Watched the pilot of Webbed Briefs by @heydonworks (of Every Layout fame). It’s a sarcastic independent vlog about web technologies, so I immediately fell in love and subscribed to the feed…
Just kidding. It doesn’t have a feed! (Yet?)

Watched the pilot of Webbed Briefs by @heydonworks (of Every Layout fame). It’s a sarcastic independent vlog about web technologies, so I immediately fell in love and subscribed to the feed…
Just kidding. It doesn’t have a feed! (Yet?)
tl;dr? skip to the proof-of-concept/demo of lazy-loading CSS where possible while still loading it “conventionally” to users without Javascript
In a “daily tip” a couple of days ago, the excellent Chris Ferdinandi recommended an approach to loading CSS asynchronously based on a refined technique by Scott Jehl. The short of it is that you load your stylesheets like this:
<link rel="stylesheet" href="/path/to/my.css" media="print" onload="this.media='all'">You see what that’s doing? It’s loading the stylesheet for the print medium, but then when the document finishes loading it’s switching the media type from “print” to “all”. Because it didn’t apply to begin with the stylesheet isn’t render-blocking. You can use this to delay secondary styles so the page essentials can load at full speed.
I don’t like this approach. I mean: I love the elegance… I just don’t like the implications.
Using Javascript to load CSS, in order to prevent that CSS blocking rendering, feels to me like it conceptually breaks the Web. It certainly violates the expectations of progressive enhancement, because it introduces a level of fault-intolerance that I consider (mostly) unacceptable.
CSS and Javascript are independent of one another. A well-designed progressively-enhanced page should function with HTML only, HTML-and-CSS only, HTML-and-JS only, or all three.CSS adds style, and JS adds behvaiour to a page; and when you insist that the user agent uses Javascript in order to load stylistic elements, you violate the separation of these technologies (I’m looking at you, the majority of heavyweight front-end frameworks!).
If you’re thinking that the only people affected are nerds like me who browse with Javascript wholly or partially disabled, you’re wrong: gov.uk research shows that around 1% of your visitors have Javascript fail for some reason or another: because it’s disabled (whether for preference, privacy, compatibility with accessibility technologies, or whaterver), blocked, firewalled, or they’re using a browser that you didn’t expect.

Chris’s daily tip got me thinking: could there exist a way to load CSS in a non-render-blocking way but which degraded gracefully in the event that Javascript was unavailable? I.e. if Javascript is working, lazy-load CSS, otherwise: load conventionally as a fallback. It turns out, there is!
In principle, it’s this:
<noscript> block, thereby only exposing it where Javascript is disabled. Give it a custom attribute to make it easy to find
later, e.g. <noscript lazyload> (if you’re a standards purist, you might prefer to use a data- attribute).
<noscript> blocks and reinject them. In modern browsers, this is as simple as e.g.
[...document.querySelectorAll('noscript[lazyload]')].forEach(ns=>ns.outerHTML=ns.innerHTML).
If you need support for Internet Explorer, you need a little more work, because Internet Explorer doesn’t expose<noscript> blocks to the DOM in a helpful way. There are a variety of possible workarounds; I’ve implemented one but not put too much thought into it because I rarely have to
think about Internet Explorer these days.
In any case, I’ve implemented a proof of concept/demonstration if you’d like to see it in action: just take a look and view source (or read the page) for details. Or view the source alone via this gist.
Lazy-loading CSS using my approach provides most of the benefits of other approaches… but works properly in environments without Javascript too.
Update: Chris Ferdinandi’s refined this into an even cleaner approach that takes the best of both worlds.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Our sources report that the underlying reason behind the impressive tech demo for Unreal Engine 5 by Epic Games is to ridicule web developers.
According to the Washington Post, the tech demo includes a new dynamic lighting system and a rendering approach with a much higher geometric detail for both shapes and textures. For example, a single statue in the demo can be rendered with 33 million triangles, giving it a truly unprecedented level of detail and visual density.
