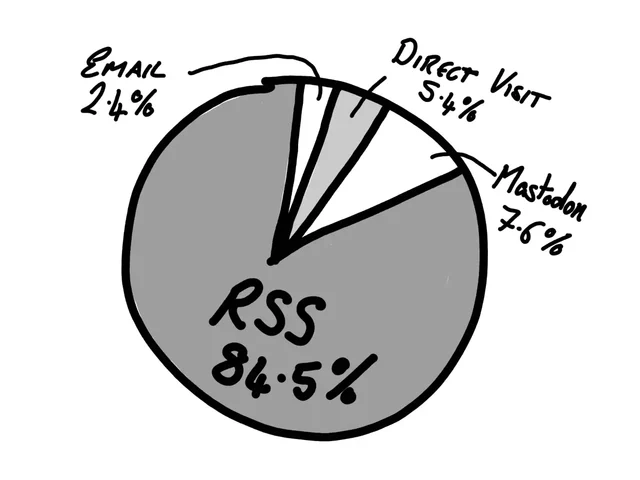
Well, quite a lot, actually. It tells me that there’s loads of you fine people reading the content on this site, which is very heart-warming. It also tells me that RSS is
by far the main way people consume my content. Which is also fantastic, as I think RSS is very
important and should always be a first class citizen when it comes to delivering content to people.
…
I didn’t get a chance to participate in Kev’s survey because, well, I don’t target
“RSS Zero” and I don’t always catch up on new articles – even by authors I follow closely – until up to a few weeks after they’re published1.
But needless to say, I’d have been in the majority: I follow Kev via my feed reader2.
But I was really interested by this approach to understanding your readership: like Kev, I don’t run any kind of analytics on my personal sites. But he’s onto something! If you
want to learn about people, why not just ask them?
Okay, there’s going to be a bias: maybe readers who subscribe by RSS are simply more-likely to respond to a survey? Or are more-likely to visit new articles quickly, which
was definitely a factor in this short-lived survey? It’s hard to be certain whether these or other factors might have thrown-off Kev’s results.
But then… what isn’t biased? Were Kev running, say, Google Analytics (or Fathom, or Strike, or Hector, or whatever)… then I wouldn’t show up in his results
because I block those trackers3
– another, different, kind of bias.
We can’t dodge such bias: not using popular analytics platforms, and not by surveying users. But one of these two options is, at least, respectful of your users’ privacy and bandwidth.
I’m tempted to run a similar survey myself. I might wait until after my long-overdue redesign – teased here – launches,
though. Although perhaps that’s just a procrastination stemming from my insecurity that I’ll hear, like, an embarrassingly-low number of responses like three or four and internalise it
as failing some kind of popularity contest4! Needs more thought.
Footnotes
1 I’m happy with this approach: I enjoy being able to treat my RSS reader as sort-of a
“magazine”, using my categorisations of feeds – which are partially expressed on my Blogroll page – as a theme. Like: “I’m going to spend 20 minutes
reading… tech blogs… or personal blogs by people I know personally… or indieweb-centric content… or news (without the sports, of course)…”
This approach makes consuming content online feel especially deliberate and intentional: very much like being in control of what I read and when.
3 In fact, I block all third-party JavaScript (and some first-party
JavaScript!) except where explicitly permitted, but even for sites that I do allow to load all such JavaScript I still have to manually enable analytics
trackers if I want them, which I don’t. Also… I sandbox almost all cookies, and I treat virtually all persistent cookies as session cookies and I
delete virtually all session cookies 15 seconds after I navigate away from a its sandbox domain or close its tab… so I’m moderately well-anonymised even where I do somehow
receive a tracking cookie.
4 Perhaps something to consider after things have gotten easier and I’ve caught up with my backlog a bit.
The recent death of Tom Lehrer has resulted in all manner of interesting facts and anecdotes about the man being published
around the Internet, but perhaps my favourite was the tale about how, while working for the NSA in 1957, he snuck an Easter Egg into a research paper… that went undetected for nearly 60
years:
…
I worked as a mathematician at the NSA during the second Obama administration and the first half of the first Trump administration. I had long enjoyed Tom Lehrer’s music, and I knew
he had worked for the NSA during the Korean War era.
The NSA’s research directorate has an electronic library, so I eventually figured, what the heck, let’s see if we can find anything he published internally!And I found a few articles
I can’t comment on. But there was one unclassified article– “Gambler’s Ruin With Soft-Hearted Adversary”.
The paper was co-written by Lehrer and R. E. Fagen, published in January, 1957. The mathematical content is pretty interesting, but that’s not what stuck out to me when I read it.
See, the paper cites FIVE sources throughout its body. But the bibliography lists SIX sources. What’s the leftover?
…
So I sent an email to the NSA historians. And I asked them: hey, when was this first noticed, and how much of a gas did people think it was? Did he get in trouble for it? That sort
of stuff.
The answer came back: “We’ve never heard of this before. It’s news to us.”
In November of 2016, nearly 60 years after the paper was published internally, I had discovered the joke.
…
Bozhe moi!
Very Tom Lehrer to hide a joke so well that nobody would even notice it for most of six decades, while undermining and subverting bureaucratic government processes.
