Inspired by XKCD 3113 “Fix This Sign”, the site features marquee animations, poor font choices, wonky rotation and alignment, and more.
Like the comic, it aims to “extort” people offended by the design choices by allowing them to pay to fix them. Once fixed, a change is fixed for everybody… at least, until
somebody pays to “reset” the site back to its catastrophic mode.
I can’t criticise Humidity Studios for taking a stupid idea from XKCD and taking it way too far, because, well, there’s this site that I
run…
That’s cute and all, but the difference between a billboard and a web page is, of course, that a web page is under the viewer’s control. Once it’s left the server and
reached your computer, there’s nothing the designer can to do stop you editing a page in any way you like. That’s just how the Web works!
A great way to do this is with userscripts: Javascript content that is injected into pages by your browser when you visit particular pages. Mostly by way of demonstration,
I gave it a go. And now you can, too! All you need is a userscript manager plugin in your browser (my favourite is Violentmonkey!) and to
install my (open source) script.
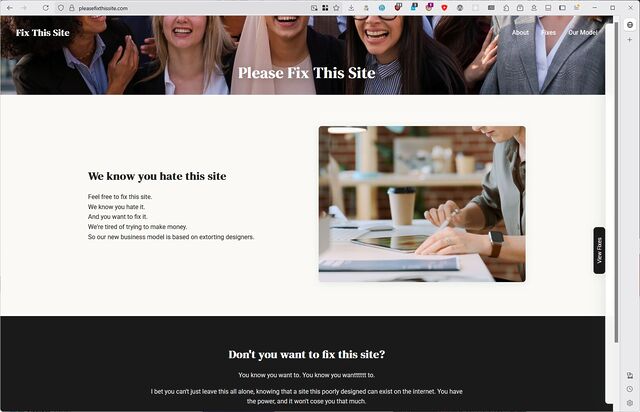
Much better! (I mean, still not a pinnacle of design… but at least my eyes aren’t bleeding any more!)
I enjoyed the art of the joke that is PleaseFixThisSite.com. But probably more than that, I enjoyed the excuse to remind you that by the time you’re viewing a Web page, it’s
running on your computer, and you can change it any way you damn well please.
Don’t like the latest design of your favourite social network? Want to reinstate a feature of a popular video playing site? Need a dark mode to spare your eyes on a particular news
publication? Annoyed by artificial wait times before you’re “allowed” to click a download button? There’s probably a userscript for all of those. And if there isn’t, you can have a go
at writing one. Userscripts are great, and you should be using them.
RotatingSandwiches.com is a website showcasing animated GIF files of rotating
sandwiches1. But it’s got a problem: 2 of the 51 sandwiches rotate the
wrong way. So I’ve fixed it:
The Eggplant Parm Sub is one of two sandwiches whose rotation doesn’t match the rest.
My fix is available as a userscript on GreasyFork, so you can use your
favourite userscript manager2
to install it and the rotation will be fixed for you too. Here’s the code (it’s pretty simple):
1
2
3
4
5
6
7
8
9
10
11
12
// ==UserScript==// @name Standardise sandwich rotation on rotatingsandwiches.com// @namespace rotatingsandwiches.com.danq.me// @match https://rotatingsandwiches.com/*// @grant GM_addStyle// @version 1.0// @author Dan Q <https://danq.me/>// @license The Unlicense / Public Domain// @description Some sandwiches on rotatingsandwiches.com rotate in the opposite direction to the majority. 😡 Let's fix that.// ==/UserScript==
GM_addStyle('.q23-image-216, .q23-image-217 { transform: scaleX(-1); }');
Unless you’re especially agitated by irregular sandwich rotation, this is perhaps the most-pointless userscript ever created. So why did I go to the trouble?
Fixing Websites
Obviously, I’m telling you this as a vehicle to talk about userscripts in general and why you should be using them.
But the real magic is being able to remix the web your way. With just a little bit of CSS or JavaScript experience you
can stop complaining that a website’s design has changed in some way you don’t like or that some functionality you use isn’t as powerful or convenient as you’d like and you can fix
it.
A website I used disables scrolling until all their (tracking, advertising, etc.) JavaScript loads, and my privacy blocker blocks those files: I could cave and disable my browser’s
privacy tools… but it was almost as fast to add setInterval(()=>document.body.style.overflow='', 200); to a userscript and now it’s fixed.
