Automattic has acquired the ActivityPub plugin for WordPress from German developer Matthias Pfefferle, who will be joining the company to continue improving support for federated platforms. Pfefferle, who is also the
author of the Webmention plugin, said his new role is to see how Automattic’s products can benefit from open protocols like
ActivityPub.
…
This is so exciting I might burst. Want to know why?
Matt Mullenweg‘s commitment to ActivityPub makes me happy. WordPress made Pingback and Trackback take off, back
in the day, and I believe that – in the same way – Automattic can help make ActivityPub more accessible and mainstream too.
Matthias Pfefferle is both an IndieWeb and an ActivityPub star; I use (and I’ve extented upon) a lot of code he’s written every day and
I sponsor him on Github! The chance that we get to work directly together is pretty slim, but it’s a chance right?
Susan A. Kitchens expressed concern that this could increase the level of
ActivityPub spam out there (which right now is very low). I worry about that too. But I’m still optimistic that we can make something awesome off the back of this acquisition and keep
the interpersonal Web federated, the way it ought to be.
You know who’s having a killer month? Automattic. Everyone who’s leaving Twitter seem to fall in at least one of these three camps:
They have gone back to the blogosphere. (using WordPress, or WordPress.com)
They have gone to Tumblr
They have gone to the fediverse (of which a fairly large percentage are WordPress installs)
In all of these cases, Automattic wins.
…
Some smart observations here by Alex. A fourth point worth noting is that Matt has openly suggested that former Twitter engineers might like to come join us in Automattic and help make the web a
better place. We’ve changed our careers pages a little lately but we’re still the same awesome
company!
I’ll be downright shocked if Matt isn’t working very hard to get Tumblr on the fediverse ASAP. He has so much to gain in supporting this movement, and very little to lose.
That’s definitely on his mind too, which I can safely say without leaking anything because he’s hinted at it himself. Exciting times.
This weekend I was experimentally reimplenting how my blog displays comments. For testing I needed to find an old post with both trackbacks and pingbacks on it. I found my post that you linked, here, and was delighted to be reminded that despite both of our blogs changing domain name (from photomatt.net to ma.tt
and from blog.scatmania.org to danq.me, respectively), all the links back and forth still work perfectly because clearly we share an apporopriate dedication to the principle that
Cool URIs Don’t Change, and set up our redirects accordingly. 🙌
Incidentally, this was about the point in time at which I first thought to myself “hey, I like what Matt’s doing with this Automattic thing; I should work there someday”. It took me
like a decade to a decade-and-a-half to get around to applying, though… 😅
Anyway: thanks for keeping your URIs cool so I could enjoy this trip down memory lane (and debug an experimental wp_list_comments callback!).
That’s a really useful thing to have in this new age of the web, where Refererer: headers are no-longer commonly passed cross-domain and Google Search no longer provides the link: operator. If you want to know if I’ve ever
linked to your site, it’s a bit of a drag to find out.
To nobody’s surprise whatsoever, I’ve made a so many links to Wikipedia that I might be single-handedly responsible for their PageRank.
So, obviously, I’ve written an implementation for WordPress. It’s really basic right now, but the source code can be
found here if you want it. Install it as a plugin and run wp outbound-links to kick it off. It’s fast: it takes 3-5 seconds to parse the entirety of danq.me,
and I’ve got somewhere in the region of 5,000 posts to parse.
You can see the results at https://danq.me/.well-known/links – if you’ve ever wondered “has Dan ever linked to my site?”, now you can find the
answer.
If this could be useful to you, let’s collaborate on making this into an actually-useful plugin! Otherwise it’ll just languish “as-is”, which is good enough for my purposes.
Almost nerdsniped myself when I discovered several #WordPress plugins that didn’t quite
do what I needed. Considered writing an overarching one to “solve” the problem. Then I remembered @xkcdcomic
927…
What happens when you give Gutenberg and Elementor to complete Beginners? In this challenge, Meg and Lily (two of my daughters) are tasked with re-creating a webpage. They’ve never
used Elementor or Gutenberg before, and I only gave them 30 minutes each.
…
Jamie of Pootlepress challenged his daughters – who are presumably both digital natives, but have no WordPress experience – to build a page to a specific design using both Gutenberg and Elementor. In 30 minutes.
Regardless of what you think about the products under test or the competitors in the challenge (Lily + Gutenberg clearly seems to be the fan favourite, which I’d sort-of expect because
IMO Gutenberg’s learning curve is much flatter that Elementor’s), this is a fantastic example of “thinking aloud” (“talkalong”)
UX testing. And with (only) a £20 prize on offer, it’s possibly the best-value testing of its type I’ve ever seen too! Both the
participants do an excellent job of expressing their praise of and frustration with different parts of the interface of their assigned editing platform, and the developers of both – and
other systems besides – could learn a lot from watching this video.
Specifically, this video shows how enormous the gulf is between how developers try to express concepts that are essential to web design and how beginner users assume things will work.
Concepts like thinking in terms of “blocks” that can resize or reposition dynamically, breakpoints, assets as cross-references rather than strictly embedded within documents, style as
an overarching concept by preference to something applied to individual elements, etc… some as second nature once you’re sixteen levels deep into the DOM and you’ve been doing it for years! But they’re rarely intuitive… or, perhaps, not expressed in a way that makes them intuitive… to new users.
Wix, the website builder company you may remember from stealing WordPress code and lying about it, has now decided the best way
to gain relevance is attacking the open source WordPress community in a bizarre
set of ads. They can’t even come up with original concepts for attack ads, and have tried to rip-off of Apple’s Mac vs PC ads, but tastelessly personify the WordPress community
as an absent, drunken father in a therapy session.
I have a lot of empathy for whoever was forced to work on these ads, including the actors, it must have felt bad working on something that’s like Encyclopedia Britannica
attacking Wikipedia. WordPress is a global movement of hundreds of thousands of volunteers and community members, coming together to make the web a better place. The code,
and everything you put into it, belongs to you, and its open source license ensures that you’re in complete control, now and forever. WordPress is free, and also gives you freedom.
