I’m off for a week of full-time volunteering with Three Rings at 3Camp, our annual volunteer hack week: bringing together our distributed
team for some intensive in-person time, working to make life better for charities around the world.
And if there’s one good thing to come out of me being suddenly and unexpectedly laid-off two days ago, it’s that I’ve got a shiny new laptop to do
my voluntary work on (Automattic have said that I can keep it).
Among the many perks of working for a company with a history so tightly-intertwined with that of the open-source WordPress project is that license to attend WordCamps – the biggest WordPress conferences – is basically a
given.
It’s frankly a wonder that this is, somehow, my first WordCamp. As well as using it1 and developing atop
it2,
of course, I’ve been contributing to WordPress since 2004 (albeit only in a tiny way, and not at all for most of the last decade!).
If you already know what WP-CLI is… let’s be friends.
Today is Contributor Day, a pre-conference day in which folks new and old get together in person to hack on WordPress and WordPress-adjacent projects. So I met up with Cem, my Level 4 Dragonslayer friend, and we took an ultra-brief induction into WP-CLI3
before diving in to try to help write some code.
Contributor Days are about many things, but perhaps their biggest value comes from lowering the barrier to becoming a new contributor to an open-source project by sitting you
right next to somebody who already knows it well.
So today, as well as meeting some awesome folks, I got to write an overly-verbose justification for a
bug report being invalid and implement my first PR for WP-CLI: a bugfix for a strange quirk in output formatting.
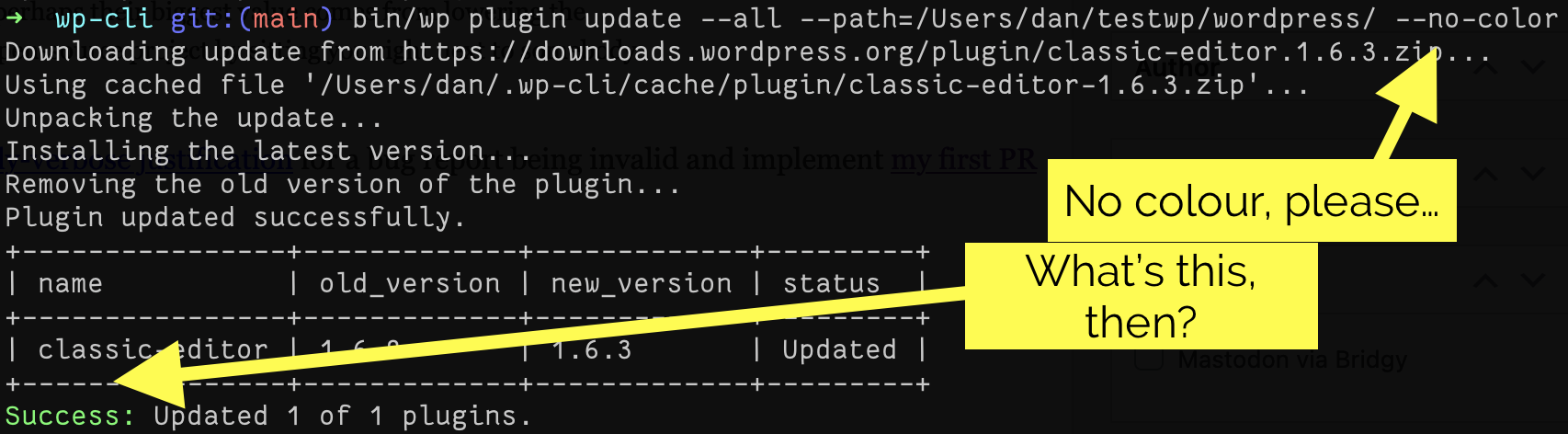
The bug I fixed is slightly hard to describe (and even harder to explain why it matters), but here’s a summary: when you run a WP-CLI command that first displays a table and
then the result, the result is likely to always appear in colour even if you specify --no-color.
