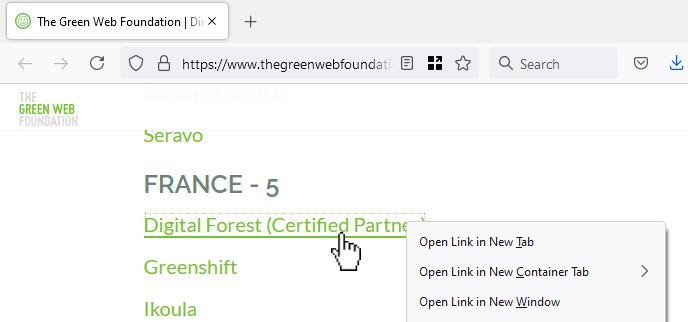
Here’s a perfect example I bumped into earlier this week, courtesy of The Green Web Foundation. This looks like a
hyperlink… but if you open it in a new tab/window, you see a page (not even a 404 page!) with the text “It looks like nothing was found at this location.”
In the site shown in the screenshot above, the developer took something the web gave them for free (a hyperlink), threw it away (by making it a link-to-nowhere), and rebuilt its
functionality with Javascript (without thinking about the fact that you can do more with hyperlinks than click them: you can click-and-drag them, you can bookmark them, you can share
them, you can open them in new tabs etc.). Ugh.
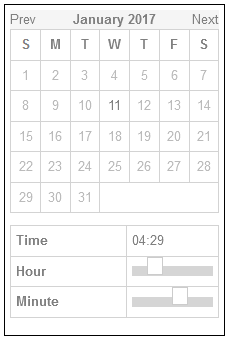
Something you can clearly type a numeric day, month and year into is best.
Three dropdowns are slightly worse, but at least if you use native HTML <select> elements keyboard
users can still “type” to filter.
Everything else – including things that look like <select>s but are really funky React <div>s, is pretty terrible.
Calendars can be great for choosing your holiday date range. But pressing “Prev” ~480 times to get to my month of birth isn’t good. Also: what’s with the time “sliders”? (Yes, I know I’ve implemented these myself, in the past, and I’m sorry.)
People designing webforms that require me to enter my birthdate:
I am begging you: just let me type it in.
Typing it in is 6-8 quick keystrokes. Trying to navigate a little calendar or spinny wheels back to the 1970s is time-consuming, frustrating and unnecessary.
They’re right. Those little spinny wheels are a pain in the arse if you’ve got to use one to go back 40+ years.
These things are okay (I guess) on mobile/touchscreen devices, though I’d still prefer the option to type in my date of birth. But send one to my desktop and I will
curse your name.
Can we do worse?
If there’s one thing we learned from making the worst volume control in the world, the other
year, it’s that you can always find a worse UI metaphor. So here’s my attempt at making a date of birth field that’s somehow
even worse than “date spinners”:
My datepicker implements a game of “higher/lower”. Starting from bounds specified in the HTML code and a random guess, it
narrows-down its guess as to what your date of birth is as you click the up or down buttons. If you make a mistake you can start over with the restart button.
Amazingly, this isn’t actually the worst datepicker into which I’ve entered my date of birth! It’s cognitively challenging compared to most, but it’s relatively fast at
narrowing down the options from any starting point. Plus, I accidentally implemented some good features that make it better than plenty of the datepickers out there:
It’s progressively enhanced – if the Javascript doesn’t load, you can still enter your date of birth in a sensible way.
Because it leans on a <input type="date"> control, your browser takes responsibility for localising, so if you’re from one of those weird countries that prefers
mm-dd-yyyy then that’s what you should see.
It’s moderately accessible, all things considered, and it could easily be improved further.
It turns out that even when you try to make something terrible, so long as you’re building on top of the solid principles the web gives you for free, you can accidentally end
up with something not-so-bad. Who knew?
Among Twitter’s growing list of faults over the years are various examples of its increasing divergence from open Web standards and developer-friendly endpoints. Do you remember when
you used to be able to subscribe to somebody’s feed by RSS? When you could see who follows somebody without first logging in?
When they were still committed to progressive enhancement and didn’t make your browser download ~5MB of Javascript or else not show any content whatsoever? Feels like a long time ago,
now.
For one of the most-popular 50 websites in the world, this score is frankly shameful.
But those complaints aside, the thing that bugged me most this week was how much harder they’ve made it to programatically get access to things that are publicly accessible via web
pages. Like avatars, for example!
If you’re a human and you want to see the avatar image associated with a given username, you can go to twitter.com/that-username and – after you’ve waited
a bit for all of the mandatory JavaScript to download and run (I hope you’re not on a metered connection!) – you’ll see a picture of the user, assuming they’ve uploaded one and not made
their profile private. Easy.
If you’re a computer and you want to get the avatar image, it used to be just as easy; just go to
twitter.com/api/users/profile_image/that-username and you’d get the image. This was great if you wanted to e.g. show a Facebook-style facepile of images of people who’d retweeted your content.
But then Twitter removed that endpoint and required that computers log in to Twitter, so a clever developer made
a service that fetched avatars for you if you went to e.g. twivatar.glitch.com/that-username.
You want to that image? Well you’ll need a Twitter account, a developer account, an OAuth token set, a stack of code…
Recently, I needed a one-off program to get the avatars associated with a few dozen Twitter usernames.
First, I tried the easy way: find a service that does the work for me. I’d used avatars.io before but it’s died, presumably because (as I soon discovered) Twitter had made
things unnecessarily hard for them.
Second, I started looking at the Twitter API
documentation but it took me in the region of 30-60 seconds before I said “fuck that noise” and decided that the set-up overhead in doing things the official way simply wasn’t
justified for my simple use case.
So I decided to just screen-scrape around the problem. If a human can just go to the web page and see the
image, a computer pretending to be a human can do exactly the same. Let’s do this:
The code is ludicrously simple. It took less time, energy, and code to write this than to follow Twitter’s “approved” procedure. You can download the code via Gist.
Given that I only needed to run it once, on a finite list of accounts, I maintain that my approach was probably kinder on their servers than just manually going to every page
and saving the avatar from it. But if you set up a service that uses this approach then you’ll certainly piss off somebody at Twitter and history shows that they’ll take their displeasure out on you without warning.
This output shows the avatar URLs of a half a dozen Twitter accounts. It took minutes to write the code and takes seconds
to run, but if I’d have done it the “right” way I’d still be unnecessarily wading through Twitter’s sprawling documentation.
But it works. It was fast and easy and I got what I was looking for.
And the moral of the story is: if you make an API and it’s terrible, don’t be surprised if people screen-scape your
service instead. (You can’t spell “scraping” without “API”, amirite?)
