic-playlist-shelf-renderer ytmusic-responsive-list-item-renderer') in my debug console and sure enough, it returned a number
of elements equal to the length of the playlist, and hovering over each one in the debugger highlighted a different track in the list.
The web application captured right-clicks, preventing the common right-click-then-inspect-element approach… so I just clicked the “pick an element” button in the debugger.
Step 3. Find the data for each track
I didn’t want to spend much time on this, so I looked for a quick and dirty solution: and there was one right in front of me. Looking at each track, I saw that it contained several
<yt-formatted-string> elements (at different depths). The first corresponded to the title, the second to the artist, the third to the album title, and the fourth to
the duration.
Better yet, the first contained an <a> element whose href was the URL of the piece of music.
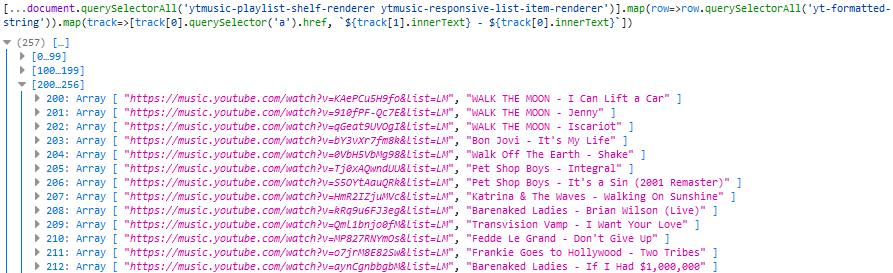
Extracting the URL and the text was as simple as a .querySelector('a').href on the first
<yt-formatted-string> and a .innerText on the others, respectively, so I ran [...document.querySelectorAll('ytmusic-playlist-shelf-renderer
ytmusic-responsive-list-item-renderer')].map(row=>row.querySelectorAll('yt-formatted-string')).map(track=>[track[0].querySelector('a').href, `${track[1].innerText} -
${track[0].innerText}`]) (note the use of [...*] to get an array) to check that I was able to get all the data I needed:
Lots of URLs and the corresponding track names in my friend’s preferred format (me, I like to separate my music into folders
by album, but I suppose I’ve got a music player with more than a floppy disk’s worth of space on it).
Step 4. Sanitise the data
We’re not quite good-to-go, because there’s some noise in the data. Sometimes the application’s renderer injects line feeds into the innerText (e.g. when escaping an
ampersand). And of course some of these song titles aren’t suitable for use as filenames, if they’ve got e.g. question marks in them. Finally, where there are multiple spaces in a row
it’d be good to coalesce them into one. I do some experiments and decide that .replace(/[\r\n]/g, '').replace(/[\\\/:><\*\?]/g, '-').replace(/\s{2,}/g, ' ') does a
good job of cleaning up the song titles so they’re suitable for use as filenames.
I probably should have it fix quotes too, but I’ll leave that as an exercise for the reader.
Step 5. Produce youtube-dl commands
Okay: now we’re ready to combine all of that output into commands suitable for running at a terminal. After a quick dig through the documentation, I decide that we needed the following
switches:
-x to download/extract audio only: it defaults to the highest quality format available, which seems reasomable
-o "the filename.%(ext)s" to specify the output filename but accept the format provided by the quality requirement (transcoding to your preferred format is a
separate job not described here)
--no-playlist to ensure that youtube-dl doesn’t see that we’re coming from a playlist and try to download it all (we have our own requirements of each song’s
filename)
--download-archive downloaded.txt to log what’s been downloaded already so successive runs don’t re-download and the script is “resumable”
The output isn’t pretty, but it’s suitable for copy-pasting into a terminal or command prompt where it ought to download a whole lot of music for offline play.
This isn’t an approach that most people will ever need: part of the value of services like YouTube Music, Spotify and the like is that you pay a fixed fee to stream whatever you like,
wherever you like, obviating the need for a large offline music collection. And people who want to maintain a traditional music collection offline are most-likely to want to do
so while supporting the bands they care about, especially as (with DRM-free digital downloads commonplace) it’s never been
easier to do so.
But for those minority of people who need to play music from their streaming services offline but don’t have or can’t use a device suitable for doing so on-the-go, this kind of approach
works. (Although again: it’s probably not permitted, so be sure to read the rules before you use it in such a way!)
Step 6. Learn something
But more-importantly, the techniques of exploring and writing console Javascript demonstrated are really useful for extracting all kinds of data from web pages (data scraping), writing your own userscripts, and much more. If there’s
one lesson to take from this blog post it’s not that you can steal music on the Internet (I’m pretty sure everybody who’s lived on this side of 1999 knows that by now), but
that you can manipulate the web pages you see. Once you’re viewing it on your computer, a web page works for you: you don’t have to consume a page in the way that the
author expected, and knowing how to extract the underlying information empowers you to choose for yourself a more-streamlined, more-personalised, more-powerful web.
