Will Microsoft’s decision make it harder for Firefox to prosper? It could. Making Google more powerful is risky on many fronts. […] If one product like Chromium has enough market
share, then it becomes easier for web developers and businesses to decide not to worry if their services and sites work with anything other than Chromium. That’s what happened when
Microsoft had a monopoly on browsers in the early 2000s before Firefox was released. And it could happen again.
Before you lament the return to a Microsoft-like monopoly, remember what happened to Microsoft’s monopoly. In fact, remember what happened to the lineal descendant of that monopoly
just last week. Near-monopolies do not necessarily mean the end of the web.
…
Yet more in the “EdgeHTML to be replaced by Chromium” story, on which I already shared my opinions. Peter-Paul does a good job of illustrating
the differences between the reduction of diversity in/increasing monopolisation of the browser space this time around and last time (when Internet Explorer 6 became
the de facto standard way to surf the Web), using it to provide a slightly less-pessimistic outlook (albeit one not without its warnings).
Click through for the full review. I’ve always loved me some Oh Joy Sex Toy, but I’ve rarely been inclined to buy
something off the back of one of Erika’s recommendations until now.
Visited GZ as part of maintenance; all well here, although the “obvious” path to the cache continues to become increasingly overgrown – a fallen tree in the way almost but not quite
justifies putting the terrain rating up half a point.
Two bicycles seem to have been abandoned near the GZ. One belongs to hire scheme Ofo and has been reported to them. Making a note here so that if one or both are seen to still
be there in the New Year they can be reported as having been “abandoned for several weeks” as per council recommendations:
https://www.oxford.gov.uk/info/20060/street_cleaning/168/report_an_abandoned_bicycle
Cache container and contents remain in perfect condition. Go find it!
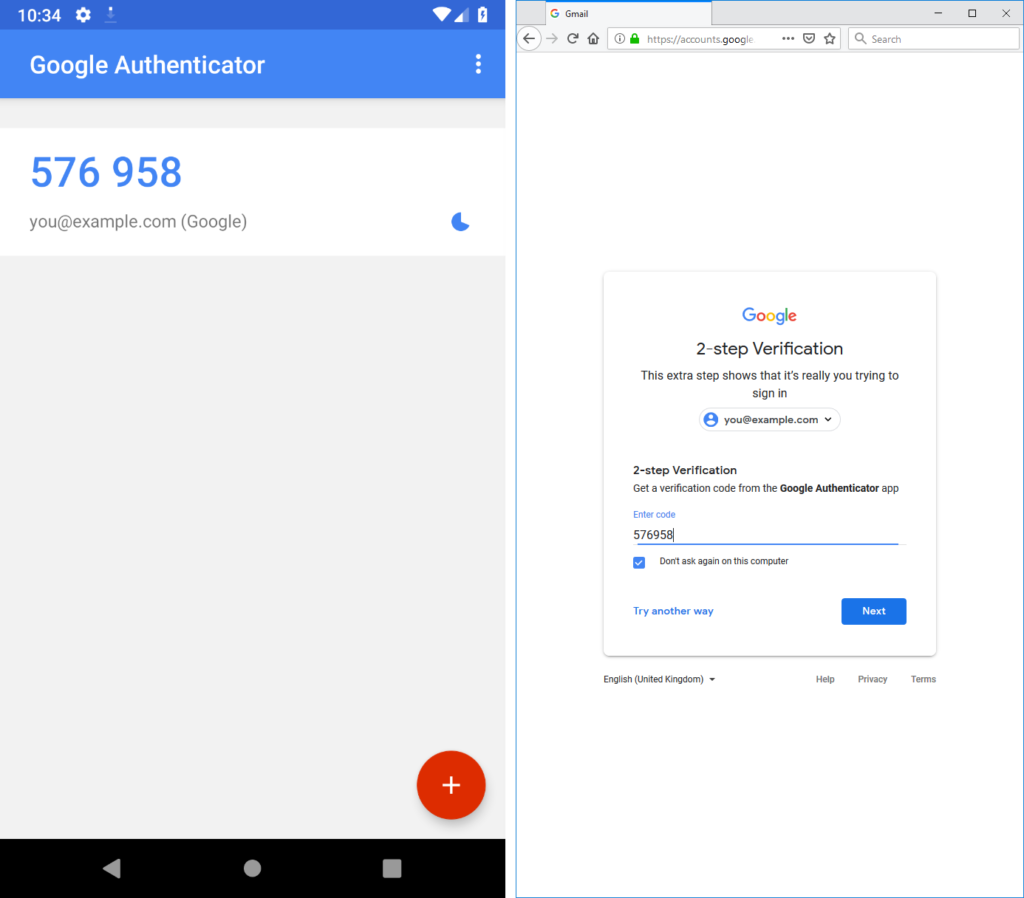
I’m a huge fan of multifactor authentication. If you’re using it, you’re probably familiar with using an app on your phone (or receiving a text or email) in addition to a username and
password when logging in to a service like your email, social network, or a bank. If you’re not using it then, well, you should be.