Don’t want a Sports section on your BBC News homepage (not just the RSS
feed!)? document.querySelector('a[href="/sport"]').closest('main > div').remove(). Sorted.
I’m a huge fan of building your own tools to “scratch your own itch”. Userscripts are a highly accessible introduction to doing so that even beginner programmers can get on board with
and start getting value from. More-advanced scripts can do immensely clever and powerful things, but even if you just use them to apply a few light CSS touches to your favourite websites, that’s still a win.
Footnotes
1 Remember when a website’s domain name used to be connected to what it was for?
RotatingSandwiches.com does.
My friend still uses a seriously retro digital music player, rather than his phone, to listen to music. It’s not a Walkman or a Minidisc player, I suppose, but it’s still pretty
elderly. But it’s not one of these.
I’m not here to speak about the legality of retaining offline copies of music from streaming services. YouTube Music seems to permit you to do this using their app, but I’ll bet there’s
something in their terms and conditions that specifically prohibits doing so any other way. Not least because Google’s arrangement with rights holders probably stipulates that they
track how many times tracks are played, and using a different player (like my friend’s portable device) would throw that off.
But what I’m interested in is the feasibility. And in answering that question, in explaining how to work out that it’s feasible.
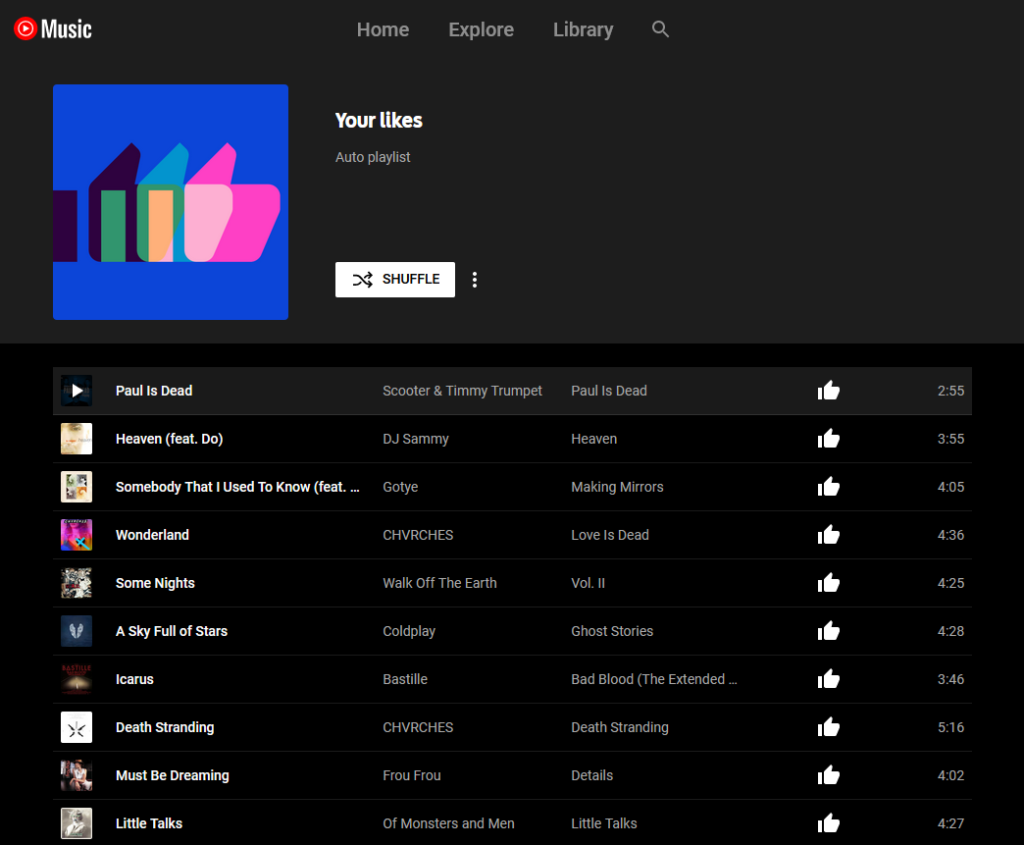
The web interface to YouTube Music shows playlists of songs and streaming is just a click away.
