Not even thanks to Daylight Saving but just because I felt energised and excited, I got up to watch the sunrise this morning… before starting work on a new Three Rings feature!

Not even thanks to Daylight Saving but just because I felt energised and excited, I got up to watch the sunrise this morning… before starting work on a new Three Rings feature!
This checkin to GCARTJD 5Gee, Under the Oak Tree reflects a geocaching.com log entry. See more of Dan's cache logs.
This one’s going to bug me! The second nearest cache to this week’s volunteering event accommodation and I had to DNF it!? Poked my fingers into every hidey hole I could find (while a nearby goose honked at me: maybe it was mocking me, or perhaps it was saying “it’s on your left” – afraid I don’t speak goose) before giving up. It’s right on my doorstep, though, so I may well be back for another attempt!
This checkin to GCARTJE 1602 reflects a geocaching.com log entry. See more of Dan's cache logs.
When I drove along this lane yesterday evening I didn’t appreciate how wonderful it’d look under the morning sun. An easy find with thanks to the cache title! TFTC!

This checkin to GCARTJK Hencote Lane reflects a geocaching.com log entry. See more of Dan's cache logs.
Some fellow volunteers and I are staying in the nearby Hencote Farm for a week of work on software that helps charities work more efficiently. As has become a longstanding tradition for me at these events, I woke early for a walk and this morning was treated, as I made my way through the vineyards, to the especially wonderful view across the valley.

I’m not sure I was supposed to exit the farm grounds the way I did, but I was eventually able to get out and was pleased to discover this cache was nearby. QEF once I’d chosen the correct host. TFTC.
Kicking off 3Camp 2026, our annual volunteering event, with the traditional “receive and sort a ludicrous amount of groceries” activity.

Most-often when a toaster has a ‘cancel’ button it’s simply labelled ‘cancel’, ‘stop’, or with a cross. But this week, I discovered a toaster that uses the ‘eject’ icon – like you’d find on a VHS tape recorder – on its button.

At first I thought this was an unusual user interface choice, but I’m coming around to it. It feels like a more-accurate and skeuomorphic representation of what actually happens than a cross suggests.
But the existence of toasters like this one does necessarily mean that, some day, some Gen Alpha will see a tape deck in, like, a museum or something, and will say ‘hey, that’s cute: the button you press to pop the tape out is the same as the one you use to pop your toast out’.
I was pretty ill yesterday. It’s probably a combination of post-flood stress and my shitty lungs’ ability to take a sore throat and turn it into something that leaves me lying in bed and groaning.
I spent most of the morning in and out of a fitful sleep, during which I dreamed up the most-bizarre application: a GPS tracker app that, after being told your destination and what you were eating, reported your journey progress to social media by describing where you were going and how much of your food was left1.
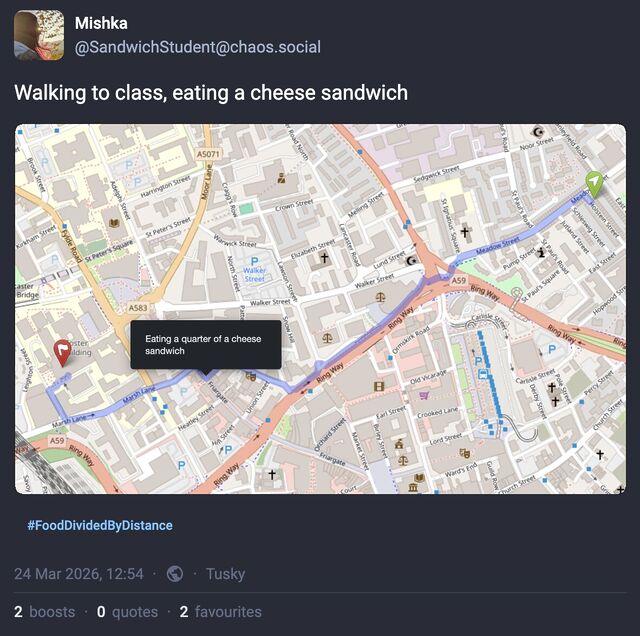
I should be clear that in the dream, I wasn’t the one that invented this concept; in fact, I didn’t even understand it at first (maybe I still don’t!). In the dream I was at some kind of unconference event with a variety of “make art with the Web” types, and I missed a session by falling asleep2. I woke (within the dream) right before the session ended and rushed in to see what was being presented, and only got the tail-end of the explanation of how a project – this project – worked, after which I felt rushed to try to understand it before somebody inevitably tried to talk to me about it.
But it could work, couldn’t it? If you’re one of those people who routinely tracks and shares their location (like Aaron Parecki, whose heatmapping inspired my own) or journeys (like Jeremy Keith does), it’s a way to add a bit of silliness to that sharing.
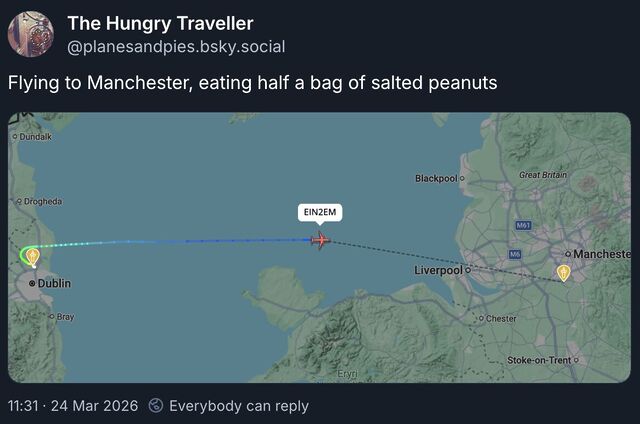
I’m probably not going to implement this. It is, in the end, the kind of stupidity that could (should?) only appear in the dreams of somebody who’s got a bad head cold.
But if you manage to take this idea and turn it into something… actually good?… let me know!
Or if you’ve just got a cool, “Web 2.0-ey” idea for the name of an app that tracks both your journey progress and your meal consumption, I’d love to hear that too.
1 Under the assumption that its consumption would be evenly distributed throughout the journey. Because everybody does that, right? Counting the number of steps they make before taking another equal-sized bite. Right?
2 Even in my dreams, I can dream of falling asleep. And, sometimes, of dreaming. A fever probably helps.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
That’s all you need to know. If you’re doing it, you’re doing it right. If you have decided to reclaim ownership of your place on the web, you’re doing it right. It doesn’t matter how you did it. It doesn’t matter if you’re self-hosting or using a SAAS. It doesn’t matter if your content lives on a database or in a TXT file. It doesn’t matter if you did everything yourself or you paid someone to do it for you. It doesn’t matter if you post once a day or once a year. What matters is that you’re doing it. Your effort is commendable. You deserve to be thanked so, thank you.
Wonderful words from Manu, there, that I think every blogger needs to be told once in a while. You have permission to write stuff. There isn’t a wrong way.
Also worth reading is his “2-step process for AI-free blogging”.
I wish I could be as pithy as Manu. But I’mma keep blogging anyway. After all; I’m doing it right!
Like many in the UK, I’m dismayed every time I see the plague of St. George’s Cross (flag of England) that nationalists have been hanging on lamp posts on recent years.
So it gave me great joy to see that this lamp post had recently acquired a (larger!) pride flag. 🏳️🌈

