In sympathy for our flood situation, my sister baked and posted us a big batch of her fantastic raisin & oatmeal cookies.

I’ve eaten like six of them already. Turns out I stress-eat. Who knew?
In sympathy for our flood situation, my sister baked and posted us a big batch of her fantastic raisin & oatmeal cookies.
I’ve eaten like six of them already. Turns out I stress-eat. Who knew?
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…
…
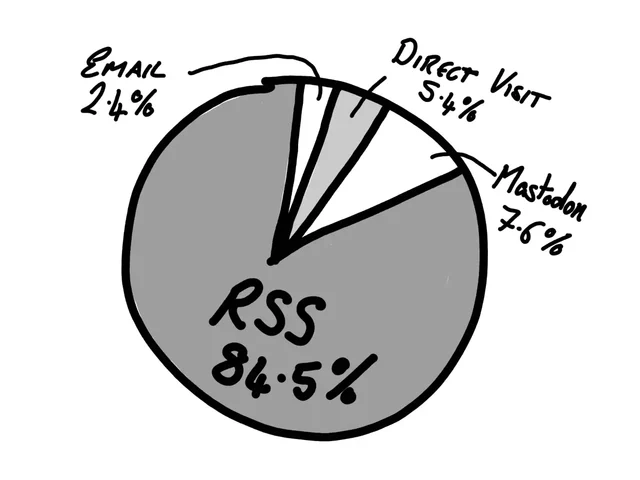
What this tells me?
Well, quite a lot, actually. It tells me that there’s loads of you fine people reading the content on this site, which is very heart-warming. It also tells me that RSS is by far the main way people consume my content. Which is also fantastic, as I think RSS is very important and should always be a first class citizen when it comes to delivering content to people.
…
I didn’t get a chance to participate in Kev’s survey because, well, I don’t target “RSS Zero” and I don’t always catch up on new articles – even by authors I follow closely – until up to a few weeks after they’re published1. But needless to say, I’d have been in the majority: I follow Kev via my feed reader2.
But I was really interested by this approach to understanding your readership: like Kev, I don’t run any kind of analytics on my personal sites. But he’s onto something! If you want to learn about people, why not just ask them?
Okay, there’s going to be a bias: maybe readers who subscribe by RSS are simply more-likely to respond to a survey? Or are more-likely to visit new articles quickly, which was definitely a factor in this short-lived survey? It’s hard to be certain whether these or other factors might have thrown-off Kev’s results.
But then… what isn’t biased? Were Kev running, say, Google Analytics (or Fathom, or Strike, or Hector, or whatever)… then I wouldn’t show up in his results because I block those trackers3 – another, different, kind of bias.
We can’t dodge such bias: not using popular analytics platforms, and not by surveying users. But one of these two options is, at least, respectful of your users’ privacy and bandwidth.
I’m tempted to run a similar survey myself. I might wait until after my long-overdue redesign – teased here – launches, though. Although perhaps that’s just a procrastination stemming from my insecurity that I’ll hear, like, an embarrassingly-low number of responses like three or four and internalise it as failing some kind of popularity contest4! Needs more thought.
1 I’m happy with this approach: I enjoy being able to treat my RSS reader as sort-of a “magazine”, using my categorisations of feeds – which are partially expressed on my Blogroll page – as a theme. Like: “I’m going to spend 20 minutes reading… tech blogs… or personal blogs by people I know personally… or indieweb-centric content… or news (without the sports, of course)…” This approach makes consuming content online feel especially deliberate and intentional: very much like being in control of what I read and when.
2 In fact, it’s by doing so – with a little help from Matthias Pfefferle – that I was inspired to put a “thank you” message in my RSS feed, among other “secret” features!
3 In fact, I block all third-party JavaScript (and some first-party JavaScript!) except where explicitly permitted, but even for sites that I do allow to load all such JavaScript I still have to manually enable analytics trackers if I want them, which I don’t. Also… I sandbox almost all cookies, and I treat virtually all persistent cookies as session cookies and I delete virtually all session cookies 15 seconds after I navigate away from a its sandbox domain or close its tab… so I’m moderately well-anonymised even where I do somehow receive a tracking cookie.
4 Perhaps something to consider after things have gotten easier and I’ve caught up with my backlog a bit.
This is an alternate history of the Web. The premise is true, but the story diverges from our timeline and looks at an alternative “Web that might have been”.