When geocachers find a geocache, they typically “log” their find both in the cache’s paper logbook and on one of the online listing sites on which the cache’s coordinates can be
found.1
A typical geocacher can find their cache container, logbook, swag, toothbrush, face flannel, soap, tin of biscuits, flask, compass, and most-importantly towel. Hang on, I’ve got my
geekeries crossed again. Photo courtesy cachemania, used under a CC BY-SA license.
I’ve been finding and hiding geocaches for… a long while, so I’ve
seen lots of log entries from people who’ve found my caches (and those of others). And it feels to me like the average length of a
geocaching log entry is getting shorter.
A single emoji is probably the shortest log entry I’ve ever seen. I’m
not claiming that its
cachedeserves a longer log (it’s far from my best work!): just using it as an example of a wider trend towards shorter logs.
“It feels to me like…” isn’t very scientific, though. Let’s see if we can do better.
Getting the data
To test my hypothesis, I needed a decade or so of logs. I didn’t want to compare old caches to new caches (in case people are biased by the logs before them) so I used Geocaching.com’s
own search to open the pages for the 500 caches closest to me that are each at least 10 years old.
My browser hates me right now.
I hacked together a quick
userscript to save all of the logs in a way that was easier than copy-pasting each of them but still didn’t involve hitting Geocaching.com’s API or automating bulk-scraping (which would violate their terms of service). Clicking each of several hundred tabs once every few minutes in
the background while I got on with other things wasn’t as much of an ordeal as you might think… but it did take a while.
Needless to say I only had to go through the cycle a couple of times before I set up a keyboard shortcut.
I mashed that together into a CSV file and for the first time looked at the size of my sample data: ~134,000 log entries,
spanning 20 years. I filtered out everything over 10 years old (because some of the caches might have no logs that old) and stripped out everything that wasn’t a “found it” or “didn’t
find it” log.
That gave me a far more-reasonable ~80,000 records with which I could make Excel cry.2
Results
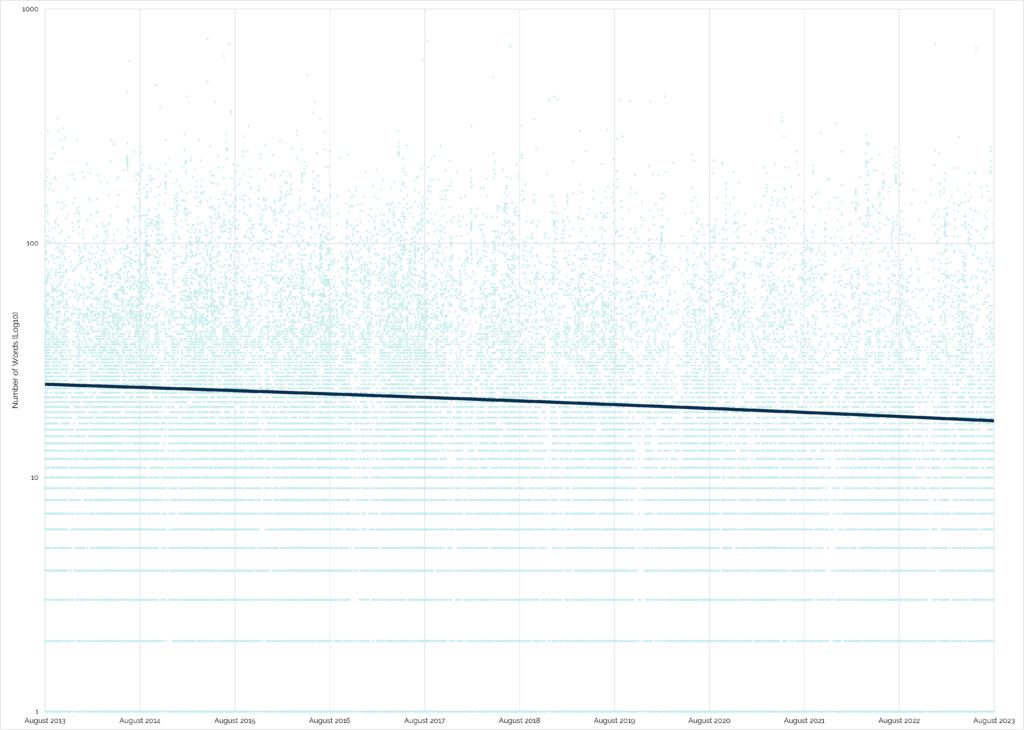
It looks like my hunch is right. The wordcount of “found” logs on traditional and multi-stage caches has generally decreased over time:
“Found” logs are great for cache owner morale: a simple “TFTC” is a lot less-inspiring that hearing about your adventure to get
to that point.