…
For those that haven’t been following the relevant bits of tech social media this last week, here’s the insanity you’ve missed:
Wix’s Twitter and YouTube responses suddenly swing from their usual “why is your customer service so slow to respond to me?” level of negative to outright hostile. LOL.
Sure, I’m not the target audience. I’ve been a WordPress user for 15 years, and every time I visit a Wix site it annoys me when I have to permit a stack of third-party JavaScript just
to load images like they’ve never heard of the <img>tag or something. Hell, I like WordPress enough that I used it as a
vehicle to get a job with Automattic, a company most-famous for its WordPress hosting provision. But even putting all of that aside: this
advertising campaign stinks.
May 27th, 17 years ago, the first release of WordPress was put into the world by Mike Little and myself. It did not have an installer, upgrades, WYSIWYG editor (or hardly any
Javascript), comment spam protection, clean permalinks, caching, widgets, themes, plugins, business model, or any funding.
…
Seventeen years ago, WordPress was first released.
Sixteen years, eleven months ago, I relaunched I relaunched my then-dormant blog. I considered WordPress/b2/cafelog, but went with a
now-dead engine called Flip instead.
Fifteen years, ten months ago, in response to a technical failure on the server I was using, I lost it all and had to recover my posts from backups. Immediately afterwards, I took the opportunity to redesign my blog and switch to WordPress. On the same day, I attended the graduation ceremony for my first degree (but somehow didn’t think this was worth blogging
about).
Fifteen years, nine months ago, Automattic Inc. was founded to provide managed WordPress hosting services. Some time later, I thought to myself: hey, they seem like a cool company, and
I like everything Matt’s done so far. I should perhaps work there someday.
I use the Post Kinds plugin to streamline the management of the different types of posts I make on my blog, based on the
IndieWeb post types list: articles, like this one, are “conventional” blog posts, but I also publish
notes (which are analogous to “tweets”), reposts (“shares” of things I’ve found online, sometimes with commentary), checkins (mostly chronicling my geocaching/geohashing), and others: I’ve extended Post Kinds to facilitate comics and
reviews, for example.
But for people who subscribe (either directly or indirectly) to everything I post, I imagine it must be a little frustrating to sometimes be
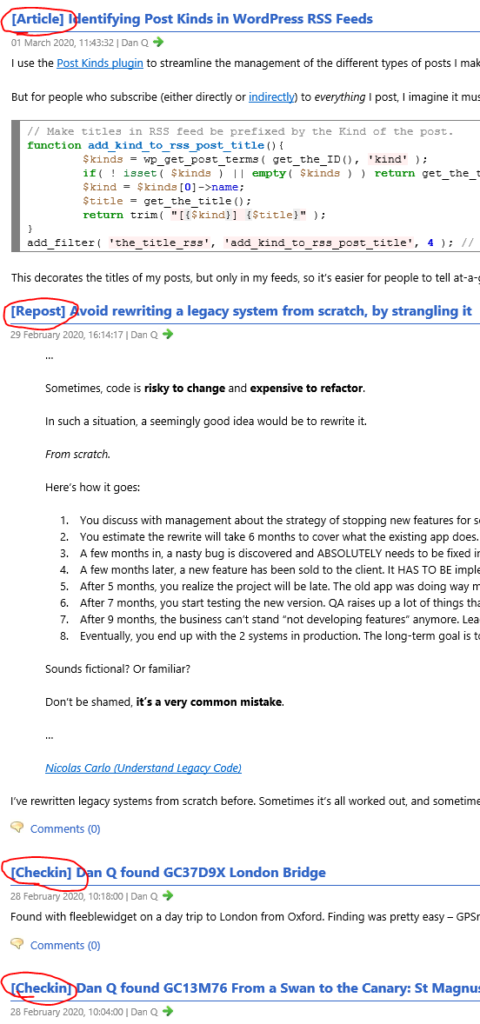
unable to identify the type of a post before clicking-through. So I’ve added the following code, which I’m sharing here and on GitHub in case it’s of any use to anybody else, to my theme’s functions.php:
// Make titles in RSS feed be prefixed by the Kind of the post.functionadd_kind_to_rss_post_title(){
$kinds= wp_get_post_terms( get_the_ID(), 'kind' );
if( !isset( $kinds ) ||empty( $kinds ) ) return get_the_title(); // sanity-check.$kind=$kinds[0]->name;
$title= get_the_title();
return trim( "[{$kind}] {$title}" );
}
add_filter( 'the_title_rss', 'add_kind_to_rss_post_title', 4 ); // priority 4 to ensure it happens BEFORE default escaping filters.
This decorates the titles of my posts, but only in my feeds, so it’s easier for people to tell at-a-glance what’s going on:
Down the line I might expand this so that it doesn’t show if the subscriber is, for example, asking only for articles (e.g. via this
feed); I’m coming up with a huge list of things I’d like to do at IndieWebCamp London! But for now, this feels like a nice simple
improvement to a plugin I love that helps it to fit my specific needs.
When I arrived at this weekend’s IndieWebCamp I still wasn’t sure what it was that I would be
working on. I’d worked recently to better understand the ecosystem surrounding DanQ.me and had a number of half-formed ideas about tightening
it up. But instead, I ended up expanding the reach of my “personal web” considerably by adding reviews as a post type to my site and building
tools to retroactively-reintegrate reviews I’d written on other silos.
