The tl;dr is: the court ruled that (a) piracy for the purpose of training an LLM is still piracy, so there’ll be a separate case about the fact that Anthropic did not pay for copies of
all the books their model ingested, but (b) training a model on books and then selling access to that model, which can then produce output based on what it has “learned” from those
books, is considered transformative work and therefore fair use.
Compelling arguments have been made both ways on this topic already, e.g.:
Some folks are very keen to point out that it’s totally permitted for humans to read, and even memorise, entire volumes, and then use what they’ve learned when they
produce new work. They argue that what an LLM “does” is not materially different from an impossibly well-read human.
By way of counterpoint, it’s been observed that such a human would still be personally liable if the “inspired” output they subsequently created was derivative
to the point of violating copyright, but we don’t yet have a strong legal model for assessing AI output in the same way. (BBC News article about Disney & Universal vs. Midjourney is going to be very interesting!)
Furthermore, it might be impossible to conclusively determine that the way GenAI works is fundamentally comparable to human thought. And that’s the thing that got
me thinking about this particular thought experiment.
A moment of philosophy
Here’s a thought experiment:
Support I trained an LLM on all of the books of just one author (plus enough additional language that it was able to meaningfully communicate). Let’s take Stephen King’s 65 novels and
200+ short stories, for example. We’ll sell access to the API we produce.
I suppose it’s possible that Stephen King was already replaced long ago with an AI that was instructed to churn out horror stories about folks in isolated Midwestern locales being
harassed by a pervasive background evil?
The output of this system would be heavily-biased by the limited input it’s been given: anybody familiar with King’s work would quickly spot that the AI’s mannerisms echoed his writing
style. Appropriately prompted – or just by chance – such a system would likely produce whole chapters of output that would certainly be considered to be a substantial infringement of
the original work, right?
If I make KingLLM, I’m going to get sued, rightly enough.
But if we accept that (and assume that the U.S. District Court for the Northern District of California would agree)… then this ruling on Anthropic would carry a curious implication.
That if enough content is ingested, the operation of the LLM in itself is no longer copyright infringement.
Which raises the question: where is the line? What size of corpus must a system be trained upon before its processing must necessarily be considered transformative
of its inputs?
Clearly, trying to answer that question leads to a variant of the sorites paradox. Nobody can ever say that, for example, an input of twenty million words
is enough to make a model transformative but just one fewer and it must be considered to be perpetually ripping off what little knowledge it has!
But as more of these copyright holder vs. AI company cases come to fruition, it’ll be interesting to see where courts fall. What is fair use and what is infringing?
And wherever the answers land, I’m sure there’ll be folks like me coming up with thought experiments that sit uncomfortably in the grey areas that remain.
A not-entirely-theoretical question about open source software licensing came up at work the other day. I thought it was interesting
enough to warrant a quick dive into the philosophy of minification, and how it relates to copyleft open source licenses. Specifically: does distributing (only) minified
source code violate the GPL?
If you’ve come here looking for a legally-justifiable answer to that question, you’re out of luck. But what I can give you is a (fictional) story:
TheseusJS is slow
TheseusJS is a (fictional) Javascript library designed to be run in a browser. It’s released under the GPLv3 license. This license allows you to download and use TheseusJS for any purpose you like, including making money off it, modifying
it, or redistributing it to others… but it requires that if you redistribute it you have to do so under the same license and include the source code. As such, it forces you to
share with others the same freedoms you enjoy for yourself, which is highly representative of some schools of open-source thinking.
It’s a cool project, but it really needs some maintenance this side of 2010.
It’s a great library and it’s used on many websites, but its performance isn’t great. It’s become infamous for the impact it has on the speed of the websites it’s used on, and it’s
often the butt of jokes by developers: “Man, this website’s slow. Must be running Theseus!”
The original developer has moved onto his new project, Moralia, and seems uninterested in handling the growing number of requests for improvements. So I’ve decided to fork it
and make my own version, FastTheseusJS and work on improving its speed.