Turns out that the level of computational optimization and sheer power of this incredible technology is meant to make fun of web developers, who struggle to maintain 15fps while scrolling a single-page application on a $2000 MacBook Pro, while enjoying 800ms delays typing the corresponding code into their Electron-based text editors.
…
Funny but sadly true. However, the Web can be fast. What makes it slow is bloated, kitchen-sink-and-all frontend frameworks, pushing computational effort to the browser with overcomplicated DOM trees and unnecessarily rich CSS rules, developer privilege, and blindness to the lower-powered devices that make up most of the browsing world. Oh, and of course embedding a million third-party scripts to get you all the analytics, advertising, etc. you think you need doesn’t help, either.
The Web will never be as fast as native, for obvious reasons. But it can be fast; blazingly so. It just requires a little thought and consideration. I’ve talked about this recently.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
As we’ve mentioned in previous blog posts, the $FAMOUS_COMPANY backend has historically been developed in $UNREMARKABLE_LANGUAGE and architected on top of $PRACTICAL_OPEN_SOURCE_FRAMEWORK. To suit our unique needs, we designed and open-sourced $AN_ENGINEER_TOOK_A_MYTHOLOGY_CLASS, a highly-available, just-in-time compiler for $UNREMARKABLE_LANGUAGE.
…
Saagar Jha tells the now-familiar story of how a bunch of techbros solved their scaling problems by reinventing the wheel. And then, when that didn’t work out, moved the goalposts of success. It’s a story as old as time; or at least as old as the modern Web.
(Should’a strangled the code. Or better yet, just refactored what they had.)
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
The performance tradeoff isn’t about where the bottleneck is. It’s about who has to carry the burden. It’s one thing for a developer to push the burden onto a server they control. It’s another thing entirely to expect visitors to carry that load when connectivity and device performance isn’t a constant.
…
This is another great take on the kind of thing I was talking about the other day: some developers who favour heavy frameworks (e.g. React) argue for the performance benefits, both in development velocity and TTFB. But TTFB alone is not a valid metric of a user’s perception of an application’s performance: if you’re sending a fast payload that then requires extensive execution and/or additional calls to the server-side, it stands to reason that you’re not solving a performance bottleneck, you’re just moving it.
I, for one, generally disfavour solutions that move a Web application’s bottleneck to the user’s device (unless there are other compelling reasons that it should be there, for example as part of an Offline First implementation, and even then it should be done with care). Moving the burden of the bottleneck to the user’s device disadvantages those on slower or older devices and limits your ability to scale performance improvements through carefully-engineered precaching e.g. static compilation. It also produces a tendency towards a thick-client solution, which is sometimes exactly what you need but more-often just means a larger initial payload and more power consumption on the (probably mobile) user’s device.
Next time you improve performance, ask yourself where the time saved has gone. Some performance gains are genuine; others are just moving the problem around.
Normally this kind of thing would go into the ballooning dump of “things I’ve enjoyed on the Internet” that is my reposts archive. But sometimes something is so perfect that you have to try to help it see the widest audience it can, right? And today, that thing is: Mackerelmedia Fish.

What is Mackerelmedia Fish? I’ve had a thorough and pretty complete experience of it, now, and I’m still not sure. It’s one or more (or none) of these, for sure, maybe:
Rock Paper Shotgun’s article about it opens with “I don’t know where to begin with this—literally, figuratively, existentially?” That sounds about right.

What I can tell you with confident is what playing feels like. And what it feels like is the moment when you’ve gotten bored waiting for page 20 of Argon Zark to finish appear so you decide to reread your already-downloaded copy of the 1997 a.r.k bestof book, and for a moment you think to yourself: “Whoah; this must be what living in the future feels like!”