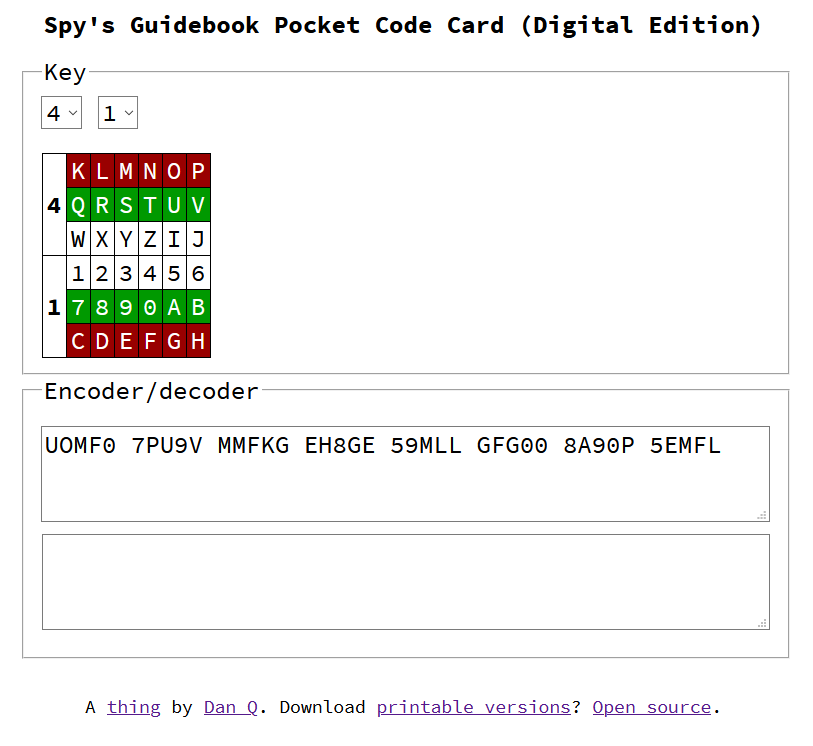
When I was a kid of about 10, one of my favourite books was Usborne’s Spy’s Guidebook. (I also liked its sister the Detective’s Handbook, but the Spy’s
Guidebook always seemed a smidge cooler to me).
I imagine that a younger version of me would approve of our 7-year-old’s bookshelf, too.
So I was pleased when our eldest, now 7, took an interest in the book too. This morning, for example, she came to breakfast with an encrypted message for me (along with the relevant
page in the book that contained the cipher I’d need to decode it).
Decryption efforts were hampered by sender’s inability to get her letter “Z”s the right damn way around.
Later, as we used the experience to talk about some of the easier practical attacks against this simple substitution cipher (letter frequency analysis, and known-plaintext attacks… I
haven’t gotten on to the issue of its miniscule keyspace yet!), she asked me to make a pocket version of the code card as described in the book.
A three-bit key doesn’t make a simple substitution cipher significantly safer, but it does serve as a vehicle to teach elementary cryptanalysis!
While I was eating leftover curry for lunch with one hand and producing a nice printable, foldable pocket card for her (which you can download here if you like) with the other, I realised something. There are likely to be a lot more messages in my
future that are protected by this substitution cipher, so I might as well preempt them by implementing a computerised encoder/decoder right away.
If you’ve got kids of the right kind of age, I highly recommend picking up a copy of the Spy’s Guidebook (and possibly the Detective’s Handbook). Either use it as a
vehicle to talk about codes and maths, like I have… or let them believe it’s secure while you know you can break it, like we did with Enigma machines after WWII. Either way, they eventually learn a valuable lesson about cryptography.
Back in 2005 I reblogged a Flash-based interactive advert I’d discovered via del.icio,us. And if that sentence wasn’t early-naughties enough for you, buckle up…
This screenshot isn’t from the original site but from my homage to it. More on that later.
At the end of 2004, Unilever brand Axe (Lynx here in the UK)
continued their strategy of marketing their
deodorant as magically transforming young men into hyper-attractive sex gods. This is, of course, an endless battle, pitting increasingly sexually-charged advertisements against the
fundamental experience of their product, which smells distinctly like locker rooms and school discos. To launch 2005’s new fragrance Feather, they teamed up with London-based
design agency Dare Digital to create a game at domain AxeFeather.com (long since occupied by domain squatters).
In the game, the player’s mouse pointer becomes a feather which they can use to tickle an attractive young woman lying on a bed. The woman’s movements – which vary based on where she’s
tickled – have been captured in digital video. This was aggressively compressed using the then-new H.263-ish
Sorensen Spark codec to make a download just-about small enough to be tolerable for people still on dial-up Internet access (which was still almost as popular as broadband). The ad became a viral hit. I can’t tell you whether it paid for itself in sales, but it
must have paid for itself in brand awareness: on Valentines Day 2005 it felt like it was all the Internet wanted to talk about.
I suspect its success also did wonders for the career of its creative consultant Olivier Rabenschlag, who left Dare a few years
later, hopped around Silicon Valley for a bit, then landed himself a job as Head of Creative (now Chief Creative Officer) with Google. Kudos.
Why?
I told you about the site 16 years ago: why am I telling you again? Because this site, which made
headlines at the time, is gone.
And not just a little bit gone, like a television ad no longer broadcast but which might still exist on YouTube somewhere (and here it is – you’re welcome for the earworm). The website went down in 2009, and because it was implemented in Flash the content
was locked away in a compiled, proprietary format, which has ceased to be meaningfully usable on the modern web.
The parts of AxeFeather.com’s code that are openly readable don’t help much, but I love this comment, which carries the scent of the adolescent web in the same way at Lynx deodorant
carries the scent of an adolescent human.
The ad was pioneering. Flash had only recently gained video support (this would be used the following year for the first version of YouTube), and it had so far been used mostly for
non-interactive linear video. This ad was groundbreaking… but now it’s disappeared like so much other Flash work. And for all that Flash might have been bad for the web,
it’s an important part of our
digital history [recommended reading].
Third-party Flash emulation is imperfect. I tried to make Axe Feather work in Ruffle and got… an empty bed? What is this, a metaphor for being a
lonely nerd?
So on a whim… I decided to see if I could recreate the ad.
Call it lockdown fever if you like, because it’s certainly not the work of a sane mind to attempt to resurrect a 16-year-old Internet advertisement. But that’s what I did.
How?
My plan: to reverse-engineer the digital assets (video, audio, cursor etc.) out of the original Flash file, and use them to construct a moderately-faithful recreation of the ad,
suitable for use on the modern web. My version must:
Work in any modern browser, without Flash of course.
Indicate how much of the video content you’d seen, because we live in an era of completionists who want to know they’ve seen it all.
Depend on no third-party frameworks/libraries: just vanilla HTML, CSS, and JavaScript.
Let’s get started.
Reverse-engineering
At this point I noticed that the videos had no audio tracks: the giggling and other sound effects must be stored separately.