FastTheseusJS is fast
I do some analysis and discover the single biggest problem with TheseusJS is that the Javascript file itself is enormous. The original developer kept all of the
copious documentation in comments in the file itself, and for some reason it doesn’t even compress well. When you use TheseusJS on a website it takes a painfully long time for
a browser to download it, if it’s not precached.
Nobody even uses the documentation in the comments: there’s a website with a fully-documented API.
My first release of FastTheseusJS, then, removes virtually of the comments, replacing them with a single comment at the top pointing developers to a website where the
API is fully documented. While I’m in there anyway, I also fix a minor bug that’s been annoying me for a while.
v1.1.0 changes
Forked from TheseusJS v1.0.4
Fixed issue #1071 (running mazeSolver() without first connecting <String> component results in endless loop)
Removed all comments: improves performance considerably
I discover another interesting fact: the developer of TheseusJS used a really random mixture of tabs and spaces for indentation, sometimes in the same line! It looks…
okay if you set your editor up just right, but it’s pretty hideous otherwise. That whitespace is unnecessary anyway: the codebase is sprawling but it seldom goes more than two
levels deep, so indentation levels don’t add much readability. For my second release of FastTheseusJS, then, I remove this extraneous whitespace, as well as removing
the in-line whitespace inside parameter lists and the components of for loops. Every little helps, right?
v1.1.1 changes
Standardised whitespace usage
Removed unnecessary whitespace
Some of the simpler functions now fit onto just a single line, and it doesn’t even inconvenience me to see them this way: I know the codebase well enough by now that it’s no
disadvantage for me to edit it in this condensed format.
Personally, I’ve given up on the tabs-vs-spaces debate and now I indent my code using semicolons. (That’s clearly a joke. Don’t flame me.)
In the next version, I shorten the names of variables and functions in the code.
For some reason, the original developer used epic rambling strings for function names, like the well-known function
dedicateIslandTempleToTheImageOfAGodBeforeOrAfterMakingASacrificeWithOrWithoutDancing( boolBeforeMakingASacrifice, objectImageOfGodToDedicateIslandTempleTo,
stringNmeOfPersonMakingDedication, stringOrNullNameOfLocalIslanderDancedWith). That one gets called all the time internally and isn’t exposed via the external
API so it might as well be shortened to d=(i,j,k,l,m)=>. Now all the internal workings of the library
are each represented with just one or two letters.
v1.1.2 changes
Shortened/standarised non-API variable and function names – improves performance
I’ve shaved several kilobytes off the monstrous size of TheseusJS and I’m very proud. The original developer says nice things about my fork on social media, resulting in a
torrent of downloads and attention. Within a certain archipelago of developers, I’m slightly famous.
But did I violate the license?
But then a developer says to me: you’re violating the license of the original project because you’re not making the source code available!
This happens every day. Probably not to this same guy every time though, but you never know. Original photo by Andrea Piacquadio.
They claim that my bugfix in the first version of FastTheseusJS represents a material change to the software, and that the changes I’ve made since then are
obfuscation: efforts short of binary compilation that aim to reduce the accessibility of the source code. This fails to meet the GPL‘s definition of source code as “the preferred form of the work for making modifications to
it”. I counter that this condensed view of the source code is my “preferred” way of working with it, and moreover that my output is not the result of some build step that
makes the code harder to read, the code is just hard to read as a result of the optimisations I’ve made. In ambiguous cases, whose “preference” wins?
Did I violate the license? My gut feeling is that no, all of my changes were within the spirit and the letter of the GPL (they’re a
terrible way to write code, but that’s not what’s in question here). Because I manually condensed the code, did so with the intention that this condensing was a feature, and
continue to work directly with the code after condensing it because I prefer it that way… that feels like it’s “okay”.