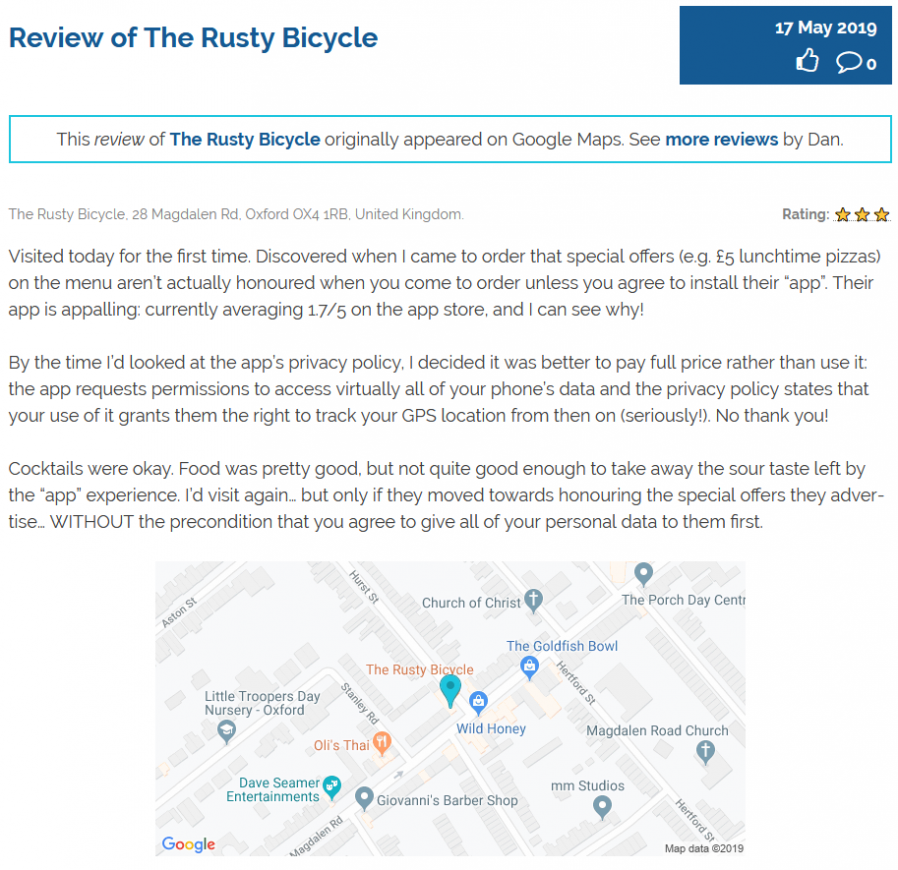
The oldest surviving review I found was my grumbling about Windows XP Home edition being just a crippled version of Pro edition. And now it’s immortalised here.
Over the years, I’ve written reviews of products using Amazon and Steam and of places using Google Maps and TripAdvisor. These are silos and my
content there is out of my control and could, for example, be deleted at a moment’s notice. This risk was particularly fresh in my mind as my friend Jen‘s Twitter account was suspended this weekend for allegedly violating the platform’s rules
(though Twitter have so far proven unwilling to tell her which rules she’s broken or even when she did so, and she’s been left completely in the dark).
My mission for the weekend was to:
Come up with a mechanism for the (microformat-friendly) display of reviews on this site, and
Reintegrate my reviews from Amazon, Steam, Google Maps and TripAdvisor
Steam reviews use a “thumbs up/thumbs down” rating system rather than a “5-star” style, but h-review is capable of expressing both and more.
I opted not to set up an ongoing POSSE nor PESOS process at this point; I’ll do this manually in the short term (I don’t write reviews on third-party sites often). Also out of
scope were some other sites on which I’ve found that I’ve posted reviews, for example BoardGameGeek. These can both be tasks for a future date.
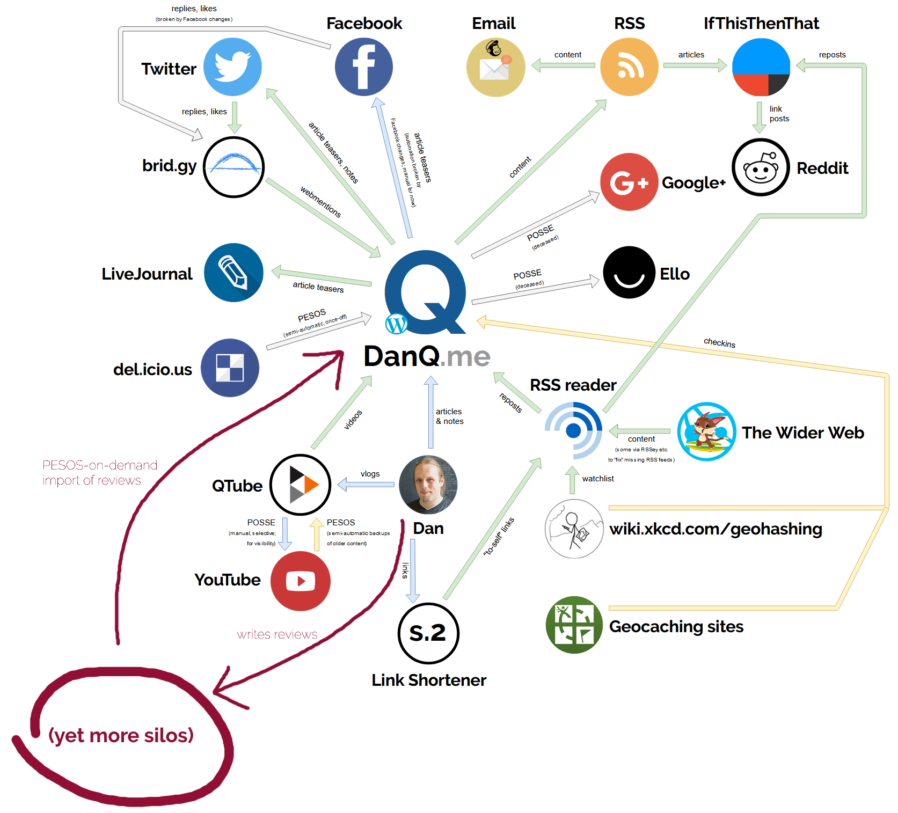
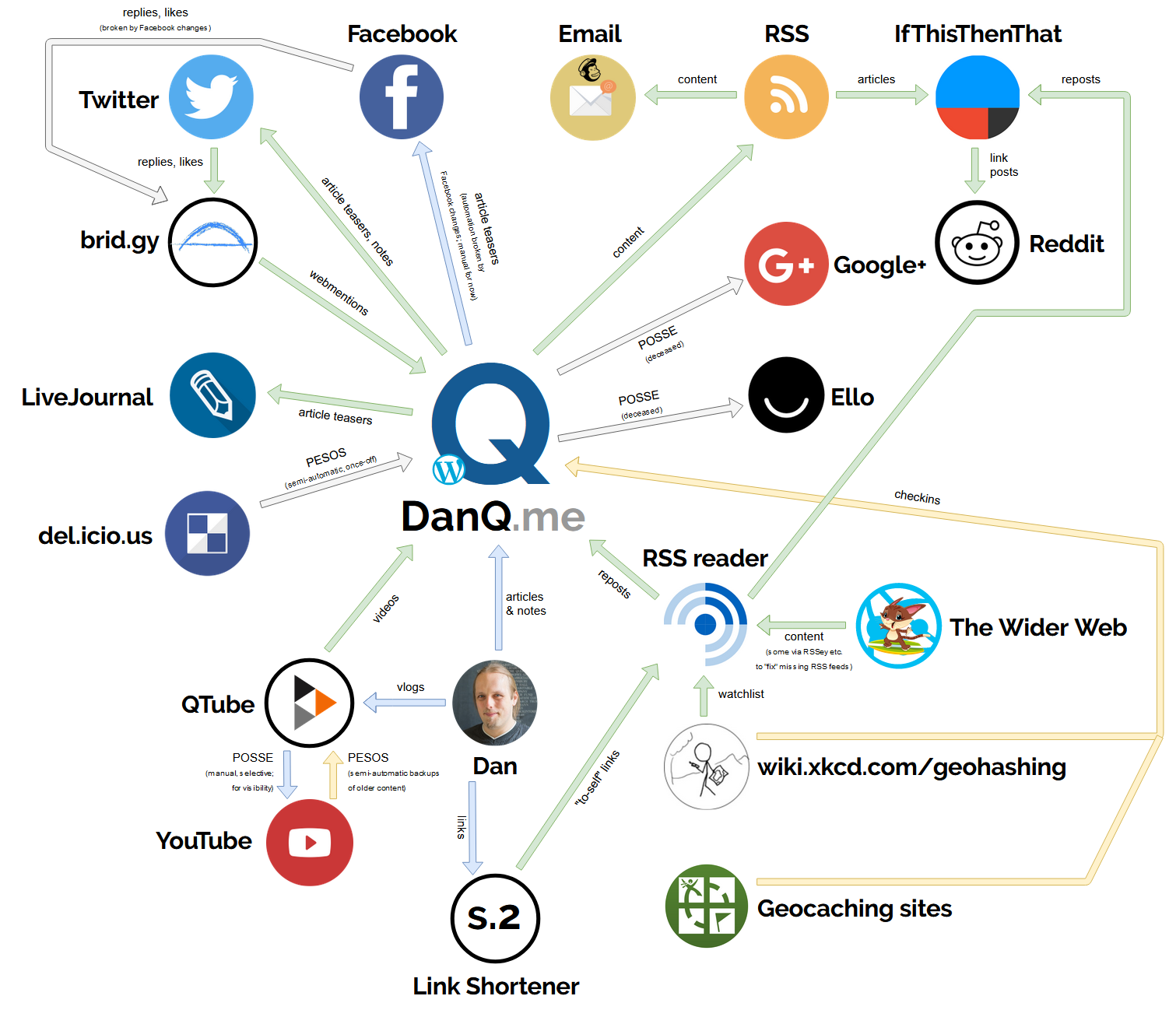
The lovely diagram I drew earlier this year? Here it is with the new loop drawn on.
I used Google Takeout to export my Google Maps reviews, which comprised the largest number of reviews of the sites I targetted and which is the
least screen-scraper friendly. I wrote a bookmarklet-based screen-scraper to get the contents of my reviews on each of the other sites. Meanwhile, I edited by WordPress theme’s functions.php to extended the Post Kinds plugin with an
extra type of post, Review, and designed a content template which wrapped reviews in appropriate microformat markup, using metadata attached to each review post to show e.g. a