I was watching a recent YouTube video by Derek Muller (Veritasium),
My Video Went Viral. Here’s Why, and I came to a realisation: I don’t watch YouTube like most people
– probably including you! – watch YouTube. And as a result, my perspective on what YouTube is and does is fundamentally biased from the way that others probably think
about it.
The Veritasium video My Video Went Viral. Here’s Why is really good and you should definitely watch at least 7 minutes of it in order to influence the algorithm.
The magic moment came for me when his video explained that the “subscribe” button doesn’t do what I’d assumed it does. I’m probably not alone in my assumptions: I’ll
bet that people who use the “subscribe” button as YouTube intend don’t all realise that it works the way that it does.
Like many, I’d assumed the “subscribe” buttons says “I want to know about everything this creator publishes”. But that’s not what actually happens. YouTube wrangles your subscription
list and (especially) your recommendations based on their own metrics using an opaque algorithm. I knew, of course, that they used such a thing to manage the list of recommended
next-watches… but I didn’t realise how big an influence it was having on the way that most YouTube users choose what they’ll watch!
“YouTube started doing some experiments… where they would change what was recommended to your subscribers. No longer was a subscription like ‘I want to see every video by this
person’; it was more of a suggestion…”
YouTube’s metrics for “what to show to you” is, of course, biased by your subscriptions. But it’s also biased by what’s “trending” (which in turn is based on watch time and
click-through-rate), what people-who-watch-the-things-you-watch watch, subscription commonalities, regional trends, what your contacts are interested in, and… who knows what else! AAA
YouTubers try to “game” it, but the goalposts are moving. And the struggle to stay on-top, especially after a fluke viral hit, leads to the application of increasingly desperate and
clickbaity measures.
This is a battle to which I’ve been mostly oblivious, until now, because I don’t watch YouTube like you watch YouTube.
“You could be a little bit disappointed in the way the game is working right now… I challenge you to think of a better way.”
Hold my beer.
Tom Scott produced an underappreciated sci-fi short last year describing a
theoretical AI which, in 2028, caused problems as a result of its single-minded focus. What we’re seeing in YouTube right
now is a simpler example, but illustrates the problem well: optimising YouTube’s algorithm for any factor or combination of factors other than a user’s stated preference (subscriptions)
will necessarily result in the promotion of videos to a user other than, and at the expense of, the ones by creators that they’ve subscribed to. And there are so many things
that YouTube could use as influencing factors. Off the top of my head, there’s:
Number of views
Number of likes
Ratio of likes to dislikes
Number of tracked shares
Number of saves
Length of view
Click-through rate on advertisements
Recency
Subscriber count
Subscriber engagement
Popularity amongst your friends
Popularity amongst your demographic
Click-through-ratio
Etc., etc., etc.
A Veritasium video I haven’t watched yet? Thanks, RSS reader.
But this is all alien to me. Why? Well: here’s how I use YouTube:
Subscription: I subscribe to creators via RSS. My RSS reader doesn’t implement YouTube’s algorithm, of course, so it just gives me exactly what I subscribe to – no more, no less.It’s not perfect
(for example, it pisses me off every time it tells me about an upcoming “premiere”, a YouTube feature I don’t care about even a little), but apart from that it’s great! If I’m
on-the-move and can’t watch something as long as involved TheraminTrees‘ latest deep-thinker, my RSS reader remembers so I can watch it later at my convenience. I can have National Geographic‘s videos “expire” if I don’t watch them within a week but Dr. Doe‘s wait for me forever. And I can implement my own filters if a feed isn’t showing exactly what I’m looking for (like I did to
strip the sport section from BBC News’ RSS feed). I’m in control.
Discovery: I don’t rely on YouTube’s algorithm to find me new content. I don’t mind being a day or two behind on what’s trending: I’m not sure I care at all? I’m far
more-interested in recommendations curated by a human. If I discover and subscribe to a channel on YouTube, it was usually (a) mentioned by another YouTuber or (b)
linked from a blog or community blog. I’m receiving recommendations from people I already respect, and they have a way higher hit-rate than YouTube’s recommendations.(I also sometimes
discover content because it’s exactly what I searched for, e.g. I’m looking for that tutorial on how to install a fiddly damn kiddy seat into the car, but this is unlikely to result
in a subscription.)
I for one welcome our content-recommending robot overlords. (So long as their biases can be configured by their users, not the networks that create them…)
This isn’t yet-another-argument that you should use RSS because it’s awesome. (Okay, so it is. RSS isn’t dead, and its killer feature is that its users get to choose
how it works. But there’s more I want to say.)
What I wanted to share was this reminder, for me, that the way you use a technology can totally blind you to the way others use it. I had no idea that many YouTube
creators and some YouTube subscribers felt increasingly like they were fighting YouTube’s algorithms, whose goals are different from their own, to get what they want. Now I can see it
everywhere! Why do schmoyoho always encourage me to press the notification bell and not just the subscribe button? Because for a
typical YouTube user, that’s the only way that they can be sure that their latest content will be seen!