But if I’d just run the code through a minification tool, my opinion changes. Suppose I’d run minify --output fasttheseus.js theseus.js and then deleted my copy of
theseus.js. Then, making changes to fasttheseus.js and redistributing it feels like a violation to me… even if the resulting code is the same as I’d have
gotten via the “manual” method!
I don’t know the answer (IANAL), but I’ll tell you this: I feel hypocritical for saying one piece of code would not violate
the license but another identical piece of code would, based only on the process the developer followed to produce it. If I replace one piece of code at a time with
less-readable versions the license remains intact, but if I replace them all at once it doesn’t? That doesn’t feel concrete nor satisfying.
Sure, I can write a blog post in just one line of code. It’ll just be a really, really, really long line… (Still perfectly readable, though!)
This isn’t an entirely contrived example
This example might seem highly contrived, and that’s because it is. But the grey area between the extremes is where the real questions are. If you agree that redistribution of (only)
minified source code violates the GPL, you’re left asking: at what point does the change occur? Code isn’t necessarily minified or
not-minified: there are many intermediate steps.
If I use a correcting linter to standardise indentation and whitespace – switching multiple spaces for the appropriate number of tabs, removing excess line breaks etc. (or do the same
tasks manually) I’m sure you’d agree that’s fine. If I have it replace whole-function if-blocks with hoisted return statements, that’s probably fine too. If I replace if blocks with
ternery operators or remove or shorten comments… that might be fine, but probably depends upon context. At some point though, some way along the process, minification goes “too
far” and feels like it’s no longer within the limitations of the license. And I can’t tell you where that point is!
This issue’s even more-complicated with some other licenses, e.g. the AGPL, which extends the requirement to share source code to hosted applications. Suppose I implement a web application that uses an AGPL-licensed library. The person who redistributed it to me only gave me the minified version, but they gave me a web address from which
to acquire the full source code, so they’re in the clear. I need to make a small patch to the library to support my service, so I edit it right into the minified version I’ve already
got. A user of my hosted application asks for a copy of the source code, so I provide it, including the edited minified library… am I violating the license for not providing the full,
unminified version, even though I’ve never even seen it? It seems absurd to say that I would be, but it could still be argued to be the case.
I love diagrams like this, which show license compatibility of different open source licenses. Adapted from a diagram by Carlo Daffara,
in turn adapted from a diagram by David E. Wheeler, used under a CC-BY-SA license.
99% of the time, though, the answer’s clear, and the ambiguities shown above shouldn’t stop anybody from choosing to open-source their work
under GPL, AGPL (or any other open source license depending on their
preference and their community). Perhaps the question of whether minification violates the letter of a copyleft license is one of those Potter Stewart “I know it when I see it” things. It certainly goes against the spirit of the thing to do so deliberately or
unnecessarily, though, and perhaps it’s that softer, more-altruistic goal we should be aiming for.
Today we reinstated youtube-dl, a popular project on GitHub, after we received additional information about the project that enabled us to reverse a Digital
Millennium Copyright Act (DMCA) takedown.
…
This is a Big Deal. For two reasons:
Firstly, youtube-dl is a spectacularly useful project. I’ve used it for many years to help me archive my own content, to improve my access to content that’s freely
available on the platform, and to help centralise (freely available) metadata to keep my subscriptions on video-sharing sites. Others have even more-important uses for the tool. I love youtube-dl, and I’d never considered the possibility
that it could be used to circumvent digital restrictions (apparently it’s got some kind of geofence-evading features you can optionally enable, for people who don’t have a
multi-endpoint VPN I guess?… I note that it definitely doesn’t break DRM…) until its GitHub repo got taken down the other week.
Which was a bleeding stupid thing to use a DMCA request on, because, y’know: Barbara Streisand Effect. Lampshading that a free, open-source tool could be used for people’s convenience is likely to
increase awareness and adoption, not decrease it! Huge thanks to the EFF for
stepping up and telling GitHub that they’d got it wrong (this letter is
great reading, by the way).