rating, embed a h-product (for products) or h-card (for
places). I also leveraged my existing work from last summer’s effort to reintegrate my geo*ing logs to automatically
add a map when I review a “place”. Finally, I threw together a quick WordPress plugin to import the data and create a stack of draft posts for proofing and publication.
I was moderately unimpressed by Oxford pub The Rusty Bicycle. I originally said so on Google Maps, and now I can say so here, too!
So now you can read all of the reviews I’ve ever posted to any of those four sites, right here, alongside any other reviews I subsequently reintegrate and any
I write directly to my blog in the future. The battle to own all of my own content after 25 years of scattering it throughout the Internet isn’t always easy, but it remains worthwhile.
(I haven’t open-sourced my work this time because it’s probably useful only to me and my very-specific set-up, but if anybody wants a copy they can get in
touch.)
With IndieWebCamp Oxford 2019 scheduled to take place during the
Summer of Hacks, I drew a diagram (click to embiggen) of the current ecosystem that powers and propogates the
content on DanQ.me. It’s mostly for my own benefit – to be able to get a big-picture view of the ways my website talks to the world and plan for what improvements I
might be able to make in the future… but it also works as a vehicle to explain what my personal corner of the IndieWeb does and how it does it.
Here’s a summary:
DanQ.me
Since fifteen years ago today, DanQ.me has been powered by a self-hosted WordPress installation. I
know that WordPress isn’t “hip” on the IndieWeb this week and that if you’re not on the JAMstack you’re yesterday’s news, but at 15 years and counting my
love affair with WordPress has lasted longer than any romantic relationship I’ve ever had with another human being, so I’m sticking with it. What’s cool in Web technologies comes and
goes, but what’s important is solid, dependable tools that do what you need them to, and between WordPress, half a dozen off-the-shelf plugins and about a dozen homemade ones I’ve got
everything I need right here.