This is the story of P3P, one of the greatest Web standards whose history has been forgotten1, and how the abject failure of its first versions paved the way for its bright future decades later. But I’m getting ahead of myself…
Drafted in 2002 in the wake of growing concern about the death of privacy on the Internet, P3P 1.0 aimed to make the collection of personally-identifiable data online transparent. Hurrah, right?
Not so much. Its immediate impact was lukewarm to negative: developers couldn’t understand why their cookies were no longer being accepted by Internet Explorer 6, the first browser to implement the standard, and the whole exercise was slated as providing a false sense of security, not stopping actual bad guys, and an attempt to apply a technical solution to a political problem.2
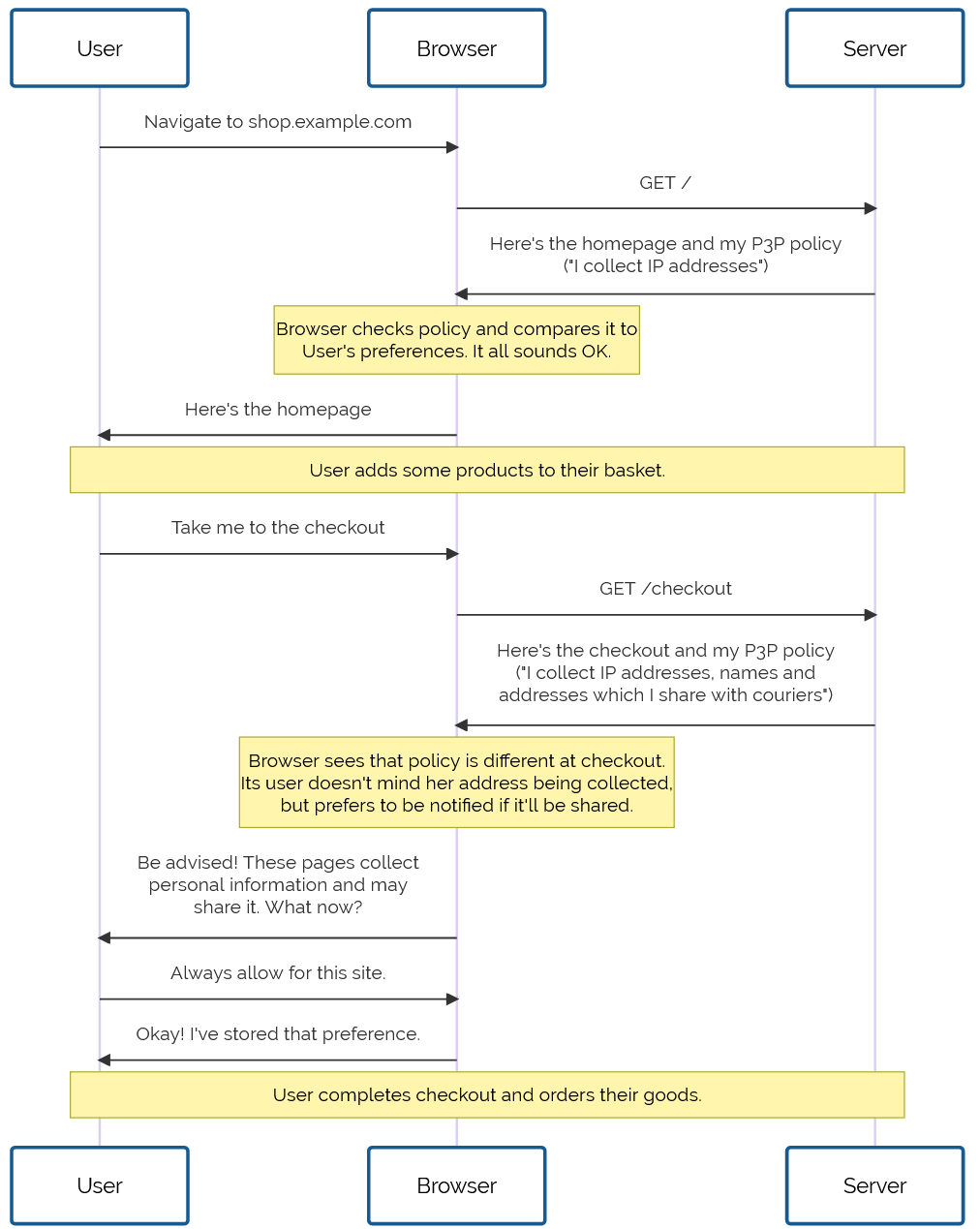
Developers are lazy3 and soon converged on the simplest possible solution: add a garbage HTTP header like P3P: CP="See our website for our privacy policy." and your cookies work just fine! Ignore the problem, ignore the
proposed solution, just do what gets the project shipped.