I hope to be able to continue contributing to WP-CLI. I learned a lot about it today, and while I don’t use it as much as I used to in my multisite-management days, I still really
respect its power as a tool.
Did I mention lately how awesome my employers are? I promise my blog’s not always gonna be me shilling for them… but today it is.
Footnotes
1 Even with the monumental stack of custom code woven into DanQ.me, a keen eye will
probably spot that it’s WordPress-powered.
3 WP-CLI is… it’s like Drush but for WordPress, if that makes sense to you? If not: it’s a
multifaceted command-line tool for installing, configuring, maintaining, and managing WordPress installations, and I’ve been in love with it for years.
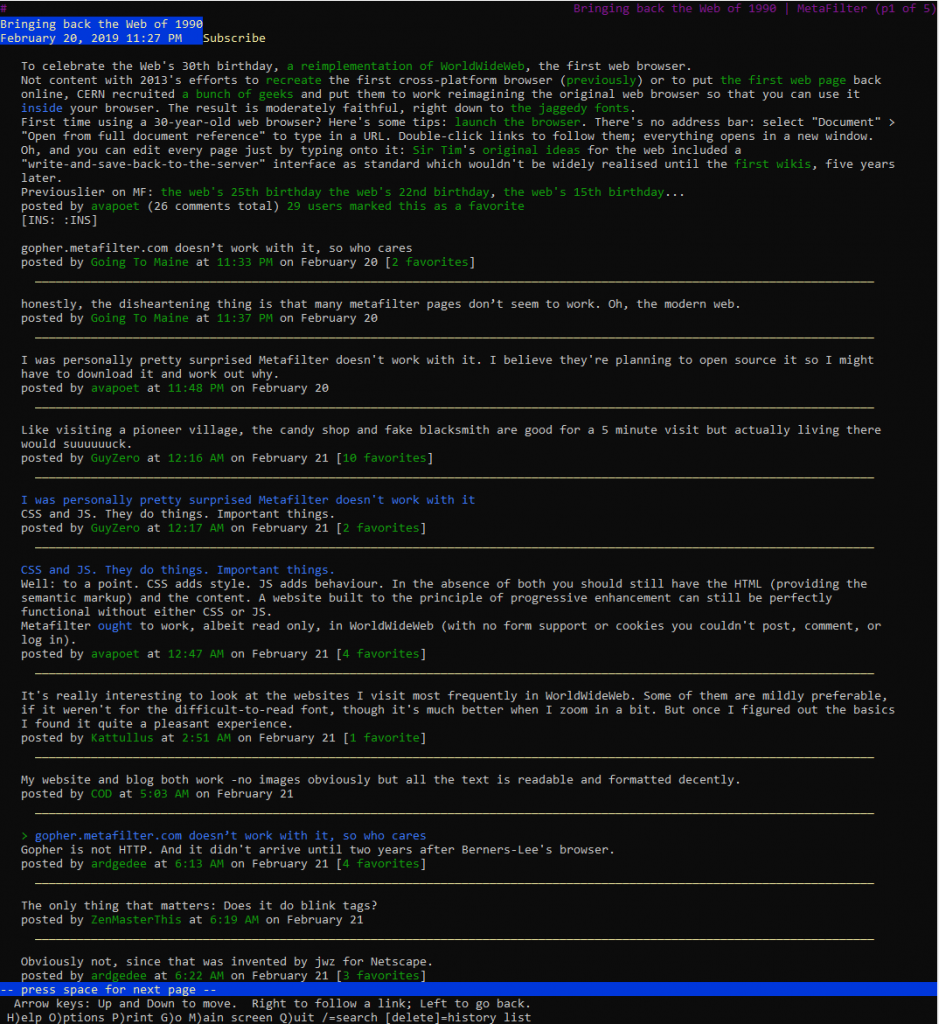
People were quick to point this out and assume that it was something to do with the modernity of MetaFilter:
honestly, the disheartening thing is that many metafilter pages don’t seem to work. Oh, the modern web.
