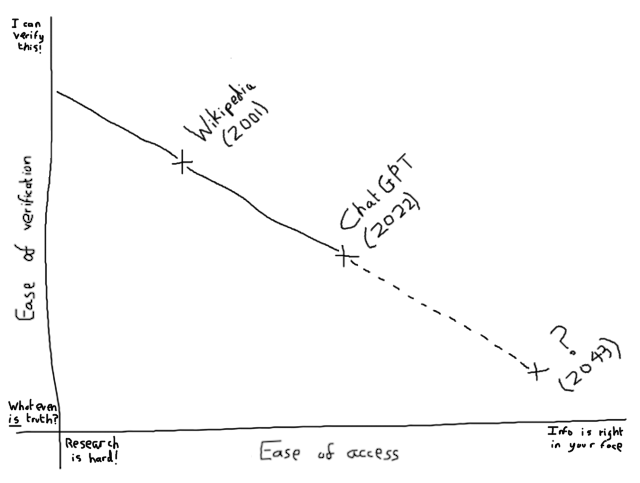
Humans invented Wikipedia, which made accessing information highly-convenient, at the risk of questions about its authenticity1.
Then humans invented GPTs, which made accessing information even more-convenient2
at the expense of introducing hallucinations that can be even harder to verify and check.
Is humanity’s long-term plan to invent something that spews complete nonsense that’s simultaneously impossible to conclusively deny?3
Footnotes
1 I’m well aware that in many subject areas Wikipedia routinely outranks many other
sources for accuracy. But the point remains, because you’ve no idea what the bias of randomuser123 is; even if you check the sources they cite, you don’t know what
sources they omitted to include. I love Wikipedia, but I can’t deny its weaknesses.
2 Sure, ChatGPT and friends aren’t always more-convenient. But if you need to
summarise information from several sources, you might find them a more-suitable tool than those which came before. Why do I feel the need to add so many footnotes to what should have
been a throwaway comment?
3 Actually, now I think about it, I’m confident that I can name some politicians who are
ahead of the machines, for now.
There’s a story that young network engineers are sometimes told to help them understand network stacks and/or the OSI model, and it goes something like this:
You overhear a conversation between two scientists on the subject of some topic relevant to their field of interest. But as you listen more-closely, you realise that the scientists
aren’t in the same place at all but are talking to one another over the telephone (presumably on speakerphone, given that you can hear them both, I guess). As you pay more attention
still, you realise that it isn’t the scientists on the phone call at all but their translators: each scientist speaks to their translator in the scientist’s own language, and the
translators are translating what they say into a neutral language shared with the other translator who translate it into the language spoken by the other scientist. Ultimately, the
two scientists are communicating with one another, but they’re doing so via a “stack” at their end which only needs to be conceptually the same as the “stack” at the other end as far
up as the step-below-them (the “first link” in their communication, with the translator). Below this point, they’re entrusting the lower protocols (the languages, the telephone
system, etc.), in which they have no interest, to handle the nitty-gritty on their behalf.
The two scientists are able to communicate with one another, but that communication is not direct.
This kind of delegation to shared intermediary protocols is common in networking and telecommunications. The reason relates to opportunity cost, or – for those of you who are Discworld fans – the Sam Vimes’ “Boots” Theory.
Obviously an efficiency could be gained here if all scientists learned a lingua franca, a universal shared second
language for their purposes… but most-often, we’re looking for a short-term solution to solve a problem today, and the short-term solution is to find a work-around that fits
with what we’ve already got: in the case above, that’s translators who share a common language. For any given pair of people communicating, it’s more-efficient to use a translator, even
though solving the global problem might be better accomplished by a universal second language (perhaps Esperanto, for valid if Eurocentric reasons!).
In the 1950s and 1960s, the concept of a self-driving car was already well-established… but the proposed mechanism for action was quite different to that which we see today.
The phenomenon isn’t limited to communications, though. Consider self-driving cars. If you look back to autonomous vehicle designs of the 1950s (because yes, we’ve been talking about
how cool self-driving cars would be for a long, long time), they’re distinctly different from the ideas we see today. Futurism of the 1950s focussed on adapting the roads themselves to
make them more-suitable for self-driving vehicles, typically by implanting magnets or electronics into the road surface itself or by installing radio beacons alongside highways to allow
the car to understand its position and surroundings. The modern approach, on the other hand, sees self-driving cars use LiDAR and/or digital cameras to survey their surroundings and complex computer hardware to interpret the data.
