Hi @avapoet, I’m the author of the JavaScript for the WorldWideWeb project, and I did read your thread on the user-agent missing and I thought I’d land the fix ;-)
The original WorldWideWeb browser that we based our work on was 0.12 with screenshots from 0.16. Both browsers supported HTTP 0.9 which didn’t send headers. Obviously unintentional
that I send the `request` user-agent, so I spent some painful hours trying to get my emulator running NeXT with a networked connection _and_ the WorldWideWeb version 1.0 – which
_did_ use HTTP 1.0 and would send a User-Agent, so I could copy it accurately into the emulator code base.
So now metafilter.com renders in the emulator, and the User Agent sent is: CERN-NextStep-WorldWideWeb.app/1.1 libwww/2.07
This comment on the MetaFilter thread, which I only just noticed, is by Remy Sharp, who was part of the team that reimplemented WorldWideWeb as part
of that hackathon (his blog posts about the experience: 1, 2,
3, 4, 5),
and acknowledges my contribution. Squee!
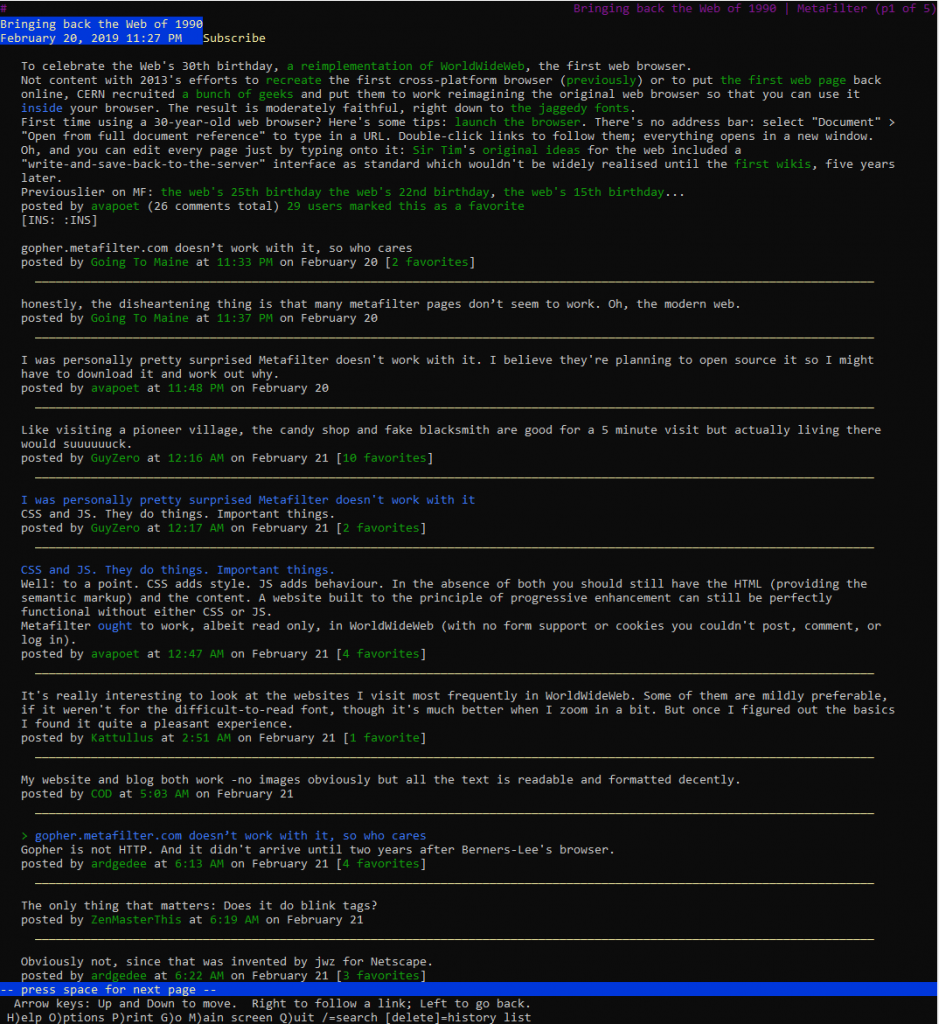
People were quick to point this out and assume that it was something to do with the modernity of MetaFilter:
honestly, the disheartening thing is that many metafilter pages don’t seem to work. Oh, the modern web.
Some even went so far as to speculate that the reason related to MetaFilter’s use of CSS and JS:
CSS and JS. They do things. Important things.