Some even went so far as to speculate that the reason related to MetaFilter’s use of CSS and JS:
CSS and JS. They do things. Important things.
This is, of course, complete baloney, and it’s easy to prove to oneself. Firstly, simply using the View Source tool in your browser on a MetaFilter page reveals source code that’s quite
comprehensible, even human-readable, without going anywhere near any CSS or JavaScript.
As late as the early 2000s I’d occasionally use Lynx for serious browsing, but any time I’ve used it since it’s been by necessity.
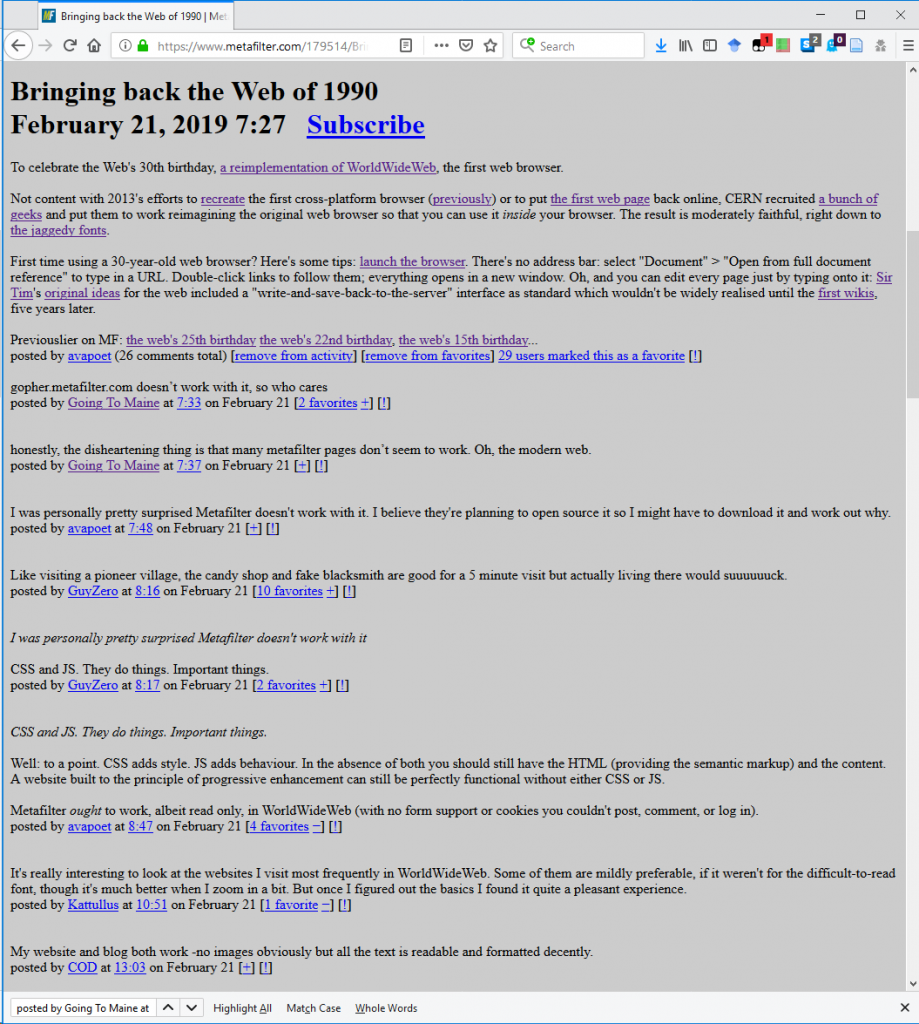
Secondly, it’s pretty simple to try browsing MetaFilter without CSS or JavaScript enabled! I tried in two ways: first,
by using Lynx, a text-based browser that’s never supported either of those technologies. I also tried by using
Firefox but with them disabled (honestly, I slightly miss when the Web used to look like this):
It only took me three clicks to disable stylesheets and JavaScript in my copy of Firefox… but I’ll be the first to admit that I don’t keep my browser configured like “normal people”
probably do.