But secondly, GitHub’s response is admirable and – assuming their honour their new stance –
effective. They acknowledge their mistake, then go on to set out a new process by which they’ll review takedown requests. That new process includes technical and legal review, erring on
the side of the developer rather than the claimant (i.e. “innocent until proven guilty”), multiparty negotiation, and limiting the scope of takedowns by allowing violators to export
their non-infringing content after the fact.
I was concerned that the youtube-dl takedown might create a FOSS “chilling effect” on GitHub. It still
might: in the light of it, I for one have started backing up my repositories and those of projects I care about to an different Git server! But with this response, I’d still be
confident hosting the main copy of an open-source project on GitHub, even if that project was one which was at risk of being mistaken for copyright violation.
Note that the original claim came not from Google/YouTube as you might have expected (if you’ve just tuned in) but from the RIAA, based on the fact that
youtube-dlcould be used to download copyrighted music videos for enjoyment offline. If you’re reminded of Sony v. Universal City Studios (1984) – the case behind the “Betamax standard” – you’re not
alone.
When I first started working at the Bodleian Libraries in 2011, their websites were looking… a little
dated. I’d soon spend some time working with a vendor (whose premises mysteriously caught fire while I was there, freeing me up to spend my
birthday in a bar) to develop a fresh, modern interface for our websites that, while not the be-all and end-all, was a huge leap forwards and has served us well for the last five years
or so.
The colour scheme, the layout, the fact that it didn’t remotely work on mobiles… there was a lot wrong with the old design of the Bodleian Libraries’ websites.
Fast-forward a little: in about 2015 we noticed a few strange anomalies in our Google Analytics data. For some reason, web addresses were appearing that didn’t exist anywhere on our
site! Most of these resulted from web visitors in Turkey, so we figured that some Turkish website had probably accidentally put our Google Analytics user ID number into their
code rather than their own. We filtered out the erroneous data – there wasn’t much of it; the other website was clearly significantly less-popular than ours – and carried on. Sometimes
we’d speculate about the identity of the other site, but mostly we didn’t even think about it.
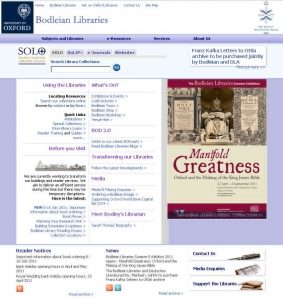
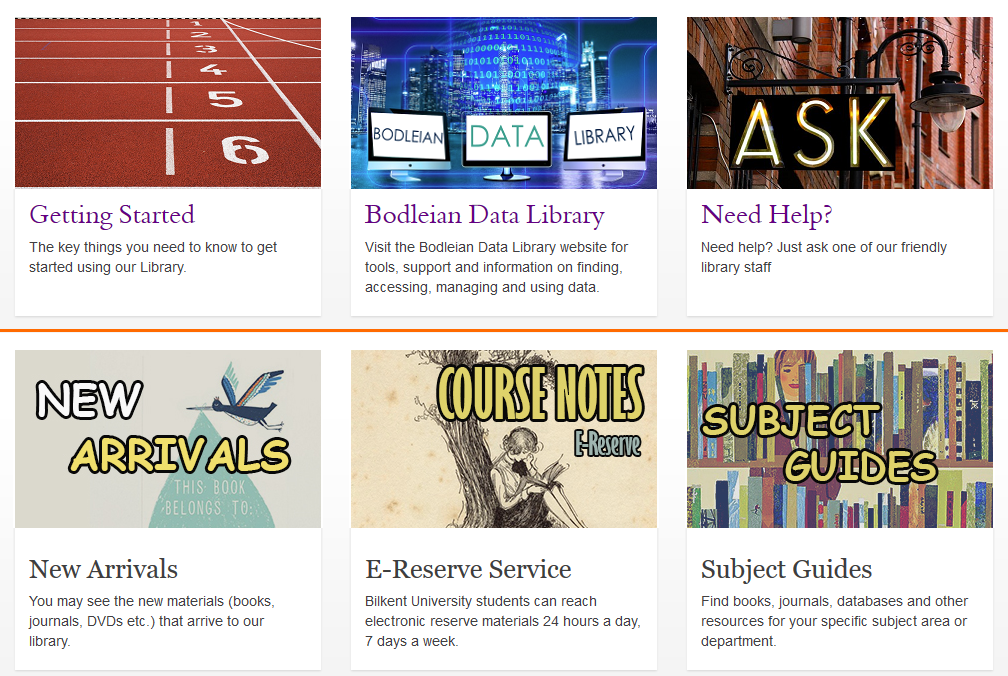
How a Bodleian Libraries’ website might appear today. Pay attention, now: there’ll be a spot-the-difference competition in a moment.