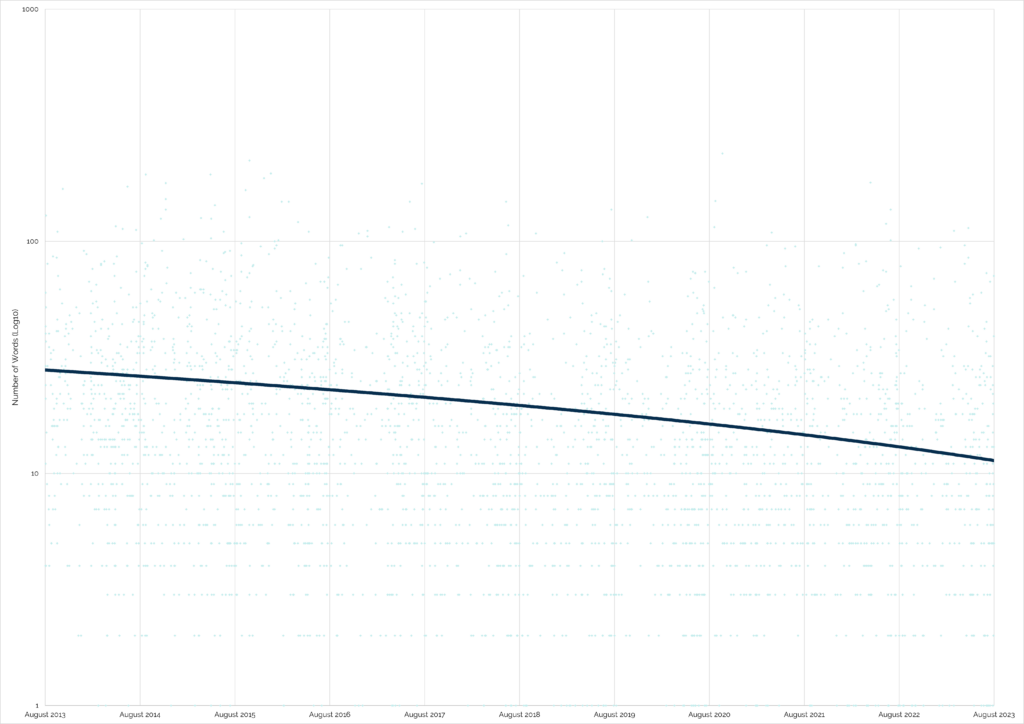
“Did not find” logs, which can be really helpful for cache owners to diagnose problems with their caches, have an even more-pronounced dip:
Geocachers are just typing “Didn’t find it” and moving on. Without an indication of the conditions at the GZ, how long they spent
looking, or an indication of whether the hint was followed, that doesn’t give a cache owner much to work with.
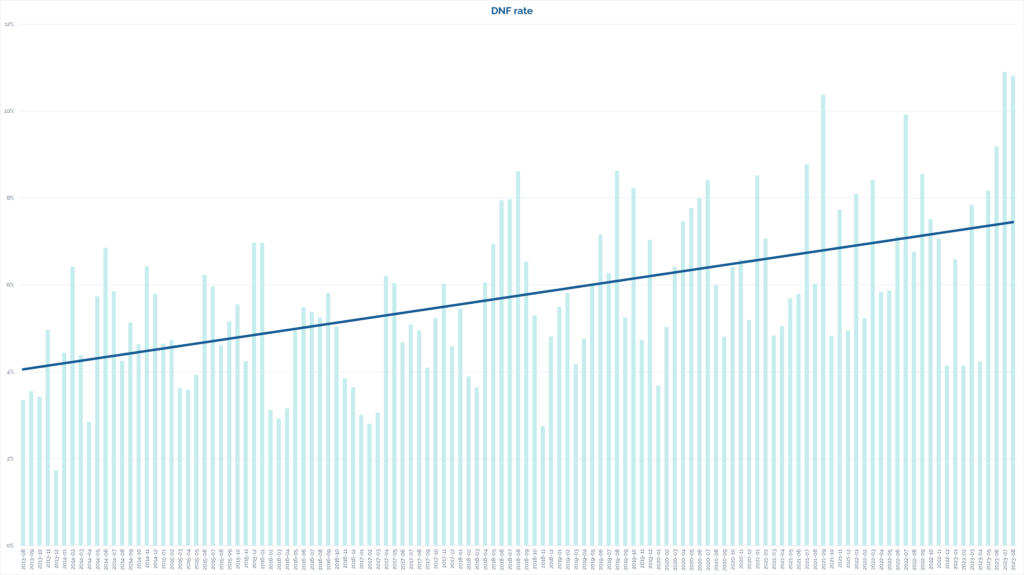
When I first saw that deep dip on the average length of “did not find” logs, my first thought was to wonder whether the sample might not be representative because the did-not-find rate
itself might have fallen over time. But no: the opposite is true:
A higher proportion than ever of geocachers are logging that they couldn’t find the cache, but they’re simultaneously saying less than ever about it.
Strangely, the only place that the trend is reversed is in “found” logs of virtual caches, which have seen a slight increase in verbosity.
I initially assumed that this resulted from “virtual
rewards” from 2017 onwards3
but this doesn’t make any sense because all of the caches in my study are 10+ years old: none of them can be “virtual rewards”.
Conclusion
Within the limitations of my research (80,000 logs from 500 caches each 10+ years old, near me), there are a handful of clear trends over the last decade:
Geocachers are leaving increasingly concise logs when they find geocaches.
