Have you ever wished there were more to the internet than the same handful of apps and sites you toggle between every day? Then you’re in for a treat.
Welcome to the indie web, a vibrant and underrated part of the internet,aesthetically evocative of the late 1990s and early 2000s. Here,
the focus is on personal websites, authentic self-expression, and slow, intentional exploration driven by curiosity and interest.
These kinds of sites took a backseat to the mainstream web around the advent of big social media platforms, butrecently the indie web has been experiencing a
revival, as more netizens look for connection outside the walled gardens created by tech giants. And with renewed interest comes a new generation of website
owner-operators, intent on reclaiming their online experience from mainstream social media imperatives of growth and profit.
…
I want to like this article. It draws attention to the indieweb, smolweb, independent modern personal web, or whatever you want to call it. It does so in a way that
inspires interest. And by way of example, it features several of my favourite retronauts. Awesome.
But it feels painfully ironic to read this article… on Substack!
Substack goes… let’s say half-way… to representing the opposite of what the indieweb movement is about! Sure, Substack isn’t Facebook or Twitter… but it’s still very much in
the same place as, say, Medium, in that it’s a place where you go if you want other people to be in total control of your Web presence.
The very things that the author praises of the indieweb – its individuality and personality, its freedom control by opaque corporate policies, its separation from the “same
handful of apps and sites you toggle between every day” – are exactly the kinds of things that Substack fails to provide.
The W3C‘s WebDX Community Group this week announced that they’ve reached a milestone with their web-features project. The project is an effort to catalogue browser support for Web features, to establish an
understanding of the baseline feature set that developers can rely on.
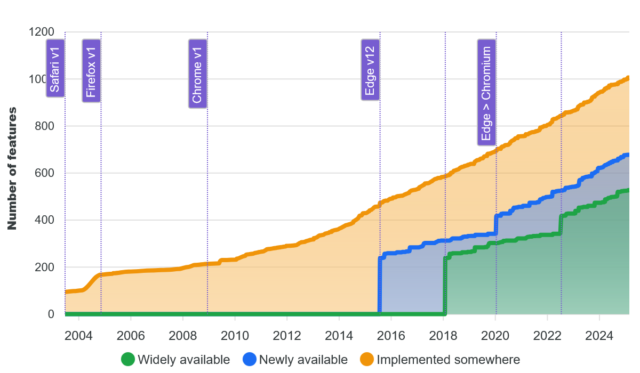
That’s great, and I’m in favour of the initiative. But I wonder about graphs like this one:
The graph shows the increase in time of the number of features available on the Web, broken down by how widespread they are implemented across the browser corpus.
The shape of that graph sort-of implies that… more features is better. And I’m not entirely convinced that’s true.
Does “more” imply “better”?
Don’t get me wrong, there are lots of Web features that are excellent. The kinds of things where it’s hard to remember how I did without them. CSS grids are for many purposes an
improvement on flexboxes; flexboxes were massively better than floats; and floats were an enormous leap forwards compared to using tables for layout! The “new” HTML5 input types are
wonderful, as are the revolutionary native elements for video, audio, etc. I’ll even sing the praises of some of the new JavaScript APIs (geolocation, web share, and push are
particular highlights).
But it’s not some kind of universal truth that “more features means better developer experience”. It’s already the case, for example, that getting started as a Web developer is
harder than it once was, and I’d argue harder than it ought to be. There exist complexities nowadays that are barriers to entry. Like the places where the promise of a
progressively-enhanced Web has failed (they’re rare, but they exist). Or the sheer plethora of features that come with caveats to their use that simply must be learned (yes, you need a
<meta name="viewport">; no, you can’t rely on JS to produce content).
Meanwhile, there are technologies that were standardised, and that we did need, but that never took off. The <keygen> element never got
implemented into the then-dominant Internet Explorer (there were other implementation problems too, but this one’s the killer). This made it functionally useless, which meant that its
standard never evolved and grew. As a result, its implementation in other browsers stagnated and it was eventually deprecated. Had it been implemented properly and iterated on, we’d
could’ve had something like WebAuthn over a decade earlier.
Which I guess goes to show that “more features is better” is only true if they’re the right features. Perhaps there’s some way of tracking the changing landscape of developer
experience on the Web that doesn’t simply count enumerate a baseline of widely-available features? I don’t know what it is, though!
A simple web
Mostly, the Web worked fine when it was simpler. And while some of the enhancements we’ve seen over the decades are indisputably an advancement, there are also plenty of places
where we’ve let new technologies lead us astray. Third-party cookies appeared as a naive consequence of first-party ones, but came to be used to undermine everybody’s privacy. Dynamic
DOM manipulation started out as a clever idea to help with things like form validation and now a significant number of websites can’t even show their images – or sometimes their text –
unless their JavaScript code gets downloaded and interpreted successfully.
