Known Leaders is an open-source
program that combines WikiData with a random generator to come up with almost-invariably inaccurate but sometimes hilarious facts. Jim Kang came up with it during Recurse Center‘s Never Graduate Week. Go have a play, or read more about how and why he made it.
When geocachers find a geocache, they typically “log” their find both in the cache’s paper logbook and on one of the online listing sites on which the cache’s coordinates can be
found.1
A typical geocacher can find their cache container, logbook, swag, toothbrush, face flannel, soap, tin of biscuits, flask, compass, and most-importantly towel. Hang on, I’ve got my
geekeries crossed again. Photo courtesy cachemania, used under a CC BY-SA license.
I’ve been finding and hiding geocaches for… a long while, so I’ve
seen lots of log entries from people who’ve found my caches (and those of others). And it feels to me like the average length of a
geocaching log entry is getting shorter.
A single emoji is probably the shortest log entry I’ve ever seen. I’m
not claiming that its
cachedeserves a longer log (it’s far from my best work!): just using it as an example of a wider trend towards shorter logs.
“It feels to me like…” isn’t very scientific, though. Let’s see if we can do better.
Getting the data
To test my hypothesis, I needed a decade or so of logs. I didn’t want to compare old caches to new caches (in case people are biased by the logs before them) so I used Geocaching.com’s
own search to open the pages for the 500 caches closest to me that are each at least 10 years old.
My browser hates me right now.
I hacked together a quick
userscript to save all of the logs in a way that was easier than copy-pasting each of them but still didn’t involve hitting Geocaching.com’s API or automating bulk-scraping (which would violate their terms of service). Clicking each of several hundred tabs once every few minutes in
the background while I got on with other things wasn’t as much of an ordeal as you might think… but it did take a while.
Needless to say I only had to go through the cycle a couple of times before I set up a keyboard shortcut.
I mashed that together into a CSV file and for the first time looked at the size of my sample data: ~134,000 log entries,
spanning 20 years. I filtered out everything over 10 years old (because some of the caches might have no logs that old) and stripped out everything that wasn’t a “found it” or “didn’t
find it” log.
That gave me a far more-reasonable ~80,000 records with which I could make Excel cry.2
Results
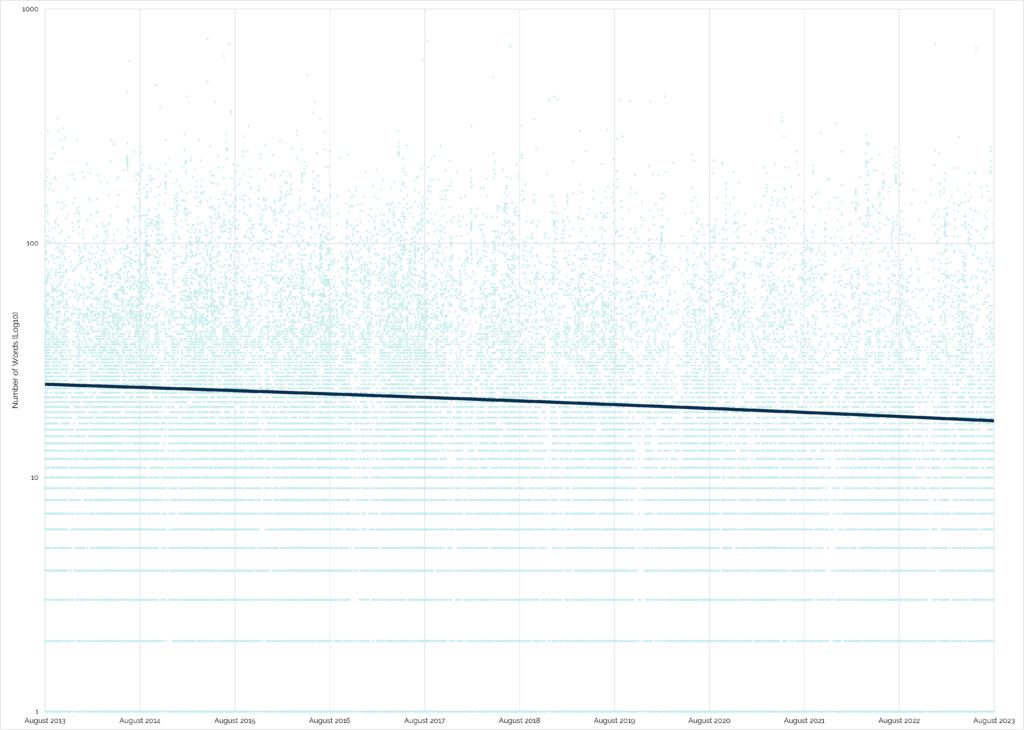
It looks like my hunch is right. The wordcount of “found” logs on traditional and multi-stage caches has generally decreased over time:
“Found” logs are great for cache owner morale: a simple “TFTC” is a lot less-inspiring that hearing about your adventure to get
to that point.
