Last night I was chatting to my friend (and fellow Three Rings volunteer) Ollie about our respective workplaces and their approach to AI-supported software engineering, and it echoed conversations I’ve had with other friends. Some workplaces, it seems, are leaning so-hard into AI-supported software development that they’re berating developers who seem to be using the tools less than their colleagues!
That’s a problem for a few reasons, principal among them that AI does not make you significantly faster but does make you learn less.1. I stand by the statement that AI isn’t useless, and I’ve experimented with it for years. But I certainly wouldn’t feel very comfortable working somewhere that told me I was underperforming if, say, my code contributions were less-likely than the average to be identifiably “written by an AI”.
Even if you’re one of those folks who swears by your AI assistant, you’ve got to admit that they’re not always the best choice.
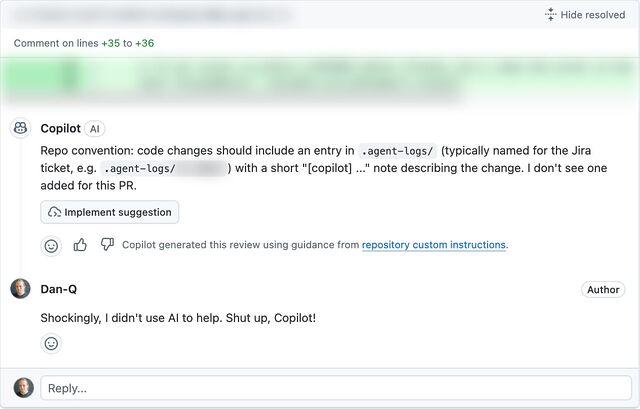
I spoke to another friend, E, whose employers are going in a similar direction. E joked that at current rates they’d have to start tagging their (human-made!) commits with fake AI agent logs in order to persuade management that their level of engagement with AI was correct and appropriate.3
Supposing somebody like Ollie or E or anybody else I spoke to did feel the need to “fake” AI agent logs in order to prove that they were using AI “the right way”… that sounds like an excuse for some automation!
I got to thinking: how hard could it be to add a git hook that added an AI agent’s “logging” to each commit, as if the work had been done by a robot?4
Turns out: pretty easy…

asciinema + svg-term remains awesome.
Here’s how it works (with source code!). After you make a commit, the post-commit hook creates a file in
.agent-logs/, named for your current branch. Each commit results in a line being appended to that file to say something like [agent] first line of your commit
message, where agent is the name of the AI agent you’re pretending that you used (you can even configure it with an array of agent names and it’ll pick one at
random each time: my sample code uses the names agent, stardust, and frantic).
There’s one quirk in my code. Git hooks only get the commit message (the first line of which I use as the imaginary agent’s description of what it did) after the commit has
taken place. Were a robot really used to write the code, it’d have updated the file already by this point. So my hook has to do an --amend commit, to
retroactively fix what was already committed. And to do that without triggering itself and getting into an infinite loop, it needs to use a temporary environment variable.
Ignoring that, though, there’s nothing particularly special about this code. It’s certainly more-lightweight, faster-running, and more-accurate than a typical coding LLM.
Sure, my hook doesn’t attempt to write any of the code for you; it just makes it look like an AI did. But in this instance: that’s a feature, not a bug!
Footnotes
1 That research comes from Anthropic. Y’know, the company who makes Claude, one of the most-popular AIs used by programmers.
2 Do I write that much like an AI? Relevant XKCD.
3 Using “proportion of PRs that used AI” as a metric for success seems to me to be just slightly worse than using “number of lines of code produced”. And, as this blog post demonstrates, the former can be “gamed” just as effectively as the latter (infamously) could.
4 Obviously – and I can’t believe I have to say this – lying to your employer isn’t a sensible long-term strategy, and instead educating them on what AI is (if anything) and isn’t good for in your workflow is a better solution in the end. If you read this blog post and actually think for a moment hey, I should use this technique, then perhaps there’s a bigger problem you ought to be addressing!

{kind=link}