Were you reading this article on Medium, you’d have downloaded ~5MB of data including 48 JS files and had 7 cookies set, just so you could… have most of the text covered with
popovers? (for comparison, reading it here takes about half a megabyte and the cookies are optional delicious)
A blog post, news article, or even an eCommerce site or social networking platform doesn’t need the vast majority of the Web’s “new” features. Those features are important for some Web
applications, but most of the time, we don’t need them. But somehow they end up being used anyway.
Whether or not the use of unnecessary new Web features is a net positive to developer experience is debatable. But it’s certainly not often to the benefit of user experience.
And that’s what I care about.
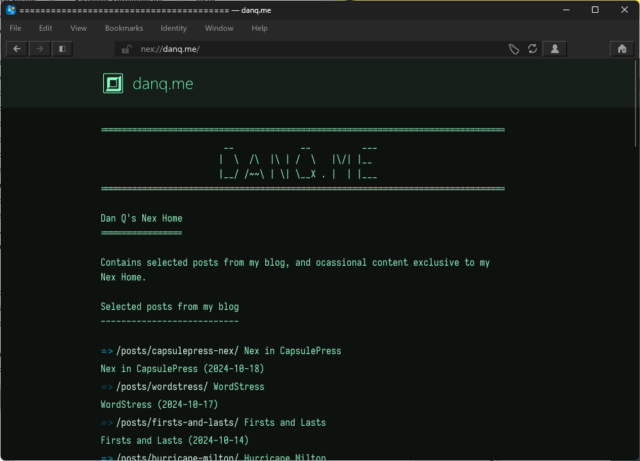
Here’s how nex://danq.me/ looks in my favourite desktop Gemini/smolweb browser Lagrange.
Nex is a lightweight Internet protocol reminiscent to me of Spartan (which CapsulePress also supports), but even more lightweight.
Without even affordances like host identification, MIME types, response codes, or the expectation that Gemtext might be supported by the client, it’s perhaps more like Gopher than it is
like Gemini.
It comes from the ever-entertaining smolweb hub of Nightfall City, whose Web interface clearly states at the top of every page the command you
could have run to see that content over the Nex protocol. Lagrange added support for Nex almost a year ago and it’s such a lightweight protocol that I was quickly able
to adapt CapsulePress’s implementation of Spartan to support Nex, too.
This is genuinely the entirety of my implementation of my Nex server, atop CapsulePress. And it’s mostly boilerplate.
Why, you might ask? Well, the reasons are the same as all the other standards supported by CapsulePress:
The smolweb is awesome.
Making WordPress into a CMS things it was never meant to do is sorta my jam.
It was a quick win while I waited for the pharmacist to shoot me up with 5G microchips my ‘flu and Covid boosters.
If you want to add Nex onto your CapsulePress, just git pull the latest version, ensure TCP port 1900 isn’t firewalled, and don’t add USE_NEX=false to
your environment. That’s all!
Maintaining a blog can be a lot of work. A single article can take weeks of research, drafting and editing, collecting and producing included materials, etc. It’s not unusual to
seek some form of compensation for it, and those rewards require initiative. With a good monetization strategy, it can become a fairly
lucrative venture.
So let’s talk about monetizing a blog, starting with the most obvious and perhaps easiest avenue: display advertising.
A content creator with an established audience can leverage that audience and sell ad space on their blog. Here’s an example:
…
I’m not sure I have words for how awesome this blog post is. If you’ve ever wanted to monetise your blog and are considering an ad-driven model, this should absolutely be the first (and
perhaps last) thing you read on the subject.
If you’re not convinced that Tyler is an appropriate authority to speak on this subject, I highly suggest you visit their other site that’s got a wealth of useful tips, PutAToothpickInTheChargingPortDoctorsHateThatShit.christmas. Yes, really.
In August, I celebrated my blog – with its homepage weighing-in at a total of just 481kb – being admitted to Kev Quirk‘s 512kb club. 512kb club celebrates websites (often personal sites) whose homepage are neither “ultra minimal”
or “link pages” but have a total size, including all assets, of under half a megabyte. It’s about making a commitment to a leaner, more-efficient Web.
My relatively-heavyweight homepage only just slipped in under the line. But, feeling inspired perhaps by some performance enhancements I’ve been planning this week at work, I
decided to try to shave a little more off:
Now, at ~234kb, danq.me just beats the excellent gomakethings.com (it’s all those heavyweight fonts, Chris!).