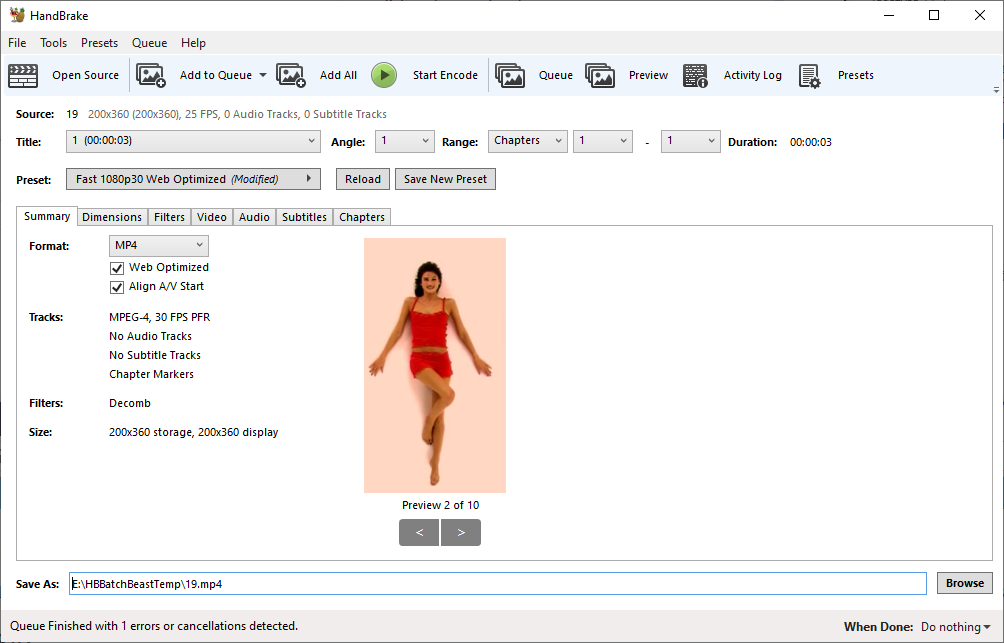
I grabbed the compiled .swf file from archive.org and ran it through
SWFExtract and an online decompiler: neither was individually able to extract
all of the assets, but together they gave me a full set. I ran the .flv files through Handbrake to get myself a set of
.mp4 files instead.
In what appears to have been an exercise in size optimisation, the original authors cropped the videos differently depending on how much space was needed (e.g. if the subject
stretched her arms above her head, more space would be required). Clearly, some re-alignment would be needed.
Seeing that the extracted video files were clearly designed to be carefully-positioned on a static background, and not all in the exact same position, I decided to make my job easier by
combining them all together, and including the background layer (the picture of the bed) as a single video. Integrating the background with the subject meant that I was able to use
video editing software to tweak the position, which I imagined would be much easier than doing so in code. Combining all of the video clips into a single file provides compression
benefits as well as making it easier to encourage a browser to precache the entire video to begin with.
My design called for three “layers” above my web page: the video, a transparent (and usually hidden) canvas showing the hit areas for debugging purposes, and the feather-shaped
cursor.
The longest clip was a little over 6 seconds long, so I split my timeline into blocks of 7 seconds, padding each clip with a freeze-frame of its final image to make each exactly 7
seconds long. This meant that calculating the position in the finished video to which I wanted to jump was as simply as multiplying the (0-indexed) clip number by 7 and seeking to that
position. The additional “frozen” frames acted as a safety buffer in case my JavaScript code was delayed by a few milliseconds in jumping to the “next” block.
I used onion-skinning to help “line up” the actress with herself as I composited her onto the bed in a single unified video of 7-second blocks.
An additional challenge was that in the original binary, the audio files were stored separately from the video clips… and slightly longer than them! A little experimentation revealed
that the ends of each clip lined up, presumably something to do with how Flash preloads and synchronises media streams. Luckily for me, the audio clips were numbered such that
they mostly mapped to the order in which the videos appeared.
Once I had a video file suitable for use on the web (you can watch the entire clip here, if you really want to), it was time to
write some code.
It feels slightly wasteful that over 50% of the resulting video clip is a freeze-frame, but modern video compression algorithms like H.264 reduce the impact considerably and the
resulting video file is about the same size as its more-optimised predecessor.
Regular old engineering
The theory was simple: web page, video, loop the first seven seconds until you click on it, then animate the cursor (a feather) and jump to another seven-second block before jumping
back or, in some cases, on to a completely new seven second block. Simple!
Of course, any serious web development is always a little more complex than you first anticipate.
I extracted from the .swf 34 distinct animated clips, which I numbered 0 through 33. 6 and 30 appeared to be duplicates of others. 0 and 33 are each two “idling” states
from which interaction can lead to other states. Note that my interpretation of the order and relationship of animation sequences differs from the original.
For example: nowadays, putting a video on a web page is as easy as a <video> tag. But, in an effort to prevent background web pages from annoying you with unexpected
audio, modern browsers won’t let a video play sound unless user interaction is the reason that the video starts playing (or unmutes, if it was playing-but-muted to
begin with). Broadly-speaking, that means that a definitive user action like a “click” event has to be in the call stack when your code makes the video play/unmute.
But changing the .currentTime of a video to force it into a loop: that’s fine! So I set the video to autoplay muted on page load, with a script to make it loop
within its first seven-second block. The actress doesn’t make any sound in block 0 (position A) anyway; so I can unmute the video when the user interacts with a hotspot.
For best performance, I used window.requestAnimationFrame to synchronise my non-interactive events (video loops, virtual cursor repositioning). This posed a slight problem
in that animationframes wouldn’t be triggered if the tab was moved to the background: the video would play through each seven-second block and into the next! Fortunately the
visibilitychange event came to the rescue and I was able to pause the video when it wasn’t being actively watched.
I originally hoped to use the cursor: CSS directive to make the “feather” cursor, but there’d be no nice way to
animate it. Comet Cursor may have been able to use animated GIFs
as cursors back in 1997 (when it wasn’t busy selling all your personal information to advertisers, back when that kind of thing used to attract widespread controversy), but modern
browsers don’t… presumably because it would be super annoying. They also don’t all respect cursor: none, so I used the old trick of using cursor: url(null.png),
none (where null.png is an almost-entirely transparent 1×1 pixel image) to hide the original cursor, then position an image dynamically. I
usegetBoundingClientRect() to allow the video to resize dynamically in CSS and convert coordinates on it represented
as percentages into actual pixel values and vice-versa: this allows it to react responsively to any screen size without breakpoints or excessive code.
Once I’d gone that far I was able to drop the GIF idea entirely and used a CSS animation for the “tickling” motion.
The hotspot overlay was added as a debugging feature but I left it in the final version. Hold the space bar to highlight hit areas.
I added a transparent <canvas> element on top of the <video> on which the hit areas are dynamically drawn to help me test the “hotspots” and tweak
their position. I briefly considered implementing a visual tool to help me draw the hotspots, but figured it wasn’t quite worth the time it would take.
As I implemented more and more of the game, I remembered one feature from the original that I’d missed: the “blowaway”. If you trigger block 31 – a result of tickling the woman’s nose –
she’ll blow your cursor off the screen. It’s particularly fun because it subverts the player’s expectations of their user interface: once you’ve got past the surprise of your
cursor being a feather, you quickly settle in to it moving like a regular cursor… but then control’s stolen from you and the cursor vanishes! (Well I thought it was cool… 16 years ago.)