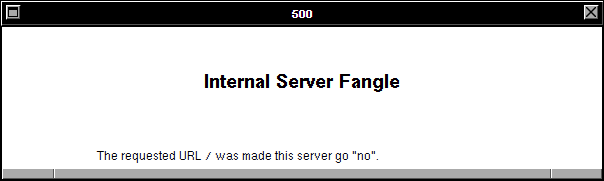
And thirdly: the error code being returned by the simulated WorldWideWeb browser is a HTTP code 500. Even if you don’t
know your HTTP codes (I mean, what kind of weirdo would take the time to memorise them all anyway <ahem>),
it’s worth learning this: the first digit of a HTTP response code tells you what happened:
1xx means “everything’s fine, keep going”;
2xx means “everything’s fine and we’re done”;
3xx means “try over there”;
4xx means “you did something wrong” (the infamous 404, for example, means you asked for a page that doesn’t exist);
5xx means “the server did something wrong”.
Simple! The fact that the error code begins with a 5 strongly implies that the problem isn’t in the (client-side) reimplementation of WorldWideWeb: if this had have been a
CSS/JS problem, I’d expect to see a blank page, scrambled content, “filler”
content, or incomplete content.
So I found myself wondering what the real problem was. This is, of course, where my geek flag becomes most-visible: what we’re talking about, let’s not forget, is a fringe
problem in an incomplete simulation of an ancient computer program that nobody uses. Odds are incredibly good that nobody on Earth cares about this except, right now, for me.
I searched for a “Geek Flag” and didn’t like anything I saw, so I came up with this one based on… well, if you recognise what it’s based on, good for you, you’re certainly allowed to
fly it. If not… well, you can too: there’s no geek-gatekeeping here.
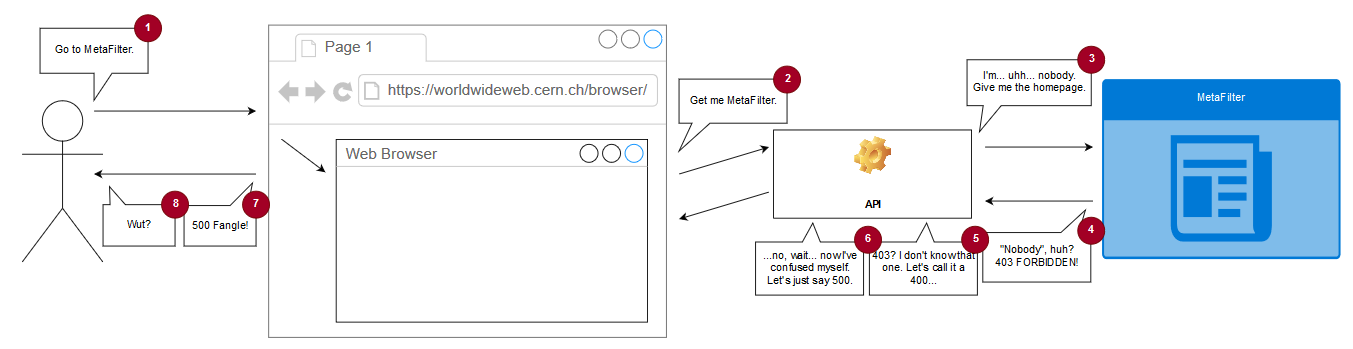
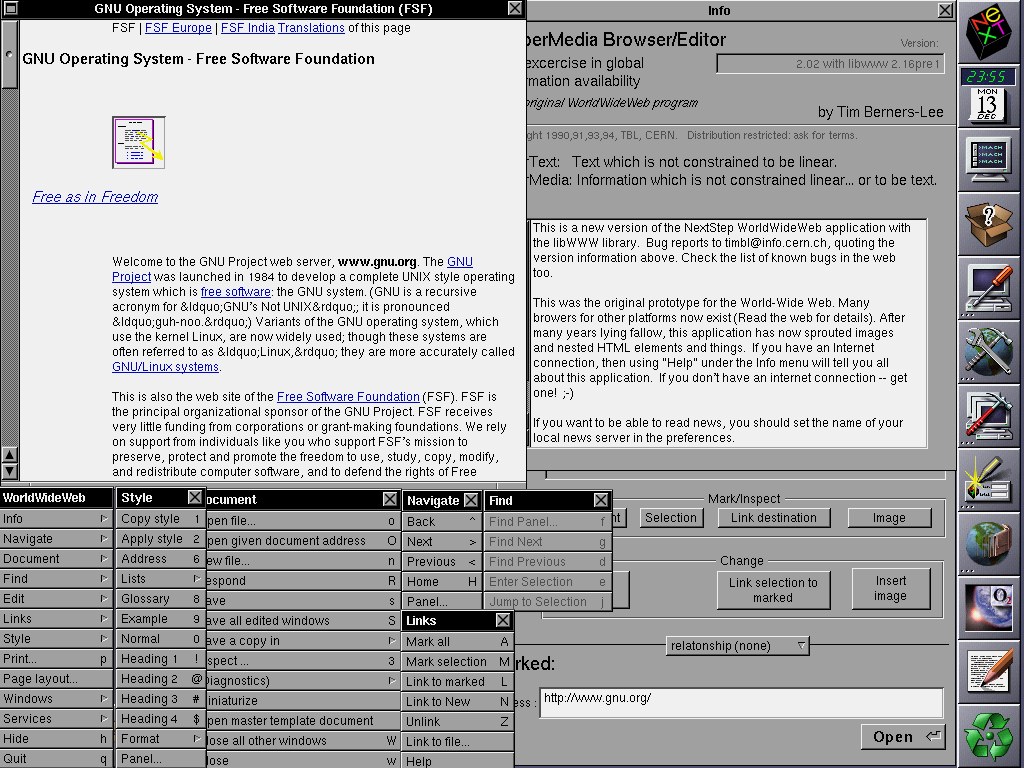
The (simulated) copy of WorldWideWeb is asked to open a document by reference, e.g. “https://www.metafilter.com/”.
To work around same-origin policy restrictions, the request is sent to an API which acts as a proxy server.
The API makes a request using the Node package “request” with this line of code: request(url, (error, response, body) =>