Spoiler: I came up with an approach, and it looks like it works. My friend can fill up their Zune or whatever the hell
it is with their tunes and bop away. But what I wanted to share with you was the underlying technique I used to develop this approach, because it involves skills that as a web
developer I use most weeks. Hold on tight, you might learn something!
youtube-dl can download “playlists” already, but to download a personal playlist requires that you faff about with authentication and it’s a bit of a drag. Just extracting
the relevant metadata from the page is probably faster, I figured: plus, it’s a valuable lesson in extracting data from web pages in general.
Here’s what I did:
Step 1. Load all the data
I noticed that YouTube Music playlists “lazy load”, and you have to scroll down to see everything. So I scrolled to the bottom of the page until I reached the end of the playlist: now
everything was in the DOM, I could investigate it with my inspector.
Step 2. Find each track’s “row”
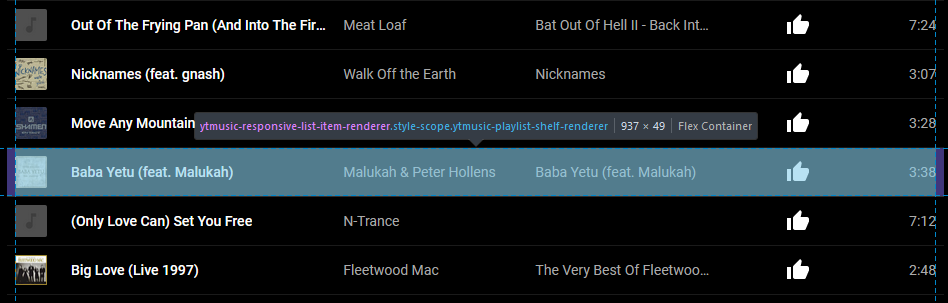
Using my browser’s debugger “inspect” tool, I found the highest unique-sounding element that seemed to represent each “row”/track. After a little investigation, it looked like
a playlist always consists of a series of <ytmusic-responsive-list-item-renderer> elements wrapped in a <ytmusic-playlist-shelf-renderer>. I tested
this by running document.querySelectorAll('ytmusic-playlist-shelf-renderer ytmusic-responsive-list-item-renderer') in my debug console and sure enough, it returned a number
of elements equal to the length of the playlist, and hovering over each one in the debugger highlighted a different track in the list.
The web application captured right-clicks, preventing the common right-click-then-inspect-element approach… so I just clicked the “pick an element” button in the debugger.
Step 3. Find the data for each track
I didn’t want to spend much time on this, so I looked for a quick and dirty solution: and there was one right in front of me. Looking at each track, I saw that it contained several
<yt-formatted-string> elements (at different depths). The first corresponded to the title, the second to the artist, the third to the album title, and the fourth to
the duration.
Better yet, the first contained an <a> element whose href was the URL of the piece of music.
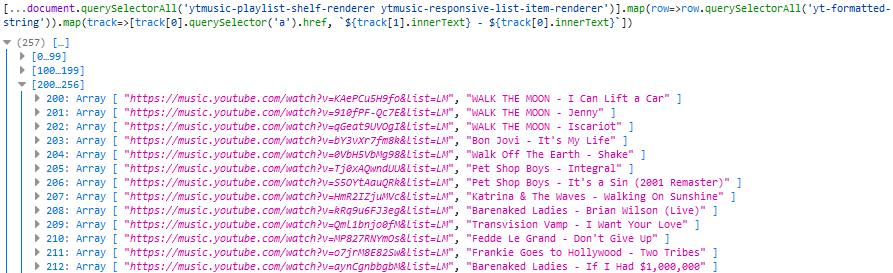
Extracting the URL and the text was as simple as a .querySelector('a').href on the first
<yt-formatted-string> and a .innerText on the others, respectively, so I ran [...document.querySelectorAll('ytmusic-playlist-shelf-renderer
ytmusic-responsive-list-item-renderer')].map(row=>row.querySelectorAll('yt-formatted-string')).map(track=>[track[0].querySelector('a').href, `${track[1].innerText} -
${track[0].innerText}`]) (note the use of [...*] to get an array) to check that I was able to get all the data I needed:
Lots of URLs and the corresponding track names in my friend’s preferred format (me, I like to separate my music into folders
by album, but I suppose I’ve got a music player with more than a floppy disk’s worth of space on it).