That phenomenon is even more-pronounced when they don’t find them.
And they’re failing-to-find caches and giving up with significantly greater frequency.
Are these trends a sign of shortening attention spans? Increased use of mobile phones for logging? Use of emoji and acronyms to pack more detail into shorter messages? I don’t know.
I’d love to see some wider research, perhaps by somebody at Geocaching.com HQ (who has database access and is thus able to easily extract
enough data for a wider analysis!). I’m also very interested in whether the identity of the cache finder has an impact on log length: is it impacted by how long ago they
started ‘caching? Whether or not they have hidden caches of their own? How many caches they’ve found?
But personally, I’m just pleased to have been able to have a question in the back of my mind and – through a little bit of code and a little bit of data-mashing – have a pretty good go
at answering it.
Footnotes
1 I have a dream that someday cache logging could be powered by Webmentions or ActivityPub or some similar decentralised-Web technology, so that cachers can log their finds on any site on which a cache is listed or
even on their own site and have all the dots joined-up… but that’s pretty far-fetched I’m afraid. It’s not stopping some of us from experimenting with possible future standards,
though…
2 Just for fun, try asking Excel to extrapolate a second-order polynomial trendline across
80,000 pairs of datapoints. Just don’t do it if you’re hoping to use your computer for anything in the next quarter hour.
3 With stricter guidelines on how a “virtual rewards” virtual caches should work than
existed for original pre-2005 virtuals, these new virtuals are more-likely than their predecessor to encourage or require longer logs.
That moment when you realise, to your immense surprise, that the research you’ve spent most of the year on might actually demonstrate the thing you set out to test after all. 😲
Screw you, null hypothesis.
Parachute use did not reduce death or major traumatic injury when jumping from aircraft in the first randomized evaluation of this intervention.
However, the trial was only able to enroll participants on small stationary aircraft on the ground, suggesting cautious extrapolation to high altitude jumps.
…
As always, when the BMJ publish a less-serious paper, it’s knock-your-socks-off funny. In this one, a randomised trial to determine whether or not parachutes are effective (compared to
a placebo in the form of an empty backpack) at preventing death resulting from falling from an aircraft, when used by untrained participants, didn’t get many volunteer participants
(funny, that!) until the experiment was adapted to involve only a leap from a stationary, grounded aircraft with an average jump height of 0.6 metres.
That no one would ever jump out of an aeroplane without a parachute has often been used to argue that randomising people to either a potentially life saving medical intervention or a
control would be inappropriate, and that the efficacy of such an intervention should be discerned from clinical judgment alone. We disagree, for the most part. We believe that
randomisation is critical to evaluating the benefits and harms of the vast majority of modern therapies, most of which are unlikely to be nearly as effective at achieving their end
goal as parachutes are at preventing injury among people jumping from aircraft.
However, RCTs are vulnerable to pre-existing beliefs about standard of care, whether or not these beliefs are justified. Our attempts to recruit in-flight passengers to our ambitious
trial were first met with quizzical looks and incredulity, predictably followed by a firm, “No, I would not jump without a parachute.” For the majority of the screened
population of the PARACHUTE trial, there was no equipoise—parachutes are the prevailing standard of care. And we concur.
But what if we provided assurances that the planes were stationary and on the ground, and that the jump would be just a couple of feet? It was at this point that our study took off.
We set out in two groups, one at Katama Airfield on Martha’s Vineyard and the other at the Yankee Air Museum in Ann Arbor. One by one, our study subjects jumped from either a small
biplane or a helicopter, randomised to either a backpack equipped with a parachute or a look-a-like control. As promised, both aircraft were parked safely on terra firma. The matchup
was, unsurprisingly, a draw, with no injuries in either group. In the first ever RCT of parachutes, the topline conclusion was clear: parachutes did not reduce death or major
traumatic injury among people jumping from aircraft.
But topline results from RCTs often fail to reveal the full story. We conducted the PARACHUTE trial to illustrate the
perils of interpreting trials outside of context. When strong beliefs about the standard of care exist in the community, often only low risk patients are enrolled in a trial, which
can unsalvageably bias the results, akin to jumping from an aircraft without a parachute. Assuming that the findings of such a trial are generalisable to the broader population may
produce disastrous consequences.
Using humour to kickstart serious conversations and to provide an alternative way of looking at important research issues is admirable in itself.
Fantastic lightweight introduction to bacteriophages and how they can potentially be our next best weapon against infection as
we approach the post-antibiotic age. Plus an interesting look at the history and the discovery of bacteriophages!
I’ve generally been pretty defensive of Microsoft Edge, the default web browser in Windows 10. Unlike its much-mocked
predecessor Internet Explorer, Edge is fast, clean, modern, and boasts good standards-compliance: all of the things that
Internet Explorer infamously failed at! I was genuinely surprised to see Edge fail to gain a significant market share in its first few years: it seemed to me
that everyday Windows users installed other browsers (mostly Chrome, which is causing its own problems) specifically because Internet Explorer was
so terrible, and that once their default browser was replaced with something moderately-good this would no longer be the case. But that’s not what’s happened. Maybe it’s because Edge’s
branding is too-remiscient of its terrible
predecessor or maybe just because Windows users have grown culturally-used to the idea that the first thing they should do on a new PC is download a different browser, but
whatever the reason, Edge is neglected. And for the most part, I’ve argued, that’s a shame.