If we’re going to become a country that hangs flags everywhere… I’d much rather that they be flags that speak of inclusivity and diversity. ❤️
This is a reply to a post published elsewhere. Its content might be duplicated as a traditional comment at the original source.
hey @dan –
how do you find things you want to blog about? is it just about letting out one’s thoughts and feelings and some sort of catch-up to one’s latest projects?
probably will start a blog of my own soon™ :3
What an interesting question, and not one I’ve heard before.
I’ve not heard it before… probably because my blogging is… eclectic! Sometimes I blog about technology. Sometimes I blog about geocaching and geohashing. Sometimes I blog about what’s going on in my life. Sometimes I blog about news, politics, and what’s going on in the world. Sometimes I blog just to share weird things I’ve seen on the Internet.
(I’ve sometimes worried that my approach to blogging alienates every conceivable audience. I mean: who wants to read all the topics above? But it helped me a lot to remind myself that I blog, primarily, for myself. I am my own target audience! Everybody else comes second.)
I certainly have more things that I want to blog about than that I actually do. And even for the things I start, I often don’t finish: I’ve got literally hundreds of incomplete drafts, and perhaps even more “concepts” noted down in Obsidian that I’ve never even started writing about.
It’s all a little skewed right now because I’ve kinda been trying to achieve the #100DaysToOffload challenge – which I’ve achieved for six consecutive years so far – in the first hundred days of 2026! Given that it’s called “100 Days To Offload” I don’t feel like it’s legitimate to claim it for 100 blog posts that aren’t on different days (otherwise I’d have achieved it already, with about 149 in the first 82 days of this year).
So yeah: I’m currently working towards a hundred-day streak, and that’s almost certainly having me blog more than I might “organically”. To that end, I’m often digging out old drafts and finalising them, right now, or else being more “impulsive” in my blogging, compared to the norm. This lunchtime, for example, I took a cycle, and it gave me a sense of normalcy that’s been somewhat missing in my life recently, and I considered writing a blog post about the experience. Impulsive, y’see!
But in general… my “process”, such as it is… is that I just look at what interests me today. There’s no secret to blogging as prolifically as I do: you’ve just got to start writing, and then keep writing. That’s all there is to it.
It’s 38 days since our house was damaged in a flash flood, and today’s the first of our ‘BER’ assessment. BER stands for Beyond Economical Repair. It basically means that anything on the list is something that the insurance company intend to ‘write off’: to declare irreparable or not-worth repairing and scrap, replacing it with an equivalent new one.

