Some days… you’re just so dog-tired you can’t even find the energy to pull your head into your basket with the rest of you.

This Twelfth of Bleptember’s a bit like that for me, too. I feel you, dog.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Some days… you’re just so dog-tired you can’t even find the energy to pull your head into your basket with the rest of you.
This Twelfth of Bleptember’s a bit like that for me, too. I feel you, dog.
Dungeons & Dragons players spend a lot of time rolling 20-sided polyhedral dice, known as D20s.
In general, they’re looking to roll as high as possible to successfully stab a wyvern, jump a chasm, pick a lock, charm a Duke1, or whatever.

Sometimes, a player gets to roll with advantage. In this case, the player rolls two dice, and takes the higher roll. This really boosts their chances of not-getting a low roll. Do you know by how much?
I dreamed about this very question last night. And then, still in my dream, I came up with the answer2. I woke up thinking about it3 and checked my working.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 2 | 2 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 3 | 3 | 3 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 4 | 4 | 4 | 4 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 5 | 5 | 5 | 5 | 5 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 6 | 6 | 6 | 6 | 6 | 6 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 16 | 17 | 18 | 19 | 20 |
| 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 17 | 18 | 19 | 20 |
| 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 18 | 19 | 20 |
| 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 19 | 20 |
| 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 20 |
| 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
The chance of getting a “natural 1” result on a D20 is 1 in 20… but when you roll with advantage, that goes down to 1 in 400: a huge improvement! The chance of rolling a 10 or 11 (2 in 20 chance of one or the other) remains the same. And the chance of a “crit” – 20 – goes up from 1 in 20 when rolling a single D20 to 39 in 400 – almost 10% – when rolling with advantage.
You can see that in the table above: the headers along the top and left are the natural rolls, the intersections are the resulting values – the higher of the two.
The nice thing about the table above (which again: was how I visualised the question in my dream!) is it really helps to visualise why these numbers are what they are. The general formula for calculating the chance of a given number when rolling D20 with advantage is ( n2 – (n-1)2 ) / 400. That is, the square of the number you’re looking for, minus the square of the number one less than that, over 400 (the total number of permutations)4.
Knowing the probability matrix, it’s theoretically possible to construct a “D20 with Advantage” die5. Such a tool would have 400 sides (one 1, three 2s, five 3s… and thirty-nine 20s). Rolling-with-advantage would be a single roll.

This is probably a totally academic exercise. The only conceivable reason I can think of would be if you were implementing a computer system on which generating random numbers was computationally-expensive, but memory was cheap: under this circumstance, you could pre-generate a 400-item array of possible results and randomly select from it.
But if anybody’s got a 3D printer capable of making a large tetrahectogon (yes, that’s what you call a 400-sided polygon – you learned something today!), I’d love to see an “Advantage D20” in the flesh. Or if you’d just like to implement a 3D model for Dice Box that’d be fine too!
1 Or throw a fireball, recall an anecdote, navigate a rainforest, survive a poisoning, sneak past a troll, swim through a magical swamp, hold on to a speeding aurochs, disarm a tripwire, fire a crossbow, mix a potion, appeal to one among a pantheon of gods, beat the inn’s landlord at an arm-wrestling match, seduce a duergar guard, persuade a talking squirrel to spy on some bandits, hold open a heavy door, determine the nature of a curse, follow a trail of blood, find a long-lost tome, win a drinking competition, pickpocket a sleeping ogre, bury a magic sword so deep that nobody will ever find it, pilot a spacefaring rowboat, interpret a forgotten language, notice an imminent ambush, telepathically commune with a distant friend, accurately copy-out an ancient manuscript, perform a religious ritual, find the secret button under the wizard’s desk, survive the blistering cold, entertain a gang of street urchins, push through a force field, resist mind control, and then compose a ballad celebrating your adventure.
2 I don’t know what it says about me as a human being that sometimes I dream in mathematics, but it perhaps shouldn’t be surprising given I’m nerdy enough to have previously recorded instances of dreaming in (a) Perl, and (b) Nethack (terminal mode).
3 When I woke up I also found that I had One Jump from Disney’s Aladdin stuck in my head, but I’m not sure that’s relevant to the discussion of probability; however, it might still be a reasonable indicator of my mental state in general.
4 An alternative formula which is easier to read but harder to explain would be ( 2(n – 1) + 1 ) / 400.
5 Or a “D20 with Disadvantage”: the table’s basically the inverse of the advantage one – i.e. 1 in 400 chance of a 20 through to 39 in 400 chance of a 1.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Maintaining a blog can be a lot of work. A single article can take weeks of research, drafting and editing, collecting and producing included materials, etc. It’s not unusual to seek some form of compensation for it, and those rewards require initiative. With a good monetization strategy, it can become a fairly lucrative venture.
So let’s talk about monetizing a blog, starting with the most obvious and perhaps easiest avenue: display advertising.
A content creator with an established audience can leverage that audience and sell ad space on their blog. Here’s an example:

…
I’m not sure I have words for how awesome this blog post is. If you’ve ever wanted to monetise your blog and are considering an ad-driven model, this should absolutely be the first (and perhaps last) thing you read on the subject.
If you’re not convinced that Tyler is an appropriate authority to speak on this subject, I highly suggest you visit their other site that’s got a wealth of useful tips, PutAToothpickInTheChargingPortDoctorsHateThatShit.christmas. Yes, really.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Such poise! Such grace! While out for a run around with her doggy pals this Eleventh of Bleptember, our dog takes every opportunity to show off her elegance and style and definitely not just look like a derpy little wazzock.

Photo courtesy Lisa from Muddy Paws.
According to news media: today, a billionaire is being taken into space, where the crew will open the rocket door and put him outside.

This seems like a great start, and I hope that the remaining 1,780+ billionaires left here on earth will be following suit soon.
Why don’t I like pickled onion crisps?
I like pickled onions. And I imagine that the flavourings used in pickled onion crisps are basically the onion flavouring from cheese & onion and the vinegar flavouring from salt & vinegar, both of which are varieties I like.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
Perhaps inspired by my resharing of Thomas‘s thoughts about the biggest problem in AI (tl;dr: he thinks it’s nomenclature; I agree that’s a problem but I don’t know if it’s the biggest issue), Ruth posted some thoughts to LinkedIn that I think are quite well-put:
I was going to write about something else but since LinkedIn suggested I should get AI to do it for me, here’s where I currently stand on GenAI.
As a person working in computing, I view it as a tool that is being treated as a silver bullet and is probably self-limiting in its current form. By design, it produces average code. Most companies prior to having access to cheap average code would have said they wanted good code. Since the average code produced by the tools is being fed back into those tools, mathematically this can’t lead anywhere good in terms of quality.
However, as a manager in tech I’m really alarmed by it. If we have tools to write code that is ok but needs a lot of double checking, we might be tempted to stop hiring people at that level. There already aren’t enough jobs for entry level programmers to feed the talent pipeline, and this is likely to make it worse. I’m not sure where the next generation of great programmers are supposed to come from if we move to an ecosystem where the junior roles are replaced by Copilot.
I think there’s a lot of potential for targeted tools to speed up productivity. I just don’t think GenAI is where they should come from.
This is an excellent explanation of no fewer than four of the big problems with “AI” as we’re seeing it marketed today:
Let’s stop and take a deeper look at the “mediocre output” claim. Ruth’s right, but if you don’t already understand why generative AI does this, it’s worth a little bit of consideration about the reason for it… and the consequences of it:
Mathematically-speaking, that’s exactly what you would expect for something that is literally statistically averaging content, but that still comes as a surprise to people.
Bear in mind, of course, that there are plenty of topics in which the average person is less-knowledgable than the average of the content that was made available to the model. For example, I know next to noting about fertiliser application in large-scale agriculture. ChatGPT has doubtless ingested a lot of literature about it, and if I ask it what fertiliser I should use for a field of black beans in silty soil in the UK, it delivers me a confident-sounding answer:

When LLMs produce exceptional output (I use the term exceptional in the sense of unusual and not-average, not to mean “good”), it appears more-creative and interesting but is even more-likely to be riddled with fanciful hallucinations.
There’s a fine line in getting the creativity dial set just right, and even when you do there’s no guarantee of accuracy, but the way in which many chatbots are told to talk makes them sound authoritative on basically every subject. When you know it’s lying, that’s easy. But people don’t always use LLMs for subjects they’re knowledgeable about!