Sometimes tickling her nose will make her blow your feather off the screen. That’ll show you.
My friend still uses a seriously retro digital music player, rather than his phone, to listen to music. It’s not a Walkman or a Minidisc player, I suppose, but it’s still pretty
elderly. But it’s not one of these.
I’m not here to speak about the legality of retaining offline copies of music from streaming services. YouTube Music seems to permit you to do this using their app, but I’ll bet there’s
something in their terms and conditions that specifically prohibits doing so any other way. Not least because Google’s arrangement with rights holders probably stipulates that they
track how many times tracks are played, and using a different player (like my friend’s portable device) would throw that off.
But what I’m interested in is the feasibility. And in answering that question, in explaining how to work out that it’s feasible.
The web interface to YouTube Music shows playlists of songs and streaming is just a click away.
Spoiler: I came up with an approach, and it looks like it works. My friend can fill up their Zune or whatever the hell
it is with their tunes and bop away. But what I wanted to share with you was the underlying technique I used to develop this approach, because it involves skills that as a web
developer I use most weeks. Hold on tight, you might learn something!
youtube-dl can download “playlists” already, but to download a personal playlist requires that you faff about with authentication and it’s a bit of a drag. Just extracting
the relevant metadata from the page is probably faster, I figured: plus, it’s a valuable lesson in extracting data from web pages in general.
Here’s what I did:
Step 1. Load all the data
I noticed that YouTube Music playlists “lazy load”, and you have to scroll down to see everything. So I scrolled to the bottom of the page until I reached the end of the playlist: now
everything was in the DOM, I could investigate it with my inspector.
Step 2. Find each track’s “row”
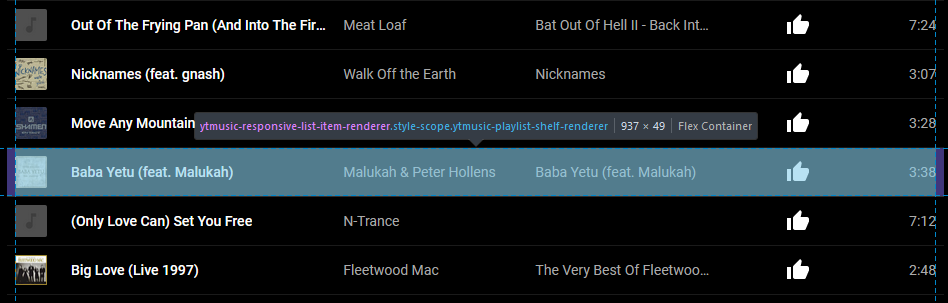
Using my browser’s debugger “inspect” tool, I found the highest unique-sounding element that seemed to represent each “row”/track. After a little investigation, it looked like
a playlist always consists of a series of <ytmusic-responsive-list-item-renderer> elements wrapped in a <ytmusic-playlist-shelf-renderer>. I tested
this by running document.querySelectorAll('ytmusic-playlist-shelf-renderer ytmusic-responsive-list-item-renderer') in my debug console and sure enough, it returned a number
of elements equal to the length of the playlist, and hovering over each one in the debugger highlighted a different track in the list.
The web application captured right-clicks, preventing the common right-click-then-inspect-element approach… so I just clicked the “pick an element” button in the debugger.
Step 3. Find the data for each track
I didn’t want to spend much time on this, so I looked for a quick and dirty solution: and there was one right in front of me. Looking at each track, I saw that it contained several
<yt-formatted-string> elements (at different depths). The first corresponded to the title, the second to the artist, the third to the album title, and the fourth to
the duration.
Better yet, the first contained an <a> element whose href was the URL of the piece of music.
Extracting the URL and the text was as simple as a .querySelector('a').href on the first
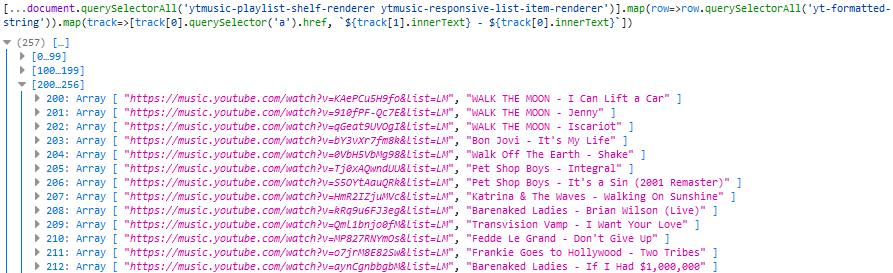
<yt-formatted-string> and a .innerText on the others, respectively, so I ran [...document.querySelectorAll('ytmusic-playlist-shelf-renderer
ytmusic-responsive-list-item-renderer')].map(row=>row.querySelectorAll('yt-formatted-string')).map(track=>[track[0].querySelector('a').href, `${track[1].innerText} -
${track[0].innerText}`]) (note the use of [...*] to get an array) to check that I was able to get all the data I needed:
Lots of URLs and the corresponding track names in my friend’s preferred format (me, I like to separate my music into folders
by album, but I suppose I’ve got a music player with more than a floppy disk’s worth of space on it).
Step 4. Sanitise the data
We’re not quite good-to-go, because there’s some noise in the data. Sometimes the application’s renderer injects line feeds into the innerText (e.g. when escaping an
ampersand). And of course some of these song titles aren’t suitable for use as filenames, if they’ve got e.g. question marks in them. Finally, where there are multiple spaces in a row
it’d be good to coalesce them into one. I do some experiments and decide that .replace(/[\r\n]/g, '').replace(/[\\\/:><\*\?]/g, '-').replace(/\s{2,}/g, ' ') does a
good job of cleaning up the song titles so they’re suitable for use as filenames.
I probably should have it fix quotes too, but I’ll leave that as an exercise for the reader.
Step 5. Produce youtube-dl commands
Okay: now we’re ready to combine all of that output into commands suitable for running at a terminal. After a quick dig through the documentation, I decide that we needed the following
switches:
-x to download/extract audio only: it defaults to the highest quality format available, which seems reasomable
-o "the filename.%(ext)s" to specify the output filename but accept the format provided by the quality requirement (transcoding to your preferred format is a
separate job not described here)
--no-playlist to ensure that youtube-dl doesn’t see that we’re coming from a playlist and try to download it all (we have our own requirements of each song’s
filename)
--download-archive downloaded.txt to log what’s been downloaded already so successive runs don’t re-download and the script is “resumable”
The output isn’t pretty, but it’s suitable for copy-pasting into a terminal or command prompt where it ought to download a whole lot of music for offline play.