Because back then you didn’t yet have any concept that “living in the future” will involve scavenging for toilet paper while complaining that you can’t stream your favourite shows in 4K on your pocket-sized supercomputer until the weekend.
Mackerelmedia Fish is a mess of half-baked puns, retro graphics, outdated browsing paradigms and broken links. And that’s just part of what makes it great.
It’s also “a short story that’s about the loss of digital history”, its creator Nathalie Lawhead says. If that was her goal, I think she managed it admirably.
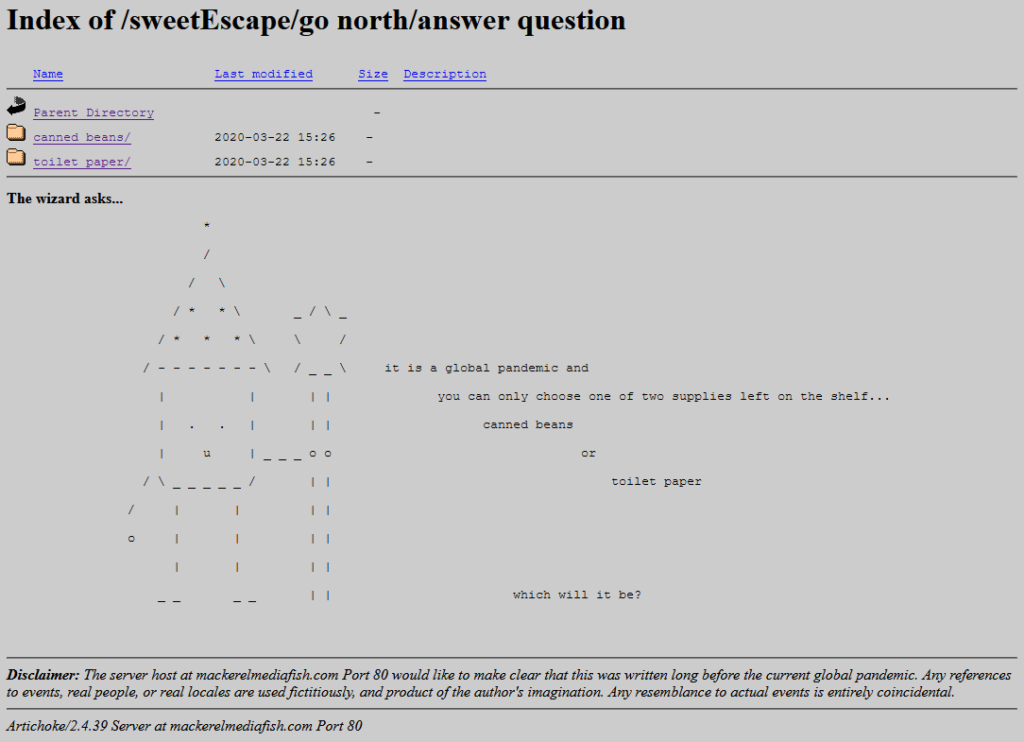
If I wasn’t already in love with the game already I would have been when I got to the bit where you navigate through the directory indexes of a series of deepening folders, choose-your-own-adventure style. Nathalie writes, of it:
One thing that I think is also unique about it is using an open directory as a choose your own adventure. The directories are branching. You explore them, and there’s text at the bottom (an htaccess header) that describes the folder you’re in, treating each directory as a landscape. You interact with the files that are in each of these folders, and uncover the story that way.
Back in the naughties I experimented with making choose-your-own-adventure games in exactly this way. I was experimenting with different media by which this kind of branching-choice game could be presented. I envisaged a project in which I’d showcase the same (or a set of related) stories through different approaches. One was “print” (or at least “printable”): came up with a Twee1-to-PDF converter to make “printable” gamebooks. A second was Web hypertext. A third – and this is the one which was most-similar to what Nathalie has now so expertly made real – was FTP! My thinking was that this would be an adventure game that could be played in a browser or even from the command line on any (then-contemporary: FTP clients aren’t so commonplace nowadays) computer. And then, like so many of my projects, the half-made version got put aside “for later” and forgotten about. My solution involved abusing the FTP protocol terribly, but it worked.