I ranted at an Edge developer I met at a conference, once, about Edge’s weak TLS debugging tools that couldn’t identify an OCSP stapling issue that only affected Edge, but I thought
that was the worse of its bugs… until now…
But I’ve changed my tune this week after doing some research that demonstrates that a long-standing security issue of Internet Explorer is alive and well in Edge. This particular issue,
billed as a “feature” by Microsoft, is deliberately absent from virtually every other web browser.
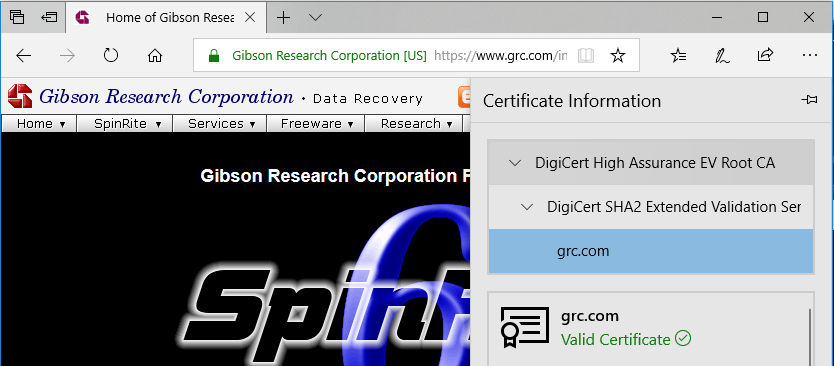
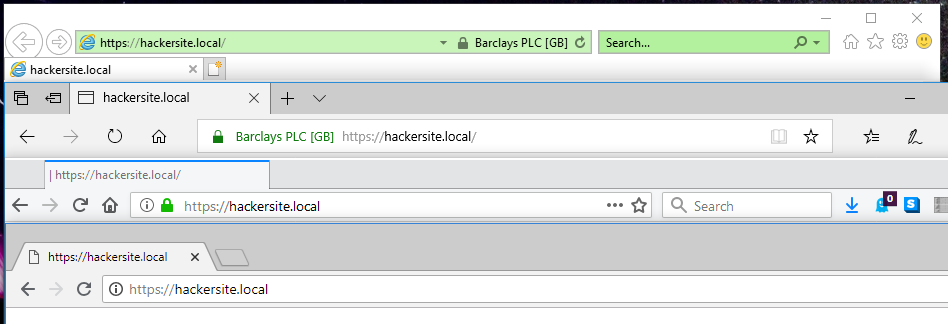
About 5 years ago, Steve Gibson observed a special feature of EV (Extended Validation) SSL certificates used on HTTPS websites: that their
extra-special “green bar”/company name feature only appears if the root CA (certificate authority) is among the browser’s default trust store for EV certificate signing. That’s
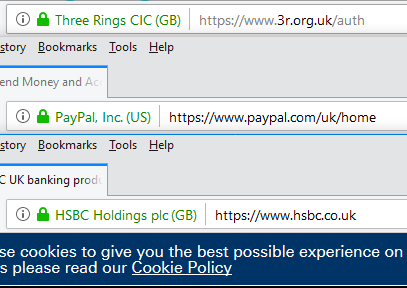
a pretty-cool feature! It means that if you’re on a website where you’d expect to see a “green bar”, like Three Rings, PayPal, or HSBC, then if you don’t see the green bar one day it most-likely means that your
connection is being intercepted in the kind of way I described earlier this year, and everything you see or send including
passwords and credit card numbers could be at risk. This could be malicious software (or nonmalicious software: some antivirus software breaks EV certificates!) or it could be your friendly local
network admin’s middlebox (you trust your IT team, right?), but either way: at least you have a chance of noticing, right?
Firefox, like most browsers, shows the company name in the address bar when valid EV certificates are presented, and hides it when the validity of that certificate is put into
question by e.g. network sniffing tools set up by your IT department.
Browsers requiring that the EV certificate be signed by a one of a trusted list of CAs and not allowing that list to be manipulated (short of recompiling the browser from
scratch) is a great feature that – were it properly publicised and supported by good user interface design, which it isn’t – would go a long way to protecting web users from unwanted
surveillance by network administrators working for their employers, Internet service providers, and governments. Great! Except Internet Explorer went and fucked it up. As Gibson
reported, not only does Internet Explorer ignore the rule of not allowing administrators to override the contents of the trusted list but Microsoft even provides a tool to help them do it!
From top to bottom: Internet Explorer 11, Edge 17, Firefox 61, Chrome 68. Only Internet Explorer and Edge show the (illegitimate) certificate for “Barclays PLC”. Sorry, Barclays; I
had to spoof somebody.
I decided to replicate Gibson’s experiment to confirm his results with today’s browsers: I was also interested to see whether Edge had resolved this problem in Internet Explorer. My
full code and configuration can be found here. As is doubtless clear from the title of this post and the
screenshot above, Edge failed the test: it exhibits exactly the same troubling behaviour as Internet Explorer.