“There is one way… to short-circuit this effect… ring that bell.”
If I may channel Yoda for a moment: No… there is another!
Of course, the business needs of YouTube mean that we’re not likely to see any change from them. So until either we have mainstream content-curating AIs that answer to their human owners rather than to commercial networks (robot butler, anybody?) or else the video fediverse catches on – and I don’t know which of those two are least-likely! – I guess I’ll stick to my algorithm-lite
subscription model for YouTube.
But at least now I’ll have a better understanding of why some of the channels I follow are changing the way they produce and market their content…
This epic video (which contains spoilers for Game of Thrones through the third episode of season eight The Long Night). If you’re somehow not up-to-date, you can
always watch the earlier iteration, which only contains spoilers through The Spoils of War, the fourth episode of
the seventh series.
The plan was very simple. We would put a small banner above the video player that would only show up for IE6 users. It would read “We will be phasing out support for your browser
soon. Please upgrade to one of these more modern browsers.” Next to the text would be links to the current versions of the major browsers, including Chrome, Firefox, IE8 and
eventually, Opera. The text was intentionally vague and the timeline left completely undefined. We hoped that it was threatening enough to motivate end users to upgrade without
forcing us to commit to any actual deprecation plan. Users would have the ability to close out this warning if they wanted to ignore it or deal with it later. The code was designed
to be as subtle as possible so that it would not catch the attention of anyone monitoring our checkins. Nobody except the web development team used IE6 with any real regularity, so
we knew it was unlikely anyone would notice our banner appear in the staging environment. We even delayed having the text translated for international users so that a translator
asking for additional context could not inadvertently surface what we were doing. Next, we just needed a way to slip the code into production without anyone catching on.
…
The little-told story of how a rogue team of YouTube engineers in 2009 helped hasten IE6‘s downfall by adding a deprecation warning
to the top of the site’s homepage… without getting the (immediate) attention of the senior developers and management who’d have squashed their efforts.
Those of you who’ve met my family will probably already have an understanding of… what they’re like. Those of you who haven’t are probably about to gain one.
Did you did you… did you know that: Becky can eat mango, all by herself?
It started on a weekend in April, when my mother and I went to a Pink concert. The support act were a really fun band called
Walk the Moon, who finished their energetic set with I Can Lift A Car, with its’ catchy chorus hook “Did you did you… did you know know: I can lift a car up, all by
myself?” Over the weeks that followed, perhaps because of its earworm qualities,
this song became sort-of an inside Rickroll between my mum and I.
For example, this Bel-Air-meme style text message used a shaggy dog story to deliver a play on words.
At one point, she sent me a link to this video (also visible below), in which she is seen to lift
a (toy) car. My sister Becky (also known as “Godzilla”) was behind the camera (and, according to the credits,
everything else), and wrote in the doobly doo: “I think I’m gonna start doing family vlogs.”
She’d experimented with vlogging before, with a short series of make-up tutorials and a “test video post” on her blog, but this represented something new: an effort to show off her family (and guest appearances from her
friends) as they really are; perhaps this was an effort to answer the inevitable question asked by people who’ve visited them – “are they always like that?” Perhaps that’s
why she chose the name she did for the Family Vlog – “IRL”.
The essential Family Vlog (“IRL”) scene is the car scene, with the camera facing backwards from the dashboard. See also my second review…
At the time of writing, Becky (on her YouTube channel) has produced eight such videos
(one, two, three, four, five, six, seven, eight), reliably rolling out one a week for the last two
months. I thought they were pretty good – I thought that was just because they were my family, but I was surprised to find that it’s slowly finding a wider reach, as I end up speaking
to friends who mention to me that they “saw the latest family vlog” (sometimes before I’ve had a chance to see it!).
As I was visiting Preston, I ended up featuring in “IRL – Week 6”. My review (click on the image for it), therefore, seemed to be equal in parts recursive and narcissistic.
Naturally, then, the only logical thing to do was to start producing my own YouTube series, on my channel,
providing reviews of each episode of my sister’s vlog. I’ve managed to get seven out so far (one, two, three, four, five, six, seven), and I’d like to think
that they’re actually better than the originals. They’re certainly more-concise, which counts for a lot, because they trim the original vlog down to just the highlights
(interrupted only occasionally by my wittering atop them).
The widget above (or this playlist) will let
you navigate your way through the entire body of vlogs, and their reviews (or lets you play them all back to back, if you’ve got two and a quarter hours to spare and a pile of brain
cells you want killing). But if you’re just looking for a taster, to see if it’s for you, then here are some starting-out points:
The best episode? My favourite is six, but number two has the most views, probably the keywords “lesbian foursome” are popular search terms. Or possibly “girls peeing”. I’m
not sure which scares me the most.
Of if you just want to drop-in and have a taster, start from the latest review.