Earlier this year, there was a spike in the volume of the traffic we were having to filter-out, so I took the time to investigate more-thoroughly. I determined that the offending
website belonged to the Library of Bilkent University, Turkey. I figured that some junior web developer there must have copy-pasted the
Bodleian’s Google Analytics code and forgotten to change the user ID, so I went to the website to take a look… but I was in for an even bigger surprise.
Hey, that looks… basically identical!
Whoah! The web design of a British university was completely ripped-off by a Turkish university! Mouth agape at the audacity, I clicked my way through several of their pages to try to
understand what had happened. It seemed inconceivable that it could be a coincidence, but perhaps it was supposed to be more of an homage than a copy-paste job? Or perhaps they
were ripped-off by an unscrupulous web designer? Or maybe it was somebody on the “inside”, like our vendor, acting unethically by re-selling the same custom design? I didn’t believe it
could be any of those things, but I had to be sure. So I started digging…
Our user research did indicate that putting the site and catalogue search tools like this was smart. Maybe they did the same research?
Menus are pretty common on many websites. They probably just had a similar idea.
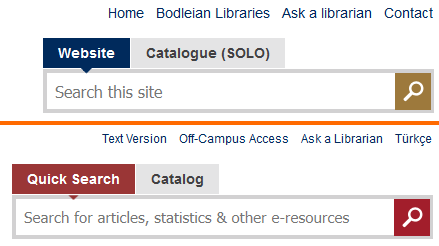
Tabs are a great way to show opening hours. Everybody knows that. And this is obviously just the a popular font.
Oh, you’ve got a slider too. With circles? And you’ve got an identical Javascript bug? Okay… now that’s a bit of a coincidence…
Okay, I’m getting a mite suspicious now. Surely we didn’t independently come up with this particular bit of design?
Well these are clearly different. Ours has a copyright notice, for example…
Oh, you DO have a copyright notice. Hang on, wait: you’ve not only stolen our design but you’ve declared it to be open-source???
I was almost flattered as I played this spot-the-difference competition, until I saw the copyright notice: stealing our design was galling enough, but then relicensing it in such a way
that they specifically encourage others to steal it too was another step entirely. Remember that we’re talking about an academic library, here: if anybody ought to
have a handle on copyright law then it’s a library!