{ ... }). When the first parameter to request is a (string) URL, the module uses its default settings for all of
the other options, which means that it doesn’t set the User-Agent header (an optional part of a Web request where the computer making the request identifies the software
that’s asking).
MetaFilter, for some reason, blocks requests whose User-Agent isn’t set. This is weird! And nonstandard: while web browsers should – in RFC2119 terms – set their User-Agent: header, web servers shouldn’t require
that they do so. MetaFilter returns a 403 and a message to say “Forbidden”; usually a message you only see if you’re trying to access a resource that requires session authentication and
you haven’t logged-in yet.
The API is programmed to handle response codes 200 (okay!) and 404 (not found), but if it gets anything else back
it’s supposed to throw a 400 (bad request). Except there’s a bug: when trying to throw a 400, it requires that an error message has been set by the request module and if there
hasn’t… it instead throws a 500 with the message “Internal Server Fangle” and no clue what actually went wrong. So MetaFilter’s 403 gets translated by the proxy into a 400 which
it fails to render because a 403 doesn’t actually produce an error message and so it gets translated again into the 500 that you eventually see. What a knock-on effect!
If you’re having difficulty visualising the process, this diagram might help you to continue your struggle with that visualisation.
This then sets a User-Agent header and makes servers that require one, such as MetaFilter, respond appropriately. I don’t know whether WorldWideWeb originally set a User-Agent header
(CERN’s source file archive seems to be missing the relevant C sources so I can’t check) but I
suspect that it did, so this change actually improves the fidelity of the emulation as a bonus. A better fix would also add support for and appropriate handling of other HTTP response
codes, but that’s a story for another day, I guess.