(I also looked into ways to make Gopher-powered hypertext fiction and toyed with the idea of using YouTube annotations to make an interactive story web [subsequently done amazingly by Wheezy Waiter, though the death of YouTube annotations in 2017 killed it]. And I’ve still got a prototype I’d like to get back to, someday, of a text-based adventure played entirely through your web browser’s debug console…! But time is not my friend… Maybe I ought to collaborate with somebody else to keep me on-course.)

In any case: Mackerelmedia Fish is fun, weird, nostalgic, inspiring, and surreal, and you should give it a go. You’ll need to be on a Windows or OS X computer to get everything you can out of it, but there’s nothing to stop you starting out on your mobile, I imagine.
Sso long as you’re capable of at least 800 × 600 at 256 colours and have 4MB of RAM, if you know what I mean.
Ironically, the web page promoting the “Digital Climate Strike” is among the dirtiest on the Internet, based on the CO2 footprint of visiting it.
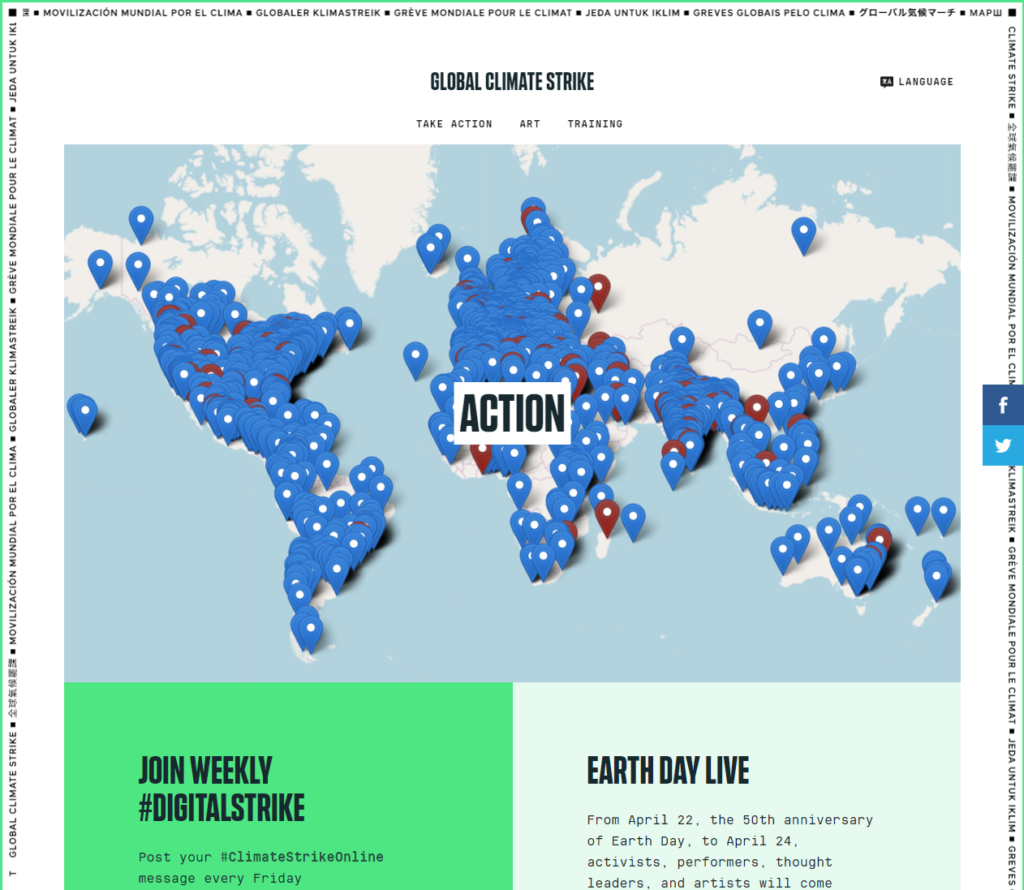
Going to that page results in about 14 Mb of data being transmitted from their server to your device (which you’ll pay for if you’re on a metered connection). For comparison, reading my recent post about pronouns results in about 356 Kb of data. In other words, their page is forty times more bandwidth-consuming, despite the fact that my page has about four times the word count. The page you’re reading right now, thanks to its images, weighs in at about 650 Kb: you could still download it more than twenty times while you were waiting for theirs.