This isn’t an approach that most people will ever need: part of the value of services like YouTube Music, Spotify and the like is that you pay a fixed fee to stream whatever you like,
wherever you like, obviating the need for a large offline music collection. And people who want to maintain a traditional music collection offline are most-likely to want to do
so while supporting the bands they care about, especially as (with DRM-free digital downloads commonplace) it’s never been
easier to do so.
But for those minority of people who need to play music from their streaming services offline but don’t have or can’t use a device suitable for doing so on-the-go, this kind of approach
works. (Although again: it’s probably not permitted, so be sure to read the rules before you use it in such a way!)
Step 6. Learn something
But more-importantly, the techniques of exploring and writing console Javascript demonstrated are really useful for extracting all kinds of data from web pages (data scraping), writing your own userscripts, and much more. If there’s
one lesson to take from this blog post it’s not that you can steal music on the Internet (I’m pretty sure everybody who’s lived on this side of 1999 knows that by now), but
that you can manipulate the web pages you see. Once you’re viewing it on your computer, a web page works for you: you don’t have to consume a page in the way that the
author expected, and knowing how to extract the underlying information empowers you to choose for yourself a more-streamlined, more-personalised, more-powerful web.
If you missed it the first time around, click through to explore an interactive panoramic view of my
workspace. It’s slightly more “unpacked” now.
As I approach my first full year as an Automattician, I find myself looking back on everything I’ve learned… but also looking around at all the things I still don’t understand! I’m not
learning something new every day any more… but I’m still learning something new most weeks.
This summer I’ve been getting up-close and personal with Gutenberg components. I’d mostly managed to avoid learning the React (eww; JSX, bad documentation, and an elephantine payload…) necessary to hack Gutenberg, but in
helping to implement new tools for WooCommerce.com I’ve discovered that it’s… not quite as painful as I’d thought. There are even some bits I quite like. But I don’t expect to
fall in love with React any time soon. This autumn I’ve been mostly working on search and personalisation, integrating customer analytics data with our marketplace to help understand
what people look for on our sites and using that to guide their future experience (and that of others “like” them). There’s always something new.
I suppose that by now everybody‘s used to meetings that look like this, but when I first started at Automattic a year ago they were less-commonplace.
My team continues to grow, with two newmatticians this month and a third starting in January. In fact, my team’s planning to fork into two closely-linked subteams; one with a focus on
customers and vendors, the other geared towards infrastructure. It’s exciting to see my role grow and change, but I worry about the risk of gradually pigeon-holing myself into an
increasingly narrow specialisation. Which wouldn’t suit me: I like to keep a finger in all the pies. Still; my manager’s reassuring that this isn’t likely to be the case and
our plans are going in the “right” direction.
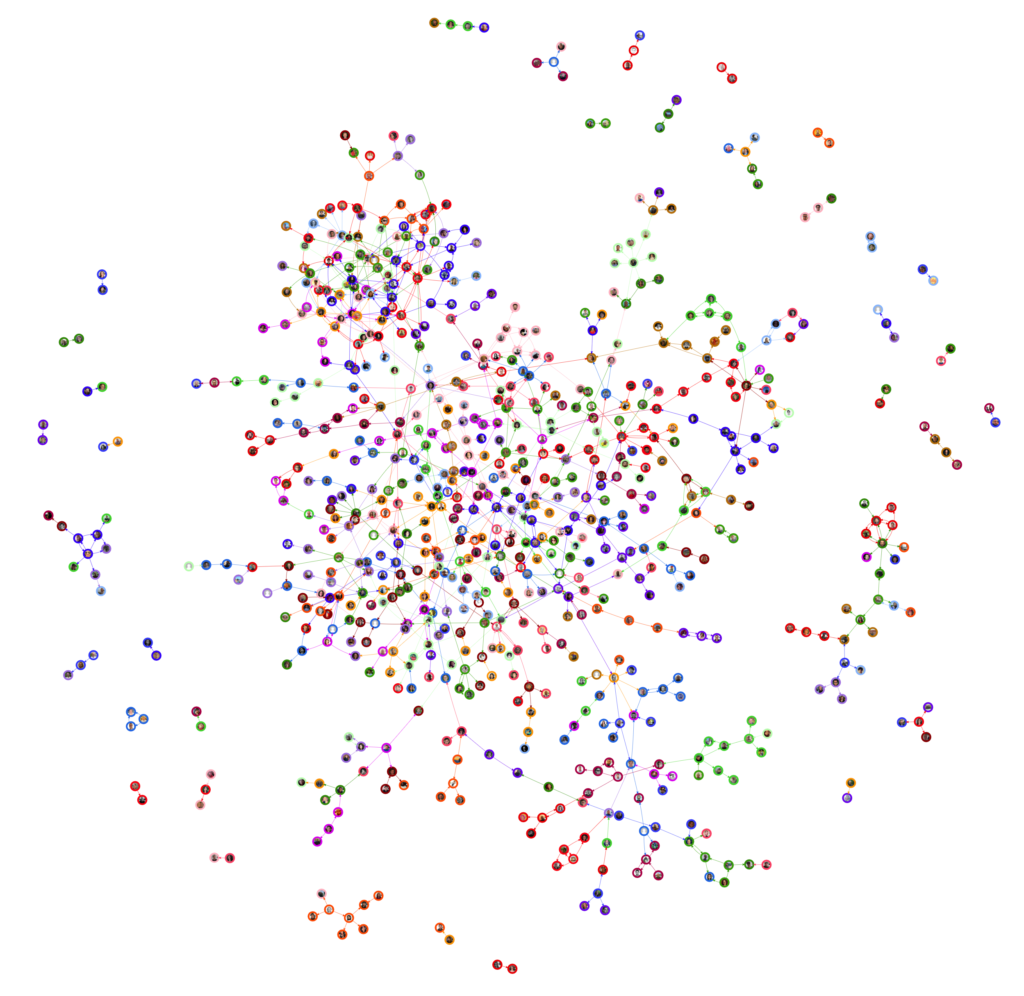
On the side of my various project work, I’ve occasionally found the opportunity for more-creative things. Last month, I did some data-mining over the company’s “kudos” history of the
last five years and ran it through vis.js to try to find a new angle on understanding how Automattic’s staff, teams, and divisions interact with one
another. It lead to some interesting results: panning through time, for example, you can see the separate island of Tumblr staff who joined us
during the acquisition gradually become more-interconnected with the rest of the organisation over the course of
the last year.
Automattic as a social graph of kudos given/received during September 2020, colour-coded by team. Were you one of us, you’d be able to zoom in and find yourself. The large “branch” in
the bottom right is mostly comprised of Tumblr staff.
The biggest disappointment of my time at Automattic so far was that I’ve not managed to go to a GM! The 2019 one – which looked awesome – took place only a couple of weeks before my contract started (despite my best efforts to wrangle
my contract dates with the Bodleian and Automattic to try to work around that), but people reassured me that it was okay because I’d make it
to the next one. Well.. 2020 makes fools of us all, I guess, because of course there’s no in-person GM this year. Maybe, hopefully, if and
when the world goes back to normal I’ll get to spend time in-person with my colleagues once in a while… but for now, we’re having to suffice with Internet-based socialisation only, just
like the rest of the world.