Without any meaningful enforcement it also perfectly feasible to, y’know, just lie about how well you treat user data. Seeing the way the wind was blowing, Mozilla dropped support for P3P, and Microsoft’s support – which had always been half-baked and lacked even the most basic user-facing controls or customisation options – languished in obscurity.
For a while, it seemed like P3P was dying. Maybe, in some alternate timeline, it did die: vanishing into nothing like VRML, WAP, and XBAP.
But fortunately for us, we don’t live in that timeline.
In 2009, the European Union revisited the Privacy and Electronic Communications Directive. The initial regulations, published in 2002, required that Web users be able to opt-out of tracking cookies, but the amendment required that sites ensure that users opted-in.
As-written, this confusing new regulation posed an immediate problem: if a user clicked the button to say “no, I don’t want cookies”, and you didn’t want to ask for their consent again on every page load… you had to give them a cookie (or use some other technique legally-indistinguishable from cookies). Now you’re stuck in an endless cookie-circle.4
This, and other factors of informed consent, quickly introduced a new pattern among those websites that were fastest to react to the legislative change:
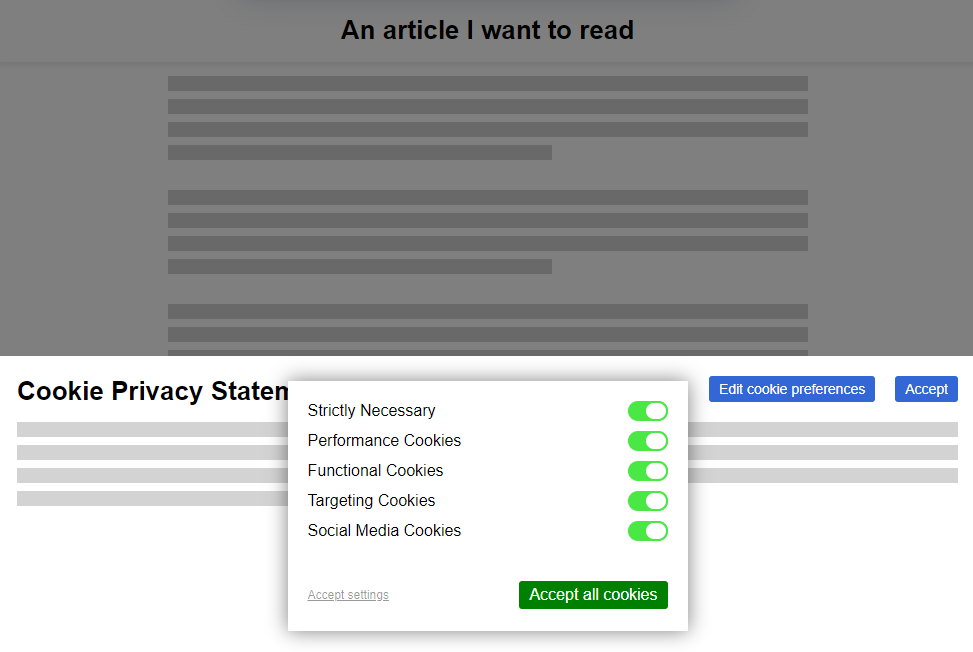
Web users rebelled. These ugly overlays felt like a regresssion to a time when popup ads and splash pages were commonplace. “If only,” people cried out, “There were a better way to do this!”
It was Professor Lorie Cranor, one of the original authors of the underloved P3P specification and a respected champion of usable privacy and security, whose rallying cry gave us hope. Her CNET article, “Why the EU Cookie Directive is a solved problem”5, inspired a new generation of development on what would become known as P3P 2.0.