This is, of course, complete baloney, and it’s easy to prove to oneself. Firstly, simply using the View Source tool in your browser on a MetaFilter page reveals source code that’s quite
comprehensible, even human-readable, without going anywhere near any CSS or JavaScript.
As late as the early 2000s I’d occasionally use Lynx for serious browsing, but any time I’ve used it since it’s been by necessity.
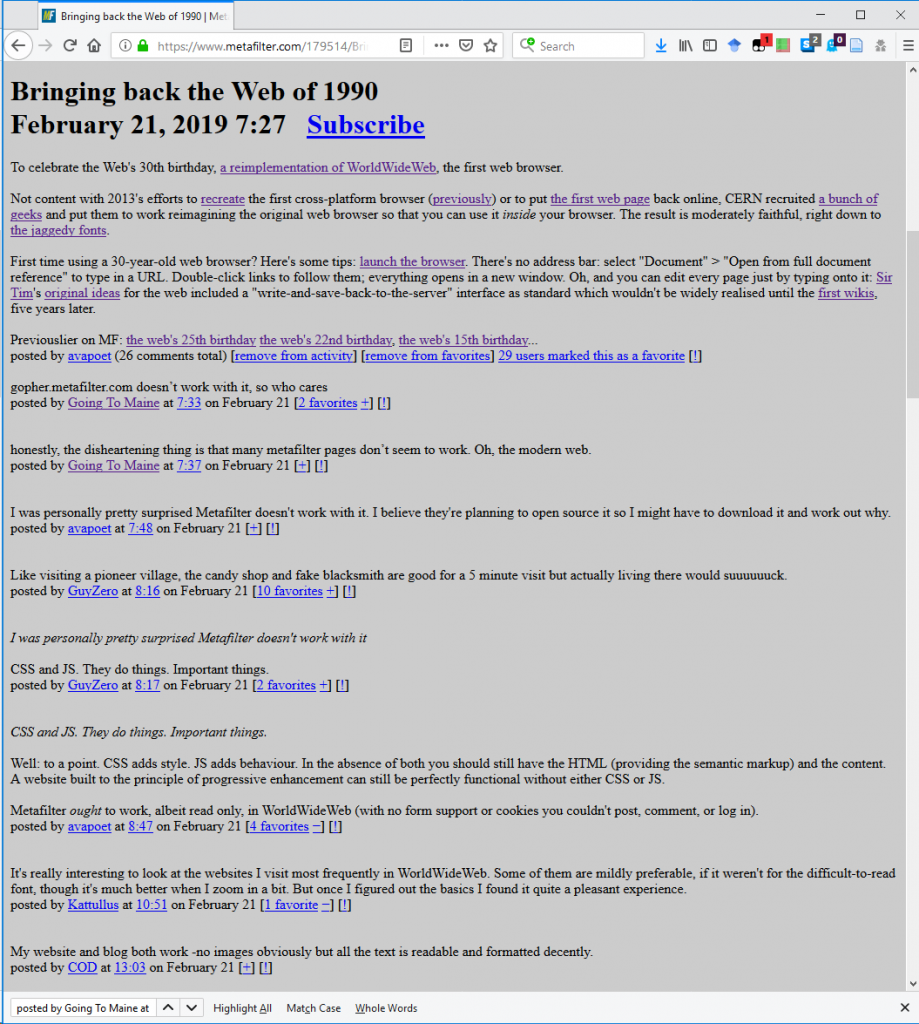
Secondly, it’s pretty simple to try browsing MetaFilter without CSS or JavaScript enabled! I tried in two ways: first,
by using Lynx, a text-based browser that’s never supported either of those technologies. I also tried by using
Firefox but with them disabled (honestly, I slightly miss when the Web used to look like this):
It only took me three clicks to disable stylesheets and JavaScript in my copy of Firefox… but I’ll be the first to admit that I don’t keep my browser configured like “normal people”
probably do.
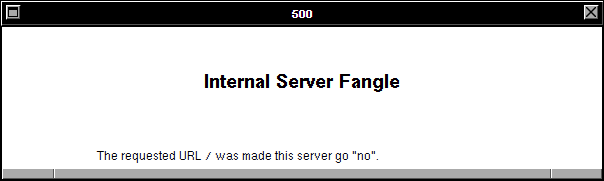
And thirdly: the error code being returned by the simulated WorldWideWeb browser is a HTTP code 500. Even if you don’t
know your HTTP codes (I mean, what kind of weirdo would take the time to memorise them all anyway <ahem>),
it’s worth learning this: the first digit of a HTTP response code tells you what happened:
1xx means “everything’s fine, keep going”;
2xx means “everything’s fine and we’re done”;
3xx means “try over there”;
4xx means “you did something wrong” (the infamous 404, for example, means you asked for a page that doesn’t exist);
5xx means “the server did something wrong”.