So today, while I work, I’m watching a trio of men carry all of the soft furnishings, white goods, and rugs, plus any plywood/MDF-based furniture that got soaked into a pair of vans on the driveway, making notes where possible of the makes and models of things as they go.
My home is rapidly becoming more cavernous and echoey.
This is a repost promoting content originally published elsewhere. See more things Dan's reposted.
The Gell-Mann Amnesia Effect of AI is a pretty well documented phenomenon:
The Gell-Mann amnesia effect is a cognitive bias describing the tendency of individuals to critically assess media reports in a domain they are knowledgeable about, yet continue to trust reporting in other areas despite recognizing similar potential inaccuracies.
Summarizing, AI sounds like a incredible genius synthesizing the world’s knowledge right up until you ask it about the thing you know about, then it’s an idiot. Even knowing about this phenomenon and having experienced it countless times, LLMs have an intoxicating quality to them.
…
I remember one time, maybe in the mid-1990s, when I saw a shopping channel (remember those? oh god, they’re still a thing, aren’t they?) where the host was trying to sell a personal computer. And… clearly, they knew absolutely nothing about it. They kept hitting on the same two or three talking points they’d been given (“mention the quad-speed CD-ROM drive!”) and fumbling their way through, and it gave me a revelation:
I knew enough about computers that I could see that the presenter was bullshitting their way through the segment. But there are plenty of things that I don’t know much about, which are also sold on this same show. Duvets, jewellery, glassware… I’m nowhere near as much an expert on these as I was on PC featuresets. Is there something inherently incomprehensible about computers? No. So it’s reasonable to assume that these salespeople probably know equally-little about everything they sell, it’s just that I don’t have the knowledge base to be able to see that.
That’s what GenAI often feels like, to me. Having collated all of the publicly-available knowledge it could find into its model doesn’t make it smarter than the smartest humans, it brings it towards probably something slightly-above-the-average in any given subject, depending on the topic. If I ask an LLM about something that I don’t understand well, it produces often highly-believable answers, but if I ask it about something that I’m an expert in, it can come off as a fool.
I’m very interested in how we teach information literacy in this new world of rapidly-generated highly-believable nonsense.
Anyway: Dave’s post doesn’t go in that direction – instead, he’s got some clever thoughts about how the “convenience” of a “good enough” AI-driven solution to any given problem risks us seeing humans as the friction point, which ultimately works against those very humans who are looking to benefit from the technology:
…We need experts to share what they know and improve the quality of our work, generated or otherwise. We even need idiots to make sure we can break ideas down into their simplest form that everyone, agents or human, understand. People can have bad attitudes, be shitty, and have wrong opinions… but people are not friction. An LLM may be able to autocorrect its way into a plausible human response, but it’s not people. It doesn’t care if it’s right or wrong.
…
This checkin to GC79ZK3 Wootton Word Wall reflects a geocaching.com log entry. See more of Dan's cache logs.
I’ve never come across the TV series nor this kind of puzzle before, and opted to solve it in an unconventional way. We’re living for a week in an AirBnB nearby – one in a long series of short term lets while we and our insurance company find us sonewhere longer-term, following flood damage to our house last month.
This morning, the younger geokid and I came out for a walk with the geopup. After a little difficulty getting a GPSr fix we eventuality found a good-looking host, and after a few laps we had the well-camouflaged container in our hands. A good sized, well maintained container and an interesting puzzle, even if the way we solved it might be considered by some to have been cheating!
SL (using my own pencil; the one in the cache is blunt and I forgot to bring my sharpener), TFTC.
The other day I needed to solve a puzzle1. Here’s the essence of it: there was a grid of 16 words. They needed to be organised into four thematic “groups” of four words each; then each group needed to be sorted alphabetically.
Each item in each group had a two-character code associated with it: these were to be concatenated together into a string and added to a pastebin.com/... URL. The correct