This difference isn’t just a matter of the available technology (although technological developments certainly inspired the new approach): it’s a fundamentally-different outlook! Early
proposals for self-driving cars aimed to overhaul the infrastructure of the road network: a “big solution” on the scale of teaching everybody a shared second language. But nowadays we
instead say “let’s leave the roads as they are and teach cars to understand them in the same way that people do.” The “big solution” is too big, too hard, and asking everybody
to chip in a little towards outfitting every road with a standardised machine-readable marking is a harder idea to swallow than just asking each person who wants to become an early
adopter of self-driving technology to pay a lot to implement a more-complex solution that works on the roads we already have.
In real life, these things spin much faster.
This week, Google showed off Duplex, a technology that they claim can perform the same kind of delegated-integration for our
existing telephone lives. Let’s ignore for a moment the fact that this is clearly going to be
overhyped and focus on the theoretical potential of this technology, which (even if it’s not truly possible today) is probably inevitable as chatbot technology improves: what does
this mean for us? Instead of calling up the hairdresser to make an appointment, Google claim, you’ll be able to ask Google Assistant to do it for you. The robot will call the
hairdresser and make an appointment on your behalf, presumably being mindful of your availability (which it knows, thanks to your calendar) and travel distance. Effectively, Google
Assistant becomes your personal concierge, making all of those boring phone calls so that you don’t have to. Personally, I’d be more than happy to outsource to a computer every time
I’ve had to sit in a telephone queue, giving the machine a summary of my query and asking it to start going through a summary of it to the human agent at the other end while I make my
way back to the phone. There are obviously ethical
considerations here too: I don’t like being hounded by robot callers and so I wouldn’t want to inflict that upon service providers… and I genuinely don’t know if it’s better or
worse if they can’t tell whether they’re talking to a machine or not.
I, for one, welcome our pizza-ordering overlords.
But ignoring the technology and the hype and the ethics, there’s still another question that this kind of technology raises for me: what will our society look like when this kind of
technology is widely-available? As chatbots become increasingly human-like, smarter, and cheaper, what kinds of ways can we expect to interact with them and with one another? By
the time I’m able to ask my digital concierge to order me a pizza (safe in the knowledge that it knows what I like and will ask me if it’s unsure, has my credit card details, and is
happy to make decisions about special offers on my behalf where it has a high degree of confidence), we’ll probably already be at a point at which my local takeaway also has a
chatbot on-staff, answering queries by Internet and telephone. So in the end, my chatbot will talk to their chatbot… in English… and work it out between the two of them.
Let that sink in for a moment: because we’ve a tendency to solve small problems often rather than big problems rarely and we’ve an affinity for backwards-compatibility, we will probably
reach the point within the lifetimes of people alive today that a human might ask a chatbot to call another chatbot: a colossally-inefficient way to exchange information built
by instalments on that which came before. If you’re still sceptical that the technology could evolve this way, I’d urge you to take a look at how the technologies underpinning the
Internet work and you’ll see that this is exactly the kind of evolution we already see in our communications technology: everything gets stacked on top of a popular existing
protocol, even if it’s not-quite the right tool for the job, because it makes one fewer problem to solve today.
Hacky solutions on top of hacky solutions work: the most believable thing about Max Headroom’s appearance in
Ready Player One (the book, not the film: the latter presumably couldn’t get the rights to the character) as a digital assistant was the versatility of his conversational
interface.
“See? My laptop says we should hook up.”
By the time we’re talking about a “digital concierge” that knows you better than anyone, there’s no reason that it couldn’t be acting on your behalf in other matters. Perhaps in the
future your assistant, imbued with intimate knowledge about your needs and interests and empowered to negotiate on your behalf, will be sent out on virtual “dates” with other people’s
assistants! Only if it and the other assistant agree that their owners would probably get along, it’ll suggest that you and the other human meet in the real world. Or you could have
your virtual assistant go job-hunting for you, keeping an eye out for positions you might be interested in and applying on your behalf… after contacting the employer to ask the kinds of
questions that it anticipates that you’d like to know: about compensation, work/life balance, training and advancement opportunities, or whatever it thinks matter to you.
We quickly find ourselves colliding with ethical questions again, of course: is it okay that those who have access to more-sophisticated digital assistants will have an advantage?
Should a robot be required to identify itself as a robot when acting on behalf of a human? I don’t have the answers.
But one thing I think we can say, based on our history of putting hacky solutions atop our existing ways of working and the direction in which digital assistants are headed, is
that voice interfaces are going to dominate chatbot development a while… even where the machines end up talking to one another!