Worse still, the most-heavyweight of the content they deliver is stuff that’s arguably strictly optional and doesn’t add to the message:
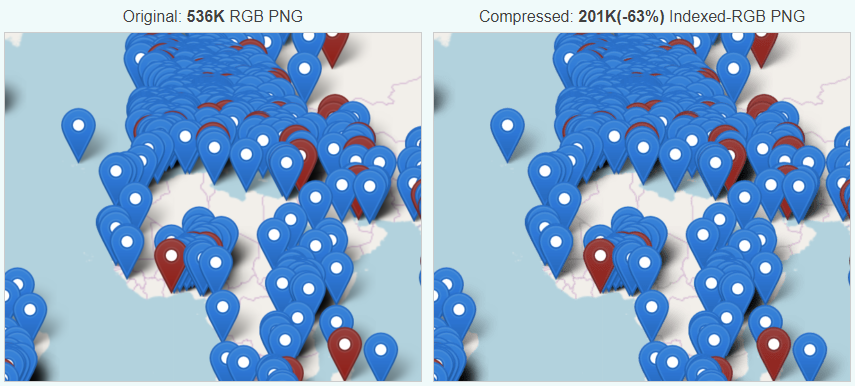
And because the site sets virtually no caching headers, even if you’ve visited the website before you’re likely to have to download the whole thing again. Every single time.
It’s not just about bandwidth: all of those fonts, that JavaScript, their 60 Kb of CSS (this page sent you 13 Kb) all has to be parsed and interpreted by your device. If you’re on a mobile device or a laptop, that means you’re burning through lithium (a non-renewable resource whose extraction and disposal is highly polluting) and
regardless of your device you’re using you’re using more electricity to visit their site than you need to. Coding antipatterns like document.write() and active event
listeners that execute every time you scroll the page keep your processor working hard, turning electricity into waste heat. It took me over 12 seconds on a high-end smartphone and a
good 4G connection to load this page to the point of usability. That’s 12 seconds of a bright screen, a processor running full tilt,a data connection working its hardest, and a
battery ticking away. And I assume I’m not the only person visiting the website today.
This isn’t really about this particular website, of course (and I certainly don’t want to discourage anybody from the important cause of saving the planet!). It’s about the bigger picture: there’s a widespread and long-standing trend in web development towards bigger, heavier, more power-hungry websites, built on top of heavyweight frameworks that push the hard work onto the user’s device and which favour developer happiness over user experience. This is pretty terrible: it makes the Web slow, and brittle, and it increases the digital divide as people on slower connections and older devices get left behind.
(Bonus reading: luckily there’s a counterculture of lean web developers…)
But this trend is also bad for the environment, and when your website exists to try to save it, that’s more than a little bit sad.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Back in 2011, some folks cross-compiled Doom (the original, not the reboot, obviously) to JavaScript, leveraging the capabilities of the then-relatively-young
<canvas> element and APIs. I was really impressed to see that JavaScript had come so far and that
performance on desktop devices was so slick. Sure, this was an 18-year-old video game, but it was playable in a browser, which was a long way from the environment for which it
was originally developed.