You see what that’s doing? It’s loading the stylesheet for the print medium, but then when the document finishes loading it’s switching the media type from “print” to “all”.
Because it didn’t apply to begin with the stylesheet isn’t render-blocking. You can use this to delay secondary styles so the page essentials can load at full speed.
Reducing blocking times, like I have on this page, is one of many steps in optimising perceived page performance.
I don’t like this approach. I mean: I love the elegance… I just don’t like the implications.
Why I don’t like lazy-loading CSS using Javascript
Using Javascript to load CSS, in order to prevent that CSS
blocking rendering, feels to me like it conceptually breaks the Web. It certainly violates the expectations of progressive enhancement, because it introduces a level of
fault-intolerance that I consider (mostly) unacceptable.
CSS and Javascript are independent of one another. A well-designed progressively-enhanced page should function with
HTML only, HTML-and-CSS only, HTML-and-JS only, or all
three.CSS adds style, and JS adds behvaiour to a page; and when
you insist that the user agent uses Javascript in order to load stylistic elements, you violate the separation of these technologies (I’m looking at you, the majority of heavyweight
front-end frameworks!).
If you’re thinking that the only people affected are nerds like me who browse with Javascript wholly or partially disabled, you’re wrong: gov.uk research shows that around 1% of your visitors have Javascript fail for some reason or another: because it’s disabled
(whether for preference, privacy, compatibility with accessibility technologies, or whaterver), blocked, firewalled, or they’re using a browser that you didn’t expect.
Can we lazy-load CSS in a way that doesn’t depend on Javascript? (spoiler: yes)
Chris’s daily tip got me thinking: could there exist a way to load CSS in a non-render-blocking way but which degraded
gracefully in the event that Javascript was unavailable? I.e. if Javascript is working, lazy-load CSS, otherwise: load
conventionally as a fallback. It turns out, there is!
In principle, it’s this:
Link your stylesheet from within a <noscript> block, thereby only exposing it where Javascript is disabled. Give it a custom attribute to make it easy to find
later, e.g. <noscript lazyload> (if you’re a standards purist, you might prefer to use a data- attribute).
Have your Javascript extract the contents of these <noscript> blocks and reinject them. In modern browsers, this is as simple as e.g.
[...document.querySelectorAll('noscript[lazyload]')].forEach(ns=>ns.outerHTML=ns.innerHTML).
If you need support for Internet Explorer, you need a little more work, because Internet Explorer doesn’t expose<noscript> blocks to the DOM in a helpful way. There are a variety of possible workarounds; I’ve implemented one but not put too much thought into it because I rarely have to
think about Internet Explorer these days.
In any case, I’ve implemented a proof of concept/demonstration if you’d like to see it in action: just take a look and view source (or read the page)
for details. Or view the source alone via this gist.
Lazy-loading CSS using my approach provides most of the benefits of other approaches… but works properly in environments without
Javascript too.
Update: Chris Ferdinandi’s refined this into an even cleaner approach that takes the best of both worlds.
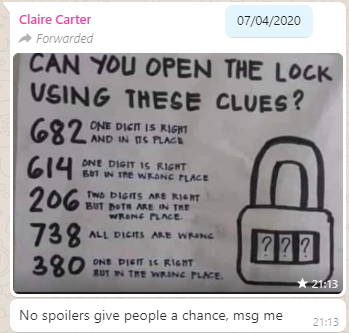
About three months ago, my friend Claire, in a WhatsApp group we both frequent, shared a brainteaser:
Was this way back at the beginning of April? Thank heavens for WhatsApp scrollback.
The puzzle was to be interpreted as follows: you have a three-digit combination lock with numbers 0-9; so 1,000 possible combinations in total. Bulls and Cows-style, a series of clues indicate how “close” each of several pre-established “guesses” are. In “bulls and
cows” nomenclature, a “bull” is a correctly-guessed digit in the correct location and a “cow” is a correctly-guessed digit in the wrong location, so the puzzle’s clues are:
682 – one bull
614 – one cow
206 – two cows
738 – no bulls, no cows
380 – one cow
Feel free to stop scrolling at this point and solve it for yourself. Or carry on; there are no spoilers in this post.
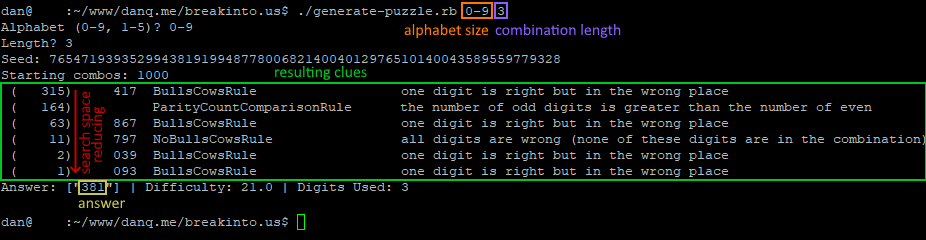
By the time I’d solved her puzzle the conventional way I was already interested in the possibility of implementing a general-case computerised solver for this kind of puzzle, so I did.
My solver uses a simple “brute force” technique, as follows:
Put all possible combinations into a search space.
For each clue, remove from the search space all invalid combinations.
Whatever combination is left is the correct answer.
The first three clues of Claire’s puzzle are sufficient alone to reduce the search space to a single answer, although a human is likely to need more.
Visualising the solver as a series of bisections of a search space got me thinking about something else: wouldn’t this be a perfectly reasonable way to programatically generate
puzzles of this type, too? Something like this:
Put all possible combinations into a search space.
Randomly generate a clue such that the search space is bisected (within given parameters to ensure that neither too many nor too few clues are needed)
Repeat until only one combination is left
Interestingly, this approach is almost the opposite of what a human would probably do. A human, tasked with creating a puzzle of this sort, would probably choose the answer
first and then come up with clues that describe it. Instead, though, my solution would come up with clues, apply them, and then see what’s left-over at the end.
Sometimes it comes up with inelegant or unchallenging suggestions, but for the most part my generator produces adequate puzzles.
I expanded my generator to go beyond simple bulls-or-cows clues: it’s also capable of generating clues that make reference to the balance of odd and even digits (in a numeric lock), the
number of different digits used in the combination, the sum of the digits of the combination, and whether or not the correct combination “ascends” or “descends”. I’ve ideas for
other possible clue types too, which could be valuable to make even tougher combination locks: e.g. specifying how many numbers in the combination are adjacent to a consecutive number,
specifying the types of number that the sum of the digits adds to (e.g. “the sum of the digits is a prime number”) and so on.