Thanks, Microsoft.
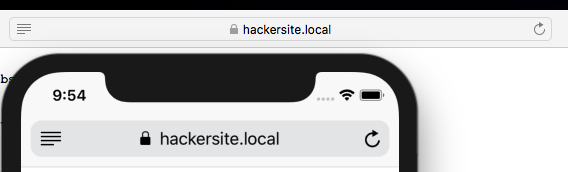
I also tried Safari (both on MacOS, above, and iOS, below) and it behaved as the other non-Microsoft browsers do (i.e. arguably more-correctly than IE or Edge).
I shan’t for a moment pretend that our current certification model isn’t without it’s problems – it’s deeply flawed; more on that in a future post – but that doesn’t give anybody an
excuse to get away with making it worse. When it became apparent that Internet Explorer was affected by the “feature” described above, we all collectively rolled our eyes
because we didn’t expect better of everybody’s least-favourite web browser. But for Edge to inherit this deliberate-fault, despite every other browser (even those that share its
certificate store) going in the opposite direction, is just insulting.
For the past 9 months I have been presenting versions of this talk to AI researchers, investors, politicians and policy makers. I felt it was time to share these ideas with a wider
audience. Thanks to the Ditchley conference on Machine Learning in 2017 for giving me a fantastic platform to get early…
Summary: The central prediction I want to make and defend in this post is that continued rapid progress in machine learning will drive the emergence of a new kind of
geopolitics; I have been calling it AI Nationalism. Machine learning is an omni-use technology that will come to touch all sectors and parts of society. The transformation of both the
economy and the military by machine learning will create instability at the national and international level forcing governments to act. AI policy will become the single most
important area of government policy. An accelerated arms race will emerge between key countries and we will see increased protectionist state action to support national champions,
block takeovers by foreign firms and attract talent. I use the example of Google, DeepMind and the UK as a specific example of this issue. This arms race will potentially speed up the
pace of AI development and shorten the timescale for getting to AGI. Although there will be many common
aspects to this techno-nationalist agenda, there will also be important state specific policies. There is a difference between predicting that something will happen and believing this
is a good thing. Nationalism is a dangerous path, particular when the international order and international norms will be in flux as a result and in the concluding section I discuss
how a period of AI Nationalism might transition to one of global cooperation where AI is treated as a global public good.
Excellent inspiring and occasionally scary look at the impact that the quest for general-purpose artificial intelligence has on the international stage. Will we enter an age of “AI
Nationalism”? If so, how will we find out way to the other side? Excellent longread.
Those who know me well know that I’m a bit of a data nerd. Even when I don’t yet know what I’m going to do with some data yet, it feels sensible to start collecting it in a
nice machine-readable format from the word go. Because you never know, right? That’s how I’m able to tell you how much gas and electricity our house used on average on any day in the
last two and a half years (and how much off that was offset by our solar panels).
The red lumps are winters, when the central heating comes on and starts burning a stack of gas.
So it should perhaps come as no huge surprise that for the last six months I’ve been recording the identity of every piece of music played by my favourite local radio station,
Jack FM (don’t worry: I didn’t do this by hand – I wrote a
program to do it). At the time, I wasn’t sure whether there was any point to the exercise… in fact, I’m still not sure. But hey: I’ve got a log of the last 45,000 songs
that the radio station played: I might as well do something with it. The Discogs API proved invaluable in automating the discovery of
metadata relating to each song, such as the year of its release (I wasn’t going to do that by hand either!), and that gave me enough data to, for example, do this (click on any image to
see a bigger version):
Decade frequency by hour: you’ve got a good chance of 80s music at any time, but lunchtime’s your best bet (or perhaps just after midnight). Note that times are in UTC+2 in this
graph.
I almost expected a bigger variance by hour-of-day, but I guess that Jack isn’t in the habit of pandering to its demographics too heavily. I spotted the post-midnight point at which you
get almost a plurality of music from 1990 or later, though: perhaps that’s when the young ‘uns who can still stay up that late are mostly listening to the radio? What about by
day-of-week, then:
Even less in it by day of week… although 70s music fans should consider tuning in on Fridays, apparently, and 80s fans will be happiest on Sundays.
The chunks of “bonus 80s” shouldn’t be surprising, I suppose, given that the radio station advertises that that’s
exactly what it does at those times. But still: it’s reassuring to know that when a radio station claims to play 80s music, you don’t just have to take their word for it
(so long as their listeners include somebody as geeky as me).
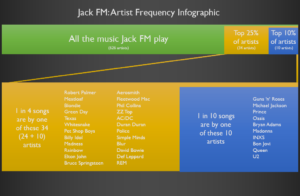
It feels to me like every time I tune in they’re playing an INXS song. That can’t be a coincidence, right? Let’s find out:
One in every ten songs are by just ten artists (including INXS). One in every four are by just 34 artists.