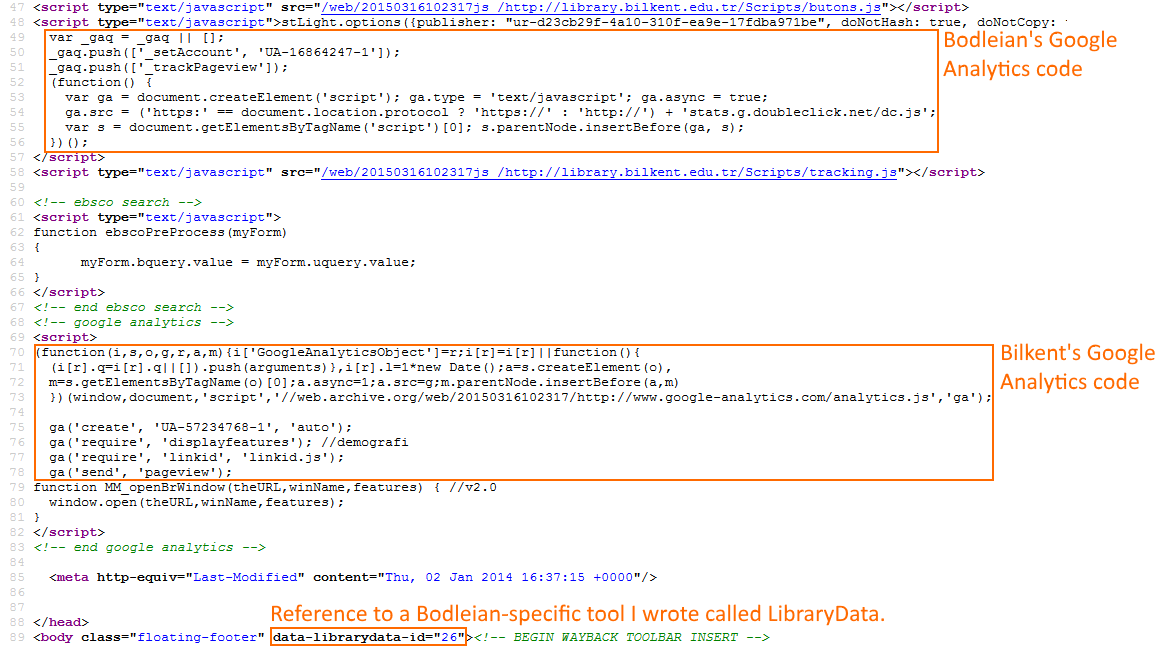
I took a dive into the source code to see if this really was, as it appeared to be, a copy-paste-and-change-the-name job (rather than “merely” a rip-off of the entire graphic design),
and, sure enough…
In their HTML source code, you can see both the Bodleian’s Google Analytics code (which they failed to remove) but also their own. And a data- attribute related to a project I wrote
and that means nothing to their site.
It looks like they’d just mirrored the site and done a search-and-replace for “Bodleian”, replacing it with “Bilkent”. Even the code’s spelling errors, comments, and indentation were
intact. The CSS was especially telling (as well as being chock-full of redundant code relating to things that appear on our website but not on theirs)…
The search-replace resulted in some icky grammar, like “the Bilkent” appearing in their code. And what’s this? That’s MY NAME in the middle of their source code!
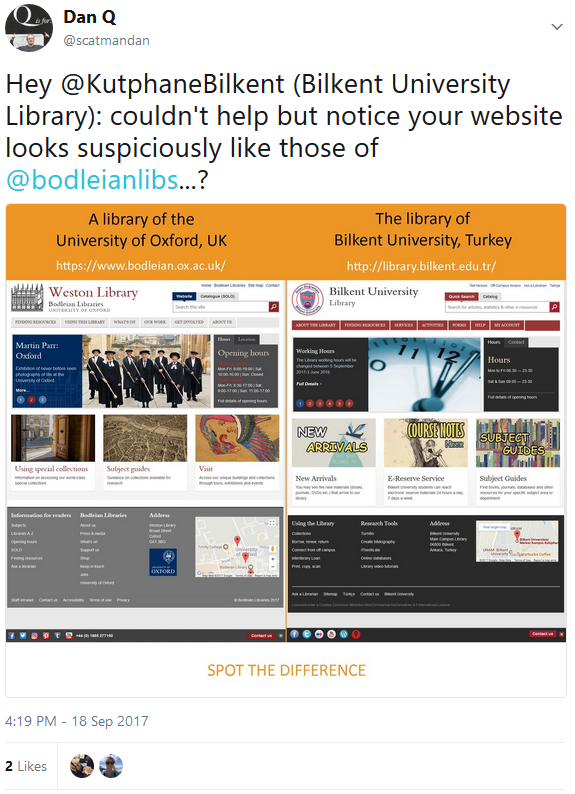
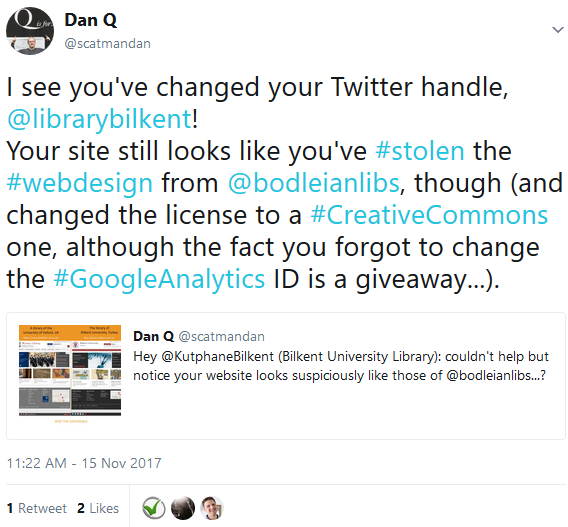
So I reached out to them with a tweet:
My first tweet to Bilkent University Library contained a “spot the difference” competition.
I didn’t get any response, although I did attract a handful of Turkish followers on Twitter. Later, they changed their Twitter handle and I thought I’d take advantage of the then-new
capability for longer tweets to have another go at getting their attention:
This time, I was a little less-sarcastic and a little more-aggressive. Turns out that’s all that was needed.
Clearly this was what it took to make the difference. I received an email from the personal email account of somebody claiming to be Taner
Korkmaz, Systems Librarian with Bilkent’s Technical Services team. He wrote (emphasis mine):
Dear Mr. Dan Q,
My name is Taner Korkmaz and I am the systems librarian at Bilkent. I am writing on behalf of Bilkent University Library, regarding your share about Bilkent on
your Twitter account.
Firstly, I would like to explain that there is no any relation between your tweet and our library Twitter handle change. The librarian who is Twitter admin at Bilkent did not notice