I’d been “blogging” – not that we called it that, yet – since late 1998, but my original collection of content-mangling Perl scripts wasn’t all that. More history…
I write articles (long posts like this) and notes (short, “tweet-like” updates) directly into the site, and just occasionally
other kinds of content. But for the most part, different kinds of content come from different parts of the ecosystem, as described below.
RSS reader
DanQ.me sits at the centre of the diagram, but it’s worth remembering that the diagram is deliberately incomplete: it only contains information flows directly relevant to my blog (and
it doesn’t even contain all of those!). The last time I tried to draw a diagram like this that described my online life in general, then my RSS reader found its way to the centre. Which figures: my RSS reader is usually the first
and often the last place I visit on the Internet, and I’ve worked hard to funnel everything through it.
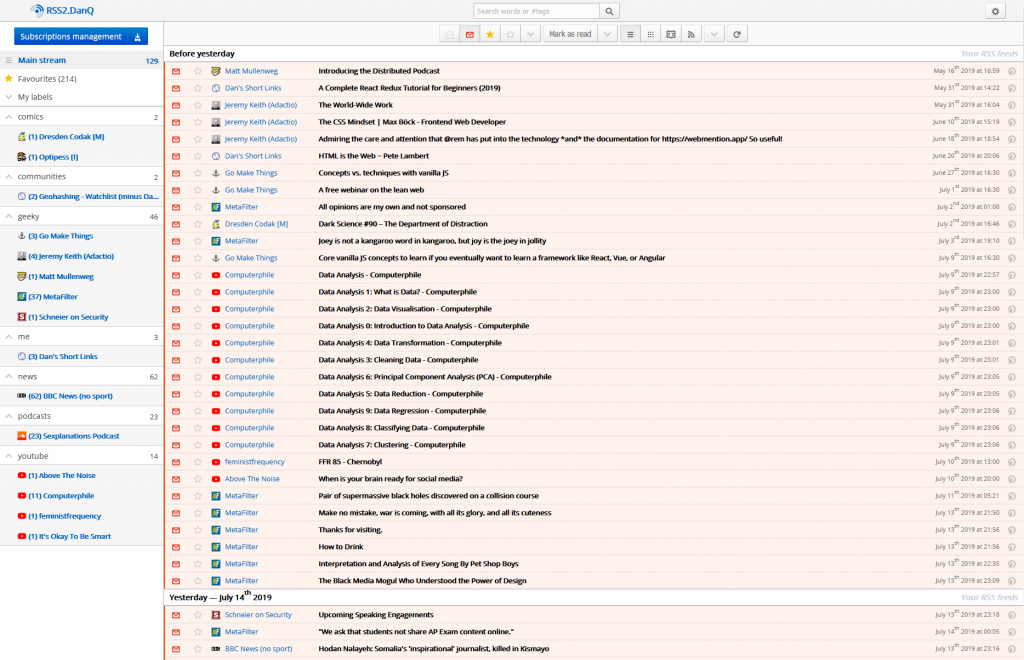
129 unread items is a reasonable-sized queue: I try to process to “RSS zero”, but there are invariably things I want to return to on a second-pass and I’ve not yet reimplemented the
“snooze button” I added to my previous RSS reader.
Right now I’m using FreshRSS – plus a handful of plugins, including some homemade ones – as my RSS reader: I switched from Tiny Tiny RSS about a year ago to take advantage of FreshRSS’s excellent responsive
themes, among other features. Because some websites don’t have RSS feeds, even where they ought to, I use my own tool
RSSey to retroactively “fix” people’s websites for them, dynamically adding feeds for my
consumption. It’s also a nice reminder that open source and remixability were cornerstones of the original Web. My RSS reader
collates information from a variety of sources and additionally gives me a one-click mechanism to push content I enjoy to my blog as a repost.
QTube
QTube is my video hosting platform; it’s a PeerTube node. If you haven’t seen it, that’s fine: most content
on it is consumed indirectly either through my YouTube channel or directly on my blog as posts of the “video” kind. Also, I don’t actually vlog very often. When I do publish videos onto QTube, their republication onto YouTube or DanQ.me is optional: sometimes I plan to
use a video inside an article post, for example, and so don’t need to republish it by itself.
I’m gradually exporting or re-uploading my backlog of YouTube videos from my current and previous channels to QTube in an effort to
recentralise and regain control over their hosting, but I’m in no real hurry. PeerTube certainly makes it easy, though!
Link Shortener
I operate a private link shortener which I mostly use for the expected purpose: to make links shorter and so easier to read out and memorise or else to make them take up less space in a
chat window. But soon after I set it up, many years ago, I realised that it could also act as a mechanism to push content to my RSS reader to “read later”. And by the time I’m using it for that, I figured, I might as well also be using it to repost content to my blog
from sources that aren’t things my RSS reader subscribes to. This leads to a process that’s perhaps unnecessarily
complex: if I want to share a link with you as a repost, I’ll push it into my link shortener and mark it as going “to me”, then I’ll tell my RSS reader to push it to my blog and there it’ll be published to the world! But it works and it’s fast enough: I’m not in the habit
of reposting things that are time-critical anyway.
Checkins
You know your sport is fringe when you need to reference another fringe sport to describe it. “Geohashing? It’s… a little like geocaching, but…”
I’ve been involved in brainstorming ways in which the act of finding (or failing to find, etc.) a geocache or reaching (or failing to
reach) a geohashpoint could best be represented as a “checkin“, and last year I open-sourced my plugin for pulling logs (with as much automation as is permitted by the terms of service of some of the
silos involved) from geocaching websites and posting them to WordPress blogs: effectively PESOS-for-geocaching. I’d prefer to be publishing on my own blog in the first instance, but syndicating my adventures from various
silos into my blog is “good enough”.
Syndication
New notes get pushed out to my Twitter account, for the benefit of my Twitter-using friends. Articles get advertised on Facebook, Twitter and LiveJournal (yes, really) in teaser form, for the benefit of friends
who prefer to get notifications via those platforms. Facebook have been fucking around with their APIs and terms of
service lately and this is now less-automatic than it used to be, which is a bit of an annoyance. My RSS feeds carry copies
of content out to people who prefer to subscribe via that medium, and I’ve also been using this to power an experimental MailChimp “daily digest” mailing list of “what Dan’s been up to”
to a small number of friends, right in their email inboxes: I’ve not made it available to everybody yet, but if you’re happy to help test it then give me a shout
and I’ll hook you up.