Here’s what I changed:
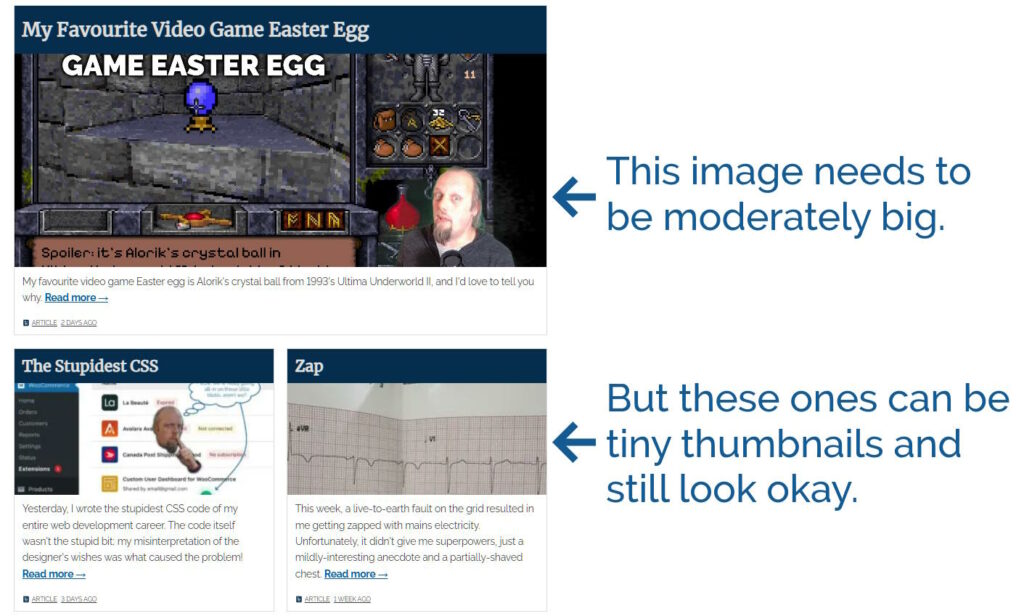
The “recent article” tiles are dynamically sized based on their number, type, and the visitor’s screen resolution. But apart from the top one they’re almost never very large. Using
thumbnail images for the non-first tile shaved off almost 160kb.
You can see the difference, but it’s still acceptable to look at, I think.
Not space-saving, but while I was in there I ensured that the first tile’s image – which almost-certainly comprises part of the Largest
Contentful Paint – is never delivered with loading="lazy".
I was providing a shortcut icon in .ico format (<link rel="shortcut icon" href="https://bcdn.danq.me/_q23t/icons/favicon-16-32-48-64-128.ico" />),
which is pretty redundant nowadays because all modern browsers (and even IE11)
support .png icons. I was already providing.png and .svg versions, but it turns out that some browsers favour the one with the
(harmful?) rel="shortcut icon" over rel="icon" if both are present, and .ico
files are – being based on Windows Bitmaps – horrendously inefficient.
By getting under the 250kb threshold, I’ve jumped up a league from Blue Team to Orange Team, so that’s nice too. I can’t see a meaningful
path from where I’m at to Green Team (under 100kb) though, so this level might have to suffice.
Now I’ve added support for Spartan3 too and, seeing as the implementations shared functionality, I’ve
combined all three – Gemini, Spartan, and Gopher – into a single package: CapsulePress.
CapsulePress is a Gemini/Spartan/Gopher to WordPress bridge. It lets you use WordPress as a CMS for any or all of
those three non-Web protocols in addition to the Web.
For example, that means that this post is available on all of:
It’s also possible to write posts that selectively appear via different media: if I want to put something exclusively on my gemlog, I can, by assigning metadata that
tells WordPress to suppress a post but still expose it to CapsulePress. Neat!
Using Gemini and friends in the 2020s make me feel like the dream of the Internet of the nineties and early-naughties is still alive. But with fewer banner ads.
I’ve open-sourced the whole thing under a super-permissive license, so if you want your own WordPress blog to “feed” your Gemlog… now you can. With a few caveats:
It’s hard to use. While not as hacky as the disparate piles of code it replaced, it’s still not the cleanest. To modify it you’ll need a basic comprehension of all
three protocols, plus Ruby, SQL, and sysadmin skills.
It’s super opinionated. It’s very much geared towards my use case. It’s improved by the use of templates. but it’s still probably only suitable for this
site for the time being, until you make changes.
It’s very-much unfinished. I’ve got a growing to-do list, which should
be a good clue that it’s Not Finished. Maybe it never will but. But there’ll be changes yet to come.
Whether or not your WordPress blog makes the jump to Geminispace4, I hope you’ll came take a look at mine at one of the URLs linked above,
and then continue to explore.
If you’re nostalgic for the interpersonal Internet – or just the idea of it, if you’re too young to remember it… you’ll find it there. (That Internet never actually went away,
but it’s harder to find on today’s big Web than it is on lighter protocols.)