your first tweet. Another librarian took this job and decided to change the twitter handle because of the Turkish letters, abbreviations, English name requirement etc. The first name
was @KutphaneBilkent (kutuphane means library in Turkish) which is not clear and not easy to understand. Now, it is @LibraryBilkent.
About 4 years ago, we decided to change our library website, (and therefore) we reviewed the appearance and utility of the web pages.
We appreciated the simplicity and clarity of the user interface of University of Oxford Bodlien Library & Radcliffe Camera, as an academic pioneer in many fields. As a not profit institution, we took advantage of your template by using CSS and HTML, and added our own original content.
We thought it would not create a problem the idea of using CSS codes since on the web page there isn’t any license notice or any restriction related to
the content of the template, and since the licenses on the web pages are mainly more about content rather than templates.
The Library has its own Google Analytics and Search Console accounts and the related integrations for the web site statistical data tracking. We would like to point out that there is
a misunderstanding regarding this issue.
In 2017, we started to work on creating a new web page and we will renew our current web page very soon.
Thank you in advance for your attention to this matter and apologies for possible inconveniences.
Yours sincerely,
Or to put it another way: they decided that our copyright notice only applied to our content and not our design and took a copy of the latter.
Do you remember when I pointed out earlier that librarians should be expected to know their way around copyright law? Sigh.
They’ve now started removing evidence of their copy-pasting such as the duplicate Google Analytics code fragment and the references to LibraryData, but you can still find the unmodified
code via archive.org, if you like.
That probably ends my part in this little adventure, but I’ve passed everything on to the University of Oxford’s legal team in case any of them have anything to say about it. And now
I’ve got a new story to tell where web developers get together over a pint: the story of the time that I made a website for a university… and a different university stole it!