I know the hackathon’s over, but I wonder if they’re taking pull requests…
This month, a collection of some of my favourite geeks got invited to CERN in Geneva to
participate in a week-long hackathon with the aim of reimplementing WorldWideWeb –
the first web browser, circa 1990-1994 – as a web application. I’m super jealous, but I’m also really pleased with what they managed
to produce.
This represents a huge leap forward from their last similar project, which aimed to recreate the line mode browser: the first web browser that
didn’t require a NeXT computer to run it and so a leap forward in mainstream appeal. In some ways, you might expect
reimplementing WorldWideWeb to be easier, because its functionality is more-similar that of a modern browser, but there were doubtless some challenges too: this early browser predated the concept of the DOM and so there are distinct
processing differences that must be considered to get a truly authentic experience.
It’s just like any other hackathon, if you ignore the enormous particle collider underneath it.
Among their outputs, the team also produced a cool timeline of the Web, which – thanks to some careful authorship – is as legible in WorldWideWeb as it is in a modern browser (if, admittedly, a little less pretty).
When Sir Tim took this screenshot, he could never have predicted the way the Web would change, technically, over the next
25-30 years. But I’m almost more-interested in how it’s stayed the same.
In an age of increasing Single Page Applications and API-driven sites and “apps”, it’s nice to be reminded that if you develop right for the Web, your content will be visible
(sort-of; I’m aware that there are some liberties taken here in memory and processing limitations, protocols and negotiation) on machines 30 years old, and that gives me hope that
adherence to the same solid standards gives us a chance of writing pages today that look just as good in 30 years to come. Compare that to a proprietary technology like Flash whose heyday 15 years ago is overshadowed by its imminent death (not to
mention Java applets or ActiveX <shudders>), iOS apps which stopped working when the operating system went 64-bit, and websites which only work
in specific browsers (traditionally Internet Explorer, though as I’ve complained before we’re getting more and more Chrome-only sites).
The Web is a success story in open standards, natural and by-design progressive enhancement, and the future-proof archivability of human-readable code. Long live the Web.
An annual tradition at Three Rings is DevCamp, an event that borrows from the “hackathon” concept and expands it to a week-long code-producing factory for the
volunteers of the Three Rings development team. Motivating volunteers is a very different game to motivating paid employees: you can’t offer to pay them more for working harder nor
threaten to stop paying them if they don’t work hard enough, so it’s necessary to tap in to whatever it is that drives them to be a volunteer, and help them get more of that out of
their volunteering.
This photo, from DevCamp 2011, is probably the only instance where I’ve had fewer monitors out than another developer.
At least part of what appeals to all of our developers is a sense of achievement – of producing something that has practical value – as well as of learning new things, applying
what they’ve learned, and having a degree of control over the parts of the project they contribute most-directly to. Incidentally, these are the same things that motivate paid
developers, too, if a Google search for studies on the subject is to believed. It’s just that employers are rarely able to willing to offer all of those things (and even if they can,
you can’t use them to pay your mortgage), so they have to put money on the table too. With my team at Three Rings, I don’t have money to give them, so I have to make up for it with a
surplus of those things that developers actually want.
At the 2015 DevCamp, developers used the solar eclipse as an excuse for an impromptu teambuilding activity: making a camera obscura out of stuff we had lying about.
It seems strange to me in hindsight that for the last seven years I’ve spent a week of my year taking leave from my day job in order to work longer, harder, and unpaid for a
voluntary project… but that I haven’t yet blogged about it. Over the same timescale I’ve spent about twice as long at DevCamp than I have, for example, skiing, yet I’ve managed
to knock out several blog posts on that subject. Part of that might be borne out of the secretive nature of Three Rings, especially in its early days (when
involvement with Three Rings pretty-much fingered you as being a Nightline volunteer, which was frowned upon), but nowadays we’ve got a couple of
dozen volunteers with backgrounds in a variety of organisations: and many of those of us that ever were Nightliner volunteers have long since graduated and moved-on to other
volunteering work besides.
Semi-cooperative horror-themed board games by candlelight are a motivator for everybody, right?
