This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly diverged from its original/technical one. Read more evolving words…
Few words have seen such mutation of meaning over their lifetimes as the word “silly”. The earliest references, found in Old English, Proto-Germanic, and Old Norse and presumably having an original root even earlier, meant “happy”. By the end of the 12th century it meant “pious”; by the end of the 13th, “pitiable” or “weak”; only by the late 16th coming to mean “foolish”; its evolution continues in the present day.

But there’s little so silly as the media-driven evolution of the word “hacker” into something that’s at least a little offensive those of us who probably would be described as hackers. Let’s take a look.
Hacker
What people think it means
Computer criminal with access to either knowledge or tools which are (or should be) illegal.
What it originally meant
Expert, creative computer programmer; often politically inclined towards information transparency, egalitarianism, anti-authoritarianism, anarchy, and/or decentralisation of power.
The Past
The earliest recorded uses of the word “hack” had a meaning that is unchanged to this day: to chop or cut, as you might describe hacking down an unruly bramble. There are clear links between this and the contemporary definition, “to plod away at a repetitive task”. However, it’s less certain how the word came to be associated with the meaning it would come to take on in the computer labs of 1960s university campuses (the earliest references seem to come from around April 1955).
There, the word hacker came to describe computer experts who were developing a culture of:
- sharing computer resources and code (even to the extent, in extreme cases, breaking into systems to establish more equal opportunity of access),
- learning everything possible about humankind’s new digital frontiers (hacking to learn, not learning to hack)
- judging others only by their contributions and not by their claims or credentials, and
- discovering and advancing the limits of computers: it’s been said that the difference between a non-hacker and a hacker is that a non-hacker asks of a new gadget “what does it do?”, while a hacker asks “what can I make it do?”
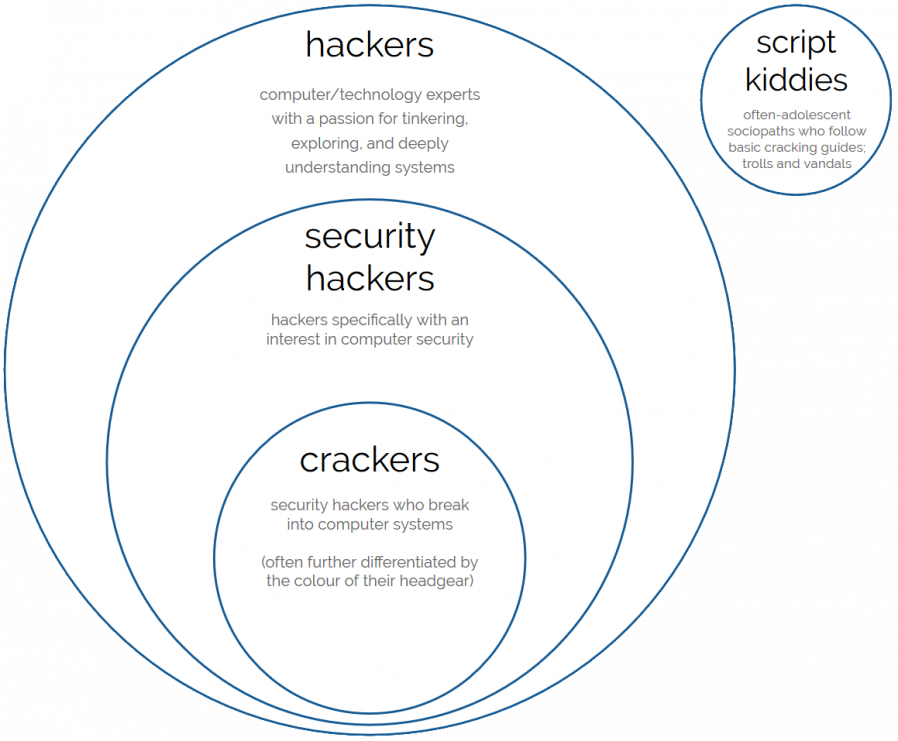
It is absolutely possible for hacking, then, to involve no lawbreaking whatsoever. Plenty of hacking involves writing (and sharing) code, reverse-engineering technology and systems you own or to which you have legitimate access, and pushing the boundaries of what’s possible in terms of software, art, and human-computer interaction. Even among hackers with a specific interest in computer security, there’s plenty of scope for the legal pursuit of their interests: penetration testing, security research, defensive security, auditing, vulnerability assessment, developer education… (I didn’t say cyberwarfare because 90% of its application is of questionable legality, but it is of course a big growth area.)
So what changed? Hackers got famous, and not for the best reasons. A big tipping point came in the early 1980s when hacking group The 414s broke into a number of high-profile computer systems, mostly by using the default password which had never been changed. The six teenagers responsible were arrested by the FBI but few were charged, and those that were were charged only with minor offences. This was at least in part because there weren’t yet solid laws under which to prosecute them but also because they were cooperative, apologetic, and for the most part hadn’t caused any real harm. Mostly they’d just been curious about what they could get access to, and were interested in exploring the systems to which they’d logged-in, and seeing how long they could remain there undetected. These remain common motivations for many hackers to this day.