While maintaining backwards compatibility, this new standard:
<link> tags alone,
Set-Cookie2: headers, which nobody used anyway, and
Internet Explorer at this point was still used by a majority of Web users. It still supported the older version of the standard, and – as perhaps the greatest gift that the much-maligned browser ever gave us – provided a reference implementation as well as a stepping-stone to wider adoption.
Opera, then Firefox, then “new kid” Chrome each adopted P3P 2.0; Microsoft finally got on board with IE 8 SP 1. Now the latest versions of all the mainstream browsers had a solid implementation6 well before the European data protection regulators began fining companies that misused tracking cookies.
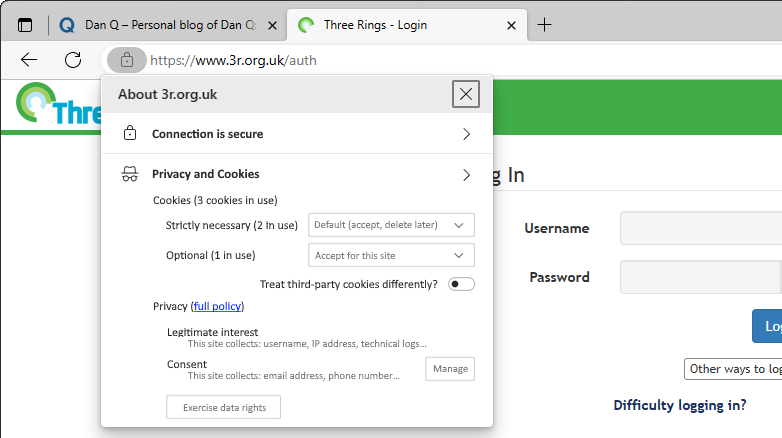
But where the story of P3P‘s successes shine brightest came in 2016, with the passing of the GDPR. The W3C realised that P3P could simplify both the expression and understanding of privacy policies for users, and formed a group to work on version 2.1. And that’s the version you use today.
When you launch a new service, you probably use one of the many free wizard-driven tools to express your privacy policy and the bases for your data processing, and it spits out a
template privacy policy. You need the human-readable version, of course, since the 2020 German court ruling that you cannot rely on a machine-readable privacy policy alone, but
the real gem is the P3P: 2.1 header version.
Assuming you don’t have any unusual quirks in your data processing (ask your lawyer!), you can just paste the relevant code into your server configuration and you’re good to go. Site users get a warning if their personal data preferences conflict with your data policies, and can choose how to act: not using your service, choosing which of your features to opt-in or out- of, or – hopefully! – granting an exception to your site (possibly with caveats, such as sandboxing your cookies or clearing them immediately after closing the browser tab).
Sure, what we’ve got isn’t perfect. Sometimes companies outright lie about their use of information or use illicit methods to track user behaviour. There’ll always be bad guys out there. That’s what laws are there to deal with.
But what we’ve got today is so seamless, it’s hard to imagine a world in which we somehow all… collectively decided that the correct solution to the privacy problem might have been to throw endless popovers into users’ faces, bury consent-based choices under dark patterns, and make humans do the work that should from the outset have been done by machines. What a strange and terrible timeline that would have been.
1 If you know P3P‘s history, regardless of what timeline you’re in: congratulations! You win One Internet Point.
2 Techbros have been trying to solve political problems using technology since long before the word “techbro” was used in its current context. See also: (a) there aren’t enough mental health professionals, let’s make an AI app? (b) we don’t have enough ventilators for this pandemic, let’s 3D print air pumps? (c) banks keep failing, let’s make a cryptocurrency? (d) we need less carbon in the atmosphere or we’re going to go extinct, better hope direct carbon capture tech pans out eh? (e) we have any problem at all, lets somehow shoehorn blockchain into some far-fetched idea about how to solve it without me having to get out of my chair why not?
3 Note to self: find a citation for this when you can be bothered.
4 I can’t decide whether “endless cookie circle” is the name of the New Wave band I want to form, or a description of the way I want to eventually die. Perhaps both.
5 Link missing. Did I jump timelines?
6 Implementation details varied, but that’s part of the joy of the Web. Firefox favoured “conservative” defaults; Chrome and IE had “permissive” ones; and Opera provided an ultra-configrable matrix of options by which a user could specify exactly which kinds of cookies to accept, linked to which kinds of personal data, from which sites, all somehow backed by an extended regular expression parser that was only truly understood by three people, two of whom were Opera developers.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
…why would cookies ever need to work across domains? Authentication, shopping carts and all that good stuff can happen on the same domain. Third-party cookies, on the other hand, seem custom made for tracking and frankly, not much else.