Yup, there’s a heavy bias towards Guns ‘n’ Roses, Michael Jackson, Prince, Oasis, Bryan Adams, Madonna, INXS, Bon Jovi, Queen, and U2 (who collectively are responsible for over a tenth
of all music played on Jack FM), and – to a lesser extent – towards Robert Palmer, Meatloaf, Blondie, Green Day, Texas, Whitesnake, the Pet Shop Boys, Billy Idol, Madness, Rainbow,
Elton John, Bruce Springsteen, Aerosmith, Fleetwood Mac, Phil Collins, ZZ Top, AC/DC, Duran Duran, the Police, Simple Minds, Blur, David Bowie, Def Leppard, and REM: taken together, one
in every four songs played on Jack FM is by one of these 34 artists.
Amazingly, the most-played song on Jack FM (Alice Cooper’s “Poison”) is not by one of the most-played 34 artists.
I was interested to see that the “top 20 songs” played on Jack FM these last six months include several songs by artists who otherwise aren’t represented at all on the station. The
most-played song is Alice Cooper’s Poison, but I’ve never recorded them playing any other Alice Cooper songs (boo!). The fifth-most-played song is Fight For Your
Right, by the Beastie Boys, but that’s the only Beastie Boys song I’ve caught them playing. And the seventh-most-played – Roachford’s Cuddly Toy – is similarly the only
Roachford song they ever put on.
Next I tried a Markov chain analysis. Markov chains are a mathematical tool that examines a sequence (in this case, a sequence
of songs) and builds a map of “chains” of sequential songs, recording the frequency with which they follow one another – here’s a great
explanation and playground. The same technique is used by “predictive text” features on your smartphone: it knows what word to suggest you type next based on the patterns of words
you most-often type in sequence. And running some Markov chain analysis helped me find some really… interesting patterns in the playlists. For example, look at the similarities between
what was played early in the afternoon of Wednesday 19 October and what was played 12 hours later, early in the morning of Thursday 20 October:
19 October 2016
20 October 2016
12:06:33
Kool & The Gang – Fresh
Kool & The Gang – Fresh
00:13:56
12:10:35
Bruce Springsteen – Dancing In The Dark
Bruce Springsteen – Dancing In The Dark
00:17:57
12:14:36
Maxi Priest – Close To You
Maxi Priest – Close To You
00:21:59
12:22:38
Van Halen – Why Can’t This Be Love
Van Halen – Why Can’t This Be Love
00:25:00
12:25:39
Beats International / Lindy – Dub Be Good To Me
Beats International / Lindy – Dub Be Good To Me
00:29:01
12:29:40
Kasabian – Fire
Kasabian – Fire
00:33:02
12:33:42
Talk Talk – It’s My Life
Talk Talk – It’s My Life
00:38:04
12:41:44
Lenny Kravitz – Are You Gonna Go My Way
Lenny Kravitz – Are You Gonna Go My Way
00:42:05
12:45:45
Shalamar – I Can Make You Feel Good
Shalamar – I Can Make You Feel Good
00:45:06
12:49:47
4 Non Blondes – What’s Up
4 Non Blondes – What’s Up
00:50:07
12:55:49
Madness – Baggy Trousers
Madness – Baggy Trousers
00:54:09
Eagle Eye Cherry – Save Tonight
00:56:09
Feeling – Love It When You Call
01:04:12
13:02:51
Fine Young Cannibals – Good Thing
Fine Young Cannibals – Good Thing
01:10:14
13:06:54
Blur – There’s No Other Way
Blur – There’s No Other Way
01:14:15
13:09:55
Pet Shop Boys – It’s A Sin
Pet Shop Boys – It’s A Sin
01:17:16
13:14:56
Zutons – Valerie
Zutons – Valerie
01:22:18
13:22:59
Cure – The Love Cats
Cure – The Love Cats
01:26:19
13:27:01
Bryan Adams / Mel C – When You’re Gone
Bryan Adams / Mel C – When You’re Gone
01:30:20
13:30:02
Depeche Mode – Personal Jesus
Depeche Mode – Personal Jesus
01:33:21
13:34:03
Queen – Another One Bites The Dust
Queen – Another One Bites The Dust
01:38:22
13:42:06
Shania Twain – That Don’t Impress Me Much
Shania Twain – That Don’t Impress Me Much
01:42:23
13:45:07
ZZ Top – Gimme All Your Lovin’
ZZ Top – Gimme All Your Lovin’
01:46:25
13:49:09
Abba – Mamma Mia
Abba – Mamma Mia
01:50:26
13:53:10
Survivor – Eye Of The Tiger
Survivor – Eye Of The Tiger
01:53:27
Scouting For Girls – Elvis Aint Dead
01:57:28
Verve – Lucky Man
02:00:29
Fleetwood Mac – Say You Love Me
02:05:30
14:03:13
Kiss – Crazy Crazy Nights
Kiss – Crazy Crazy Nights
02:10:31
14:07:15
Lightning Seeds – Sense
Lightning Seeds – Sense
02:14:33
14:11:16
Pretenders – Brass In Pocket
Pretenders – Brass In Pocket
02:18:34
14:14:17
Elvis Presley / JXL – A Little Less Conversation
Elvis Presley / JXL – A Little Less Conversation
02:21:35
14:22:19
U2 – Angel Of Harlem
U2 – Angel Of Harlem
02:24:36
14:25:20
Trammps – Disco Inferno
Trammps – Disco Inferno
02:28:37
14:29:22
Cast – Guiding Star
Cast – Guiding Star
02:31:38
14:33:23
New Order – Blue Monday
New Order – Blue Monday
02:36:39
14:41:26
Def Leppard – Let’s Get Rocked
Def Leppard – Let’s Get Rocked
02:40:41