Using an app in addition to your username and password, wherever you can, may be the single biggest step you can make to improving your personal digital security.
Ruth recently had a problem when she lost her phone and couldn’t connect to a service for which she usually used an authenticator app like the
one pictured above, so I thought I’d share with you my personal strategy for managing multifactor authentication, in case it’s of any use to anybody else. After all: the issue of
not-having-the-right-second-factor-to-hand has happened to me before, it’s certainly now happened to Ruth, and it’s probably
something that’s happened to other people I know by now, too.
It could happen to anybody. What’s your authentication plan?
Here’s my strategy:
Favour fewer different multifactor solutions. Instead of using e.g. text messaging for one, an app for another, a different app for a third, a hardware token
for a fourth, and so on, try to find the fewest number of different solutions that work for your personal digital life. This makes backing up and maintenance easier.
I use RFC6238/TOTP (better known as “Google Authenticator”) for
almost all second factor purposes: the only exceptions are my online bank (who use a proprietary variant of RFC6238 that I’ve not finished reverse-engineering) and Steam (who use a
proprietary implementation of RFC6238 with a larger character set, for some reason, in their Steam Guard app).
Have a backup plan. Here’s the important bit. If you use your phone to authenticate, and you lose access to your phone for a period of time (broken, lost, stolen, out
of battery, in use by a small child playing a game), you can’t authenticate. That’s why it’s important that you have a backup plan.
That’s probably more backup devices than you need, but YMMV.
Some suggested backup strategies to consider (slightly biased towards TOTP):
Multiple devices: (Assuming you’re using TOTP or something like it) there’s nothing to stop you
setting up multiple devices to access the same account. Depending on how the service you’re accessing provides the code you need to set it up, you might feel like you have to
set them all up at the same time, but that’s not strictly true: there’s another way…
Consider setting up a backdoor: Some systems will allow you to print e.g. a set of “backup codes” and store them in a safe place for later use should you lose access
to your second factor. Depending on the other strategies you employ, you should consider doing this: for most (normal) people, this could be the single safest way to retain access to
your account in the event that you lose access to your second factor. Either way, you should understand the backdoors available: if your online bank’s policy is to email you
replacement credentials on-demand then your online bank account’s security is only as good as your email account’s security: follow the chain to work out where the weak links are.
Retain a copy of the code: The code you’re given to configure your device remains valid forever: indeed, the way that it works is that the
service provider retains a copy of the same code so they can generate numbers at the same time as you, and thus check that you’re generating the same numbers as them. If you keep a
copy of the backup code (somewhere very safe!) you can set up any device you want, whenever you want. Personally, I keep copies of all TOTP configuration codes in my password safe (you’re using a password safe, right?).
Set up the infrastructure what works for you: To maximise my logging-on convenience, I have my password safe enter my TOTP numbers for me: I’m using KeeOTP for KeePass, but since 2016 LastPass users can do basically the
same thing. I’ve also implemented my own TOTP client in Ruby to run on desktop computers I control (just be careful to protect the secrets file), because sometimes you just want a
command-line solution. The code’s below, and I think you’ll agree that it’s simple enough that you can audit it for your own safety too.
I’ve occasionally been asked whether my approach actually yields me any of the benefits of two-factor authentication. After all, people say, aren’t I weakening its benefits by storing
the TOTP generation key in the same place as my usernames and passwords rather than restricting it to my mobile
device. This is true, and it is weaker to do this than to keep the two separately, but it’s not true to say that all of the benefits are negated: replay attacks by an
attacker who intercepts a password are mitigated by this approach, for example, and these are a far more-common vector for identity theft than the theft and decryption of password
safes.
Everybody has to make their own decisions on the balance of their convenience versus their security, but for me the sweet spot comes here: in preventing many of the most-common attacks
against the kinds of accounts that I use and reinforcing my existing username/strong-unique-passwords approach without preventing me from getting stuff done. You’ll have to make your
own decisions, but if you take one thing away from this, let it be that there’s nothing to stop you having multiple ways to produce TOTP/Google Authenticator credentials, and you should consider doing so.