…
Then there’s third-party JavaScript.
In retrospect, it seems unbelievable that third-party JavaScript is even possible. I mean, putting arbitrary code—that can then inject even more arbitrary code—onto your website? That seems like a security nightmare!
I imagine if JavaScript were being specced today, it would almost certainly be restricted to the same origin by default.
…
Jeremy hits the nail on the head with third-party cookies and Javascript: if the Web were invented today, there’s no way that these potentially privacy and security-undermining features would be on by default, globally. I’m not sure that they’d be universally blocked at the browser level as Jeremy suggests, though: the Web has always been about empowering developers, acting as a playground for experimentation, and third-party stuff does provide benefits: sharing a login across multiple subdomains, for example (which in turn can exist as a security feature, if different authors get permission to add content to those subdomains).
Instead, then, I imagine that a Web re-invented today would treat third-party content a little like we treat CORS or we’re beginning to treat resource types specified by Content-Security-Policy and Feature-Policy headers. That is, website owners would need to “opt-in” to which third-party domains could be trusted to provide content, perhaps subdivided into scripts and cookies. This wouldn’t prohibit trackers, but it would make their use less of an assumed-default (develolpers would have to truly think about the implications of what they were enabling) and more transparent: it’d be very easy for a browser to list (and optionally block, sandbox, or anonymise) third-party trackers could potentially target them, on a given site, without having to first evaluate any scripts and their sources.
I was recently inspired by Dave Rupert to remove Google Analytics from this blog. For a while, there’ll have been no third-party scripts being delivered on this site at all, except through iframes (for video embedding etc., which is different anyway because there’s significantly less scope leak). Recently, I’ve been experimenting with Jetpack because I get it for free through my new employer, but I’m always looking for ways to improve how well my site “stands alone”: you can block all third-party resources and this site should still work just fine (I wonder if I can add a feature to my service worker to allow visitors to control exactly what third party content they’re exposed to?).
Just accepted @Facebook’s new cookie policy. 😋 @USENIXSecurity #usesec19

This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
For a philosopher, Helen Nissenbaum is a surprisingly active participant in shaping how we collect, use, and protect personal data. Nissenbaum, who earned her PhD from Stanford, is a professor of information science at Cornell Tech, New York City, where she focuses on the intersection of politics, ethics, and values in technology and digital media — the hard stuff. Her framework for understanding digital privacy has deeply influenced real-world policy.
In addition to several books and countless papers, she’s also coauthored privacy plug-ins for web browsers including TrackMeNot, AdNauseum, and Adnostic. Nissenbaum views these pieces of code as small efforts at rationalizing a marketplace where opaque consent agreements give consumers little bargaining power against data collectors as they extract as much information, and value from this information, as they can. Meanwhile, these practices offer an indefinite value proposition to consumers while compromising the integrity of digital media, social institutions, and individual security.
…
Last week I was talking to Alexander Dutton about an idea that we had to implement cookie-like behaviour using browser caching. As I first mentioned last year, new laws are coming into force across Europe that will require websites to ask for your consent before they store cookies on your computer. Regardless of their necessity, these laws are badly-defined and ill thought-out, and there’s been a significant lack of information to support web managers in understanding and implementing the required changes.

To illustrate one of the ambiguities in the law, I’ve implemented a tool which tracks site visitors almost as effectively as cookies (or similar technologies such as Flash Objects or Local Storage), but which must necessarily fall into one of the larger grey areas. My tool abuses the way that “permanent” (301) HTTP redirects are cached by web browsers.
[callout][button link=”http://c301.scatmania.org/” align=”right” size=”medium” color=”green”]See Demo Site[/button]You can try out my implementation for yourself. Click on the button to see the sample site, then close down all of your browser windows (or even restart your computer) and come back and try again: the site will recognise you and show you the same random number as it did the first time around, as well as identifying when your first visit was.[/callout]
Here’s how it works, in brief:

Compared to conventional cookie-based tracking (e.g. Google Analytics), this approach:
Moreover, this technique falls into a slight legal grey area. It would certainly be against the spirit of the law to use this technique for tracking purposes (although it would be trivial to implement even an advanced solution which “proxied” requests, using a database to associate conventional cookies with unique IDs, through to Google Analytics or a similar solution). However, it’s hard to legislate against the use of HTTP 301s, which are an even more-fundamental and required part of the web than cookies are. Also, and for the same reasons, it’s significantly harder to detect and block this technique than it is conventional tracking cookies. However, the technique is somewhat brittle and it would be necessary to put up with a reduced “cookie lifespan” if you used it for real.