News media though – after being excited by “hacker” ideas introduced by WarGames – rightly realised that a hacker with the same elementary resources as these teens but with malicious intent could cause significant real-world damage. Bruce Schneier argued last year that the danger of this may be higher today than ever before. The press ran news stories strongly associating the word “hacker” specifically with the focus on the illegal activities in which some hackers engage. The release of Neuromancer the following year, coupled with an increasing awareness of and organisation by hacker groups and a number of arrests on both sides of the Atlantic only fuelled things further. By the end of the decade it was essentially impossible for a layperson to see the word “hacker” in anything other than a negative light. Counter-arguments like The Conscience of a Hacker (Hacker’s Manifesto) didn’t reach remotely the same audiences: and even if they had, the points they made remain hard to sympathise with for those outside of hacker communities.

A lack of understanding about what hackers did and what motivated them made them seem mysterious and otherworldly. People came to make the same assumptions about hackers that they do about magicians – that their abilities are the result of being privy to tightly-guarded knowledge rather than years of practice – and this elevated them to a mythical level of threat. By the time that Kevin Mitnick was jailed in the mid-1990s, prosecutors were able to successfully persuade a judge that this “most dangerous hacker in the world” must be kept in solitary confinement and with no access to telephones to ensure that he couldn’t, for example, “start a nuclear war by whistling into a pay phone”. Yes, really.

The Future
Every decade’s hackers have debated whether or not the next decade’s have correctly interpreted their idea of “hacker ethics”. For me, Steven Levy’s tenets encompass them best:
- Access to computers – and anything which might teach you something about the way the world works – should be unlimited and total.
- All information should be free.
- Mistrust authority – promote decentralization.
- Hackers should be judged by their hacking, not bogus criteria such as degrees, age, race, or position.
- You can create art and beauty on a computer.
- Computers can change your life for the better.
Given these concepts as representative of hacker ethics, I’m convinced that hacking remains alive and well today. Hackers continue to be responsible for many of the coolest and most-important innovations in computing, and are likely to continue to do so. Unlike many other sciences, where progress over the ages has gradually pushed innovators away from backrooms and garages and into labs to take advantage of increasingly-precise generations of equipment, the tools of computer science are increasingly available to individuals. More than ever before, bedroom-based hackers are able to get started on their journey with nothing more than a basic laptop or desktop computer and a stack of freely-available open-source software and documentation. That progress may be threatened by the growth in popularity of easy-to-use (but highly locked-down) tablets and smartphones, but the barrier to entry is still low enough that most people can pass it, and the new generation of ultra-lightweight computers like the Raspberry Pi are doing their part to inspire the next generation of hackers, too.
That said, and as much as I personally love and identify with the term “hacker”, the hacker community has never been less in-need of this overarching label. The diverse variety of types of technologist nowadays coupled with the infiltration of pop culture by geek culture has inevitably diluted only to be replaced with a multitude of others each describing a narrow but understandable part of the hacker mindset. You can describe yourself today as a coder, gamer, maker, biohacker, upcycler, cracker, blogger, reverse-engineer, social engineer, unconferencer, or one of dozens of other terms that more-specifically ties you to your community. You’ll be understood and you’ll be elegantly sidestepping the implications of criminality associated with the word “hacker”.
The original meaning of “hacker” has also been soiled from within its community: its biggest and perhaps most-famous advocate‘s insistence upon linguistic prescriptivism came under fire just this year after he pushed for a dogmatic interpretation of the term “sexual assault” in spite of a victim’s experience. This seems to be absolutely representative of his general attitudes towards sex, consent, women, and appropriate professional relationships. Perhaps distancing ourselves from the old definition of the word “hacker” can go hand-in-hand with distancing ourselves from some of the toxicity in the field of computer science?
(I’m aware that I linked at the top of this blog post to the venerable but also-problematic Eric S. Raymond; if anybody can suggest an equivalent resource by another author I’d love to swap out the link.)
Verdict: The word “hacker” has become so broad in scope that we’ll never be able to rein it back in. It’s tainted by its associations with both criminality, on one side, and unpleasant individuals on the other, and it’s time to accept that the popular contemporary meaning has won. Let’s find new words to define ourselves, instead.
![[Animated GIF] Puppy flumps onto a human.](/_q23u/2019/09/cute-puppy.gif)