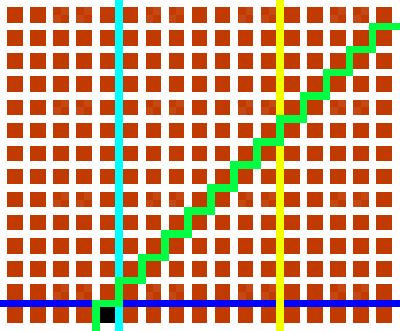
Like the original puzzle, puzzles produced by my generator might have redundancies. In the picture above, the black square can be defined by the light blue, dark blue, and green
bisections only: the yellow bisection is rendered redundant by the light blue one. I’ve left this as a deliberate feature.
Next up, I wanted to make a based interface so that people could have a go at the puzzles in their web browser, track their progress through the levels, get a “score” based on the
number and difficulty of the locks that they’d cracked (so they can compare it to their friends), and save their progress to carry on next time.
I implemented in pure vanilla HTML, CSS, SVG and JS, with no dependencies. Compressed, it delivers to your browser and is ready-to-play in a little
under 10kB, most of which is the puzzles themselves (which are pregenerated and stored in a JSON file). Naturally, it lends itself well to running offline, so it’s PWA-enhanced with a
service worker so it can be “installed” onto your device, too, and it’ll check for bonus puzzles and other updates periodically.
Naturally, the original puzzle appears in the web-based game, too.
Honestly, the hardest bit of implementing the frontend was the “spinnable” digits: depending on your browser, these are an endless-scrolling <ul> implemented mostly in
CSS and with snap points set, and then some JS to work out “what you meant” based on
where you span to. Which feels like the right way to implement such a thing, but was a lot more work than putting together my own control, not least because of browser
inconsistencies in the implementation of snap points.
Anyway: you should go and play the game, now, and let me know what you think. Is it worth expanding and improving? Should I leave it as it is? I’m
open to ideas (and if you don’t like that I’m not implementing your suggestions, you can always fork a copy of the code and change
it yourself)!
Our sources report that the underlying reason behind the impressive tech demo for Unreal Engine 5 by Epic Games is to ridicule web developers.
According to the Washington Post, the tech demo includes a new dynamic lighting system and a rendering approach with a much higher geometric detail for both shapes and textures. For
example, a single statue in the demo can be rendered with 33 million triangles, giving it a truly unprecedented level of detail and visual density.
Turns out that the level of computational optimization and sheer power of this incredible technology is meant to make fun of web developers, who struggle to maintain 15fps while
scrolling a single-page application on a $2000 MacBook Pro, while enjoying 800ms delays typing the corresponding code into their Electron-based text editors.
…
Funny but sadly true. However, the Web can be fast. What makes it slow is bloated, kitchen-sink-and-all frontend frameworks, pushing computational effort to the browser with
overcomplicated DOM trees and unnecessarily rich CSS rules, developer
privilege, and blindness to the lower-powered devices that make up most of the browsing world. Oh, and of course embedding a million third-party scripts to get you all the analytics,
advertising, etc. you think you need doesn’t help, either.
The Web will never be as fast as native, for obvious reasons. But it can be fast; blazingly so. It just requires a little thought and consideration. I’ve talked about this recently.
Back in 2011, some folks cross-compiled Doom (the original, not the reboot, obviously) to JavaScript, leveraging the capabilities of the then-relatively-young
<canvas> element and APIs. I was really impressed to see that JavaScript had come so far and that
performance on desktop devices was so slick. Sure, this was an 18-year-old video game, but it was playable in a browser, which was a long way from the environment for which it
was originally developed.
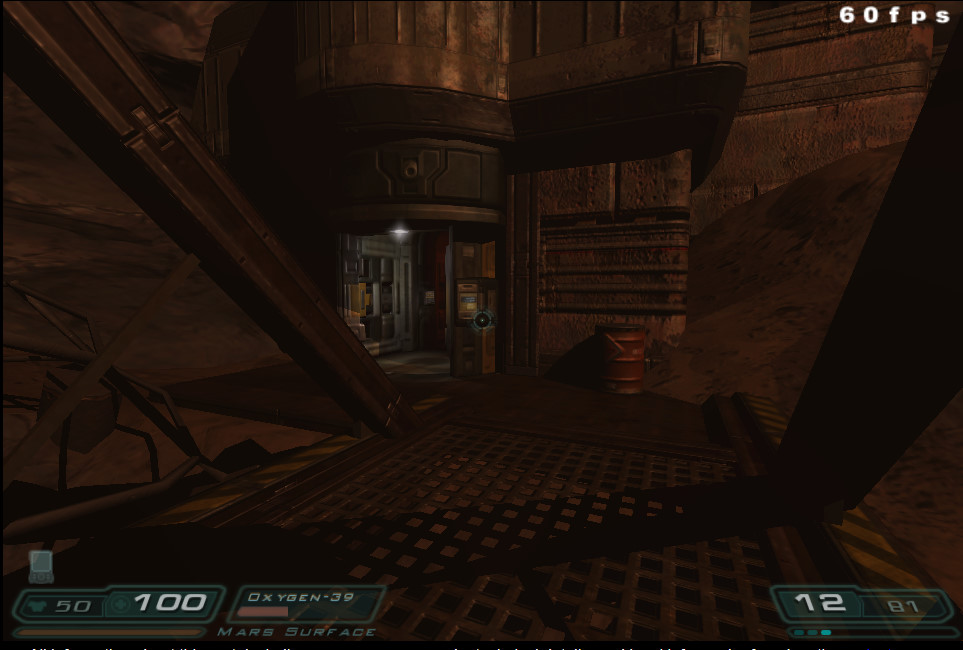
Now Doom 3‘s playable in a browser, and my mind’s blown all over again. This follows almost the same curve – Doom 3’s 16 years old – but it still goes to show that there’s
little limit to the power of client-side browser programming. They’ve done this magic with WebAssembly; while WebAssembly goes
slightly against my ideas about the open-source nature of the Web, I still respect the power it commands to do heavyweight crunching tasks like this one.
How long until AAA developers start developing with the Web as an additional platform?
“Why make the web more boring? Because boring is fast, resilient, fault tolerant, and accessible. Boring is the essence of unobtrusive designs that facilitate interactions rather than
hinder them.” says Jeremy.
He’s right. I’ve become increasingly concerned in recent years in the trend towards overuse of heavyweight frameworks. These frameworks impose limitations on device/network
capabilities, browser features, caching, accessibility, stability, and more. It’s possible to work around many of those limitations, but doing so often takes additional work, and so
most developers, especially junior developers raised on a heavyweight framework who haven’t yet been exposed to the benefits of working around them. Plus, such mitigations tend to make
already-bloated web applications – full of unnecessary cruft – larger still; the network demands of the application grow ever larger.
What are these frameworks for? They often provide valuable components and polyfills, certainly, but they also have a tendency to reimplement what the browser already gives you:
e.g. routing and caching come free with HTTP, buttons and links from HTML, design from CSS, (progressive) interactivity from JS. Every developer should feel free to use a framework if it suits
them and the project they’re working on… but adoption of a framework should only come after consideration and understanding of what it provides, and at what cost.