In my example above, a more-useful robot would have stated that it didn’t know the answer to the question rather than, y’know, lying. But the nature of the statistical models used by LLMs means that they can’t know what they don’t know: they don’t have a “known unknowns” space.
Regarding the “damages the training pipeline”: I’m undecided on whether or not I agree with Ruth. She might be on to something there, but I’m not sure. Needs more thought before I commit to an opinion on that one.
Oh, and an addendum to this – as a human, I find the proliferation of AI tools in spaces that are all about creating connections with other humans deeply concerning. I saw a lot of job applications through Otta at my previous role, and they were all kind of the same – I had no sense of the person behind the averaged out CV I was looking at. We already have a huge problem with people presenting inauthentic versions of themselves on social media which makes it harder to have genuine interactions, smoothing off the rough edges of real people to get something glossy and processed is only going to make this worse.
AI posts on social media are the chicken nuggets of human interaction and I’d rather have something real every time.
Emphasis mine… because that’s a fantastic metaphor. Content generated where a generative AI is trying to “look human” are so-often bland, flat, and unexciting: a mass-produced most-basic form of social sustenance. So yeah: chicken nuggets.

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
How is it the Tenth of Bleptember already? This young lady has so-far put off her morning nap and is instead intently watching me to see what I do next with my workday. Maybe it’ll involve dog treats! (Spoiler: it probably won’t. But you never know…)

This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
The biggest problem with “AI” is probably that it’s used as label for two completely different things:
1. Specialized neural networks trained to do highly specific tasks (e.g. cancer screening) which often work reasonably well as a tool to support human experts
2. Generative AI which thoroughly produces the most mid bullshit
It doesn’t help that neither are intelligent in any way, they’re both statistical pattern matching.
Fundamentally, Thomas seems to be arguing that the biggest problem with AI is how it is marketed, or things-that-are-called-AI are marketed as AI. Also that LLMs, by producing s statistical average of their input data, produce output that’s pretty-average (which is, of course, statistically that you’d expect)1.
I’m not sure he’s right: the energy footprint and the copyright issues of generative AI might be the biggest problems. But maybe.
1 That’s not entirely true, of course: sometimes they produce output that’s wild and random, but we describe those as “hallucinations” and for many purposes they’re even worse. At least “mid bullshit” can be useful if you’re specifically looking to summarise existing content (and don’t mind fact-checking it later if it’s important): y’know, the thing people use Wikipedia for.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Happy Ninth of Bleptember! Today’s picture of our bleppy pupper comes from the rug near the front door. It’s certainly not as comfortable as her basket or bed, but it affords an excellent view of the comings-and-goings of the house. She flops down here, like a pancake, when she wants to be able to audit who’s in and who’s out at any given time (her dorky tongue hanging out all the while).

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
Rainy Sundays like this Eighth of Bleptember are for bleppy cuddles on the sofa, not for running around outside.

This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
There’s a squirrel over there and it Can’t. Be. Trusted. Demmy tries to explain her logic regarding the little furry tree-dwellers on a morning walk this Seventh of Bleptember.

This evening, I’m reduced to re-alcoholising my alcohol-free beer. Unfortunately the cleanest-tasting vodka I have is “only” 40% ABV, so by adding enough of it to bring the beer back to its correct ABV… I’m technically watering-down the beer.

This might be the strangest cocktail I’ve ever made.
This post is part of 🐶 Bleptember, a month-long celebration of our dog's inability to keep her tongue inside her mouth.
A wet and grey school run this Sixth of Bleptember isn’t enough to take the spirit of adventure out of this dog. But neither will it encourage her to put her tongue away.