Part of the motivation – one of the perks of being a Three Rings developer – for me at least, is DevCamp itself. Because it’s an opportunity to drop all of my “day job” stuff
for a week, go to some beatiful far-flung corner of the country, and (between early-morning geocaching/hiking expeditions and late night drinking tomfoolery) get to spend long days
contributing to something awesome. And hanging out with like-minded people while I do so. I like I good hackathon of any variety, but I love me some Three Rings DevCamp!
The geocaches near DevCamp 2016 were particularly fabulous, though. Like this one – GC4EE6C – part of an Alice In Wonderland-themed series.
So yeah: DevCamp is awesome. It’s more than a little different than those days back in 2003 when I wrote all the code and Kit worked hard
at distracting me with facts about the laws of Hawaii – for the majority of DevCamp 2016 we had half a dozen developers plus two documentation writers
in attendance! – but it’s still fundamentally about the same thing: producing a piece of software that helps about 25,000 volunteers do amazing things and make the world a better place.
We’ve collectively given tens, maybe hundreds of thousands of hours of time in developing and supporting it, but that in turn has helped to streamline the organisation of about 16
million person-hours of other volunteering.
So that’s nice.
An end-of-day “Show & Tell” session at DevCamp 2016.
Oh, and I was delighted that one of my contributions this DevCamp was that I’ve finally gotten around to expanding the functionality of the “gender” property so that there are now more
than three options. That’s almost more-exciting than the geocaches. Almost.
Edit: added a missing word in the sentence about how much time our volunteers had given, making it both more-believable and more-impressive.
Last month I got the opportunity to attend the EEBO-TCP Hackfest,
hosted in the (then still very-much under construction) Weston Library at my workplace. I’ve
done a couple of hackathons and similar get-togethers before, but this one was somewhat different in that it was unmistakably geared towards a different kind of geek than the
technology-minded folks that I usually see at these things. People like me, with a computer science background, were remarkably in the minority.
Me in the Weston Library (still under construction, as evidenced by the scaffolding in the background).
Instead, this particular hack event attracted a great number of folks from the humanities end of the spectrum. Which is understandable, given its theme: the Early English Books Online
Text Creation Partnership (EEBO-TCP) is an effort to digitise and make available in marked-up, machine-readable text formats a huge corpus of English-language books printed between 1475
and 1700. So: a little over three centuries of work including both household names (like Shakespeare, Galileo, Chaucer, Newton, Locke, and Hobbes) and an enormous number of others that
you’ll never have heard of.
After an introduction to the concept and the material, attendees engaged in a speed-networking event to share their thoughts prior to pitching their ideas.
The hackday event was scheduled to coincide with and celebrate the release of the first 25,000 texts into the public domain, and attendees were challenged to come up with ways to use
the newly-available data in any way they liked. As is common with any kind of hackathon, many of the attendees had come with their own ideas half-baked already, but as for me: I had no
idea what I’d end up doing! I’m not particularly familiar with the books of the 15th through 17th centuries and I’d never looked at the way in which the digitised texts had been
encoded. In short: I knew nothing.
The ideas pitch session quickly showed some overlap between different project ideas, and teams were split and reformed a few times as people found the best places for themselves.
Instead, I’d thought: there’ll be people here who need a geek. A major part of a lot of the freelance work I end up doing (and a lesser part of my work at the Bodleian, from
time to time) involves manipulating and mining data from disparate sources, and it seemed to me that these kinds of skills would be useful for a variety of different conceivable
projects.
XML may have been our interchange format, but everything fell into Excel in the end for speedy management even by less-technical team members.