A long while ago, inspired by Nick Berry‘s analysis of optimal Hangman strategy, I worked it backwards to find the
hardest words to guess when playing Hangman. This week, I showed these to my colleague Grace – who turns out to be a fan of word puzzles – and our conversation inspired me to go a little deeper. Is it possible, I
thought, for me to make a Hangman game that cheats by changing the word it’s thinking of based on the guesses you make in order to make it as difficult as possible for you to
win?
The principle is this: every time the player picks a letter, but before declaring whether or not it’s found in the word –
Make a list of all possible words that would fit into the boxes from the current game state.
If there are lots of them, still, that’s fine: let the player’s guess go ahead.
But if the player’s managing to narrow down the possibilities, attempt to change the word that they’re trying to guess! The new word must be:
Legitimate: it must still be the same length, have correctly-guessed letters in the same places, and contain no letters that have been declared to be incorrect
guesses.
Harder: after resolving the player’s current guess, the number of possible words must be larger than the number of possible words that would have
resulted otherwise.
Yeah, you’re screwed now.
You might think that this strategy would just involve changing the target word so that you can say “nope” to the player’s current guess. That happens a lot, but it’s not always the
case: sometimes, it’ll mean changing to a different word in which the guessed letter also appears. Occasionally, it can even involve changing from a word in which the guessed
letter didn’t appear to one in which it does: that is, giving the player a “freebie”. This may seem counterintuitive as a strategy, but it sometimes makes sense: if
saying “yeah, there’s an E at the end” increases the number of possible words that it might be compared to saying “no, there are no Es” then this is the right move for a
cheating hangman.
Playing against a cheating hangman also lends itself to devising new strategies as a player, too, although I haven’t yet looked deeply into this. But logically, it seems that the
optimal strategy against a cheating hangman might involve making guesses that force the hangman to bisect the search space: knowing that they’re always going to adapt towards the
largest set of candidate words, a perfect player might be able to make guesses to narrow down the possibilities as fast as possible, early on, only making guesses that they actually
expect to be in the word later (before their guess limit runs out!).
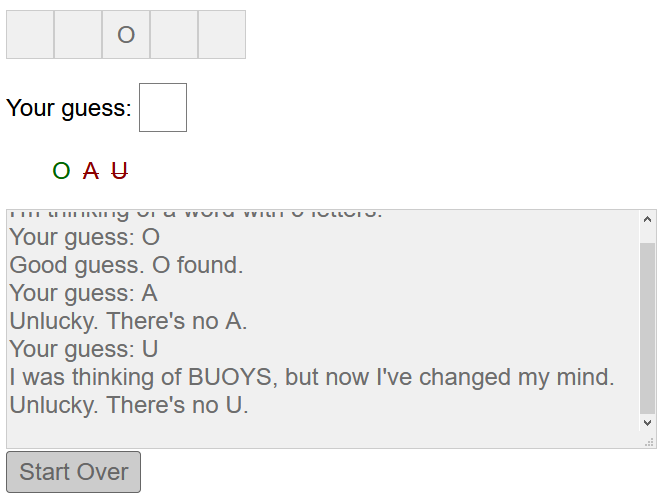
The game is brutally-difficult, but surprisingly fun, and you can have it tell you when and how it cheats so you can begin to understand its strategy.
I also find myself wondering how easily I could adapt this into a “helpful hangman”: a game which would always change the word that you’re trying to guess in order to try to make you
win. This raises the possibility of a whole new game, “suicide hangman”, in which the player is trying to get themselves killed and so is trying to pick letters that can’t
possibly be in the word and the hangman is trying to pick words in which those letters can be found, except where doing so makes it obvious which letters the player must avoid next.
Maybe another day.
In the meantime, you’re welcome to go play the game (and let me know what you think, below!) and, if you’re of such an inclination, read the source code. I’ve used some seriously ugly techniques to make this work, including regular expression metaprogramming (using
regular expressions to write regular expressions), but the code should broadly make sense if you want to adapt it. Have fun!
Update 26 September 2019, 16:23: I’ve now added “helpful mode”, where the computer tries to cheat on your behalf
rather than against you, but it’s not as helpful as you’d think because it assumes you’re playing optimally and have already memorised the dictionary!
I wasn’t sure that my whiteboard at the Bodleian, which reminds my co-workers exactly how many days I’ve got left in the office, was
attracting as much attention as it needed to. If I don’t know what my colleagues don’t know about how I do my job, I can’t write it into my handover notes.
Tick, tick, tick, tick, boom.
So I repurposed a bit of digital signage in the office with a bit of Javascript to produce a live countdown. There’s a lot of code out there to produce countdown timers, but mine
had some very specific requirements that nothing else seems to “just do”. Mine needed to:
Only count down during days that I’m expected to be in the office.
Only count down during working hours.
Carry on seamlessly after a reboot.
[insert Countdown theme song here]
Naturally, I’ve open-sourced it in case anybody else needs one, ever. It’s pretty basic, of course,
because I’ve only got a hundred and fifty-something hours to finish a lot of things so I only wanted to throw a half hour at this while I ate my lunch! But if you want one,
just put in an array of your working dates, the time you start each day, and the number of hours in your workday, and it’ll tick away.
The vast majority of respondents are still using Sass and vanilla CSS? Wow! This made me pause and think. Because I feel there’s an analogy here between that unseen dark matter,
and the huge crowd of web developers who are using such “boring” technology stacks.
…
This! As a well-established developer who gets things done with a handful of solid, reliable, tried-and-tested toolsets, I’ve sometimes felt like I must be “falling behind” on the
hot-new-tech curve because I can’t keep up with whichever yet-another-Javascript-framework is supposed to be hipthis week. Earlier in my career, I didn’t have this problem. And it’s not just that we’re inventing new libraries, frameworks, and (even) languages faster than ever before –
and I’m pretty sure we are – nor is it that my thirty-something brain is less-plastic than the brain of my twenty-something younger self… it’s simpler than that: it’s that the level of
productivity that’s expected of an engineer of my level of seniority precludes me from playing with more than a couple of new approaches each year. I try, and I manage, to get a working
understanding of a new language and a framework or two most years, and I appreciate that that’s more than I’m expected to do (and more than many will), but it still feels like a drop in
the ocean: there’s always a “new hotness”.
But when I take the time to learn a “new hotness”, these days, nine times out of ten it doesn’t “stick” for me. Why? Because most of the new technologies we seem to be
inventing don’t actually add anything to the vast majority of use cases. Hipper (and often smarter) developers than me might latch on to the latest post-reational database or
the most-heavyweight CSS-in-JS-powered realtime web framework, and they dominate the online discussion, but that doesn’t make their ideas right for my projects. They’re a loud
minority with a cool technology, and I’m a little bit jealous that they have the time to learn and play with it… but I’ll just keep delivering value with the tools I’ve got,
thanks.






















![You have [20] work days left to ask Dan that awkward question.](https://bcdn.danq.me/_q23u/2019/09/20190903_152221-898x437.jpg)