Quantum computing is all the rage. It seems like hardly a day goes by without some news outlet describing the extraordinary things this technology promises. Most commentators forget,
or just gloss over, the fact that people have been working on quantum computing for decades—and without any practical results to show for it.
We’ve been told that quantum computers could “provide breakthroughs in many disciplines, including
materials and drug discovery, the optimization of complex manmade systems, and artificial intelligence.” We’ve been assured that
quantum computers will “forever alter our economic, industrial, academic, and societal landscape.” We’ve even been told that “the encryption that protects the world’s most sensitive
data may soon be broken” by quantum computers. It has gotten to the point where many researchers in various fields of physics feel obliged to justify whatever work they are doing by
claiming that it has some relevance to quantum computing.
Meanwhile, government research agencies, academic departments (many of them funded by government agencies), and corporate laboratories are spending billions of dollars a year
developing quantum computers. On Wall Street, Morgan Stanley and other financial giants expect quantum computing to mature soon and are keen to figure out
how this technology can help them.
It’s become something of a self-perpetuating arms race, with many organizations seemingly staying in the race if only to avoid being left behind. Some of the world’s top technical
talent, at places like Google, IBM, and Microsoft, are working hard, and with lavish resources in state-of-the-art laboratories, to realize their vision of a quantum-computing future.
In light of all this, it’s natural to wonder: When will useful quantum computers be constructed? The most optimistic experts estimate it will take 5 to 10 years. More cautious
ones predict 20 to 30 years. (Similar predictions have been voiced, by the way, for the last 20 years.) I belong to a tiny minority that answers, “Not in the foreseeable future.”
Having spent decades conducting research in quantum and condensed-matter physics, I’ve developed my very pessimistic view. It’s based on an understanding of the gargantuan technical
challenges that would have to be overcome to ever make quantum computing work.
…
Great article undermining all the most-widespread popular arguments about how quantum computing will revolutionise aboslutely everything, any day now. Let’s stay realistic, here:
despite all the hype, it might well be the case that it’s impossible to build a quantum computer of sufficient complexity to have any meaningful impact on the world beyond the
most highly-experimental and theoretical applications. And even if it is possible, its applications might well be limited: the “great potential” they carry is highly
hypothetical.
Don’t get me wrong, I’m super excited about the possibility of quantum computing, too. But as Mickhail points out, we must temper our excitement with a little realism and not give in to
the hype.
One man – who appears to be afraid of chickens – plays Toto’s Africa on a rubber chicken, with backup from a real chicken. Congratulations: if you watched this, you just won
the whole damn Internet.
Even if you love Chrome, adore Gmail, and live in Google Docs or Analytics, no single company, let alone a user-tracking advertising giant, should control the internet.
…
Diversity is as good for the web as it is for society. And it starts with us.
Yet more fallout from the Microsoft announcement that Edge will switch to Chromium, which I discussed earlier. This one’s pretty inspirational, and gives a good reminder about what our responsibilities are to the Web, as its
developers.
Fantastic lightweight introduction to bacteriophages and how they can potentially be our next best weapon against infection as
we approach the post-antibiotic age. Plus an interesting look at the history and the discovery of bacteriophages!
Microsoft is officially giving up on an independent shared platform for the internet. By adopting Chromium, Microsoft hands over control of even more of online life to Google.
This may sound melodramatic, but it’s not. The “browser engines” — Chromium from Google and Gecko Quantum from Mozilla — are “inside baseball” pieces of software that actually
determine a great deal of what each of us can do online. They determine core capabilities such as which content we as consumers can see, how secure we are when we watch content, and
how much control we have over what websites and services can do to us. Microsoft’s decision gives Google more ability to single-handedly decide what possibilities are available to
each one of us.
From a business point of view Microsoft’s decision may well make sense. Google is so close to almost complete control of the infrastructure of our online lives that it may not be
profitable to continue to fight this. The interests of Microsoft’s shareholders may well be served by giving up on the freedom and choice that the internet once offered us. Google is
a fierce competitor with highly talented employees and a monopolistic hold on unique assets. Google’s dominance across search, advertising, smartphones, and data capture creates a
vastly tilted playing field that works against the rest of us.
From a social, civic and individual empowerment perspective ceding control of fundamental online infrastructure to a single company is terrible. This is why Mozilla exists. We compete with Google not because it’s a good business opportunity. We compete with Google because the health
of the internet and online life depend on competition and choice. They depend on consumers being able to decide we want something better and to take action.