I’m a big fan of blocking out uninterrupted time on your work calendar for focus activities, even if you don’t have a specific focus task to fill them with.
It can be enough to simple know that, for example, you’ve got a 2-hour slot every Friday morning that you can dedicate to whatever focus-demanding task you’ve got that week, whether it’s a deep debugging session, self-guided training and development activities, or finally finishing that paper that’s just slightly lower priority than everything else on your plate.
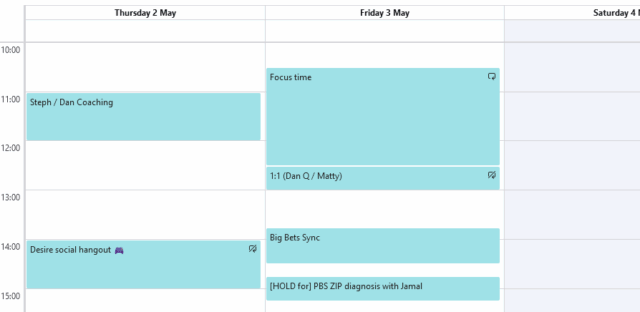
I appreciate that my colleagues respect that blocked period: I almost never receive meeting requests in that time. That’s probably because most people, particularly because we’re in such a multi-timezone company, use their calendar’s “find a suitable time for everybody” tool to find the best time for everyone and it sees that I’m “busy” and doesn’t suggest it.
If somebody does schedule a meeting that clashes with that block then, well, it’s probably pretty urgent!
But it turns out this strategy doesn’t work for everybody:
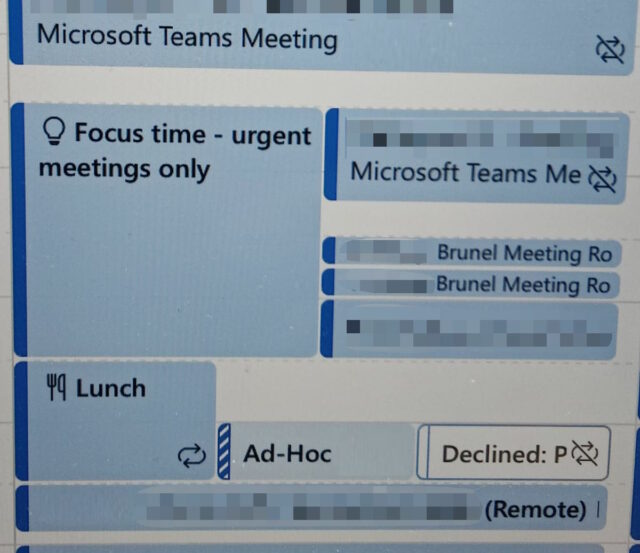
My partner recently showed me a portion of her calendar, observing that her scheduled focus time had been overshadowed by four subsequently-created meetings that clashed with it. Four!
Maybe that’s an exception and this particular occasion really did call for a stack of back-to-back urgent meetings. Maybe everything was on fire. But whether or not this particular occasion is representative for my partner, I’ve spoken to other friends who express the same experience: if they block out explicit non-meeting time on their calendar, they get meeting requests for that time anyway. At many employers, “focus time” activities don’t seem to be widely-respected.
Maybe your workplace is the same. The correct solution probably involves a cultural shift: a company-wide declaration in favour of focus time as a valuable productivity tool (which it is), possibly coupled with recommendations about how to schedule them sensitively, e.g. perhaps recommending a couple of periods in which they ought to be scheduled.
But for a moment, let’s consider a different option:
Does your work culture doesn’t respect scheduled focus time but does respect scheduled meetings? This might seem to be the case in the picture above: note that the meetings that clash with the focus time don’t clash with one another but tessellate nicely. Perhaps you need… fake meetings.

Of course, creating fake meetings just so you can get some work done is actually creating more work. Wouldn’t it be better if there were some kind of service that could do it for you?
Here’s the idea: a web service that exposes an API endpoint. You start by specifying a few things about the calendar you’d like to fill, for example:
This results in a URL containing those parameters. Accessing that URL yields an iCalendar feed containing those meetings. All you need to do is get your calendar software to subscribe to those events and they’ll appear in your calendar, “filling” your time.
So long as your iCalendar feed subscription refreshes often enough, you could even have an option to enable the events to self-delete e.g. 15 minutes before their start time, so that you don’t panic when your meeting notification pops up right before they “start”!
Normally, you’d expect me to pull the covers off some hilarious domain name I’ve chosen and reveal exactly the service I describe, but I’m not doing that today. There’s a few reasons for that:

So yeah: I’m not going down that avenue.
But maybe if you’re in a field where you’d benefit from it, try blocking out some focus time in your calendar. I think it’s a fantastic idea, and I love that I’m employed somewhere that I can do so and it works out.
Or if you’ve tried that and discovered that your workplace culture doesn’t respect it – if colleagues routinely book meetings into reserved spaces – maybe you should try fake meetings and see if they’re any better-respected. But I’m afraid I can’t help you with that.
1 Consider, for example, how I’m trying to take a photo of my dog, with her tongue stuck out, every day of this month.