Step 4. Sanitise the data
We’re not quite good-to-go, because there’s some noise in the data. Sometimes the application’s renderer injects line feeds into the innerText (e.g. when escaping an
ampersand). And of course some of these song titles aren’t suitable for use as filenames, if they’ve got e.g. question marks in them. Finally, where there are multiple spaces in a row
it’d be good to coalesce them into one. I do some experiments and decide that .replace(/[\r\n]/g, '').replace(/[\\\/:><\*\?]/g, '-').replace(/\s{2,}/g, ' ') does a
good job of cleaning up the song titles so they’re suitable for use as filenames.
I probably should have it fix quotes too, but I’ll leave that as an exercise for the reader.
Step 5. Produce youtube-dl commands
Okay: now we’re ready to combine all of that output into commands suitable for running at a terminal. After a quick dig through the documentation, I decide that we needed the following
switches:
-x to download/extract audio only: it defaults to the highest quality format available, which seems reasomable
-o "the filename.%(ext)s" to specify the output filename but accept the format provided by the quality requirement (transcoding to your preferred format is a
separate job not described here)
--no-playlist to ensure that youtube-dl doesn’t see that we’re coming from a playlist and try to download it all (we have our own requirements of each song’s
filename)
--download-archive downloaded.txt to log what’s been downloaded already so successive runs don’t re-download and the script is “resumable”
The output isn’t pretty, but it’s suitable for copy-pasting into a terminal or command prompt where it ought to download a whole lot of music for offline play.
This isn’t an approach that most people will ever need: part of the value of services like YouTube Music, Spotify and the like is that you pay a fixed fee to stream whatever you like,
wherever you like, obviating the need for a large offline music collection. And people who want to maintain a traditional music collection offline are most-likely to want to do
so while supporting the bands they care about, especially as (with DRM-free digital downloads commonplace) it’s never been
easier to do so.
But for those minority of people who need to play music from their streaming services offline but don’t have or can’t use a device suitable for doing so on-the-go, this kind of approach
works. (Although again: it’s probably not permitted, so be sure to read the rules before you use it in such a way!)
Step 6. Learn something
But more-importantly, the techniques of exploring and writing console Javascript demonstrated are really useful for extracting all kinds of data from web pages (data scraping), writing your own userscripts, and much more. If there’s
one lesson to take from this blog post it’s not that you can steal music on the Internet (I’m pretty sure everybody who’s lived on this side of 1999 knows that by now), but
that you can manipulate the web pages you see. Once you’re viewing it on your computer, a web page works for you: you don’t have to consume a page in the way that the
author expected, and knowing how to extract the underlying information empowers you to choose for yourself a more-streamlined, more-personalised, more-powerful web.
[this post was originally made to a private subreddit]
I love the MegaLounges, and I really love the MegaManLounge. We’re a hugely disparate group of people yet we’ve come together into a wonderful community that I’m proud to be
a part of. And I felt like it’d be nice to give something back. But what?
If you’re like me, you love the experience of bumping into another MMLer elsewhere in the Redditverse (or around the Internet in general). I mean, what’d be really awesome is if we could find one another in the real world, but that’s a project for another day. Anyway: my
point is that I get a thrill when I spot a fellow MMLer wandering around in Redditland. But oftentimes I don’t look closely at people’s usernames, and I’m sure there must be times
that I’ve just overlooked one of you in some long thread in /r/AskReddit or /r/TodayILearned or something. I’d rather know
that you were there, my MML brothers and sisters.
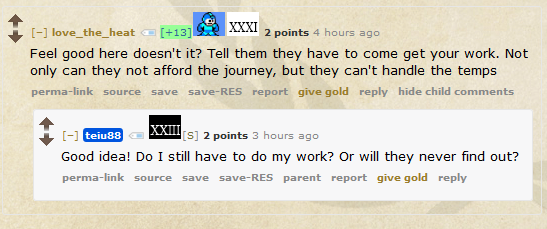
So I spent this afternoon putting together a tool that does just that. Here’s a screenshot to show you what I’m talking
about.