Most days don’t see an email sent or see an email with only one item, but some days – like this one – are busier. I still need to update the brand colours here, too!
Finally, a couple of IFTTT recipes push my articles and my reposts to Reddit communities: I don’t
really use Reddit myself, any more, but I’ve got friends in a few places there who prefer to keep up-to-date with what I’m up to via that medium. For historical reasons, my reposts to
Reddit don’t go directly via my blog’s RSS feeds but “shortcut” directly from my RSS reader: this is suboptimal because I don’t get to tweak post titles for Reddit but it’s not a big deal.
What IFTTT does isn’t magic, but it’s often indistinguishable from it.
I used to syndicate content to Google+ (before it joined the long list of Things Google Have Killed) and to Ello
(but it never got much traction there). I’ve probably historically syndicated to other places too: I’ve certainly manually-republished content to other blogs, from time to time, too.
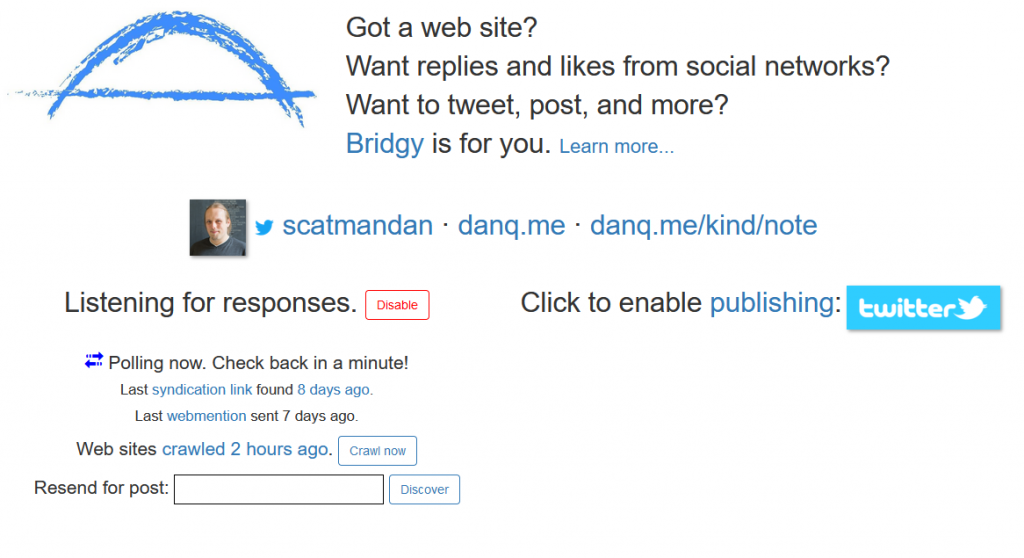
I use Ryan Barrett‘s excellent Brid.gy to convert Twitter replies and likes back into Webmentions for publication as comments on my blog. This used to work for Facebook, too, but again: Facebook
fucked it over. I’ve occasionally manually backfed significant Facebook comments, but it’s not ideal: I might like to look at using similar technologies to RSSey to subvert
Facebook’s limitations.
I’ve never had a need for Brid.gy’s “publishing” (i.e. POSSE) features, but its backfeed features “just work”, and it’s awesome.
Reintegration
I’ve routinely retroactively reintegrated content that I’ve produced elsewhere on the Web. This includes my previous blogs (which is why you can browse my archives, right here on this
site, all the way back to some of the cringeworthy angsty-teenager posts I made in the 1990s) but also some Reddit posts,
some replies originally posted directly to other people’s blogs, all my old del.icio.us bookmarks, long-form forum
posts, posts I made to mailing lists and newsgroups, and more. As a result, there’s a lot of backdated content on this site, nowadays: almost a million words, and significantly
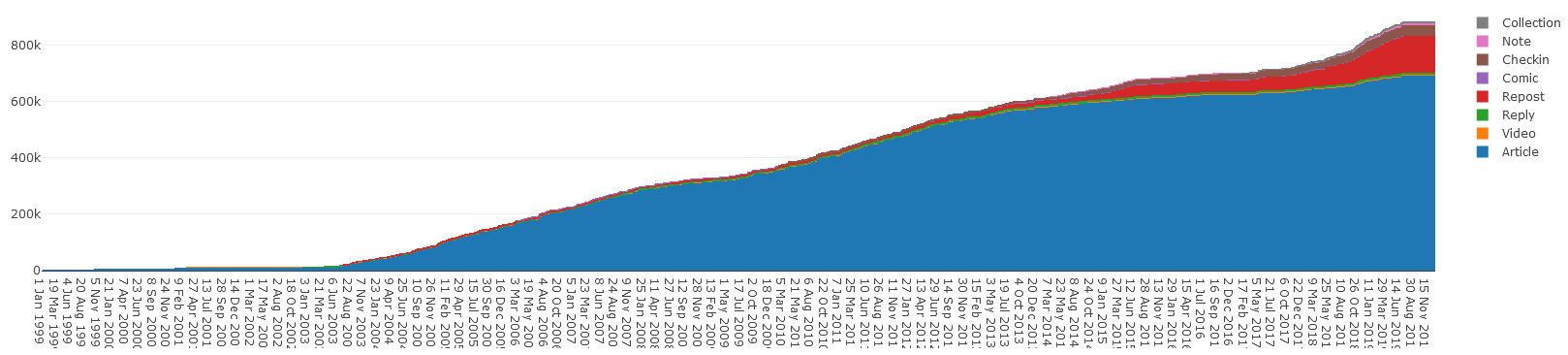
more than the 600,000 or so I counted a few years ago, before my biggest push for reintegration!
Cumulative wordcount per day, by content type. The lion’s share has always been articles, but reposts are creeping up as I’ve been writing more about the things I reshare, lately.