14:46:28
Phil Collins – Sussudio
Phil Collins – Sussudio
02:45:42
14:50:30
Shawn Mullins – Lullaby
Shawn Mullins – Lullaby
02:49:43
14:55:31
Stars On 45 – Stars On 45
Stars On 45 – Stars On 45
02:53:45
16:06:35
Dead Or Alive – You Spin Me Round Like A Record
Dead Or Alive – You Spin Me Round Like A Record
03:00:47
16:09:36
Dire Straits – Walk Of Life
Dire Straits – Walk Of Life
03:03:48
16:13:37
Keane – Everybody’s Changing
Keane – Everybody’s Changing
03:07:49
16:17:39
Billy Idol – Rebel Yell
Billy Idol – Rebel Yell
03:10:50
16:25:41
Stealers Wheel – Stuck In The Middle
Stealers Wheel – Stuck In The Middle
03:14:51
16:28:42
Green Day – American Idiot
Green Day – American Idiot
03:18:52
16:33:44
A-Ha – Take On Me
A-Ha – Take On Me
03:21:53
16:36:45
Cranberries – Dreams
Cranberries – Dreams
03:26:54
Elton John – Philadelphia Freedom
03:30:56
Inxs – Disappear
03:36:57
Kim Wilde – You Keep Me Hanging On
03:40:59
16:44:47
Living In A Box – Living In A Box
16:47:48
Status Quo – Rockin’ All Over The World
Status Quo – Rockin’ All Over The World
03:45:00
The similarities between those playlists (which include a 20-songs-in-a-row streak!) surely can’t be coincidence… but they do go some way to explaining why listening to Jack FM
sometimes gives me a feeling of déjà vu (along with, perhaps, the no-talk, all-jukebox format). Looking
elsewhere in the data I found dozens of other similar occurances, though none that were both such long chains and in such close proximity to one another. What does it mean?
There are several possible explanations, including:
The exotic, e.g. they’re using Markov chains to control an auto-DJ, and so just sometimes it randomly chooses to follow a long chain that it “learned” from a real DJ.
The silly, e.g. Jack FM somehow knew that I was monitoring them in this way and are trying to troll me.
My favourite: these two are actually the same playlist, but with breaks interspersed differently. During the daytime, the breaks in the list are more-frequent and longer,
which suggests: ad breaks! Advertisers are far more-likely to pay for spots during the mid-afternoon than they are in the middle of the night (the gap in the overnight playlist could
well be a short ad or a jingle), which would explain why the two are different from one another!
But the question remains: why reuse playlists in close proximity at all? Even when the station operates autonomously, as it clearly does most of the time, it’d surely be easy enough to
set up an auto-DJ using “smart random” (because truly
random shuffles don’t sound random to humans) to get the same or a better effect.
One of the things I love about Jack FM is how little they take seriously. Like their style guide.
Which leads to another interesting observation: Jack FM’s sister stations in Surrey and Hampshire also maintain a similar playlist most of the time… which means that they’re either
synchronising their ad breaks (including their duration – I suspect this is the case) or else using filler jingles to line-up content with the beginnings and ends of songs. It’s a
clever operation, clearly, but it’s not beyond black-box comprehension. More research is clearly needed. (And yes, I’m sure I could just call up and ask – they call me “Newcastle Dan”
on the breakfast show – but that wouldn’t be even half as fun as the data mining is…)
Scientists investigating this week’s catastrophic lunchquake in the Dan’s Lunchbox region have released a statement today about the techtonic causes of the disaster.
Analysis of the lunchquake.
“The upheaval event, which reached 5.9 on the Tupperware Scale, was probably caused by overenthusiastic cycling,” explained Dr. Pepper, Professor of Lunchtime Beverages at Tetrapak
University.
“The breadospheres ‘float’ on soft, viscous eggmayolayers. Usually these are stable, but sometimes a lateral shift can result in entire breadosphere plates being displaced underneath
one another.”
This is what happened earlier this week, when a breadospheric shift resulted in catastrophic sinkage in the left-side-of-lunchbox area, eggmayolayer “vents”, and an increase in the
height of Apple Mountain.
No lives were lost during the disaster. However, two jammie dodgers were completely ruined.
Recent emissions in the ring of fire area is unrelated to this recent lunchquake, and are instead believed to be associated with excessive consumption of spicy food at lunchtimes.
I’m scared. Kit is researching the laws governing marriage in Hawaii, and I’m not exactly sure why.
“Hey; you can get married at 15 in Hawaii!”
Meanwhile, I’m currently coding a wiki engine. For those of you who aren’t in-the-know, a wiki is a collaborative network of web pages that anybody can edit. They’re fun, if a little
anarchic.