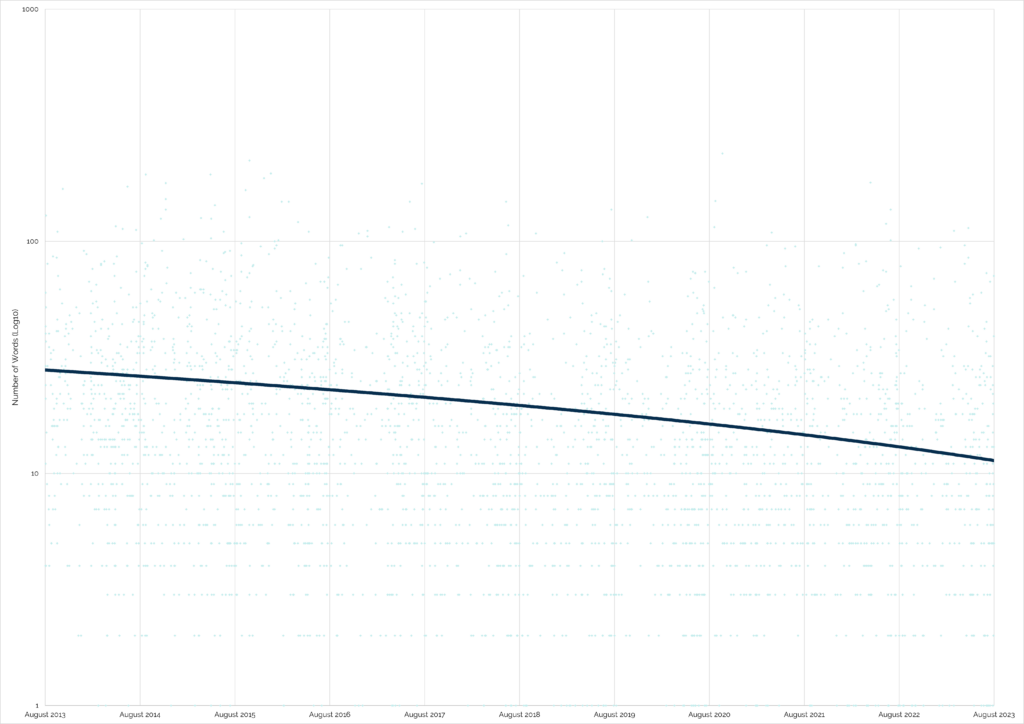
“Did not find” logs, which can be really helpful for cache owners to diagnose problems with their caches, have an even more-pronounced dip:
Geocachers are just typing “Didn’t find it” and moving on. Without an indication of the conditions at the GZ, how long they spent
looking, or an indication of whether the hint was followed, that doesn’t give a cache owner much to work with.
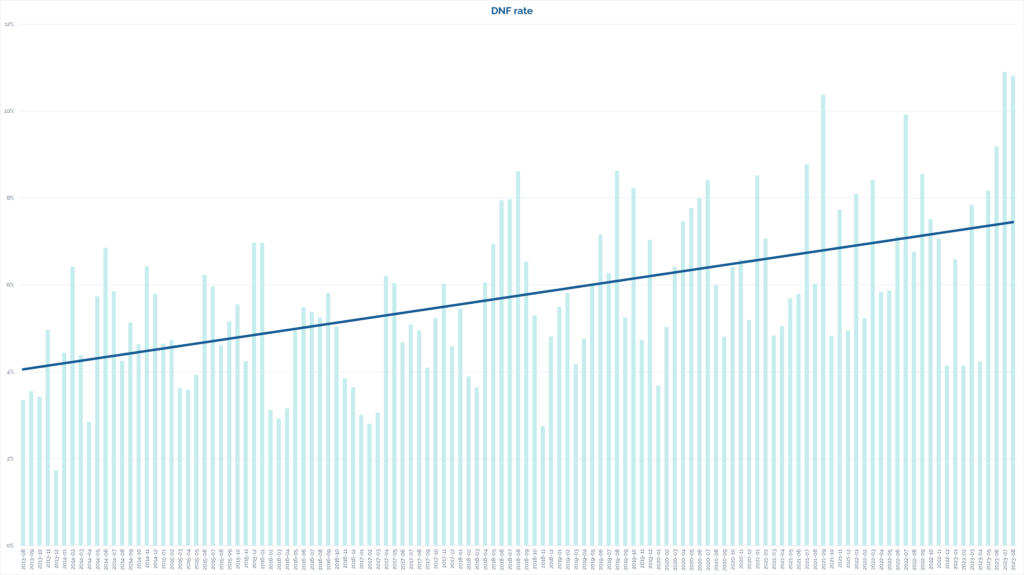
When I first saw that deep dip on the average length of “did not find” logs, my first thought was to wonder whether the sample might not be representative because the did-not-find rate
itself might have fallen over time. But no: the opposite is true:
A higher proportion than ever of geocachers are logging that they couldn’t find the cache, but they’re simultaneously saying less than ever about it.