Now Doom 3‘s playable in a browser, and my mind’s blown all over again. This follows almost the same curve – Doom 3’s 16 years old – but it still goes to show that there’s little limit to the power of client-side browser programming. They’ve done this magic with WebAssembly; while WebAssembly goes slightly against my ideas about the open-source nature of the Web, I still respect the power it commands to do heavyweight crunching tasks like this one.
How long until AAA developers start developing with the Web as an additional platform?
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Don’t understand why Web accessibility is important? Need a quick and easily-digestible guide to the top things you should be looking into in order to make your web applications screenreader ready? Try this fun, video-game-themed 5 minute video from Microsoft.
There’s a lot more to accessibility than is covered here, and it’s perhaps a little over-focussed on screenreaders, but it’s still a pretty awesome introduction.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
A new email-based extortion scheme apparently is making the rounds, targeting Web site owners serving banner ads through Google’s AdSense program. In this scam, the fraudsters demand bitcoin in exchange for a promise not to flood the publisher’s ads with so much bot and junk traffic that Google’s automated anti-fraud systems suspend the user’s AdSense account for suspicious traffic.
…
The shape of our digital world grows increasingly strange. As anti-DoS techniques grow better and more and more uptime-critical websites hide behind edge caches, zombie network operators remain one step ahead and find new and imaginative ways to extort money from their victims. In this new attack, the criminal demands payment (in cryptocurrency) under threat that, if it’s not delivered, they’ll unleash an army of bots to act like the victim trying to scam their advertising network, thereby getting the victim’s site demonetised.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
I first got into web design/development in the late 90s, and only as I type this sentence do I realize how long ago that was.
And boy, it was horrendous. I mean, being able to make stuff and put it online where other people could see it was pretty slick, but we did not have very much to work with.
I’ve been taking for granted that most folks doing web stuff still remember those days, or at least the decade that followed, but I think that assumption might be a wee bit out of date. Some time ago I encountered a tweet marvelling at what we had to do without
border-radius. I still remember waiting with bated breath for it to be unprefixed!But then, I suspect I also know a number of folks who only tried web design in the old days, and assume nothing about it has changed since.
I’m here to tell all of you to get off my lawn. Here’s a history of CSS and web design, as I remember it.
(Please bear in mind that this post is a fine blend of memory and research, so I can’t guarantee any of it is actually correct, especially the bits about causality. You may want to try the W3C’s history of CSS, which is considerably shorter, has a better chance of matching reality, and contains significantly less swearing.)
(Also, this would benefit greatly from more diagrams, but it took long enough just to write.)
…
I too remember the bad-old days of the pre-CSS and early-CSS Web. Back then, when we were developing for it, we thought that it was magical. We tolerated issues like having to copy-paste our navigation around a stack of static pages, manually change our design all over the place etc…. but man… I wouldn’t want to go back to working that way!
This is an excellent long-read for an up-close-and-personal look at how CSS has changed over the decades. Well worth a look if you’ve any interest in the topic.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
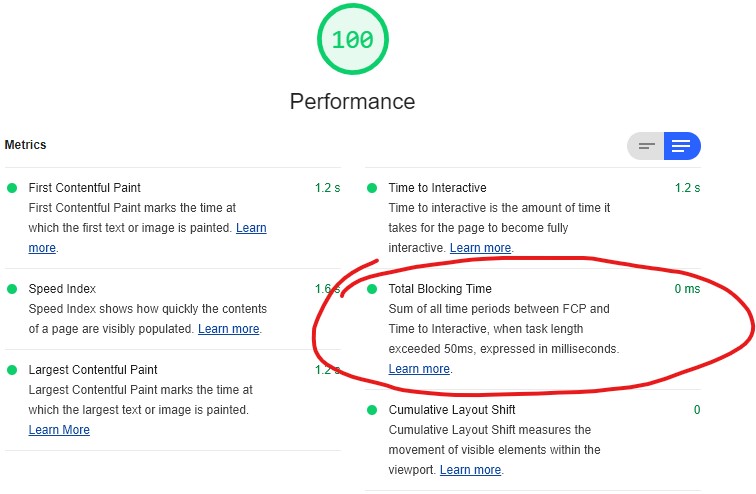
Google’s built-in testing tool Lighthouse judges the accessibility of our websites with a score between 0 and 100. It’s laudable to try to get a high grading, but a score of 100 doesn’t mean that the site is perfectly accessible. To prove that I carried out a little experiment.