I paired up with a chap called Stephen Gregg, a lecturer in 18th century literature from Bath Spa University. His idea
was to use this newly-open data to explore the frequency (and the change in frequency over the centuries) of particular structural features in early printed fiction: features like
chapters, illustrations, dedications, notes to the reader, encomia, and so on). This proved to be a perfect task for us to pair-up on, because he had the domain knowledge to ask
meaningful questions, and I had the the technical knowledge to write software that could extract the answers from the data. We shared our table with another pair, who had
technically-similar goals – looking at the change in the use of features like lists and tables (spoiler: lists were going out of fashion, tables were coming in, during the 17th century)
in alchemical textbooks – and ultimately I was able to pass on the software tools I’d written to them to adapt for their purposes, too.
A quick meeting on the relative importance of ‘chapters’ as a concept in 16th century literature. Half of the words that the academics are saying go over my head, but I’m formulating
XPath queries in my head while I wait.
And here’s where I made a discovery: the folks I was working with (and presumably academics of the humanities in general) have no idea quite how powerful data mining tools could be in
giving them new opportunities for research and analysis. Within two hours we were getting real results from our queries and were making amendments and refinements in our questions and
trying again. Within a further two hours we’d exhausted our original questions and, while the others were writing-up their findings in an attractive way, I was beginning to look at how
the structural differences between fiction and non-fiction might be usable as a training data set for an artificial intelligence that could learn to differentiate between the two,
providing yet more value from the dataset. And all the while, my teammates – who’d been used to looking at a single book at a time – were amazed by the possibilities we’d uncovered for
training computers to do simple tasks while reading thousands at once.
The area around Old St. Paul’s Cathedral was the place to be if you were a 16th century hipster looking for a new book.
Elsewhere at the hackathon, one group was trying to simulate the view of the shelves of booksellers around the old St. Paul’s Cathedral, another looked at the change in the popularity
of colour and fashion-related words over the period (especially challenging towards the beginning of the timeline, where spelling of colours was less-standardised than towards the end),
and a third came up with ways to make old playscripts accessible to modern performers.
Aside from an increase in the relative frequency of the use of colour words to describe yellow things, there’s not much to say about this graph.
At the end of the session we presented our findings – by which I mean, Stephen explained what they meant – and talked about the technology and its potential future impact – by which I
mean, I said what we’d like to allow others to do with it, if they’re so-inclined. And I explained how I’d come to learn over the course of the day what the word encomium meant.
Presenting our findings in amazing technicolour Excel.
My personal favourite contribution from the event was by Sarah Cole, who adapted the text of a story about a witch
trial into a piece of interactive fiction, powered by Twine/Twee, and then
allowed us as an audience to collectively “play” her game. I love the idea of making old artefacts more-accessible to modern audiences through new media, and this was a fun and
innovative way to achieve this. You can even play her game
online!
(by the way: for those of you who enjoy my IF recommendations: have a
look at Detritus; it’s a delightful little experimental/experiential game)
Things are about to go very badly for Joan Buts.
But while that was clearly my favourite, the judges were far more impressed by the work of my teammate and I, as well as the team who’d adapted my software and used it to investigate
different features of the corpus, and decided to divide the cash price between the four of us. Which was especially awesome, because I hadn’t even realised that there was a
prize to be had, and I made the most of it at the Drinking About Museums event
I attended later in the day.
Cold hard cash! This’ll be useful at the bar, later!
If there’s a moral to take from all of this, it’s that you shouldn’t let your background limit your involvement in “hackathon”-like events. This event was geared towards literature,
history, linguistics, and the study of the book… but clearly there was value in me – a computer geek, first and foremost – being there. Similarly, a hack event I attended last year, while clearly tech-focussed, wouldn’t have
been as good as it was were it not for the diversity of the attendees, who included a good number of artists and entrepreneurs as well as the obligatory hackers.
“Nice work, Stephen.” “Nice work, Dan.”
But for me, I think the greatest lesson is that humanities researchers can benefit from thinking a little bit like computer scientists, once in a while. The code I wrote (which uses Ruby and Nokogiri) is freely
available for use and adaptation, and while I’ve no idea whether or not it’ll ever be useful to anybody again, what it represents is the research benefits of
inter-disciplinary collaboration. It pleases me to see things like the “Library Carpentry” (software for research, with a library slant) seeming to take off.