Simple! The fact that the error code begins with a 5 strongly implies that the problem isn’t in the (client-side) reimplementation of WorldWideWeb: if this had have been a
CSS/JS problem, I’d expect to see a blank page, scrambled content, “filler”
content, or incomplete content.
So I found myself wondering what the real problem was. This is, of course, where my geek flag becomes most-visible: what we’re talking about, let’s not forget, is a fringe
problem in an incomplete simulation of an ancient computer program that nobody uses. Odds are incredibly good that nobody on Earth cares about this except, right now, for me.
I searched for a “Geek Flag” and didn’t like anything I saw, so I came up with this one based on… well, if you recognise what it’s based on, good for you, you’re certainly allowed to
fly it. If not… well, you can too: there’s no geek-gatekeeping here.
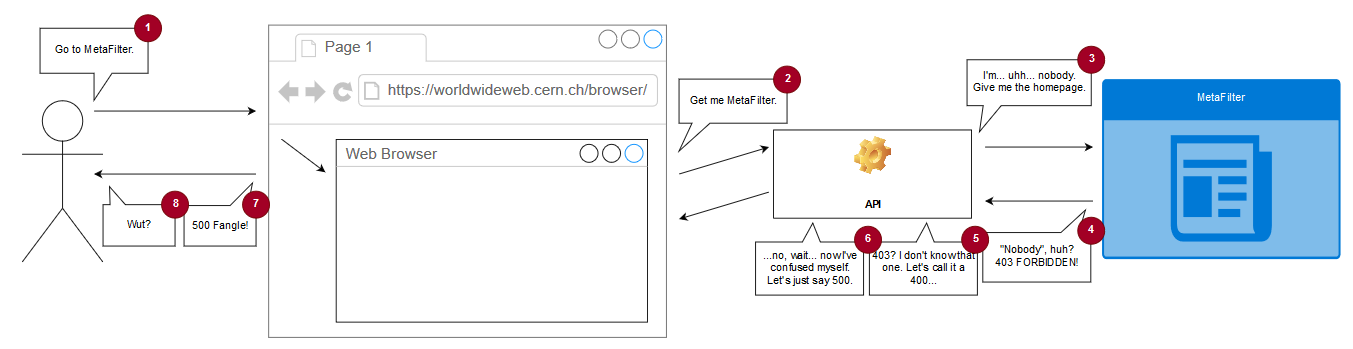
The (simulated) copy of WorldWideWeb is asked to open a document by reference, e.g. “https://www.metafilter.com/”.
To work around same-origin policy restrictions, the request is sent to an API which acts as a proxy server.
The API makes a request using the Node package “request” with this line of code: request(url, (error, response, body) =>
{ ... }). When the first parameter to request is a (string) URL, the module uses its default settings for all of
the other options, which means that it doesn’t set the User-Agent header (an optional part of a Web request where the computer making the request identifies the software
that’s asking).
MetaFilter, for some reason, blocks requests whose User-Agent isn’t set. This is weird! And nonstandard: while web browsers should – in RFC2119 terms – set their User-Agent: header, web servers shouldn’t require
that they do so. MetaFilter returns a 403 and a message to say “Forbidden”; usually a message you only see if you’re trying to access a resource that requires session authentication and
you haven’t logged-in yet.
The API is programmed to handle response codes 200 (okay!) and 404 (not found), but if it gets anything else back
it’s supposed to throw a 400 (bad request). Except there’s a bug: when trying to throw a 400, it requires that an error message has been set by the request module and if there
hasn’t… it instead throws a 500 with the message “Internal Server Fangle” and no clue what actually went wrong. So MetaFilter’s 403 gets translated by the proxy into a 400 which
it fails to render because a 403 doesn’t actually produce an error message and so it gets translated again into the 500 that you eventually see. What a knock-on effect!
If you’re having difficulty visualising the process, this diagram might help you to continue your struggle with that visualisation.
This then sets a User-Agent header and makes servers that require one, such as MetaFilter, respond appropriately. I don’t know whether WorldWideWeb originally set a User-Agent header
(CERN’s source file archive seems to be missing the relevant C sources so I can’t check) but I
suspect that it did, so this change actually improves the fidelity of the emulation as a bonus. A better fix would also add support for and appropriate handling of other HTTP response
codes, but that’s a story for another day, I guess.
I know the hackathon’s over, but I wonder if they’re taking pull requests…