…
Manuel Matuzovic wrote a web page that’s pretty-much inaccessible to everybody: it doesn’t work with keyboard navigation, touchscreens, or mice. It doesn’t work with screen readers. Even if you fix the other problems, its contrast is bad enough that almost nobody could read it. It fails ungracefully if CSS or JavaScript is unavailable. Even the source code is illegible. This took a special kind of evil.
But it scores 100% for accessibility on Lighthouse! I earned my firework show for this site last year but I know better than to let that lull me into complacency: accessibility isn’t something a machine can test for you, only something that (at best) it can give you guidance on.
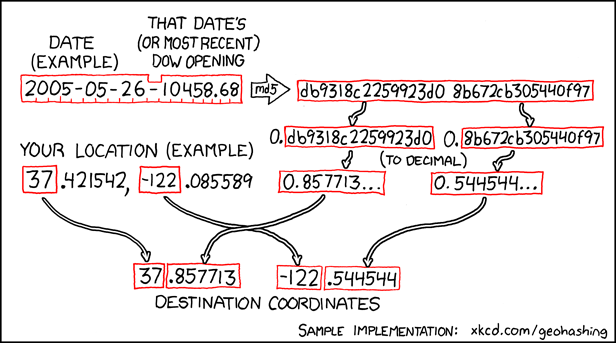
I keep my life pretty busy and don’t get as much “outside” as I’d like, but when I do I like to get out on an occasional geohashing expedition (like these ones). I (somewhat badly) explained geohashing in the vlog attached to my expedition 2018-08-07 51 -1, but the short version is this: an xkcd comic proposed an formula to use a stock market index to generate a pair of random coordinates, impossible to predict in advance, for each date. Those coordinates are (broadly) repeated for each degree of latitude and longitude throughout the planet, and your challenge is to get to them and discover what’s there. So it’s like geocaching, except you don’t get to find anything at the end and there’s no guarantee that the destination is even remotely accessible. I love it.
Most geohashers used to use a MediaWiki-powered website to coordinate their efforts and share their stories, until a different application on the server where it resided got hacked and the wiki got taken down as a precaution. That was last September, and the community became somewhat “lost” this winter as a result. It didn’t stop us ‘hashing, of course: the algorithm’s open-source and so are many of its implementations, so I was able to sink into a disgusting hole in November, for example. But we’d lost the digital “village square” of our community.
So I emailed Davean, who does techy things for xkcd, and said that I’d like to take over the Geohashing wiki but that I’d first like (a) his or Randall’s blessing to do so, and ideally (b) a backup of the pages of the site as it last-stood. Apparently I thought that my new job plus finishing my dissertation plus trying to move house plus all of the usual things I fill my time with wasn’t enough and I needed a mini side-project, because when I finally got the go-ahead at the end of last month I (re)launched geohashing.site. Take a look, if you like. If you’ve never been Geohashing before, there’s never been a more-obscure time to start!
Luckily, it’s not been a significant time-sink for me: members of the geohashing community quickly stepped up to help me modernise content, fix bots, update hyperlinks and the like. I took the opportunity to fix a few things that had always bugged me about the old site, like the mobile-unfriendly interface and the inability to upload GPX files, and laid the groundwork to make bigger changes down the road (like changing the way that inline maps are displayed, a popular community request).