It’d be interesting to graph the differentiation of this chart to see the periods of my life that I was writing the most: I have a hypothesis, and centralising my own content under my
control makes it easier
Why do I do this? Because I really, really like owning my identity online! I’ve tried the “big” silo alternatives like Facebook, Twitter, Medium, Instagram etc., and they’ve eventually
always lead to disappointment, either because they get shut down or otherwise made-unusable, because
of inappropriately-applied “real names” policies, because they give too much power to
untrustworthy companies, because they impose arbitrary limitations on my content, because they manipulate output
promotion (and exacerbate filter bubbles), or because they make the walls of their walled gardens taller and stop you integrating with them how you used to.
A handful of silos have shown themselves to be more-trustworthy than the average – in particular, eschewing techniques that promote “lock-in” – and I’d love to tell you more about them
and what I think you should look for in a silo, another time. But for now: suffice to say that just like I don’t use YouTube like most people do, I
elect not to use Facebook or Twitter in the conventional ways either. And it’s awesome, thanks.
There are plenty of reasons that people choose to take control of their own Web presence – and everybody who puts content online ought to consider
it – but I imagine that few individuals have such a complicated publishing ecosystem as I do! Now you’ve got a picture of how my digital content production workflow works, and
perhaps start owning your online identity, too.
Like Automattic (Matt’s company), Three Rings has also long been ahead of the curve from a “recruit
talent from wherever it is, let people work from wherever they are” perspective. Until I was recently reading (more than I had previously) about the way that Automattic “works” I was
uncertain about the scalability of Three Rings’ model. Does it work for a commercial company (rather than a volunteer-run non-profit like Three Rings)? Does it work when you make the
jump from dozens of staff to hundreds? It’s reassuring to see that yes, this kind of approach certainly can work, and to get some context on how it does (in Automattic’s case,
at least). Nice video, Matt!
As an ocassional geocacher and geohasher, I’m encouraged to post logs describing my adventures, and each major provider wants me to post my logs into theirsilo (see e.g. my logs on geocaching.com, on opencache.uk, and on the geohashing wiki). But as a believer in
the ideals behind the IndieWeb (since long before anybody said “IndieWeb”), I’m opposed to keeping the only copy of content that I produce in an
environment controlled by somebody else (why?).
How do I reconcile this?
Just another hundred metres to the cache, then it’s time to freeze my ass back to base.
What I’d prefer would be to be able to write my logs here, on my own blog, and for my content to by syndicated via some process into the logging systems of the various silo sites I
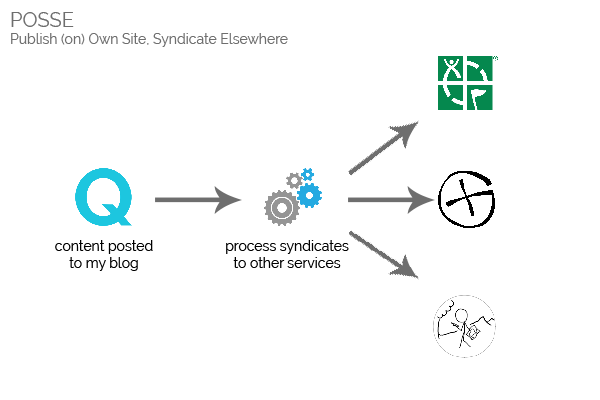
prefer. This approach is called POSSE – Publish on Own Site, Syndicate
Elsewhere. In addition to the widely-described benefits of this syndication strategy, such a system would also make it possible for me to:
write single posts that represent the same location published on multiple silos (e.g. a visit to a geocache published on two different listing sites [e.g. 1, 2])
Applying such an tool would require some work as different silos have different acceptable content rules (geocaching.com, for example, effectively forbids mention of the existence of
other geocache listing sites), but that’d theoretically be workable.
The ideal solution would be POSSE-based.
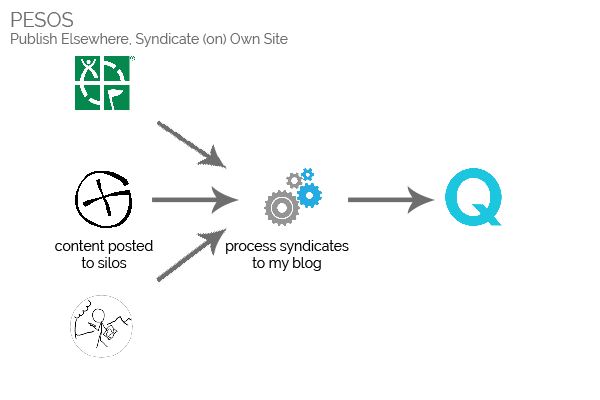
Unfortunately, content rules aren’t the only factor making PESOS – writing content into each silo and then copying it
to my blog – preferable to POSSE. There’s also:
Not all of the silos offer suitable (published) APIs, and where they do, the APIs are all distinctly different.
Geocaching.com specifically forbids the use of unapproved automated robots to access the site (and almost
certainly wouldn’t approve the kind of tool that would be ideal).
The siloed services are well-supported by official and third-party apps with medium-specific logic which make them the best existing way to produce logs.
A PESOS-based solution is far easier to implement, in this case.
Needless to say: as much as I’d have loved to POSSE my geo* logs, PESOS will do.