four URLs would each contain a quarter of the answer to the puzzle.
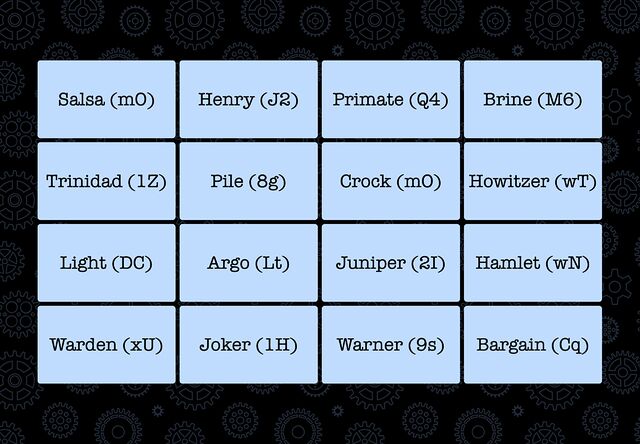
I’m sure I could have solved the puzzle. But I figured it’d be more satisfying to solve a different puzzle, with the same answer: how to write a program that finds the correct URLs for me.
Here’s what I came up with:
#!/usr/bin/env ruby require 'set' require 'net/http' require 'uri' FRAGMENTS = [ 'Salsa|mO', 'Henry|J2', 'Primate|Q4', 'Brine|M6', 'Trinidad|1Z', 'Pile|8g', 'Crock|mO', 'Howitzer|wT', 'Light|DC', 'Argo|Lt', 'Juniper|2I', 'Hamlet|wN', 'Warden|xU', 'Joker|1H', 'Warner|9s', 'Bargain|Cq', ] result = FRAGMENTS.permutation(4).to_a sorted_results = result.map { |combination| combination.sort }.uniq shortened_results = sorted_results.map { |combination| combination.map { |fragment| fragment.split('|').last } } urls = shortened_results.map { |combination| "https://pastebin.com/#{combination.join('')}" } START_AT = 0 urls[START_AT..].each_with_index do |url, idx| uri = URI(url) response = Net::HTTP.get_response(uri) print '.' if response.code != '404' puts "\nHIT at index #{idx + START_AT}: #{url}" end sleep(rand(0..3) * 0.1) end
Here’s how it works:
I kicked off the program and got on with some work. Meanwhile, in the background, it permuted the puzzle for me. Within a few minutes, I had four working pastebin URLs, which collectively gave me the geocache’s coordinates. Tada!
I still solved a puzzle. It probably took me, as a strong programmer, about as long as it would have taken me to solve the puzzle the conventional way were I a strong… “only connect”-er5. But I adapted the puzzle into a programming puzzle and solved it a completely different way, . Here’s the arguments, as I see them:
Click on a 😡 or a 🧠 to let me know whether you think I cheated or not, or drop me a comment if you’ve got a more-nuanced opinion.
1 Okay, okay, it was for a geocache.
2 Don’t try to solve this one; it’s randomly generated.
3 This version of the program is adapted to the fake gameboard I showed earlier. You won’t get any meaningful results by running this program in its current state. But you could quickly adapt it to a puzzle of this format, I suppose.
4 It occurred to me that it could have been more-efficient to eliminate from the list any possibilities that are ruled-out by any existing finds… but efficiency is a balancing act. For a program that you’ll only run once – and in the background, while you do other things, to boot – there’s a tipping point at which it’s better to just get it running than it is to improve its performance.
5 There’s a clear parallel here to the various ways in which I’ve solved jigsaw-puzzle-based geocaches, because I’m far more interested in (a) programming and (b) getting out into the world and finding geocaches in interesting places than I am in doing a virtual jigsaw puzzle!
This is a reply to a post published elsewhere. Its content might be duplicated as a traditional comment at the original source.
100%. If I “get in early” on something, it’s because that thing interests me, not because I’m betting on its future. With a hundred new ideas a day and only one of them “making it”, it’s a fools’ game to try to jump on board every bandwagon that comes along.
With cryptocurrencies, though, I’m fortunate enough to have an even better comeback at the cryptobros that try to shill me whatever made-up currency they’re “investing” in today: I’ve already done better than they ever will, at them.
When Bitcoin first appeared, I took a technical interest in it. I genuinely never anticipated it’d take off (I made the same incorrect guess with MP3s, too!), but I thought it was a fun concept to play about with. The only Bitcoins I ever paid for must’ve been worth an average of 50p each, or so.
I sold my entire wallet of Bitcoins when they hit around £750 each. I know a tulip economy when I see one, I thought. Plus: I was no longer interested in blockchains now I was seeing how they were actually being used: my interest had been entirely in the technology and its applications, not in the actual idea of a currency!
Sure, I kick myself ocassionally, given that I later saw the value rise to tens of thousands of pounds each. But hey, I was never in it for the money anyway.
So yeah, I tell cryptobros; I already made a 1500% ROI on cryptocurrency. And no, I’m not buying any cryptocurrencies any more. Whatever they think “getting in early” was, they’re wrong, because I was there years ahead of them and I wasn’t even doing it to “get in early”; I did it because it was interesting. And honestly, isn’t that a better story to be able to tell?