So yeah: Geohashing’s back, not that it ever went away, and I got to be part of the mission to make it so. I feel like I am, as geohashers say… out standing in my field.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
2020 is only three weeks old, but there has been a lot of browser news that decreases rendering engine diversity. It’s time for some good news on that front: a new rendering engine, Flow. Below I conduct an interview with Piers Wombwell, Flow’s lead developer.
This year alone, on the negative side Mozilla announced it’s laying off 70 people, most of whom appear to come from the browser side of things, while it turns out that Opera’s main cash cow is now providing loans in Kenya, India, and Nigeria, and it is looking to use ‘improved credit scoring’ (from browsing data?) for its business practices.
On the positive side, the Chromium-based Edge is here, and it looks good. Still, rendering engine diversity took a hit, as we knew it would ever since the announcement.
So let’s up the diversity a notch by welcoming a new rendering engine to the desktop space. British company Ekioh is working on a the Flow browser, which sports a completely new multi-threaded rendering engine that does not have any relation to WebKit, Gecko, or Blink.
…
Well, I didn’t expect this bit of exciting news!
I’m not convinced that Flow is the solution to all the world’s problems (its target platforms and use-cases alone make it unlikely to make it onto the most-used-browsers leaderboard any time soon), but I’m really glad that my doomsaying about the death of browser diversity being a one-way street might… might… turn out not to be true.
Time will tell. But for now, this is Good News for the Web.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
I think that CSS would be greatly helped if we solemnly state that “CSS4 is here!” In this post I’ll try to convince you of my viewpoint.
I am proposing that we web developers, supported by the W3C CSS WG, start saying “CSS4 is here!” and excitedly chatter about how it will hit the market any moment now and transform the practice of CSS.
Of course “CSS4” has no technical meaning whatsoever. All current CSS specifications have their own specific versions ranging from 1 to 4, but CSS as a whole does not have a version, and it doesn’t need one, either.
Regardless of what we say or do, CSS 4 will not hit the market and will not transform anything. It also does not describe any technical reality.
Then why do it? For the marketing effect.
…
Hurrah! CSS4 is here!
I’m sure that, like me, you’re excited to start using the latest CSS technologies, like paged media, hyphen control, the zero-specificity :where() selector, and new accessibility selectors like the ‘prefers-reduced-motion’ @media query. The browser support might not be “there” yet, but so long as you’ve got a suitable commitment to progressive enhancement then you can be using all of these and many more today (I am!). Fantastic!
But if you’ve got more than a little web savvy you might still be surprised to hear me say that CSS4 is here, or even that it’s a “thing” at all. Welll… that’s because it isn’t. Not officially. Just like JavaScript’s versioning has gone all evergreen these last few years, CSS has gone the same way, with different “modules” each making their way through the standards and implementation processes independently. Which is great, in general, by the way – we’re seeing faster development of long-overdue features now than we have through most of the Web’s history – but it does make it hard to keep track of what’s “current” unless you follow along watching very closely. Who’s got time for that?
When CSS2 gained prominence at around the turn of the millennium it was revolutionary, and part of the reason for that – aside from the fact that it gave us all some features we’d wanted for a long time – was that it gave us a term to rally behind. This browser already supports it, that browser’s getting there, this other browser supports it but has a f**ked-up box model (you all know the one I’m talking about)… we at last had an overarching term to discuss what was supported, what was new, what was ready for people to write articles and books about. Nobody’s going to buy a book that promises to teach them “CSS3 Selectors Level 3, Fonts Level 3, Writing Modes Level 3, and Containment Level 1”: that title’s not even going to fit on the cover. But if we wrapped up a snapshot of what’s current and called it CSS4… now that’s going to sell.
Can we show the CSS WG that there’s mileage in this idea and make it happen? Oh, I hope so. Because while the modular approach to CSS is beautiful and elegant and progressive… I’m afraid that we can’t use it to inspire junior developers.
Also: I don’t want this joke to forever remain among the top results when searching for CSS4…