I’ve been working in Milton Keynes the tail end of this week while my kids attend a ski camp at the X-scape centre. While eating my lunch today I came out for a walk to find this
geocache.
Approaching from the direction of the car park was definitely the right route and I was soon standing at GZ alongside a likely host. I had to search for some time, though, before I
found this surprisingly we’ll-concealed cache.
(I was hindered perhaps by my own eagerness to check the hint, which left me searching several feet lower down than the container eventually turned out to be!)
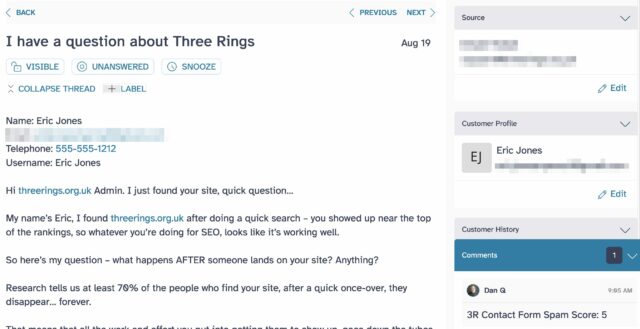
Three Rings operates a Web contact form to help people get in touch with us: the idea
is that it provides a quick and easy way to reach out if you’re a charity who might be able to make use of the system, a user who’s having difficulty with the features of the software,
or maybe a potential new volunteer willing to give your time to the project.
But then the volume of spam it received increased dramatically. We don’t want our support team volunteers to spend all
their time categorising spam: even if it doesn’t take long, it’s demoralising. So what could we do?
It’s clearly spam, but if it takes you 2 seconds to categorise it and there are 30 in your Inbox, that’s still a drag.
Our conventional antispam tools are configured pretty liberally: we don’t want to reject a contact from a legitimate user just because their message hits lots of scammy keywords (e.g.
if a user’s having difficulty logging in and has copy-pasted all of the error messages they received, that can look a lot like a password reset spoofing scam to a spam filter). And we
don’t want to add a CAPTCHA, because not only do those create a barrier to humans – while not necessarily reducing spam very much, nowadays – they’re often terrible for accessibility,
privacy, or both.
But it didn’t take much analysis to spot some patterns unique to our contact form and the questions it asks that might provide an opportunity. For example, we discovered that
spam messages would more-often-than-average:
Fill in both the “name” and (optional) “Three Rings username” field with the same value. While it’s cetainly possible for Three Rings users to have
a login username that’s identical to their name, it’s very rare. But automated form-fillers seem to disproportionately pair-up these two fields.
Fill the phone number field with a known-fake phone number or a non-internationalised phone number from a country in which we currently support no charities.
Legitimate non-UK contacts tend to put international-format phone numbers into this optional field, if they fill it at all. Spammers often put NANP (North American Numbering Plan)
numbers.
Include many links in the body of the message. A few links, especially if they’re to our services (e.g. when people are asking for help) is not-uncommon in legitimate
messages. Many links, few of which point to our servers, almost certainly means spam.
Choose the first option for the choose -one question “how can we help you?” Of course real humans sometimes pick this option too, but spammers almost always
choose it.
None of these characteristics alone, or any of the half dozen or so others we analysed (including invisible checks like honeypots and IP-based geofencing), are reason to
suspect a message of being spam. But taken together, they’re almost a sure thing.
To begin with, we assigned scores to each characteristic and automated the tagging of messages in our ticketing system with these scores. At this point, we didn’t do anything to block
such messages: we were just collecting data. Over time, this allowed us to find a safe “threshold” score above which a message was certainly spam.
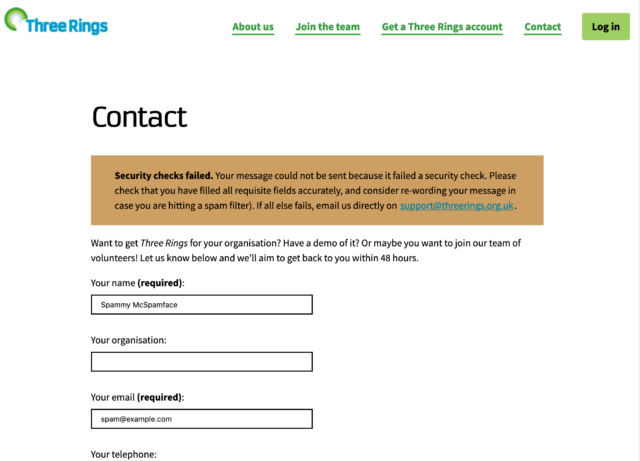
Even when a message fails our customised spam checks, we only ‘soft-block’ it: telling the user their message was rejected and providing suggestions on working around that or emailing
us conventionally. Our experience shows that the spammers aren’t willing to work to overcome this additional hurdle, but on the very rare ocassion a human hits them, they are.
Once we’d found our threshold we were able to engage a soft-block of submissions that exceeded it, and immediately the volume of spam making it to the ticketing system dropped
considerably. Under 70 lines of PHP code (which sadly I can’t share with you) and we reduced our spam rate by over 80% while having, as far as we can see, no impact on the
false-positive rate.
Where conventional antispam solutions weren’t quite cutting it, implementing a few rules specific to our particular use-case made all the difference. Sometimes you’ve just got to roll
your sleeves up and look at the actual data you do/don’t want, and adapt your filters accordingly.