Rendering text, how hard could it be? As it turns out, incredibly hard! To my knowledge, literally no system renders text “perfectly”. It’s all best-effort, although some efforts
are more important than others.
…
Just so you have an idea for how a typical text-rendering pipeline works, here’s a quick sketch:
Styling (parse markup, query system for fonts)
Layout (break text into lines)
Shaping (compute the glyphs in a line and their positions)
Rasterization (rasterize needed glyphs into an atlas/cache)
Composition (copy glyphs from the atlas to their desired positions)
Unfortunately, these steps aren’t as clean as they might seem.
…
Delightful dive into the variety of issues that face developers who have to implement text rendering. Turns out this is, and might always remain, an unsolved issue.
Some years ago, a friend of mine told me about an interview they’d had for a junior programming position. Their interviewer was one of that particular breed who was attached to
programming-test questions: if you’re in the field of computer science, you already know that these questions exist. In any case: my friend was asked to write pseudocode to shuffle a
deck of cards: a classic programming problem that pretty much any first-year computer science undergraduate is likely to have considered, if not done.
Let’s play at writing software. Rather than a computer, we’ll use paper. But to make it sound techy, we’ll call it “pseudocode”.
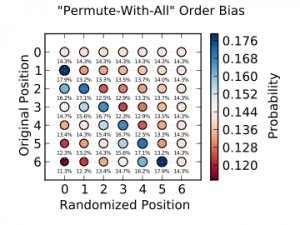
There are lots of wrong ways to programmatically shuffle a deck of cards, such as the classic “swap the card in each position with the card in a randomly-selected position”,
which results in biased
results. In fact, the more that you think in terms of how humans shuffle cards, the less-likely you are to come up with a good answer!
If we shuffled a deck of six cards with this ‘broken’ algorithm, for example, we’d be more-likely to find the card that was originally in second place at the top of the deck than in
any other position. This kind of thing REALLY matters if, for example, you’re running an online casino.
The simplest valid solution is to take a deck of cards and move each card, choosing each at random, into a fresh deck (you can do this as a human, if you like, but it takes a while)…
and that’s exactly what my friend suggested.
The interviewer was ready for this answer, though, and asked my friend if they could think of a “more-efficient” way to do the shuffle. And this is where my friend had a brain fart and
couldn’t think of one. That’s not a big problem in the real world: so long as you can conceive that there exists a more-efficient shuffle, know what to search for, and can
comprehend the explanation you get, then you can still be a perfectly awesome programmer. Demanding that people already know the answer to problems in an interview setting
doesn’t actually tell you anything about their qualities as a programmer, only how well they can memorise answers to stock interview questions (this interviewer should have stopped this
line of inquiry one question sooner).
Writing a program to shuffle a deck takes longer than just shuffling it, but that’s hardly the point, is it?
The interviewer was probably looking for an explanation of the modern form of the Fisher-Yates shuffle algorithm, which does the same thing as my friend suggested but without needing to start a “separate”
deck: here’s a video demonstrating it. When they asked for greater efficiency, the interviewer was probably looking for a more
memory-efficient solution. But that’s not what they said, and it’s certainly not the only way to measure efficiency.
When people ask ineffective interview questions, it annoys me a little. When people ask ineffective interview questions and phrase them ambiguously to boot, that’s just makes
me want to contrive a deliberately-awkward answer.
So: another way to answer the shuffling efficiency question would be to optimise for time-efficiency. If, like my friend, you get a question about improving the efficiency of a
shuffling algorithm and they don’t specify what kind of efficiency (and you’re feeling sarcastic), you’re likely to borrow either of the following algorithms. You won’t find
them any computer science textbook!
Complexity/time-efficiency optimised shuffling
Precompute and store an array of all 52! permutations of a deck of cards. I think you can store a permutation in no more than 226 bits, so I calculate that 2.3 quattuordecillion yottabytes would be plenty sufficient to store such an array. That’s
about 25 sexdecillion times more data than is believed to exist on the Web, so you’re going to need to upgrade your hard drive.
To shuffle a deck, simply select a random number x such that 0 <= x < 52! and retrieve the deck stored at that location.
This converts the O(n) problem that is Fisher-Yates to an O(1) problem, an entire complexity class of improvement.
Sure, you need storage space valued at a few hundred orders of magnitude greater than the world GDP, but if you didn’t specify cost-efficiency, then that’s not what you get.
If you’ve got a thousand galaxies worth of free space you can just fill them with
actual decks of cards – one for each permutation – and physically pick one at random. That sounds convenient, right?
You’re also going to need a really, really good PRNG to ensure that the 226-bit binary number you generate has sufficient entropy. You could always use a real
physical deck of cards to seed it, Solitaire/Pontifex-style, and go full meta, but I
worry that doing so might cause this particular simulation of the Universe to implode, sooo… do it at your own risk?
Perhaps we can do one better, if we’re willing to be a little sillier…
If you live in a universe in which quantum optimised shuffling isn’t possible, the technique below can be adapted to create a universe in which it is.
Assuming the many-worlds interpretation of quantum mechanics is applicable to reality, there’s a
yet-more-efficient way to shuffle a deck of cards, inspired by the excellent (and hilarious) quantum bogosort algorithm:
Create a superposition of all possible states of a deck of cards. This divides the universe into 52! universes; however, the division has no cost, as it happens constantly anyway.
Collapse the waveform by observing your shuffled deck of cards.
The unneeded universes can be destroyed or retained as you see fit.
Let me know if you manage to implement either of these.