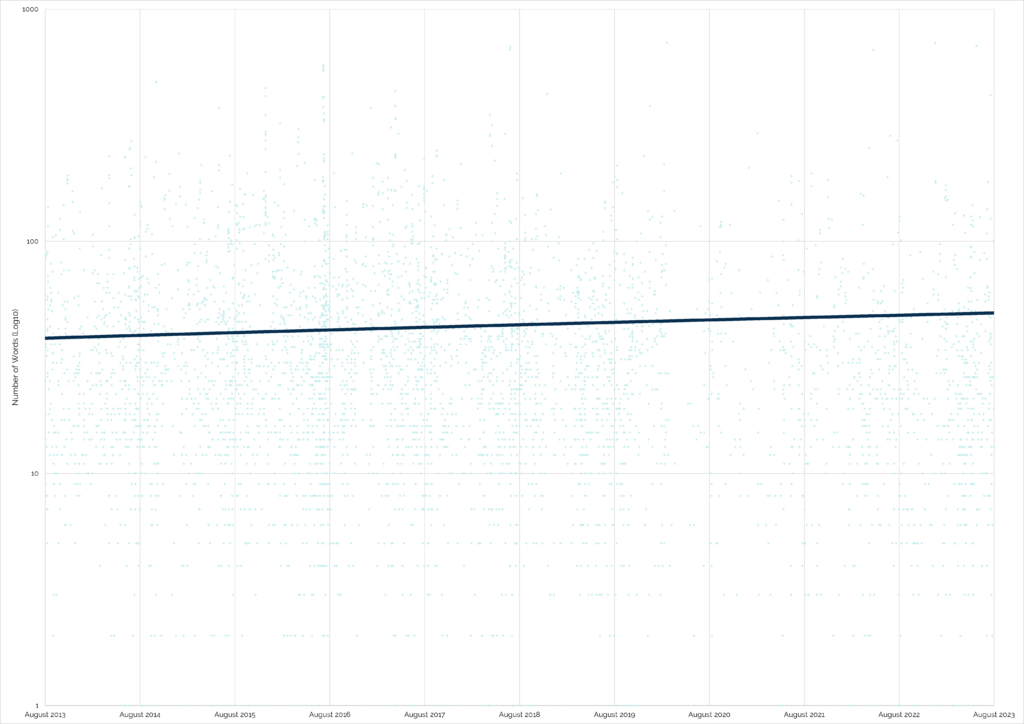
Strangely, the only place that the trend is reversed is in “found” logs of virtual caches, which have seen a slight increase in verbosity.
I initially assumed that this resulted from “virtual
rewards” from 2017 onwards3
but this doesn’t make any sense because all of the caches in my study are 10+ years old: none of them can be “virtual rewards”.
Conclusion
Within the limitations of my research (80,000 logs from 500 caches each 10+ years old, near me), there are a handful of clear trends over the last decade:
Geocachers are leaving increasingly concise logs when they find geocaches.
That phenomenon is even more-pronounced when they don’t find them.
And they’re failing-to-find caches and giving up with significantly greater frequency.
Are these trends a sign of shortening attention spans? Increased use of mobile phones for logging? Use of emoji and acronyms to pack more detail into shorter messages? I don’t know.
I’d love to see some wider research, perhaps by somebody at Geocaching.com HQ (who has database access and is thus able to easily extract
enough data for a wider analysis!). I’m also very interested in whether the identity of the cache finder has an impact on log length: is it impacted by how long ago they
started ‘caching? Whether or not they have hidden caches of their own? How many caches they’ve found?
But personally, I’m just pleased to have been able to have a question in the back of my mind and – through a little bit of code and a little bit of data-mashing – have a pretty good go
at answering it.
Footnotes
1 I have a dream that someday cache logging could be powered by Webmentions or ActivityPub or some similar decentralised-Web technology, so that cachers can log their finds on any site on which a cache is listed or
even on their own site and have all the dots joined-up… but that’s pretty far-fetched I’m afraid. It’s not stopping some of us from experimenting with possible future standards,
though…
2 Just for fun, try asking Excel to extrapolate a second-order polynomial trendline across
80,000 pairs of datapoints. Just don’t do it if you’re hoping to use your computer for anything in the next quarter hour.
3 With stricter guidelines on how a “virtual rewards” virtual caches should work than
existed for original pre-2005 virtuals, these new virtuals are more-likely than their predecessor to encourage or require longer logs.