[callout][button link=”http://c301.scatmania.org/” align=”right” size=”medium” color=”green”]See Demo Site[/button] [button link=”https://gist.github.com/avapoet/5318224″ align=”right” size=”medium” color=”orange”]Download Code[/button] Please try out the demo, or download the source code (Ruby/Sinatra) and see for yourself how this technique works.[/callout]
Note that I am not a lawyer, so I can’t make a statement about the legality (or not) of this approach to tracking. I would suspect that if you were somehow caught doing it without the consent of your users, you’d be just as guilty as if you used a conventional approach. However, it’s certainly a technically-interesting approach that might have applications in areas of legitimate tracking, too.
Update: The demo site is down, but I’ve update the download code link so that it still works.
This week, I was reading the new EU legislation [PDF] which relates to, among other things, the way that websites are allowed to use HTTP cookies (and similar technologies) to track their users. The Information Commissioner’s Office has released a statement to ask website owners to review their processes in advance of the legislation coming into effect later this month, but for those of you who like the big-print edition with pictures, here’s the short of it:
From 26th May, a website must not give you a cookie unless it’s either (a) an essential (and implied) part of the functionality of the site, or (b) you have opted-in to it. This is a stark change from the previous “so long as you allow opt-outs, it’s okay” thinking of earlier legislation, and large organisations (you know, like the one I now work for) in particular are having to sit up and pay attention: after all, they’re the ones that people are going to try to sue.
The legislation is surprisingly woolly on some quite important questions. Like… who has liability for ensuring that a user has opted-in to third-party cookies (e.g. Google Analytics)? Is this up to the web site owner or to the third party? What about when a site represents companies both in and outside the EU? And so on.
Seeking guidance, I decided to browse the website of the Information Commissioner’s Office. And guess what I found…

…not what I was looking for: just more circular and woolly thinking. But I did find that the ICO themselves does not comply with the guidance that they themselves give. Upon arriving at their site – and having never been asked for my consent – I quickly found myself issued with five different cookies (with lifespans of up to two years!). I checked their privacy policy, and found a mention of the Google Analytics cookie they use, but no indication about the others (presumably they’re not only “opt-out”, but also “secret”). What gives, guys?
Honestly: I’m tempted to assume that only this guy has the right approach. I’m all in favour of better cookie law, but can’t we wait until after the technological side (in web browsers) is implemented before we have to fix all of our websites? Personally, I thought that P3P policies (remember when those were all the rage?) had a lot of potential, properly-implemented, because they genuinely put the power into the hands of the users. The specification wasn’t perfect, but if it had have been, we wouldn’t be in the mess we are now. Perhaps it’s time to dig it up, fix it, and then somehow explain it to the politicians.
If you’re using CookieStore to manage sessions in your Ruby on Rails application, Rails 2.2 provides the great feature that you’re now able to use HTTPOnly cookies. These are a great benefit because, for compatible web browsers, they dramatically reduce the risk of a Cross Site Scripting (XSS) attack being able to be used to hijack your users’ sessions, which is particularly important on sites displaying user-generated content. You simply have to adjust your environment.rb file with something like:
config.action_controller.session = {
:session_key => ‘_session_id’,
:session_http_only => true,
:secret => ‘your-secret’
}
config.action_controller.session_store = :cookie_store
Unfortunately, the Rails developers didn’t see fit to extend HTTPOnly cookies to those of us using ActiveRecordStore, where the XSS risk is still just as real. To fill this gap, I’ve produced a very simple and only slightly-hackish plugin which overrides the functionality of Rails’ CGI::Cookie to force all cookies produced by Rails to be HTTPOnly, regardless of the session store being used.
To use it, download this file and extract it into your application’s vendor/plugins directory, and restart your application server. You can test that it’s working using Tamper Data, FireCookie, or whatever your favourite cookie sniffing tool is.