Will Microsoft’s decision make it harder for Firefox to prosper? It could. Making Google more powerful is risky on many fronts. And a big part of the answer depends on what the web
developers and businesses who create services and websites do. If one product like Chromium has enough market share, then it becomes easier for web developers and businesses to decide
not to worry if their services and sites work with anything other than Chromium. That’s what happened when Microsoft had a monopoly on browsers in the early 2000s before Firefox was
released. And it could happen again.
If you care about what’s happening with online life today, take another look at Firefox. It’s radically better than it was 18 months ago — Firefox once again holds its own when it
comes to speed and performance. Try Firefox as your default browser for a week and then decide. Making Firefox
stronger won’t solve all the problems of online life — browsers are only one part of the equation. But if you find Firefox is a good product for you, then your use makes Firefox
stronger. Your use helps web developers and businesses think beyond Chrome. And this helps Firefox and Mozilla make overall life on the internet better — more choice, more security
options, more competition.
Scathing but well-deserved dig at Microsoft by Mozilla, following on from the Edge-switch-to-Chromium I’ve been going on about. Chris is right:
more people should try Firefox (it’s been my general-purpose browser on desktop and mobile ever since Opera threw in the towel and joined the Chromium hivemind in 2013, and on-and-off
plenty before then) – not just because it’s a great browser (and it is!) but also now because it’s important for the diversity and
health of the Web.
Our eldest, 4, started school this year and this week saw her first parents’ evening. This provided an opportunity for we, her parents, to “come out” to her teacher about our slightly-unconventional relationship structure. And everything was fine, which is nice.
We’re a unusual shape for a family. But three of us are an unusual shape for being in a kids’ soft play area, too, I suppose.
I’m sure the first few months of every child’s school life are a time that’s interesting and full of change, but it’s been particularly fascinating to see the ways in which our young
academic’s language has adapted to fit in with and be understood by her peers.
I first became aware of these changes, I think, when I overheard her describing me to one of her school friends as her “dad”: previously she’d always referred to me as her “Uncle Dan”.
I asked her about it afterwards and she explained that I was like a dad, and that her friend didn’t have an “Uncle Dan” so she used words that her friend would know. I’m not
sure whether I was prouder about the fact that she’d independently come to think of me as being like a bonus father figure, or the fact that she demonstrated such astute audience
management.
She’s since gotten better at writing on the lines (and getting “b” and “d” the right way around), but you can make out “I have two dads”.
I don’t object to being assigned this (on-again, off-again, since then) nickname. My moniker of Uncle Dan came about as a combination of an effort to limit ambiguity
(“wait… which dad?”) and an attempt not to tread on the toes of actual-father JTA: the kids themselves are welcome to call me pretty-much whatever they’re comfortable with. Indeed, they’d be carrying on a family tradition if they
chose-for-themselves what to call me: Ruth and her brothers Robin and Owen address their father not by a
paternal noun but by his first name, Tom, and this kids have followed suit by adopting “Grand-Tom” as their identifier for him.
Knowing that we were unusual, though, we’d taken the time to do some groundwork before our eldest started school. For example we shared a book about and spent a while talking about how
families differ from one another: we figure that an understanding that families come in all kinds of shapes and sizes is a useful concept in general from a perspective of
diversity and and acceptance. In fact, you can hear how this teaching pays-off in the language she uses to describe other aspects of the differences she sees in her friends and
their families, too.
Still, it was a little bit of a surprise to find myself referred to as a “dad” after four years of “Uncle Dan”.
I’ve no idea what the littler one – picture here with his father – will call me when he’s older, but this week has been a “terrible 2s” week in which he’s mostly called me “stop it”
and “go away”.
Nonetheless: in light of the fact that she’d clearly been talking about her family at school and might have caused her teacher some confusion, when all three of us “parents” turned up
to parents’ evening we opted to introduce ourselves and our relationship. Which was all fine (as you’d hope: as I mentioned the other day, our unusual relationship structure is pretty boring, really), and the only
awkwardness was in having to find an additional chair than the teacher had been expecting to use with which to sit at the table.
There’s sometimes a shortage of happy “we did a thing, and it went basically the same as it would for a family with monogamous parents” poly-family stories online, so I thought this one
was worth sharing.
And better yet: apparently she’s doing admirably at school. So we all celebrated with an after-school trip to one of our favourite local soft play centres.
Run run run run run run run STOP. Eat snack. Run run run run run run…