I’ve written a basic browser plugin that highlights MMLers (and other MegaLounge-like folks) anywhere on Reddit. So the idea is, if you install this plugin, you’ll always
know if somebody’s an MMLer or a MegaLounger because they’ll get one or two icons next to their name. In the screenshot – taken on /r/MegaLoungeVenus
(the 23rd MegaLounge) you’ll see a snipped of a conversation between our very own /u/love_the_heat and /u/teiu88. /u/love_the_heat has two icons: the first one (obviously) indicates that he’s a MegaMan, and the second one shows that he’s reached MegaLounge level thirty-one
(yes, there are quite a lot of MegaLounge levels now). /u/teiu88 only has one icon (he’s not a MegaMan!), showing that he’s at MegaLounge level twenty-three.
Note that it’s coloured differently to show that this is the level that I’m looking at right now: this helps because I can see whether people are commenting at their highest
lounge level or not, which may factor into my decision about where and when to gild them.
Someday, I’d like to make this available to MegaLoungers in general, but first I’d like to show it off to you, fine MegaMen, and hear what you think. Is this tool useful to anybody?
Should I make a production-grade version to share with you all? Or am I solving a problem that nobody actually has?
Just to add: there are several things I’d like to add and questions I’ve not yet answered before I release it to you; notably:
Right now it identifies members of the Super Secret MegaLounge, which is a violation of the rules of that lounge, so obviously I can’t release it yet. I’d like to find a
way to have it identify such people but only to other members of that lounge, but failing that, I need to have it just “skip” that lounge when showing how high somebody’s ascended.
On which note: what do you think about it identifying MegaMen? If I ever make this tool more-widely available than the MegaManLounge, should the version used by non-MegaManLounge
people identify MegaManLounge members, or not? I can see arguments either way, but I will of course go with the will of you fabulous people on this matter.
I’d like to add tooltips so that people who haven’t got the entire MegaLounge ascension mapped out in their minds can work out what’s what.
Similarly, I’d like to improve the icons so that they e.g. have gemstones next to the gemstone lounges, planets next to the planetary ones, etc.
Oh, and I really ought to make it work in more than just Firefox. I’d like it to work in Chrome, at the very least, too. IE can suck it, mind.
What do you think?
tl;dr: I’ve made a browser plugin that makes Reddit look like this, showing people’s highest MegaLounge and
MegaManLounge status. Is it a good idea?
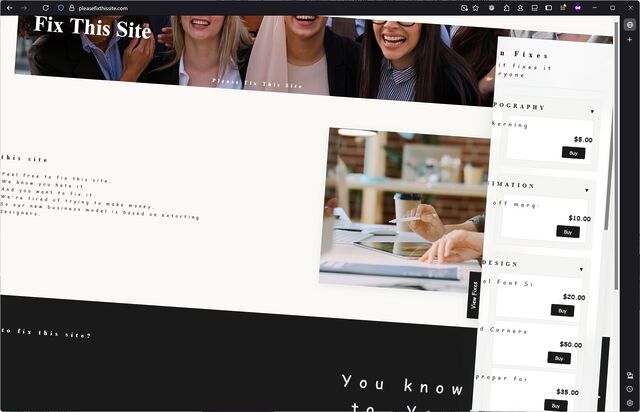
![XKCD comic. Transcript: [A single panel containing a large, elevated sign with Ponytail standing in front of it.] [Title, slightly off horizontal, more to the right than central and the character spacing is not entirely consistent/aesthetic:] Doanate[sic] to fix this sign! [To the left of the lower part of the sign there is an 'QR code', tilted slightly with a plaintext link beneath it:] https://[illegible].com [To the right are several dollar values, in one column, and 'fixes', in a second, some of which have their own self-demonstrating quirks.] [The letters "R" and "N" may be too close together:] $10 fix kerning [Both dollar value and fix text are shifted left of their respective columns:] $20 align columns [This line is in a smaller font:] $20 fix text size $50 fix typo $50 fix centering $100 fix rotation [Ponytail stands looking at the sign, apparently in the process of using a smartphone:] Grrr... [Caption below panel:] My new company's business model is based on extorting graphic designers.](https://bcdn.danq.me/_q23u/2025/07/fix_this_sign1.png)


{kind=link}