Implementation
My implementation is a WordPress plugin which does two things. The first is that it provides a Javascript bookmarklet and an
accompanying dynamically-generated Javascript file (the former loads the latter) served from my blog’s domain. That Javascript file contains reference to every log already published to
my blog, so that the Javascript code can deliberately omit these logs from any import. When executed on a log listing page like those linked above, it copies all of the details of that
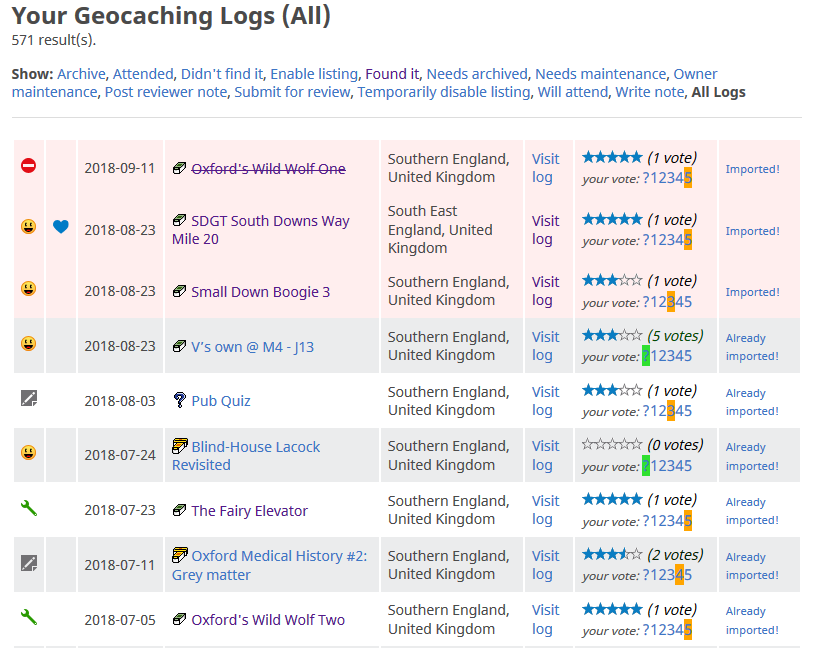
log into a form which submits them back to my blog, where it’s received by the second part of the plugin.
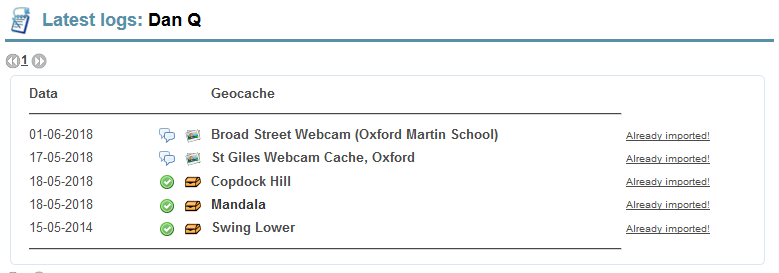
The import controls appear in a new, right-most column (GCVote is also visible running in my browser).
The second part of the plugin takes this data and creates a new draft post. My plugin is pretty opinionated on this part because it’s geared strongly towards my use-case, so if you want
to use it yourself you’ll probably want to tweak the code a little (e.g. it applies specific tags and names metadata fields a particular way).
When run on OpenCache.uk effectively the same interface is presented, even though the underlying mechanisms and data locations are different.
It’s not fully-automated and it’s not POSSE,but it’s “good enough” and it’s enabled me to synchronise all of my cache logs to my blog. I’ve plans to extend it to support other GPS game services to streamline my de-siloisation even further.
One of the most-popular WordPress plugins is Jetpack, a product of Automattic (best-known for providing the widely-used WordPress hosting service “WordPress.com“). Among Jetpack’s
features (many of which are very good) is Jetpack Protect which adds – among other things – the possibility for a CAPTCHA to appear on your login pages. This feature is slightly worse than pointless as it makes
it harder for humans to log in but has no significant impact upon automated robots; at best, it provides a false sense of security and merely frustrates and slows down legitimate human
editors.
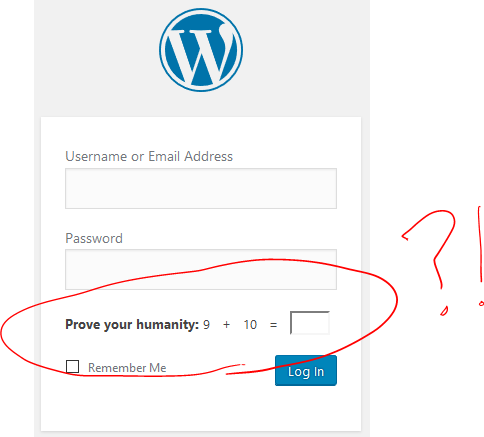
Thanks, WordPress, for slowing me down with a CAPTCHA that a robot can solve more-easily than a human.
“Proving your humanity”, as you’re asked to do, is a task that’s significantly easier for a robot to perform than a human. Eventually, of course, all tests of this nature seem likely to fail as robots become smarter than humans
(especially as the most-popular system is specifically geared towards training robots), but that’s hardly an excuse for inventing a system
that was a failure from its inception. Jetpack’s approach is fundamentally flawed because it makes absolutely no effort to disguise the challenge in a way that humans are able to read
any-differently than robots. I’ll demonstrate that in a moment.
Don’t just disable this, though! Other “Protect” features make sense. If only you could disable just the one that doesn’t…
A while back, a colleague of mine network-enabled Jetpack Protect across a handful of websites that I occasionally need to log into, and it bugged me that it ‘broke’ my password safe’s
ability to automatically log me in. So to streamline my workflow – as well as to demonstrate quite how broken Jetpack Protect’s CAPTCHA is, I’ve written a userscript that you can install into your web browser that will
completely circumvent it, solving the maths problems on your behalf so that you don’t have to. Here’s how to use it:
Install a userscript manager into your browser if you don’t have one already: I use Tampermonkey, but it ought to work with almost any of
them.
From now on, whenever you go to a page whose web path begins with “/wp-login.php” that contains a Jetpack Protect maths problem, the answer will be automatically calculated and
filled-in on your behalf. The usual userscript rules apply: if you don’t trust me, read the source code (there are really only five lines to check) and disable automatic updates for it
(especially as it operates across all domains), and feel free to adapt/improve however you see fit. Maybe if we can get enough people using it Automattic will fix this
half-hearted CAPTCHA – or at least give us a switch to disable it in the first
place.
Update: 15 October 2018 – the latest version of Jetpack makes an insignificant change to this CAPTCHA; version 1.2 of this script (linked above) works around the change.